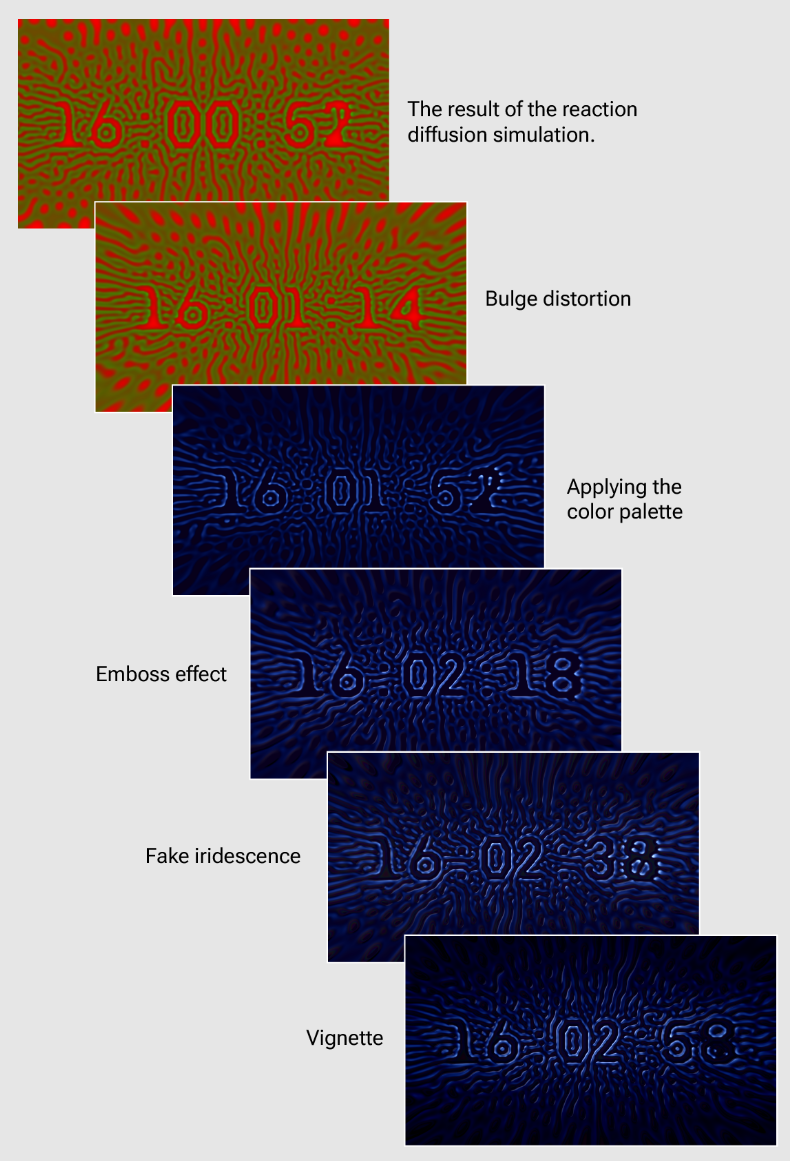
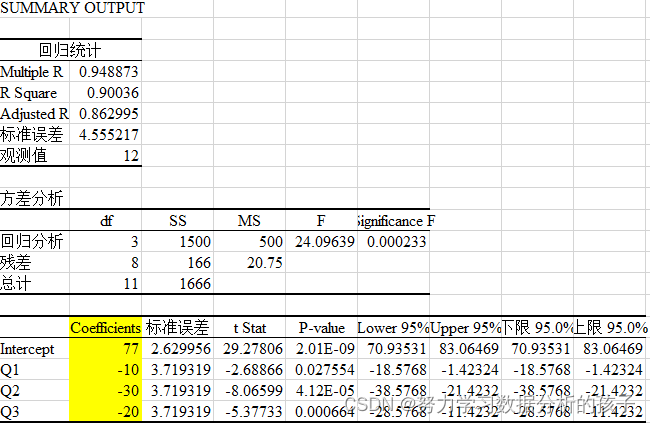
在本教程中,我们将使用 WebGPU 技术中的计算着色器实现图像效果。更多精彩内容尽在数字孪生平台。

程序结构
主要构建两个 WebGPU 管道:
- 运行反应扩散算法多次迭代的计算管道(
js/rd-compute.js和js/shader/rd-compute-shader.js) - 渲染管道,它获取计算管道的结果并通过渲染全屏三角形(
js/composite.js和js/shader/composite-shader.js)来创建最终合成图像。
WebGPU 是一个非常繁琐的 API,为了使其更容易使用,我使用了 webgpu-utils 库。此外,还包含 float16 库,用于创建和更新计算管道的存储纹理。
计算管道流程
在 GPU 上运行反应扩散模拟的一种常见方法是使用纹理交替。就是创建两个纹理,一个纹理保存要读取的模拟的当前状态,另一个纹理存储当前迭代的结果。每次迭代后,纹理都会交换。
此方法也可以使用片段着色器和帧缓冲在 WebGL 中实现。但是在 WebGPU 中,我们可以使用计算着色器和存储纹理作为缓冲区来实现相同的效果。这样做的优点是我们可以直接写入我们想要的纹理内的任何像素,还获得了计算着色器带来的性能优势。
初始化
首先是使用所有必要的布局描述符初始化管道。此外,还必须设置所有的缓冲区、纹理和绑定组。webgpu-utils 库就可以在这里节省大量工作。
WebGPU 不允许在创建缓冲区或纹理后更改其大小。因此,我们必须区分大小不变的缓冲区(例如uniform)和在某些情况下发生变化的缓冲区(例如调整画布大小时的纹理)。对于后者,我们需要一种方法来重新创建它们并在必要时销毁旧的缓冲区。
用于反应扩散模拟的所有纹理都是画布大小的一小部分(例如画布大小的四分之一)。要处理的像素数量较少,可以释放计算资源以进行更多迭代。因此,可以以相对较小的视觉损失进行更快的模拟。
除了“纹理交换”中涉及的两个纹理之外,示例中还有第三个纹理,我将其称为种子纹理。此纹理包含在其上绘制时钟字母的 HTML 画布的图像数据。种子纹理用作反应扩散模拟的一种影响图,以可视化时钟字母。当 WebGPU 画布调整大小时,必须重新创建该纹理以及相应的 HTML 画布大小调整。
运行模拟
完成所有必要的初始化后,我们可以使用计算着色器实际运行反应扩散模拟。我们先回顾一下计算着色器的一些特性。
计算着色器的每次调用都会并行处理多个线程。线程数由计算着色器的工作组(workgroup)大小定义。着色器的调用次数由调度(dispatch)大小定义(线程总数 = 工作组大小 * 调度大小)。
这些值以三个维度指定。因此,并行处理 64 个线程的计算着色器可能如下所示:
@compute @workgroup_size(8, 8, 1) fn compute() {}
运行此着色器 256 次(即 16,384 个线程)需要如下的调度大小:
pass.dispatchWorkgroups(16, 16, 1);
反应扩散模拟要求我们处理纹理的每个像素。实现此目的的一种方法是使用 workgroup 大小为 1 和 dispatch大小等于像素总数(像是模仿片段着色器)。但是这样不会提高性能,因为 workgroup 中的多个线程比单独的调度更快。
另一方面,我们可能想到使用等于像素数的 workgroup 大小,并且仅调用一次(dispatch 大小为 1)。然而这是不可能的,因为最大 workgroup 大小是有限的。对于 WebGPU 的一般建议是选择 workgroup 大小为 64。这要求我们将纹理内的像素数量划分为 workgroup 大小(= 64 像素)的块,并经常调度工作组以覆盖整个纹理。
因此,现在我们有了 workgroup 大小的恒定值,并且能够找到适当的 dispatch 大小来运行我们的模拟。但是其实我们还有更多可以优化的地方。
每线程像素数
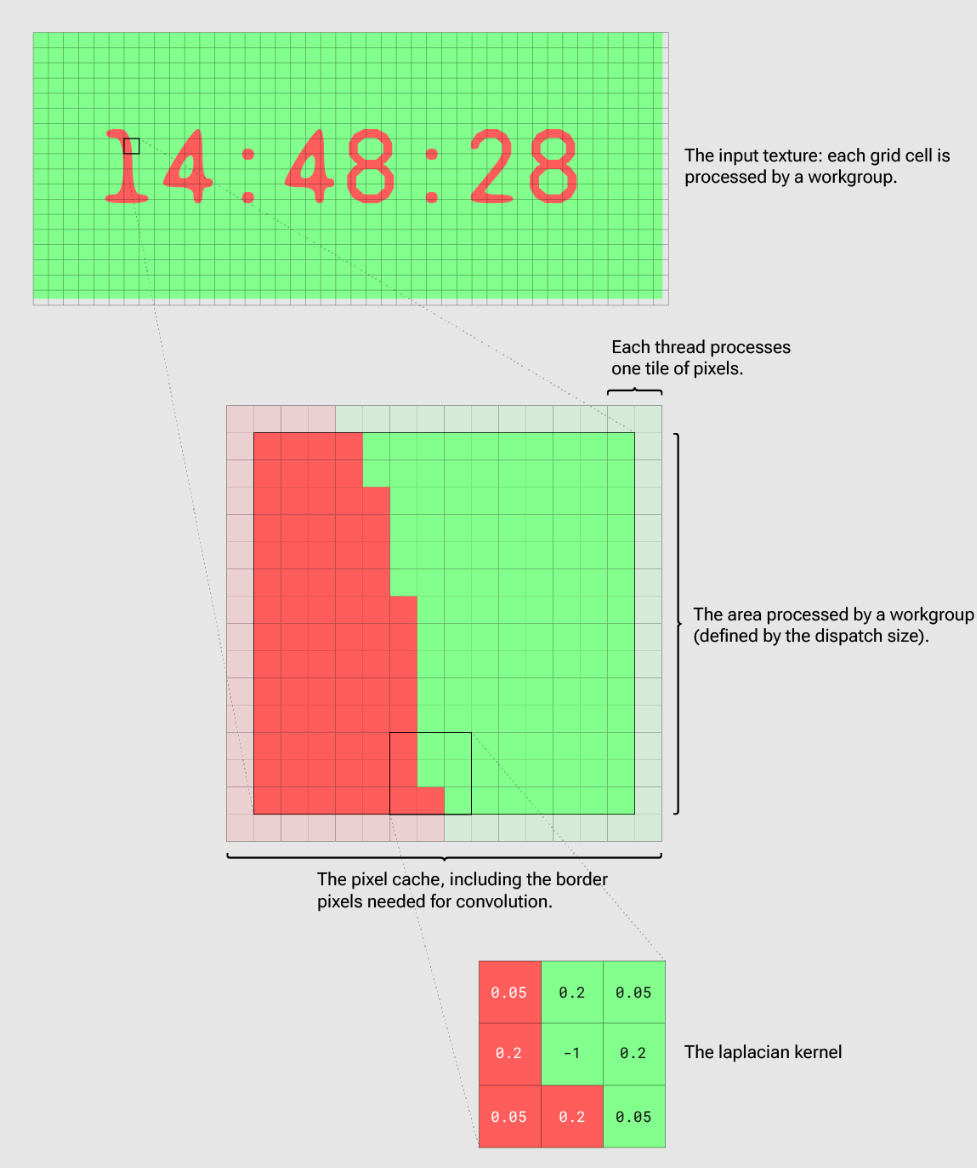
为了使每个workgroup覆盖更大的区域(更多像素),我们引入了图块大小。图块大小定义每个单独线程处理的像素数,这就需要我们在着色器中使用嵌套 for 循环,所以我们需要保持图块大小非常小(例如 2×2)。
像素缓存
运行反应扩散模拟的一个重要步骤是与拉普拉斯核(3×3 矩阵)进行卷积。因此,对于我们处理的每个像素,我们必须读取内核覆盖的所有 9 个像素才能执行计算。由于像素与像素之间的内核重叠,因此会出现大量冗余纹理读取。
幸运的是,计算着色器允许我们跨线程共享内存。所以我们可以创建像素缓存。这个方式(来自图像模糊示例)是每个线程读取其图块的像素并将它们写入缓存。一旦workgroup的每个线程都将其像素存储在缓存中(我们通过工作组屏障确保这一点),实际处理只需要使用从缓存中预取的像素。因此它不需要任何进一步的纹理读取。计算函数的结构可能如下所示:
// workgroup所有线程共享的像素缓存
var<workgroup> cache: array<array<vec4f, 128>, 128>;
@compute @workgroup_size(8, 8, 1)
fn compute_main(/* ...builtin variables */ ) {
// 将此线程的图块的像素添加到缓存中
for (var c=0u; c<2; c++) {
for (var r=0u; r<2; r++) {
// ... 从内置变量计算像素坐标
// 将像素值存储在缓存中
cache[y][x] = value;
}
}
// 在所有线程都到达此点之前不要继续
workgroupBarrier();
// 处理该线程图块的每个像素
for (var c=0u; c<2; c++) {
for (var r=0u; r<2; r++) {
// ... 执行反应扩散算法
textureStore(/* ... */);
}
}
}
}
但我们还必须注意另一个棘手的问题:内核卷积要求我们读取比最终处理的像素更多的像素。我们可以扩展像素缓存大小,但是workgroup线程共享的内存大小限制为 16,384 字节。因此,我们必须将每一侧的dispatch大小减少 (kernelSize - 1)/2。下面的插图可以让这些步骤更加清晰:
UV扰动
与片段着色器解决方案相比,使用计算着色器的一个缺点是无法在计算着色器中使用采样器来存储纹理(只能加载整数像素坐标)。如果想通过移动纹理空间(即以小数增量扰动 UV 坐标)来对模拟进行动画处理,则必须自己进行采样。
解决这个问题的一种方法是使用手动双线性采样函数。示例中使用的采样函数基于此处所示的采样函数,并进行了一些调整以供在计算着色器中使用。这允许我们对浮点像素值进行采样:
fn texture2D_bilinear(t: texture_2d<f32>, coord: vec2f, dims: vec2u) -> vec4f {
let f: vec2f = fract(coord);
let sample: vec2u = vec2u(coord + (0.5 - f));
let tl: vec4f = textureLoad(t, clamp(sample, vec2u(1, 1), dims), 0);
let tr: vec4f = textureLoad(t, clamp(sample + vec2u(1, 0), vec2u(1, 1), dims), 0);
let bl: vec4f = textureLoad(t, clamp(sample + vec2u(0, 1), vec2u(1, 1), dims), 0);
let br: vec4f = textureLoad(t, clamp(sample + vec2u(1, 1), vec2u(1, 1), dims), 0);
let tA: vec4f = mix(tl, tr, f.x);
let tB: vec4f = mix(bl, br, f.x);
return mix(tA, tB, f.y);
}
这就是示例中所示的从中心开始的模拟脉动运动的创建方式。
合成渲染
反应扩散模拟完成后,唯一剩下的就是将结果绘制到屏幕上。这是合成渲染管道的工作。
我这里简要概述示例程序中涉及的步骤:
- 凸出变形:在对反应扩散结果纹理进行采样之前,将凸出变形应用于 UV 坐标(基于此 Shadertoy 代码),可以增加场景的深度感。
- 颜色:应用调色板(来自 Inigo Quilez)
- 浮雕滤镜:简单的浮雕效果赋予“纹理”一定的体积。
- 假彩虹色:这种微妙的效果基于不同的调色板,但应用于压花结果的负空间。假虹彩使场景看起来更加充满活力。
- 晕影:晕影叠加用于使边缘变暗。