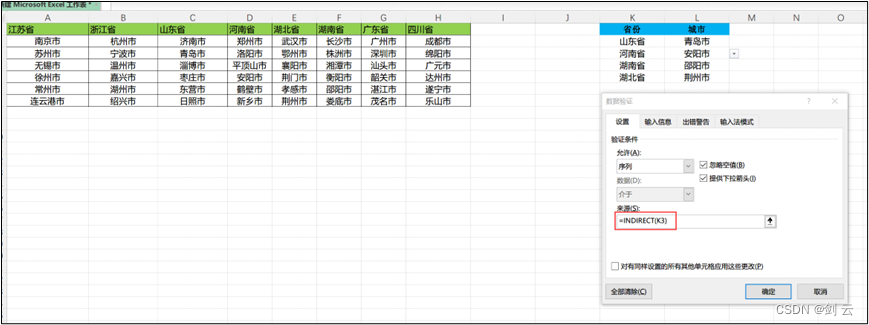
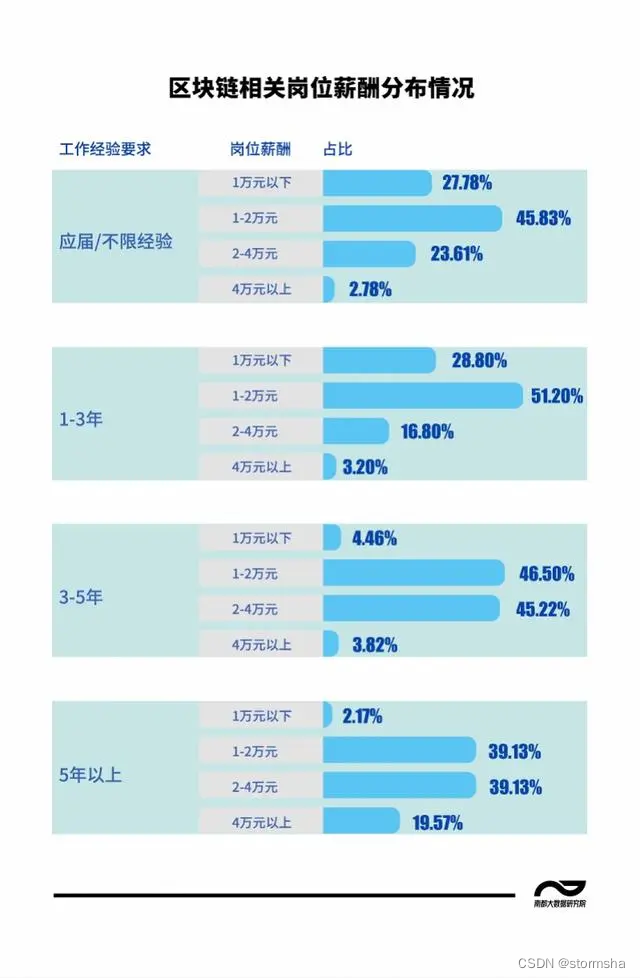
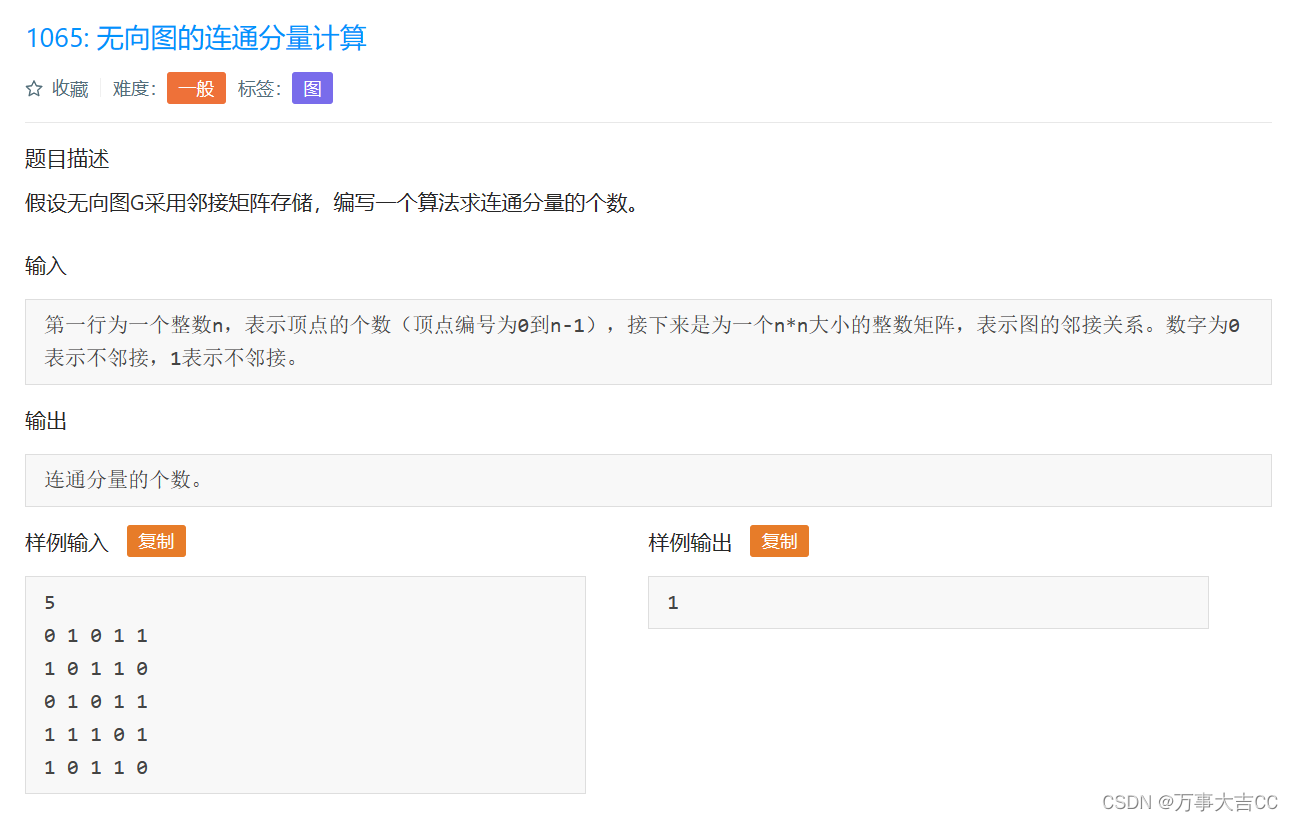
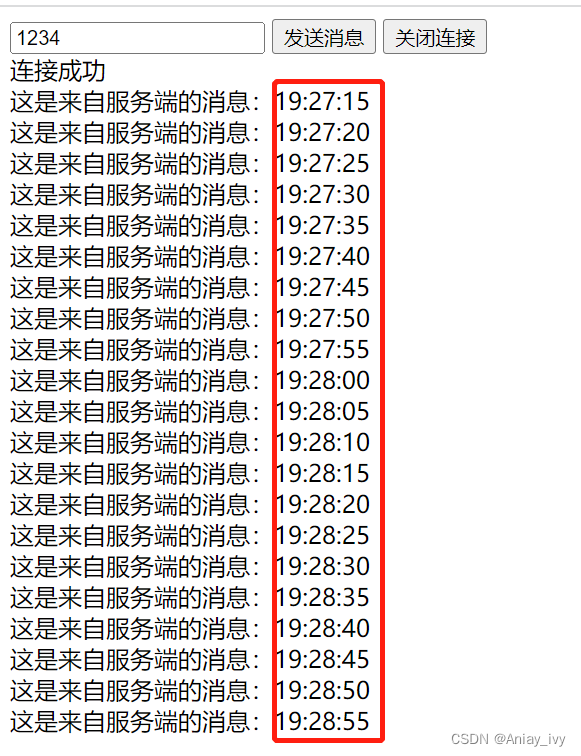
叠甲:以下文章主要是依靠我的实际编码学习中总结出来的经验之谈,求逻辑自洽,不能百分百保证正确,有错误、未定义、不合适的内容请尽情指出!
文章目录
- 1.使用协议和序列化
- 1.1.自定义协议,自定义序列化
- 1.2.自定义协议,JSON 序列化
- 2.HTTP 协议的结构
- 2.1.URI 统一资源定位符
- 2.2.HTTP 的报文基本结构
- 2.2.1.请求报文格式
- 2.2.2.响应报文格式
- 2.3.查看 HTTP 请求报文
- 2.4.查看 HTTP 响应报文
- 3.HTTP 协议的方法
- 3.1.GET 方法
- 3.1.1.使用 telnet 客户端
- 3.1.2.使用 from 标签
- 3.1.3.使用 URL 路径
- 3.1.4.使用 link 超链接
- 3.1.5.使用 src 资源链接
- 3.2.POST 方法
- 3.3.其他方法
- 3.3.1.PUT 方法
- 3.3.2.HEAD 方法
- 3.3.3.DELETE 方法
- 3.3.4.OPTIONS 方法
- 3.3.5.TRACE 方法
- 3.3.6.CONNECT 方法
- 3.3.7.PATCH 方法
- 4.HTTP 协议的状态
- 5.HTTP 协议的头部
- 5.1.Content-Type
- 5.1.1.多文件的 http 请求
- 5.1.2.多文件的 http 响应
- 5.2.Content-Length
- 5.3.Host
- 5.4.User-Agent
- 5.5.Location
- 5.6.Cookie、Set-Cookie
- 5.7.Refere
- 6.HTTP 协议的缺陷
- 6.1.HTTP 的长短链接问题
- 6.2.HTTP 的数据安全问题
- 6.1.1.数据加密和数据解密
- 6.1.2.数据摘要或数据指纹
- 6.1.3.加密+摘要=数据签名
- 6.1.4.多种加密方式的演化
- 6.1.4.1.直接对称加密
- 6.1.4.2.直接非对称加密
- 6.1.4.3.双重非对称加密
- 6.1.4.4.非对称加密+对称加密
- 6.1.4.5.非对称加密+对称加密+证书认证
- 6.1.4.5.1.数字证书的申请、签发、检验流程?
- 6.1.4.5.2.数字证书中的数字签名为何需要加密?
- 6.1.4.5.3.CA 机构的公钥怎么在浏览器查看?
- 6.1.4.5.4.怎么自己申请一份数字证书?
概要:程序员在网络程序上编写满足日常需求的网络程序基本都是在应用层编写的(包括我们之前编写的套接字编程),本节我们要有意识的站在应用层的角度上重新理解套接字编程。
1.使用协议和序列化
我们之前读写数据的时候都是按照字符串的方式来发送和接收的,那如果是具有 结构化的数据 怎么办呢?假设我们需要实现一个网络计算器,就需要先规定好两个结构体(其实从这就是制定协议的开始了):
//网络计算器中的请求和响应结构
//客户端发送下面请求结构的实例化
typedef struct Request {
int _a;
int _b;
char _op;
} Request;
Request reqt = { 10, 20, '+' };
//服务端发送下面响应结构的实例化
typedef struct Response {
int _result;
int _errodCode;
} Response;
Response reqe = { 30, 0 };
进一步可认为,协议定制的时所需要用到的字段也是协议的一部分。
规定好协议后,如果客户端和服务端规定传输数据的规格直接进行传输确实是可以(这也就是为什么读写接口不直接使用类型为 char* 的缓冲区而是使用 void* 的原因之一),但是这种做法拓展性很差,很容易失效。
而如果我们先使用结构来定义交互的信息,但按照某个规则转化为字符串,接受数据时把字符串转化为结构体。而这个过程,就是所谓 序列化(多变一, 结构数据转字符数据) 和 反序列化(一变多, 字符数据转结构数据) 的概念。
例如将 10, 20, '+' 转化为 "10 20 +",通过网络把字节流直接传输到另外一段,这种做法相当于加了一层软件层,把应用和网络进行解耦。
注意:序列化只是一种理想情况,如果制定协议的双方已经非常明确各种大小端和对齐规则,则很可能真就直接传递一个结构实例化对象(实际就是直接使用二进制传递),然后在另一端直接解析。但是这种做法通常只适合较为底层的协议,这些协议封装的很好,几乎无需担心出错的问题。
还有一种可能,由于 TCP 传输的过程是基于字节流的,无法保证传输数据时的完整性(有可能多条数据混杂为一条数据,也有可能数据发送到一半还有部分未发送),因此我们也需要解决这个问题。
简单粗暴的方法就是在协议的报头中设置一个完整数据的长度,但长度数据一旦较大,其本身也有只被发送了部分。因此较好的一种解决方案是使用 \r\n 作为报文的分割符,每次网络通信的时候,一两个特殊字符一定是会被完整发送的(底层保证了这一现象)。因此要判断一个数据是否完整,只需要使用 \r\n 包含完整数据的长度即可。接收方通过对 \r\n 的分割得到完整的长度信息,这里最好给个图解,待补充…
我们可以尝试实践一下,让抽象的概念化为具体的代码。
1.1.自定义协议,自定义序列化
稍微解释一下,实际上调用 recv()/send() 时,不是直接发送到网络中(更不是直接写到对方主机内存中),而是拷贝读写缓冲区的过程,写端写入/拷贝缓冲区后,通过网络发送,对端读取拷贝/缓冲区的过程。
补充:实际上这些
IO函数(例如recv()/send())都是拷贝函数
因此 TCP 的面向字节流特征,在对端读取的时候无法保证对端的 inbuffer 读取到一个完整请求,并且万一 inbuffer 只传递了一部分的数据交付给上层程序怎么办?如果直接把一部分的数据进行序列化操作,将会得到完全错误甚至崩溃的结果。
而中间网络发送的过程不归应用层来决定的,而是其他层来决定(例如传输控制层里规定的:什么时候发?发多少?出错了怎么办?)。您可以简单认为,所谓的 面向字节流的初步理解,就是:发送的次数和接受的次数没有任何关系,取决于操作系统的决策。操作系统认为缓冲区攒够了一定长度就会发送出去,我们无法保证每次发送都是一个完整的数据块。
因此下面自定义的协议中,就需要对协议进行一定的定制:
- 先使用一个
length来保证接受方知道一个完整数据的长度 - 而使用
\r\n作为特殊符则可以正确区分length是一个长度信息而不是内容,并且也可以保证length被完整分割
其中就可以把 length 理解为协议报头,内容为有效载荷,整体就是一个协议的实例。
# makefile(自定义协议,并且自定义序列化)
.PHONY:all
all:cal_client cal_server
cal_client:cal_client.cpp
g++ -o $@ $^ -std=c++11 -lpthread
cal_server:cal_server.cpp
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -rf cal_client cal_server log_dir
//log.hpp(自定义协议,并且自定义序列化)
/* 文件描述
Log log = Log(bool debugShow = true, //选择是否显示 DEBUG 等级的日志消息
std::string writeMode = "SCREEN", //选择日志的打印方式
std::string logFileName = "log" //选择日志的文件名称
);
log.WriteModeEnable(); //中途可以修改日志的打印方式
log.LogMessage(DEBUG | NORMAL | WARNING | ERROR | FATAL, "%s %d", __FILE__, __LINE__)); //打印日志
*/
#pragma once
#include <iostream>
#include <string>
#include <fstream>
#include <cstdio>
#include <cstdarg>
#include <ctime>
#include <pthread.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
//日志级别
#define DEBUG 0 //调试
#define NORMAL 1 //正常(或者叫 INFO)
#define WARNING 2 //警告
#define ERROR 3 //错误
#define FATAL 4 //致命
enum WriteMode
{
SCREEN = 5,
ONE_FILE,
CLASS_FILE
};
const char* gLevelMap[] = {
"DEBUG", //debug 模式
"NORMAL", //正常(或者叫 INFO)
"WARNING", //警告
"ERROR", //非致命错误
"FATAL" //严重错误
};
const std::string logdir = "log_dir";
//日志功能主要有:日志等级、发送时间、日志内容、代码行数、运行用户
class Log
{
private:
void __WriteLogToOneFile(std::string logFileName, const std::string& message)
{
std::ofstream out(logFileName, std::ios::app);
if (!out.is_open())
return;
out << message;
out.close();
}
void __WriteLogToClassFile(const int& level, const std::string& message)
{
std::string logFileName = "./";
logFileName += logdir;
logFileName += "/";
logFileName += _logFileName;
logFileName += "_";
logFileName += gLevelMap[level];
__WriteLogToOneFile(logFileName, message);
}
void _WriteLog(const int& level, const std::string& message)
{
switch (_writeMode)
{
case SCREEN: //向屏幕输出
std::cout << message;
break;
case ONE_FILE: //向单个日志文件输出
__WriteLogToOneFile("./" + logdir + "/" + _logFileName, message);
break;
case CLASS_FILE: //向多个日志文件输出
__WriteLogToClassFile(level, message);
break;
default:
std::cout << "write mode error!!!" << std::endl;
break;
}
}
public:
//构造函数,debugShow 为是否显示 debug 消息,writeMode 为日志打印模式,logFileName 为日志文件名
Log(bool debugShow = true, const WriteMode& writeMode = ONE_FILE, std::string logFileName = "log")
: _debugShow(debugShow), _writeMode(writeMode), _logFileName(logFileName)
{
mkdir(logdir.c_str(), 0775); //创建目录
}
//调整日志打印方式
void WriteModeEnable(const WriteMode& mode)
{
_writeMode = mode;
}
//拼接日志消息并且输出
void LogMessage(const int& level, const char* format, ...)
{
//1.若不是 debug 模式,且 level == DEBUG 则不做任何事情
if (_debugShow == false && level == DEBUG)
return;
//2.收集日志标准部分信息
char stdBuffer[1024];
time_t timestamp = time(nullptr); //获得时间戳
struct tm* local_time = localtime(×tamp); //将时间戳转换为本地时间
snprintf(stdBuffer, sizeof stdBuffer, "[%s][pid:%s][%d-%d-%d %d:%d:%d]",
gLevelMap[level],
std::to_string(getpid()).c_str(),
local_time->tm_year + 1900, local_time->tm_mon + 1, local_time->tm_mday,
local_time->tm_hour, local_time->tm_min, local_time->tm_sec
);
//3.收集日志自定义部分信息
char logBuffer[1024];
va_list args; //声明可变参数列表,实际时一个 char* 类型
va_start(args, format); //初始化可变参数列表
vsnprintf(logBuffer, sizeof logBuffer, format, args); //int vsnprintf(char *str, size_t size, const char *format, va_list ap); 是一个可变参数函数,将格式化后的字符串输出到缓冲区中。类似带 v 开头的可变参数函数有很多
va_end(args); //清理可变参数列表,类似 close() 和 delete
//4.拼接为一个完整的消息
std::string message;
message += "--> 标准日志:"; message += stdBuffer;
message += "\t 用户日志:"; message += logBuffer;
message += "\n";
//5.打印日志消息
_WriteLog(level, message);
}
private:
bool _debugShow;
WriteMode _writeMode;
std::string _logFileName;
};
//sock.hpp(自定义协议,并且自定义序列化)
/* 文件描述
主要是对套接字编程的常见接口做封装,是一个关于套接字的工具包
*/
#pragma once
#include <memory>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include "log.hpp"
class ThreadData
{
public:
int _sock;
std::string _ip;
uint16_t _port;
};
class Sock
{
private:
const static int g_backlog = 20; //一般不会太大,也不会太小
public:
//空的构造函数
Sock() {}
//创建监听套接字
int _Socket()
{
int listenSock = socket(AF_INET, SOCK_STREAM, 0);
if (listenSock < 0)
{
_log.LogMessage(FATAL, "socket() error %s %d", __FILE__, __LINE__);
exit(1);
}
_log.LogMessage(NORMAL, "socket() success %s %d", __FILE__, __LINE__);
return listenSock;
}
//绑定监听套接字
void _Bind(int listenSock, uint16_t port, std::string ip = "0.0.0.0")
{
struct sockaddr_in local;
memset(&local, 0, sizeof local);
local.sin_family = AF_INET;
local.sin_port = htons(port);
inet_pton(AF_INET, ip.c_str(), &local.sin_addr);
if (bind(listenSock, (struct sockaddr*)&local, sizeof(local)) < 0)
{
_log.LogMessage(FATAL, "bind() error %s %d", __FILE__, __LINE__);
exit(2);
}
_log.LogMessage(NORMAL, "bind() success %s %d", __FILE__, __LINE__);
}
//置套接字监听状态
void _Listen(int listenSock)
{
if (listen(listenSock, g_backlog) < 0)
{
_log.LogMessage(FATAL, "listen() error %s %d", __FILE__, __LINE__);
exit(3);
}
_log.LogMessage(NORMAL, "listen() success %s %d", __FILE__, __LINE__);
}
//服务端等待连接后,返回服务套接字(参数还带有服务端的信息)
int _Accept(int listenSock, std::string* ip, uint16_t* port)
{
struct sockaddr_in src;
socklen_t len = sizeof(src);
int serviceSock = accept(listenSock, (struct sockaddr*)&src, &len);
if (serviceSock < 0)
{
_log.LogMessage(FATAL, "accept() error %s %d", __FILE__, __LINE__);
return -1;
}
_log.LogMessage(NORMAL, "accept() success %s %d", __FILE__, __LINE__);
*port = ntohs(src.sin_port);
*ip = inet_ntoa(src.sin_addr);
return serviceSock;
}
//客户端主动连接服务端
bool _Connect(int sock, const std::string& server_ip, const uint16_t& server_port)
{
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(server_port);
server.sin_addr.s_addr = inet_addr(server_ip.c_str());
if (connect(sock, (struct sockaddr*)&server, sizeof(server)) == 0)
{
_log.LogMessage(NORMAL, "accept() success %s %d", __FILE__, __LINE__);
return true;
}
_log.LogMessage(FATAL, "connect() error %s %d", __FILE__, __LINE__);
return false;
}
private:
Log _log;
};
//tcp_server.hpp(自定义协议,并且自定义序列化)
/* 文件描述
主要是对 sock.hpp 的使用,构建一个可用的 TCP 服务端
*/
#pragma once
#include <functional>
#include <vector>
#include <pthread.h>
#include "sock.hpp"
#include "log.hpp"
class TcpServer
{
private:
class ThreadData
{
public:
ThreadData(int serviceSock, TcpServer* server) : _serviceSock(serviceSock), _server(server) {}
~ThreadData() {}
public:
int _serviceSock;
TcpServer* _server;
};
using func_t = std::function<void(int)>;
private:
void __Excute(int serviceSock)
{
for (auto& func : _funcs)
{
func(serviceSock); //执行任务列表中的所有任务
}
}
static void* _ThreadRoutine(void* args)
{
pthread_detach(pthread_self()); //线程分离
ThreadData* td = static_cast<ThreadData*>(args); //解包参数
td->_server->__Excute(td->_serviceSock); //执行所有绑定的方法
close(td->_serviceSock);
delete td;
return nullptr;
}
public:
//利用套接字工具包初始化套接字
TcpServer(const uint16_t& port, const std::string& ip = "0.0.0.0")
{
_listensock = _sock._Socket();
_sock._Bind(_listensock, port, ip);
_sock._Listen(_listensock);
}
//给服务器绑定的一些 void(int) 类型的服务(PS:请在服务器启动之前绑定,该方法没有保证线程安全)
void BindService(func_t func)
{
_funcs.push_back(func);
}
//启动 tcp 服务器
void Start()
{
while(true) //不断获取新的服务套接字
{
std::string client_ip;
uint16_t client_port;
int serviceSock = _sock._Accept(_listensock, &client_ip, &client_port);
if (serviceSock == -1)
{
continue;
}
else
{
_log.LogMessage(NORMAL, "creat new link success, sock %d, %s %d", serviceSock, __FILE__, __LINE__);
//创建子线程,让子线程完成任务,一个线程分配一个服务套接字做服务
pthread_t tid;
ThreadData* td = new ThreadData(serviceSock, this);
pthread_create(&tid, nullptr, _ThreadRoutine, td); //注意子线程内部做了线程分离,也自己做了 td 制作的释放
}
}
}
~TcpServer()
{
if (_listensock >= 0)
close(_listensock);
}
private:
Sock _sock; //套接字工具包
int _listensock; //监听套接字
std::vector<func_t> _funcs; //任务列表
Log _log; //日志对象
};
//protocol.hpp(自定义协议,并且自定义序列化)
/* 文件描述
主要是对协议的定制,该协议是自定义的,是对协议的模拟
其中约定就体现在:
(1) 结构化的数据
(2) 序列和反序列化的解析顺序
(3) 运算结果的状态码
(4) 报头的封装规定
*/
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include "log.hpp"
#define SPACE " "
#define SPACE_LEN strlen(SPACE) //这么做是为了可拓展
#define SEP "\r\n"
#define SEP_LEN strlen(SEP) //这么做是为了可拓展
//请求中有效载荷的“序列化”和“反序列化”(客户端序列化请求,服务端反序列化请求)
class Request
{
public:
Request() {}
Request(int x, int y, char op) : _x(x), _y(y), _op(op) {}
//序列化为 "_x _op _y"
std::string Serialize()
{
std::string str;
str += std::to_string(_x);
str += SPACE;
str += _op;
str += SPACE;
str += std::to_string(_y);
return str;
}
//反序列化为 { int _x; int _y; char _op; }
bool Deserialize(const std::string& str)
{
std::size_t left = str.find(SPACE);
if (left == std::string::npos)
return false;
std::size_t right = str.rfind(SPACE);
if (right == std::string::npos)
return false;
_x = atoi(str.substr(0, left).c_str());
_op = str[left + SPACE_LEN];
_y = atoi(str.substr(right + SPACE_LEN).c_str());
return true;
}
public:
int _x; //操作数
int _y; //操作数
char _op; //操作符
};
//响应中有效载荷的“序列化”和“反序列化”(服务端序列化响应,客户端反序列化请求)
class Response
{
public:
Response() {}
Response(int result, int code) : _result(result), _code(code) {}
//序列化为 "_code _result"
std::string Serialize()
{
std::string str;
str += std::to_string(_code);
str += SPACE;
str += std::to_string(_result);
return str;
}
//反序列化为 { int _result; int _code; }
bool Deserialize(const std::string& str)
{
std::size_t pos = str.find(SPACE);
if (pos == std::string::npos)
return false;
_code = atoi(str.substr(0, pos).c_str());
_result = atoi(str.substr(pos + SPACE_LEN).c_str());
return true;
}
public:
int _result; //计算结果
int _code; //计算状态码
};
//读取数据报
bool Recv(int sock, std::string* out)
{
Log log;
char buffer[1024] = { 0 };
ssize_t str = recv(sock, buffer, sizeof(buffer) - 1, 0);
if (str > 0)
{
*out += buffer;
return true;
}
else if (str == 0) //对端关闭了
{
log.LogMessage(WARNING, "clienr quit... %s %d", __FILE__, __LINE__);
return false;
}
else
{
log.LogMessage(FATAL, "recv() error %s %d", __FILE__, __LINE__);
return false;
}
}
//发送数据报
void Send(int sock, const std::string str)
{
send(sock, str.c_str(), str.size(), 0);
}
//提取完整有效载荷
std::string Decode(std::string& buffer)
{
//length\r\n123 + 456\r\n
//长度信息还没有读取完毕,返回空串继续读取,直到下次一次能遇到 '\r\n' 标识符
std::size_t pos = buffer.find(SEP);
if (pos == std::string::npos)
{
return "";
}
//走到这里说明一定可以获取到长度,若剩余的大小 surplus >= 报头的长度 length,说明足够返回至少一个完整数据报
int length = atoi(buffer.substr(0, pos).c_str());
int surplus = buffer.size() - pos - SEP_LEN - SEP_LEN; //除去标志符后剩余的字符长度
if (surplus < length) //虽然获取到了长度信息,但是数据还不够凑成一个完整的数据报
{
return "";
}
else //surplus >= 报头的长度 length,则说明至少存在一个完整的数据报,可以进行提取并且返回
{
buffer.erase(0, pos + SEP_LEN); //移走前面的长度信息和标识符(虽然暴力,不过我们的重点不在效率)
std::string data = buffer.substr(0, length); //拷贝需要的有效载荷信息
buffer.erase(0, length + SEP_LEN); //移走已经被拷贝的数据和后面的标识符
return data;
}
}
//添加报头和标志符
std::string Encode(const std::string& str)
{
std::string length = std::to_string(str.size());
std::string new_package = length;
new_package += SEP; //这个 SEP 标识符是为了分割长度信息和有效载荷,区别两者
new_package += str;
new_package += SEP; //这个 SEP 标识符更多是为了打印时方便一点
return new_package;
}
//daemon.hpp(自定义协议,并且自定义序列化)
#pragma once
#include <iostream>
#include <unistd.h>
#include <signal.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
//调用下述函数时,就会
void MyDaemon()
{
//1.忽略信号,避免服务端因为某些原因挂掉
signal(SIGPIPE, SIG_IGN); //防止运行过程中出现非法写入的问题(例如服务端写到一半时,客户端因为异常而被关闭),避免因为客户端出现问题,导致服务端跟着挂掉
signal(SIGCHLD, SIG_IGN); //不向父进程提醒,因此不回收子进程
//2.避免自己成为组长
if (fork() > 0)
{
exit(0); //父进程直接正常终止
}
//下面是子进程的部分
//3.调用 setsid()
setsid(); //成为新的会话
//4.标准输出、标准输入、标准错误的重定向(尤其是不能在屏幕上进行日志打印,一旦打印就有可能暂停和中止)
int devNnll = open("/dev/null", O_RDONLY | O_WRONLY); //在 Linux 中基本都有 /dev/null,其特点就是写入任何数据都会清空,也无法读取任何数据(文件黑洞)
if (devNnll > 0)
{
dup2(devNnll, 0); //oldfd 复制-> newfd
dup2(devNnll, 1);
dup2(devNnll, 2);
close(devNnll);
}
}
//cal_server.cpp(自定义协议,并且自定义序列化)
#include <signal.h>
#include <cstdio>
#include "tcp_server.hpp"
#include "protocol.hpp"
#include "daemon.hpp"
//使用手册
static void Usage(std::string proc)
{
std::cout << "\nUsage: " << proc << " [ip] [port]\n" << std::endl;
}
//线程的调用方法
static Response _CalculatorHelp(const Request& req)
{
Response resp(0, 0);
switch (req._op)
{
case '+':
resp._result = req._x + req._y;
break;
case '-':
resp._result = req._x - req._y;
break;
case '*':
resp._result = req._x * req._y;
break;
case '/':
if (req._y == 0)
resp._code = 1;
else
resp._result = req._x / req._y;
break;
case '%':
if (req._y == 0)
resp._code = 2;
else
resp._result = req._x % req._y;
break;
default:
resp._code = 3;
break;
}
return resp;
}
void Calculator(int sock)
{
std::string inbuffer;
while (true)
{
//1.读取从客户端发送的、序列化后的请求
bool result = Recv(sock, &inbuffer);
if (!result) //通过这里的 if 语句也只能证明读取成功,不能保证数据的完整性
break;
std::cout << "inbuffer:" << inbuffer << std::endl; //[debug]
//2.保证得到完整的响应数据
std::string package = Decode(inbuffer); //(1)返回空的时候说明内部没有有效数据或者报文不完整
if (package.empty())
{
continue; //继续循环读取,直到 package 不为空
}
else //(2)否者就是可以使用的,已经有完整的数据报了
{
std::cout << "Decode:inbuffer:" << inbuffer << std::endl; //[[debug]]
std::cout << "package:" << package << std::endl; //[debug]
//3.反序列化请求,拿数据去计算后返回给请求结构体对象
Request req;
req.Deserialize(package);
Response resp;
resp = _CalculatorHelp(req); //将反序列化的结果拿去计算
//4.序列化响应,并且加上报头发送给客户端
std::string respString = resp.Serialize(); //把响应结果序列化
std::cout << "respString:" << respString << std::endl; //[debug]
respString = Encode(respString);
std::cout << "Encode:respString:" << respString << std::endl; //[debug]
Send(sock, respString); //写回响应结果
//TODU:但是这个发送也有一些问题,这里暂时不提,后续讲多路转接的时候再来修改
}
}
}
int main(int argc, char* argv[]) //使用 ./cal_server 8080 来启动服务端
{
if (argc != 2)
{
Usage(argv[0]);
exit(4);
}
MyDaemon(); //调用后,父进程的部分退出,内部创建的子进程变成守护进程,后续可以使用 ps -axj | grep cal_server 来查看(可以观察到 PPID:1 ,这说明守护进程就是一种孤儿进程)
printf("dimou");
//以下步骤都开始由子进程进行操作,注意日志消息需要写入到文件中,而不能直接输出(为方便修改,我直接把之前写的日志类构造函数中的 writeMode 默认为 ONE_FILE),并且需要把所有的标准 IO 输出都会被重定向到 /dev/null 中
std::unique_ptr<TcpServer> server(new TcpServer(atoi(argv[1])));
server->BindService(Calculator); //在任务列表中绑定一些任务
server->Start(); //启动服务器
return 0;
}
//cal_client.cpp(自定义协议,并且自定义序列化)
#include <iostream>
#include <string>
#include <unistd.h>
#include "log.hpp"
#include "sock.hpp"
#include "protocol.hpp"
//使用手册
static void Usage(std::string proc)
{
std::cout << "\nUsage: " << proc << " [ip] [port]\n" << std::endl;
}
int main(int argc, char const* argv[])
{
if (argc != 3)
{
Usage(argv[0]);
exit(5);
}
Log log = Log();
Sock sock; //套接字工具包
std::string server_ip = argv[1];
uint16_t server_port = atoi(argv[2]);
int sockfd = sock._Socket();
sock._Connect(sockfd, server_ip, server_port); //连接服务端
bool quit = false;
while (!quit)
{
//1.获取需求
std::cout << "Please Enter x, y, op: ";
int x = 0;
int y = 0;
char op = 0;
std::cin >> x >> y >> op;
//2.制作请求并且进行序列化
Request req(x, y, op);
std::string result = req.Serialize();
//3.添加报头和标志位再发送请求
result = Encode(result);
Send(sockfd, result);
//4.读取响应并做处理
while (true)
{
std::string buffer;
bool res = Recv(sockfd, &buffer);
if (!res) //通过这个 if 语句只能说明读取没有出错
{
quit = true;
break;
}
std::string package = Decode(buffer); //尝试获取完整的数据包
if (package.empty())
{
continue; //继续读取,直到读取到一个完整的数据包
}
//5.把完整的响应做反序列化
Response resp;
resp.Deserialize(package);
//6.检测结果是否出现异常
std::string err;
switch (resp._code)
{
case 0:
//让 err 继续保持空即可
break;
case 1:
err = "/0 error";
break;
case 2:
err = "%0 error";
break;
case 3:
err = "other error";
break;
default:
break;
}
if (err.empty()) //为空
{
std::cout << "code: " << resp._code << " - result:" << resp._result << '\n';
}
else
{
std::cerr << err << std::endl;
}
break;
}
}
close(sockfd); //客户端结束后最好还是关闭套接字标识符
return 0;
}
1.2.自定义协议,JSON 序列化
可以使用 JSON 来帮助我们进行序列化和反序列化的工作,可以使用 sudo yum install jsoncpp-devel 下载关于 JSON 的第三方库。
注意:由于是第三方库,使用
gcc时需要带上参数。
# makefile(自定义协议,改为 JSON 序列化)
.PHONY:all
all:cal_client cal_server
cal_client:cal_client.cpp
g++ -o $@ $^ -std=c++11 -lpthread -ljsoncpp
cal_server:cal_server.cpp
g++ -o $@ $^ -std=c++11 -lpthread -ljsoncpp
.PHONY:clean
clean:
rm -rf cal_client cal_server log_dir
//protocol.hpp(自定义协议,改为 JSON 序列化)
/* 文件描述
主要是对协议的定制,该协议是自定义的,是对协议的模拟
其中约定就体现在:
(1) 结构化的数据
(2) 序列和反序列化的解析顺序
(3) 运算结果的状态码
(4) 报头的封装规定
*/
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <jsoncpp/json/json.h>
#include "log.hpp"
#define SPACE " "
#define SPACE_LEN strlen(SPACE) //这么做是为了可拓展
#define SEP "\r\n"
#define SEP_LEN strlen(SEP) //这么做是为了可拓展
//请求中有效载荷的“序列化”和“反序列化”(客户端序列化请求,服务端反序列化请求)
class Request
{
public:
Request() {}
Request(int x, int y, char op) : _x(x), _y(y), _op(op) {}
//序列化为 JSON 字符串
std::string Serialize()
{
Json::Value root;
root["x"] = _x;
root["y"] = _y;
root["op"] = _op;
Json::FastWriter fwriter;
return fwriter.write(root);
}
//反序列化为 JSON 数据
bool Deserialize(const std::string& str)
{
Json::Value root;
Json::Reader reader;
reader.parse(str, root); //第二个是输出型参数
_x = root["x"].asInt();
_y = root["y"].asInt();
_op = root["op"].asInt();
}
public:
int _x; //操作数
int _y; //操作数
char _op; //操作符
};
//响应中有效载荷的“序列化”和“反序列化”(服务端序列化响应,客户端反序列化请求)
class Response
{
public:
Response() {}
Response(int result, int code) : _result(result), _code(code) {}
//序列化为 JSON 字符串
std::string Serialize()
{
Json::Value root;
root["result"] = _result;
root["code"] = _code;
Json::FastWriter fwriter;
return fwriter.write(root);
}
//反序列化为 JSON 数据
bool Deserialize(const std::string& str)
{
Json::Value root;
Json::Reader reader;
reader.parse(str, root); //第二个是输出型参数
_result = root["result"].asInt();
_code = root["code"].asInt();
return true;
}
public:
int _result; //计算结果
int _code; //计算状态码
};
//读取数据报
bool Recv(int sock, std::string* out)
{
Log log;
char buffer[1024] = { 0 };
ssize_t str = recv(sock, buffer, sizeof(buffer) - 1, 0);
if (str > 0)
{
*out += buffer;
return true;
}
else if (str == 0) //对端关闭了
{
log.LogMessage(WARNING, "clienr quit... %s %d", __FILE__, __LINE__);
return false;
}
else
{
log.LogMessage(FATAL, "recv() error %s %d", __FILE__, __LINE__);
return false;
}
}
//发送数据报
void Send(int sock, const std::string str)
{
send(sock, str.c_str(), str.size(), 0);
}
//提取完整有效载荷
std::string Decode(std::string& buffer)
{
//length\r\n123 + 456\r\n
//长度信息还没有读取完毕,返回空串继续读取,直到下次一次能遇到 '\r\n' 标识符
std::size_t pos = buffer.find(SEP);
if (pos == std::string::npos)
{
return "";
}
//走到这里说明一定可以获取到长度,若剩余的大小 surplus >= 报头的长度 length,说明足够返回至少一个完整数据报
int length = atoi(buffer.substr(0, pos).c_str());
int surplus = buffer.size() - pos - SEP_LEN - SEP_LEN; //除去标志符后剩余的字符长度
if (surplus < length) //虽然获取到了长度信息,但是数据还不够凑成一个完整的数据报
{
return "";
}
else //surplus >= 报头的长度 length,则说明至少存在一个完整的数据报,可以进行提取并且返回
{
buffer.erase(0, pos + SEP_LEN); //移走前面的长度信息和标识符(虽然暴力,不过我们的重点不在效率)
std::string data = buffer.substr(0, length); //拷贝需要的有效载荷信息
buffer.erase(0, length + SEP_LEN); //移走已经被拷贝的数据和后面的标识符
return data;
}
}
//添加报头和标志符
std::string Encode(const std::string& str)
{
std::string length = std::to_string(str.size());
std::string new_package = length;
new_package += SEP; //这个 SEP 标识符是为了分割长度信息和有效载荷,区别两者
new_package += str;
new_package += SEP; //这个 SEP 标识符更多是为了打印时方便一点
return new_package;
}
而其他的代码不变即可,归功于我们的隔离,我们可以轻易修改序列化的方案。
虽然我们完全可以自己继续完善我们自定义的协议,但是在应用层早就有更加统一的标准,这个标准协议之一就是 HTTP 协议。
注意:
JSON的作用主要有两个,一个是方便序列化和反序列化,另一个是方便组织数据,这里发挥了第一种作用。
2.HTTP 协议的结构
所谓应用层,大部分的工作都和文本处理有关,如果我们学习 HTTP 就意味着一定有很多的文本分析、字段填充、协议处理。
HTTP 协议本身具有四个特性:
- 较易用(格式简单,编写容易)
- 无链接(底层实现虽然可能是
TCP这种由链接的,但是这不是HTTP该关心的) - 无状态(指不会记录用户曾经访问的历史记录)
- 不安全(传输过程中没有涉及到加密,数据容易泄露)
补充:
HTTP也叫 超文本协议,这里的“超”在不仅仅可以传输文本文件,还可以是其他图片、视频等文件…
2.1.URI 统一资源定位符
我们先来认识 URI 的结构和相关概念。

上述示例图就可以帮助您理解 协议、域名(可以等价理解为IP地址)、端口、路径和文件、参数、锚 等概念。
- 协议为
http代表使用http协议 - 域名会被
DNS做解析,最终变成IP地址,这个工作由浏览器完成。还可以被继续细分为登录信息@服务器地址 - 而服务端开发的端口号一般对于客户端程序都是已知的,因此很多情况下都可以默认不写,因此重要的端口号通常都不会随意修改
- 资源路径(或叫
Web根目录)一般代表资源请求时在服务器上的路径,而该路径不是一定在服务器的根目录开始,由服务器决定根的位置(后面解释) - 而后面的参数和锚就可以向服务器传递参数或者对网页中的内容进行定位,一般通过前端页面表单或者客户端发送
补充:如果
URI中涉及到保留的特殊字符,则需要写成对于的特殊字符代码(urlencode/urldecode操作),这个过程通常由客户端完成。服务器收到时再进行转回(将字符的编码转为16进制,从左到右取4位(不足按4位处理),每两位刚好一字节,前面加上%,编码为%XY格式,这里给出一些在线工具)。
警告:为了区分资源路径和
URL,我后续涉及到的网络代码中,谈资源路径会使用path,而谈浏览器资源定位符会使用URL,有些程序会把这两个单词混淆,不易您阅读…
只要 URL 设置的好,就可以使用浏览器这种特殊的客户端程序,通过 URL 转化成的 HTTP 请求发送给服务器,进而访问服务器上的资源(例如 .html 文件,也就是一个网站页面文件),因此资源在没有被获取之前,一定都在服务器上。
而对于 Linux 来说,所谓资源也可以理解为文件,服务端进程先把资源加载到自己的上下文中,在通过一系列的套接字编程发送给客户端进程中(发送文件就相当于先在服务端读取文件的文本内容,然后发送响应给客户端)。
因此 URI 也就叫 统一资源定位符,通过这种方式找到资源的网络,就被称为 万维网。
补充:关于
URI更加详细的知识可以看 MDN 的文章,上面的URL图解就是来源于这里。
2.2.HTTP 的报文基本结构
浏览器有了 URL,就可以把 URL 中的信息进一步使用 http 协议进行请求封装。而 http 协议是应用层的协议,底层通常采用 TCP 通信,在通信之前就以及做好三次握手和四次挥手。
另外,我后续讲解的协议版本主要是 HTTP1.0(多条链接多条请求, 短链接),现在常用的版本是 HTTP/1.1(一条链接多条请求, 长链接) 和 HTTP/2.0。
2.2.1.请求报文格式
http 协议是基于行的文本协议,可以把整个请求文本看作如下结构:
| 行 | 内容 |
|---|---|
| 请求行 | 请求方法 请求路径 协议版本\r\n |
| 请求头部 | 多个 "key": value\r\n 行构成(内部还可能包含本次请求的属性,可以接受的编码格式、客户端信息、长链接还是短链接、正文长度…) |
| 空行 | \r\n |
| 请求正文 | 可以省略,之后提及 |
吐槽:这里有个细节,
HTTP协议的序列化和反序列是依靠\r\n来进行的,本身没有依靠类似JSON等第三方库,因此我们可以认为制定协议的过程中,免不了制定序列化规则…
-
请求报头
(1)请求方法:请求方法对于浏览器客户端来说,通常默认填写为
GET,请求路径填写而我们之前说的url中的path也就是资源路径,协议版本可以由浏览器进行自动填充(2)请求头部:我后面进行补充
(3)空行:仅仅是为了分割
http报头部分和http正文部分 -
请求正文
这里先暂时略过,您大概知道请求也可以填充请求正文的部分向服务端发送数据就行,并且关于请求正文的长度在请求头部中有设置。虽然
http的序列化和反序列化没有使用JSON,但是JSON还有一个优点就是方便组织数据,因此我们可以把序列化后的JSON数据作为请求正文传递给服务端。
补充:我们还可以把这个结构看作线性结构,将所有行拼接为一行来看,转化为一串字符串后就会发送给服务端。
2.2.2.响应报文格式
| 行 | 内容 |
|---|---|
| 状态行 | 协议版本 状态码 状态码描述\r\n |
| 响应头部 | 多个 "key": value\r\n 行构成 |
| 空行 | \r\n |
| 响应正文 | 可以省略,之后提及(也就是平时在网页上看到的资源) |
-
响应报头
(1)状态行:服务器根据客户端的请求做分析后,得到相应的结果和状态码,其中状态码就会在这里被设置,状态码描述也在这里设置,而协议版本哪怕是不填充,有些较为现代的浏览器也可以进行自动填充
(2)响应头部:我后面进行补充
(3)空行:仅仅是为了分割
http报头部分和http正文部分 -
请求正文
这里先暂时略过,您大概知道请求也可以填充请求正文的部分向客户端发送数据就行,并且关于响应正文的长度在响应头部中有设置。如果客户端发送的是
JSON数据,这里也可以选择使用JSON来组织好分析结果再作为响应正文发送给客户端,也是JSON的第二个作用。
补充:我们也可以把这个结构看作线性结构,将所有行拼接为一行来看,转化为一串字符串后就会发送给客户端。
补充:为什么请求和响应需要有重复的协议版本信息呢?这是在做版本交互,可以让特定版本的(比如较低版本协议的客户端)客户端看到该看到的信息,而不会出现不兼容的问题。
2.3.查看 HTTP 请求报文
而在使用关于 http 的相关系统调用之前,我们先来查看一下浏览器发送的 http 请求报头信息我们是否能够使用服务器接收到呢?
# makefile
http_server:http_server.cpp
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -rf http_server
//log.hpp
/* 文件描述
Log log = Log(bool debugShow = true, //选择是否显示 DEBUG 等级的日志消息
std::string writeMode = "SCREEN", //选择日志的打印方式
std::string logFileName = "log" //选择日志的文件名称
);
log.WriteModeEnable(); //中途可以修改日志的打印方式
log.LogMessage(DEBUG | NORMAL | WARNING | ERROR | FATAL, "%s %d", __FILE__, __LINE__)); //打印日志
*/
#pragma once
#include <iostream>
#include <string>
#include <fstream>
#include <cstdio>
#include <cstdarg>
#include <ctime>
#include <pthread.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
//日志级别
#define DEBUG 0 //调试
#define NORMAL 1 //正常(或者叫 INFO)
#define WARNING 2 //警告
#define ERROR 3 //错误
#define FATAL 4 //致命
enum WriteMode
{
SCREEN = 5,
ONE_FILE,
CLASS_FILE
};
const char* gLevelMap[] = {
"DEBUG", //debug 模式
"NORMAL", //正常(或者叫 INFO)
"WARNING", //警告
"ERROR", //非致命错误
"FATAL" //严重错误
};
const std::string logdir = "log_dir";
//日志功能主要有:日志等级、发送时间、日志内容、代码行数、运行用户
class Log
{
private:
void __WriteLogToOneFile(std::string logFileName, const std::string& message)
{
std::ofstream out(logFileName, std::ios::app);
if (!out.is_open())
return;
out << message;
out.close();
}
void __WriteLogToClassFile(const int& level, const std::string& message)
{
std::string logFileName = "./";
logFileName += logdir;
logFileName += "/";
logFileName += _logFileName;
logFileName += "_";
logFileName += gLevelMap[level];
__WriteLogToOneFile(logFileName, message);
}
void _WriteLog(const int& level, const std::string& message)
{
switch (_writeMode)
{
case SCREEN: //向屏幕输出
std::cout << message;
break;
case ONE_FILE: //向单个日志文件输出
__WriteLogToOneFile("./" + logdir + "/" + _logFileName, message);
break;
case CLASS_FILE: //向多个日志文件输出
__WriteLogToClassFile(level, message);
break;
default:
std::cout << "write mode error!!!" << std::endl;
break;
}
}
public:
//构造函数,debugShow 为是否显示 debug 消息,writeMode 为日志打印模式,logFileName 为日志文件名
Log(bool debugShow = true, const WriteMode& writeMode = SCREEN, std::string logFileName = "log")
: _debugShow(debugShow), _writeMode(writeMode), _logFileName(logFileName)
{
mkdir(logdir.c_str(), 0775); //创建目录
}
//调整日志打印方式
void WriteModeEnable(const WriteMode& mode)
{
_writeMode = mode;
}
//拼接日志消息并且输出
void LogMessage(const int& level, const char* format, ...)
{
//1.若不是 debug 模式,且 level == DEBUG 则不做任何事情
if (_debugShow == false && level == DEBUG)
return;
//2.收集日志标准部分信息
char stdBuffer[1024];
time_t timestamp = time(nullptr); //获得时间戳
struct tm* local_time = localtime(×tamp); //将时间戳转换为本地时间
snprintf(stdBuffer, sizeof stdBuffer, "[%s][pid:%s][%d-%d-%d %d:%d:%d]",
gLevelMap[level],
std::to_string(getpid()).c_str(),
local_time->tm_year + 1900, local_time->tm_mon + 1, local_time->tm_mday,
local_time->tm_hour, local_time->tm_min, local_time->tm_sec
);
//3.收集日志自定义部分信息
char logBuffer[1024];
va_list args; //声明可变参数列表,实际时一个 char* 类型
va_start(args, format); //初始化可变参数列表
vsnprintf(logBuffer, sizeof logBuffer, format, args); //int vsnprintf(char *str, size_t size, const char *format, va_list ap); 是一个可变参数函数,将格式化后的字符串输出到缓冲区中。类似带 v 开头的可变参数函数有很多
va_end(args); //清理可变参数列表,类似 close() 和 delete
//4.拼接为一个完整的消息
std::string message;
message += "--> 标准日志:"; message += stdBuffer;
message += "\t 用户日志:"; message += logBuffer;
message += "\n";
//5.打印日志消息
_WriteLog(level, message);
}
private:
bool _debugShow;
WriteMode _writeMode;
std::string _logFileName;
};
//sock.hpp
/* 文件描述
主要是对套接字编程的常见接口做封装,是一个关于套接字的工具包
*/
#pragma once
#include <memory>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include "log.hpp"
class ThreadData
{
public:
int _sock;
std::string _ip;
uint16_t _port;
};
class Sock
{
private:
const static int g_backlog = 20; //一般不会太大,也不会太小
public:
//空的构造函数
Sock() {}
//创建监听套接字
int _Socket()
{
int listenSock = socket(AF_INET, SOCK_STREAM, 0);
if (listenSock < 0)
{
_log.LogMessage(FATAL, "socket() error %s %d", __FILE__, __LINE__);
exit(1);
}
_log.LogMessage(NORMAL, "socket() success %s %d", __FILE__, __LINE__);
return listenSock;
}
//绑定监听套接字
void _Bind(int listenSock, uint16_t port, std::string ip = "0.0.0.0")
{
struct sockaddr_in local;
memset(&local, 0, sizeof local);
local.sin_family = AF_INET;
local.sin_port = htons(port);
inet_pton(AF_INET, ip.c_str(), &local.sin_addr);
if (bind(listenSock, (struct sockaddr*)&local, sizeof(local)) < 0)
{
_log.LogMessage(FATAL, "bind() error %s %d", __FILE__, __LINE__);
exit(2);
}
_log.LogMessage(NORMAL, "bind() success %s %d", __FILE__, __LINE__);
}
//置套接字监听状态
void _Listen(int listenSock)
{
if (listen(listenSock, g_backlog) < 0)
{
_log.LogMessage(FATAL, "listen() error %s %d", __FILE__, __LINE__);
exit(3);
}
_log.LogMessage(NORMAL, "listen() success %s %d", __FILE__, __LINE__);
}
//服务端等待连接后,返回服务套接字(参数还带有服务端的信息)
int _Accept(int listenSock, std::string* ip, uint16_t* port)
{
struct sockaddr_in src;
socklen_t len = sizeof(src);
int serviceSock = accept(listenSock, (struct sockaddr*)&src, &len);
if (serviceSock < 0)
{
_log.LogMessage(FATAL, "accept() error %s %d", __FILE__, __LINE__);
return -1;
}
_log.LogMessage(NORMAL, "accept() success %s %d", __FILE__, __LINE__);
*port = ntohs(src.sin_port);
*ip = inet_ntoa(src.sin_addr);
return serviceSock;
}
//客户端主动连接服务端
bool _Connect(int sock, const std::string& server_ip, const uint16_t& server_port)
{
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(server_port);
server.sin_addr.s_addr = inet_addr(server_ip.c_str());
if (connect(sock, (struct sockaddr*)&server, sizeof(server)) == 0)
{
_log.LogMessage(NORMAL, "accept() success %s %d", __FILE__, __LINE__);
return true;
}
_log.LogMessage(FATAL, "connect() error %s %d", __FILE__, __LINE__);
return false;
}
private:
Log _log;
};
//usage.hpp
/* 文件描述
存放用户的说明手册
*/
#pragma once
#include <iostream>
#include <string>
static void Usage(std::string proc)
{
std::cout << "\nUsage: " << proc << " [ip] [port]\n" << std::endl;
}
//http_server.hpp
/* 文件描述
使用 sock.hpp 工具包进一步封装的 HTTP 服务端
*/
#pragma once
#include <signal.h>
#include <functional>
#include "sock.hpp"
#include "log.hpp"
class HttpServer
{
private:
using func_t = std::function<void(int)>;
public:
HttpServer(const uint16_t& port, func_t func)
: _port(port), _func(func)
{
_listenSock = _sock._Socket();
_sock._Bind(_listenSock, _port);
_sock._Listen(_listenSock);
}
void Start()
{
signal(SIGCHLD, SIG_IGN);
while (true)
{
std::string client_ip;
uint16_t client_port = 0;
int serviceSock = _sock._Accept(_listenSock, &client_ip, &client_port);
if (fork() == 0)
{
close(_listenSock);
_func(serviceSock);
exit(0);
}
close(serviceSock);
}
}
~HttpServer()
{
if (_listenSock >= 0)
close(_listenSock);
}
private:
int _listenSock;
uint16_t _port;
Sock _sock;
func_t _func;
};
//http_server.cpp
#include <iostream>
#include <memory>
#include <cassert>
#include "http_server.hpp"
#include "usage.hpp"
void HandlerHttpRequest(int sockfd)
{
char buffer[1024] = { 0 };
ssize_t s = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (s > 0)
{
buffer[s] = 0
std::cout << buffer << "---------------\n" << std::endl;
}
}
int main(int argc, char const* argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(-1);
}
std::unique_ptr<HttpServer> hs(new HttpServer(atoi(argv[1]), HandlerHttpRequest));
hs->Start();
return 0;
}
运行起来后使用浏览器来访问。
# 运行程序
./http_server 8081
--> 标准日志:[NORMAL][pid:23542][2024-3-30 20:3:55] 用户日志:accept() success sock.hpp 86
--> 标准日志:[NORMAL][pid:23542][2024-3-30 20:3:55] 用户日志:accept() success sock.hpp 86
...
而作为客户端的浏览器需要在 URL 地址栏中填入 http://服务器ip地址:server程序占用端口号 来向服务器发送 http 请求。
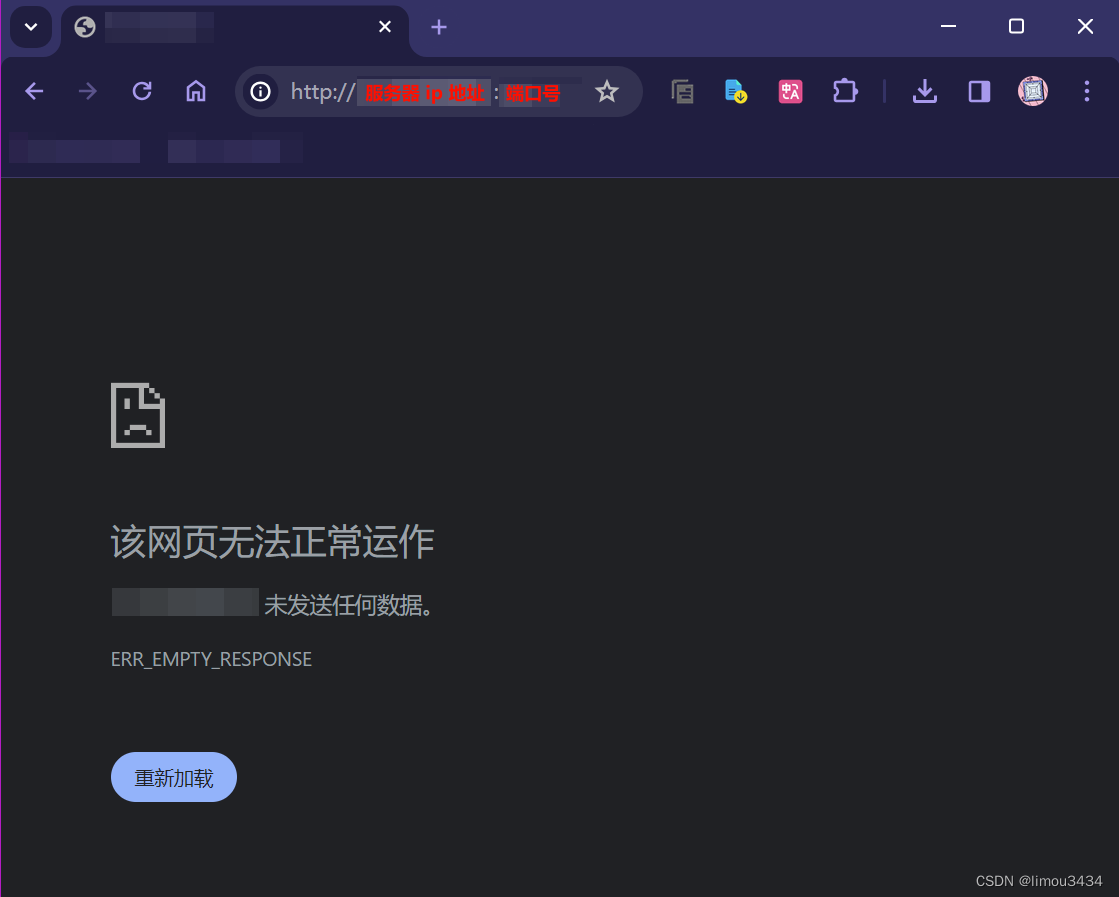
# 服务端运行结果
GET / HTTP/1.1 # 请求行:请求方法 Web根目录 协议版本, 下面都是请求报头
Host: ip:port # 本次请求的目标 ip 和 port, 这里我抹去了我的 ip:port, 您这里显示的就是一串具体数字
Connection: keep-alive # 代表支持长链接
Cache-Control: max-age=0 # 资源的缓存时间
Upgrade-Insecure-Requests: 1 # 升级不安全请求
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 # 发起请求的客户端信息
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 # 本次请求可以接受的一些资源文件格式
Accept-Encoding: gzip, deflate # 支持的压缩
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7 # 支持的语言
# 这里有一段空行, 别忘记了
---------------
# 这里本来是请求正文的部分, 但是我们的浏览器只是做了访问请求, 没有发送任何数据, 因此这里为空
那服务端怎么返回给浏览器数据呢?我们可以尝试在 HandlerHttpRequest() 中直接向客户端写回一个 html 标签(这些知识就属于 Web 三大件的知识了,您可以前去 MDN 网站了解一下,或者看我的三篇关于 HTML、CSS、JS 的基础文章)。
//修改服务端的 HandlerHttpRequest()
void HandlerHttpRequest(int sockfd)
{
//1.读取请求
char buffer[1024] = { 0 };
ssize_t s = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (s > 0)
{
buffer[s] = 0;
std::cout << buffer << "---------------\n" << std::endl;
}
//2.返回响应
std::string httpResponse = "HTTP/1.1 200 OK\r\n"; //状态行
httpResponse += "\r\n"; //暂时不写响应报头,直接添加空行(现代的浏览器大部分都可以补充上报头的属性,依旧可以进行自定义识别)
httpResponse += "<p>I am limou.</p>";
send(sockfd, httpResponse.c_str(), httpResponse.size(), 0);
}
其他的不用改动,直接在浏览器上重新使用对应的 url 进行访问即可。
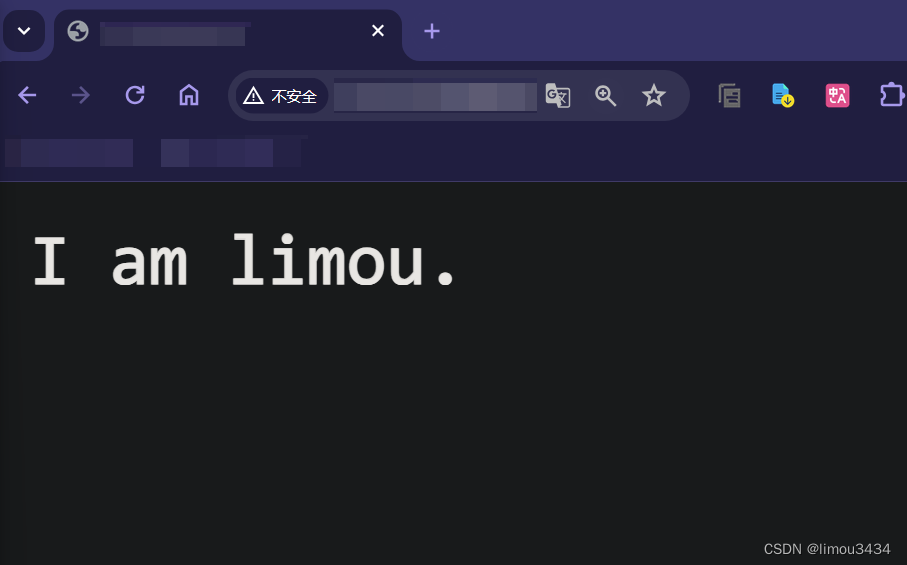
这里我主要是想带您查看和使用 HTTP 协议的请求报文和响应报文,接下来我会让您的服务器向客户端发送服务端上存储的某些文件。
2.4.查看 HTTP 响应报文
有了现有的 HTTP 格式,我们还可以做一些简单粗暴的应用,而不满足返回一串字符串,可以试着返回一些 html 代码。
# makefile
http_server:http_server.cpp
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -rf http_server log_dir
//log.hpp
/* 文件描述
Log log = Log(bool debugShow = true, //选择是否显示 DEBUG 等级的日志消息
std::string writeMode = "SCREEN", //选择日志的打印方式
std::string logFileName = "log" //选择日志的文件名称
);
log.WriteModeEnable(); //中途可以修改日志的打印方式
log.LogMessage(DEBUG | NORMAL | WARNING | ERROR | FATAL, "%s %d", __FILE__, __LINE__)); //打印日志
*/
#pragma once
#include <iostream>
#include <string>
#include <fstream>
#include <cstdio>
#include <cstdarg>
#include <ctime>
#include <pthread.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
//日志级别
#define DEBUG 0 //调试
#define NORMAL 1 //正常(或者叫 INFO)
#define WARNING 2 //警告
#define ERROR 3 //错误
#define FATAL 4 //致命
enum WriteMode
{
SCREEN = 5,
ONE_FILE,
CLASS_FILE
};
const char* gLevelMap[] = {
"DEBUG", //debug 模式
"NORMAL", //正常(或者叫 INFO)
"WARNING", //警告
"ERROR", //非致命错误
"FATAL" //严重错误
};
const std::string logdir = "log_dir";
//日志功能主要有:日志等级、发送时间、日志内容、代码行数、运行用户
class Log
{
private:
void __WriteLogToOneFile(std::string logFileName, const std::string& message)
{
std::ofstream out(logFileName, std::ios::app);
if (!out.is_open())
return;
out << message;
out.close();
}
void __WriteLogToClassFile(const int& level, const std::string& message)
{
std::string logFileName = "./";
logFileName += logdir;
logFileName += "/";
logFileName += _logFileName;
logFileName += "_";
logFileName += gLevelMap[level];
__WriteLogToOneFile(logFileName, message);
}
void _WriteLog(const int& level, const std::string& message)
{
switch (_writeMode)
{
case SCREEN: //向屏幕输出
std::cout << message;
break;
case ONE_FILE: //向单个日志文件输出
__WriteLogToOneFile("./" + logdir + "/" + _logFileName, message);
break;
case CLASS_FILE: //向多个日志文件输出
__WriteLogToClassFile(level, message);
break;
default:
std::cout << "write mode error!!!" << std::endl;
break;
}
}
public:
//构造函数,debugShow 为是否显示 debug 消息,writeMode 为日志打印模式,logFileName 为日志文件名
Log(bool debugShow = true, const WriteMode& writeMode = SCREEN, std::string logFileName = "log")
: _debugShow(debugShow), _writeMode(writeMode), _logFileName(logFileName)
{
mkdir(logdir.c_str(), 0775); //创建目录
}
//调整日志打印方式
void WriteModeEnable(const WriteMode& mode)
{
_writeMode = mode;
}
//拼接日志消息并且输出
void LogMessage(const int& level, const char* format, ...)
{
//1.若不是 debug 模式,且 level == DEBUG 则不做任何事情
if (_debugShow == false && level == DEBUG)
return;
//2.收集日志标准部分信息
char stdBuffer[1024];
time_t timestamp = time(nullptr); //获得时间戳
struct tm* local_time = localtime(×tamp); //将时间戳转换为本地时间
snprintf(stdBuffer, sizeof stdBuffer, "[%s][pid:%s][%d-%d-%d %d:%d:%d]",
gLevelMap[level],
std::to_string(getpid()).c_str(),
local_time->tm_year + 1900, local_time->tm_mon + 1, local_time->tm_mday,
local_time->tm_hour, local_time->tm_min, local_time->tm_sec
);
//3.收集日志自定义部分信息
char logBuffer[1024];
va_list args; //声明可变参数列表,实际时一个 char* 类型
va_start(args, format); //初始化可变参数列表
vsnprintf(logBuffer, sizeof logBuffer, format, args); //int vsnprintf(char *str, size_t size, const char *format, va_list ap); 是一个可变参数函数,将格式化后的字符串输出到缓冲区中。类似带 v 开头的可变参数函数有很多
va_end(args); //清理可变参数列表,类似 close() 和 delete
//4.拼接为一个完整的消息
std::string message;
message += "--> 标准日志:"; message += stdBuffer;
message += "\t 用户日志:"; message += logBuffer;
message += "\n";
//5.打印日志消息
_WriteLog(level, message);
}
private:
bool _debugShow;
WriteMode _writeMode;
std::string _logFileName;
};
//sock.hpp
/* 文件描述
主要是对套接字编程的常见接口做封装,是一个关于套接字的工具包
*/
#pragma once
#include <memory>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include "log.hpp"
class ThreadData
{
public:
int _sock;
std::string _ip;
uint16_t _port;
};
class Sock
{
private:
const static int g_backlog = 20; //一般不会太大,也不会太小
public:
//空的构造函数
Sock() {}
//创建监听套接字
int _Socket()
{
int listenSock = socket(AF_INET, SOCK_STREAM, 0);
if (listenSock < 0)
{
_log.LogMessage(FATAL, "socket() error %s %d", __FILE__, __LINE__);
exit(1);
}
_log.LogMessage(NORMAL, "socket() success %s %d", __FILE__, __LINE__);
return listenSock;
}
//绑定监听套接字
void _Bind(int listenSock, uint16_t port, std::string ip = "0.0.0.0")
{
struct sockaddr_in local;
memset(&local, 0, sizeof local);
local.sin_family = AF_INET;
local.sin_port = htons(port);
inet_pton(AF_INET, ip.c_str(), &local.sin_addr);
if (bind(listenSock, (struct sockaddr*)&local, sizeof(local)) < 0)
{
_log.LogMessage(FATAL, "bind() error %s %d", __FILE__, __LINE__);
exit(2);
}
_log.LogMessage(NORMAL, "bind() success %s %d", __FILE__, __LINE__);
}
//置套接字监听状态
void _Listen(int listenSock)
{
if (listen(listenSock, g_backlog) < 0)
{
_log.LogMessage(FATAL, "listen() error %s %d", __FILE__, __LINE__);
exit(3);
}
_log.LogMessage(NORMAL, "listen() success %s %d", __FILE__, __LINE__);
}
//服务端等待连接后,返回服务套接字(参数还带有服务端的信息)
int _Accept(int listenSock, std::string* ip, uint16_t* port)
{
struct sockaddr_in src;
socklen_t len = sizeof(src);
int serviceSock = accept(listenSock, (struct sockaddr*)&src, &len);
if (serviceSock < 0)
{
_log.LogMessage(FATAL, "accept() error %s %d", __FILE__, __LINE__);
return -1;
}
_log.LogMessage(NORMAL, "accept() success %s %d", __FILE__, __LINE__);
*port = ntohs(src.sin_port);
*ip = inet_ntoa(src.sin_addr);
return serviceSock;
}
//客户端主动连接服务端
bool _Connect(int sock, const std::string& server_ip, const uint16_t& server_port)
{
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(server_port);
server.sin_addr.s_addr = inet_addr(server_ip.c_str());
if (connect(sock, (struct sockaddr*)&server, sizeof(server)) == 0)
{
_log.LogMessage(NORMAL, "accept() success %s %d", __FILE__, __LINE__);
return true;
}
_log.LogMessage(FATAL, "connect() error %s %d", __FILE__, __LINE__);
return false;
}
private:
Log _log;
};
//usage.hpp
/* 文件描述
存放用户的说明手册
*/
#pragma once
#include <iostream>
#include <string>
static void Usage(std::string proc)
{
std::cout << "\nUsage: " << proc << " [ip] [port]\n" << std::endl;
}
//util.hpp
/* 文件描述
是一个针对字符串处理的工具包
*/
#include <iostream>
#include <string>
#include <vector>
class Util
{
public:
//根据 sep 剪切 str 内容为行存储到 *out 中
static void _CutString(const std::string& str, const std::string& sep, std::vector<std::string>* out)
{
std::size_t start = 0;
while (start < str.size())
{
auto pos = str.find(sep, start);
if (pos == std::string::npos)
{
break;
}
std::string sub = str.substr(start, pos - start);
out->push_back(sub);
start += sub.size();
start += sep.size();
}
if (start < str.size())
out->push_back(str.substr(start));
}
};
//http_server.hpp
/* 文件描述
使用 sock.hpp 工具包进一步封装的 HTTP 服务端
*/
#pragma once
#include <signal.h>
#include <functional>
#include "sock.hpp"
#include "log.hpp"
class HttpServer
{
private:
using func_t = std::function<void(int)>;
public:
HttpServer(const uint16_t& port, func_t func)
: _port(port), _func(func)
{
_listenSock = _sock._Socket();
_sock._Bind(_listenSock, _port);
_sock._Listen(_listenSock);
}
void Start()
{
signal(SIGCHLD, SIG_IGN);
while (true)
{
std::string client_ip;
uint16_t client_port = 0;
int serviceSock = _sock._Accept(_listenSock, &client_ip, &client_port);
if (fork() == 0)
{
close(_listenSock);
_func(serviceSock);
exit(0);
}
close(serviceSock);
}
}
~HttpServer()
{
if (_listenSock >= 0)
close(_listenSock);
}
private:
int _listenSock;
uint16_t _port;
Sock _sock;
func_t _func;
};
//http_server.cpp
#include <iostream>
#include <vector>
#include <memory>
#include <fstream>
#include <cassert>
#include "http_server.hpp"
#include "usage.hpp"
#include "util.hpp"
#define ROOT "./wwwroot"
#define HOMW_PAGE "index.html"
void HandlerHttpRequest(int sockfd)
{
//1.读取请求
char buffer[1024] = { 0 };
ssize_t s = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
//2.分割请求信息
std::vector<std::string> vline;
Util::_CutString(buffer, "\n", &vline);
for (auto& it : vline)
std::cout << "---" << it << std::endl;
std::vector<std::string> vblock;
Util::_CutString(vline[0], " ", &vblock);
//3.获取资源
std::string target = ROOT; //"./wwwroot"
std::string file = vblock[1];
if (file == "/")
file = "/index.html";
target += file; //"./wwwroot/index.html"
std::cout << "***" << target << "***" << "\n\n";
std::string content;
std::ifstream in(target);
if (in.is_open())
{
std::string line;
while (std::getline(in, line)) //注意这里有一个隐藏的 bug, 这里只能读取字符文本, 而无法读取二进制的图片或者视频文件
{
content += line;
}
}
in.close();
//2.返回响应
std::string httpResponse;
if (content.empty())
{
httpResponse = "HTTP/1.1 404 NOT FOUND\r\n"; //状态行
}
else
{
httpResponse = "HTTP/1.1 200 OK\r\n"; //状态行
}
httpResponse += "\r\n"; //暂时不写响应报头,直接添加空行(现代的浏览器大部分都可以补充上报头的属性,依旧可以进行自定义识别)
httpResponse += content; //暂时不写响应报头,直接添加空行(现代的浏览器大部分都可以补充上报头的属性,依旧可以进行自定义识别)
send(sockfd, httpResponse.c_str(), httpResponse.size(), 0);
}
int main(int argc, char const* argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(-1);
}
std::unique_ptr<HttpServer> hs(new HttpServer(atoi(argv[1]), HandlerHttpRequest));
hs->Start();
return 0;
}
<!-- wwwroot/index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<p>I am limou, this is my html!</p>
</body>
</html>
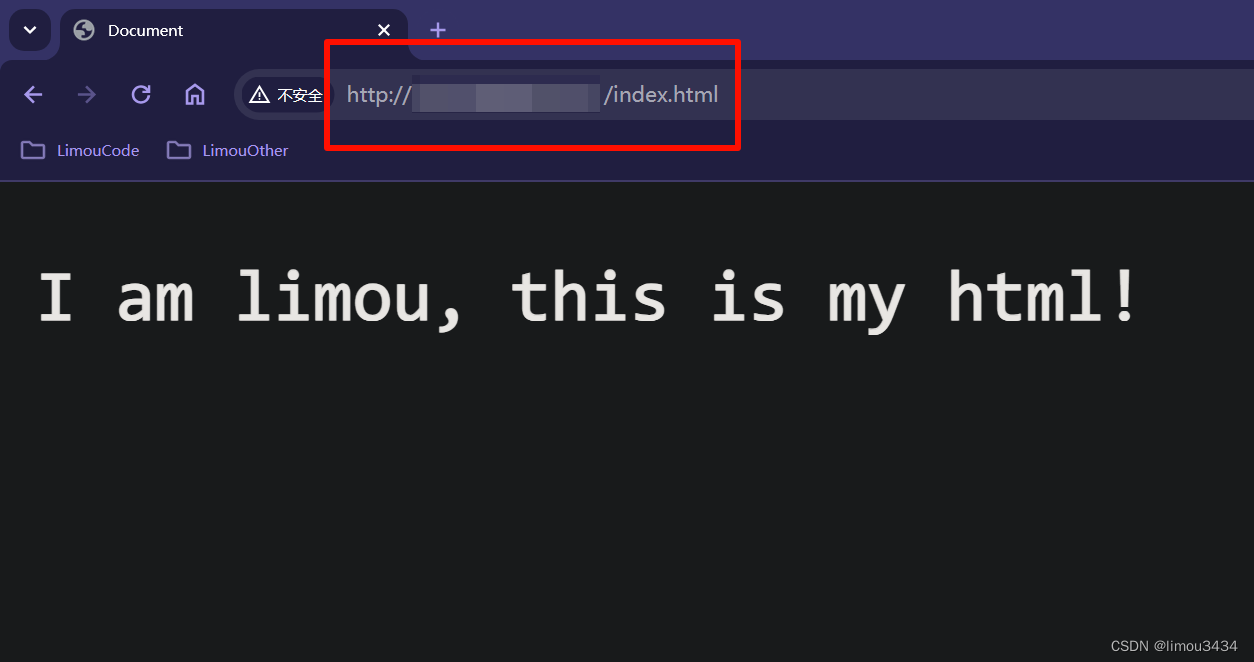
上面看到的只是浏览器给响应做好渲染后的最终结果,如果我们希望看到更加原生的 http 响应报文怎么办呢?原生一点就使用 telnet 工具直接发送原生的请求得到原生的响应。
# 服务端程序运行后
$ ./http_server port
--> 标准日志:[NORMAL][pid:13648][2024-5-7 19:52:40] 用户日志:socket() success sock.hpp 42
--> 标准日志:[NORMAL][pid:13648][2024-5-7 19:52:40] 用户日志:bind() success sock.hpp 60
--> 标准日志:[NORMAL][pid:13648][2024-5-7 19:52:40] 用户日志:listen() success sock.hpp 71
# 服务端本地发送 http 请求
$ telnet 127.0.0.1 8081
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
^]
telnet>
GET / HTTP/1.1
HTTP/1.1 200 OK
<!-- wwwroot/index.html --><!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title></head><body> <p>I am limou, this is my html!</p></body></html>Connection closed by foreign host.
//服务端接受到请求后
$ ./http_server port
--> 标准日志:[NORMAL][pid:13648][2024-5-7 19:52:40] 用户日志:socket() success sock.hpp 42
--> 标准日志:[NORMAL][pid:13648][2024-5-7 19:52:40] 用户日志:bind() success sock.hpp 60
--> 标准日志:[NORMAL][pid:13648][2024-5-7 19:52:40] 用户日志:listen() success sock.hpp 71
--> 标准日志:[NORMAL][pid:13648][2024-5-7 19:52:45] 用户日志:accept() success sock.hpp 86
---GET / HTTP/1.1
***./wwwroot/index.html***
可以看到返回的 http 请求是没有经过渲染的 html 字符文本。
现代化一点的话,也可以使用 Fiddler、Postman 这些软件工具来抓取响应报文,也就是所谓的抓包工具。这类工具能拦截浏览器发出的请求和从服务端返回的响应,因此也可以称为 中间人程序。


注意:值得注意的是,这里的网路根路径不一定是
Linux的根路径,可以由服务端代码自己定义(则种行为也被叫定义路由,而浏览器请求的资源根目录一般也叫做根路由)。
补充:如果需要发送图片,就不能在读取正文的时候直接使用以下代码。
// 错误的代码 std::string content; std::ifstream in(target); if (in.is_open()) { std::string line; while (std::getline(in, line)) // 注意这里有一个隐藏的 bug, 这里只能读取字符文本, 而无法读取二进制的图片或者视频文件 { content += line; } } in.close();应当改为以下代码。
// 正确的代码 std::fstream in(path, std::ios::binary); if (in.is_open()) { in.seekg(0, in.end); //设置文件指针到结尾 int sizeOfFile = in.tellg(); // 获取当前的读取读取指针相对于文件开始位置的偏移量, 也就相当于获取文件的大小 in.seekg(0, in.beg); // 恢复文件指针到开头 std::vector<char> content(sizeOfFile); in.read(content.data(), sizeOfFile); // content.data() 返回内存空间的起始地址 // std::string content; // content.resize(sizeOfFile); // in.read((char*)content.c_str(), sizeOfFile); // content.data() 返回内存空间的起始地址, 或者使用 in.read(&content[0], ...) 的形式 in.close(); } in.close();但是这份代码还是有点不严谨,还需要设置响应头部字段
Content-Type,后面还会提及,这里先简单提及一下`。
3.HTTP 协议的方法
在 http 请求的请求行中有一个请求方法,日常客户端使用服务器一般就是两种:
- 从服务器拿取资源,一般使用
GET方法 - 向服务端发送数据,一般使用
POST方法
资源一般都是客户端可以感受到的图片、视频、网页等,但是上面这种说法不太严谨,也不够直观,后面我会细细讲解两者的区别。而浏览器直接使用 URL 向服务器获取资源时,默认使用 GET 方法进行请求。
对于不同的方法,其实有对请求和响应做一定的要求,可以前往 MDN 查看 HTTP 开发规范手册。
3.1.GET 方法
我们可以先试着使用这个方法,使用 telnet 来获取百度首页的网页资源。
3.1.1.使用 telnet 客户端
还可以使用 telnet 客户端,显式的通过 GET 方法获取资源。
# 使用 telnet 客户端访问百度网页
$ telnet www.baidu.com 80
Trying 183.2.172.185...
Connected to www.baidu.com.
Escape character is '^]'.
^]
telnet>
GET / HTTP/1.1 # 方法 + 路由 + 协议版本
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: no-cache
Connection: keep-alive
Content-Length: 9508
Content-Type: text/html
Date: Mon, 01 Apr 2024 02:29:04 GMT
P3p: CP=" OTI DSP COR IVA OUR IND COM "
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Pragma: no-cache
Server: BWS/1.1
Set-Cookie: BAIDUID=AC1F454F02ADF312E8B1746A81CB4569:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BIDUPSID=AC1F454F02ADF312E8B1746A81CB4569; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: PSTM=1711938544; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BAIDUID=AC1F454F02ADF312DA82A0D20DE67052:FG=1; max-age=31536000; expires=Tue, 01-Apr-25 02:29:04 GMT; domain=.baidu.com; path=/; version=1; comment=bd
Traceid: 1711938544153071309810394761683123290134
Vary: Accept-Encoding
X-Ua-Compatible: IE=Edge,chrome=1
X-Xss-Protection: 1;mode=block
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="description" content="全球领先的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。"><link rel="shortcut icon" href="//www.baidu.com/favicon.ico" type="image/x-icon"><link rel="search" type="application/opensearchdescription+xml" href="//www.baidu.com/content-search.xml" title="百度搜索"><title>百度一下,你就知道</title><style type="text/css">body{margin:0;padding:0;text-align:center;background:#fff;height:100%}html{overflow-y:auto;color:#000;overflow:-moz-scrollbars;height:100%}body,input{font-size:12px;font-family:"PingFang SC",Arial,"Microsoft YaHei",sans-serif}a{text-decoration:none}a:hover{text-decoration:underline}img{border:0;-ms-interpolation-mode:bicubic}input{font-size:100%;border:0}body,form{position:relative;z-index:0}#wrapper{height:100%}#head_wrapper.s-ps-islite{padding-bottom:370px}#head_wrapper.s-ps-islite .s_form{position:relative;z-index:1}#head_wrapper.s-ps-islite .fm{position:absolute;bottom:0}#head_wrapper.s-ps-islite .s-p-top{position:absolute;bottom:40px;width:100%;height:181px}#head_wrapper.s-ps-islite #s_lg_img{position:static;margin:33px auto 0 auto;left:50%}#form{z-index:1}.s_form_wrapper{height:100%}#lh{margin:16px 0 5px;word-spacing:3px}.c-font-normal{font:13px/23px Arial,sans-serif}.c-color-t{color:#222}.c-btn,.c-btn:visited{color:#333!important}.c-btn{display:inline-block;overflow:hidden;font-family:inherit;font-weight:400;text-align:center;vertical-align:middle;outline:0;border:0;height:30px;width:80px;line-height:30px;font-size:13px;border-radius:6px;padding:0;background-color:#f5f5f6;cursor:pointer}.c-btn:hover{background-color:#315efb;color:#fff!important}a.c-btn{text-decoration:none}.c-btn-mini{height:24px;width:48px;line-height:24px}.c-btn-primary,.c-btn-primary:visited{color:#fff!important}.c-btn-primary{background-color:#4e6ef2}.c-btn-primary:hover{background-color:#315efb}a:active{color:#f60}#wrapper{position:relative;min-height:100%}#head{padding-bottom:100px;text-align:center}#wrapper{min-width:1250px;height:100%;min-height:600px}#head{position:relative;padding-bottom:0;height:100%;min-height:600px}.s_form_wrapper{height:100%}.quickdelete-wrap{position:relative}.tools{position:absolute;right:-75px}.s-isindex-wrap{position:relative}#head_wrapper.head_wrapper{width:auto}#head_wrapper{position:relative;height:40%;min-height:314px;max-height:510px;width:1000px;margin:0 auto}#head_wrapper .s-p-top{height:60%;min-height:185px;max-height:310px;position:relative;z-index:0;text-align:center}#head_wrapper input{outline:0;-webkit-appearance:none}#head_wrapper .s_btn_wr,#head_wrapper .s_ipt_wr{display:inline-block;zoom:1;background:0 0;vertical-align:top}#head_wrapper .s_ipt_wr{position:relative;width:546px}#head_wrapper .s_btn_wr{width:108px;height:44px;position:relative;z-index:2}#head_wrapper .s_ipt_wr:hover #kw{border-color:#a7aab5}#head_wrapper #kw{width:512px;height:16px;padding:12px 16px;font-size:16px;margin:0;vertical-align:top;outline:0;box-shadow:none;border-radius:10px 0 0 10px;border:2px solid #c4c7ce;background:#fff;color:#222;overflow:hidden;box-sizing:content-box}#head_wrapper #kw:focus{border-color:#4e6ef2!important;opacity:1}#head_wrapper .s_form{width:654px;height:100%;margin:0 auto;text-align:left;z-index:100}#head_wrapper .s_btn{cursor:pointer;width:108px;height:44px;line-height:45px;padding:0;background:0 0;background-color:#4e6ef2;border-radius:0 10px 10px 0;font-size:17px;color:#fff;box-shadow:none;font-weight:400;border:none;outline:0}#head_wrapper .s_btn:hover{background-color:#4662d9}#head_wrapper .s_btn:active{background-color:#4662d9}#head_wrapper .quickdelete-wrap{position:relative}#s_top_wrap{position:absolute;z-index:99;min-width:1000px;width:100%}.s-top-left{position:absolute;left:0;top:0;z-index:100;height:60px;padding-left:24px}.s-top-left .mnav{margin-right:31px;margin-top:19px;display:inline-block;position:relative}.s-top-left .mnav:hover .s-bri,.s-top-left a:hover{color:#315efb;text-decoration:none}.s-top-left .s-top-more-btn{padding-bottom:19px}.s-top-left .s-top-more-btn:hover .s-top-more{display:block}.s-top-right{position:absolute;right:0;top:0;z-index:100;height:60px;padding-right:24px}.s-top-right .s-top-right-text{margin-left:32px;margin-top:19px;display:inline-block;position:relative;vertical-align:top;cursor:pointer}.s-top-right .s-top-right-text:hover{color:#315efb}.s-top-right .s-top-login-btn{display:inline-block;margin-top:18px;margin-left:32px;font-size:13px}.s-top-right a:hover{text-decoration:none}#bottom_layer{width:100%;position:fixed;z-index:302;bottom:0;left:0;height:39px;padding-top:1px;overflow:hidden;zoom:1;margin:0;line-height:39px;background:#fff}#bottom_layer .lh{display:inline;margin-right:20px}#bottom_layer .lh:last-child{margin-left:-2px;margin-right:0}#bottom_layer .lh.activity{font-weight:700;text-decoration:underline}#bottom_layer a{font-size:12px;text-decoration:none}#bottom_layer .text-color{color:#bbb}#bottom_layer a:hover{color:#222}#bottom_layer .s-bottom-layer-content{text-align:center}</style></head><body><div id="wrapper" class="wrapper_new"><div id="head"><div id="s-top-left" class="s-top-left s-isindex-wrap"><a href="//news.baidu.com/" target="_blank" class="mnav c-font-normal c-color-t">新闻</a><a href="//www.hao123.com/" target="_blank" class="mnav c-font-normal c-color-t">hao123</a><a href="//map.baidu.com/" target="_blank" class="mnav c-font-normal c-color-t">地图</a><a href="//live.baidu.com/" target="_blank" class="mnav c-font-normal c-color-t">直播</a><a href="//haokan.baidu.com/?sfrom=baidu-top" target="_blank" class="mnav c-font-normal c-color-t">视频</a><a href="//tieba.baidu.com/" target="_blank" class="mnav c-font-normal c-color-t">贴吧</a><a href="//xueshu.baidu.com/" target="_blank" class="mnav c-font-normal c-color-t">学术</a><div class="mnav s-top-more-btn"><a href="//www.baidu.com/more/" name="tj_briicon" class="s-bri c-font-normal c-color-t" target="_blank">更多</a></div></div><div id="u1" class="s-top-right s-isindex-wrap"><a class="s-top-login-btn c-btn c-btn-primary c-btn-mini lb" style="position:relative;overflow:visible" name="tj_login" href="//www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1">登录</a></div><div id="head_wrapper" class="head_wrapper s-isindex-wrap s-ps-islite"><div class="s_form"><div class="s_form_wrapper"><div id="lg" class="s-p-top"><img hidefocus="true" id="s_lg_img" class="index-logo-src" src="//www.baidu.com/img/flexible/logo/pc/index.png" width="270" height="129" usemap="#mp"><map name="mp"><area style="outline:0" hidefocus="true" shape="rect" coords="0,0,270,129" href="//www.baidu.com/s?wd=%E7%99%BE%E5%BA%A6%E7%83%AD%E6%90%9C&sa=ire_dl_gh_logo_texing&rsv_dl=igh_logo_pcs" target="_blank" title="点击一下,了解更多"></map></div><a href="//www.baidu.com/" id="result_logo"></a><form id="form" name="f" action="//www.baidu.com/s" class="fm"><input type="hidden" name="ie" value="utf-8"> <input type="hidden" name="f" value="8"> <input type="hidden" name="rsv_bp" value="1"> <input type="hidden" name="rsv_idx" value="1"> <input type="hidden" name="ch" value=""> <input type="hidden" name="tn" value="baidu"> <input type="hidden" name="bar" value=""> <span class="s_ipt_wr quickdelete-wrap"><input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off"> </span><span class="s_btn_wr"><input type="submit" id="su" value="百度一下" class="bg s_btn"> </span><input type="hidden" name="rn" value=""> <input type="hidden" name="fenlei" value="256"> <input type="hidden" name="oq" value=""> <input type="hidden" name="rsv_pq" value="b9ff093e0000e419"> <input type="hidden" name="rsv_t" value="3635FYbdbC8tlWmudZmYaUnaucNe+RzTzNEGqg/JuniQU10WL5mtMQehIrU"> <input type="hidden" name="rqlang" value="cn"> <input type="hidden" name="rsv_enter" value="1"> <input type="hidden" name="rsv_dl" value="ib"></form></div></div></div><div id="bottom_layer" class="s-bottom-layer s-isindex-wrap"><div class="s-bottom-layer-content"><p class="lh"><a class="text-color" href="//home.baidu.com/" target="_blank">关于百度</a></p><p class="lh"><a class="text-color" href="//ir.baidu.com/" target="_blank">About Baidu</a></p><p class="lh"><a class="text-color" href="//www.baidu.com/duty" target="_blank">使用百度前必读</a></p><p class="lh"><a class="text-color" href="//help.baidu.com/" target="_blank">帮助中心</a></p><p class="lh"><a class="text-color" href="//www.beian.gov.cn/portal/registerSystemInfo?recordcode=11000002000001" target="_blank">京公网安备11000002000001号</a></p><p class="lh"><a class="text-color" href="//beian.miit.gov.cn/" target="_blank">京ICP证030173号</a></p><p class="lh"><span id="year" class="text-color"></span></p><p class="lh"><span class="text-color">互联网药品信息服务资格证书 (京)-经营性-2017-0020</span></p><p class="lh"><a class="text-color" href="//www.baidu.com/licence/" target="_blank">信息网络传播视听节目许可证 0110516</a></p></div></div></div></div><script type="text/javascript">var date=new Date,year=date.getFullYear();document.getElementById("year").innerText="©"+year+" Baidu "</script></body></html>
3.1.2.使用 from 标签
如果您曾经学 html 的 <from> 时,无法深刻理解它的属性,那在现在这个属性无法困住您。
<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<p>I am limou, this is my html!</p>
<form action="/a/b/c/d" method="GET">
User:<input type="text" name="user"><br>
Password:<input type="text" name="pwd"><br> <!-- 不过这里的类型最好是 password,可以把密码字符以小圆点的方式展现 -->
<input type="submit" value="登录"><br> <!-- submit 会使得表单数据添加到 URL 中, 导致被提交, 但是 button 不会 -->
<!-- 其中 name 就是提交表单数据时 URL 地址栏中的关键字 -->
</form>
</body>
</html>
这个标签就可以通过一个按钮把表单资源提交到服务器中,而实际上表单中的数据最终会被转化为一个 HTTP 请求。如果前面的代码保持不变,我们尝试在浏览器再次访问这个页面。
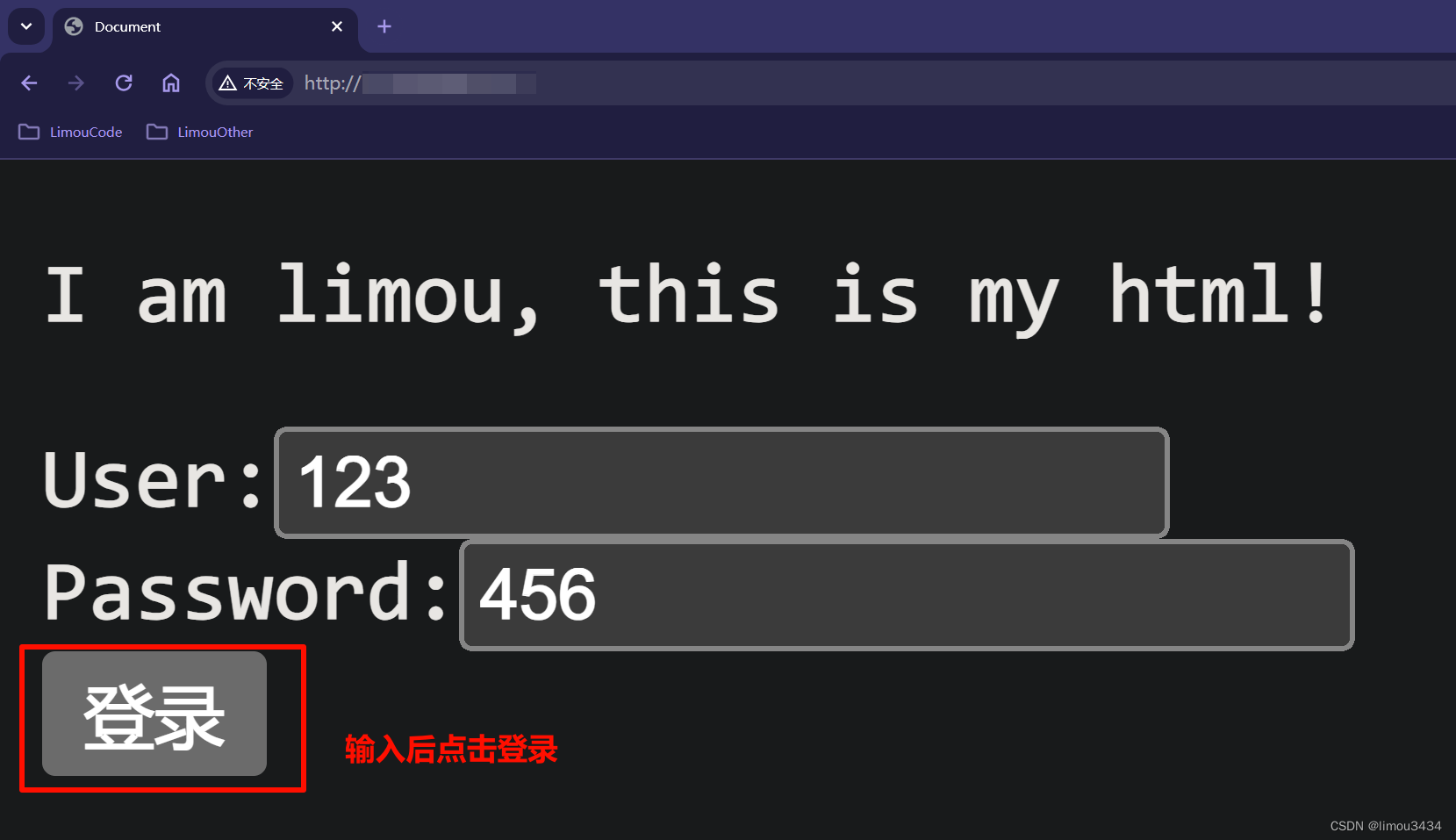
输入账号和密码后,直接点击登录,查看 URL 地址栏的变化。
填好 action 的值,也就是资源路径,可以让服务器返回的这个页面被用户提交表单时:
- 按
当前浏览器的URL + action + 表单参数组合为一个完整的字符串 - 上述字符串被填入浏览器的
URL地址栏 - 然后通过
http协议将上述字符串包装为一个http请求 - 通过套接字等读写接口结合序列化请求发给服务端
- 服务端对请求进行反序列化,进一步解析这个请求,进行相应的处理
- 服务端解析成功,通过套接字编程返回序列化响应
- 客户端(浏览器)反序列化响应,通过内置的渲染器,把字符渲染为页面
补充:一般这个
action前端页面都填写的是#,常见的做法是让JS代码拦截表单的提交,然后绑定按钮事件,由JS代码来提交表单和发送请求(例如ajax()请求)。经过上述的学习,您应该就能理解如何进行前后端分离了。
- 后端程序员需要对浏览器的
URL地址栏中的路由和表单参数做对应的方法编写,最后形成路由接口。- 将接口提供给前端程序员,前端程序员需要拿一些功能时,通过
<form action="...">的方式或者JS的方式通过IP:PORT/路由的方式获取响应资源,编写对应的前端代码。
另外这里一定要注意一个细节,GET 方法一般请求指定资源的表示,应只用于请求数据,而不应该包含数据。在 GET 请求中发送正文可能会导致一些现有的实现拒绝该请求。虽然规范没有禁止这种行为,但是语义上没有该定义,最好是避免在 GET 请求中发送有效载荷…
不过有一种情况 GET 可以向服务器传递参数,就是设置了查询字符的 GET 请求(其实就是上述的表单提交请求)。这种情况下参数不会设置在正文中,而是通过资源路径直接传递。这些参数通常是为了辅助服务器进行更好的资源查询工作,而不是改变服务器上的某些资源。
而如果是 C++ 的 web 服务端,通常会使用正则表达式来进行解析,以接受除了 url 中资源路径以外的查询字符串(这点我放在代码或项目中体现)。
3.1.3.使用 URL 路径
之前我们直接输入 URL 时,浏览器默认是以 GET 方法获取资源的,这点您知道即可。
3.1.4.使用 link 超链接
这点又是很容易被忽略,html 文档中的超链接 <link> 包裹的文本被点击后,就会发生网站跳转,实际上就和填写 URL 没什么区别。
3.1.5.使用 src 资源链接
其实图片等媒体资源在 .html 中也会被设置路径,因此请求图片资源的时候实际上也是在触发 html 请求,只不过浏览器判断是图片标签后帮助我们封装好请求罢了…但也因此,我们需要在服务端的响应头部中支持 Content-Type 对图片等资源的设置,因此我们前面说的在查看 http 响应结构中最后补充的关于二进制图片的返回还差这一步 Content-Type 的设置,需要设置对图片资源的请求。
补充:这也能解释为什么有些时候明明图片资源在服务器上,其
html网页请求正确返回,但是图片等资源却无法正确显示的原因,这点在一些实现较差的浏览器上就能体现。<img src="example.jpg" alt="图片加载失败, 请检查网络连接或者稍后再试。">不过图片标签也有对应的解决方式,就是使用
alt暂时顶替图片内容,以文本的形式阐释图片…
补充:这里给您再补充一点知识,如果我们使用
bing搜索"你好",则会出现类似https://www.bing.com/search?q=limou3434&form=QBLH&sp=-1&ghc=1&lq=0&pq=limou3434&sc=3-9&qs=n&sk=&cvid=8DBFBC063CE34165AD3B12E87CE9A217&ghsh=0&ghacc=0&ghpl=的URL路径,这里会看到/search这个请求,您可以大胆猜测这个GET请求后面的查询字符串被交给了/search,其很有可能就对应C/C++服务器的某一个线程/进程。甚至有可能查询字符串被分割给线程池,等所有线程都返回结果拼凑起来,或者干脆先返回的线程先返回一部分的查询结果,让用户“感觉”搜索查询的速度变快了(有点声东击西的感觉hhhhh)…因此在这里我们可以看到
C++的应用,做Linux服务器,但是可能不适合做HTTP应用开发,这里原因有很多我可以给您简单列举以下:
- 开发周期长,维护较困难,本身语法就较为困难
C++网络应用开发工具库不够统一,甚至可以说是破碎- 截至目前(
2024-5-9)C++还是没有标准的网络库,原生书写请求和响应比较繁琐,可能需要制作轮子因此
C/C++在写搜索引擎、游戏、登陆注册则很适合使用C++…而一个接口请求对应一个线程/进程的思路,其实就是很多语言设置路由的思路,像下面
Python flask代码。# Python flask 中设置路由 from flask import Flask app = Flask(__name__) @app.route("/") # 下面就是注册的路由函数, 当浏览器访问资源根路径时, 会被一个线程/进程执行 def hello(): return "Hello, World!"您如果在大学期间学习的
C++语言,您也会发现C++ Web应用开发的难处…
补充:可以 前往 MDN 查看 GET 方法…
3.2.POST 方法
实际上 POST 方法就比 GET 少了一个东西,就是不会在 URL 中携带表单参数,这样做会比较私密一些,但不会安全(后面提到 HTTP 协议的安全问题时还会继续提到)。
我们在 wwwroot/ 下新建立一个网页 blog.html,然后把 index.html 内表单的提交方法改为 POST,把 action 修改为 /blog.html。
<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<p>I am limou, this is my html!</p>
<form action="/blog.html" method="POST">
User:<input type="text" name="user"><br>
Password:<input type="password" name="pwd"><br>
<input type="submit" value="登录"><br> <!-- submit 会使得表单数据添加到 URL 中, 导致被提交, 但是 button 不会 -->
<!-- 其中 name 就是提交表单数据时 URL 地址栏中的关键字 -->
</form>
</body>
</html>
<!-- blog.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My Blog</title>
</head>
<body>
This is my blog!
</body>
</html>
其他代码依旧不变,运行服务端然后在浏览器中进行访问和登录。
输入账户和密码,直接点击登录,观察 URL 地址栏的变化和页面的渲染。
这就实现了页面跳转,并且可以看到,表单参数没有和原来的 URL 进行拼接,不会回显在这个地址栏中(会比 GET 更加私密,但私密不代表安全,在网络传输中依旧是明文密码,只有经过加密才是比较安全的),而是被填充到了正文部分中。
通常来说,GET 的表单参数是有长度限制的,取决于浏览器的版本和具体实现。而 POST 内的表单参数理论上是可以无效长的,因为正文有头部的长度设置,可以分为多次传输一个 http 请求。
吐槽:与其说
POST和GET方法是一对反义词,不如说POST是GET的加强私密版。
- 两者都可以获取资源
- 前者在
URL中直接通过正文来作为参数,其他参数包含在http请求中(这点可以查看服务端对于http请求的读取结果来验证),无需我们自己对整个字符串做处理也能通过http来获取其他参数- 后者在
URL中正文作为参数的同时,还会传入其他参数,这些其他参数不会包含在http请求中(这点可以查看服务端对于http请求的读取结果来验证),这点就比较麻烦,需要我们自己解析字符串获取其他参数- 对于需要频繁检索或获取数据的情况,建议使用
GET方式- 对于需要向服务器发送大量数据或进行修改操作的情况,建议使用
POST方式。- 上述提到的其他参数,实际上就是一个
http请求结构中的请求正文部分
补充:关于
GET和POST中有所谓 幂等 的概念,“幂等”和“等于”是两个不同的概念。
- 幂等(Idempotent):指 一个操作被重复执行多次,结果都是一样的。无论进行多少次操作,最终的结果都是相同的。在计算机科学和数学中,幂等性通常用来描述某个操作或函数的性质。例如
HTTP方法中的GET和DELETE通常被认为是幂等的,因为对它们的多次调用不会产生不同的结果;而POST方法则不一定是幂等的,因为多次调用可能会产生不同的结果。- 等于(Equal to):指两个或多个对象在数值或其他性质上完全相同,等于通常用来比较两个对象是否相同或相等。
有点类似
C语言的+/-和++/--的区别,后者会产生副作用…
补充:可以 前往 MDN 查看 POST 方法…
3.3.其他方法
最后,给您补充一些其他常见的 HTTP 方法。
HTTP1.0 定义了三种请求方法:GET、POST、HEAD
HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE、CONNECT
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体 |
| 2 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中,POST 请求可能会导致新的资源的建立和/或已有资源的修改 |
| 3 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容 |
| 4 | HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 5 | DELETE | 请求服务器删除指定的页面 |
| 6 | OPTIONS | 允许客户端查看服务器支持的请求方法 |
| 7 | TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
| 8 | CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器 |
| 9 | PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 |
3.3.1.PUT 方法
这里简单把 POST 和 PUT 做一下区分,假设我们有一个简单的 RESTful API,用于管理用户信息,其中包含一个端点 /users/{userId},用于更新特定用户的信息。
现在假设我们有一个名为 Alice 的用户,她的用户 ID 是 123,初始的用户信息如下:
# 初始信息
{
"userId": 123,
"name": "Alice",
"age": 30
}
假设客户端想要使用PUT方法将Alice的年龄从30岁修改为31岁。客户端发送的请求如下:
# 客户端发送 PUT 请求
PUT /users/123 HTTP/1.1
Content-Type: application/json
{
"userId": 123,
"name": "Alice",
"age": 31
}
服务器收到这个请求后,会将 ID 为 123 的用户的信息替换为请求中的信息,即将 Alice 的年龄从 30 岁修改为 31 岁。
如果客户端再次发送相同的 PUT 请求,服务器的响应将会是相同的,因为服务器上的用户信息已经被完全替换为新的信息,这就展示了 PUT 方法的幂等性。
无论客户端发送多少次相同的 PUT 请求,服务器上 Alice 用户的信息始终会包含以下信息。
{
"userId": 123,
"name": "Alice",
"age": 31
}
当切换为 POST 方法时,通常情况下不具备幂等性。POST 方法的主要作用是向服务器提交数据,服务器会根据请求创建新的资源或执行特定的操作。POST 方法的非幂等性主要是由以下几个因素造成的:
-
创建新的资源:通常情况下,
POST方法用于创建新的资源,而不是更新现有资源。每次客户端发送POST请求,服务器都会创建一个新的资源,并返回一个唯一标识该资源的URI。因此,多次发送相同的POST请求会导致服务器上创建多个资源,而不是只创建一个。 -
执行特定操作:有时候,
POST方法也用于执行一些特定的操作,比如提交表单、发送评论等。这些操作可能会对服务器状态进行修改,因此不具备幂等性。
举个例子,假设我们有一个简单的博客网站,其中有一个端点 /posts 用于创建新的博客文章。客户端使用 POST 方法向服务器提交新的博客文章内容。每次发送相同的 POST 请求,服务器都会创建一个新的博客文章,并返回一个唯一标识该文章的 URI。因此,多次发送相同的 POST 请求会导致服务器上创建多个博客文章,而不是只创建一个。
因此可以简单理解为 POST 是创建修改,而 PUT 是更新修改。需要注意的是,服务器不一定会确保请求方法的幂等性,有些应用可能会错误地打破幂等性约束。
3.3.2.HEAD 方法
而 HEAD 方法请求资源的头部信息,并且这些头部信息与 GET 方法请求时返回的一致。该请求方法的一个使用场景是在下载一个大文件前先通过 HEAD 请求读取其 Content-Length 的值获取文件的大小,而无需实际下载文件,以此可以节约带宽资源。
3.3.3.DELETE 方法
DELETE 请求方法用于删除指定的资源。
3.3.4.OPTIONS 方法
OPTIONS 方法请求给定的 URL 或服务器的允许的通信/请求选项。客户端可以用这个方法指定一个 URL,或者用星号(*)来指代整个服务器。
其响应中包含 Allow 头部字段,其值表明了服务器支持的所有 HTTP 方法。
3.3.5.TRACE 方法
TRACE 方法是 HTTP 协议中的一个请求方法,它的主要作用是用于诊断目的,允许客户端向服务器发送一个请求,然后服务器会将请求消息原封不动地返回给客户端。TRACE 方法通常用于检查请求和响应消息是否在传输过程中被修改了,以及用于排查网络请求和响应的问题。
3.3.6.CONNECT 方法
CONNECT 方法是 HTTP 协议中的一种特殊的请求方法,它主要用于在客户端和目标服务器之间建立一条端到端的隧道连接。CONNECT 方法通常与 HTTPS 代理一起使用,用于在客户端和目标服务器之间建立加密的、端到端的通信通道。主要用于代理服务器,代理服务器可能收到请求后不进行处理,而是转发给别的服务器做处理。
3.3.7.PATCH 方法
PATCH 请求方法用于对资源进行部分修改。
补充:可以 前往 MDN 查看其他方法…
4.HTTP 协议的状态
HTTP 状态就是请求的状态,由三个十进制数字组成,第一个十进制数字定义了状态码的类型。响应分为五类:信息响应(100–199)、成功响应(200–299)、重定向(300–399)、客户端错误(400–499)、服务器错误(500–599),一般被包含在 HTTP 响应中:
| 分类 | 分类描述 |
|---|---|
| 1** | 信息响应,服务器收到请求,需要请求者继续执行操作(不常见) |
| 2** | 成功响应,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求(比如登录时发送的页面跳转) |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误(一般很少人使用,避免被恶意客户知道服务器的上限等信息,然后进行恶意攻击) |
)——在我们之前网络版本计算器中,计算结束后的返回响应中还包含一个“状态”,用来判断计算结果是否可行,就相当于这里提到的 HTTP 状态码。
吐槽:这里给一段精辟的吐槽…
补充:可以 前往 MDN 查看更加详细的状态码信息。
一般状态码有对应的官方状态描述,但是由于一些历史原因,有一些状态码和状态描述有很多混乱对应的现象,这点不奇怪。
吐槽:由于历史和商业竞争(毕竟网页之类的客户端距离用户最近,并且也最容易用明显的方式查看出来,竞争最激烈),对于前端程序员来说,这些混乱简直就是灾难,现代的前端程序员往往最头疼的就是设备适配问题。
上状态码的混乱 + 不同浏览器对 HTTP 支持程度不一 + 前端技术的高速迭代, 最终总会出现各种奇奇怪怪的问题,前端编程在这个地方的编写难度不亚于某些后端代码的编写。
而状态码有可能需要配合一些头部字段来使用,可以查看开发手册来对应开发…
5.HTTP 协议的头部
以下是常见的协议头部,通常以 K-V 的键值对形式出现在报头的请求和响应头部中。有些只有请求报头有,有些只有响应报头有,有些两者都有。
补充:关于协议头部的其他内容,可以去 腾讯云 HTTP 开发教程 中查看一下,或者在 MDN 的 HTTP 开发教程 中看一下。
或者您也可以简单观察一下之前 http 报文发送过程中请求和响应的头部字段。
# 请求报文
GET / HTTP/1.1 # 请求行:请求方法 Web根目录 协议版本, 下面都是请求报头
Host: ip:port # 本次请求的目标 ip 和 port, 这里我抹去了我的 ip:port, 您这里显示的就是一串具体数字
Connection: keep-alive # 代表支持长链接
Cache-Control: max-age=0 # 资源的缓存时间
Upgrade-Insecure-Requests: 1 # 升级不安全请求
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 # 发起请求的客户端具体信息
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 # 本次请求可以接受的一些资源文件格式
Accept-Encoding: gzip, deflate # 支持的压缩
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7 # 支持的语言
# 这里有一段空行, 别忘记了
---------------
# 这里本来是请求正文的部分, 但是我们的浏览器只是做了访问请求, 没有发送任何数据, 因此这里为空
# 响应报文
GET / HTTP/1.1
HTTP/1.1 200 OK
<!-- wwwroot/index.html --><!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title></head><body> <p>I am limou, this is my html!</p></body></html>Connection closed by foreign host.
注意:不过我们写的响应报文有些简陋,您简单看一下浏览器制作的请求报文即可,后面还会带您了解上述没有出现的属性…
另外,提醒您一点 HTTP 不过是大家公认的一直“约定”罢了,对于自己研发的服务器,基本上想怎么处理 http 请求就怎么处理。对服务器来说,不过是“一纸约定”罢。而且就算是浏览器,不同浏览器也对不同版本的 HTTP 的支持不一,哪怕是同版本的也有可能不一。因此对于浏览器,也只是“一纸约定”罢。
那为什么我们需要准许协议约定呢?首先我们要知道做了什么才是遵循协议的行为。
-
如果您查看
HTTP的开发手册,在客户端根据请求的需要设置HTTP的头部字段,然后根据HTTP结构封装为一个完整的http请求发送给服务器(这个过程就是在编写HTTP浏览器的过程)。 -
而对于的服务端程序,得到
http请求后,根据HTTP开发手册解析请求,然后根据开发手册中指定了请求中包含某些头部字段时必须要做什么,服务端程序做对应的实际实现即可(这个过程就是再编写HTTP服务器的过程)。
类比:这就相当于两国战争,一国胜利签署战争协议,如果一个承诺赔偿另外一国物资,然后再协议上书写具体的物资、物资的数量、如何传递物资、何时传递物资、如何制作物资、如何对接物资…等等问题,但是一旦涉及到实际物资的传输过程,具体操作还是两国之间的人来做,只不过是根据协议来操作罢,协议本身没有做什么…
5.1.Content-Type
响应正文的类型/媒体类型有很多种,如果响应没有设置好这个头部,则用户端有可能接受到文件会以乱码的形式呈现出来。
补充:可以 前往 MDN 查看媒体类型 MIME type,尤其是里面的 MIME types 列表 超链接,有所有的不同类型文件对应的媒体类型。
那如果响应正文中的数据具有多种格式怎么办,您可以考虑使用 multipart 格式来包含多个部分。multipart 格式允许您在单个 HTTP 响应中包含多个部分,每个部分可以有不同的内容类型(Content-Type)和内容,常见的使用场景有:发送邮件中的附件、上传文件…
在 http 响应中可以使用 multipart/mixed 或者 multipart/form-data 来包含多个部分,具体的实现方式如下:
- 在响应头部中设置
Content-Type: multipart/mixed或者Content-Type: multipart/form-data - 在每个部分之间使用一个特定的边界字符串进行分隔。这个边界字符串在响应头中的
Content-Type中指定,例如boundary=boundary_string,其中boundary_string是一个唯一的字符串 - 每个部分都包含自己的
Content-Type和内容,您可以在每个部分中设置不同的Content-Type,以适应不同的需要
补充:您也可以 前去 MDN 查看 Content-Type…
5.1.1.多文件的 http 请求
这里我们再来深入理解 HTML 中的表单元素,表单元素的使用能和上面的 multipart 属性对应起来。如果浏览器中有以下的 html 代码,通过 HTML form 提交生成的 POST 请求中,请求头的 Content-Type 由 form 元素上的 enctype 属性指定,我们可以在这里指定多 Content-Type 类型的多文件 http 请求。
<!-- "多文件/多表单元素"传输的表单页面 -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<!-- 带有表单元素的部分 html 页面 -->
<form action="http://ip:port" method="post" enctype="multipart/form-data">
<input type="text" name="description" accept="text/plain" value="some text" /> <!-- some text 是文本框中默认文本, 您可以手动替换为别的, 其中 accept 可以指定用户上传的媒体类型, 体现在用户在选择文件时弹出的资源管理器中, 文件后缀名筛选工具栏中会选择对应数据的后缀名 -->
<input type="file" name="myFile" accept="text/html"/> <!-- 这里假设选择一个 foo.txt 文件, 然后点击上传按钮 -->
<button type="submit">Submit</button>
</form>
</body>
</html>
html 文件经过浏览器渲染后,得到页面结果如下。
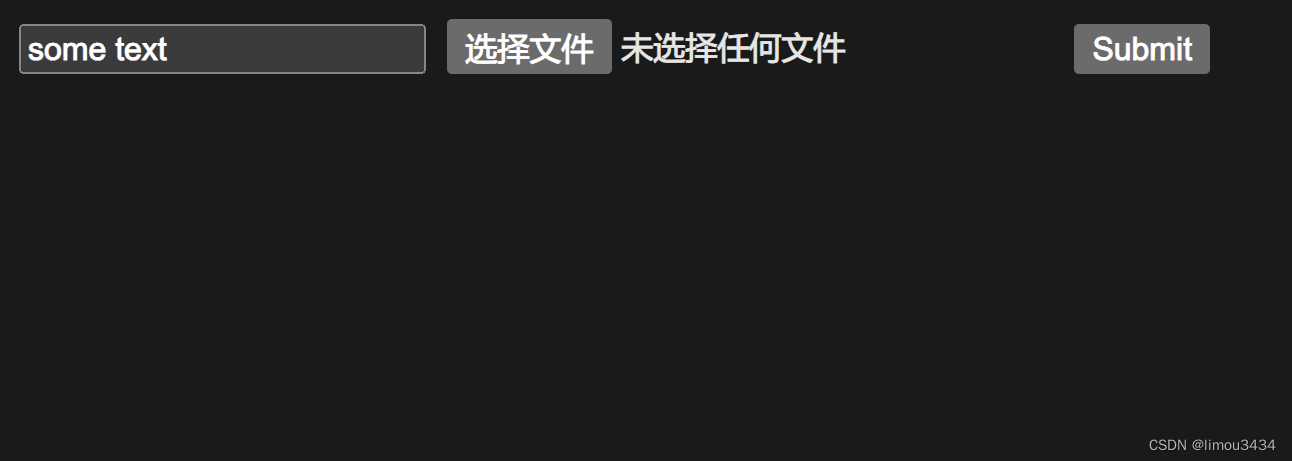
foo.txt 内的内容如下:
# foo.txt
> cat foo.txt
Hello, I am limou.
请求头看起来像这样:
# 根据表单提交得到的 http 请求
POST / HTTP/1.1
Host: ip:port
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36
Content-Length: 308
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7
Cache-Control: max-age=0
Connection: close
Content-Type: multipart/form-data; boundary=----WebKitFormBoundarydi1zApKBm3AaE1Jz
Origin: http://ip:port
Referer: http://ip:port/
Upgrade-Insecure-Requests: 1
----WebKitFormBoundarydi1zApKBm3AaE1Jz
Content-Disposition: form-data; name="description"
some text
----WebKitFormBoundarydi1zApKBm3AaE1Jz
Content-Disposition: form-data; name="myFile"; filename="foo.txt"
Content-Type: text/plain
Hello, I am limou.
----WebKitFormBoundarydi1zApKBm3AaE1Jz
而表单中的每一个 name,对应的媒体类型不需要额外设置,浏览器会根据文件的后缀名帮助填充。在上面的示例中,boundary 设置的是边界字符串,用于分隔不同的表单元素部分(通常也会由浏览器自己生成,这个标识通常是依靠某些算法来生成的随机标识)。响应正文中包含了两个部分,第一个部分的内容类型是 text/plain,第二个部分的内容类型是 application/json。
如果是自定义的媒体类型,可能就需要自己实现封装 http 请求(也就是自己实现一个浏览器)…
5.1.2.多文件的 http 响应
类似的,服务器在接收到这些文件后,可以通过相应的后缀名或者文件类型来确定文件的类型,然后进行相应的处理,也可以返回类似下面的响应(不过由于我们的服务端程序是自己实现的,因此您需要在之前编写的网络代码中手动添加头部信息…)。
# 包含多个 Content-Type 的 http 响应
HTTP/1.1 200 OK
Content-Type: multipart/mixed; boundary=boundary_string # 这里设定了不同 boundary_string 的分隔符
--boundary_string
Content-Type: text/plain
某些文本内容
--boundary_string
Content-Type: application/json
{
"key": "value"
}
--boundary_string
5.2.Content-Length
代表响应正文的长度,可以把报文中的报头和正文做分离。注意是正文自己的字节长度,也就是是指请求正文或响应正文的长度,是以十进制数字表示的八位字节的数目。换句话说,它是消息体的字节长度。举个例子,如果一个 http 响应的正文长度为 100 字节,那么 <length> 就是 100。这个长度通常用来解析消息体的边界,以便正确地获取和处理消息的内容。
在较为现代的浏览器中,请求或响应的消息体长度大于零,则消息的头部会包含 Content-Length 字段,该字段的值就是消息体的长度。例如:
# http 请求中的 Content-Length 部分
Content-Length: 100
这样服务端程序就知道要读取多少字节的数据作为消息体。
5.3.Host
客户端告知服务器,所请求的资源在哪个 ip:port 对应的服务器上,和 URL 内设置 ip:port 保持一样。
补充:您也可以 前去 MDN 查看 Host…
5.4.User-Agent
声明用户的操作系统和浏览器版本信息,不过这个很复杂…
补充:您也可以 前去 MDN 查看 User-Agent…
5.5.Location
一般搭配 3xx 状态码使用,可以设置一个 url 值(可以是绝对地址,也可以是相对地址),告诉客户端接下来要去哪里访问。
永久重定向典型的就是 301,临时重定向典型的就是 302 和 307 状态。具体来说,就是浏览器客户端向服务端发起 http 请求,服务端再返回 http 响应的同时,除了在响应内部加上状态码,还需要设置头部字段 Location 告知新的跳转地址。浏览器客户端接收到新的地址后,会自动根据这个地址向服务端自动重新发送 http 请求,这次服务端返回的 http 响应就可以返回 url 对应的资源。
我们来用代码演示一下,这里我只需要修改两个文件 http_server.cpp 和 index.html 即可。
//http_server.cpp
#include <iostream>
#include <vector>
#include <memory>
#include <fstream>
#include <cassert>
#include "http_server.hpp"
#include "usage.hpp"
#include "util.hpp"
#define ROOT "./wwwroot"
#define HOMW_PAGE "index.html"
void HandlerHttpRequest(int sockfd)
{
//1.读取请求
char buffer[1024] = { 0 };
ssize_t s = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
//2.分割请求信息
std::vector<std::string> vline;
Util::_CutString(buffer, "\n", &vline);
for (auto& it : vline)
std::cout << "---" << it << std::endl;
std::vector<std::string> vblock;
Util::_CutString(vline[0], " ", &vblock);
//3.获取资源
std::string target = ROOT; //"./wwwroot"
std::string file = vblock[1];
if (file == "/")
file = "/index.html";
target += file; //"./wwwroot/index.html"
std::cout << "***" << target << "***" << "\n\n";
std::string content;
std::ifstream in(target);
if (in.is_open())
{
std::string line;
while (std::getline(in, line))
{
content += line;
}
}
in.close();
//2.返回响应
std::string httpResponse;
if (content.empty()) //资源不存在的话
{
httpResponse = "HTTP/1.1 302 FOUND\r\n"; //状态行
httpResponse += "Location: https://blog.csdn.net/m0_73168361?spm=1000.2115.3001.5343"; //重定向到我的 CSDN 博客
}
else
{
httpResponse = "HTTP/1.1 200 OK\r\n"; //状态行
}
httpResponse += "\r\n"; //暂时不写响应报头,直接添加空行(现代的浏览器大部分都可以补充上报头的属性,依旧可以进行自定义识别)
httpResponse += content; //暂时不写响应报头,直接添加空行(现代的浏览器大部分都可以补充上报头的属性,依旧可以进行自定义识别)
send(sockfd, httpResponse.c_str(), httpResponse.size(), 0);
}
int main(int argc, char const* argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(-1);
}
std::unique_ptr<HttpServer> hs(new HttpServer(atoi(argv[1]), HandlerHttpRequest));
hs->Start();
return 0;
}
服务端运行程序准备好接受响应,然后浏览器访问该服务器,获取到下面的 html 页面后,渲染出页面。
<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<p>I am limou, this is my html!</p>
<form action="/error.html" method="POST"> <!-- 注意这里是相对 url 地址, 会根据当前浏览器 URL 地址栏中的内容来查询服务器资源 -->
User:<input type="text" name="user"><br>
Password:<input type="password" name="pwd"><br>
<input type="submit" value="登录"><br> <!-- submit 会使得表单数据添加到 URL 中, 导致被提交, 但是 button 不会 -->
<!-- 其中 name 就是提交表单数据时 URL 地址栏中的关键字 -->
</form>
</body>
</html>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<p>I am limou, this is my html!</p>
<form action="/error.html" method="POST">
User:<input type="text" name="user"><br>
Password:<input type="password" name="pwd"><br>
<input type="submit" value="登录"><br> <!-- submit 会使得表单数据添加到 URL 中, 导致被提交, 但是 button 不会 -->
<!-- 其中 name 就是提交表单数据时 URL 地址栏中的关键字 -->
</form>
</body>
</html>
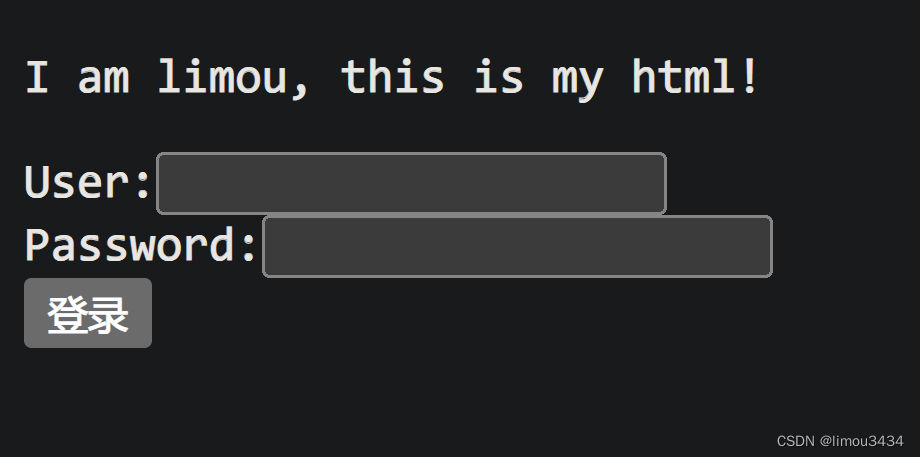
点击登录时,由于找不到对应的资源,就会发生重定向,最终跳转到我在 CSDN 上的一个博客网页。
利用这个重定向的特点,就可以在站内编写不同错误码对应的错误页面,一旦资源不存在,就可以跳转到这些错误页面(因此会有人对这些错误页面进行自定义,更加符合调试需求和个性化需求)。
也可以进行用户登录的跳转,或者某些网站因为 ip 进行更换,因此可以利用这个 Location 来让老用户跳转到新 ip 而不是旧 ip。
因此永久重定向就是真的要更换 ip,而临时重定向就是短暂转移 ip。设置 301 时,浏览器会根据响应中重定向的 url,以后替换为请求该 url。而设置 302、307 就只会在每次请求时,才发生重定向。
补充:因此这里有一个有趣的现象,如果一个服务器崩溃了,但是在崩溃之前发送了
301和重定向url,此时客户端请求该服务器的url时依旧是成功的,原因就是浏览器存储了重定向的url,把用户原来访问的url永久替换为重定向url了。
另外有些重定向可能会被浏览器更改请求方法。
注意:您可能察觉到了,无论错误码是什么,只要我们填写了
Location属性,就可以进行网页跳转,这些都需要程序员自己决定,最好是遵循官方规则,避免造成混乱。
补充:您也可以 前去 MDN 查看 Location…
5.6.Cookie、Set-Cookie
用于在客户端存储少量信息,通常用来实现会话管理的功能。
HTTP 协议的无状态会有一个问题,如果一些网站需要登录信息,在跳转的时候就会丢弃登录信息,这就会比较扯。但 HTTP 协议本身是无状态的,因此需要把这些状态记录交给浏览器,HTTP 请求和响应中各有属性 Cookie 和 Set-Cookie。服务器使用 Set-Cookie 响应头部向用户代理(一般是浏览器)发送 cookie 信息,告知客户端存储一对 cookie。
# http 响应中的部分
Set-Cookie: <cookie-name>=<cookie-value>
浏览器接受到响应后,就会把 cookie 值保存起来。浏览器以后对该服务器发起的每一次新请求,都会将之前保存的 cookie 信息通过 Cookie 请求头部再发送给服务器验证(而无需交给用户重写填写)。
而保存这些 cookie 私密信息的就是 Cookie 文件,有可能被浏览器设置为磁盘文件或者内存文件。但如果 cookie 文件将所有私密数据都存储在本地文件,则一旦个人计算机被黑客入侵,就会全部被泄露(这非常不安全)。并且还有可能被中间人截取明文 cookie 信息,导致个人隐私泄露。
因此现在主流的 cookie 文件虽然依旧保留,但是在服务端接受到一个用户登录的信息后,使用算法来形成一个唯一 id 给这些私密信息命名。然后把该 id 返回给用户,再保存在用户的 cookie 文件里。后续客户端使用 cookie 文件中 id 通过 Cookie 请求头部发送给服务端即可。
现在的 cookie 文件中确实没有直接的隐私信息被中间人获取到了,那有没有可能被盗用呢?还是有可能,那这和直接存储隐私文件有什么区别呢?最大的区别就在于:
- 即便黑客可以拿到你的
cookie信息,他也无法直接看到很多具体的私密信息 - 此时用户的数据安全由客户转移到软件开发者,这比小白用户更加安全,例如识别出
ip地址的异常切换,则令cookie无效 - 黑客为了不让服务器检测到
ip转移的不合理之处,可能盗取到cookie后不直接使用,而是逐步切换ip,让cookie请求看上去比较正常。但服务端还可以设置cookie的超时时间,避免cookie长期有效,让黑客有足够的时间欺骗服务器关于ip地址的转化
我们添加 http_server.cpp 中关于 cookie 头部的具体内容。
//http_server.cpp
#include <iostream>
#include <vector>
#include <memory>
#include <fstream>
#include <cassert>
#include "http_server.hpp"
#include "usage.hpp"
#include "util.hpp"
#define ROOT "./wwwroot"
#define HOMW_PAGE "index.html"
void HandlerHttpRequest(int sockfd)
{
//1.读取请求
char buffer[1024] = { 0 };
ssize_t s = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
//2.分割请求信息
std::vector<std::string> vline;
Util::_CutString(buffer, "\n", &vline);
for (auto& it : vline)
std::cout << "---" << it << std::endl;
std::vector<std::string> vblock;
Util::_CutString(vline[0], " ", &vblock);
//3.获取资源
std::string target = ROOT; //"./wwwroot"
std::string file = vblock[1];
if (file == "/")
file = "/index.html";
target += file; //"./wwwroot/index.html"
std::cout << "***" << target << "***" << "\n\n";
std::string content;
std::ifstream in(target);
if (in.is_open())
{
std::string line;
while (std::getline(in, line))
{
content += line;
}
}
in.close();
//2.返回响应
std::string httpResponse;
if (content.empty()) //资源不存在的话
{
httpResponse = "HTTP/1.1 302 FOUND\r\n"; //状态行
httpResponse += "Location: https://blog.csdn.net/m0_73168361?spm=1000.2115.3001.5343"; //重定向到我的 CSDN 博客
}
else
{
httpResponse = "HTTP/1.1 200 OK\r\n"; //状态行
httpResponse += "Content-Type: text/html\r\n"; //状态行(支持文本和html)
httpResponse += "Content-Length: " + std::to_string(content.size()) + "\r\n"; //状态行(添加正文长度)
httpResponse += "Set-Cookie: This is a cookie.\r\n"; //状态行(设置 cookie)
}
httpResponse += "\r\n"; //暂时不写响应报头,直接添加空行(现代的浏览器大部分都可以补充上报头的属性,依旧可以进行自定义识别)
httpResponse += content; //暂时不写响应报头,直接添加空行(现代的浏览器大部分都可以补充上报头的属性,依旧可以进行自定义识别)
send(sockfd, httpResponse.c_str(), httpResponse.size(), 0);
}
int main(int argc, char const* argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(-1);
}
std::unique_ptr<HttpServer> hs(new HttpServer(atoi(argv[1]), HandlerHttpRequest));
hs->Start();
return 0;
}
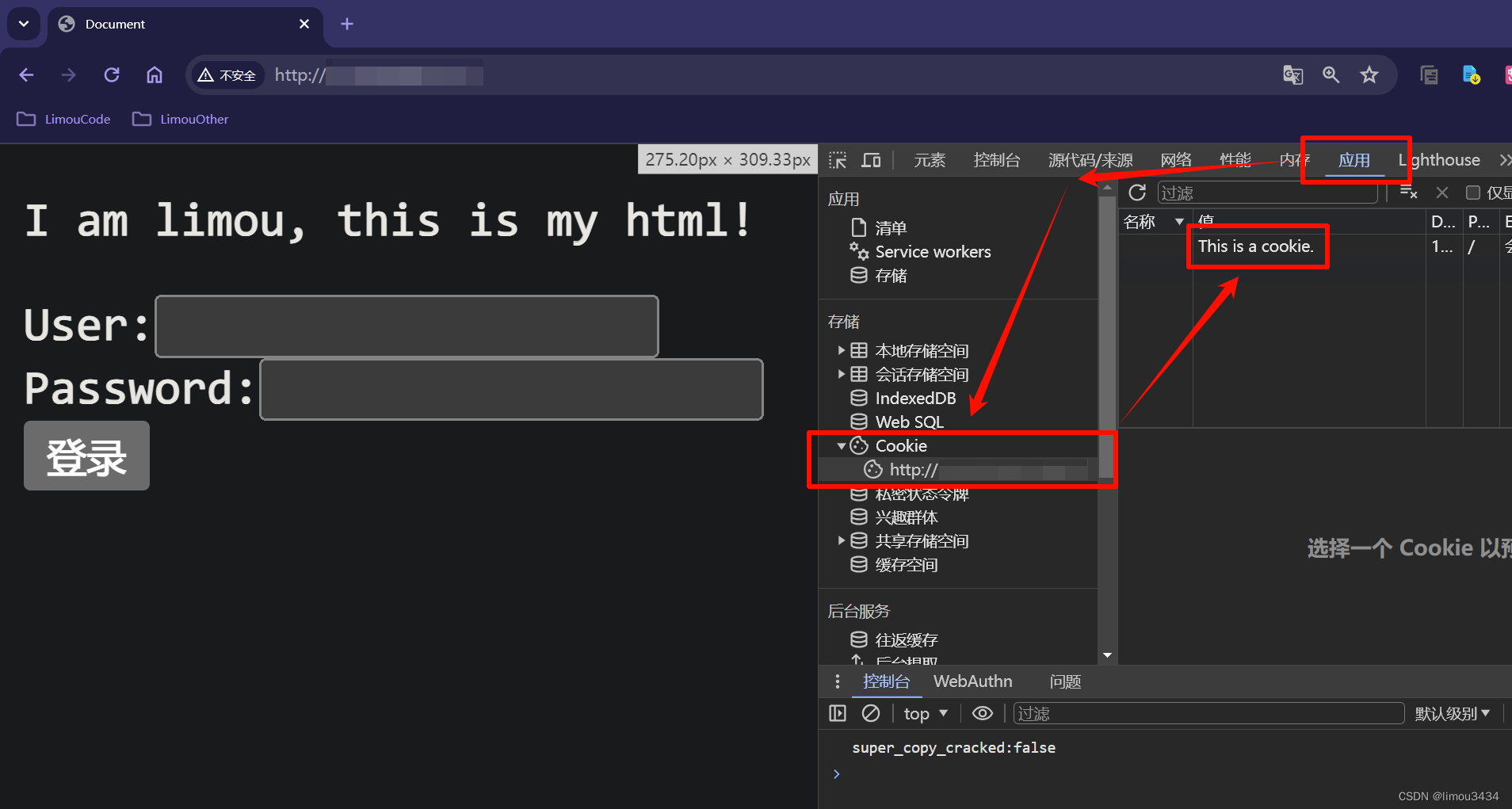

也可以使用 JS 代码来查看。
并且往后浏览器发送请求时,还可以在运行服务端程序的服务器上看到带有 cookie 的请求。
# 服务端程序设置 cookie 后浏览器发送的请求
$ ./http_server port
--> 标准日志:[NORMAL][pid:10844][2024-5-7 23:10:25] 用户日志:socket() success sock.hpp 42
--> 标准日志:[NORMAL][pid:10844][2024-5-7 23:10:25] 用户日志:bind() success sock.hpp 60
--> 标准日志:[NORMAL][pid:10844][2024-5-7 23:10:25] 用户日志:listen() success sock.hpp 71
--> 标准日志:[NORMAL][pid:10844][2024-5-7 23:10:30] 用户日志:accept() success sock.hpp 86
---GET / HTTP/1.1
---Host: ip:port
---User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36
---Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
---Accept-Encoding: gzip, deflate
---Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7
---Cache-Control: max-age=0
---Connection: close
---Cookie: This is my cookie. # 这个 cookie 是我以前设置的旧的 cookie
---Upgrade-Insecure-Requests: 1
---
***./wwwroot/index.html***
--> 标准日志:[NORMAL][pid:10844][2024-5-7 23:10:30] 用户日志:accept() success sock.hpp 86
---GET /favicon.ico HTTP/1.1 # 这是对网站图标资源的请求, 是浏览器得到 URL 后默认发送的一个请求
---Host: ip:port
---User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36
---Accept: image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8
---Accept-Encoding: gzip, deflate
---Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7
---Connection: close
---Cookie: This is a cookie.
---Referer: http://ip:port/
---
***./wwwroot/favicon.ico***
另外 cookie 也可以设置有效时间,不过需要额外借助两个头部字段。
-
Expires 字段:
Expires字段指定了Cookie的过期时间,以格林威治标准时间(GMT)格式表示。当浏览器收到带有Expires字段的cookie后,会将其保存到指定的过期时间。示例:Set-Cookie: sessionId=abc123; Expires=Wed, 21 Oct 2024 07:28:00 GMT -
Max-Age 字段:
Max-Age字段指定了 Cookie 的最大存活时间,以秒为单位表示。当浏览器收到带有Max-Age字段的 Cookie 后,会将其保存指定的秒数后过期。示例:Set-Cookie: sessionId=abc123; Max-Age=3600
这两个字段的作用相似,但使用方式稍有不同。一般来说,Max-Age 字段比 Expires 字段更推荐,因为它可以指定相对时间而不是绝对时间,更加灵活,且不受时区的影响。如果同时设置了 Expires 和 Max-Age 字段,浏览器会优先使用 Max-Age 字段。
但只有一个 cookie 设置还远远做不到会话管理,因为相关 cookie 的维护工作还有很多,哪怕浏览器已经做了一半的工作,服务端也会涉及到加密、保存用户数据、密码或 cookie 认证方式等问题,我在未来相关的 C++ 项目开发中会进行提及。
补充:您也可以 前去 MDN 查看 Cookie 和 前去 MDN 查看 Set-Cookie…
5.7.Refere
显示请求是从哪一个网页转过来的,这个字段还挺有用的:
- 网站统计和分析:通过收集
Referer信息,网站管理员可以了解访问者是从哪些页面跳转过来的,从而分析流量来源和用户行为 - 防盗链:有些网站希望他们的内容只能在特定的网页上访问,而不是被其他网站直接引用。这时可以通过检查
Referer来判断请求的来源,如果不是指定的来源,则拒绝提供服务 - 安全验证:在某些情况下,服务器可能需要验证请求的合法性。通过检查
Referer字段,服务器可以判断请求是否来自于预期的来源,以防止恶意请求或CSRF(跨站请求伪造)攻击 - 定向跳转:有些网站可以根据用户的
Referer信息,对用户进行定向跳转,提供更精准的服务或信息
吐槽:您还需要注意一点,我们在编写自己的服务端程序时,如果我们对客户端的请求单独作解析,但是却不遵守相应的规则来使用,那
http实际上也就是一个口头约定…举个例子,在服务端自己解析
http请求,即使在请求头中包含了Connection: close字段,但您仍然选择在具体实现中不关闭连接,那么这个连接仍然会保持打开状态,从而实现了长连接的效果。
HTTP协议本身并没有强制要求服务器在收到Connection: close字段时立即关闭连接,而是作为一种约定。如果你在服务端实现中选择不遵循这种约定,而是保持连接处于打开状态,那么客户端和服务器之间的连接就会继续保持长连接的状态,允许在同一连接上进行多次请求和响应的通信。不过对于现代浏览器客户端来说,对用户发送的
http请求和服务端回复的http响应会自动进行补全、封装、做出对应的动作…
补充:跨站请求伪造(
CSRF),也称为“冲突请求伪造”,是一种网络安全攻击,利用了用户在当前已经登录的身份的情况下,来执行未经用户授权的操作。攻击者通过伪造一个请求,然后诱使受害者访问包含该请求的页面,从而执行攻击者设计的操作,例如修改用户账户信息、发送恶意邮件等。攻击者通常会利用受害者已经在目标网站上的有效会话(如
cookie),并在受害者不知情的情况下发送恶意请求。攻击者可以通过各种方式诱使受害者访问包含恶意请求的页面,例如通过社交工程手段、恶意链接、钓鱼网站等方式。
CSRF攻击的危害在于,它可以以受害者的身份执行操作,从而导致信息泄露、账户劫持、恶意操作等后果。对于网站开发者来说,要防范CSRF攻击,通常需要采取一些安全措施,例如使用随机生成的token验证请求、检查Referer字段、使用SameSite Cookie等。对于用户来说,应当保持警惕,不轻易点击可疑链接,避免在不信任的网站上登录敏感账户。
补充:您也可以 前去 MDN 查看 Referer
6.HTTP 协议的缺陷
6.1.HTTP 的长短链接问题
最初版本的 HTTP 协议并没有版本号,后被定位在 0.9 以区分后来的版本。HTTP/0.9 极其简单:请求由单行指令构成,以唯一可用方法 GET 开头,其后跟目标资源的路径(一旦连接到服务器,协议、服务器、端口号这些都不是必须的)。
# http/0.9 的请求
GET /mypage.html
响应也极其简单,只包含响应文档本身。
# http/0.9 的响应
<html>这是一个非常简单的 HTML 页面</html>
HTTP/0.9 的响应内容并不包含 HTTP 头。这意味着只有 HTML 文件可以传送,无法传输其他类型的文件。也没有状态码或错误代码。一旦出现问题,一个特殊的包含问题描述信息的 HTML 文件将被发回,供人们查看。
后来发展的 HTTP/1.0 增加了很多有用的字段和方法,也基本就是我上面提及的那些内容…
不过,HTTP/1.0 还是有一些小缺陷的。一张完整的网页,会由非常多的资源构成。而我们之前写的都是短链接,我们处理一个 http 请求就直接关闭了 TCP 服务套接字,一旦资源较多,就会不断创建 TCP 套接字(多个短链接对应多个 http),因此最好是一个 TCP 套接字处理多个 http 请求(一个长连接对应多个 http)。
但 HTTP1.0(多条链接多条请求, 短链接) 内没有约定关于长短链接的问题,而现在常用的版本 HTTP/1.1(一条链接多条请求, 长链接) 和 HTTP/2.0 则内含有关于链接的约定。
对应长连接的头部字段就是 Connection: keep-alive 或 Connection: close。当然,即使客户端请求头中包含了 Connection: keep-alive 字段,服务器也有权决定是否关闭连接。如果服务器内部不支持长连接,它可能会选择在每个请求完成后关闭连接,而不管客户端的请求头中是否包含了 Connection: keep-alive 字段。
补充:您也可以 前去 MDN 网站查看 Connection。
6.2.HTTP 的数据安全问题
HTTP 本身是不安全的,哪怕使用 POST 提交数据也是一样的,这点可以使用抓包工具来体现。我们用 POST 来提交一下表单试一试,看看抓包工具能否抓取到账户和密码。
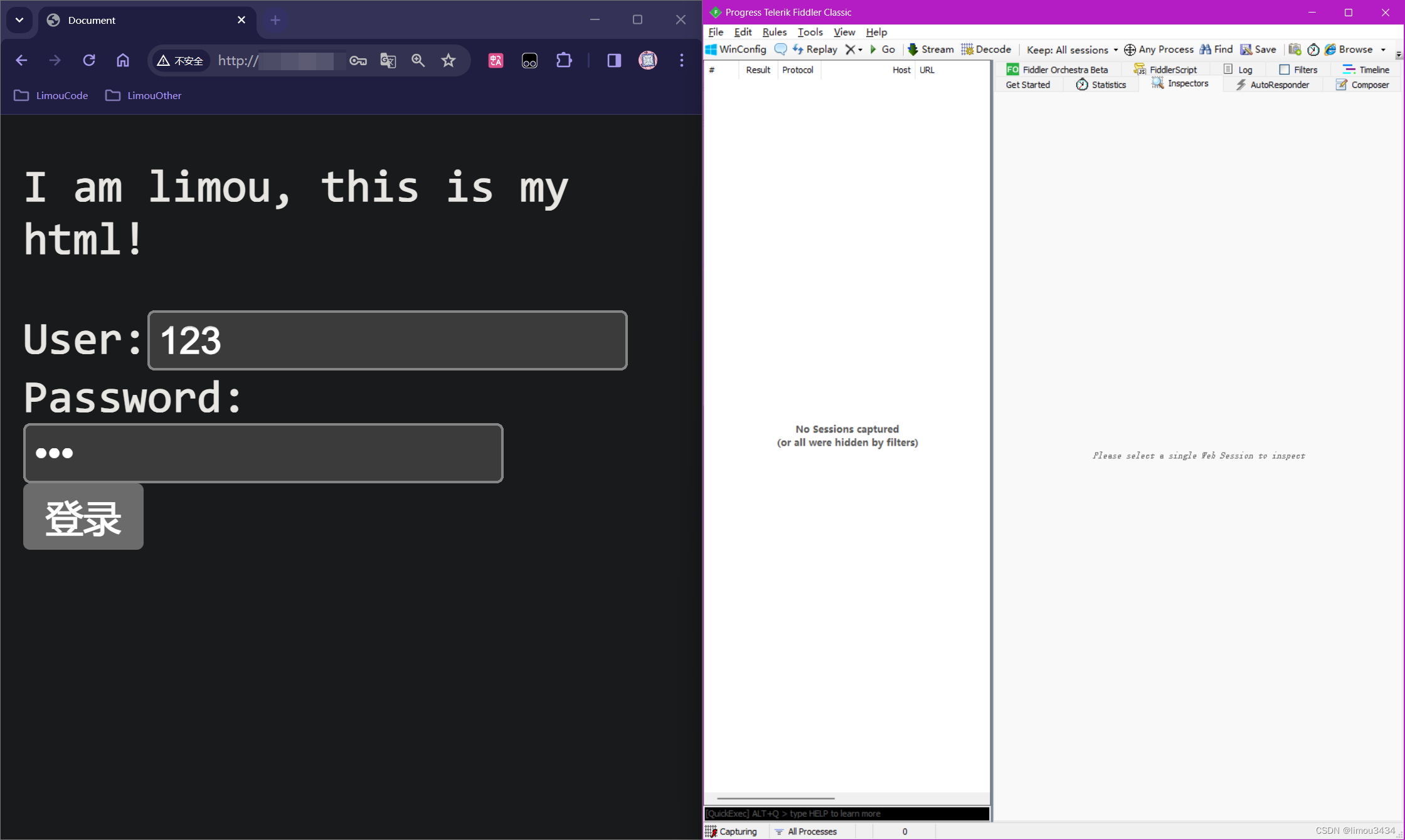
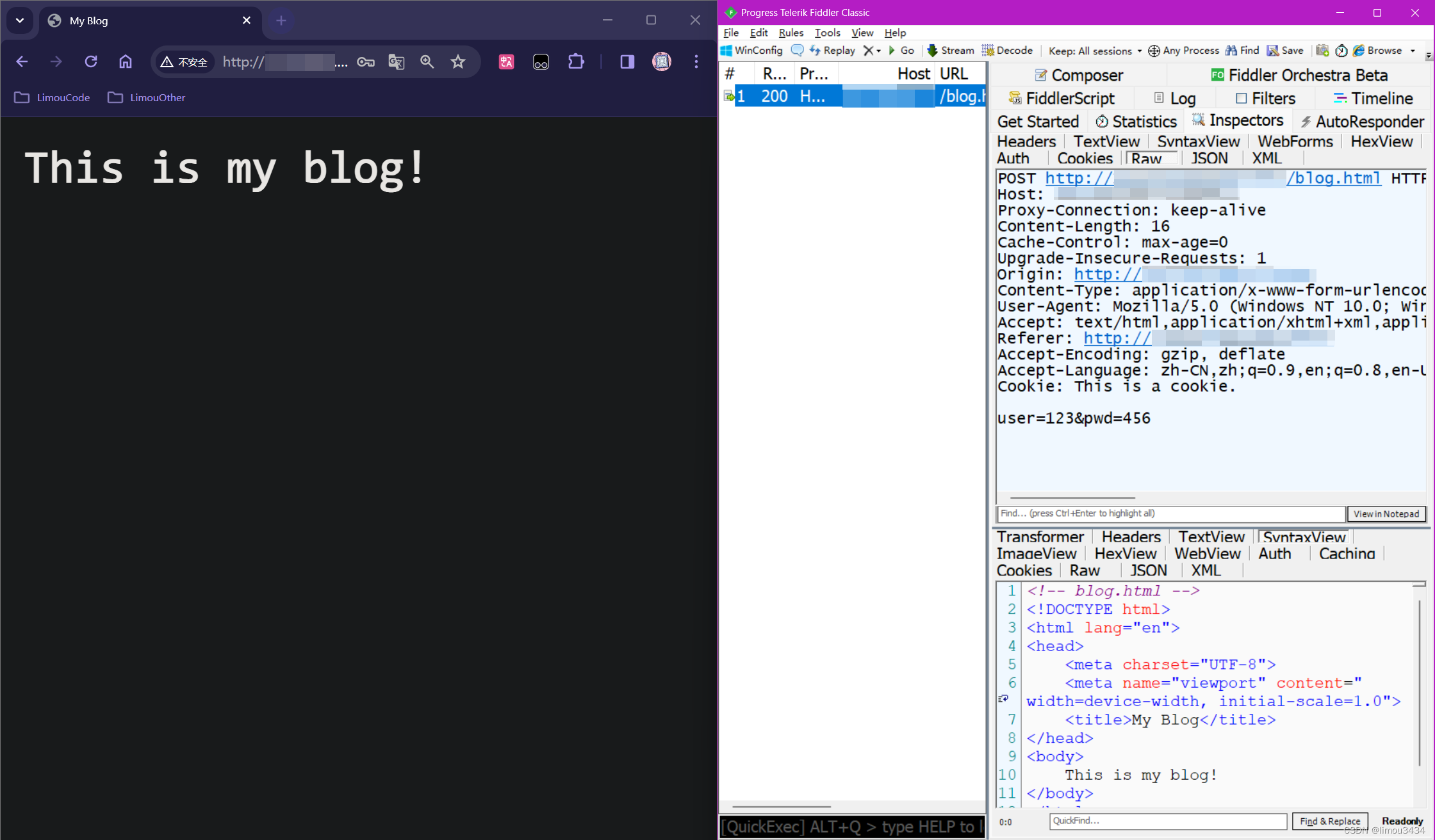
果然,抓取到了明文密码(就在右侧 http 请求的正文中),因此即便 POST 方法是私密的(指不会在 URL 中出现提交时的参数)但也不够安全(能够被中间人抓包得到数据)。
补充:这也就是很多的
http前缀开头的网站都会被浏览器标注不安全警告的原因。
fiddler 会劫持客户的浏览器的请求,由 fiddler 发送请求,再由 fiddler 接受响应,这也就是为什么它可以进行抓包的原因。
因此之后就出现了 HTTPS 协议,这种协议会比 HTTP 协议更加安全,HTTPS 协议就是在 HTTP 的协议内增加了一个 TLS/SSL 加密解密层(也相当于一个软件层),学习 HTTPS,就必须了解一些关于数据安全和加密的基础知识。
6.1.1.数据加密和数据解密
- 加密就是把明文数据经过算法生成密文数据
- 解密就是把密文数据经过算法还原明文数据
在加密和解密的过程中有可能需要用到辅助密钥,密文可以通过密钥来得到明文。
加密的意义何在呢?这里举一个例子,从早些时候的 运营商劫持 现象开始谈起。
- 网络传输的过程中,任何数据包都会中途经过运营商的网络设备(路由器、交换机等),运营商的网络设备有可能解析出传输的数据内容然后进行篡改
- 在下载某一些软件的时候,就是发送一个
HTTP请求给服务器,服务区返回的HTTP响应可能被运营商劫持(或者干脆被黑客劫持),被篡改内容再发送给用户 - 最终出现“明明我点击下载这个软件,却下载了各种‘全家桶’”的现象
因此不要简单认为客户端请求和服务端响应之间是空白的,会经过一系列中间节点/中间设备,每一个节点都有可能出现问题,容易出现所谓的 中间人攻击(也是大部分的网络攻击方式),因此互联网中明文传输是非常危险的事情。
补充:一些手机带有热点功能,实际上就是把手机作为了路由器,其他手机连上这个台手机后发送的所有
HTTP请求都会转到这台开了热点的手机里进行发送,因此如果不加密,理论上手机也是可以进行数据抓包的(包括那些公共热点、公共网络)。
现实生活中的 ARP 欺骗、ICMP 攻击、假 wifi、钓鱼网站、恶意的运营商…都有可能成为中间人。
而加密的方式也有很多,这里提及两种加密方式:
-
对称加密:通过同一个密钥,把“明文”加密为“密文”,并且也能把“密文”解密为“明文”。类似的算法一般公开、速度快、计算量少、效率高,常见的有
DES、3DES、AES、TDEA、TDEA、Blowfish、RC2。补充:最简单的对称加密就是异或,如果设置密钥
key=8888,则明文a=1234经过算法a^key=b=9834得到密文b=9834,只有接受对方持有密钥key,然后再进行b^key=1234才可以重新拿到明文a。 -
非对称加密:需要用两个密钥(公钥和私钥,两者必须是配对的)分别进行加密和解密,而两个密钥是相对概念,把公开的密钥作为公钥,非公开的作为密钥。相当于一把锁(公钥)和一把钥匙(私钥),公钥被公开后,所有人都可以拿公钥进行加密,而只有拿到不公开私钥的人才可以进行解密。这种算法强度和复杂性很高、加密速度较慢、安全性更好,常见的有
RSA、DSA、ECDSA,使用非对称加密需要注意加密解密的效率问题。补充:而关于非对称加密的相关算法我无法像对称加密一样简单列出一个例子,感兴趣您可以 去 Wiki 一下最简单的 RSA 非对称加密算法。另外,您还需要注意,如果私钥和公钥互换身份,那上一次的公钥就是这一次的私钥,因为两者是相对的概念。
数据加密后是否安全的最简单判定,就是让数据强行解密的代价高过数据本身价值。
6.1.2.数据摘要或数据指纹
谈及加密还需要涉及到 数据摘要/数据指纹,其最基本的原理就是利用单向散列函数对信息进行运算,生成一串固定长度的数字摘要。数据摘要本身不是加密机制(这是因为没有解密机制,不过也可以粗糙理解为一种无解密的单向加密),其主要目的只是为了检查数据有没有发生改动,确保数据的唯一性。数据摘要的最大特点,就是任意的文本经过 hash 后形成的摘要都是不一样的,而最常见的散列算法就是 MD5。
$ md5sum <file_name> # 在 Linux 中计算机文件 md5 值的指令
补充:百度网盘在上传文件之前,可能先回对文件做数据摘要,先传输到百度的服务器,查看是否有重复的文件,如果有就把该文件共享给您,然后直接拉满进度条,最后实现“秒传”,因此一个网盘用户基数越多,上传效率就有可能越高。
感兴趣的话您可以去看看差评君关于网盘的运营流程,以及百度网盘做的一系列工作。
6.1.3.加密+摘要=数据签名
而摘要经过加密就会得到数字签名,数据签名我们后面学习数字证书的适合就会
6.1.4.多种加密方式的演化
下面的加密方式我们主要针对中间人攻击进行优化,而对于黑客入侵客户端电脑这种攻击不深入提及(因为有其他的解决方案)…
6.1.4.1.直接对称加密
- 首先假设客户端和服务端都提前持有一个密钥,我们先不管这个密钥是哪一端生成的
- 客户端通过密钥,把明文加密为密文,发送密文请求
- 服务端持有密钥进行解密,得到明文请求,返回密文响应
缺点:如何让网络中的两者同时拥有一份共同的密钥并且不泄露呢?密钥通常是在服务端中生成的,把密钥设置在服务端不难,但是怎么给客户端呢?
- 对称加密的密钥不能公开只能私有,肯定不能直接传输出去(有可能会被中间人直接截取)
- 加密传输出去?别逗了,再用一个新密钥加密密钥传输出去么…传输一个密钥需要一份新密钥,就是一个因果悖论
- 还要设置一个客户端对应一个密钥,密钥还不能被客户端固定化(因为密钥有可能被攻破),需要定期对密钥进行失效,然后重新管理新密钥。因此密钥无法提前预制,还需要维护每个客户端和密钥的关系
6.1.4.2.直接非对称加密
- 服务器先把公钥以明文发送给客户端,保证所有客户端都可以拿到这个公钥(此时也包括中间人),而服务器自己留有一份私钥不外传
- 客户端使用公钥进行加密,密文被传输到网络上,即便是中间人也没有办法立刻对这个密文解密,只有拥有私钥的服务器才可以进行解密
缺点:这里我们确实保证了 Client->Server 方向上的数据安全问题,但服务端怎么发送数据给客户端呢?很明显,客户端没有私钥,无法得知服务端返回的密文响应的具体内容。并且还有一种可能,有可能被中间人伪造服务端公钥,这点我将在下一种加密方法中谈…
6.1.4.3.双重非对称加密
在非对称加密保证 Client->Server 方向的数据安全基础上,如果让客户端也拥有一个私钥,也直接使用非对称加密保证 Server->Client 方向上的数据安全问题可以么?的确可以,中间人的确是无法直接在网络中获取到数据了。但是客户端的私钥该由谁来生成呢?很明显,那如果这份私钥也在服务器生成的话,就又回到一开始使用对称加密的问题了,私钥怎么传输分配给用户?因此只能是客户端自己生成私钥。
缺点:但这有个很严重的问题,也就是中间人伪造服务端公钥问题(前一种方法)。
- 中间人如果先保存了服务端公钥,然后单独生成自己的公钥和私钥,把中间人公钥伪装成服务端公钥发送给用户
- 用户用中间人公钥对自己的请求进行加密(用户无法区分公钥是否是服务器的),发送出去后,又被中间人用中间人私钥解密获取明文请求信息(此时用户信息被泄露)
- 然后中间人自己用之前保存的服务端公钥加密用户的明文请求,再发送给服务器
- 同理,也可以伪装为客户端公钥发送给服务端,服务端的响应也会被中间人获取
- 此时双向对称加密形同虚设…
另外,还有一个缺陷,就是私钥生成的加密速度比较慢,会导致客户端接受数据较慢,影响用户体验。
6.1.4.4.非对称加密+对称加密
我们再尝试非对称加密结合对称加密。
- 假设服务端具有非对称公钥
S和私钥S',服务器在客户端发起请求时把公钥给回客户端 - 客户端在本地动态生成对称密钥
X,然后把对称密钥X通过S加密发送给服务器,服务端再使用S'得到对称密钥X(对称密钥的加密解密效率高) - 此时双方就得到了对称密钥
X,以后就直接使用X进行加密解密即可(前两步就是密钥协商阶段,后一步就是数据通信阶段),整个过程是安全的
缺点:并且如果 MITM 攻击(中间人攻击)在一开始握手协商的时候进行攻击会怎么样?同时会不会发生中间人伪造服务端公钥的问题?
- 假设中间人在第四种场景中,服务端准备好非对称公钥
S和私钥S',而中间人也准备好非对称公钥M和M' - 然后服务器本想把公钥
S交给了客户端,这个信息可能被中间人劫持,中间人把公钥S保存,并且先替换为自己的公钥M - 然后把公钥
M推送给客户端,客户端在本地生成对称密钥X,只能通过M经过加密发送给服务器,但是中间人又先一步进行劫持,用自己的M'来获取客户端的密钥X(此时密钥泄露,后续的加密通信对于中间人都是暴露的),再通过之前保存的S公钥加密发送给服务端,服务端使用私钥S'进行解密,比中间人晚一步获取密钥X - 现在,客户端、中间人、服务端都知道这把对称密钥
X,所谓的加密形同虚设…
6.1.4.5.非对称加密+对称加密+证书认证
虽然上述的方法都无法根治网络加密的问题,但根据上述方法可以总结出规律:只要已经交互了密钥,中间人就来晚了,无法简单获取传输过程中经过加密的数据。并且而中间人的攻击实际上来自两方面:
- 客户端无法得知公钥是不是服务器的公钥,进而有了盗取数据和修改数据的机会
- 在上述前提下,中间人可能可以篡改数据,只为了传递错误的信息而不为获取实际的信息
因此就有了 CA 认证以及证书的相关概念,为了进一步解决上述问题,在服务端使用 HTTP 协议服务器之前,需要先向 CA 机构申领一份数字证书,内部包含:证书申请者信息,服务器公钥信息。
6.1.4.5.1.数字证书的申请、签发、检验流程?
服务器把证书传输给客户端,客户端从证书里读取公钥就行,证书可以对公钥进行溯源,查验公钥是否经过权威机构的认证,也可以查验是否是自己需要的公钥,这样中间人就无法生成自己的公钥交给客户端,客户端一检查就会发现公钥是假公钥。
补充:公钥的可信度来源于对权威机构的信赖,类似国家政府颁发的身份证。
而没有证书的网站您在访问的时候一定要注意一些提交表单的行为,通常访问这类网站时,浏览器都会做出提示。
Window11 电脑使用 certmgr.msc 可以查看本地存储的数字证书。
申请证书时,我们自己保存好自己的私钥、确认一系列申请信息(公钥/申请者/域名),然后利用类似 .CSR 在线生成网站 这种工具生成请求文件 .csr,最后直接向 CA 机构进行申请即可。
CA 机构经过一系列的合法审核,返回申请者一份证书。那 CA 如何签发证书呢?首先需要使用数字签名,也就是对 INFO 进行散列值,接着使用 CA 机构自己的私钥进行加密,形成一份数据签名。然后把签名和数据放在一起形成一份认证(携带签名的数据)。此时证书内就包含一份数字签名和一份明文信息。
那客户端如何检验证书呢?先把证书中的明文数据和签名做分离,对明文数据重做一次流程生成散列值,然后在通过 CA 机构的公钥来解密签名,查验两个哈希值是否相等,这样即可查验明文数据是否发生数据变动。
因此,公钥就被安全送到客户端,客户端就可以利用服务端公钥 X 来加密自己的对称密钥发送给服务端,服务端就可以利用自己的密钥得到客户端的对称密钥。此时我们发现,中间人好像要开始无从下手了。
6.1.4.5.2.数字证书中的数字签名为何需要加密?
这里注意一个问题,为什么需要 CA 机构用自己的的密钥进行加密呢?
我们可以假设 CA 机构没有使用自己的的密钥 T' 进行加密,此时中间人可以把数字签字和明文数据一起篡改,把明文数据中的公钥替换为自己的公钥,然后其他信息也修改为合法信息,保证整个证书是合法的,然后把数字签名也根据明文数据进行修改。
这样的话,客户端经过检验也会发现,数字签名的内容和明文数据哈希后的数值相同,就错误得到了中间人的公钥。
而如果有 CA 的加密,导致数字签名在世界上只有 CA 机构做到加密,而其他人就无法加密,因此哪怕中间人篡改了明文数据,然后生成对应的数字签名,也无法获得 CA 机构的密钥进行加密。如果中间人强行用了自己的私钥加密,那么客户端就无法拿着 CA 机构给与的公钥进行正确的解密,进而导致识别数字签名和明文数据不匹配。
那如果对中间人真的使用合法的数字签名来忽悠客户端呢?客户端的确是可以检验其合法性,但是也会发现证书内的域名和自己请求的域名不一致,也会停止访问。并且中间人自己的信息也会被泄露,一旦可溯源其认证信息,后面就不是技术问题了,而到了法律层的问题,此时的中间人才是真正意义的无从下手…
后续就是对称加密的传输过程了,可以说此时的加密方案想要破解的难度就大大提升了,再辅助一些其他的策略或机制,大大提高了安全性。
吐槽:高级吧,我们甚至还给网络七层协议之上加了一层“法律约束层”…
补充:只认
CA公钥的行为就导致CA私钥就被赋予了签发数字证书的权力,因此也只有CA机构才能签发证书。
总结:因此到这里我们知道,
HTTPS协议中的数字证书会涉及到三组钥,服务端的公钥S和私钥S',CA机构自己的公钥T和私钥T',客户端自己经过一段时间更新的非对称密钥X。
6.1.4.5.3.CA 机构的公钥怎么在浏览器查看?
浏览器内部就会存储服务端的公钥,CA 机构的公钥 T,对称密钥 X,而且浏览器内部也可以查询服务端的公钥。
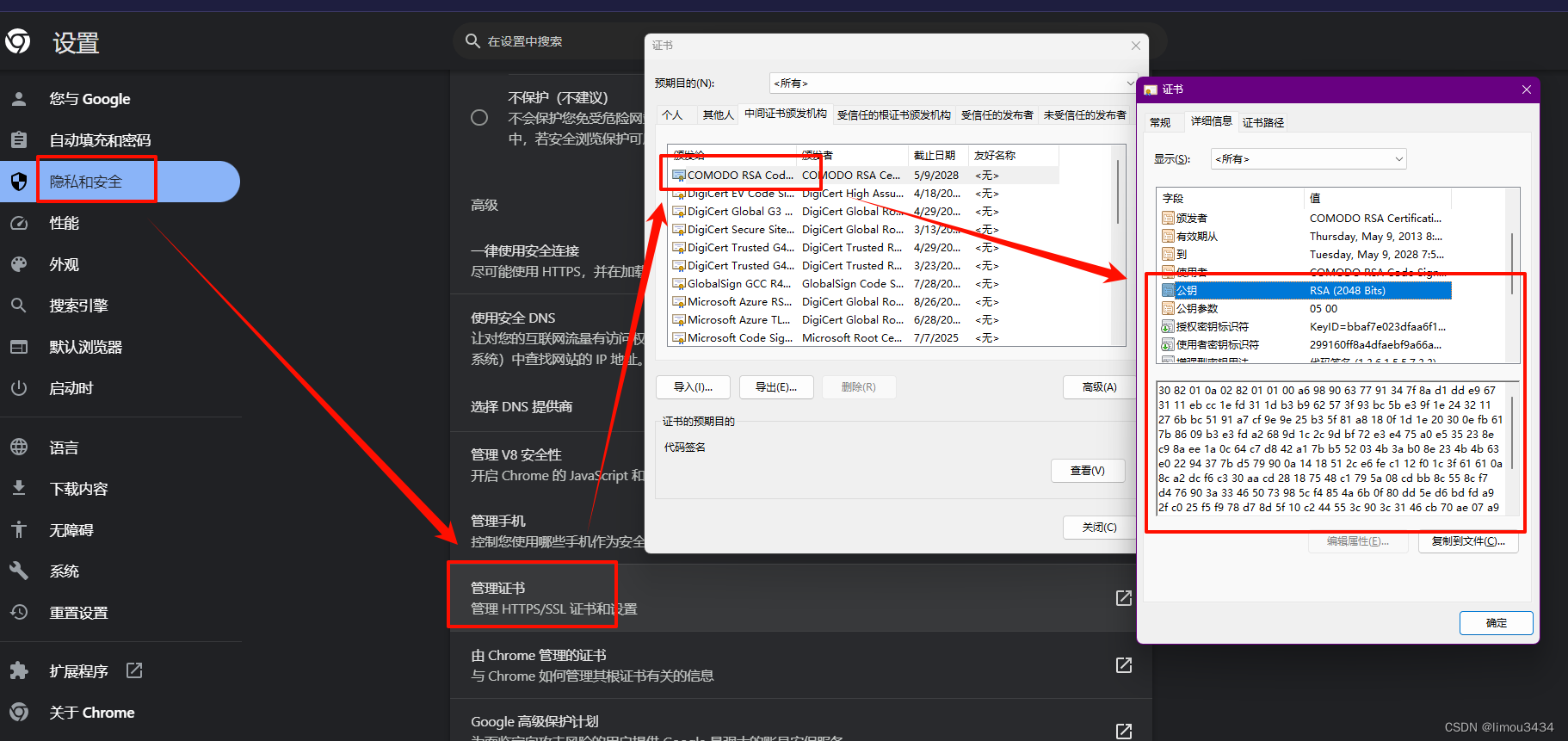
注意:这里可以看到有很多种类型的证书,以后有机会再补充…
6.1.4.5.4.怎么自己申请一份数字证书?
实际上实际开发中的一线程序员很难遇到自己申请数字证书的情况,一般公司都做好了对应的证书申请和证书维护,待补充…