微软亚洲研究院与 Azure 语音组的研究员们提出了通用语音预训练模型 WavLM。通过 Denoising Masked Speech Modeling 框架(核心思想是通过预测被掩蔽(即遮蔽或删除)的语音部分来训练模型,同时还包括去噪的过程),研究员们将 WavLM 适配到了17个任务上,并且都取得了非常好的效果,这使得语音预训练模型的有效性从语音识别任务延伸到了非内容识别的语音任务。基于在94,000小时无监督的英文数据上进行训练,WavLM 还在多个语音相关的数据集上都取得了 SOTA 的成绩。模型为开源模型,并集成到了 Hugging Face 的 Transformer 框架中方便使用者调用。
1、技术原理及架构
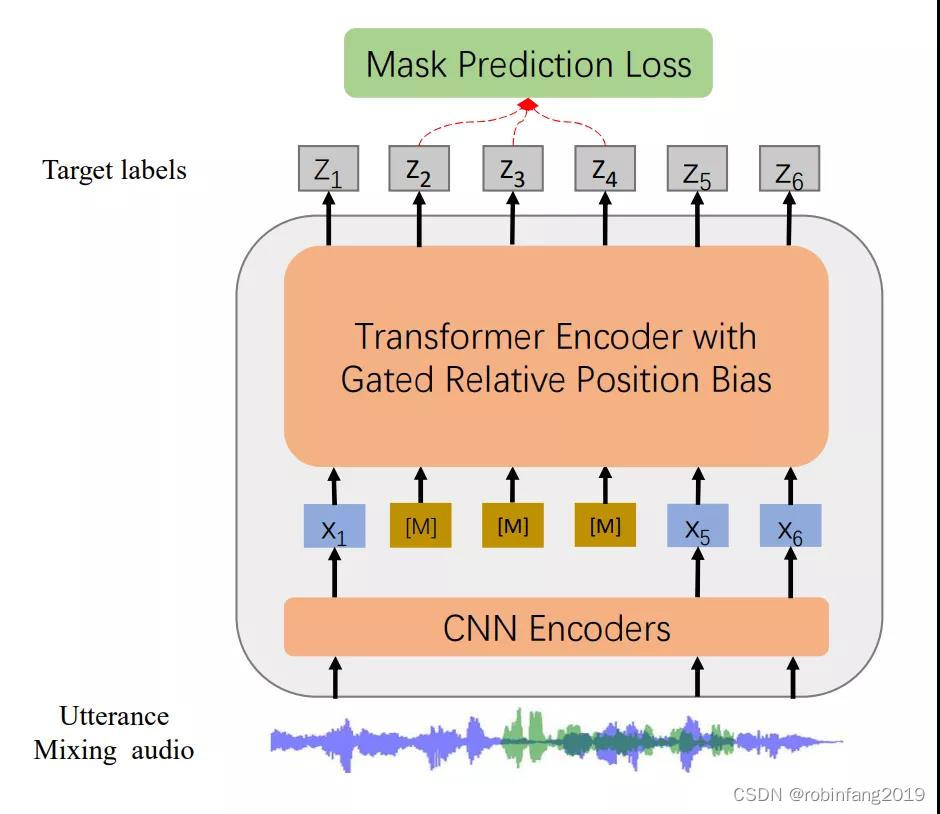
WavLM模型是一种基于HuBERT框架构建的预训练模型,专门用于处理语音任务。该模型的设计重点在于语音内容的建模和发言人身份的保持。
WavLM采用了Denoising Masked Speech Modeling(去噪掩蔽语音建模)的预训练方案。这种方法通过掩盖部分语音数据并尝试预测这些被掩盖的部分来进行训练,从而增强模型对语音内容的理解能力。
此外,WavLM还引入了双编码器结构,这种结构使得模型能够更好地处理语音数据中的复杂信息,并提高模型的鲁棒性。双编码器的使用也是为了优化模型在不同语音任务上的表现,使其能够更加灵活地适应不同的应用场景。
在技术实现上,WavLM还采用了提示感知LoRA权重适配器,这是一种通过两阶段课程学习方法进行优化的技术,可以帮助模型更好地理解和生成语音内容。
2、使用WavLM进行语音识别
2.1 环境配置
确保您的Python环境是3.6或更高版本。安装transformers和torch库。您可以使用pip来安装这些库:
pip install transformers torch
2.2 硬件要求
WavLM模型的大小和复杂性可能需要相对较高的计算资源。根据模型的版本(WavLM Base或WavLM Large),需要一块具有至少几个GB显存的GPU。对于WavLM Large,建议使用具有16GB或更高显存的GPU。
如果没有可用的GPU,可以在具有足够RAM的CPU上运行WavLM,但计算速度会慢得多。
2.3 准备数据
确保您的语音数据是以16kHz的采样率进行的。如果需要,您可以使用音频处理工具对数据进行重采样或预处理。
2.4 加载模型
使用Hugging Face的Transformers库,加载WavLM模型。
可以根据需要调整模型配置,例如更改模型的输出层以适应不同的任务。
2.5 处理音频
使用WavLMProcessor来处理您的音频数据。这将涉及将音频转换为模型所需的格式,例如提取声谱图特征。
2.6 模型使用
获取模型输出:将处理后的音频输入到模型中,获取输出。
解码输出:将模型的输出转换为文本。这可能需要使用额外的解码器或语言模型来将声学模型输出转换为文本。
后处理:对识别结果进行后处理,例如去除空格和标点符号,或者进行额外的文本清理。
2.7 资源监控
在运行模型时,监控GPU的显存使用情况,以确保不会出现显存不足的问题。
如果您的模型非常大或者您在处理大量的数据,可能需要调整batch size以避免显存溢出。
3、相关资源
开源模型:unilm/wavlm at master · microsoft/unilm · GitHub
Hugging Face集成:https://huggingface.co/microsoft/wavlm-large
在线DEMO(检测两段语音是否来自同一说话人):
https://huggingface.co/spaces/microsoft/wavlm-speaker-verification