目录
1.视图
1.1.什么是视图?
1.2.创建视图的语法
1.3.简单视图和复杂视图
1.4.创建复杂视图
1.4.1.创建复杂视图的步骤
1.4.2.示例
1.4.3.注意事项
1.5.视图中使用DML的规定
1.5.1.屏蔽DML操作
1.6.删除视图
2.序列
2.1.语法:
2.2.查询序列
2.3.修改序列
2.4.删除序列
3.索引
3.1.单列索引
3.2.复合索引
3.3.什么时候创建索引
3.4.什么时候不要创建索引
3.5.查询索引
3.6.删除索引
4.同义词
4.1.创建同义词
4.2.删除同义词
1.视图
1.1.什么是视图?
- 视图是一个虚表.
- 视图建立在已有表的基础上,视图赖以建立的这些表称为基表.
- 向视图提供数据内容的语句为select语句,可以将视图理解为存储起来的select语句.
- 视图向用户提供基表数据的另一种表现形式.
- 最大的优点就是简化复杂的查询。
1.2.创建视图的语法
create [or replace] [force | noforce] view view_name [(alias_column_name [, alias_column_name] ...)]
as
select ... [from ...];
[with check option [constraint constraint_name]]
[with read only [constraint constraint_name]];-
其中:
create [or replace]:如果视图已经存在,使用or replace选项将替换现有的视图定义。如果不存在,则仅使用create。 [force | noforce]:force:即使基表不存在,也强制创建视图(但这样的视图将无法使用,直到基表被创建)。noforce:这是默认选项,如果基表不存在,则不会创建视图。
view_name:新视图的名称。(alias_column_name [, alias_column_name] ...):为视图中的列定义别名(可选)。as select ... [from ...]:定义视图的查询语句。[with check option [constraint constraint_name]]:此选项确保对视图进行的任何更改(如insert、update或delete)都满足视图的where子句条件(如果有的话)。constraint constraint_name是可选的,用于为约束指定一个名称。[with read only [constraint constraint_name]]:此选项使视图成为只读视图,即不能通过视图进行insert、update或delete操作。constraint constraint_name是可选的,用于为约束指定一个名称。
语法1:
create view 视图名称 as 子查询 假设我们有一个名为employees的表,并且我们想要创建一个只显示姓氏为"Smith"的员工的视图:
create view view_smith_employees as
select employee_id, first_name, last_name
from employees
where last_name = 'smith';语法2:
create or replace view 视图名称 as 子查询 假设我们有一个名为employees的表,并且我们想要创建一个只显示姓氏为"Smith"的员工的视图
如果视图已经存在我们可以使用语法2来创建视图,这样已有的视图会被覆盖。
create or replace view view_smith_employees as
select employee_id, first_name, last_name
from employees
where last_name = 'smith';1.3.简单视图和复杂视图
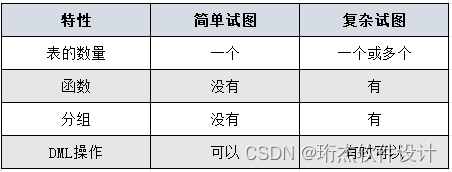
不建议通过视图对表中数据进行修改,因为会受到很多的限制。
1.4.创建复杂视图
复杂视图通常指的是那些SQL语句中包含聚合函数(如SUM、AVG、COUNT等)、多表连接、子查询或层次化查询等复杂操作的视图。
1.4.1.创建复杂视图的步骤
- 确定需求:首先,你需要明确视图需要满足什么样的业务需求或查询需求。
- 编写SQL语句:根据需求编写复杂的SQL查询语句。这可能包括使用聚合函数、多表连接、子查询等。
- 创建视图:使用
CREATE VIEW语句和编写的SQL查询语句来创建视图。
1.4.2.示例
示例1:多表连接和聚合函数
假设你有两个表:orders(订单表)和customers(客户表)。你想要创建一个视图,显示每个客户的订单总数和总金额。
create view view_customer_orders as
select c.customer_id, c.customer_name, count(o.order_id) as total_orders, sum(o.order_amount) as total_amount
from customers c
join orders o on c.customer_id = o.customer_id
group by c.customer_id, c.customer_name;示例2:层次化查询(使用START WITH和CONNECT BY)
假设你有一个表示组织结构的表organization,其中包含emp_id(员工ID)、emp_name(员工姓名)和manager_id(经理ID)等字段。你想要创建一个视图,显示每个员工及其所有下属员工。
create view view_organization_hierarchy as
select emp_id, emp_name, level as hierarchy_level
from organization
start with manager_id is null
connect by prior emp_id = manager_id;1.4.3.注意事项
- 性能:复杂视图可能会导致查询性能下降,特别是在处理大量数据时。因此,在创建复杂视图之前,最好先对SQL语句进行性能优化。
- 可维护性:复杂视图可能难以理解和维护。为了保持代码的可读性和可维护性,建议在创建视图时添加适当的注释,并遵循良好的编码规范。
- 权限:与简单视图一样,你需要确保只有授权的用户才能访问和修改复杂视图。可以通过授予或撤销视图的权限来实现这一点。
- 修改限制:对于包含聚合函数或多表连接的复杂视图,可能无法直接对其进行修改(如INSERT、UPDATE或DELETE)。在尝试对复杂视图进行修改之前,请确保了解相关的限制和约束。
1.5.视图中使用DML的规定
- 可以在简单视图中执行DML操作
- 当视图定义中包含以下元素之一时不饿能使用delete:
- 组函数
- GROUP BY 子句
- DISTINCT 关键字
- ROWNUM 伪列
- 当视图定义中包含以下元素之一时不能使用update:
- 组函数
- GROUP BY 子句
- DISTINCT 关键字
- ROWNUM 伪列
- 列的定义方式为表达式
- 当视图定义中包含以下元素之一时不能使用insert:
- 组函数
- GROUP BY 子句
- DISTINCT 关键字
- ROWNUM 伪列
- 列的定义方式为表达式
- 列中非空的列在视图定义中未包括
1.5.1.屏蔽DML操作
- 可以使用WITH READ ONLY 选项屏蔽对视图的DML操作
- 任何DML操作都会返回一个Oracle server 错误
1.6.删除视图
删除视图只是删除视图的定义,并不会删除基本表的数据。
drop view view_smith_employees;
drop view view_organization_hierarchy;2.序列
在很多数据库中都存在一个自动增长的列,如果现在要想在oracle中完成自动增长的功能,则只能依靠序列完成,所有的自动增长操作,需要用户手工完成处理。并且Oracle将序列值装入内存可以提高访问效率。
序列:可供多个用户用来产生唯一数值的数据库对象:
- 自动提供唯一的数值
- 共享对象
- 主要用于提供主键值
- 将序列值装入内存可以提高访问效率
2.1.语法:
create sequence 序列名
[increment by n] -- 定义序列的步长,默认为1
[start with n] -- 定义序列的初始值,默认为1
[{maxvalue n | nomaxvalue}] -- 定义序列的最大值,nomaxvalue表示没有最大值限制
[{minvalue n | nominvalue}] -- 定义序列的最小值,nominvalue表示没有最小值限制
[{cycle | nocycle}] -- 定义当序列达到限制值后是否循环,默认为nocycle
[{cache n | nocache}]; -- 定义是否缓存序列值,默认为nocache示例:
-
创建一个简单的序列,从1开始,每次递增1:
create sequence seq_example; -
创建一个从100开始,每次递增2的序列
create sequence seq_example_start_inc start with 100 increment by 2; -
创建一个从1开始,每次递增1,最大值为1000的序列,当达到最大值时循环:
create sequence seq_example_max_cycle start with 1 increment by 1 maxvalue 1000 cycle; -
创建一个使用缓存的序列(注意:使用缓存的序列在数据库异常关闭时可能会导致值的不连续):
create sequence seq_example_cache start with 1 increment by 1 cache 20;
注意事项
- 当你使用
cache选项时,Oracle会预先分配并缓存指定数量的序列值。如果数据库异常关闭,则可能会丢失尚未使用的缓存值。为了避免这种情况,你可以使用NOCACHE或定期重新启动序列(使用alter sequence ... restart)。 - 当你定义
maxvalue和cycle时,序列在达到最大值后会从头开始(即minvalue)。同样,如果定义了minvalue和cycle,序列在达到最小值后会重新开始(即maxvalue)。 - 你可以使用
nextval和currval来从序列中获取值。NEXTVAL返回序列的下一个值,并将序列递增。currval返回序列的当前值(但在首次使用之前,必须先调用nextval)。
2.2.查询序列
-
查询当前用户下的所有序列名称:
SELECT sequence_name FROM user_sequences; -
查询数据库中所有用户的所有序列名称:
SELECT sequence_name FROM all_sequences; -
查询当前用户下某个序列的详细信息(包括名称、最小值、最大值、递增步长和当前值):
SELECT sequence_name, min_value, max_value, increment_by, last_number FROM user_sequences WHERE sequence_name = '你的序列名';如果你想要查询所有序列的详细信息,可以省略
WHERE子句。 - 查询指定序列的当前值:
注意:你不能直接通过查询
user_sequences或all_sequences视图来获取序列的当前值。但是,你可以通过调用序列的CURRVAL(如果已经调用过NEXTVAL)或NEXTVAL(这会返回下一个值并递增序列)来获取。但请注意,CURRVAL不能在序列的第一次使用之前被调用。例如,如果你有一个名为
seq_test的序列,并且你已经至少调用过一次seq_test.NEXTVAL,那么你可以这样查询当前值:SELECT seq_test.CURRVAL FROM dual;但如果你还没有调用过
seq_test.NEXTVAL,那么上述查询将会失败。在这种情况下,你应该首先调用seq_test.NEXTVAL来获取并递增序列的值,然后再使用seq_test.CURRVAL。 -
连接到Oracle数据库:要使用上述查询,你首先需要连接到Oracle数据库。你可以使用SQL*Plus、SQL Developer、PL/SQL Developer或其他支持Oracle的工具来连接。
-
编写和执行查询:在连接到数据库后,你可以编写并执行上述查询来获取序列的信息。
2.3.修改序列
修改序列可以使用ALTER SEQUENCE语句来修改序列的属性
- 修改序列的起始值(START WITH)
如果你想修改序列的起始值,可以使用
START WITH子句。例如,如果你有一个名为seq_test的序列,你想将其起始值设置为1000,你可以执行以下SQL语句:ALTER SEQUENCE seq_test START WITH 1000; -
修改序列的递增值(INCREMENT BY)
如果你想修改序列的递增值,可以使用
INCREMENT BY子句。例如,如果你希望每次从序列中获取值时,它都递增5,你可以执行以下SQL语句:ALTER SEQUENCE seq_test INCREMENT BY 5; -
修改序列的最大值(MAXVALUE)和最小值(MINVALUE)
你还可以修改序列的最大值和最小值。但是请注意,一旦序列已经达到了其当前的最大值或最小值,并且你尝试再次从中获取值(除非指定了
CYCLE),Oracle将会报错。以下是如何修改最大值和最小值的示例:ALTER SEQUENCE seq_test MAXVALUE 2000; ALTER SEQUENCE seq_test MINVALUE 500; -
设置序列是否循环(CYCLE/NOCYCLE)
ALTER SEQUENCE seq_test CYCLE;或者,如果你想禁止循环并允许序列在达到其限制时报错,你可以使用
NOCYCLE选项:ALTER SEQUENCE seq_test NOCYCLE; -
修改序列的缓存设置(CACHE/NOCACHE)
当使用
CACHE选项时,Oracle会预先分配并缓存一组序列号。这可以提高获取序列号的性能,但如果在数据库异常关闭时丢失了尚未使用的缓存值,可能会导致序列中的“间隙”。你可以使用NOCACHE选项来禁用缓存。例如:ALTER SEQUENCE seq_test CACHE 20; ALTER SEQUENCE seq_test NOCACHE; -
注意事项
- 在修改序列之前,请确保你了解这些更改可能如何影响依赖于该序列的应用程序或数据库对象。
- 在生产环境中进行任何更改之前,最好在测试环境中验证这些更改。
- 当你修改一个正在被多个用户或进程使用的序列时,需要特别小心,以确保这些更改不会导致任何问题或不一致性。
- 必须时序列的拥有者或对序列有ALTER权限
- 只有将来的序列值会被改变
- 改变序列的初始值只能通过删除序列之后重建序列的方法实现
2.4.删除序列
在 Oracle 数据库中,你可以使用 DROP SEQUENCE 语句来删除一个已经存在的序列。在删除序列之前,请确保没有其他的数据库对象(如表、触发器、存储过程等)正在引用该序列,因为这将导致删除操作失败。
以下是 DROP SEQUENCE 语句的基本语法:
DROP SEQUENCE sequence_name;其中 sequence_name 是你想要删除的序列的名称。
例如,如果你有一个名为 my_sequence 的序列,并且你想要删除它,你可以使用以下 SQL 语句:
DROP SEQUENCE my_sequence;当你执行这个语句后,Oracle 将删除该序列,并且释放与该序列关联的所有资源。请注意,一旦序列被删除,所有与该序列关联的数据也将被永久删除,并且无法恢复。因此,在执行删除操作之前,请务必确保你已经备份了所有重要的数据。
另外,如果你只是想重置序列的当前值,而不是完全删除它,你可以使用 ALTER SEQUENCE 语句的 RESTART WITH 选项。例如,要将 my_sequence 的当前值重置为 1,你可以使用以下 SQL 语句:
ALTER SEQUENCE my_sequence RESTART WITH 1;3.索引
索引是用于加速数据存取的数据对象。合理的使用索引可以大大降低i/o的次数,从而提高数据访问性能。
- 一种独立于表的模式对象,可以存储在与表不同的磁盘或表空间中
- 索引被删除或损坏,不会对 表产生影响,其影响的只是查询的速度
- 索引一旦建立,Oracle管理系统会对其进行自动维护,而且由Oracle管理系统决定何时使用索引,用户不用再查询语句中指定使用哪个索引
- 再删除一个表时,所有基于该表的索引会自动被删除
- 通过指针加速Oracle服务器的查询速度
- 通过快读定位数据的方法,减少磁盘 I/O
3.1.单列索引
在Oracle数据库中,单列索引是一种索引类型,它基于表中的单个列创建。这种索引可以显著提高查询性能,特别是当查询条件基于该列时。
以下是关于Oracle单列索引的一些要点:
-
定义:单列索引是在表的单个列上创建的索引。它允许数据库系统更快地访问基于该列的数据。
-
创建:你可以使用
CREATE INDEX语句来创建单列索引。例如,假设你有一个名为employees的表,并且你想要在last_name列上创建一个单列索引,那么你可以使用以下SQL语句:CREATE INDEX idx_last_name ON employees(last_name);在这个例子中,
idx_last_name是索引的名称,employees是表名,而last_name是你要创建索引的列名。 -
用途:单列索引特别适用于在查询中使用单个列进行条件过滤、排序和连接操作的情况。当查询条件基于索引列时,数据库系统可以快速定位到相关数据,而无需扫描整个表。
-
性能:通过减少磁盘I/O次数和提高数据访问速度,单列索引可以显著提高查询性能。但是,它们也会占用额外的存储空间,并可能增加写操作的开销(如插入、更新和删除操作)。
-
注意事项:虽然单列索引可以提高查询性能,但过度使用它们可能会导致性能下降。在创建索引之前,你应该仔细评估你的查询需求和数据模式,以确定哪些列最适合创建索引。此外,定期审查和优化你的索引策略也是很重要的,以确保它们仍然满足你的性能需求。
-
其他索引类型:除了单列索引之外,Oracle还支持其他类型的索引,如组合索引(基于多个列)、唯一索引(确保列中的值是唯一的)、位图索引(用于处理低基数数据)等。你可以根据你的具体需求选择适当的索引类型。
3.2.复合索引
Oracle复合索引,也被称为联合索引或组合索引,是指在Oracle数据库中,同时基于两个或两个以上列创建的索引。它允许数据库系统更快地访问基于这些列组合的数据。
以下是关于Oracle复合索引的一些要点:
-
创建:你可以使用
CREATE INDEX语句来创建复合索引。例如,假设你有一个名为employees的表,并且你想要在last_name和first_name列上创建一个复合索引,那么你可以使用以下SQL语句:CREATE INDEX idx_name ON employees(last_name, first_name);在这个例子中,
idx_name是索引的名称,employees是表名,而last_name和first_name是你要创建索引的列名。 -
使用:当查询条件同时涉及到复合索引的多个列时,复合索引可以显著提高查询性能。但是,需要注意复合索引的最左前缀原则,即查询条件必须包含复合索引的最左侧列,否则复合索引可能不会被使用。
-
性能:虽然复合索引可以提高查询性能,但也可能增加写操作的开销(如插入、更新和删除操作),因为当这些操作涉及到复合索引的列时,索引也需要被相应地更新。
-
设计:在设计复合索引时,应该充分考虑各字段的筛选度和查询需求。通常,建议将选择性最高的字段(即具有更多唯一值的字段)放在复合索引的最左侧。
-
注意事项:过度使用复合索引可能会导致性能下降,因为每个复合索引都会占用额外的存储空间,并可能增加写操作的开销。因此,在创建复合索引之前,你应该仔细评估你的查询需求和数据模式,以确定哪些列组合最适合创建复合索引。
总之,Oracle复合索引是一种强大的工具,可以帮助你提高数据库查询性能。但是,在使用它时需要注意其特点和使用原则,以确保其能够发挥最佳效果。
3.3.什么时候创建索引
- 列中数据值分布范围很广
- 列经常在where子句或连接条件中出现
- 表经常被访问而且数据量很大,访问的数据大概占数据总量的2%到4%
3.4.什么时候不要创建索引
- 表很小
- 列不经常作为连接条件或出现在where子句中
- 查询的数据大于2%到4%
- 表经常更新
3.5.查询索引
在 Oracle 数据库中,你可以使用多种方法来查询索引。以下是一些常用的查询索引的方法:
- 查询某个表的索引:使用
USER_INDEXES、ALL_INDEXES或DBA_INDEXES视图,配合USER_IND_COLUMNS、ALL_IND_COLUMNS或DBA_IND_COLUMNS视图,可以查询某个表的索引信息。例如,查询用户拥有的某个表(比如
employees)的所有索引:SELECT idx.index_name, idx.table_name, idx.column_name, idx.column_position FROM USER_IND_COLUMNS idx JOIN USER_INDEXES i ON idx.index_name = i.index_name WHERE idx.table_name = 'EMPLOYEES' ORDER BY idx.index_name, idx.column_position;如果你有权限,也可以将
USER_替换为ALL_或DBA_来查询其他用户或整个数据库的索引。 - 查询所有索引:如果你想要查询数据库中所有的索引,可以直接查询
DBA_INDEXES视图(需要相应的权限):SELECT index_name, table_name, uniqueness FROM DBA_INDEXES ORDER BY table_name, index_name;这里的
uniqueness列会显示索引是唯一的(UNIQUE)还是非唯一的(NONUNIQUE)。 - 查询索引的详细信息:你还可以查询
DBA_IND_COLUMNS、DBA_IND_PARTITIONS、DBA_IND_STATISTICS等视图来获取关于索引的更详细信息,如索引的分区信息、统计信息等。 - 使用数据字典:除了上述的视图外,你还可以使用 Oracle 的数据字典来获取索引信息。例如,执行
DESCRIBE INDEX index_name;(其中index_name是你要查询的索引名)可以获取索引的列信息。但请注意,DESCRIBE命令通常用于描述表或视图的结构,对于索引可能不如使用视图来得详细。 - 使用 SQL*Plus 或其他工具:你可以使用 SQL*Plus、SQL Developer、PL/SQL Developer 等工具来执行上述查询,并查看结果。这些工具通常提供了图形化的界面来查看和管理数据库对象,包括索引。
3.6.删除索引
-
确定要删除的索引名称:
首先,你需要知道你想要删除的索引的名称。你可以通过查询USER_INDEXES、ALL_INDEXES或DBA_INDEXES视图来获取这些信息。 -
使用 DROP INDEX 语句:
一旦你知道了索引的名称,你就可以使用DROP INDEX语句来删除它。示例:
DROP INDEX index_name;其中
index_name是你想要删除的索引的名称。 -
确保你有足够的权限:
删除索引需要相应的权限。如果你没有权限,你可能需要联系你的数据库管理员或者使用有足够权限的用户来执行这个操作。 -
考虑索引对性能的影响:
在删除索引之前,请确保你了解这个索引是如何被使用的,以及删除它可能会如何影响数据库的性能。索引可以提高查询性能,但也会占用存储空间并可能增加插入、更新和删除操作的开销。 -
注意依赖对象:
确保没有数据库对象(如视图、存储过程、触发器等)依赖于你要删除的索引。如果有依赖对象,你可能需要先修改或删除这些对象,然后再删除索引。 -
备份:
在删除任何数据库对象之前,始终建议进行备份。这可以在出现错误或意外情况时提供恢复选项。
示例:
假设你有一个名为 idx_employees_last_name 的索引,并且你想要删除它。你可以使用以下 SQL 语句来执行此操作:
DROP INDEX idx_employees_last_name;执行此语句后,idx_employees_last_name 索引将被删除。
4.同义词
Oracle同义词是数据库对象的一个别名,经常用于简化对象访问和提高对象访问的安全性。在Oracle数据库中,同义词提供了一种在不同数据库用户之间实现无缝交互的方式,扩展了数据库的使用范围。
Oracle同义词有两种类型:
- 公用Oracle同义词:由一个特殊的用户组Public所拥有,数据库中所有的用户都可以使用公用同义词。公用同义词往往用来标示一些比较普通的数据库对象,这些对象往往大家都需要引用。
- 私有Oracle同义词:与公用同义词相对应,由创建它的用户所有。只有这个同义词的创建者,或者通过授权的用户,才有权使用属于自己的私有同义词。私有同义词名称不可与当前模式的对象名称相同。
4.1.创建同义词
同义词的创建语法如下:
CREATE [PUBLIC] SYNONYM synonym_name FOR object_name;其中,[PUBLIC] 是可选的,用于指定是否创建公用同义词。synonym_name 是要创建的同义词的名称,object_name 是要为之创建同义词的数据库对象的名称。
例如,要为用户 john 创建一个名为 employees_syn 的私有同义词,该同义词引用 hr.employees 表,可以使用以下SQL语句:
CREATE SYNONYM employees_syn FOR hr.employees;注意,执行此语句的用户需要具有创建同义词的权限,并且该用户需要能够访问 hr.employees 表。
要查询Oracle数据库中的同义词列表,可以使用以下SQL查询语句:
- 查询当前用户及其访问权限范围内的所有同义词信息:
SELECT * FROM ALL_SYNONYMS; - 查询当前用户自己创建的所有同义词信息:
SELECT * FROM USER_SYNONYMS; - 查询所有同义词的详细信息(包括同义词所引用的对象及其所有者等信息):
SELECT * FROM ALL_OBJECTS WHERE OBJECT_TYPE='SYNONYM';
4.2.删除同义词
在Oracle数据库中,要删除同义词,你可以使用DROP SYNONYM语句。根据同义词的类型(私有或公有),你可能需要指定相应的权限。
以下是如何删除同义词的步骤:
-
确定要删除的同义词名称:
首先,你需要知道你想要删除的同义词的名称。你可以通过查询DBA_SYNONYMS、ALL_SYNONYMS或USER_SYNONYMS视图来获取这些信息。 -
使用DROP SYNONYM语句:
一旦你知道了同义词的名称,你就可以使用DROP SYNONYM语句来删除它。对于私有同义词(只由当前用户拥有的),你可以直接执行以下语句:
DROP SYNONYM synonym_name;其中
synonym_name是你要删除的同义词的名称。对于公有同义词(由所有用户共享的),你需要使用
PUBLIC关键字,但通常只有DBA或具有相应权限的用户才能删除公有同义词:DROP PUBLIC SYNONYM synonym_name; -
确保你有足够的权限:
删除同义词需要相应的权限。如果你没有权限,你可能需要联系你的数据库管理员或者使用有足够权限的用户来执行这个操作。 -
注意依赖对象:
在删除同义词之前,请确保没有数据库对象(如视图、存储过程、触发器等)依赖于这个同义词。如果有依赖对象,你可能需要先修改或删除这些对象,然后再删除同义词。 -
备份:
在删除任何数据库对象之前,始终建议进行备份。这可以在出现错误或意外情况时提供恢复选项。 -
检查是否删除成功:
执行完DROP SYNONYM语句后,你可以查询DBA_SYNONYMS、ALL_SYNONYMS或USER_SYNONYMS视图来确认同义词是否已被成功删除。
请注意,执行DROP SYNONYM语句后,同义词将被永久删除,并且无法恢复(除非你有备份)。因此,在执行此操作之前,请务必谨慎考虑。