目录
1.网页采集
2.单词翻译
编辑 3.豆瓣排行榜
4.kfs 餐厅信息
实现步骤:(1)指定url
(2)发起请求
(3)获取响应数据
(4)持久化存储
1.网页采集
import requests
if __name__ == '__main__':
#UA伪装
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
}
url='https://www.sogou.com/web?='
#处理url携带的参数,封装到字典()(动态)
kw=input('输入要搜索的信息:')
param={
'query':kw
}
response=requests.get(url,params=param,headers=headers)
page_text=response.text
#将抓取的数据保存下来
with open(kw+'.html','w',encoding='utf-8') as f:
f.write(page_text)
抓取到的数据以html保存下来
2.单词翻译
import requests
import json
if __name__=="__main__":
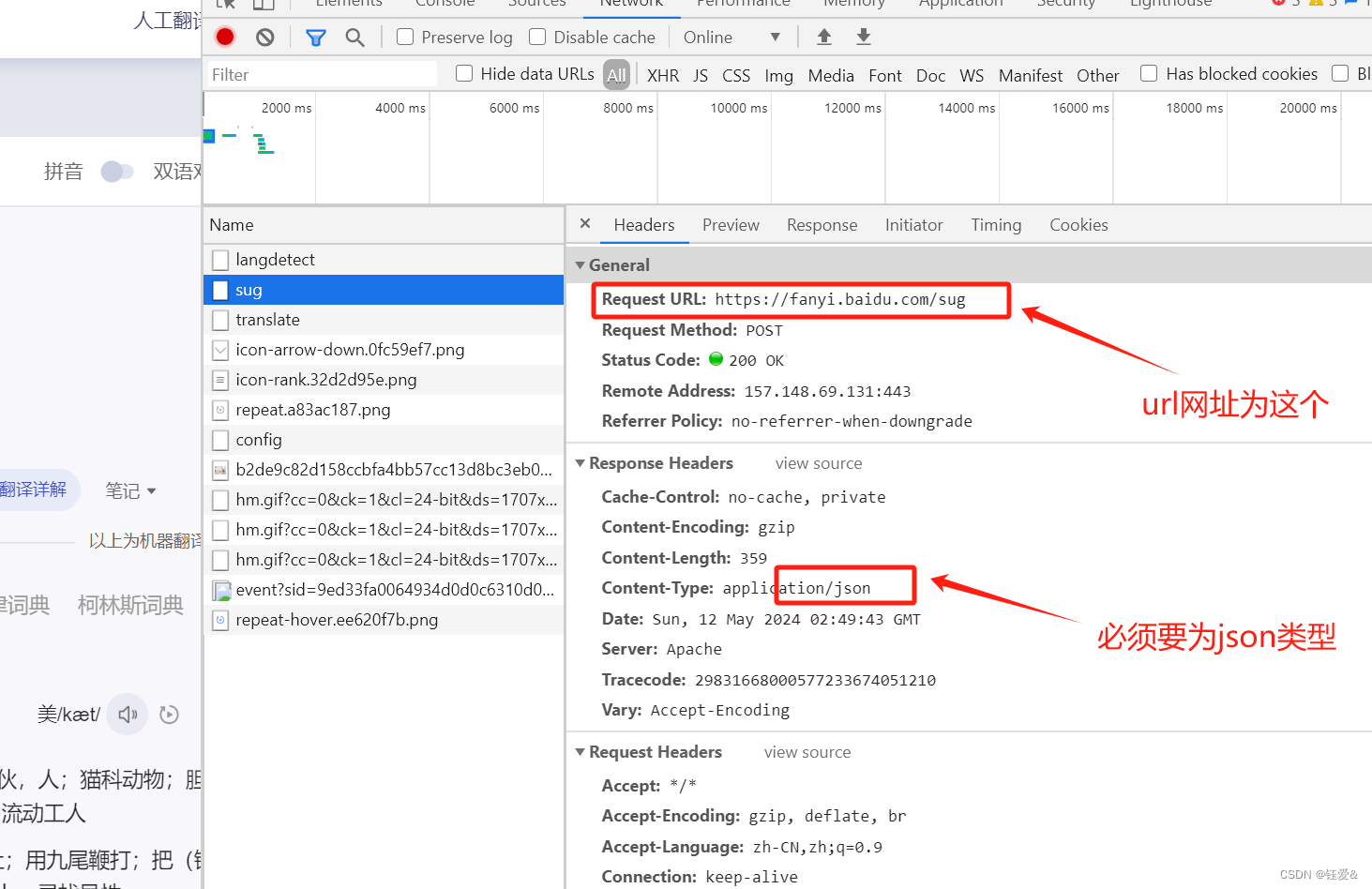
post_url='https://fanyi.baidu.com/sug'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6251 SLBChan/105'
}
word=input("请输入译文:")
data={
'kw':word
}
response=requests.post(url=post_url,data=data,headers=headers)
#获取响应数据;json()方法返回的是对象(响应对象是json类型才可使用)
dic_obj=response.json()
#存储
"""
json.dumps()将数据以json的数据形势写入文件
ensure_ascii=False:禁止使用ascill码值,则使用unicode编码,因为默认为ascill
"""
fp=open(word+'.json','w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False)
 3.豆瓣排行榜
3.豆瓣排行榜
import requests
import json
if __name__ == '__main__':
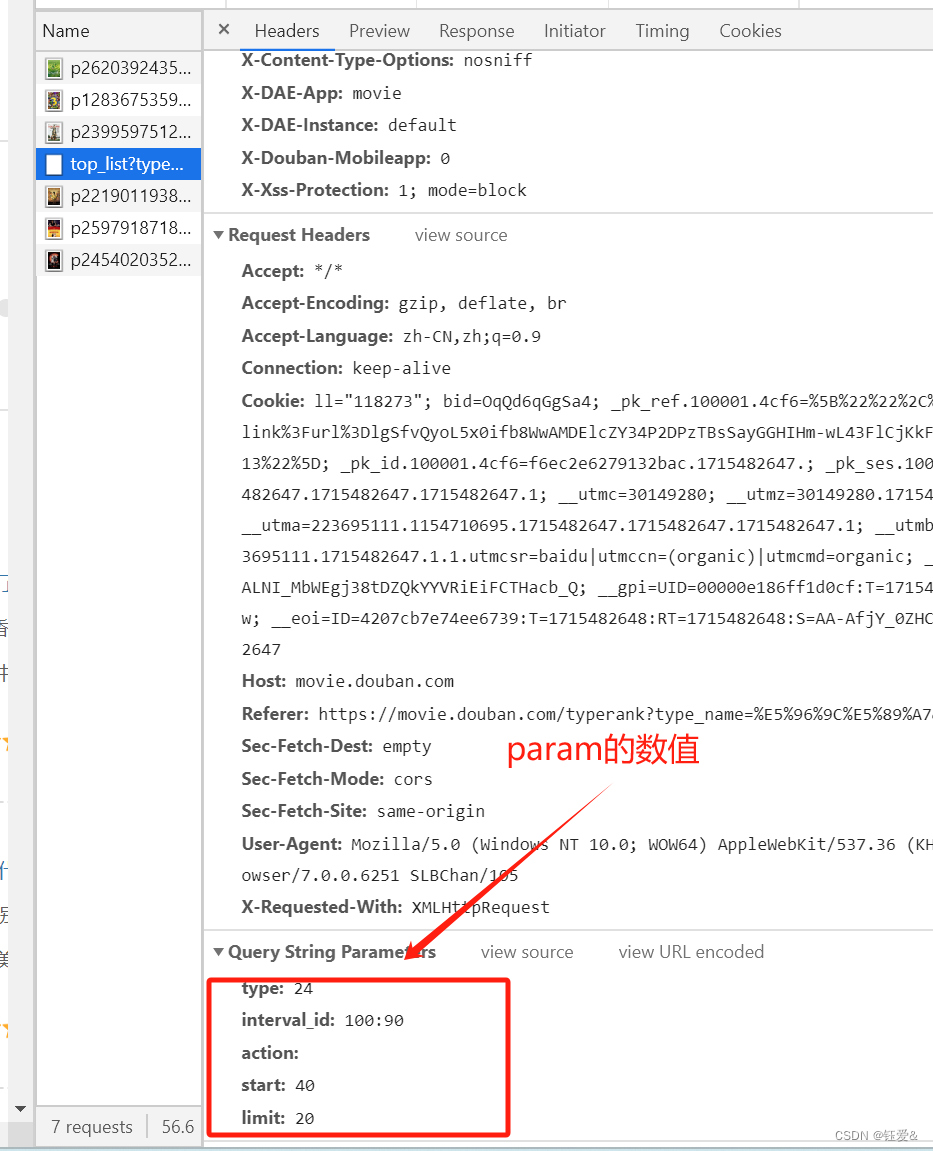
# url='https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=40&limit=20'
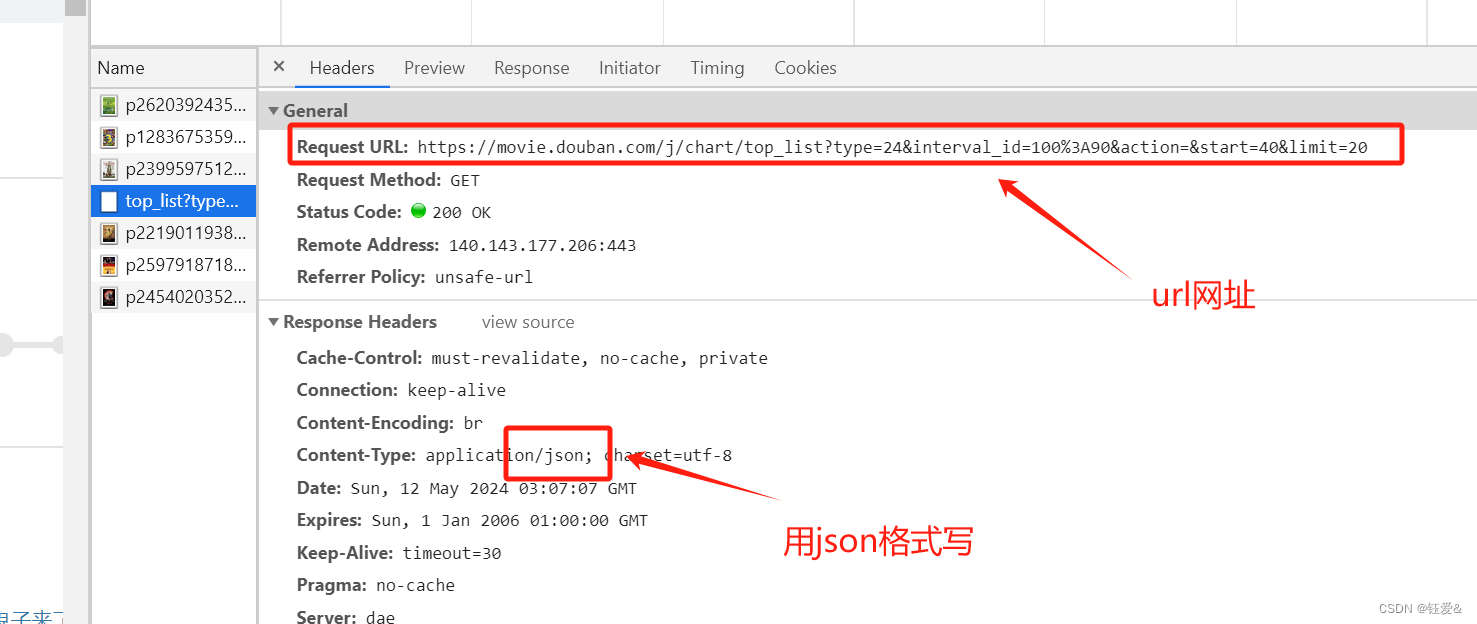
url = 'https://movie.douban.com/j/chart/top_list?'
param={
'type': '24',
'interval_id':'100:90',
'action':'',
'start':'0',#从库中的第几部电影取
'limit':'20'#一次取出的个数
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6251 SLBChan/105'
}
response=requests.get(url=url,params=param,headers=headers)
list_data=response.json()
fp=open('./douban.json','w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False)
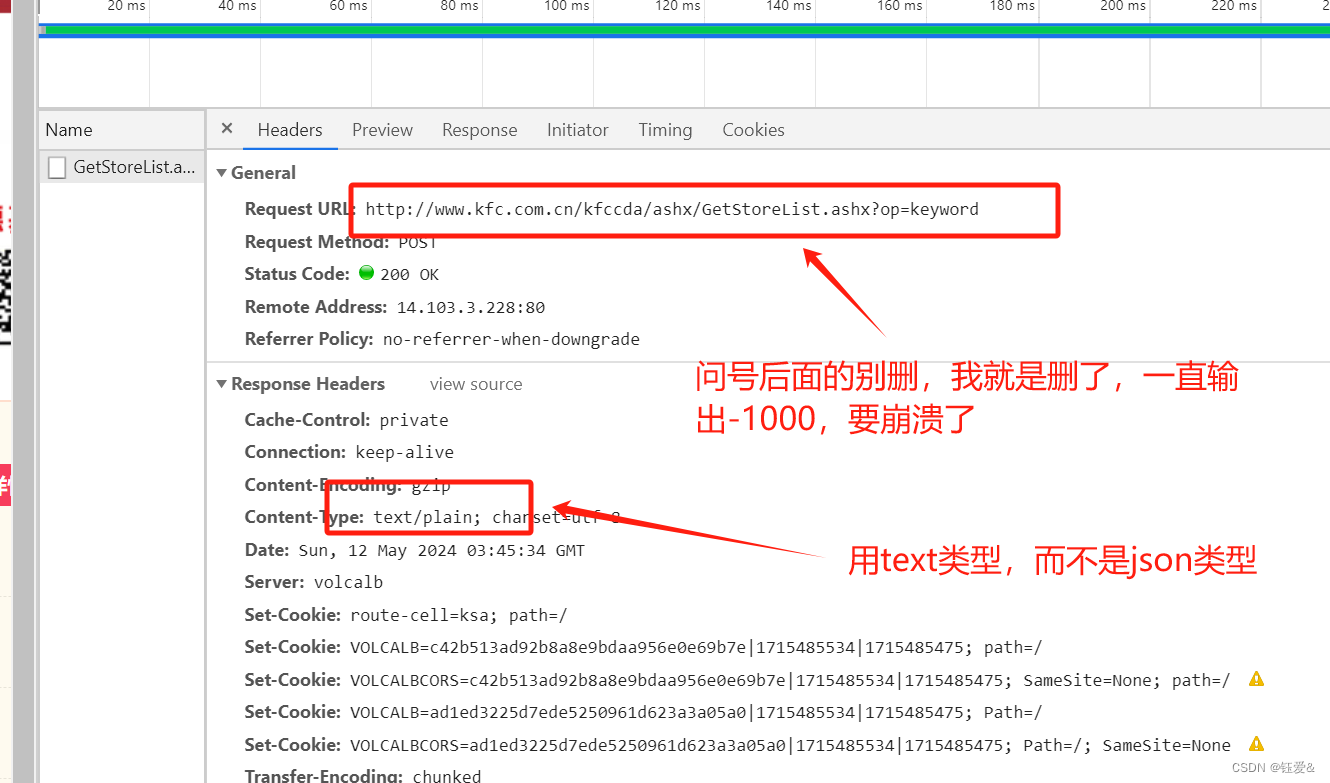
4.kfs 餐厅信息
import requests
import json
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6251 SLBChan/105'
}
address = input("请输入要查询地址:")
page=1
name=[]
while True:
param = {
'cname': '',
'pid': '',
'keyword': address,
'pageIndex': page,#第几页
'pageSize': '10'
}
page+=1
# 获取响应数据
response = requests.get(url=url, params=param, headers=headers)
#json.loads():将json转化为python数据
dict_text=json.loads(response.text)
if len(dict_text['Table1'])==0:
break
else:
name.append(dict_text['Table1'])
b=dict_text['Table']
print(f'{address}一共有{b[0]['rowcount']}家kfc餐厅')
for y in name:#遍历页数
for i in y:#遍历每一页餐厅的具体信息
print(f'餐厅名:{i['storeName']} 餐厅地址:{i['addressDetail']}')
with open(f'{address}_kfc_restaurants.json', 'w', encoding='utf-8') as f:
#indent = 4:缩进空格数,会竖着输出,不然不写就会只有一行
json.dump(name, f, ensure_ascii=False,indent=4)