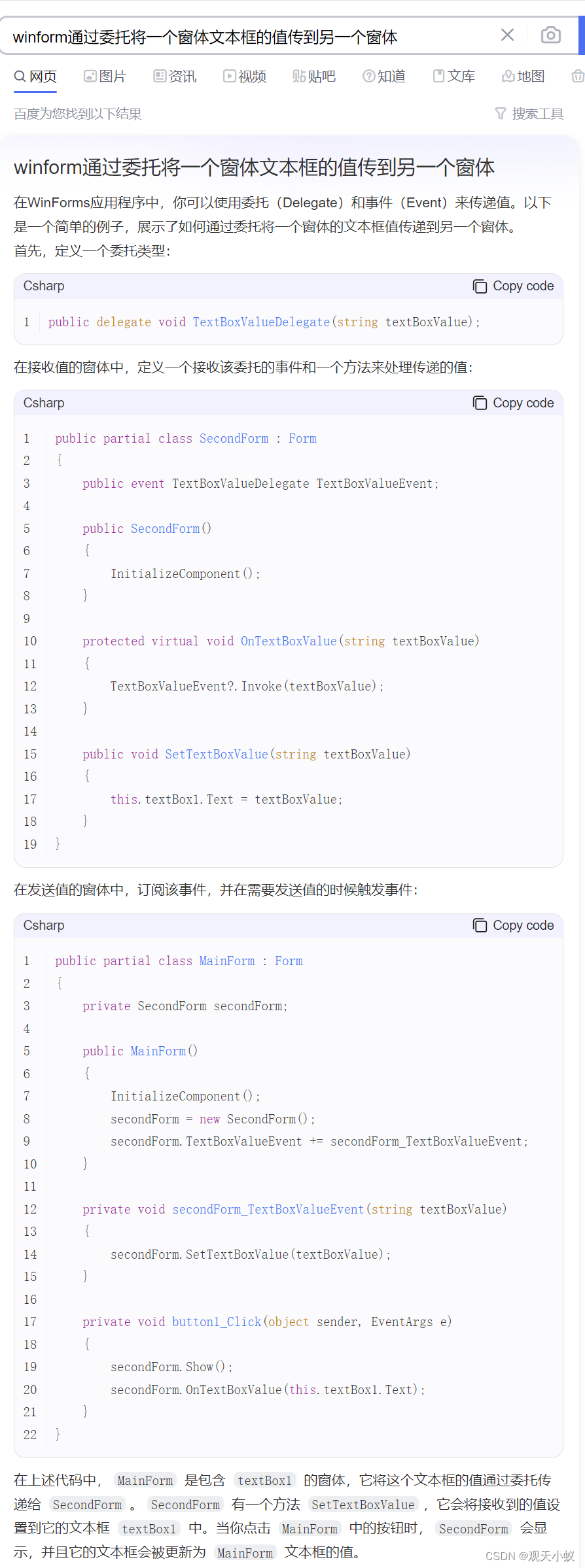
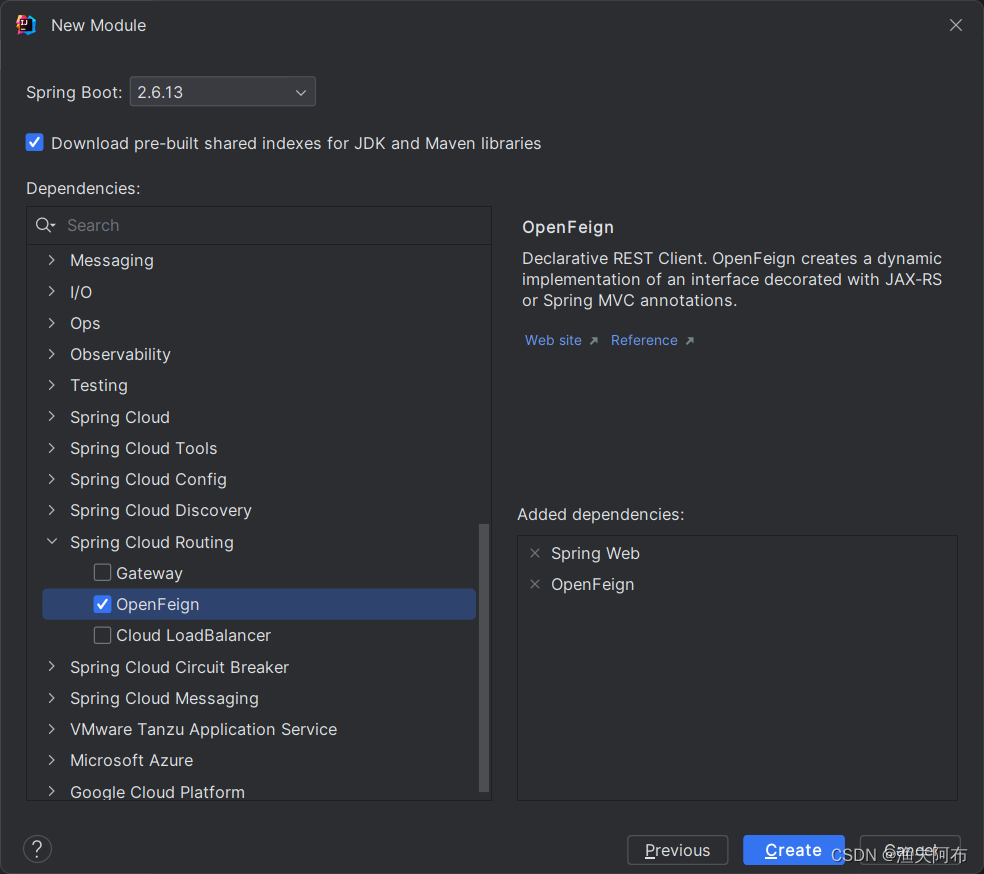
一.知识目录:
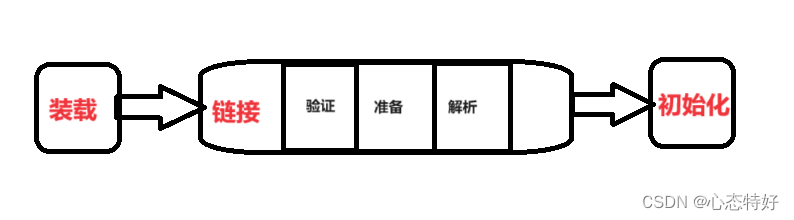
二.什么是java异常:
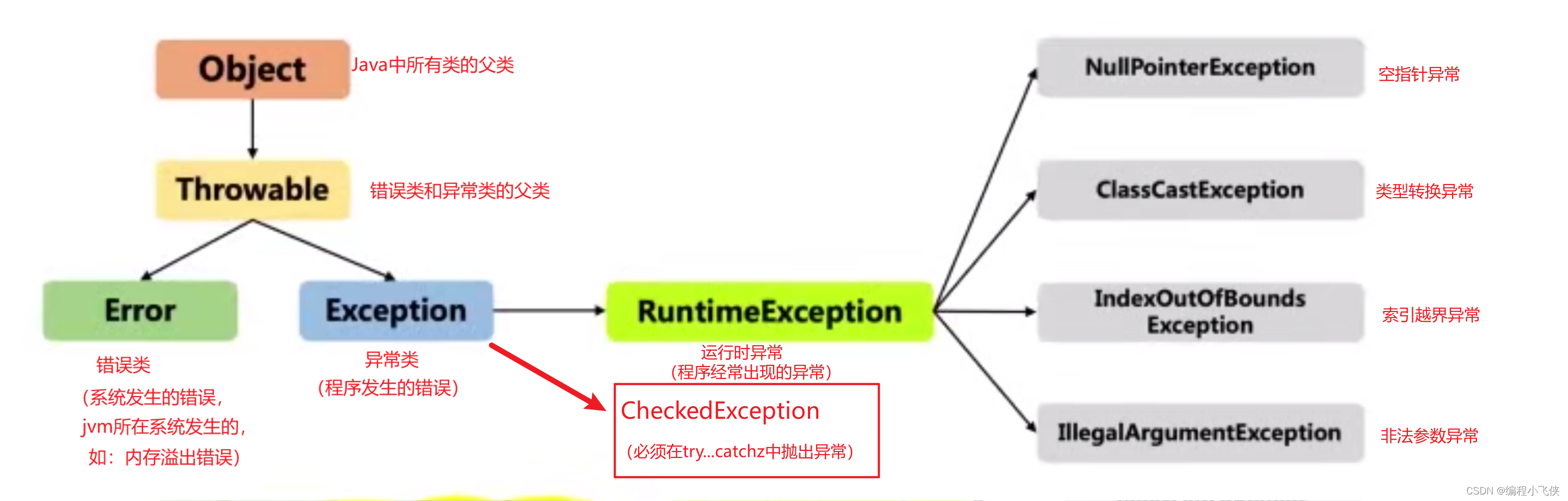
2.1 Throwable类中的重要方法:
(1)四个构造方法(用来构造throwable对象,不同构造方法可以传递不同的参数值):
/** 构造一个将 null 作为其详细消息的新 throwable */
Throwable()
/** 构造带指定详细消息的新 throwable */
Throwable(String message)
/** 构造一个带指定 cause 和 (cause==null ? null : cause.toString())(它通常包含类和 cause 的详细消息)的详细消息的新 throwa
Throwable(Throwable cause)
/** 构造一个带指定详细消息和 cause 的新 throwable */
Throwable(String message, Throwable cause)
(2)getMessage(返回当前Throwable对象的详细消息字符串,通常我们在try catch里面,会使用getMessage记录下异常):
public String getMessage() {
return detailMessage;
}
public Throwable(String message) {
fillInStackTrace();
detailMessage = message;
}
getMessage方法中返回的detailMessage就是在构造Throwable时指定的。
(3)getLocalizedMessage(这个方法只比 getMessage 多了 “Localized”,它翻译过来的意思是 “本地化的”。getLocalizedMessage 就是加了本地化后的信息的 Message,和 getMessage 是一样的,如果要加入本地化信息要重写这个方法。):
public String getLocalizedMessage() {
// 这里直接返回了 getMessage 方法,所以,默认它们是相同的
return getMessage();
}
2.2数据结构中的堆栈:
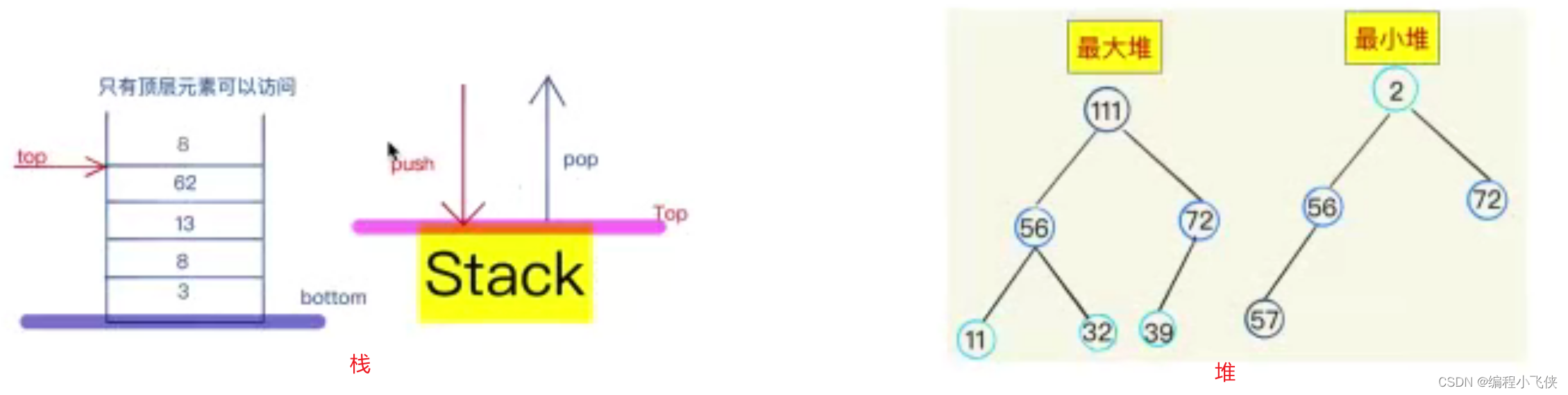
**栈:**是限制插入和删除只能在一个位置上进行的线性表
**堆:**是一种特别的树状数据结构,是一棵完全二叉树;但是,完全二叉树不一定是堆
2.3 java虚拟机中的堆和栈:
**堆和栈:**是指对内存进行操作和管理的一些方式,注意要和数据结构中的堆和栈区分开
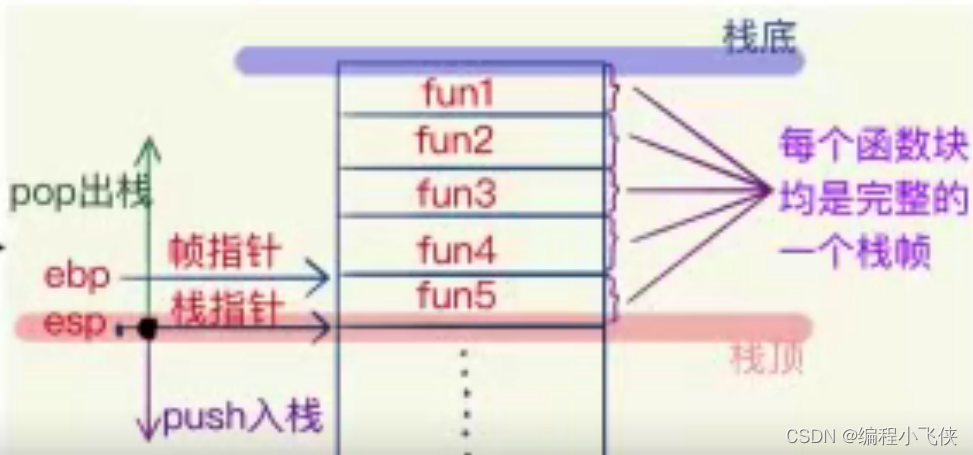
虚拟机栈的基本性质:
内存管理:由虚拟机自动分配和释放
内存存放:存放函数的参数值,局部变量的值等等,满足先进后出的原则存储
结构:栈的一端是固定的(栈顶),另一端是浮动的(栈底)
速度:由虚拟机自动分配,所以速度很快,比堆快很多
申请大小受限:默认栈空间1兆,超过内存空间限制大小,会报错
结构如下:
虚拟机堆的基本性质:
内存管理:Jvm里的堆特指用于存放java对象的内存区域。jvm堆被同一个jvm实例中的所有java线程共享。jvm堆通常由某种自动内存管理机制所管理,这种机制叫做垃圾回收。
申请/回收:由jvm做的,自动回收
JVM内存结构:
虚拟机栈可能出的两类异常:
- StackOverflowError(栈溢出)
- OutofMemoryError(栈内存空间不够)
虚拟机可能会抛出的异常:
- OutofMemoryError(堆内存空间不够)
2.4 java对异常处理的两种方法:
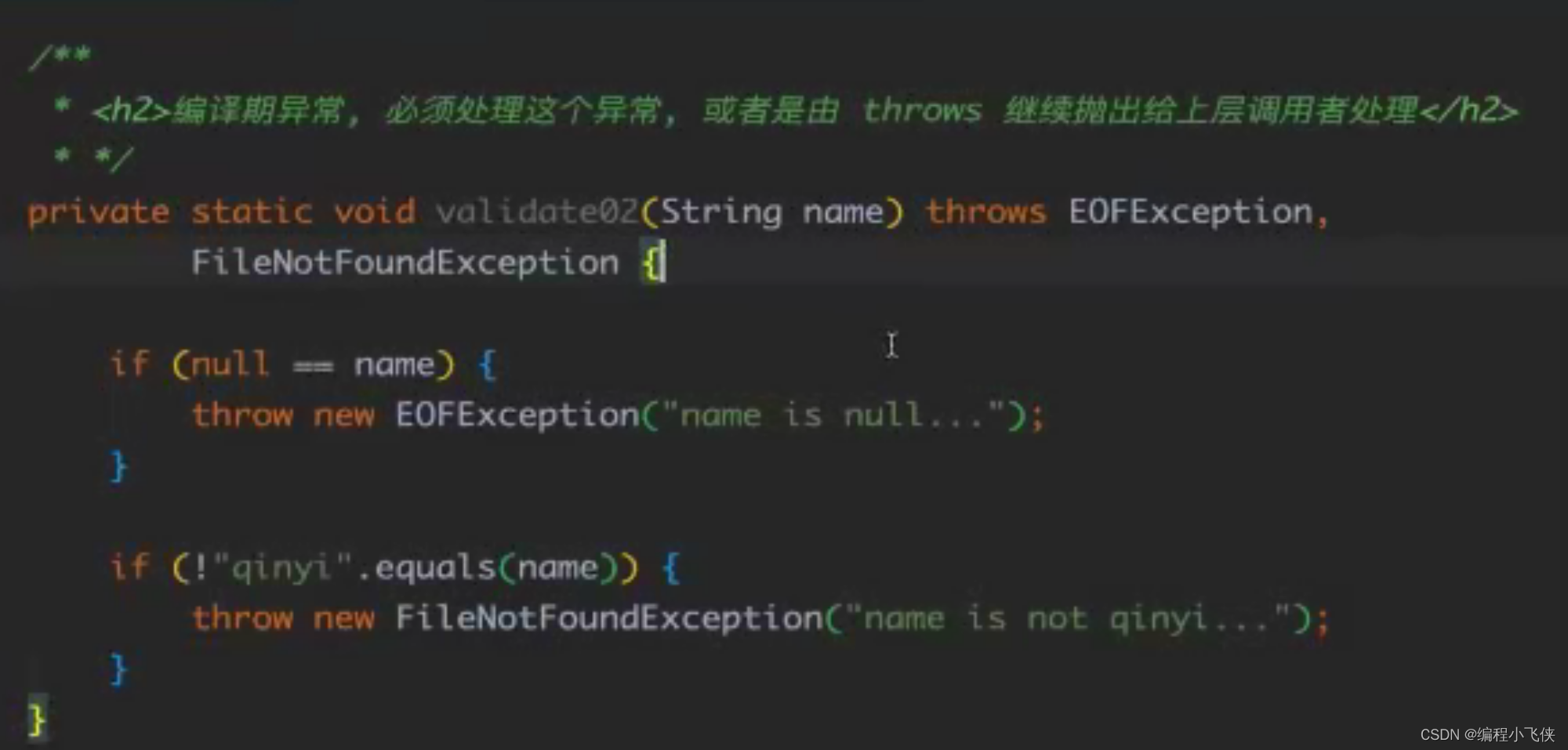
(1)声明异常:
throw关键字,它用来抛出一个指定的异常对象。必须写在方法内部,必须是Exception或Exception子类对象。

throws用在方法声明上,用于表示当前方法不处理异常,而是提醒该方法的调用者来处理异常。方法内部抛出编译器异常。
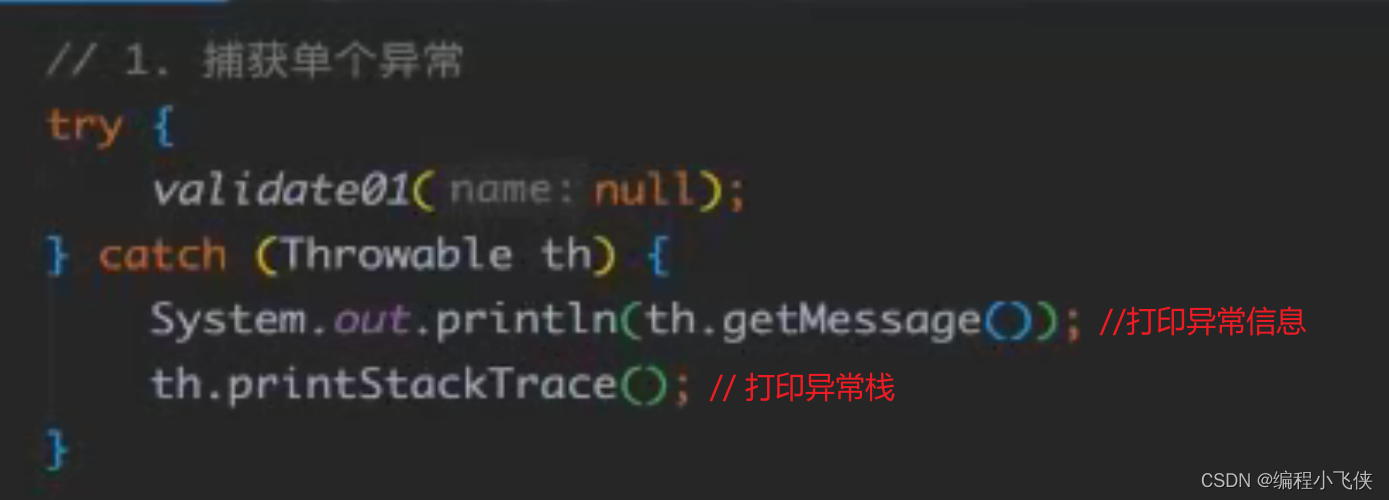
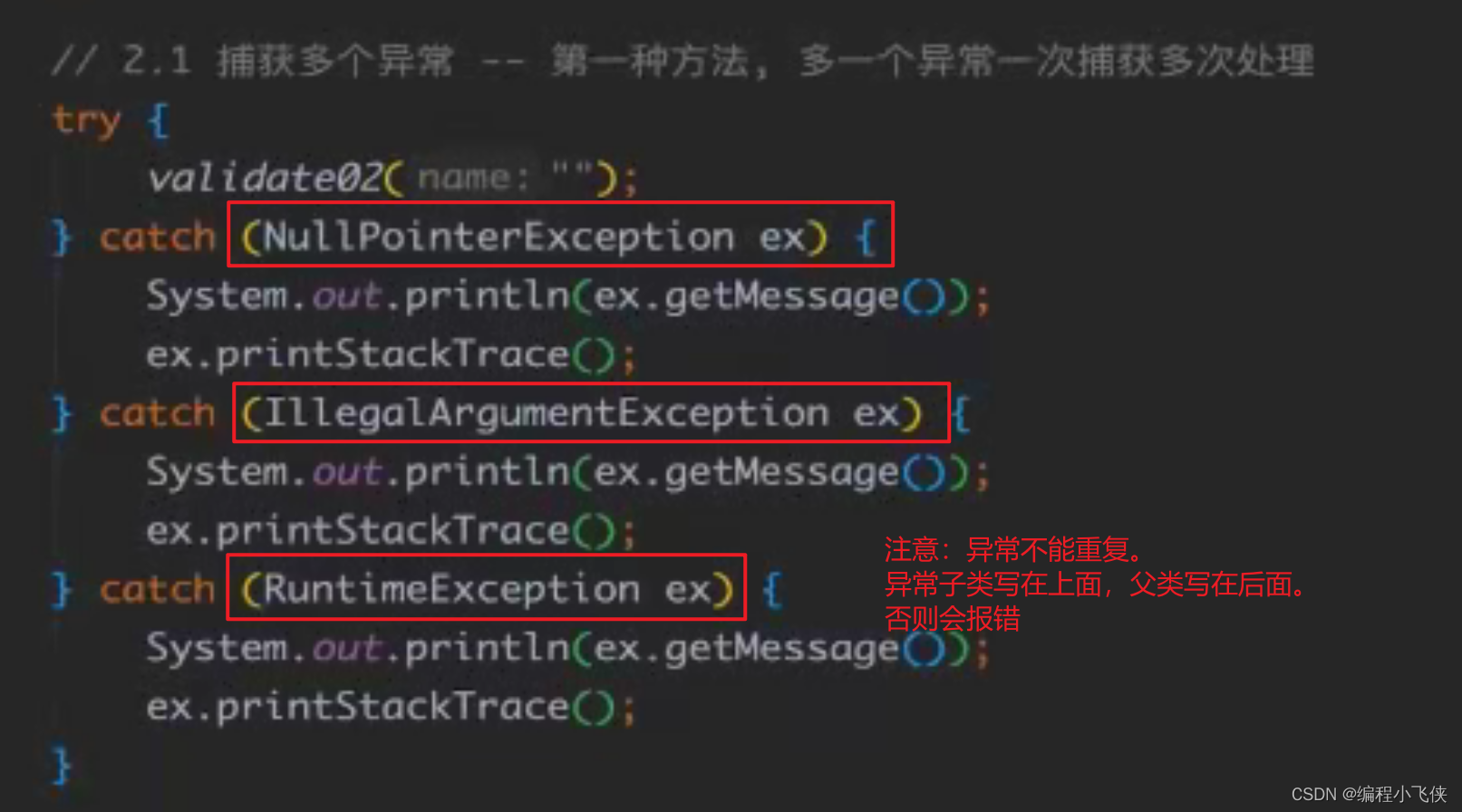
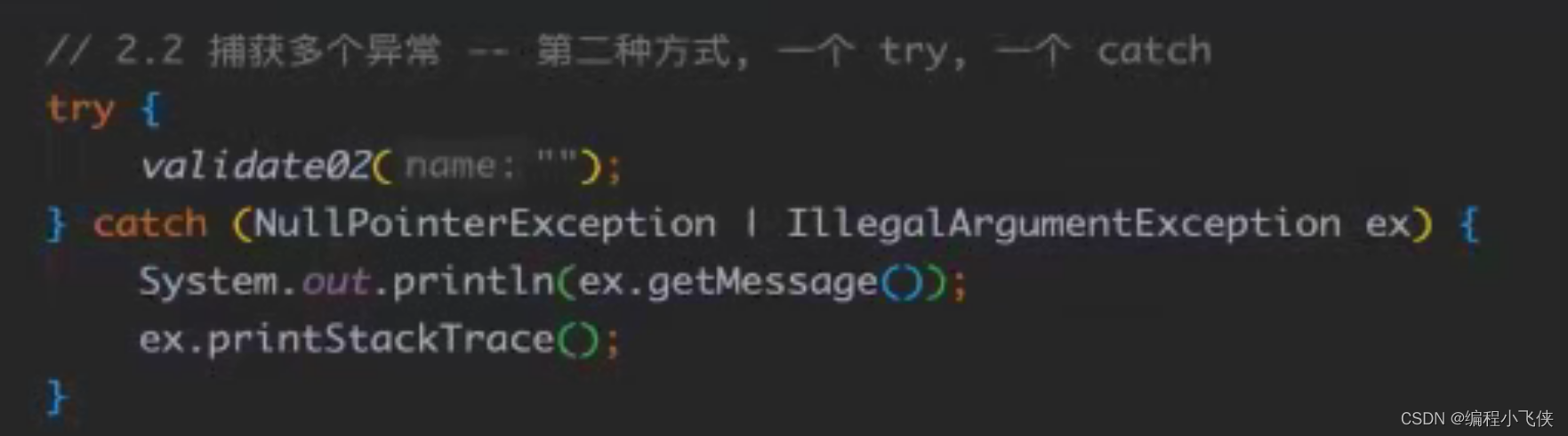
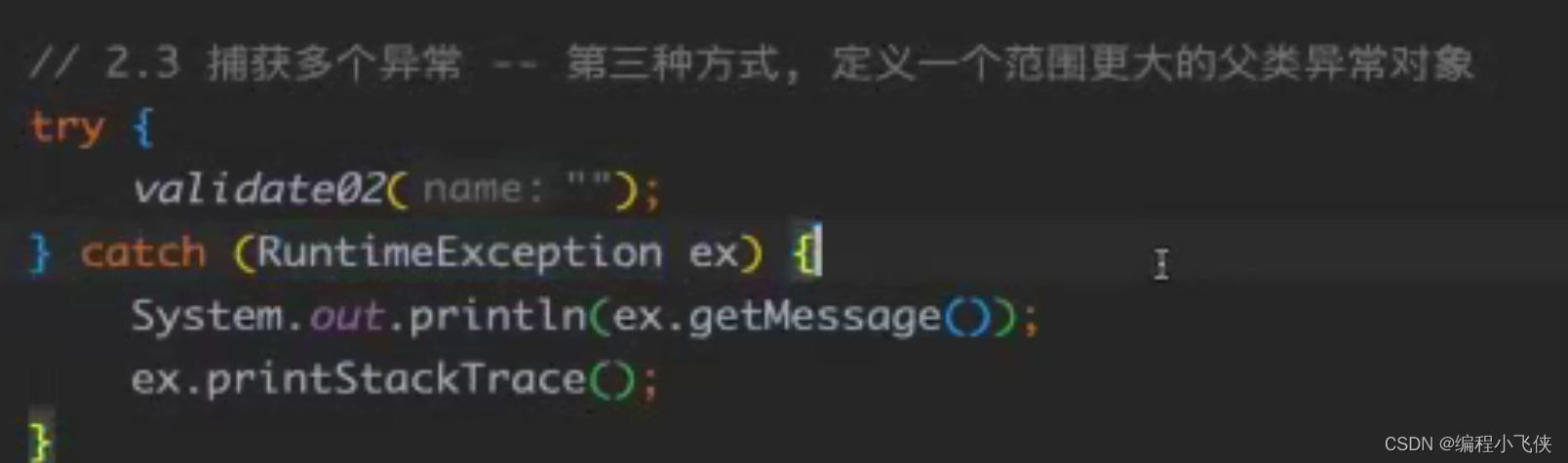
(2)捕获异常:
**try:**该代码块中编写可能产生异常的代码
**catch:**用来进行某种有异常的捕获,堆捕获到的异常进行处理
**finally: **有一些特定的代码无论异常是否发生,都需要执行
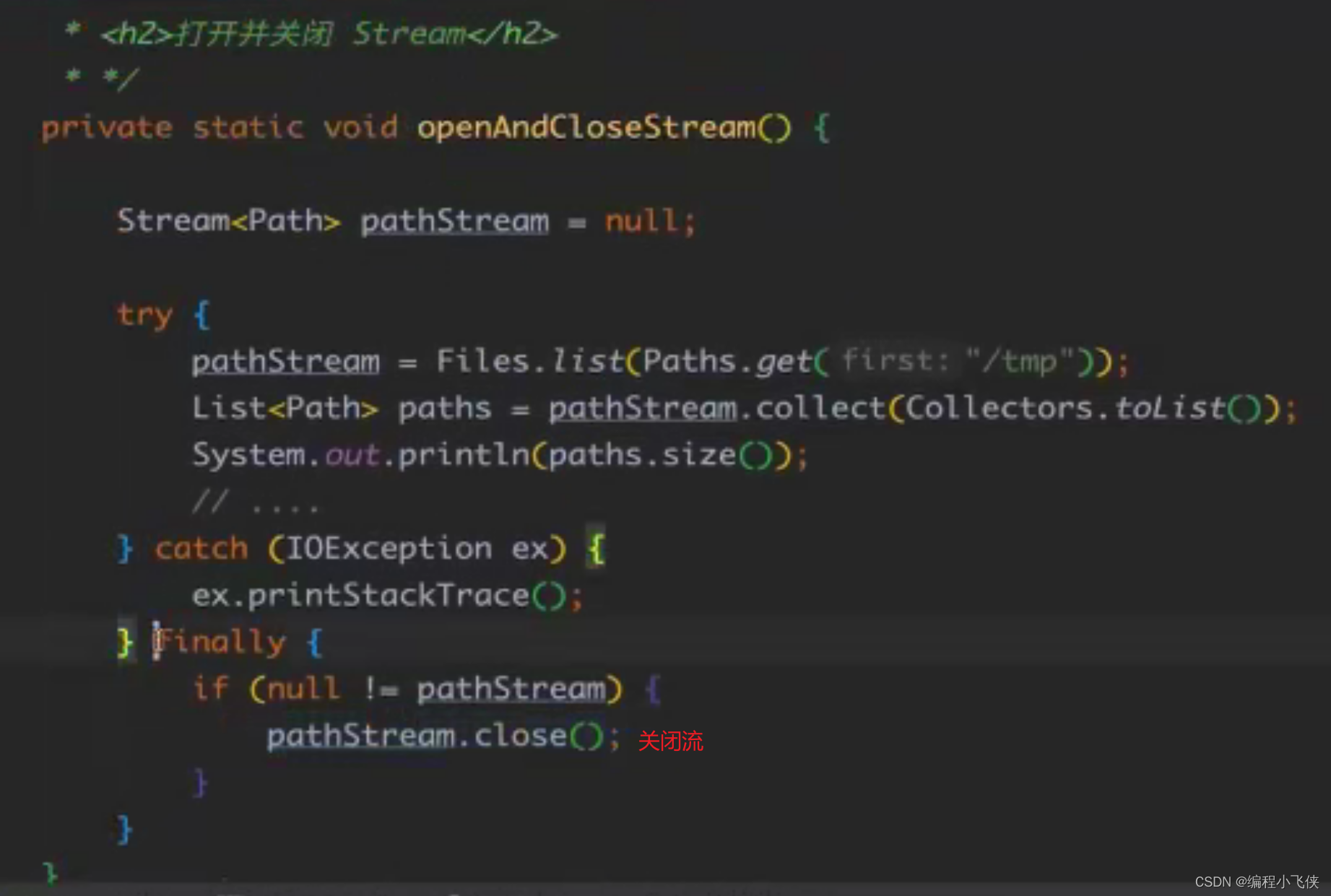
三.异常处理的基本原则:
3.1 不要滥用异常处理:
(1)不要让异常掺杂在业务流程中,不然会难以发现业务流程中的错误
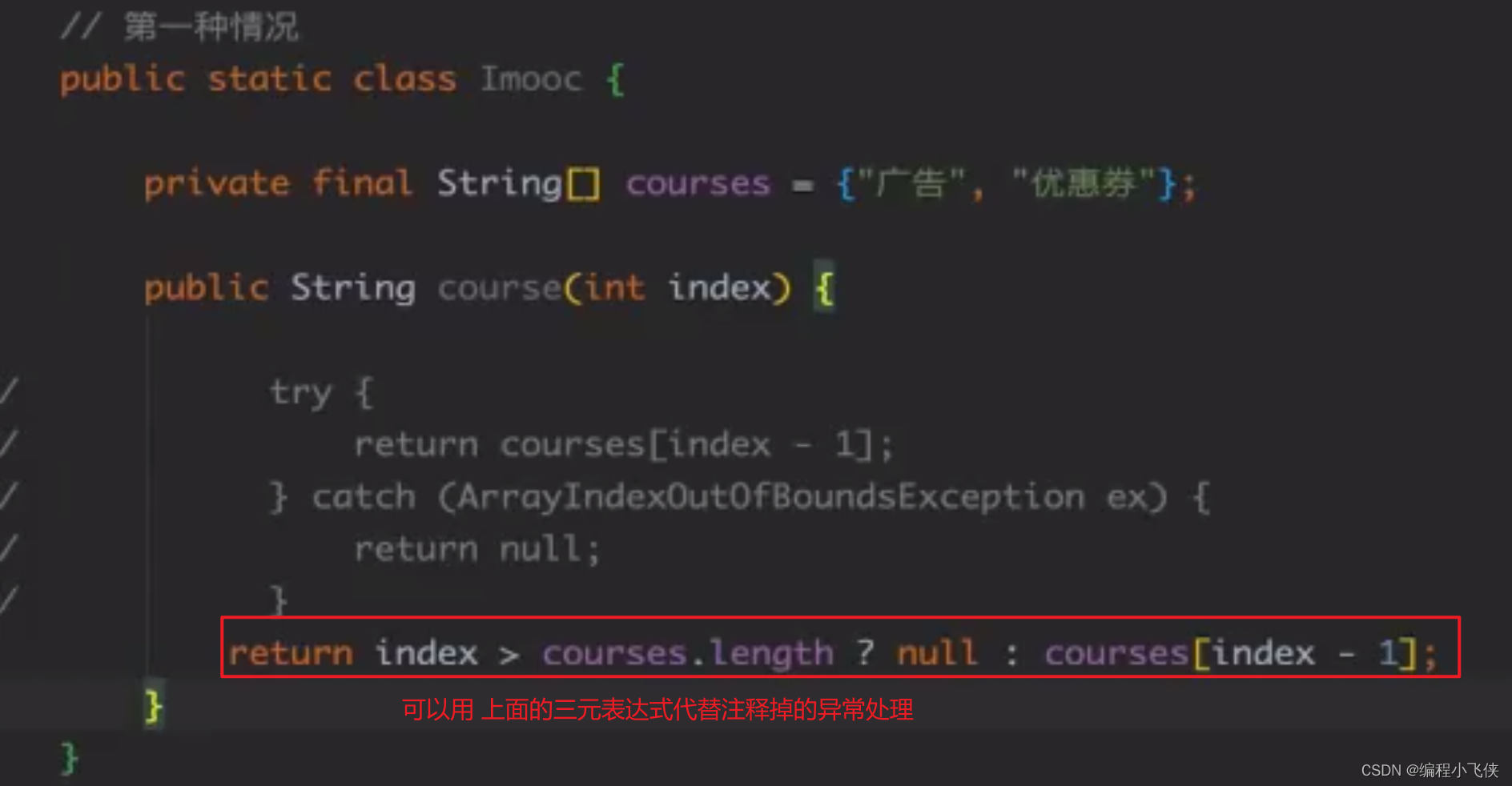
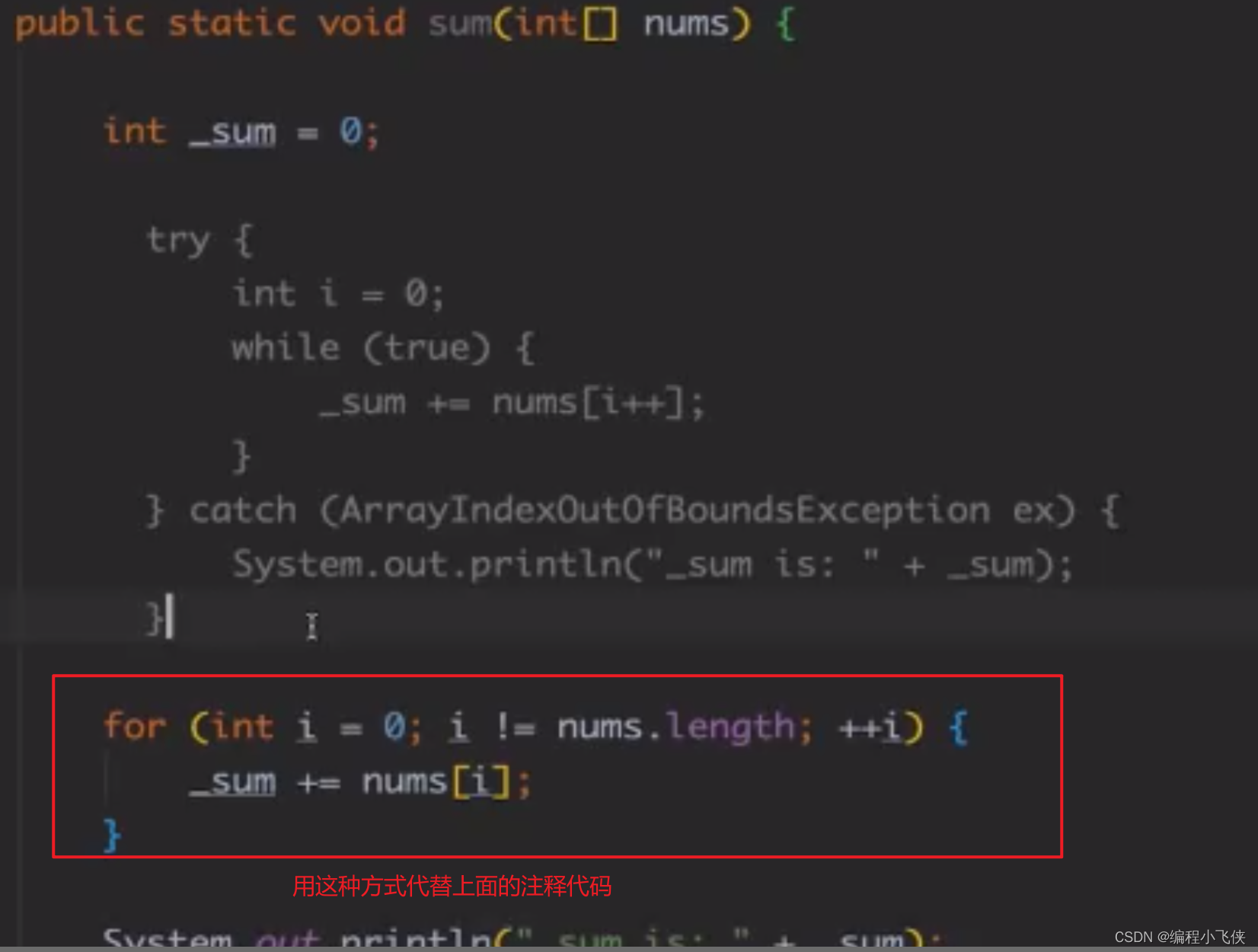
(2)一些循环的边界控制或判断应该由逻辑来完成,不能依赖异常捕获,否则是沉余
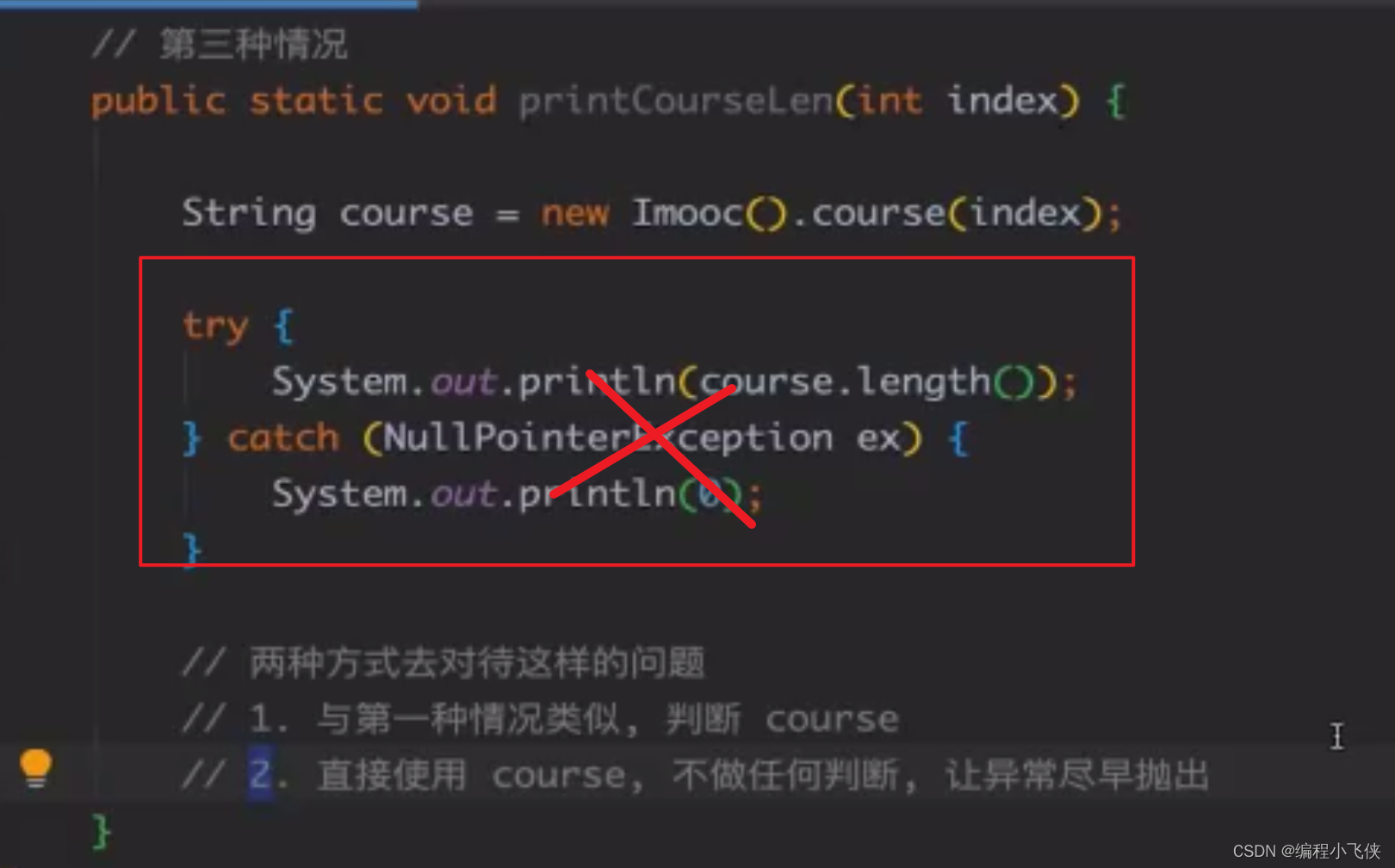
(3)接口之间的调用更多的是依赖判断和服务提供方,不是猜测可能抛出的异常
3.2 自定义异常和标准异常的优点:
(1)标准异常的好处:
学习成本低
编译器和虚拟机不需要做额外的工作,工程的整体性能不会下降(而且标准异常经过长时间的优化,性能更优)
(2)自定义异常好处:
自定义的异常会更容易理解错误的原因和位置
可以随心控制异常信息的打印逻辑和内容
3.3 异常被忽略
虽然try…catch了,但是没有在catch里面去处理异常(例如只打印了日志),也是忽略了异常
使用throw,throws向上抛出了异常,但是调用方没有处理异常,只是交给了jvm,也是忽略了异常
(1)for循环中大批量的处理数据,一般都不会让异常直接抛出,会记录下异常信息
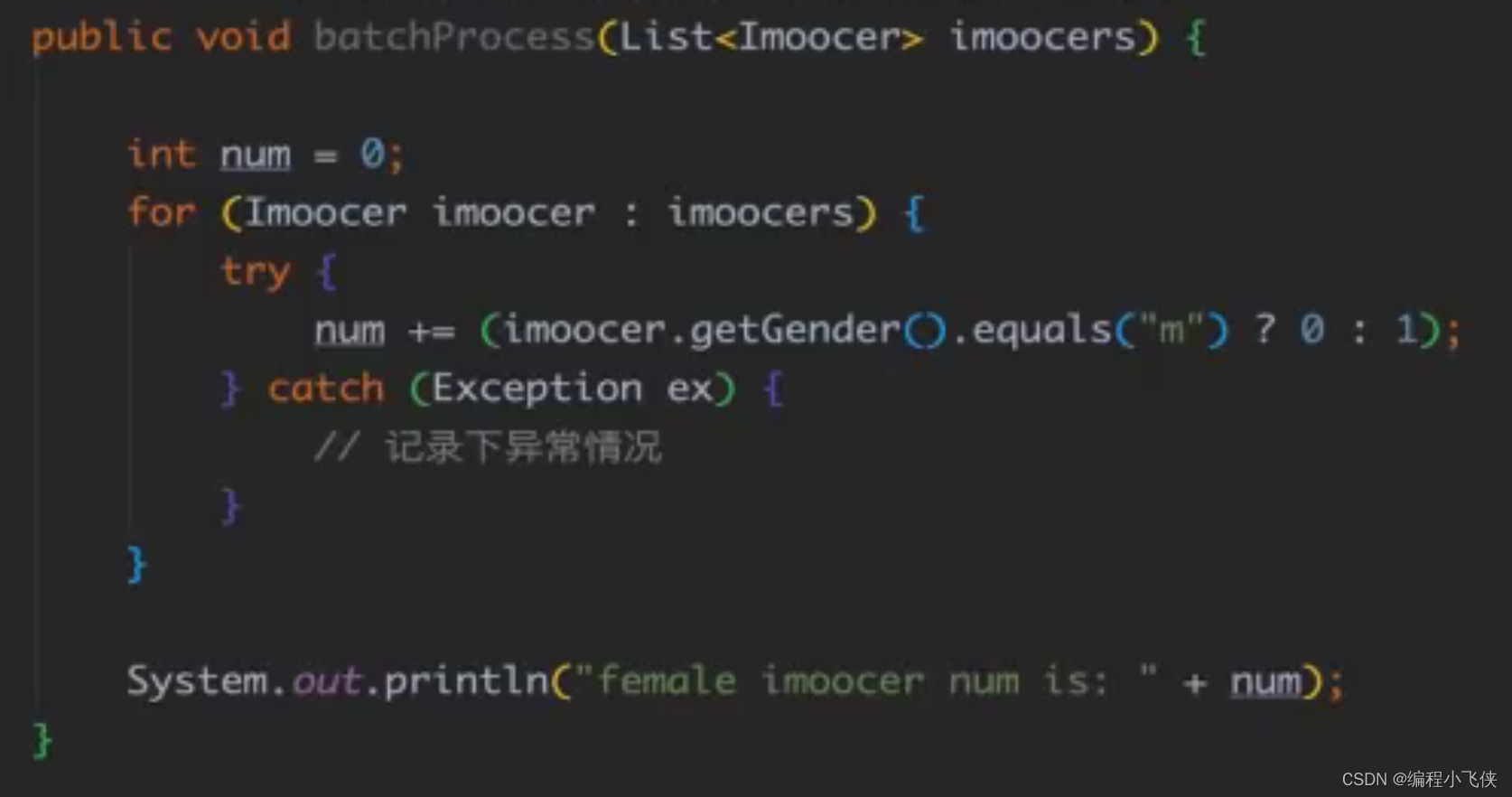
(2)存在网络请求(RPC),允许一定次数的失败重试,即忽略掉偶发性的异常
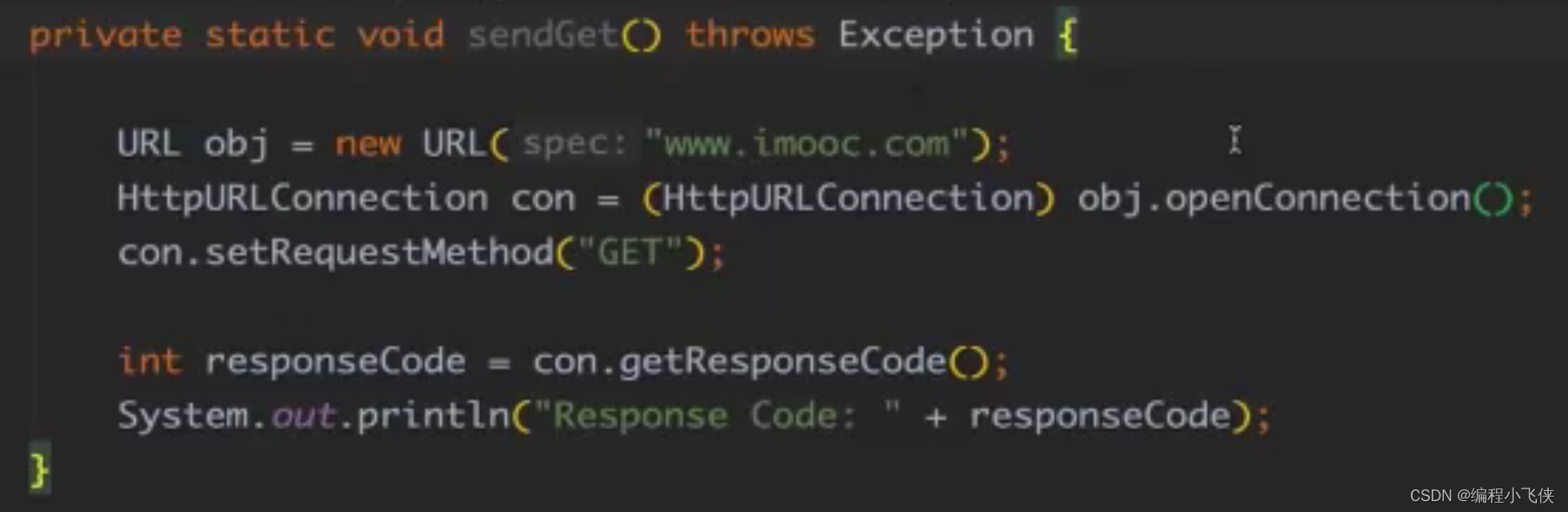
(3)不影响业务的整体逻辑情况,例如手机验证码发生失败,不会去抛出异常,会打印一个日志
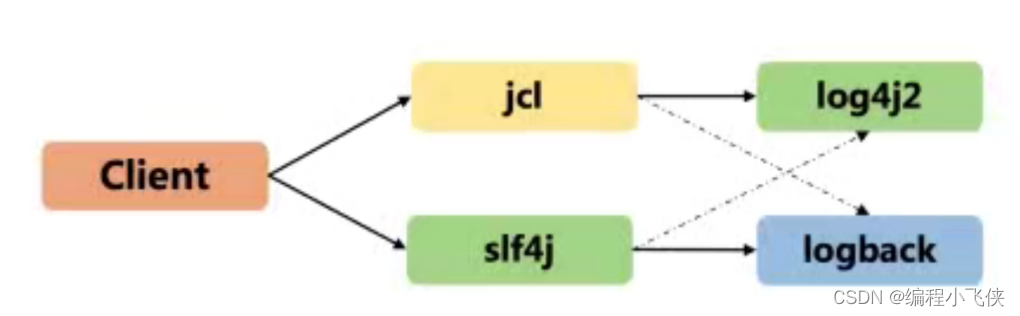
四.Java日志框架体系:
在Java 应用的开发中,常见的日志框架有 JCL (commons-ogging) ,s4j,JUL (java.utl.logging) , log4j,log4j2, logback等。这些大致可以分为两类,一类是日志门面JCL、sI4,定义日志的抽象接口,不是功能实现; 另一类是日志实现(JUL,log4,log42,logback),负责真正的实现日志。
4.1 常见的两类组合:jcl + log4j2,slf4j + logback (以上是常见的组合,也可以和交换或和其他组合)
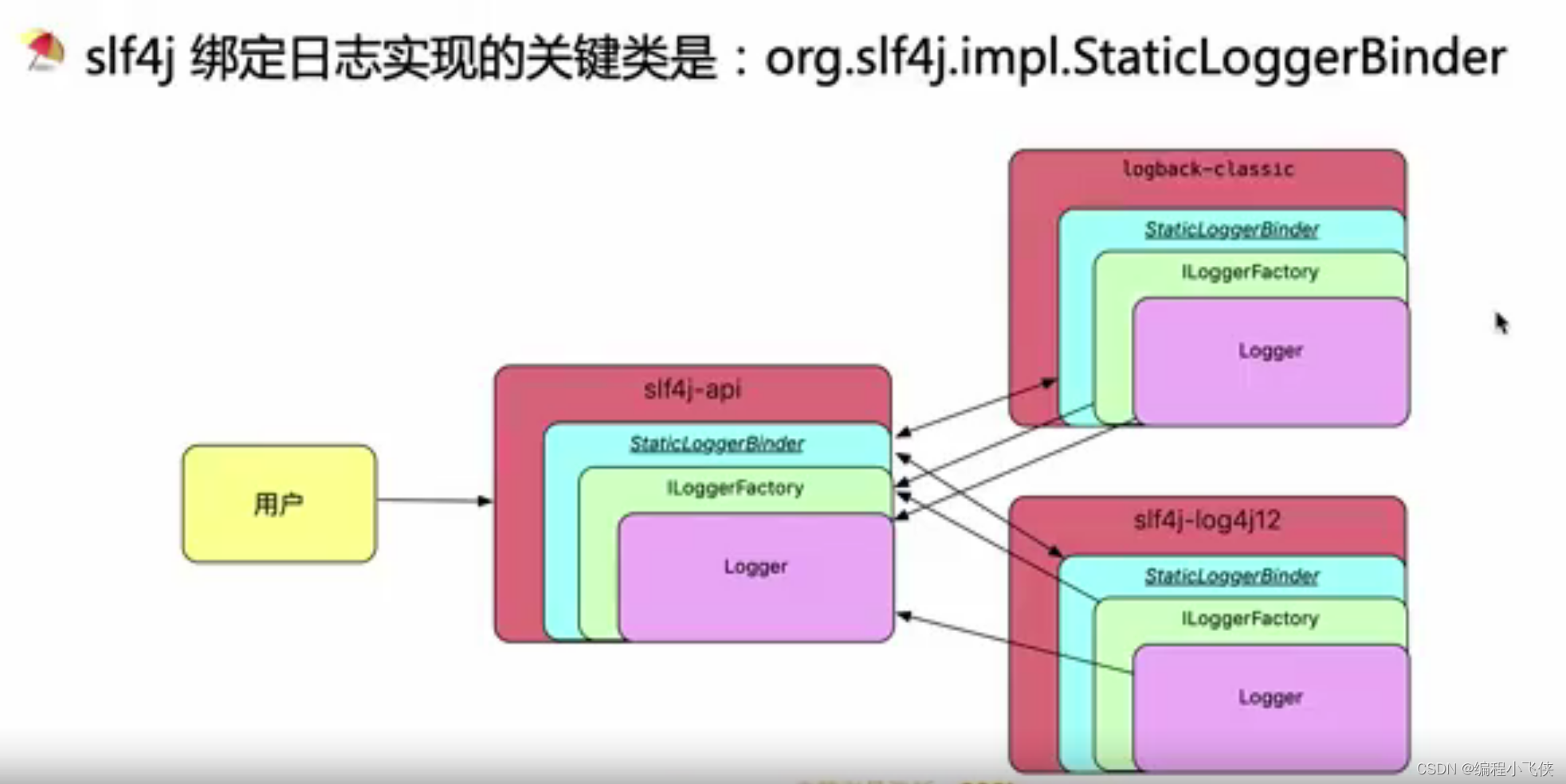
4.2 SLF4J 和 JCL 怎么绑定日志实现:
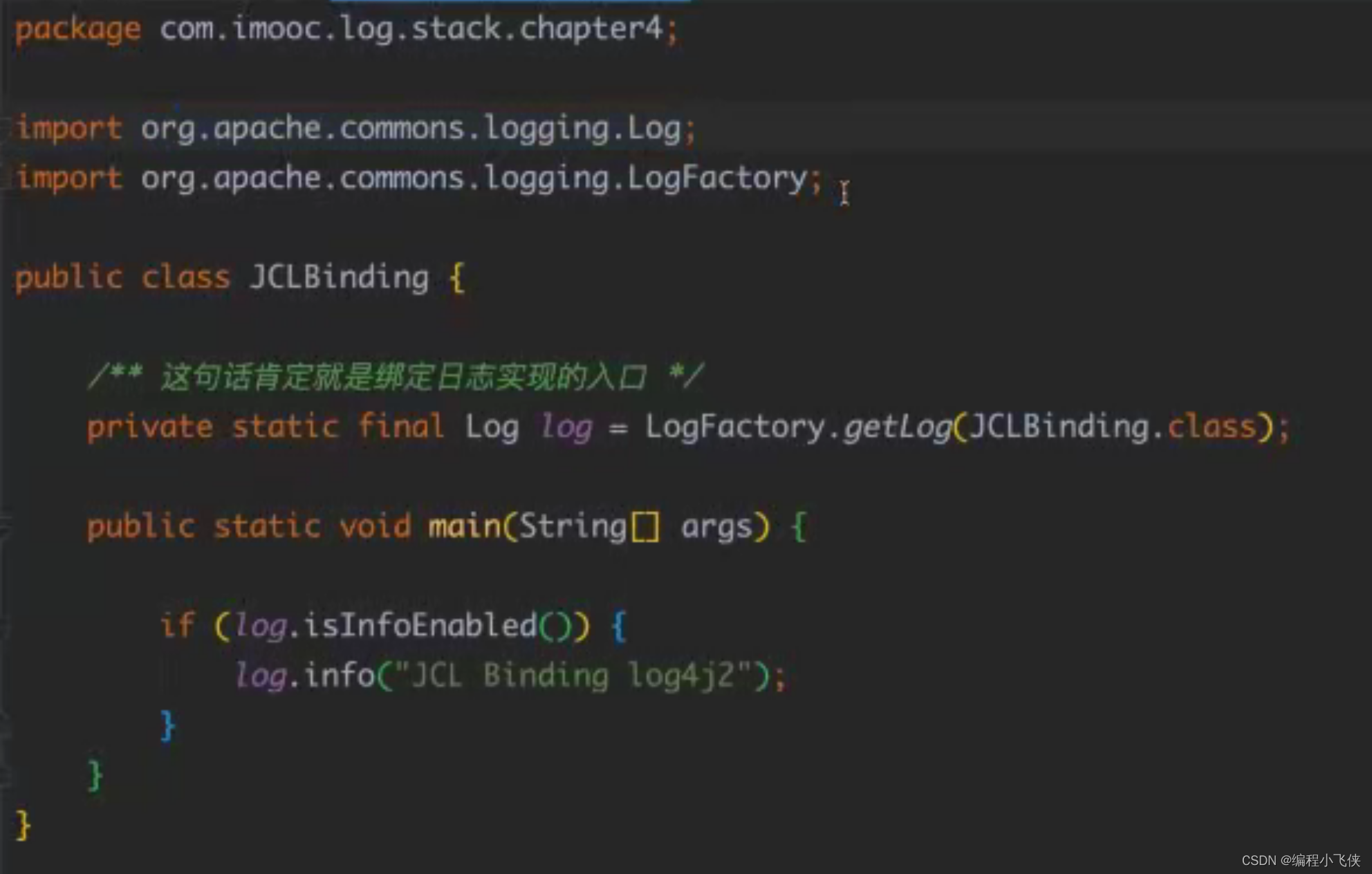
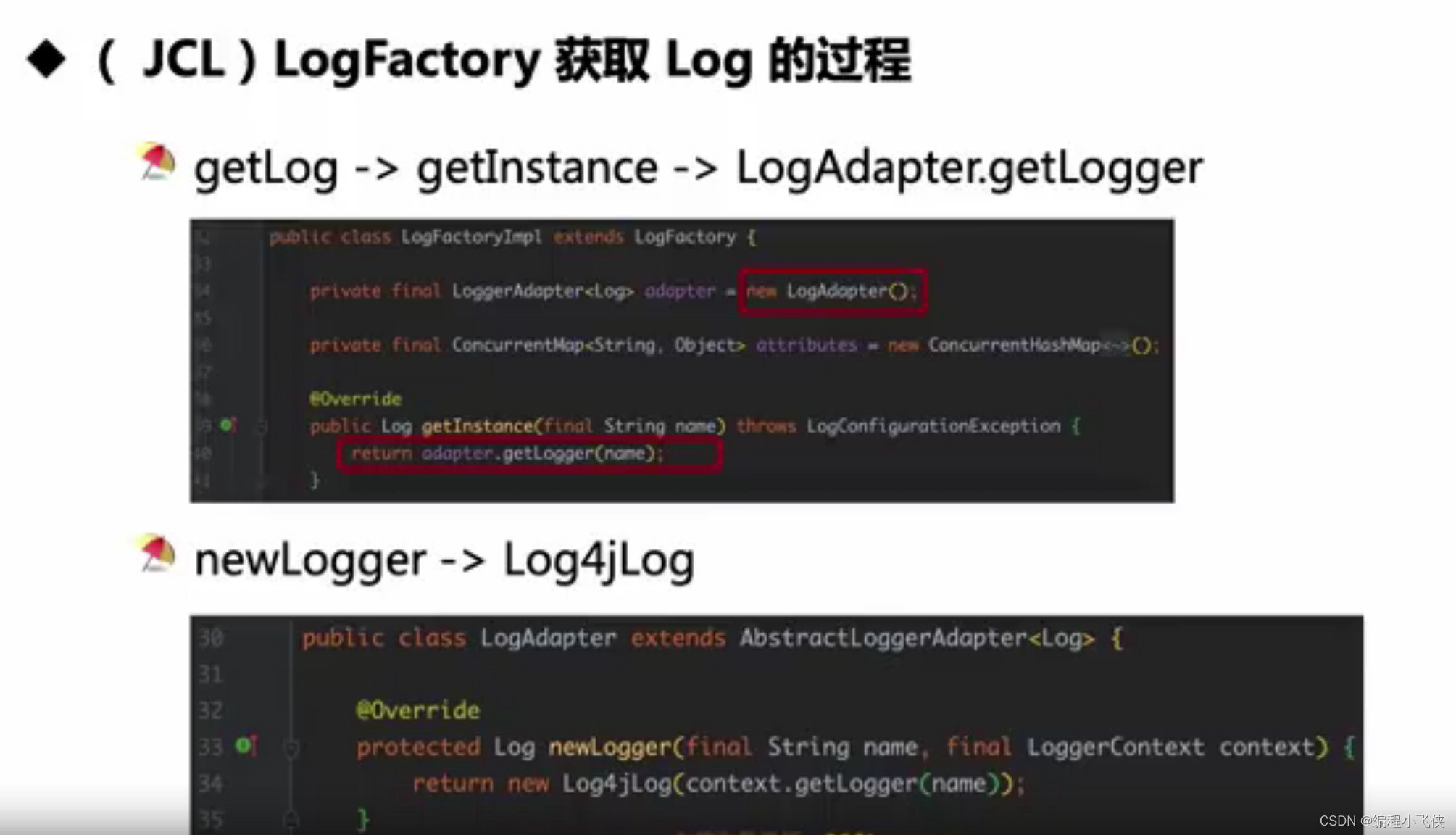
**4.2.1 JCL绑定日志实现(log4j2):**使用ClassLoader动态加载。
获取log4j2实例:

(1)在pom.xml 文件引入commons-logging 与log4j2 的依赖
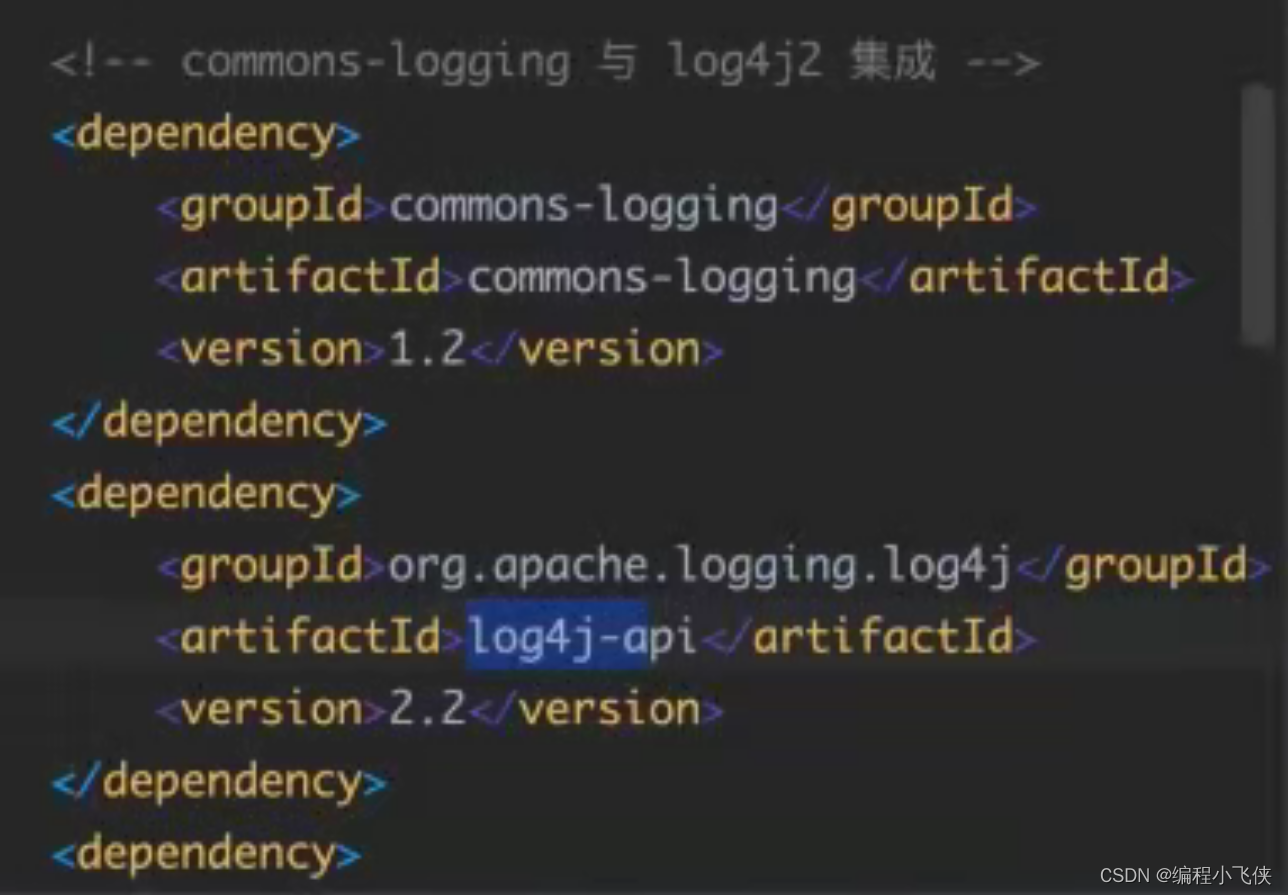
(2) jcl 绑定日志实现入口

**4.2.2 SLF4j 绑定日志实现(logback)😗*通过静态绑定,即它会在编译的时候确定使用哪个日志框架。
获取logback实例:

4.3 Log4j2的应用:
- 基本的打印方法
- JCL不支持占位符,但是log4j2支持
- 将异常栈打印到日志中**
(1) log4j2默认的配置文件:
如果你只是在工程中引入了log4j2(JCL),而没有做过任何配置时,你会发现,log4j2也可以工作,这其实就是当log4j2找不到配置文件时,使用DefaultConfiguration 类提供的默认的配置:
- 为root Logger 添加一个ConsoleAppender
- 为该ConsoleAppender 设置一个pattern为%d(HH:mm:ss.SSS}[%t]%-5level %logger{36}-%msg%n的I PatternLayout
等价默认log4j2配置文件的内容如下:
<?xml version="1.” encoding="UTF-8"?>
<Configuration status="WARN” monitorinterval="5">
<Appenders>
<!-- 默认打印到控制台 -->
<Console name="Console" target="SYSTEM OUT">
<!-- 默认打印格式 -->
<PatternLayout pattern="%d(HH:mm:ss.SSs) [%t] %-5level %logger(36) - %msg%n"/></Console>
</Appenders>
<Loggers>
<!-- 默认打印日志级别为 error -->
<Root level="error">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
配置文件各标签的含义如下:
- Configuration: 它有两个属性,status 和 monitorinterval
-
status: 用来指定 log4j2 本身的打印日志的级别 -
monitorinterval: 用于指定 log4j2 自动重新配置的监测间隔时间,单位是 s,最小是 5s - Appenders: 负责将LogEvents 传递到目的地。每 Appender 都必须实现 Appender 接口,常用的有三种子节点: Console、 RolingFile、
- Loggers: 常见的有两种,Root 和 Logger
- Console: 用来定义输出到控制台的 Appender
-
name: 指定 Appender 的名字 -
target: SYSTEM OUT 或 SYSTEM ERR,一般只设置默认: SYSTEM OUT -
PatternLayout: 输出格式,不设置默认为: %m%n
常用的格式有:
- %p: 输出日志信息优先级,即 DEBUG,INFO,WARN,ERROR,FATAL
- %d:输出日志时间点的日期或时间,默认格式为 ISO8601,也可以在其后指定格式,比如: %dyyy MWM dd HH:mm:ss,SSS)
- %r: 输出自应用启动到输出该 log 信息耗费的毫秒数
(2)使用方法:
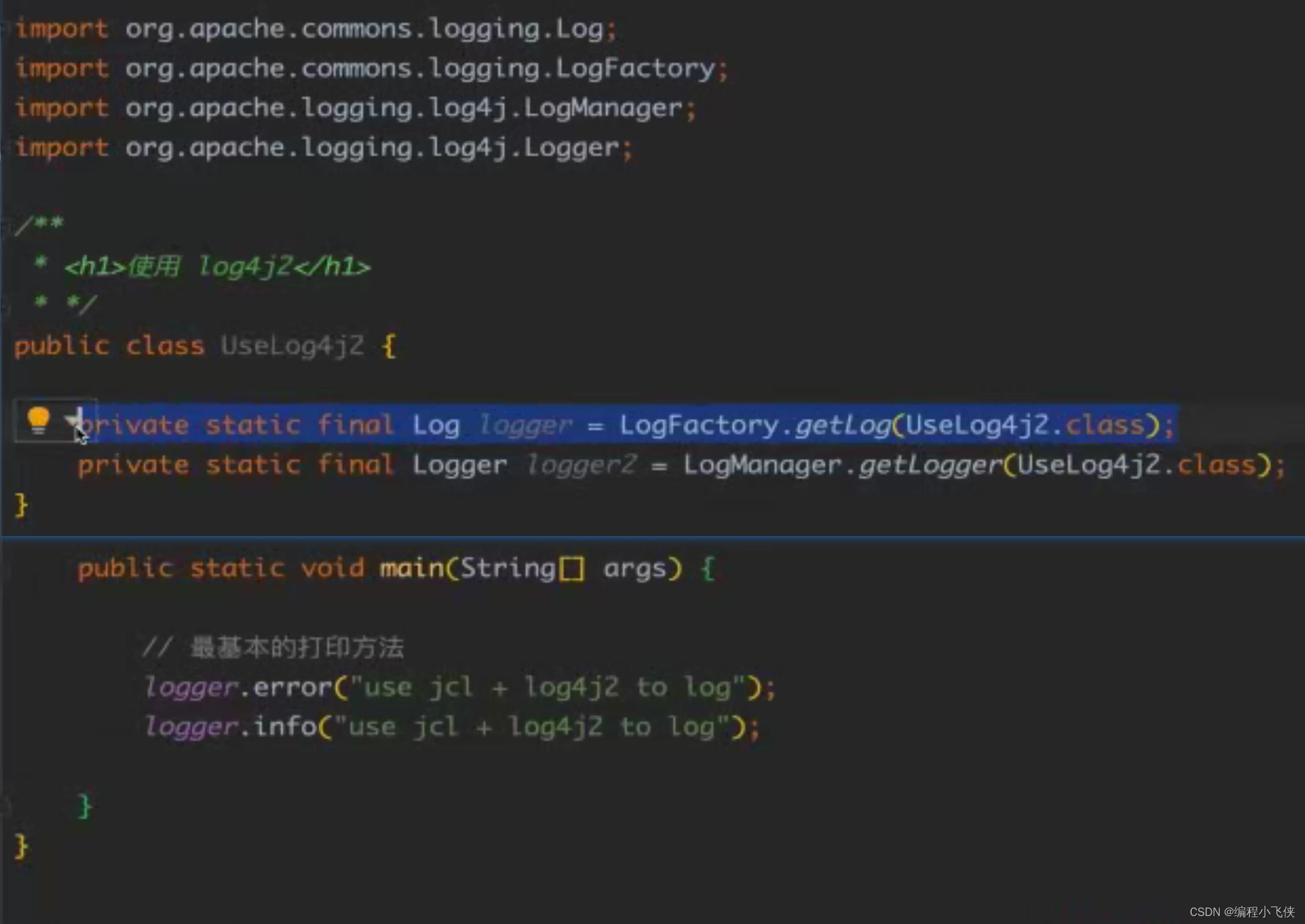
打印结果:

4.4 Logback的应用:
- slf4j对jcl 有所改进,支持占位符
- 支持打印不同级别的日志,但是只有>= 设定级别的日志才会被记录下来
- 初始化会遵循一定的策略寻找配置
Logback的模块组成:
logback 主要由三个模块组成: logback-core、logback-classic 以及 logback-access:
- logback-core 是其它模块的基础设施,其它模块基于它构建,显然,logback-core 提供了一些关键的通用机制
- logback-classic 的地位和作用等同于 log4J,它也被认为是 log4J 的一个改进版,并且它实现了简单日志门面 slf4j
- logback-access 主要作为一个与 servlet 容器交互的模块,比如说 tomcat 或者 jetty,提供一些与 HTTP 访问相关的功能
(1)在pom.xml 引入logback依赖:
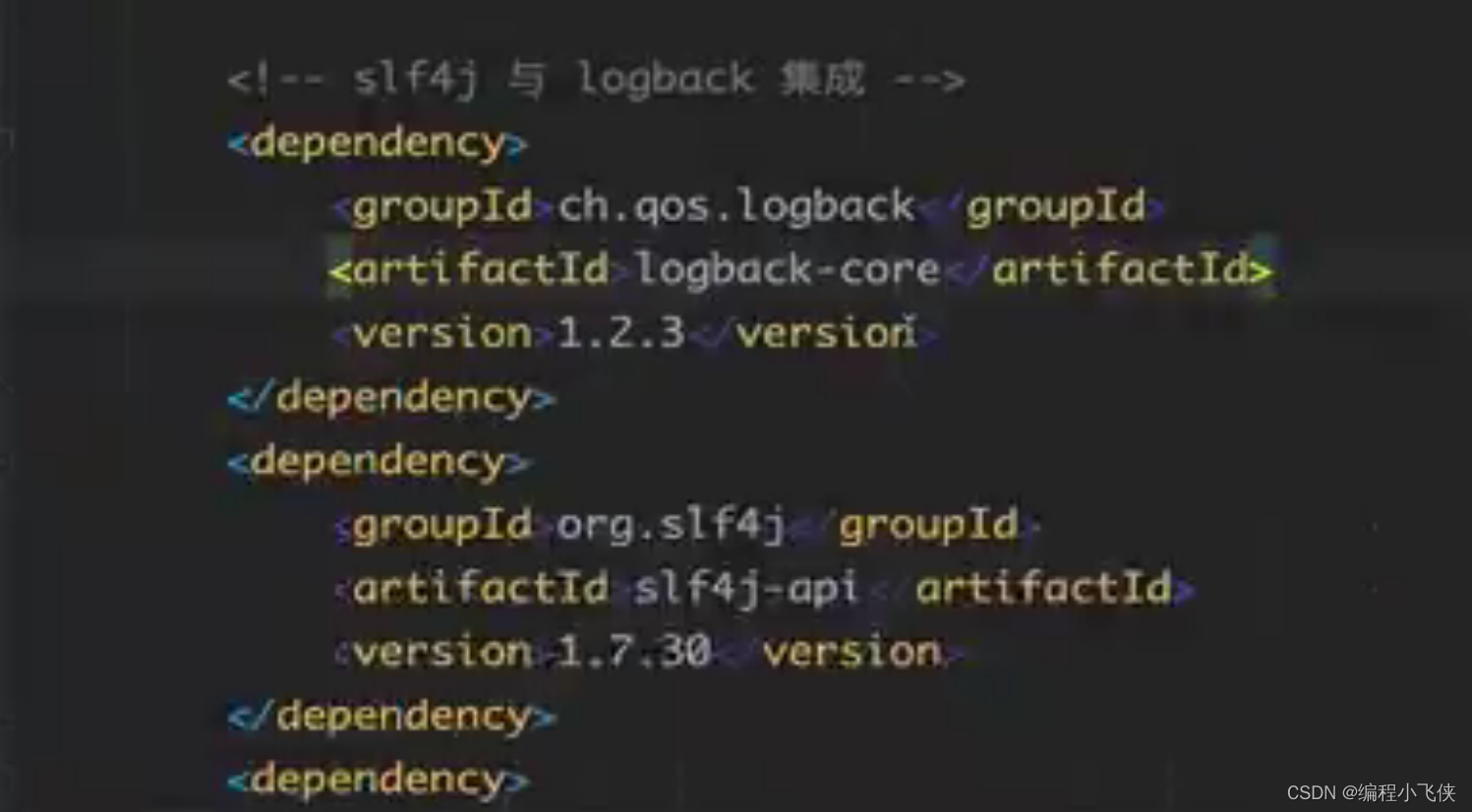
(2) 配置文件:
<?xml version="1.” encoding="UTF-8"?>
<configuration>
<appender name="STDOUT” class="ch.gos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d(HH:mm:ss.sss) [%thread] %-5level %logger(36) - %msg%n</pattern></encoder>
</appender>
<root level="debug">
<appender-ref ref="STDOUT” />
</root>
<logger name="com.imooc.log.stack,chapter4" level="info" additivity="false"><appender-ref ref="STDOUT"/>
</logger>
</configuration>
(3)使用方法:
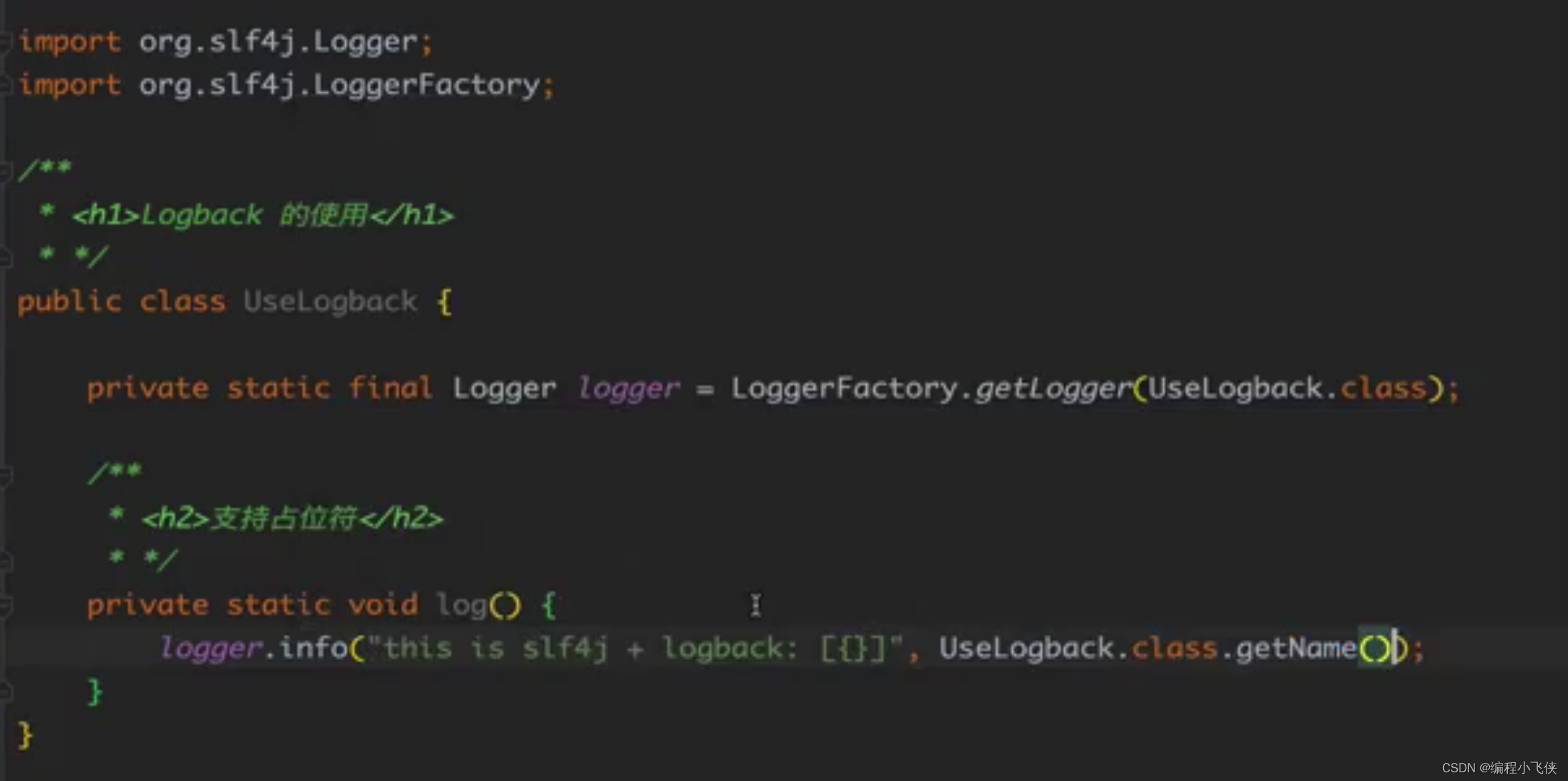
4.5 Lombox注解使用日志框架:
(1) 在pom.xml添加lombox的jar包依赖如下:
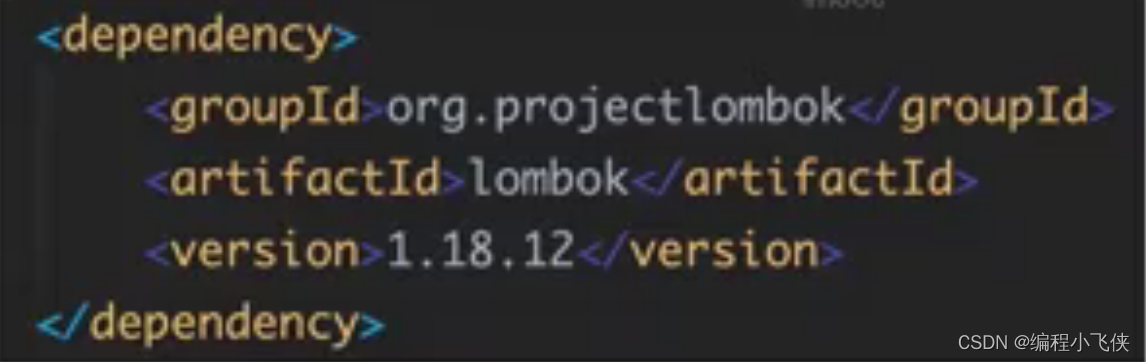
(2) 在idea中添加lombox插件
(3) Lombox 提供三个注解:
(4)使用lombox工具的Slf4j注解打印日志:
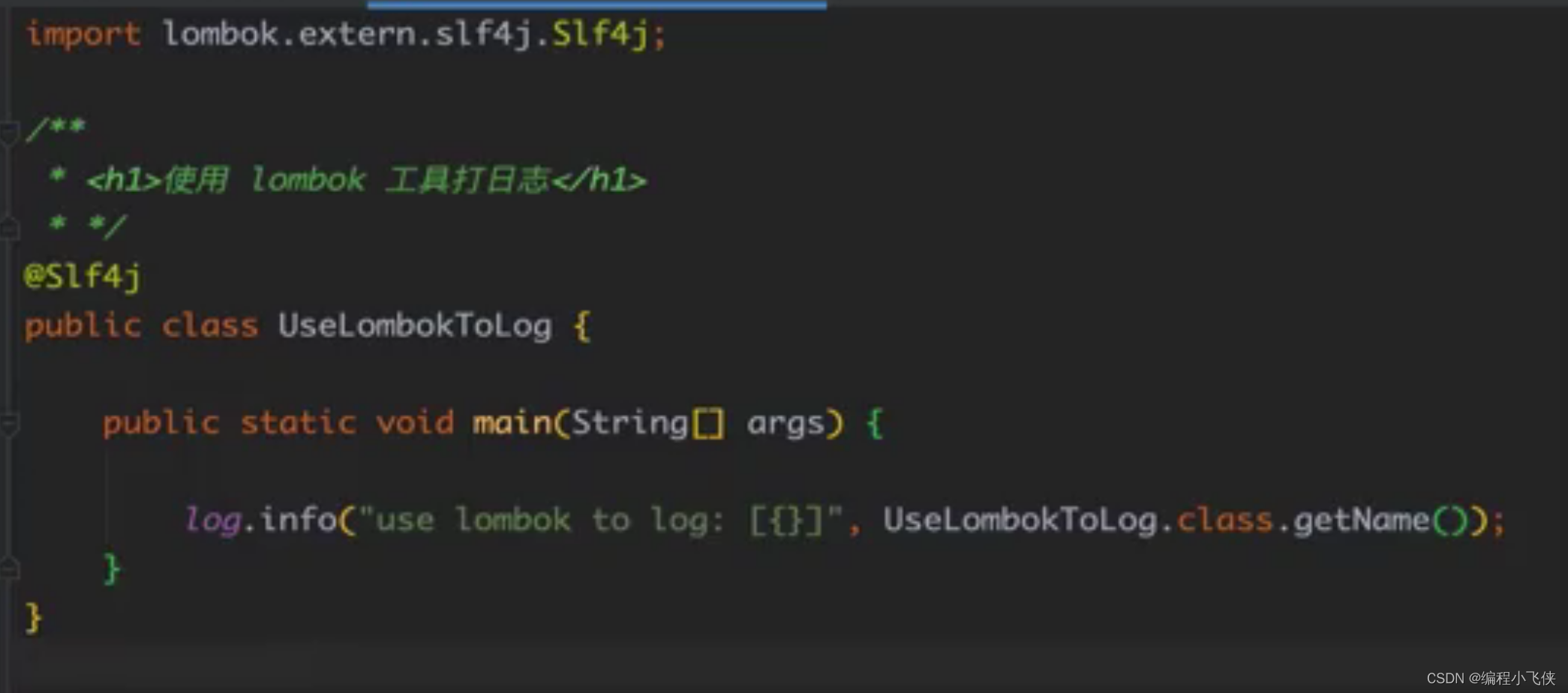
运行后会在控制台输出 use lombox to log
(5)Lombox是如何实现的:
lombox在编译期时把lombox的注解代码,转化为常规的java方法而实现的。这关联到Java的编译过程中的注解处理。
Java编译过程:
1.java代码
2.解析与填充符号表
3.注解处理
4.分析与字节码生成
5.生成二进制文件(.class)
总结:
jcl + log4j2 和 slf4j + logback 使用代码如下:
// 获取 jc1 日志上下文
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
private static final Log logger = LogFactory.getLog(UseLog4j2.class);
// 获取 slf4j 日志上下文
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
private static final Logger ogger = LoggerFactory.getLogger(UseLogback.class);

五.日志规范:
5.1 logback的五种日志级别的优先级排序:
trace < debug < info < warm < error
trace(级别最小,打印信息最为详细),包括 TRACE / DEBUG /INFO /WARN / ERROR 的日志级别都打印,
debug包括 DEBUG / INFO / WARN / ERROR 的日志级别都打印
info包括 INFO / WARN / ERROR 的日志级别都打印,普通的运行时事件 (启动/关闭/业务流程)
warn包括 WARN / ERROR 的日志级别都打印;使用已弃用的APL,APl使用不当,“几乎”错误,其他运行时情况是不希望的或意外的,但不一定是“错误的
error(级别最大,打印信息最为简略), 只打印error的日志级别。;其他运行时错误或意外情况。
logback的官网:https://logback.qos.ch/manual/architecture.html
(1)日志要有滚动策略,这是考虑到避免单个文件过大,以及磁盘占用问题,滚动策略有
- 按照时间滚动:即每隔一定的时间建立一个新的日志文件,单位可以是小时或者天
- 按照单个日志文件大小滚动:即每当日志文件达到一定大小则建立一个新的日志文件,通常建议单个日志文件大小不要超过 500M
- 同时按照时间和单个日志文件大小滚动:这种模式通常适用于希望保留一定时间的日志,但是又不希望单个日志文件过大的场景
- 最后,对于日志滚动策略来说,有2个比较关键的参数:最大保留日志数量和最大磁盘占用空间。这2个参数切记一定要设置,如果没有设置,
有可能会出现把线上机器磁盘打满的情况。
(2)日志需要有意义而不沉余
HTTP 请求的入参和结果
大多数情况下,我们都会记录下 HTTP 请求的参数以及响应的结果,但是,也需要酌情考虑这里的可行性,如果入参和结果都很大,那么,只记录一些 “核心” 的信息就可以了。
程序异常的原因
我们使用 try…catch 尝试捕获可能会抛出的异常,此时,我们有两种选择:继续向上抛给接口的调用方或者是在 catch 中自行处理问题。如果继续向上抛出,就不要再去打日志了(重复了);在 catch 中处理的话,一定要记录下来是什么原因导致的错误。
远程接口调用(HTTP 或 RPC)情况
当你的接口需要调用其他服务的接口时,你一定要记录下请求的参数以及返回的响应,因为这种远程调用是极有可能失败的,且需要是可审计的。
特殊的条件分支
5.2.LogBack的MDC解析:
(1)MDC的含义:Mapped Diagnostic Context,可以理解成一个线程安全的存放诊断日志的容器。对外有put,get,remove,clear接口。
public class MDC {
//Put a context value as identified by key
//into the current thread's context map.
public static void put(String key, String val);
//Get the context identified by the key parameter.
public static String get(String key);
//Remove the context identified by the key parameter.
public static void remove(String key);
//Clear all entries in the MDC.
public static void clear();
}
可以看到,MDC 对外提供的接口非常简单,目非常类似于数据结构 Map。一般,我们在代码中,只需要将指定的值 put到线程上下文中,在对应的地方使用 get 方法获取对应的值。此外,对于一些线程池使用的应用场景,可能我们在最后使用结束时,需要调用 clear 方法来清洗将的数据 (这个一定要注意,否则,会出现数据混乱的问题)。
(2)MDC的用途(目前只有logBack和log4j支持):
- 对于 Web 工程而言,请求在一瞬间可能会有很多个,那么,也会导致不同请求之间的日志穿插。此时,如果我想要从大量的日志信息中找出户或者某个请求的操作过程,将会是非常麻烦的,这可以使用MDC。
- 在WEB应用中,如果想在日志中输出请求用户IP 地址、请URL、统计耗时等等MDC基本都能支撑
- 可以在MDC中填充REQUESTID追踪单请求的执行轨迹
- 微服务场景下,使用 MDC埋点,做到链路跟踪(最好是有日志收集工具,将多实例、多系统的日志实现收集,再根据MDC埋点进行grep,就可以打印一个完整的微服务请求链路)
在代码中使用MDC:
import lombok.extern.slf4j.Slf4j;
import org.slf4j.MDC;
@Slf4j
public class UseMDC {
private static final String FLAG = "CURRENT_TID";
private static void mdc01() {
MDC.put(FLAG, String.valueOf(Thread.currentThread().getId()));
log.info("log in mdc01, current thread id is: {}", Thread.currentThread().getId());
}
}
(3) 微服务日志链路:
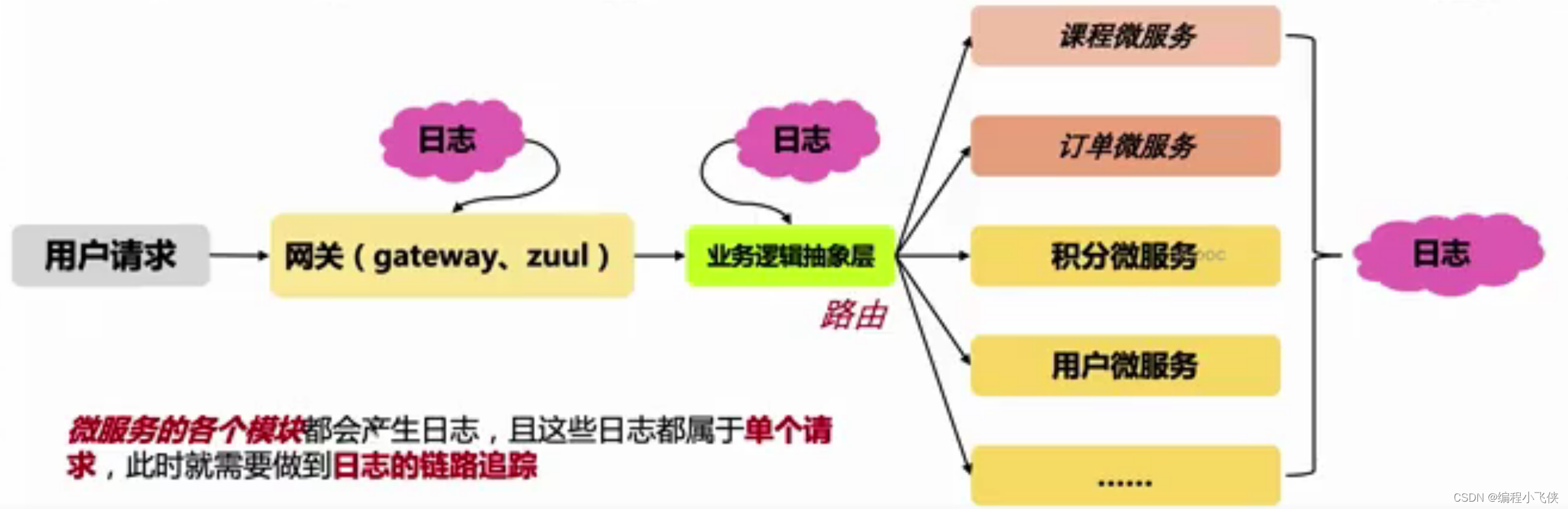
(4)MDC于分布式调用链路追踪日志:
MDC是用来做诊断工具的,其中有两大核心用途:
- 搞清楚当前工程的对于普通的 web应用来说,给每个请求添加一条标识符(例如UUID),可快速的grep到某一个请求的完整链路
- 利用MDC实现对于分布式应用来说,一个链路会经过多个系统,此时也可以利用MDC实现多个系统日志的拼接
总结:
六.idea的代码调试:
6.1 远程debug springBoot 工程(只适合在测试环境,不要在正式环境使用远程调试):
远程调试的协议支持:jdwp
idea的远程调试:
- 前提条件1:本地机器与部署机器之间的网络需要互通的
- 前提条件2:两端的代码要完全一致,否则不能命中断点
- 增加远程调试的配置
七.java线程堆栈:
7.1什么是线程堆栈:
线程堆栈也称作线程调用堆栈。Java 程堆栈是虚拟机中线程(包括锁)状态的一个瞬间快照,即系统在某个时刻所有线程的运行状态,包括每一个线程的调用堆栈,锁的持有情况等信息。
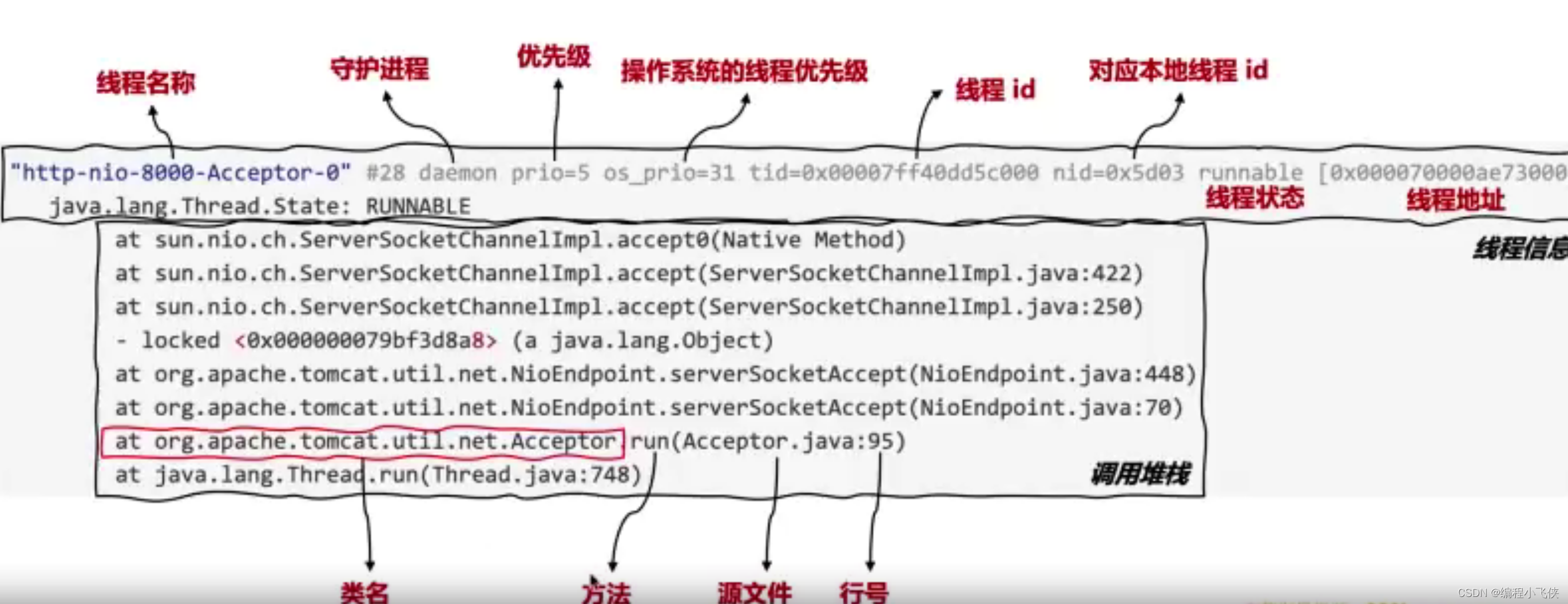
7.2线程堆栈包含的信息:
- 线程的名字,ID,线程的数量等等
- 线程的运行状态,锁的状态(锁被哪个线程持有,哪个线程在等待锁等等)
- 调用堆栈(即函数的调用层次关系,包含完整的类名,所执行的方法,源代码的行数
7.3 线程堆栈信息能用来解决什么问题:
适合稳定性问题分析以及性能问题分析: - 系统在运行的过程中,突然CPU 使用率过高
- 线程死锁、死循环、饥饿等等
- 找出消耗CPU最高的线程
- 由于线程数量太多造成的系统失败(例如无法创建新线程)
获取运行时线程堆栈: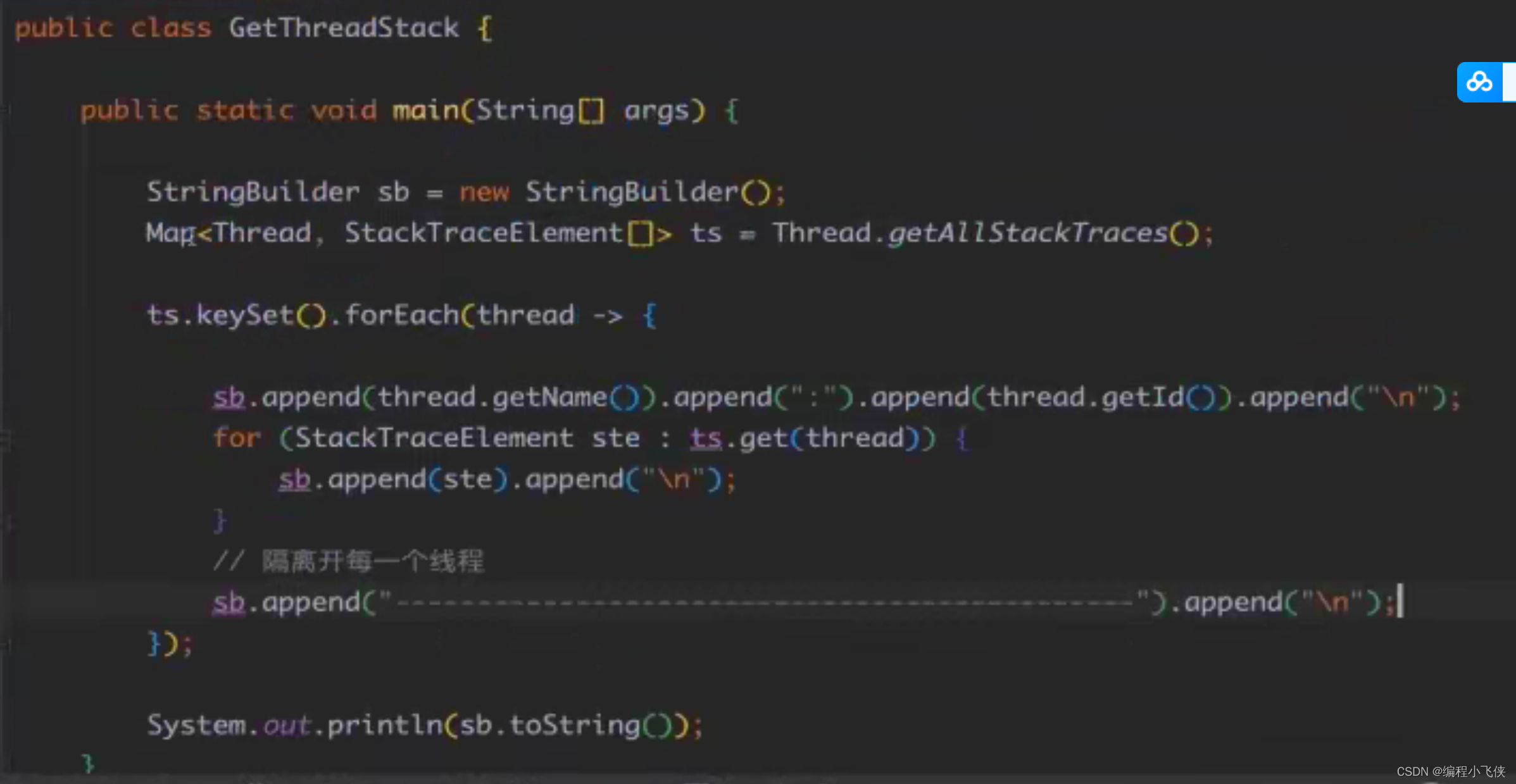
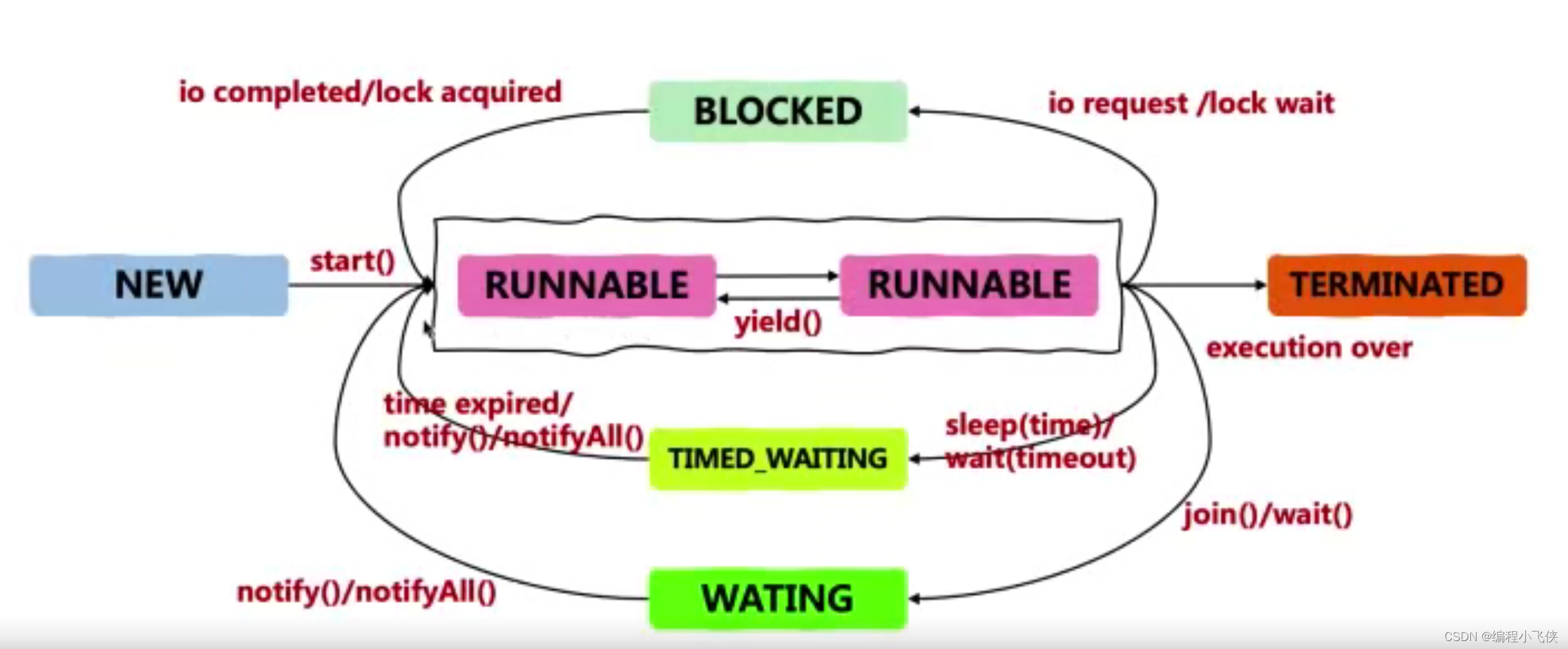
7.4 JDK中定义的6种线程状态:
源码路径:java.lang.Thread.State
六种状态:
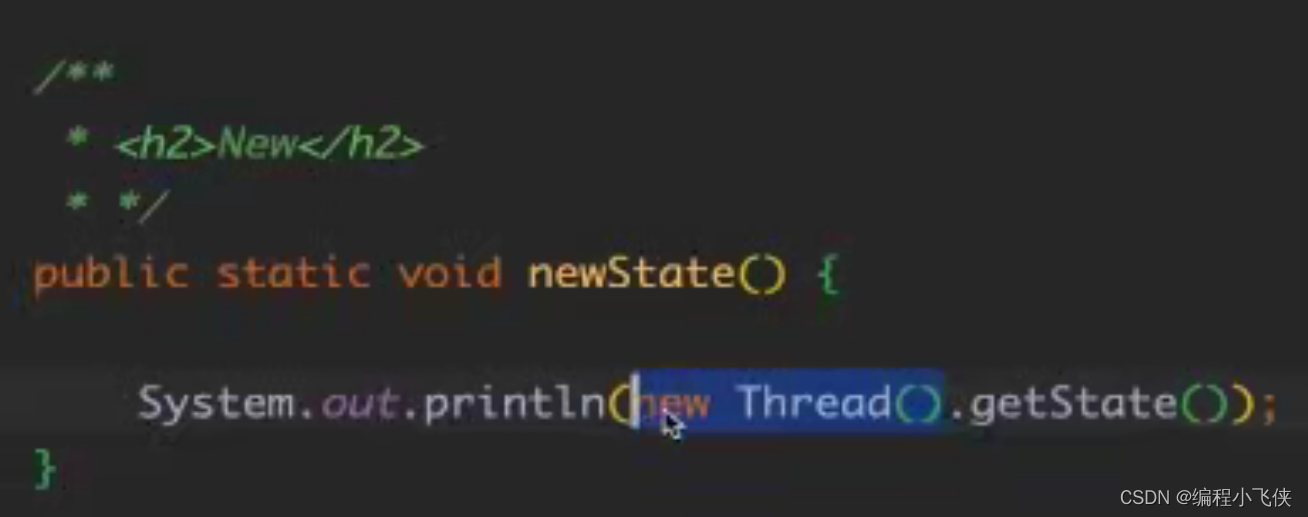
New:新创建的线程,还没有执行,不存在堆栈日志中,因为还没有执行
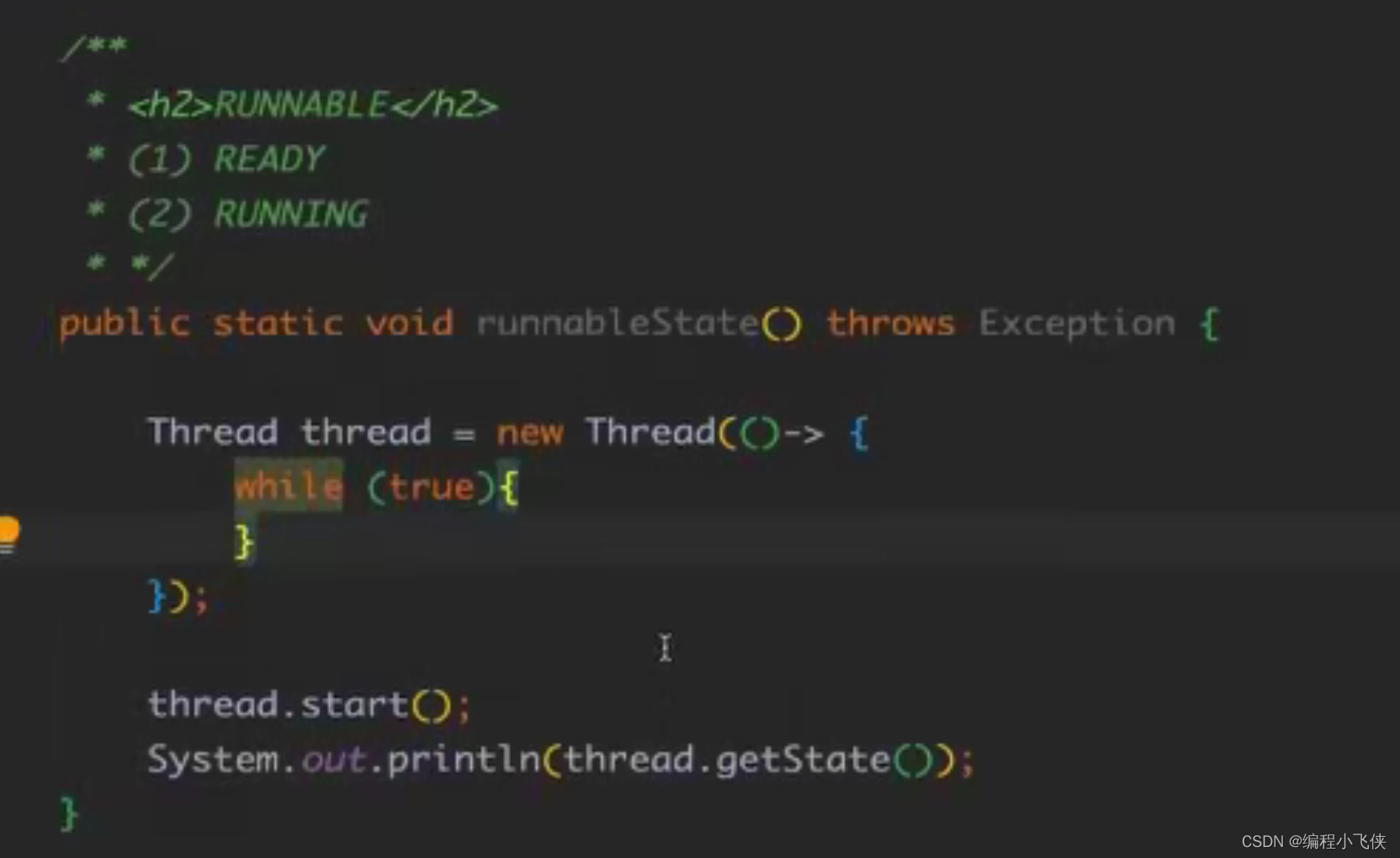
ROUNNABLE:运行中的线程,正在执行 run() 方法的 Java 代码
BLOCKED:运行中的线程因为某一些操作被阻塞而挂起
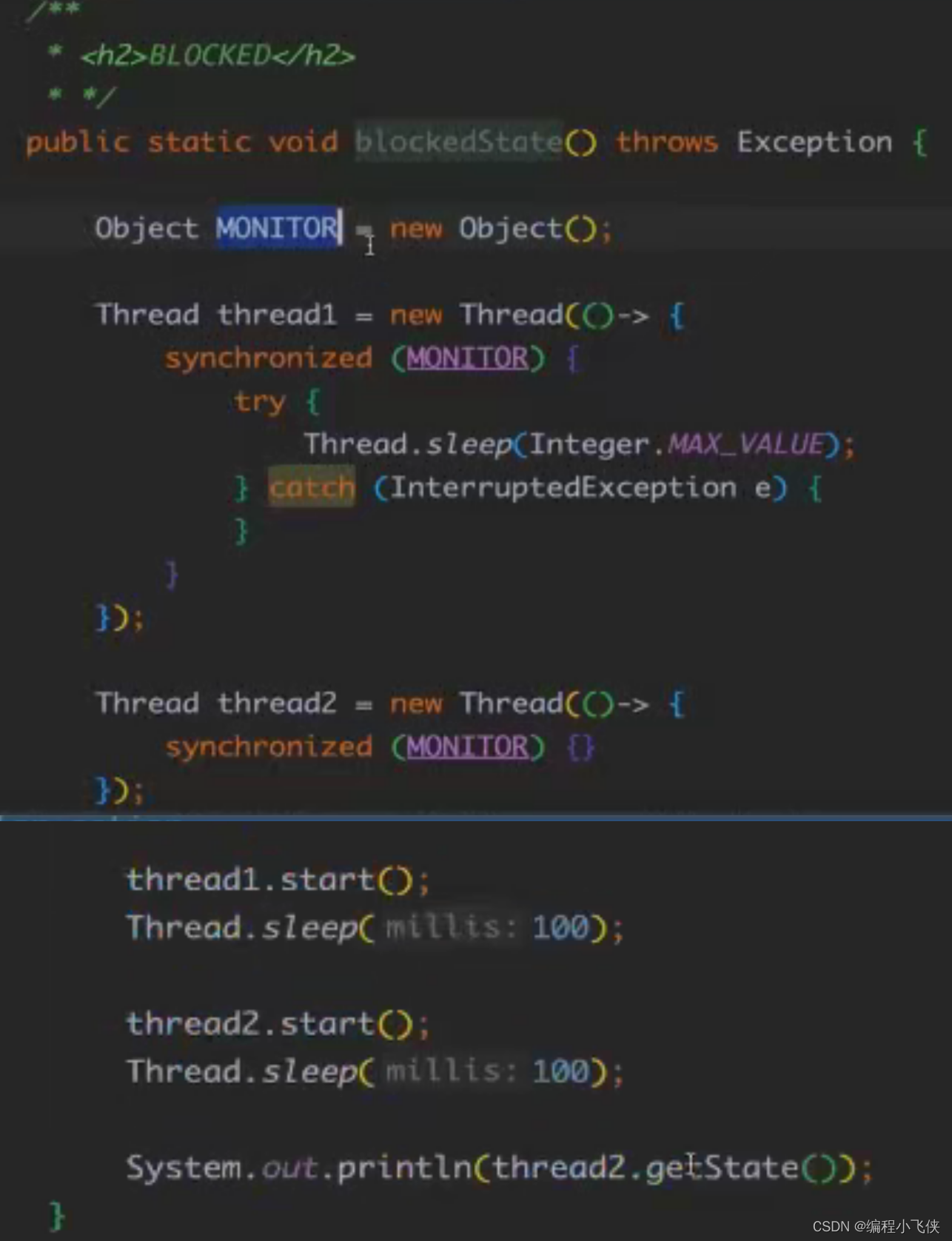
WATING:运行中的线程因为某一些操作导致单钱线程等待其他线程,无限期地等待
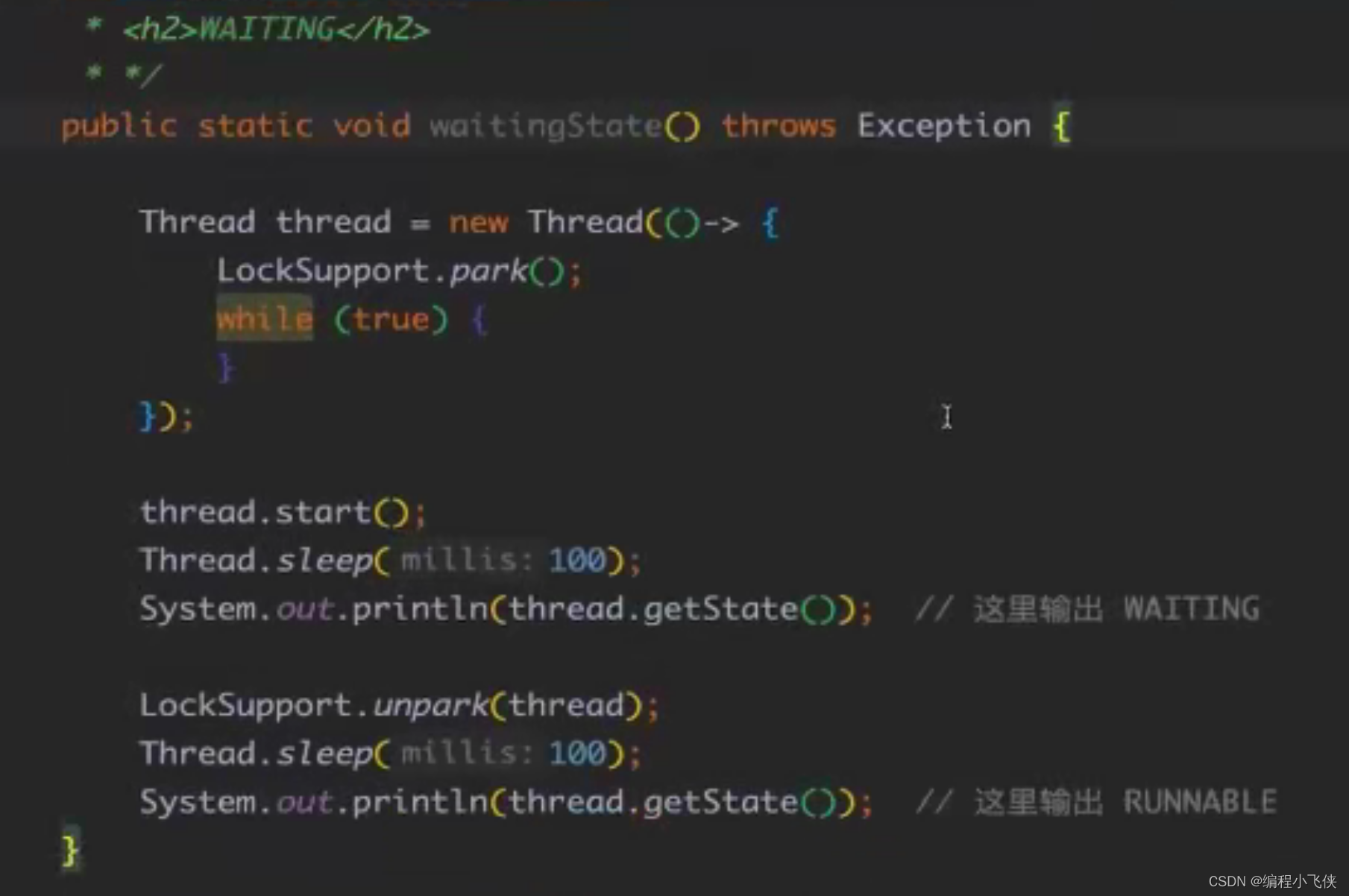
TIMED_WATING:运行中的线程因为某一些操作导致单钱线程等待其他线程,有限期地等待,如因为执行 sleep() 方法正在计时等待
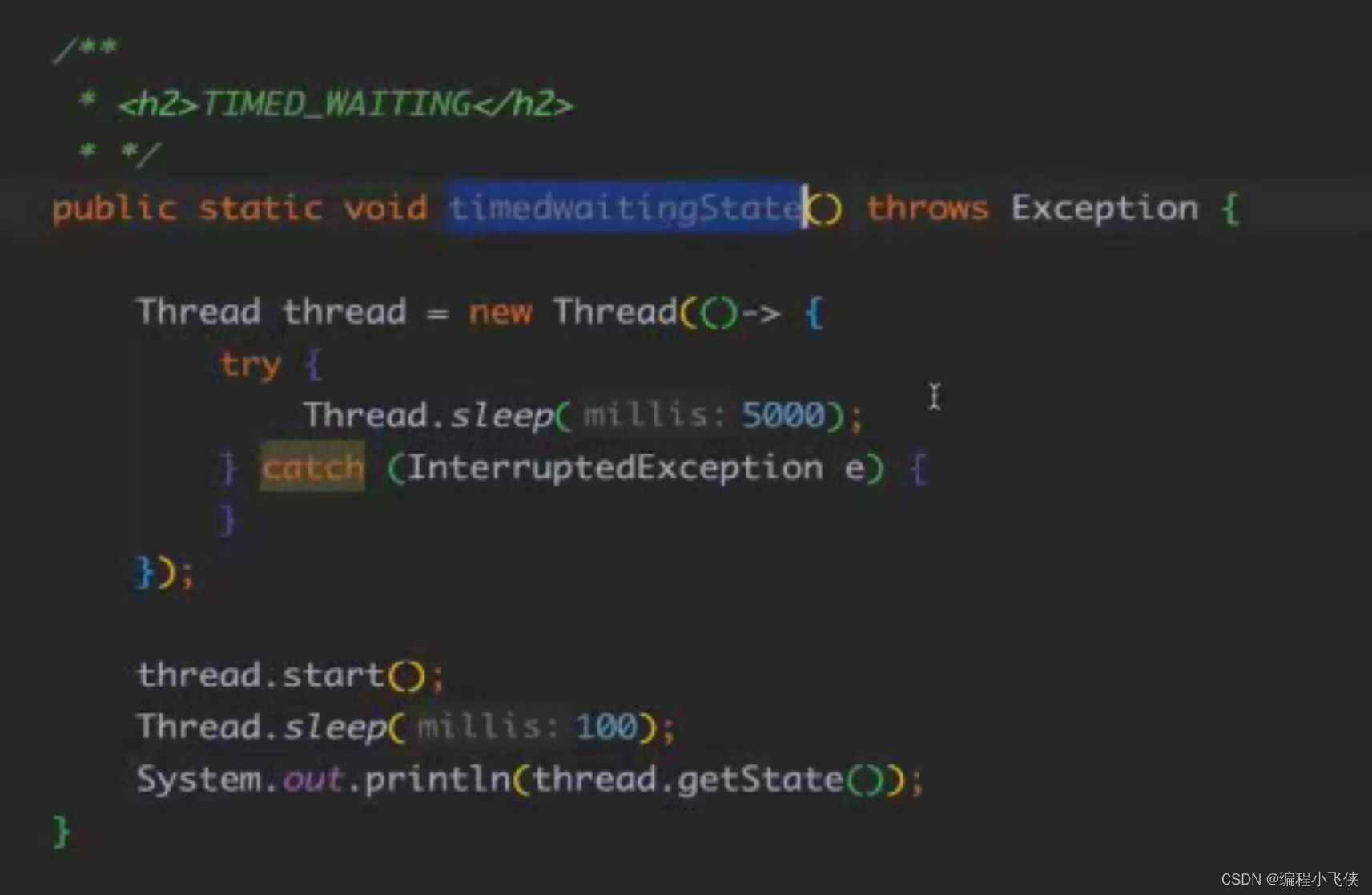
TERMINATED:线程已经终止,run() 方法执行完毕
6种状态的切换方式:
任何一个 JVM 中的线程,它的状态一定属于这6个其中的一个,且在线程的整个生命周期中,它的状态是不断变化的
使用jstack 命今获取线程堆栈日志:
stack (stack trace for lava 是 Java 虚拟机自带的一种堆栈跟踪工具,它用于打出给定的 Java 进程,core file、远程调试服务的 Java堆栈信息。也就是说,当你安装了 Java,这个工具顺带也就被安装了。
jstack工具的使用:
- man jstack:(这对于 Linux 或者 Mac 用户来说一定不会陌生
- 直接在命令行执行 jstack 或者 jstack --help 也会打印它的使用方法
执行jstack后的使用方法显示如下:

Usage 部分基本上说明了 jstack 的功能:
- pid,进程 id
- executable core,Java 程序的 core dump
- remote server IP or hostname,远程 debug 服务的主机名或 ip
- server_id,唯一id,对于一台主机上运行多个远程 debug 服务
jstack 主要用来查看某个 Java 进程内的线程堆栈信息。语法格式如下:
jstack [option] pid
# 由于线程堆栈会打印很多内容,一般我们都会重定向到文件中
jstack pid > /stack_log.txt
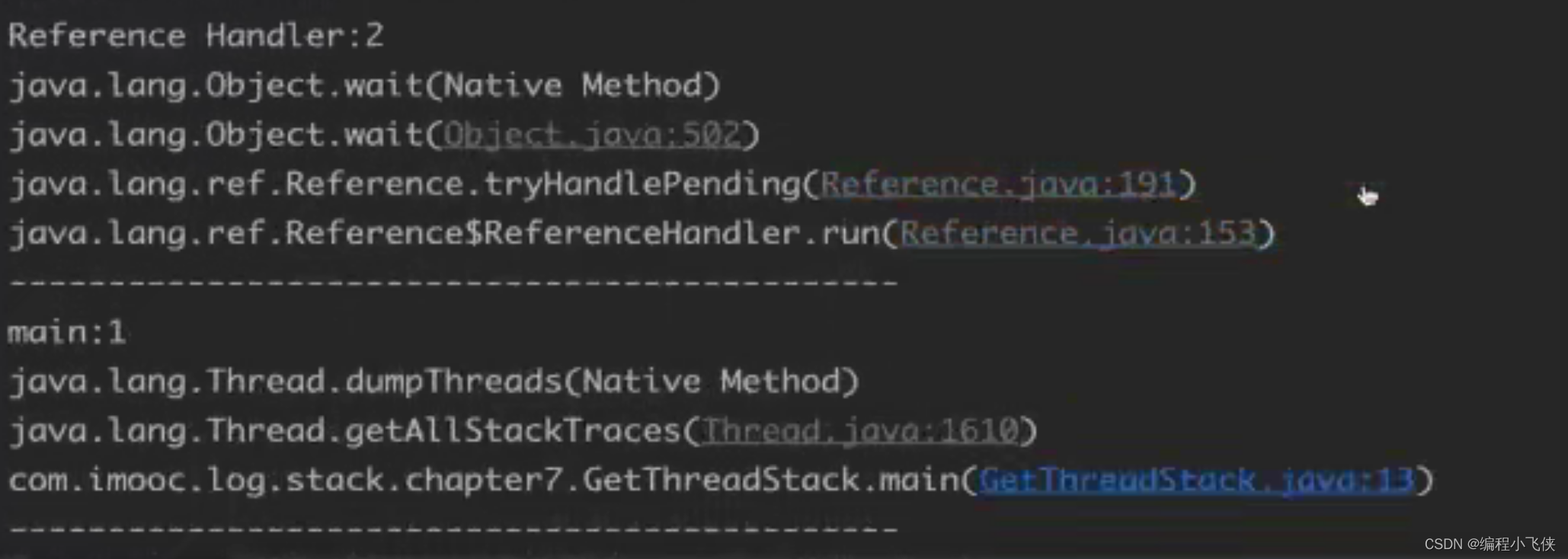
线程堆栈日志信息解读:
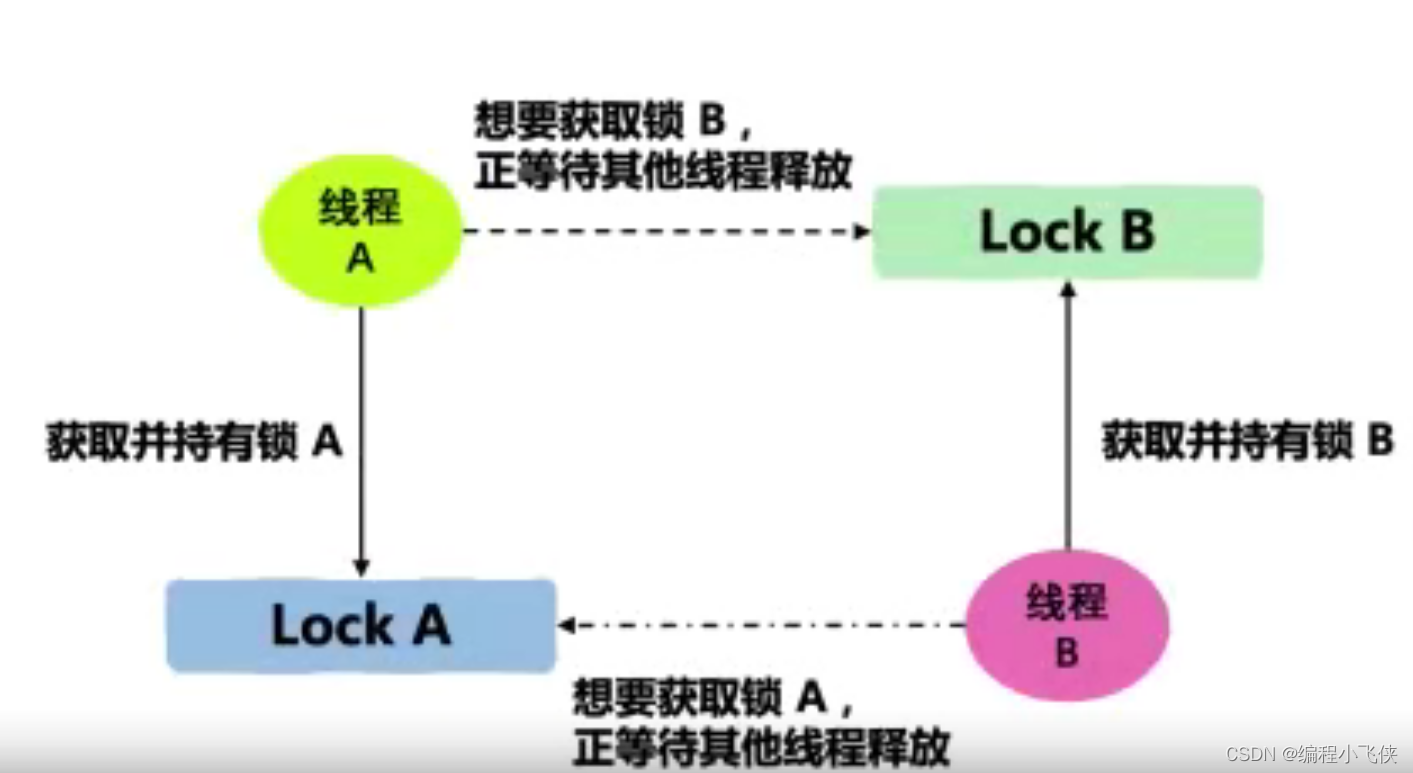
7.5 死锁的定义和形成过程:
死锁是多线程特有的问题:线程间相互等待资源,而又不释放自身的资源,导致无穷无尽的等待,其结果是系统任务永远无法执行完成。
public class DeadLock {
private static final Object obj1 = new Object();
private static final Object obj2 = new Object();
/** <h2>死锁案例</h2> **/
private static void deadLockExample() {
final Object o1 = new Object();
final Object o2 = new Object();
Runnable r1 = () -> {
synchronized(o1){
try {
Thread.sleep(2000);
}catch (InterruptedException ex) {
ex.printStackTrace();
}
synchronized(o2){
System.out.println("R1 Done!");
}
}
};
Runnable r2 = () -> {
synchronized(o2){
try {
Thread.sleep(2000);
}catch (InterruptedException ex) {
ex.printStackTrace();
}
synchronized(o1){
System.out.println("R2 Done!");
}
}
};
new Thread(r1, name: "Thread1").start();
new Thread(r2, name: "Thread2").start();
}
/** <h2>以固定的颁序去获取锁,不会死锁</h2> **/
private static void fixedOrderGetLock(){
synchronized (obj1) {
System.out.printIn(Thread.currentThread().getName() + "get lock obj1 success!";
try {
Thread.sleep(2000);
}catch (InterruptedException ex) {
ex.printStackTrace();
}
synchronized (obj2) {
System.out.printIn(Thread.currentThread().getName() + "get lock obj2 success!";
}
}
}
private static: void hasNotDeadLockExample(){
Runnable r1 = DeadLock::fixedOrderGetLock;
Runnable r2 = DeadLock::fixedOrderGetLock;
new Thread(r1, name: "Thread1").start();
new Thread(r2, name: "Thread2").start();
}
public static void main(String[] args){
// deadLockExample();
hasNotDeadLockExample();
}
}
7.6 线程处于WAITING状态的原因:
- 使用了不带时限的Object.wait方法
- 使用了不带时限的Thread.join方法
- 使用了LockSupport.part
避免的大量线程处于WAITING状态的场景:
- 任意创建线程池,大量的线程获取不到 task,导致WAITING线程很多(浪费虚拟机内存,可能会导致以后的操作、创建对象内存不足)
- 线程池提交任务完成之后,没有及时关闭,导致WAITING 线程很多(浪费虚拟机内存,可能会导致以后的操作、创建对象内存不足)
- 由于需要处理的任务比较多,线程池中的线程个数配置很大,但是任务中并不是集中的,导致很多线程处于park和unpark的切换之中(频繁的上下文切换,导致CPU 使用率升高
八.JVM性能调优:
8.1性能调优包含:
架构调优,代码调优,JVM调优,数据库调优,操作系统调优。
8.2 什么是JVM 调优,调优的指标是什么
JVM调优在架构调优和代码调休后,都没有达到效果,才进行JVM调优。
- JVM 调优指的就是对当前系统进行性能调优,简单来说就是:尽可能使用较小的内存和CPU来让Java程序获得更高的吞吐量及较低的延迟
- 调优都是由指标来支撑的
吞吐量:是指不考虑垃圾收集引起的停顿时间或内存消耗,应用达到的最高性能指标
**延迟:**缩短由于垃圾收集引起的停顿时间或者完全消除因垃圾收集所引起的停顿,避免应用运行时发生抖动
内存占用:垃圾收集器流畅运行所需要的内存数量
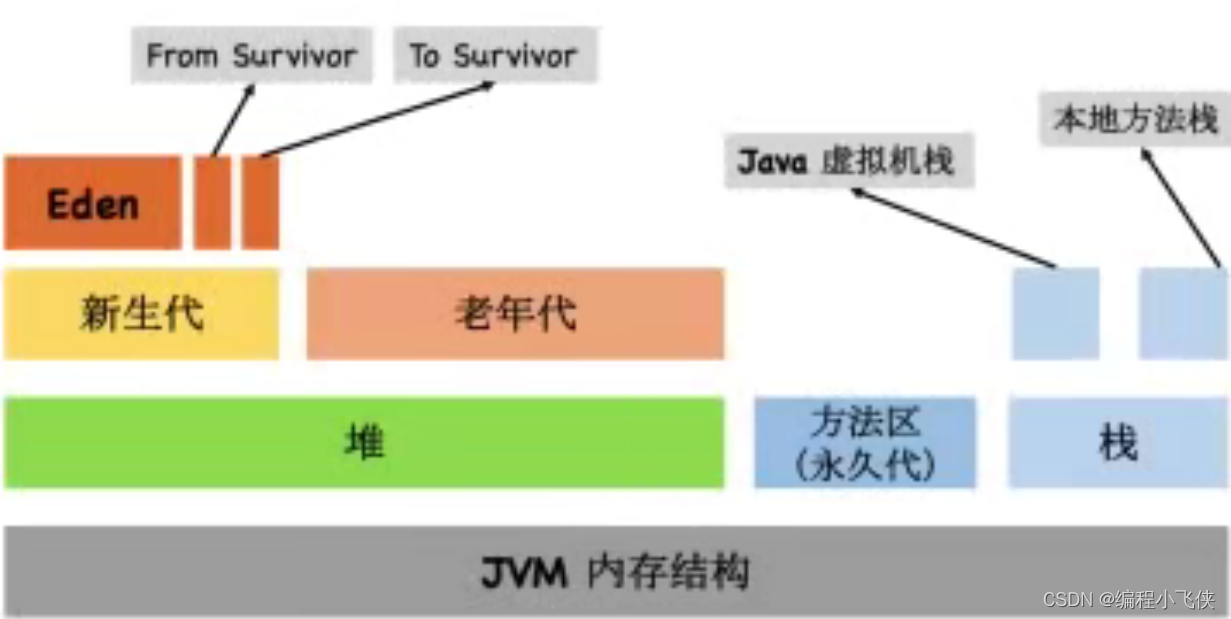
JVM内存结构:
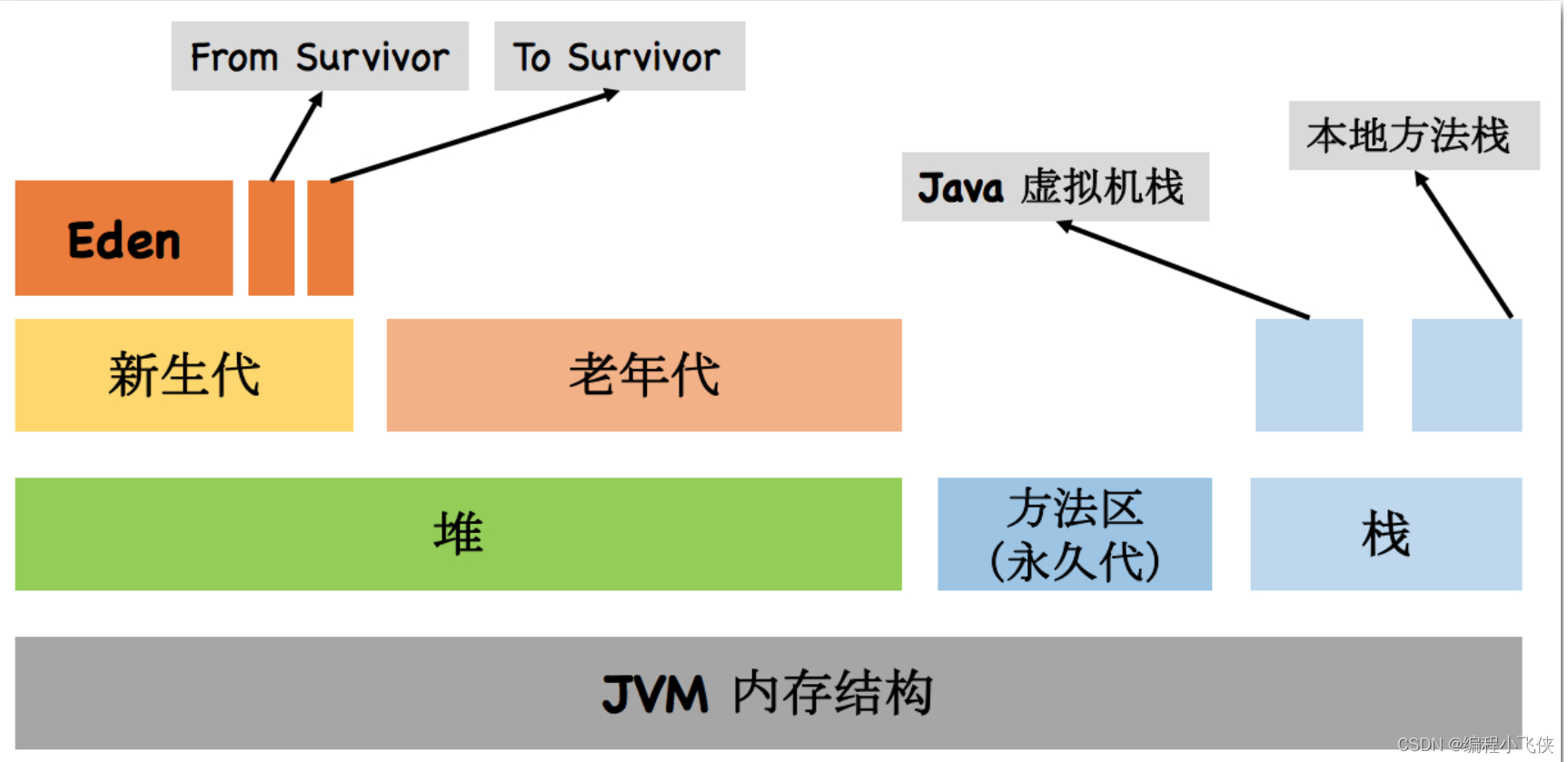
- JVM 的内存空间分为三大部分:堆内存、方法区、栈内存。其中栈内存可以再细分为 Java 虚拟机栈和本地方法;堆内存可以划分为新生代和老年代、新生代中还可以再次划分为 Eden区、From Survivor 区和 To Survivor 区。
- 在内存结构中,其中一部分是线程共享的,包括 Java 堆和方法区;另一部分是线程私有的,包括虚拟机栈和本地方法栈和程序计数器这一小部分内存。
堆内存:
堆是 JVM 所管理的内存中最大的一块,它是被所有线程共享的区域,是在 JVM 启动时创建的。堆里面存放的都是对象的实例(即我们在代码中new 出来的)。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里被分配。
另外,堆内存分为两个部分:年轻代(或者叫新生代)和老年代。我们平常所说的垃圾回收,主要回收的就是堆区。更细一点划分新生代又可划
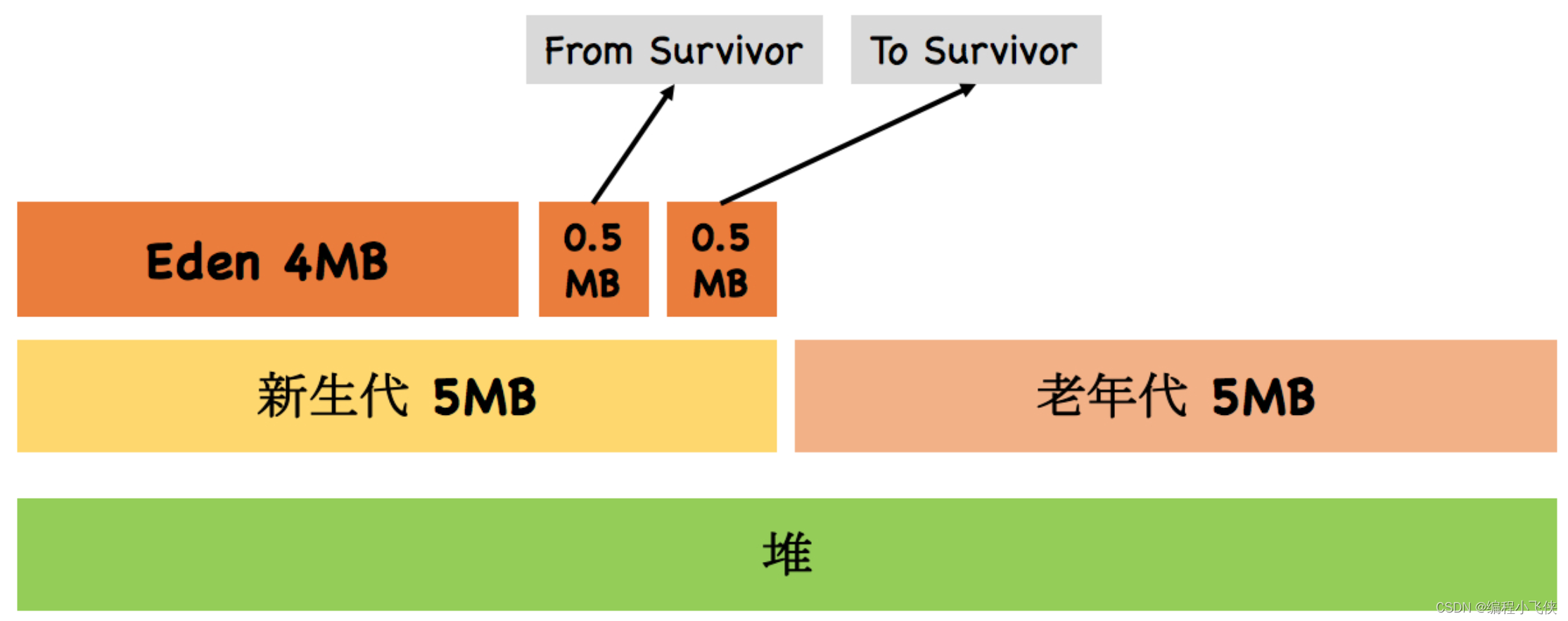
Eden 区和 2个 Survivor 区(From 和 To )。它们的大小分配及配置参数是: - 年轻代和老年代大小的比例为 1:2,该值可以通过参数 –XX:NewRatio 来指定
- 默认的,Eden : from : to = 8 : 1 : 1,可以通过参数 –XX:SurvivorRatio 来设定
何时需要考虑去做JVM 调优:吞吐量低、延迟高、经常出现OOM等等
- Full GC次数频繁
- GC停顿时间过长(例如1秒)
- 应用出现 OutOfMemory 等内存异常
- 系统吞吐量与响应性能不高或持续下降
JVM 调优的基本原则:JVM 调优是一个手段,但并不一定所有问题都可以通过JVM 进行调优解决
- 大多数的Java应用不需要进行JVM优化
- 大多数导致 GC问题的原因是代码层面的问题导致的
- 减少使用全局变量和大对象;减少创建对象的数量
- 分析 GC情况优化代码比优化JVM 参数更好
- 优先架构调优和代码调优,JVM 优化优先级放到最低
JVM调优的目标:

8.3GC算法和常用垃圾收集器:
GC 可以狭义的理解为对 Java 堆中的垃圾对象进行回收。那么,在 GC 之前,就需要确定哪些才是垃圾对象。两种 JVM 垃圾判定算法:引用算法、可达性分析算法。
对象存活分析:

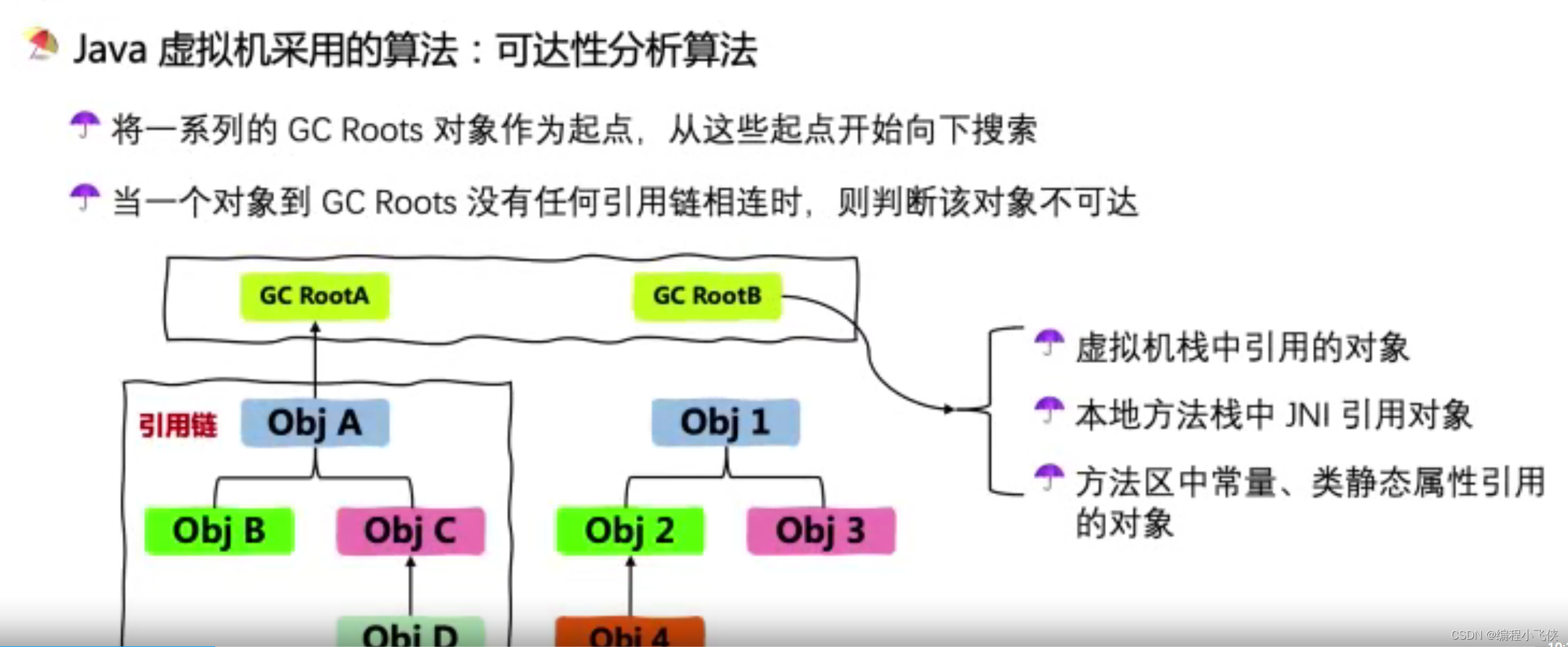
GC算法:
垃圾收集器实现:
- 标记-清除:标记和清除过程效率都不高,产生大量的内存碎片
- 标记-复制:浪费内存空间,对象需要来回复制,效率不高
- 标记-整理:不仅要标记存活对象,还要整理所有存活对象的引用地址,在效率上不如复制算法
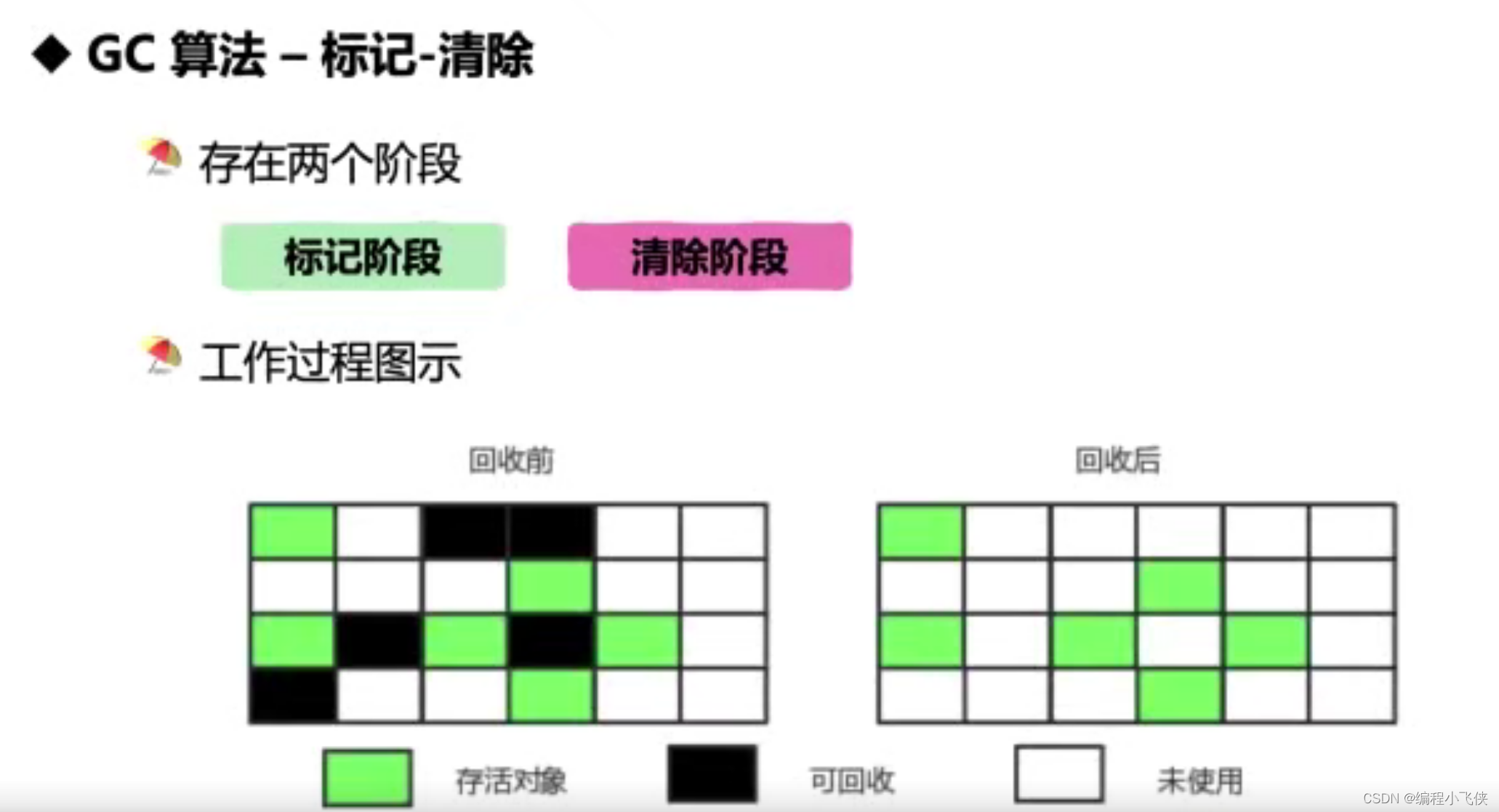
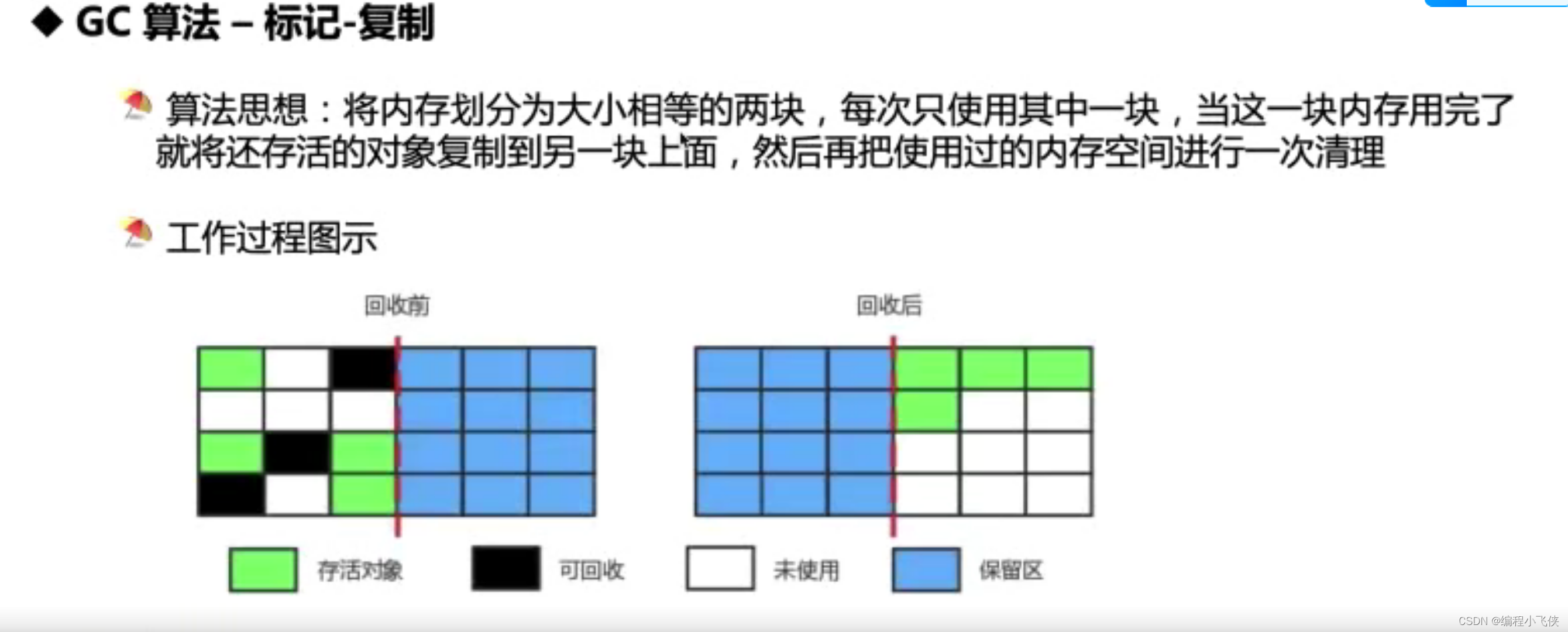
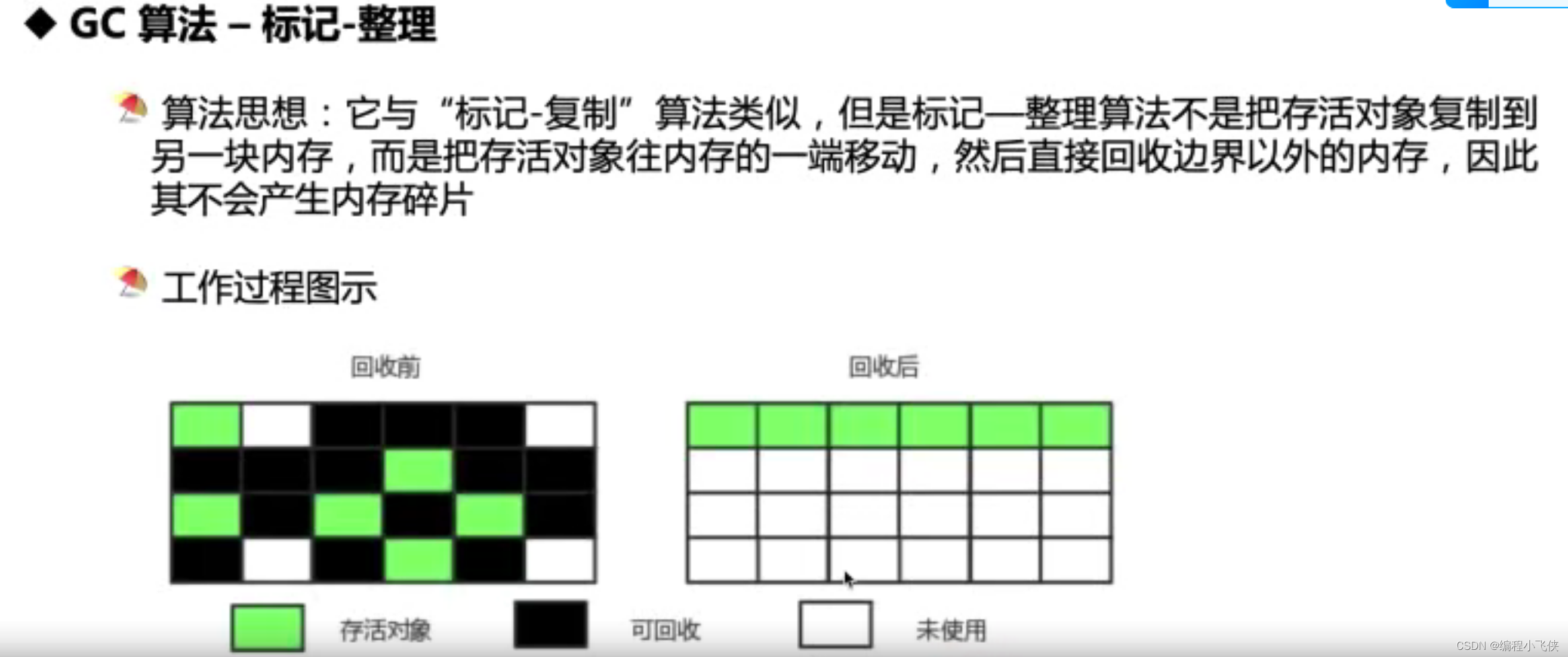
常用垃圾收集器:
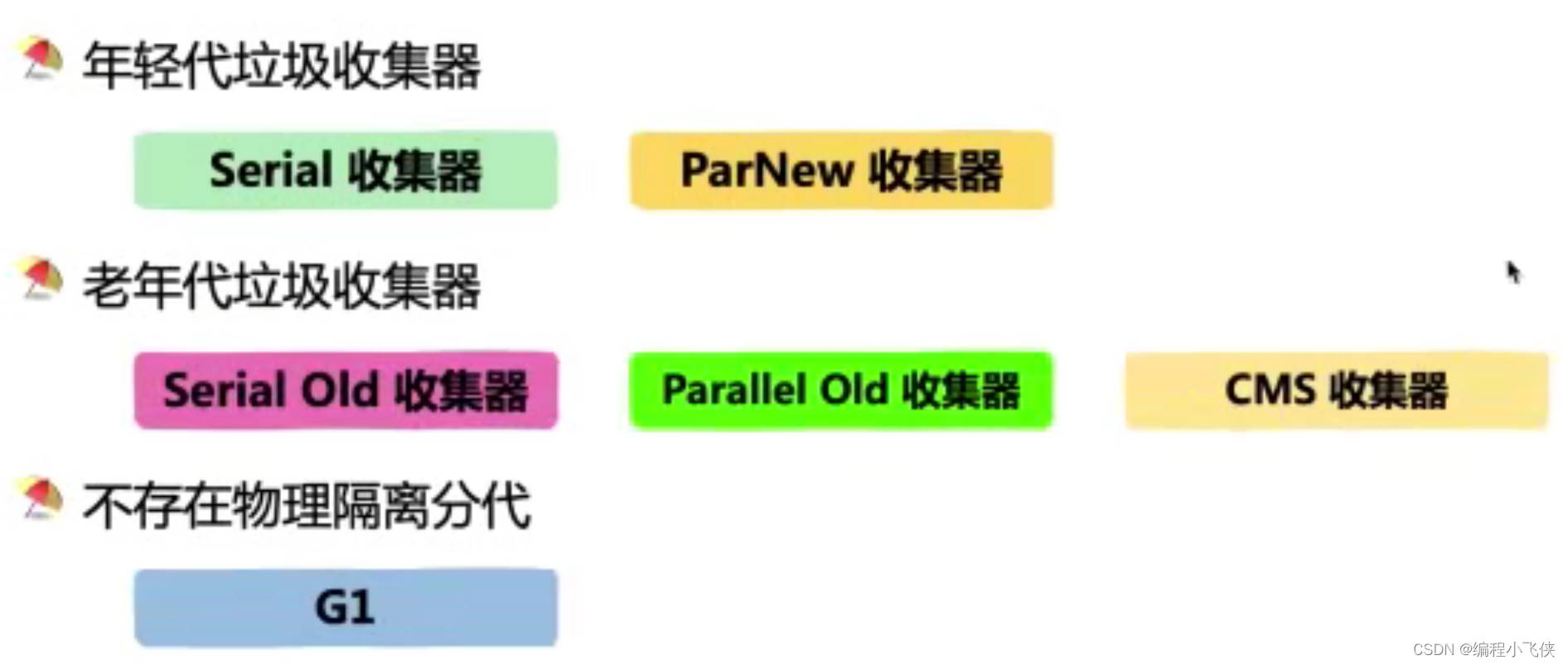
8.4 JDK工具:用于查看JVM配置参数的jinfo
jinfo(JDK自带的命令,主要有三大功能):
- 可以用来查看正在运行的 java 应用程序的扩展参数,包括 Java System 属性和JVM 命令行参数
- 可以动态的修改正在运行的JVM一些参数
- 当系统崩溃时,jinfo可以从core 文件里面知道崩溃的Java应用程序的配置信息
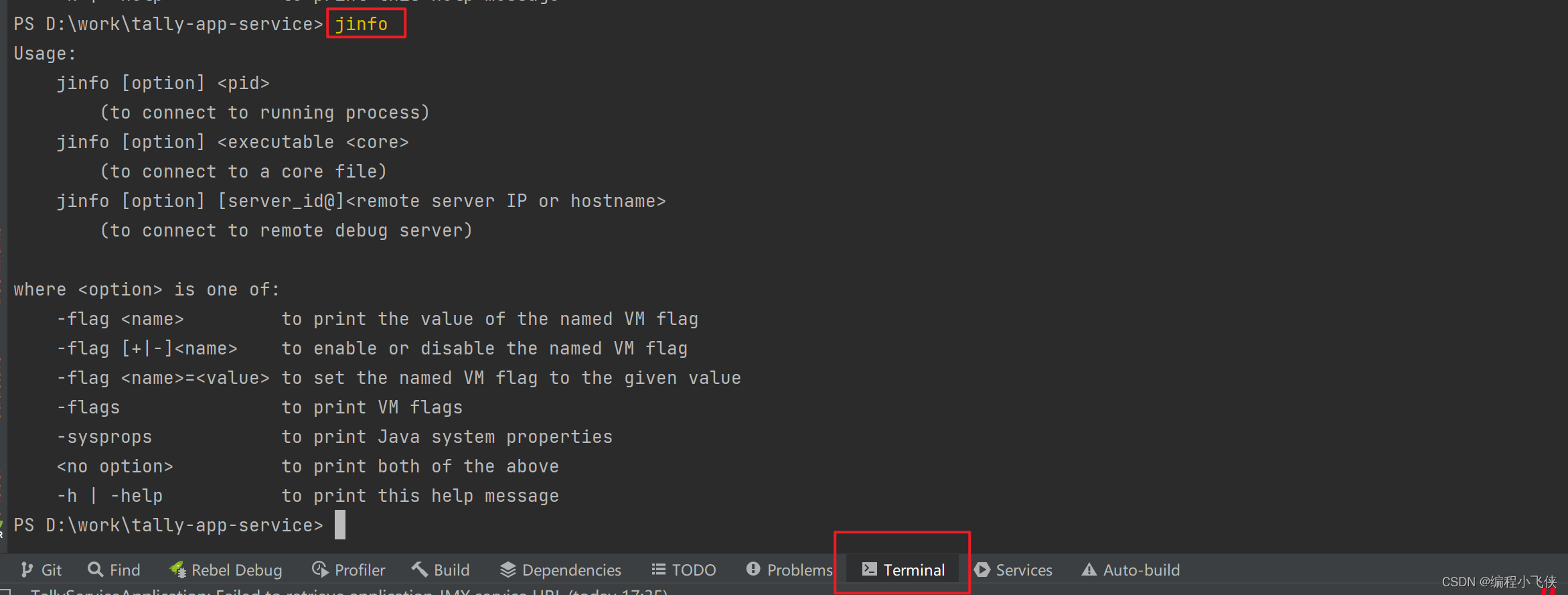
jinfo文档说明:
man jinfo
jinfo -help
jinfo
打印java系统属性:
查看Java版本:
java -version

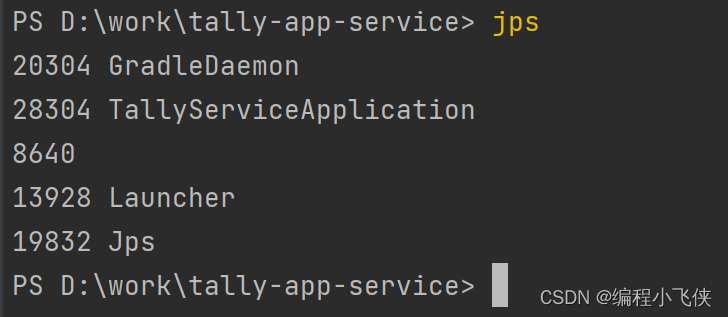
查看当前工程t的进程id:
jps
输出当前JVM的全部参数和系统属性:
jinfo 28304 (这个命令输出信息是jinfo -flags 28304 和 jinfo -sysprops 28304 的输出信息的结合)
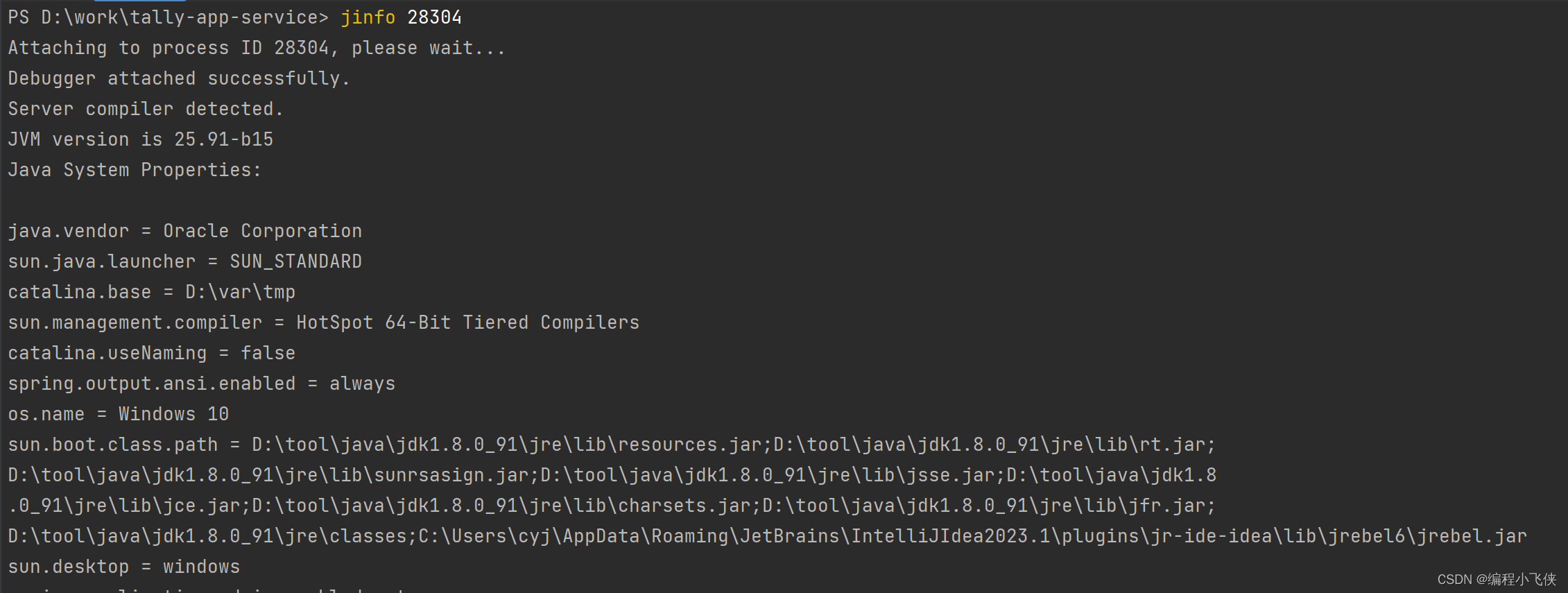
查看是否有开启打印GC的功能:
jinfo -flag PrintGC 28304
下面打印内容PrintGc 前面有- 表示没有开启打印GC功能

开启打印GC的功能(是boolean型的才在前面+或-):
jinfo -flag +PrintGC 28304

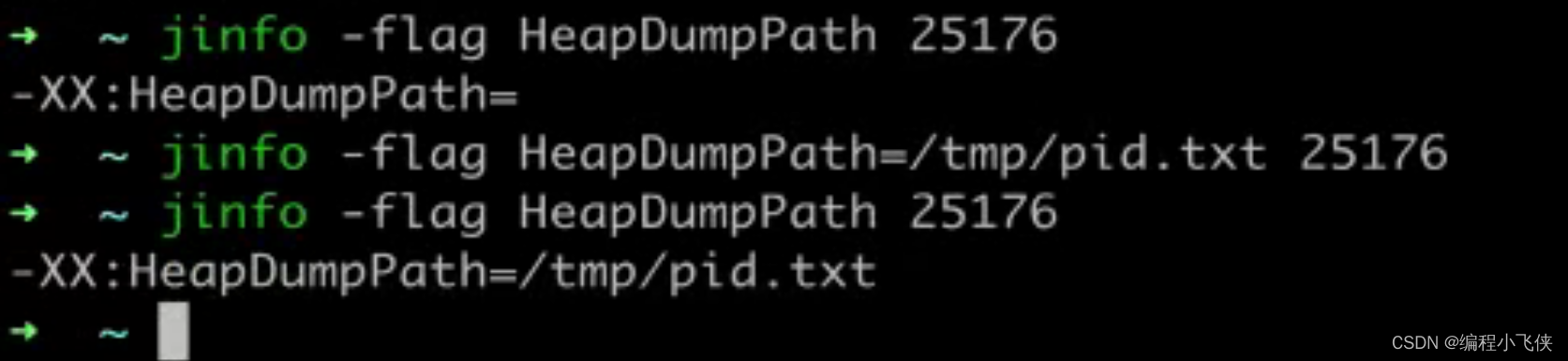
boolean型的动态修改值用=如下:
jinfo -flag HeapDumpPath=/tmp/pid.txt 25176
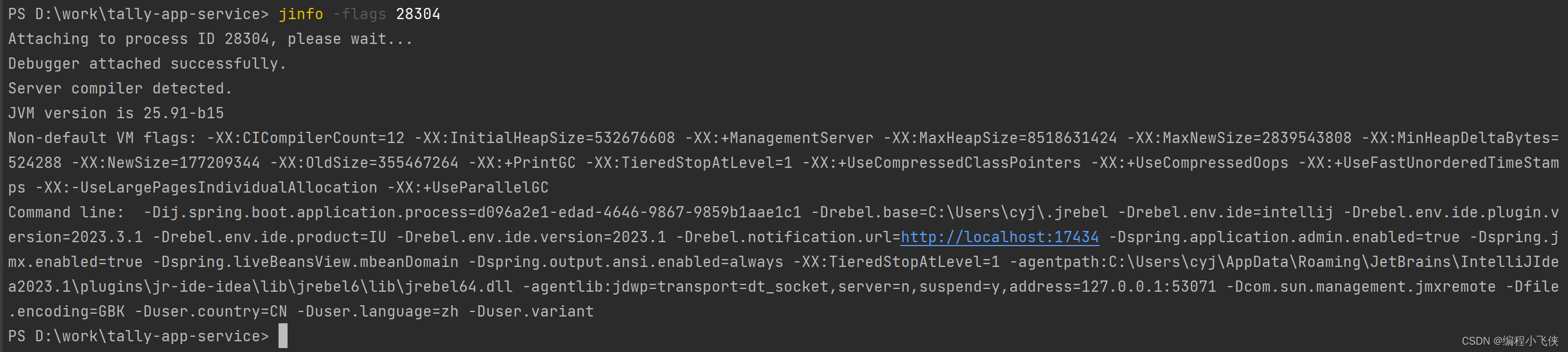
输出当前JVM虚拟机的所有参数:
jinfo -flags 28304
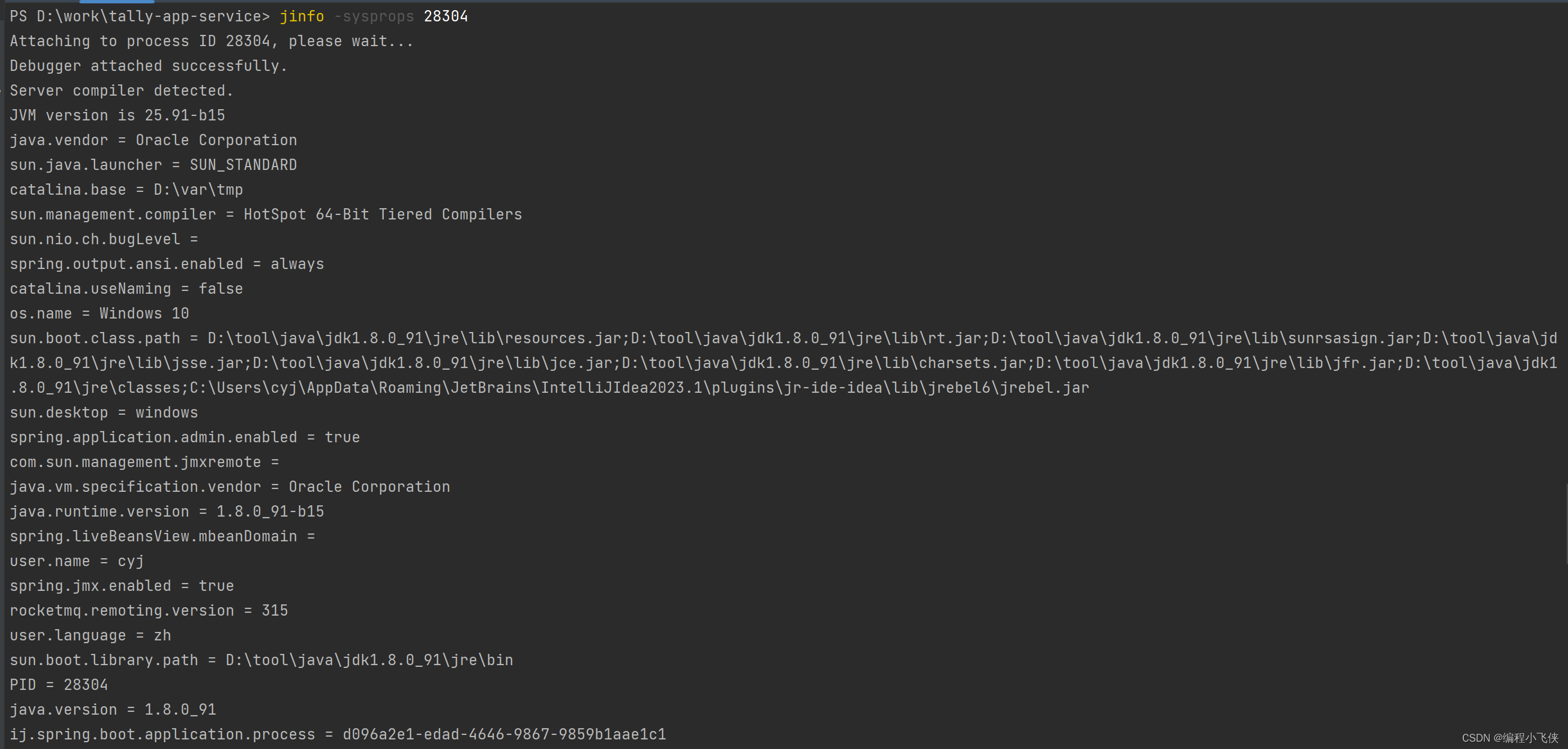
输出当前JVM虚拟机的全部系统属性:
jinfo -sysprops 28304
8.5JDK工具:用于查看JVM堆内存使用的jmap
jmap:JDK自带的分析工具,输出进程,核心文件的共享对象内存或者堆内存的相关信息
最常见的应用方向:
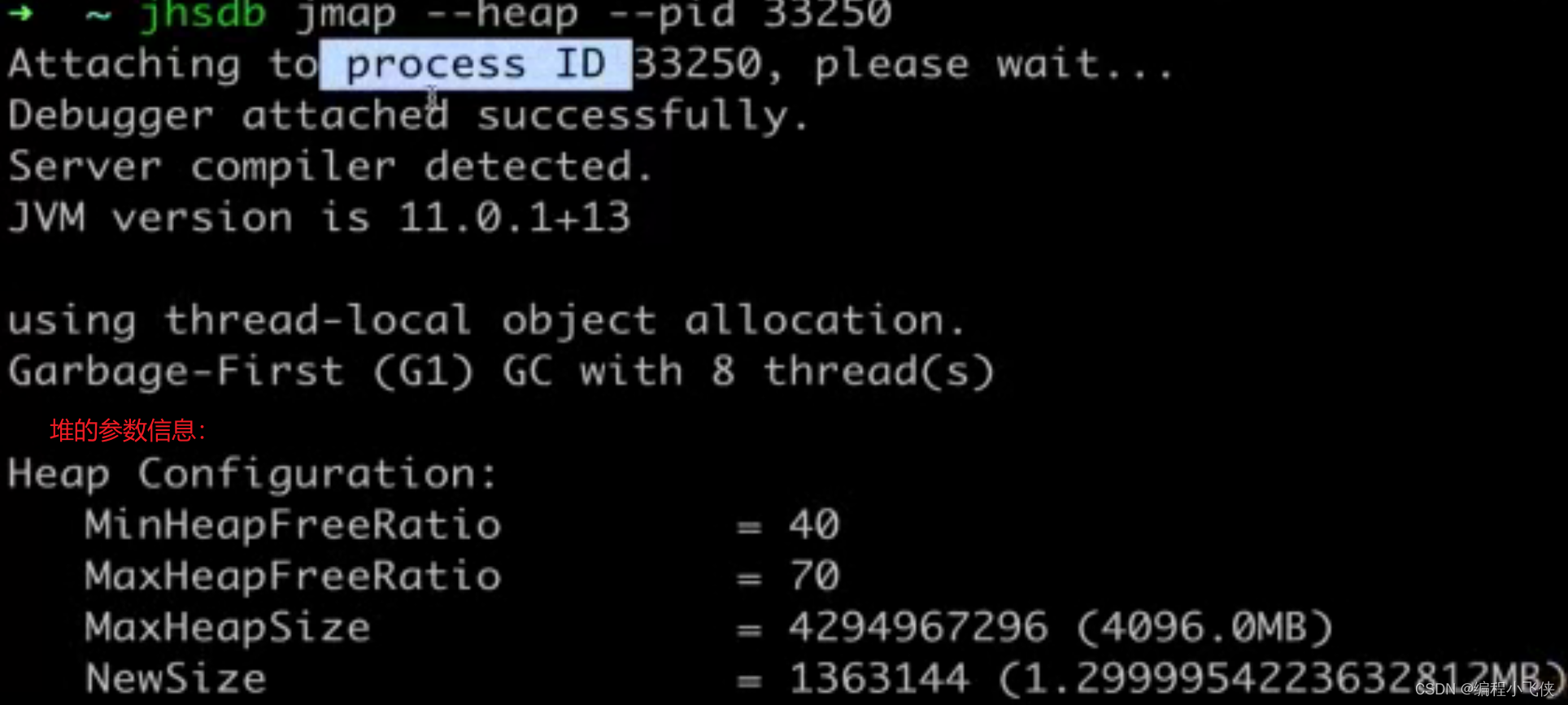
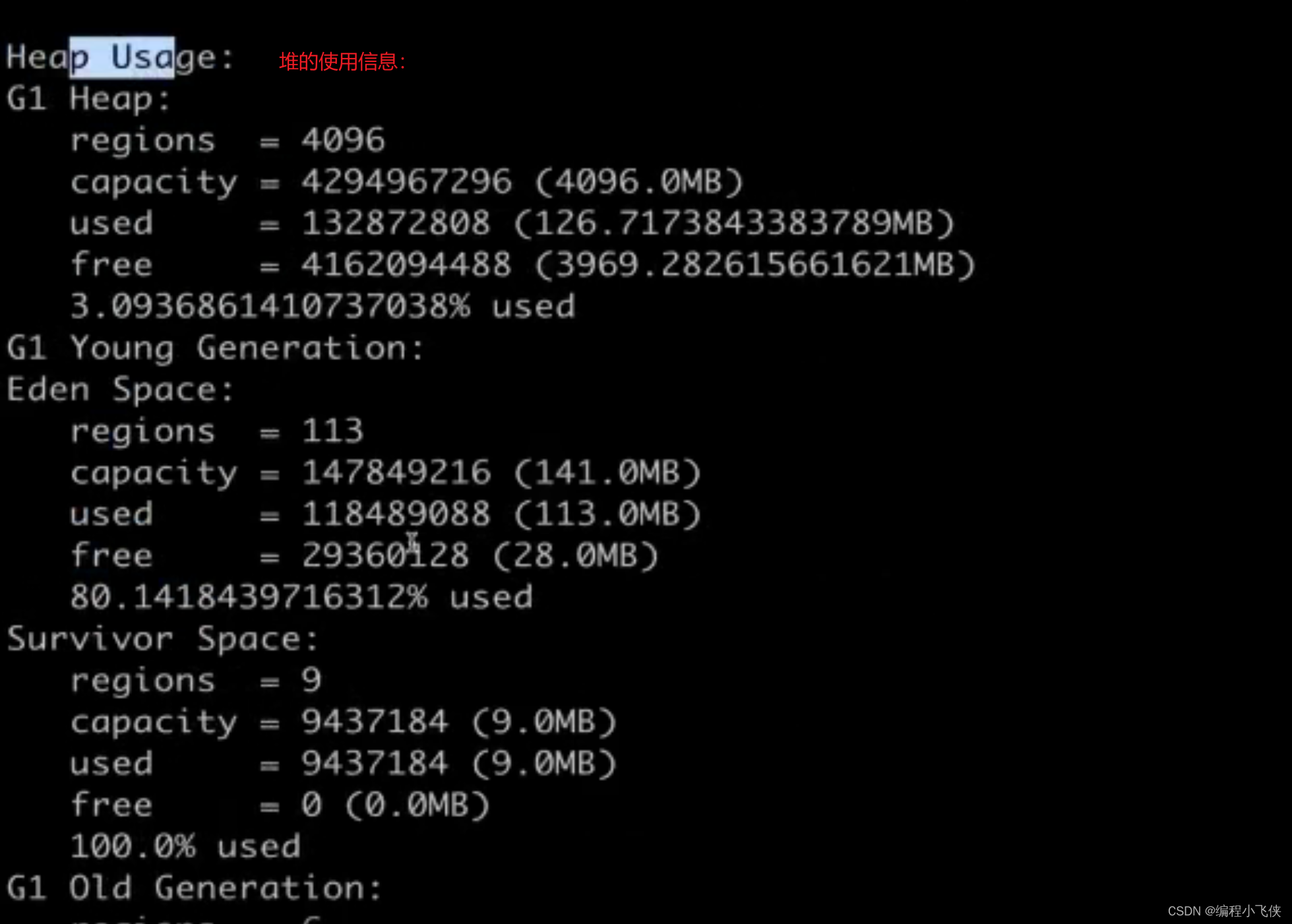
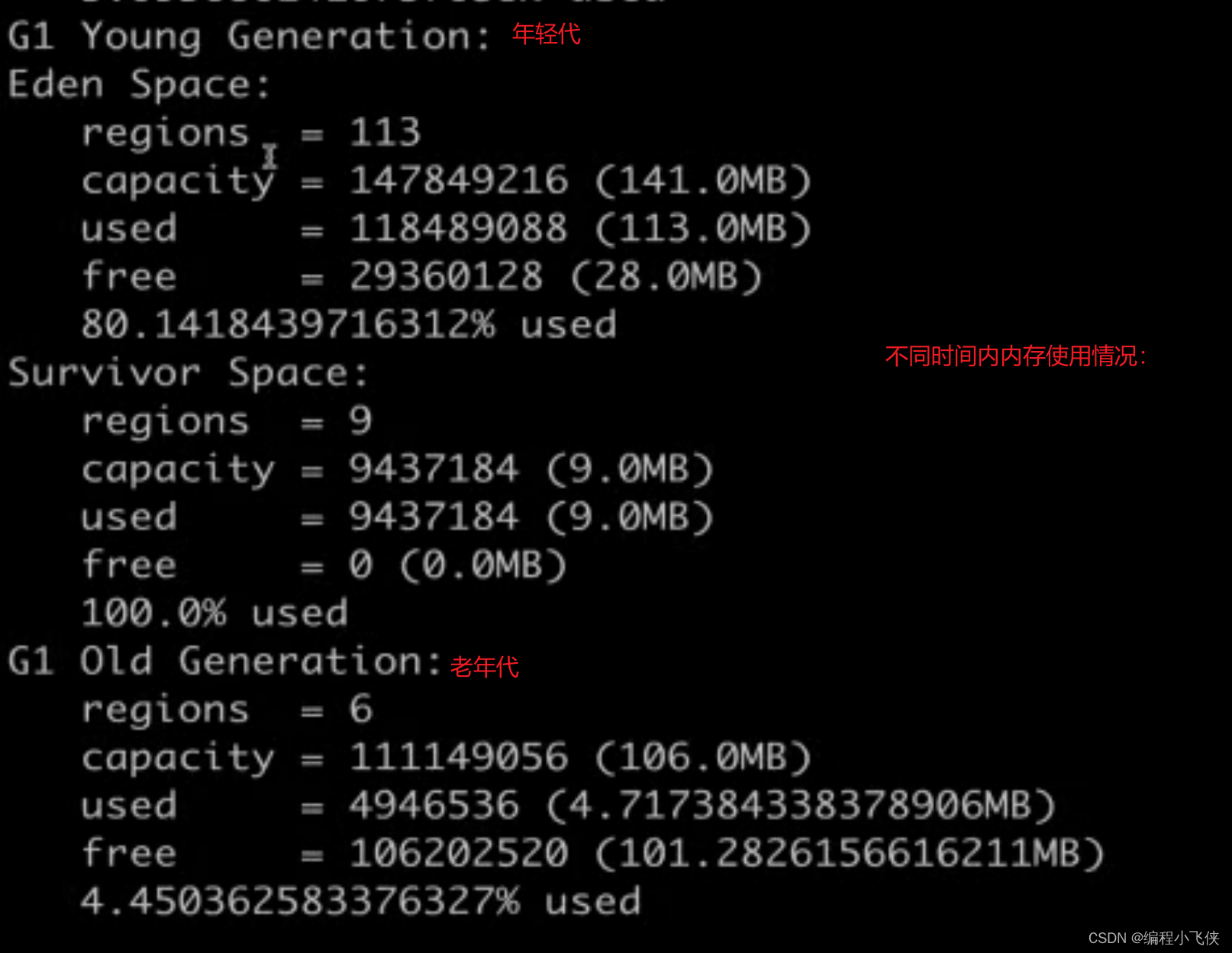
- Java 堆的详细信息:包括使用的GC算法,堆的配置信息和各个内存区域内存的使用情况
- 显示堆中对象的统计信息,会包括每一个Java 类,对象的数量,内存使用大小,类名称
- 打印正等候回收的对象的信息
- 生成堆转储快照dump文件,使用jhat以html的方式查看
查看jmap命令帮助文档:
jmap -help
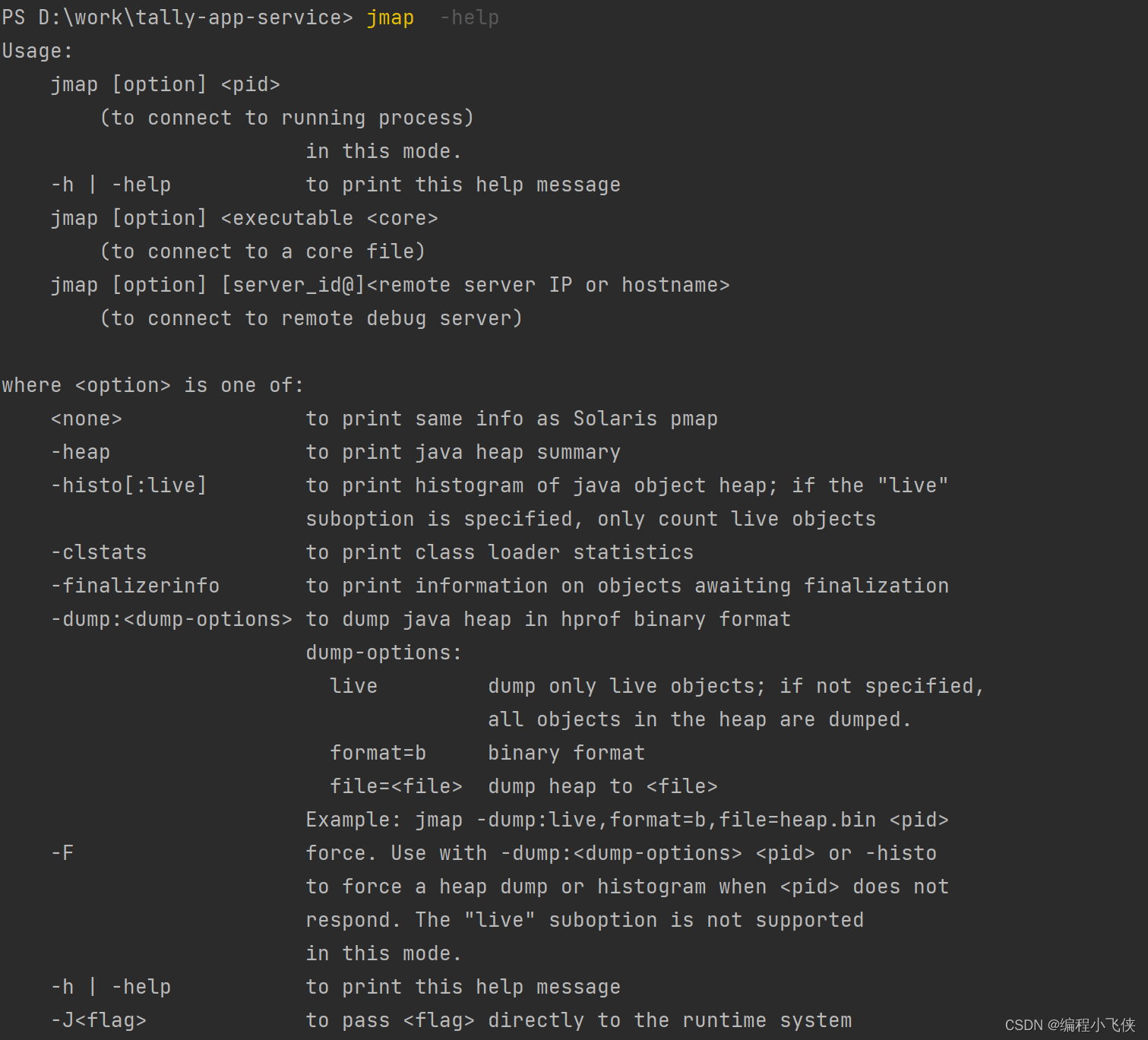
打印堆的详细信息:
jmap --heap --pid 28304
打印当前工程的所有Java类。java类的路径,内存使用情况,大小:
jmap -histo:live 28304 |more
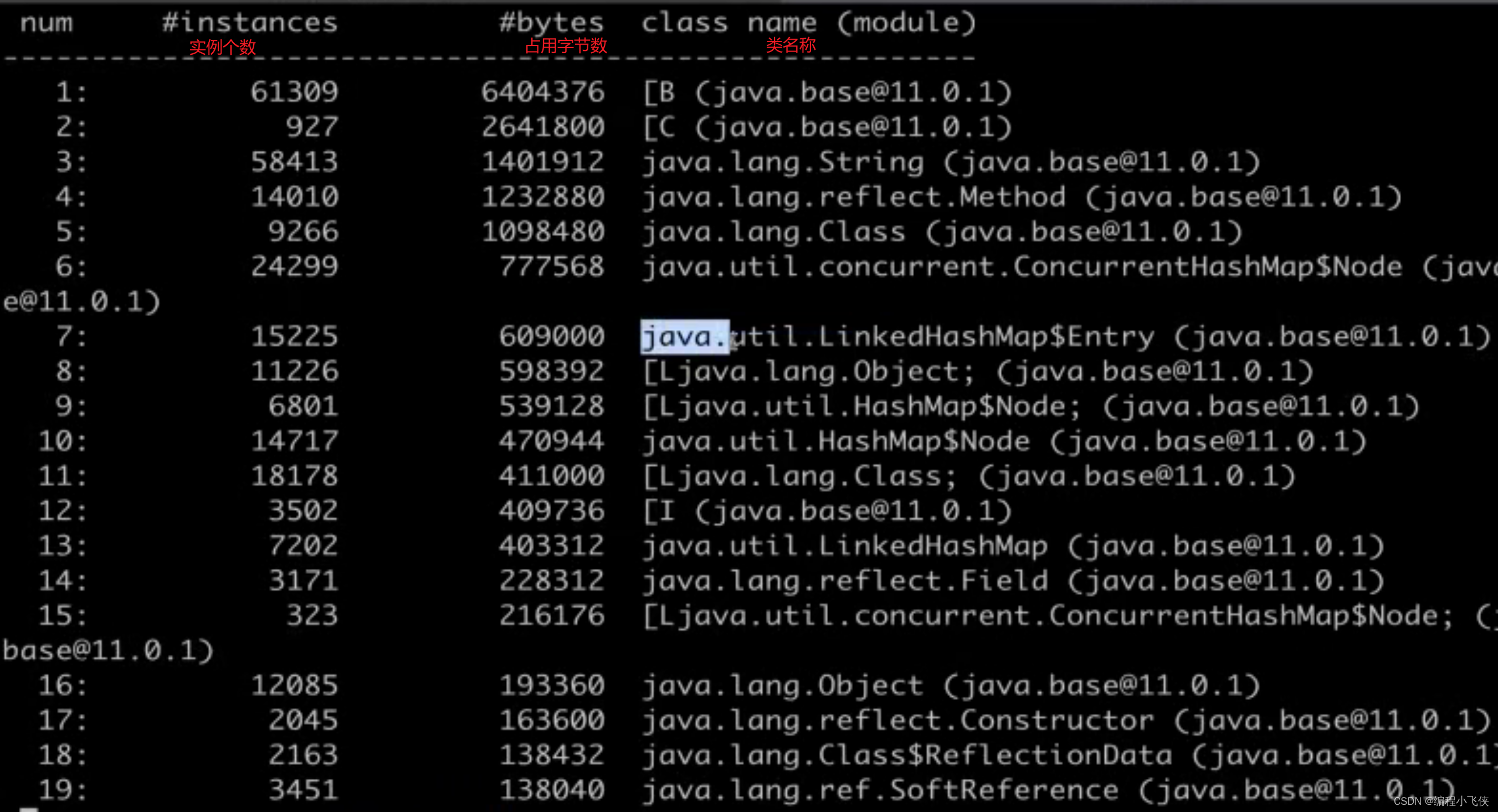
查看当前工程那些实例对象不断地等待回收(GC比较频繁的时候使用到):
jmap -finalizerinfo 28304
因为GC不频繁,所以提示没有找到

生成堆存储信息:
dump:live 把存活的对象下载到下面的文件中
format=b 二进制的方式
/tmp/heap.bin 要存到的文件中,这个文件要存在
jmap -dump:live,format=b,file=/tmp/heap.bin 28304

把二进制文件转化为html形式显示:
jhat /tmp/heap.bin
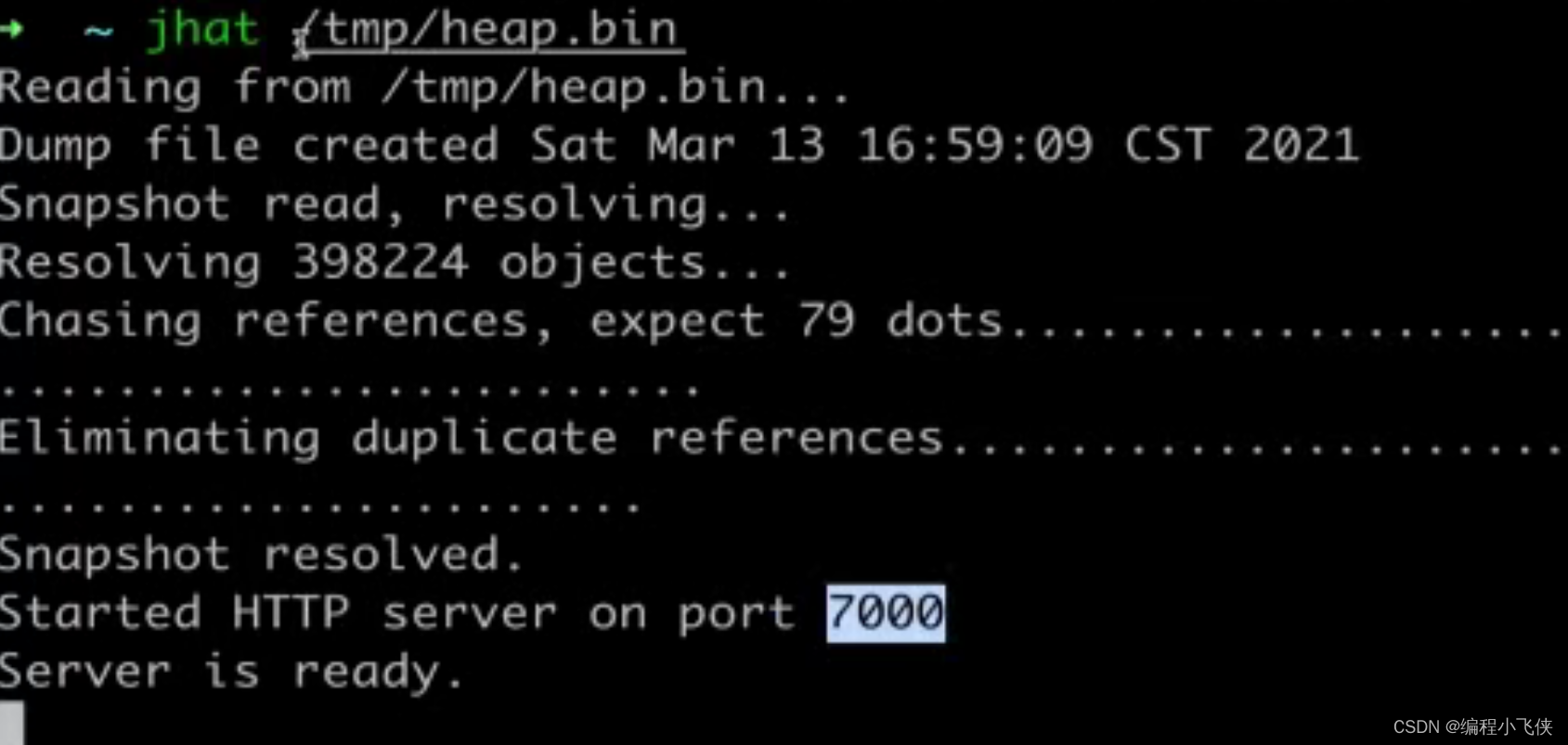
在本地访问7000端口就可以查询二进制文件转化为html形式的文件

8.6 用于查看JVM统计信息的jstat
jdk工具jstat:
- 用于监控虚拟机各种运行状态信息的命令行工具,可以显示虚拟机进程中的类装载,内存,垃圾收集,JIT编辑等运行数据
- 用于查询三类虚拟机信息:类装载,垃圾收集,运行期编译情况
查看jstat 帮助文档:
jstat -help
查看需要查看的虚拟机信息options:
jstat -options

查看类装载的信息:
jstat -class 28304

查看虚拟机编译统计信息:
jstat -compiler 28304

打印垃圾回收统计,查询GC信息,查看GC次数和时间:
每250毫秒查询一次,一共查询5次
jstat -gc 28304 250 5
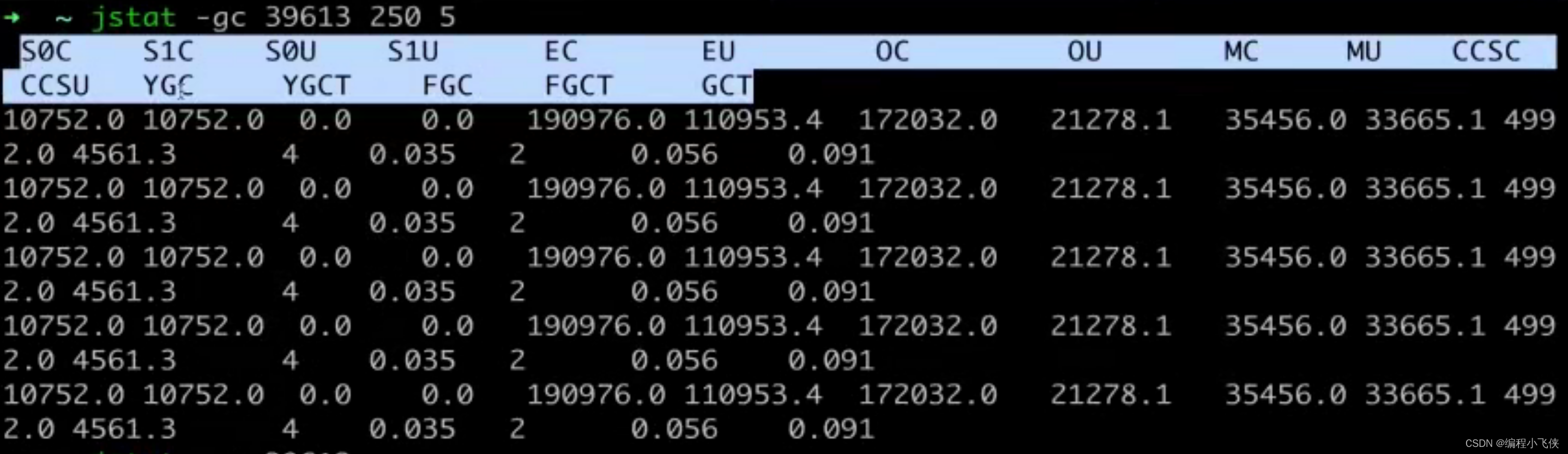
查询Jvm中,内存中,三代(年轻代,老年代,永久区)对象的内存使用和占用大小
jstat -gccapacity 28304

查询GC统计信息:
每250毫秒查询一次,一共查询5次
jstat -gcutil 28304 250 5
统计年轻代GC统计信息:
jstat -gcnew 28304

查询Jvm中,内存中,年轻代对象的内存使用和占用大小
jstat -gcnewcapacity 28304

统计老年代GC统计信息:
jstat -gcold 28304

查询Jvm中,内存中,老年代对象的内存使用和占用大小
jstat -gcoldcapacity 28304

8.7 获取并分析java GC 日志
两种获取GC日志方式:
方式一:命令动态查询:
jstat -gc 进程id 250 5
方式二:设定JVM参数:
-XX:Newsize=5M -XX:MaxNewsize=5M -XX:Initialheapsize= 10M -XX:MaxHeapsize=10M -XX:SurvivorRatio= 8 -XX:PretenuresizeThreshold= 10M -XX:+UseParNewGC -XX:+UseConcMarksweepGo -XX:+PrintGCDetails -XX:+PrintGcTimestamps
配置信息解读:
-XX:NewSize :初始年轻代大小
-XX:MaxNewSize :最大年轻代大小
-XX:InitialHeapSize :初始堆大小
-XX:MaxHeapSize :最大堆大小
-XX:SurvivorRatio :设置两个 Survivor 与 Eden 大小的比值,设置为8的含义是 (From + To)Survivor:Eden = 2:8,即一个 Survivor 占
代大小的 1/10
-XX:PretenureSizeThreshold :指定大对象阈值
-XX:+UseParNewGC :年轻代使用 ParNew 垃圾收集器
-XX:+UseConcMarkSweepGC :老年代使用 CMS 收集器
-XX:+PrintGCDetils :打印详细的 GC 日志
-XX:+PrintGCTimeStamps :打印出每次 GC 发生的时间
上面这样的配置会使得 GC 日志打印在控制台上,如果内容过多不便于查看,可以使用 -Xloggc:gc.log 参数将 GC 日志写入文件中(并指定了文件是 gc.log)。
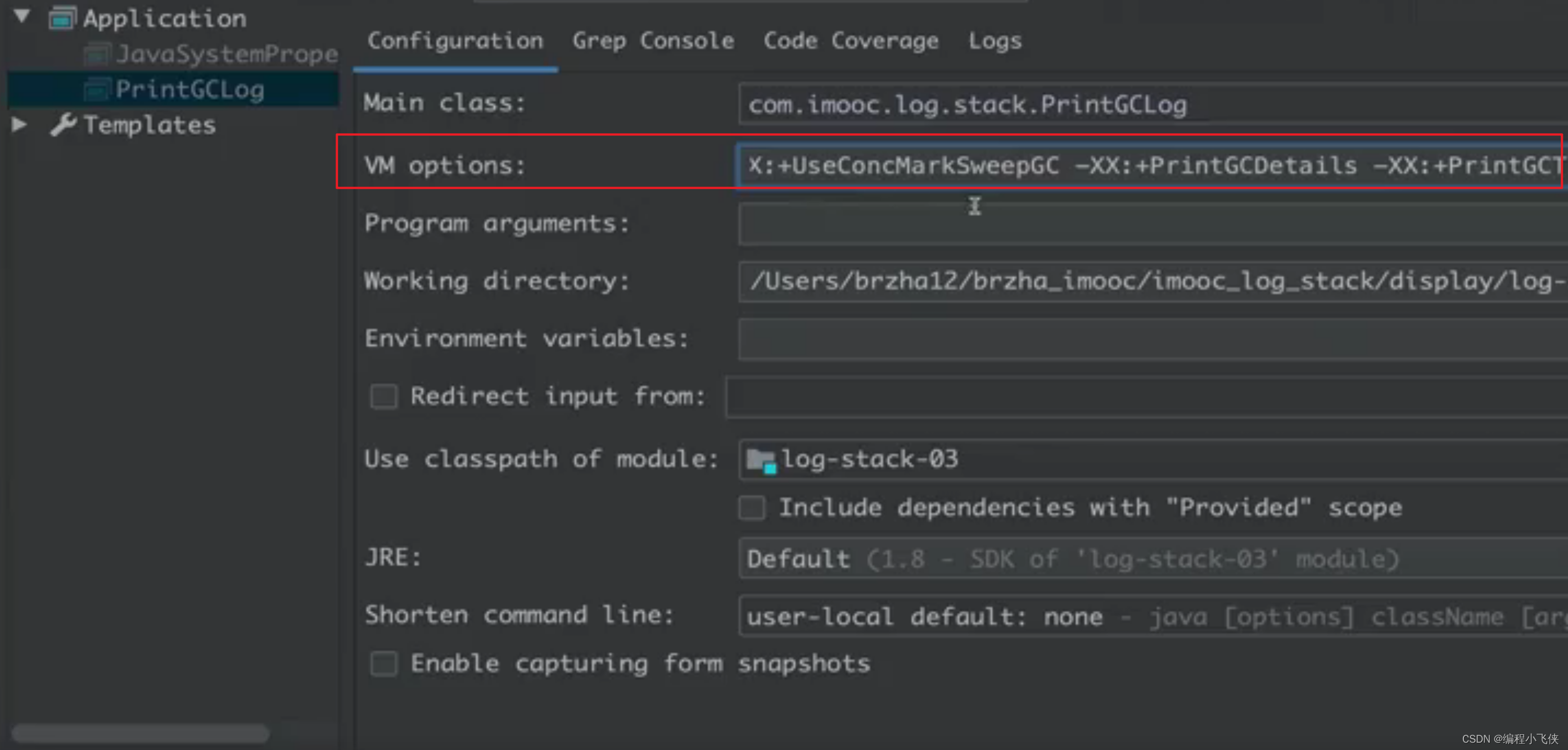
以上配置,可以得到下图的堆结构:
8.8 频繁的Minor GC 和 Major GC:
**Minor GC :**从年轻代空间(包含Eden 和 Survivor区域)回收内存,也叫做Young GC
**Major GC:**从老年代空间回收内存
**Full GC:**清理整个内存堆-既包括年轻代也包括老年代
(1)Minor GC 的影响:增加服务的相应时间
(2)为什么会出现频繁的Minor GC :Minor GC发生在年轻代,年轻代内存空间太少自然就会出现频繁的Minor GC。年轻代内存空间不够,但是代码又在频繁地new 对象。
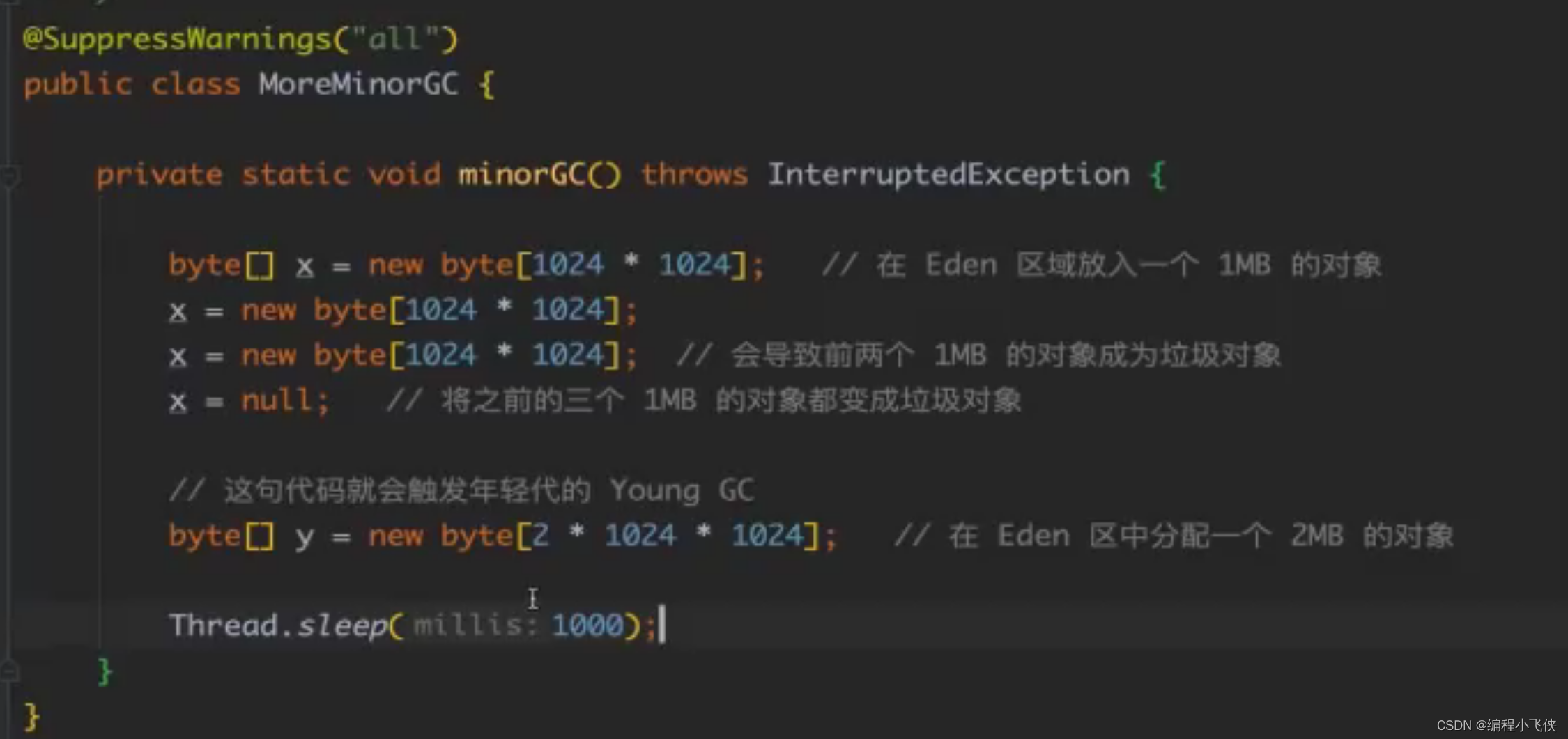
(3)扩容年轻代后,减少了Minor GC的次数,不会影响单次Minor GC时间。
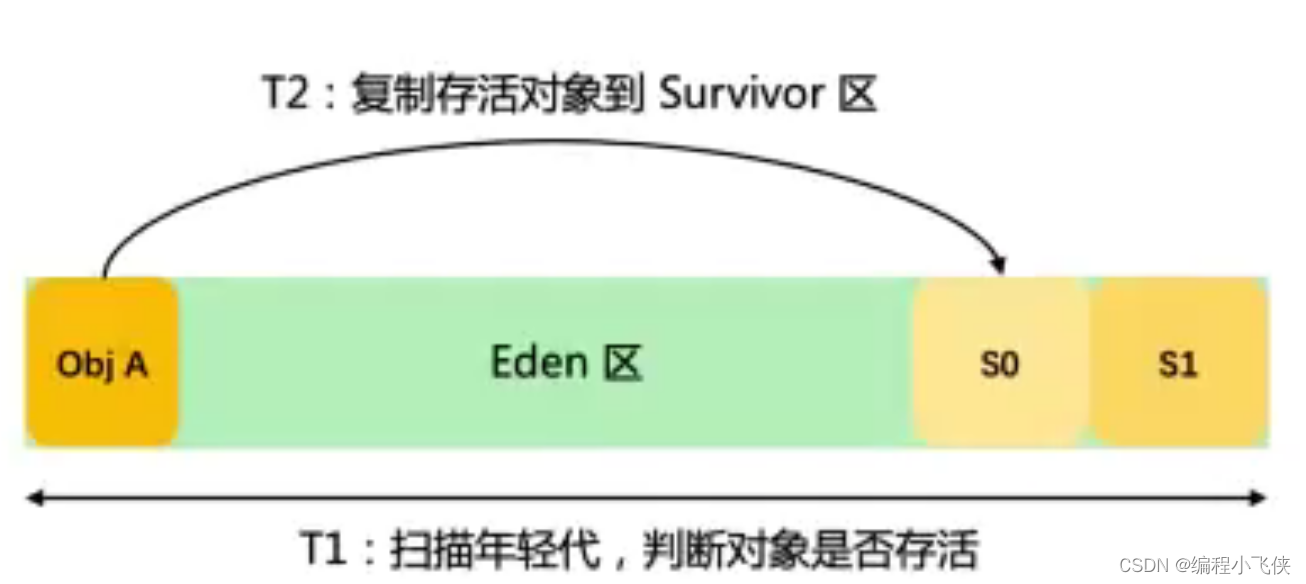
单次Minor GC时间 = T1 + T2
结论:
单次Minor GC时间更多取决于GC后存活对象的数量,而非Eden区的大小
如果应用存在大量的短期对象,应该选择较大的年轻代;如果存在相对较多的持久对象,老年代应该适当增大
在相同的内存分配率的前提下,新生代中的Eden区增加一倍,Minor GC的次数就会减少一半。
8.9 频繁的Full GC
(1)造成的影响:进程暂停响应,系统性能下降
(2)对象存活路径:

(3)什么情况会触发JVM的Full GC:
- System.gc()方法的调用
- 老年代空间不足
- 堆中分配了大对象
注意:虽然增加内存空间可以解决以上问题,但是不要盲目增加内存空间,需要考虑是否是代码问题。