登神长阶
第十神装 HashSet
第十一神装 HashMap
目录
👔一.哈希
🧥1.概念
🩳2.Object类的hashCode()方法:
👚3.String类的哈希码:
👠4.注意事项:
🎷二.哈希桶
🪗1.哈希桶原理
🎸2.哈希桶的实现细节
🪘3.总结
📲三.解决哈希冲突的常用方法*
💰四.HashSet
🪙1.定义
💵2.操作
💶3.特性
💷4.内部实现
💳5.应用场景
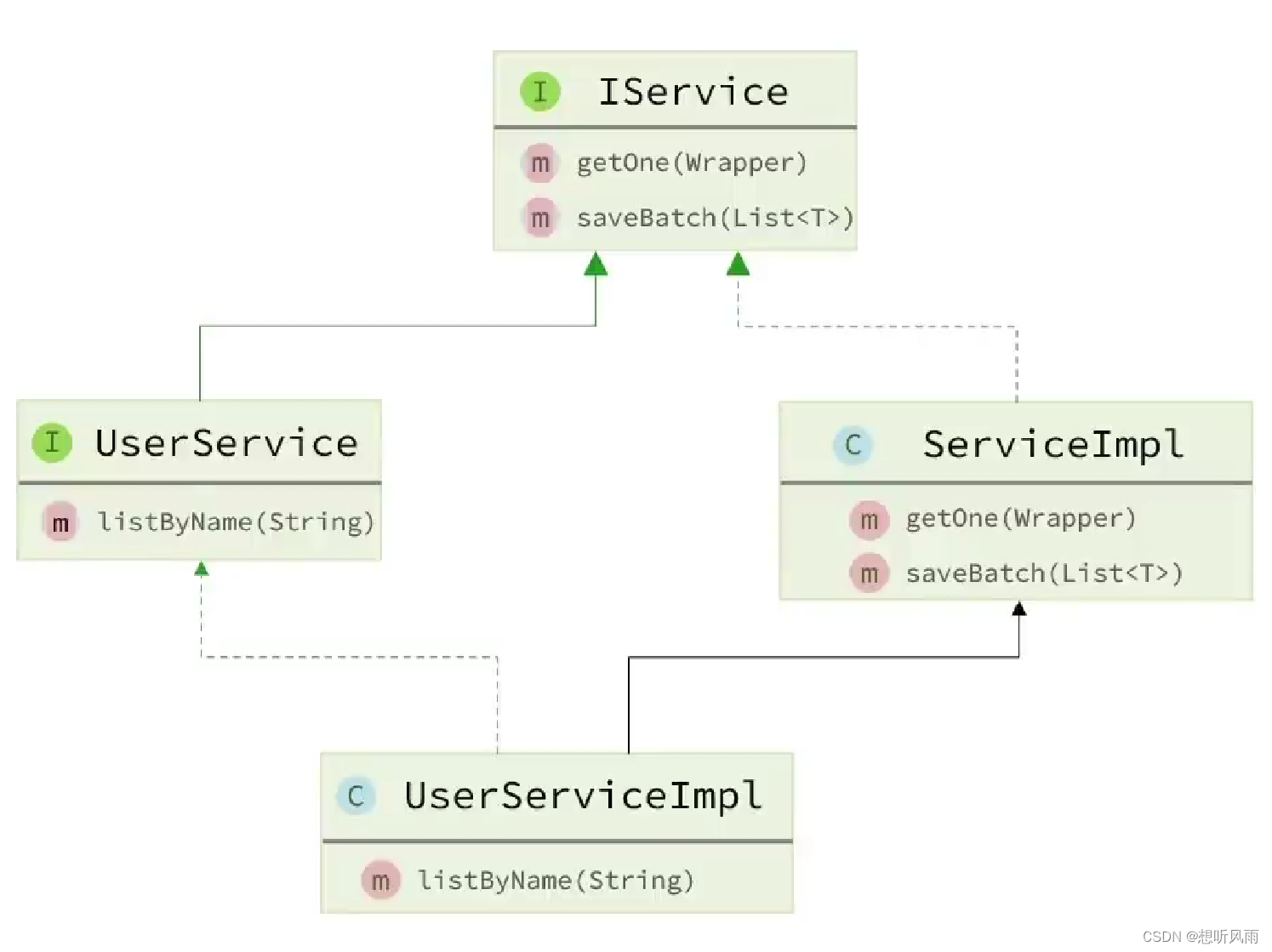
✏️五.HashMap
✒️1.定义
🖋️2.操作
🖊️3.特性
🖍️4.内部实现
🖌️5.应用场景
📝六.对比
💼七.总结与反思
👔一.哈希
🧥1.概念
在Java中,哈希(Hash)是一个广泛应用于数据结构和算法中的概念,主要用于快速查找、存储和比较数据。哈希的核心在于哈希函数(Hash Function),它将输入(通常称为键,key)映射到一个固定范围的输出值,这个输出值称为哈希值(Hash Value)或哈希码(HashCode)。哈希的目的在于将原本复杂、不规则的数据转化为简洁的、固定长度的值,使得数据的存储和检索更加高效。
🩳2.Object类的hashCode()方法:
Java中的每个对象都继承自Object类,而Object类有一个hashCode()方法,这个方法被设计用来返回对象的哈希码。默认的hashCode()实现通常基于对象的内存地址,但子类通常会重写此方法,以便根据对象的实际内容生成更有意义的哈希值,这对于使用对象作为键的哈希表操作尤为重要。
-
作用:
hashCode()方法返回对象的哈希码值(哈希码),是一个int类型的整数。- 哈希码是根据对象的内存地址或者根据对象的内容计算得到的一个唯一标识符。
- 在Java中,
hashCode()方法通常与equals()方法一起使用,用于判断两个对象是否相等。
-
默认实现:
- 在
Object类中,hashCode()方法的默认实现是根据对象的内存地址计算得到的哈希码。 - 换句话说,如果两个对象在内存中的地址不同,那么它们的哈希码也会不同。
- 在
-
重写规则:
- 在自定义类中,通常需要重写
hashCode()方法,以便根据对象的内容来生成哈希码,而不是依赖于默认的内存地址。 - 如果重写了
equals()方法,就应该同时重写hashCode()方法,保证相等的对象拥有相等的哈希码。 - 重写
hashCode()方法时,应该遵循以下规则:- 相等的对象必须具有相等的哈希码。
- 不相等的对象尽量产生不同的哈希码,以减少哈希冲突的发生。
- 在自定义类中,通常需要重写
-
使用场景:
- 在集合类中,如
HashMap、HashSet等,hashCode()方法被用于确定对象在集合中的存储位置,加快数据的查找速度。 - 当我们需要比较自定义类的对象是否相等时,通常会重写
equals()和hashCode()方法。
- 在集合类中,如
总之,Object类的hashCode()方法是用于获取对象的哈希码的方法,可以通过重写该方法来根据对象的内容生成哈希码,以便在集合中进行快速查找和比较。
👚3.String类的哈希码:
String类是一个典型重写了hashCode()方法的类,它根据字符串的内容计算哈希值,这意味着内容相同的字符串将拥有相同的哈希值,这有助于在哈希表中快速定位和比较字符串。
👠4.注意事项:
- 哈希函数应该是高效的,即计算速度快。
- 哈希函数应该尽量均匀分布,以减少哈希冲突。
- 哈希值虽然可以用于快速比较,但不保证绝对唯一,因此在判断对象相等时,除了比较哈希值外,还需要比较对象的实际内容(通过
equals()方法)。 - 在实现自定义类的
hashCode()时,应当遵守与equals()方法的一致性原则,即如果两个对象通过equals()判断为相等,它们的哈希码也必须相等。反之,哈希码相等的对象不一定通过equals()判断相等。
🎷二.哈希桶
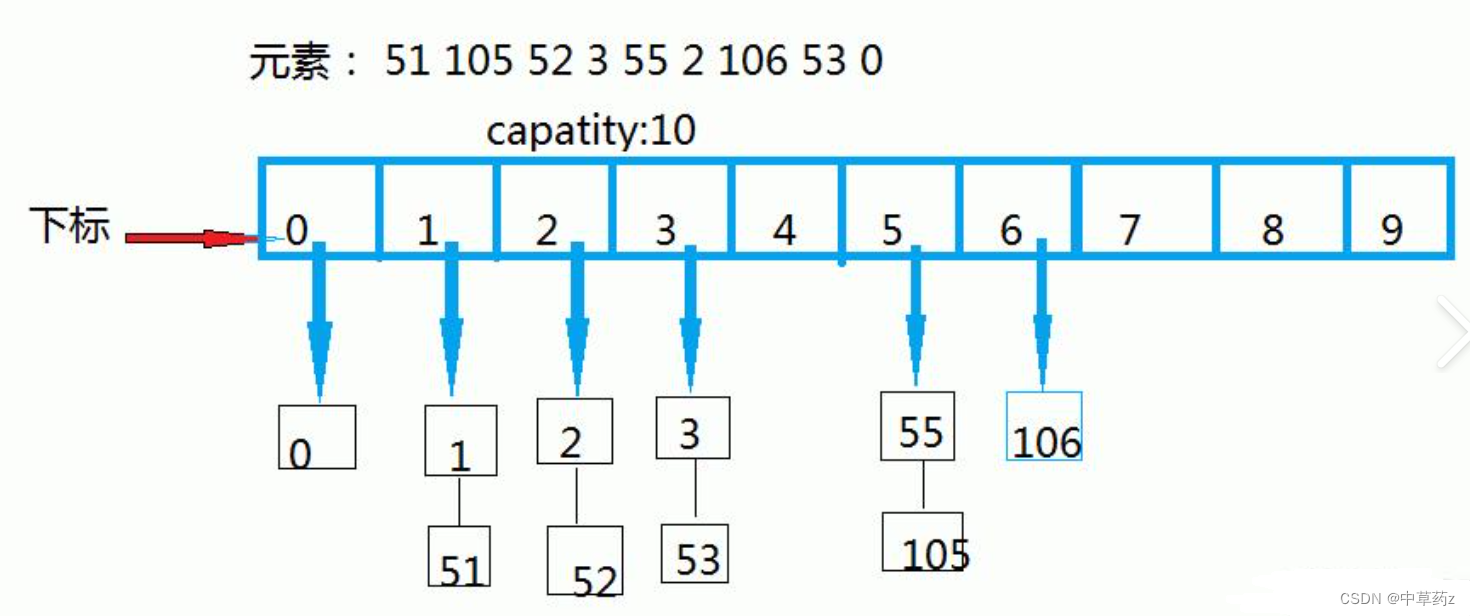
哈希桶(Hash Bucket)是哈希表(Hash Table)中用于解决哈希冲突的一种常用方法,它是哈希表数据结构的一个重要组成部分。哈希桶是哈希表中存储元素的地方,通常是一个数组。每个桶都有一个索引,通过哈希函数计算得到的哈希值会决定元素被放置在哪个桶中。
🪗1.哈希桶原理
哈希桶解决哈希冲突的方法是,将哈希表的每个槽(或索引)扩展为一个“桶”(Bucket),这个桶本质上是一个数据结构(通常是链表、数组或其他容器),可以存储多个具有相同哈希值的元素。具体来说,当一个键通过哈希函数计算得到的索引已经有其他元素时,新的元素会被添加到这个索引对应的桶中,而不是覆盖原有的元素。
🎸2.哈希桶的实现细节
-
哈希函数:用于将键转换成索引。好的哈希函数能够尽量均匀地分布元素,减少冲突。
-
桶的实现:常用的桶实现是链表,因为链表插入和删除操作的时间复杂度较低。但在Java 8以后的HashMap中,当桶中的元素数量达到一定阈值时,会将链表转换为红黑树,以进一步优化查询性能。
-
负载因子:表示哈希表中已填入元素的数量与哈希表长度的比例,用于衡量哈希表的填充程度。当负载因子超过某个预设值时,哈希表会进行扩容,重新调整大小,以减少冲突,保持高效性能。
-
扩容:扩容通常涉及创建一个新的、更大容量的哈希表,并将原哈希表中的所有元素重新哈希到新表中。这个过程可以确保桶的平均长度减少,从而减少冲突。
-
冲突处理:当多个键映射到同一索引时,桶中的链表(或红黑树)结构用于存储这些冲突的键值对,并通过遍历链表(或树)来查找具体的元素。
🎹源代码模拟实现
// key-value 模型
public class HashBucket {
private static class Node {
private int key;
private int value;
Node next;
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
private Node[] array;
private int size; // 当前的数据个数
private static final double LOAD_FACTOR = 0.75;
private static final int DEFAULT_SIZE = 8;//默认桶的大小
public int put(int key, int value) {
int index = key % array.length;
Node cur = array[index];
//遍历当前列表,看是否存在当前值
while (cur != null) {
if (cur.key == key) {
cur.value = value;
}
cur = cur.next;
}
//若无当前值,则进行头插法
Node node = new Node(key, value);
node.next = array[index];
array[index] = node;
size++;
//判断是否超载
if (loadFactor()>=LOAD_FACTOR){
//扩容
resize();
}
return 0;
}
private void resize() {
Node[] newArr=new Node[array.length*2];
for (int i = 0; i < array.length; i++) {
Node cur=array[i];
while(cur!=null){
//遍历链表,将数据储存到新数组
int newIndex=cur.key% newArr.length;
Node curN=cur.next;
cur.next=newArr[newIndex];
newArr[newIndex]=cur;
cur=curN;
}
}
array=newArr;
}
private double loadFactor() {
return size * 1.0 / array.length;
}
public HashBucket() {
array=new Node[10];
}
public int get(int key) {
int index=key%array.length;
Node cur=array[index];
while(cur!=null){
if (cur.key==key){
return cur.value;
}
cur=cur.next;
}
return -1;
}
}🪘3.总结
哈希桶机制通过将冲突的元素组织在一起,而非直接覆盖,保证了哈希表的灵活性和高效性。它允许哈希表在面对大量数据时仍能保持较好的性能,尤其是在冲突较多的情况下。通过调整哈希函数、负载因子和适时的扩容,可以进一步优化哈希表的效率。在Java中,HashMap和HashSet就是使用哈希桶来实现的,它们是Java集合框架中非常重要的组件。
📲三.解决哈希冲突的常用方法*
解决哈希冲突是哈希表设计中的关键环节,目的是确保即使两个或多个键通过哈希函数计算出相同的索引,也能高效地存储和检索这些键值对。以下是几种常用的解决哈希冲突的方法:

1. 开放定址法(Open Addressing)
- 线性探测法(Linear Probing):当发生冲突时,从冲突位置开始,沿着数组线性地检查下一个位置,直到找到一个空位。这种方法简单,但容易造成“聚集”现象,影响查找效率。
- 二次探测法(Quadratic Probing):在冲突发生后,按照某种探测序列(通常是二次的,如i^2 + c)寻找下一个空位,这可以减少聚集现象。
- 双重散列法(Double Hashing):使用第二个哈希函数来计算步长,当发生冲突时,按步长跳跃寻找下一个可用位置,以减少探测的顺序性。
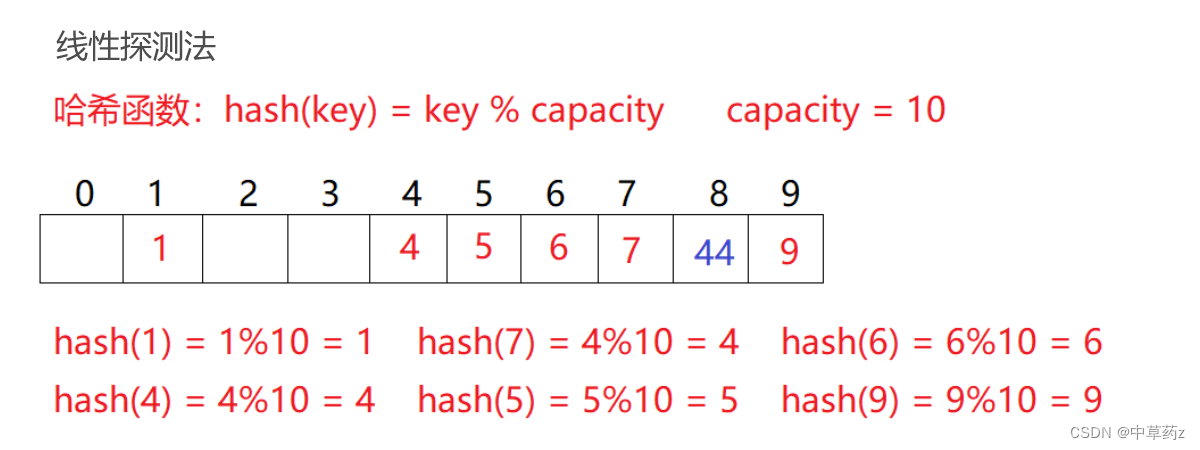

2. 再哈希法(Rehashing)
当第一个哈希函数导致冲突时,使用第二个、第三个不同的多个哈希函数继续尝试寻找空闲位置。这种方法减少了冲突的机会,但增加了计算开销。
再哈希法通过使用一系列哈希函数不断尝试新的位置,而双重散列法则通过一个固定的步长规则在哈希表中进行探测。
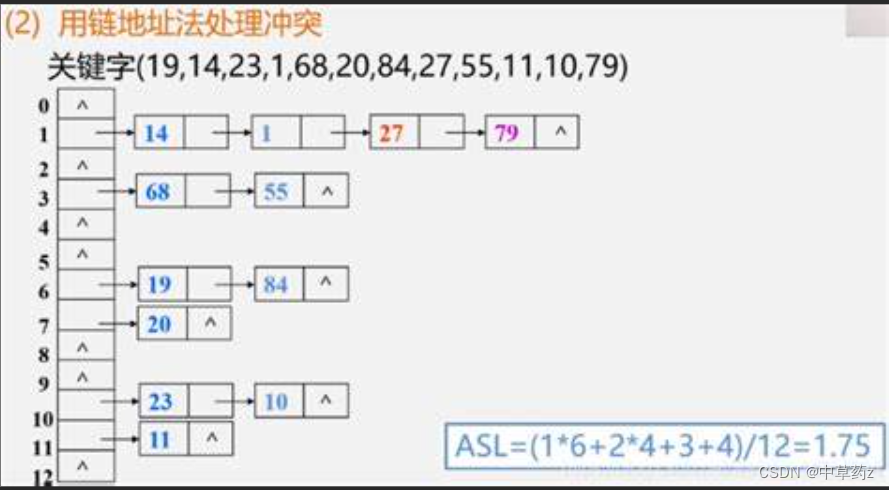
3. 链地址法(Separate Chaining)
每个哈希表的索引位置对应一个链表或其它动态数据结构(如红黑树,Java 8中HashMap的实现)。当发生冲突时,将新的元素添加到该索引位置的链表中。这种方法简单且灵活,但链表过长时会降低查找效率。
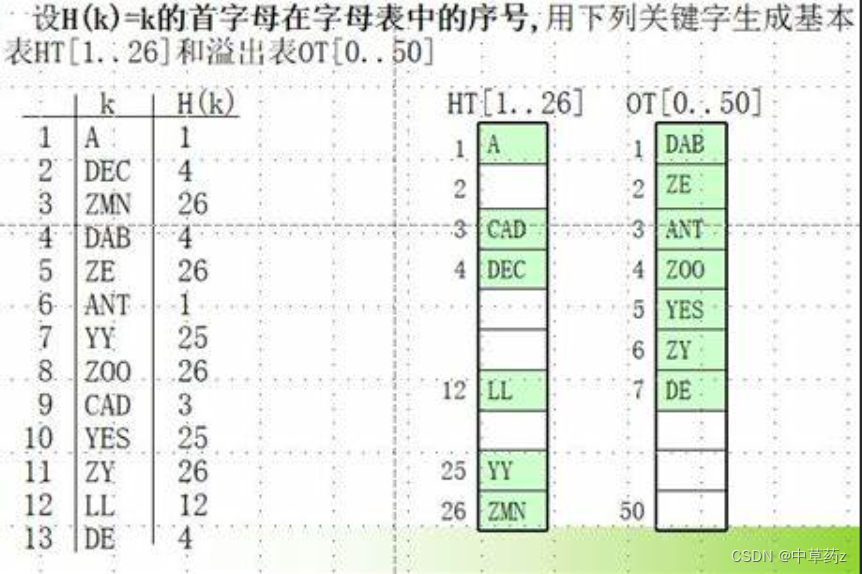
4. 建立公共溢出区(Overflow Area)
这种方法将哈希表分为两个部分:基本表和溢出表。当基本表中的位置已满时,冲突的元素被放置在溢出表中。这种方式实现简单,但效率不如链地址法。
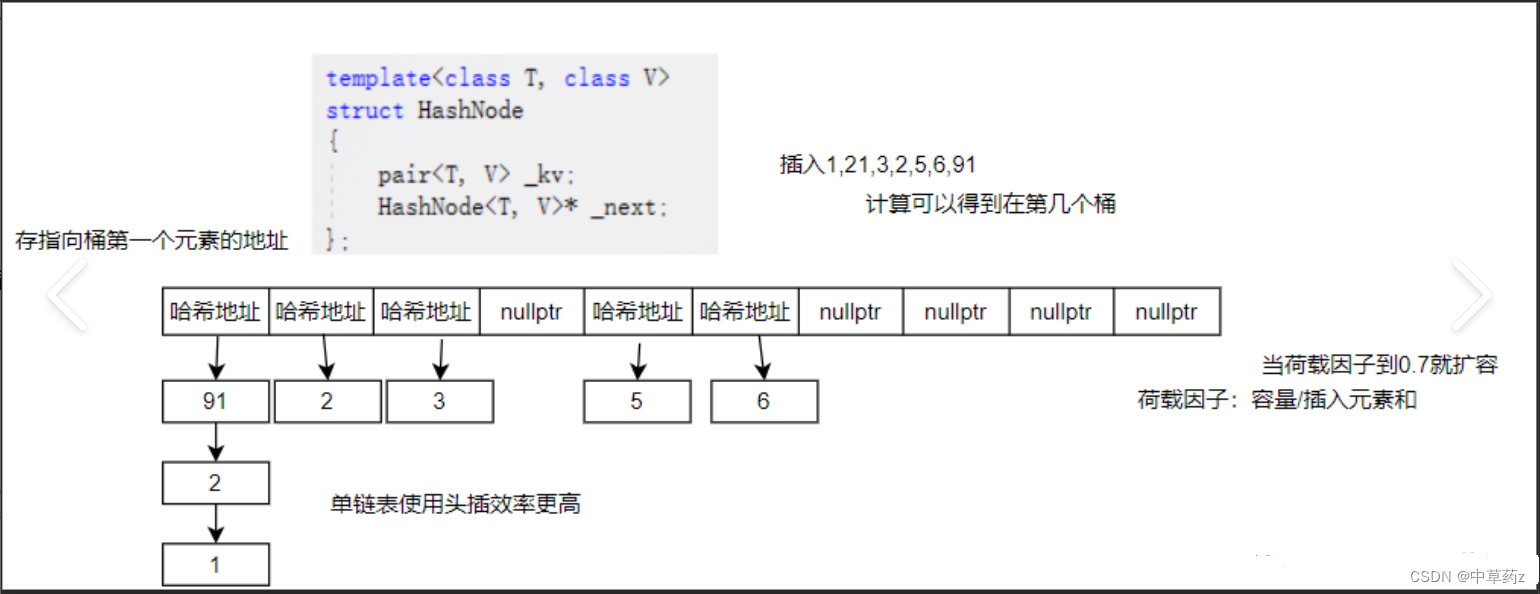
5. 开散列法(Open Hashing)*
这是一种特殊的链地址法,哈希表本身是一个指针数组,每个元素指向一个链表的头节点。这种方法强调了链表的独立性,便于管理和扩展。
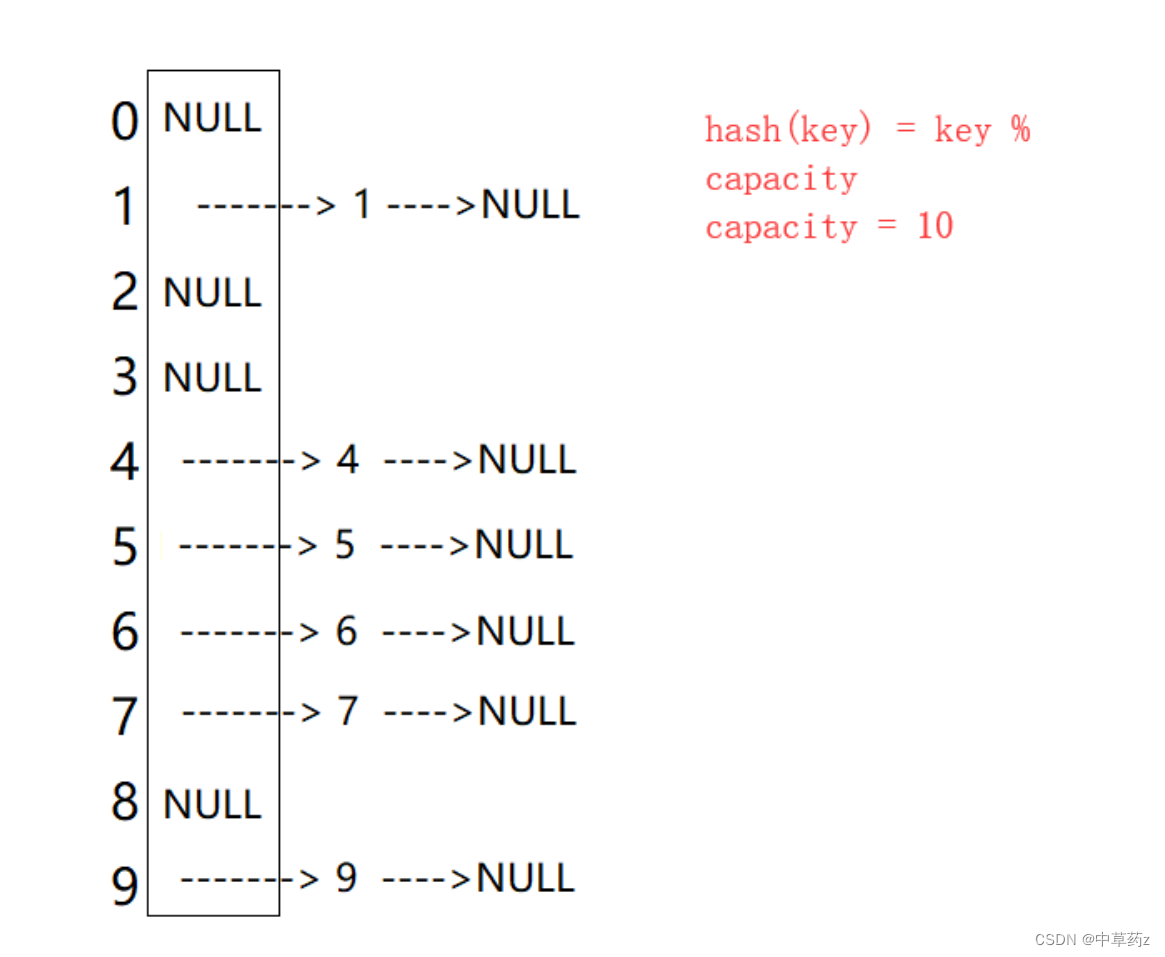
负载因子调整
无论采取哪种冲突解决策略,维护一个合理的负载因子(已用单元数与总单元数的比例)至关重要。当负载因子超过某个阈值时,通常会触发哈希表的扩容操作,通过增大哈希表的大小并重新分配所有元素来减少冲突,保持高效的查找性能。
每种方法都有其优势和劣势,实际应用时需根据具体需求和数据特点选择最适合的冲突解决策略。例如,对于内存充足的场景,链地址法因其实现简单且效果稳定而常用;而在内存受限或查找性能要求极高的场景下,开放定址法或再哈希法可能更为合适。
💰四.HashSet
此部分建议,对照上一篇来学习 Java 【数据结构】 TreeSet&TreeMap(二叉搜索树详解)【神装】
🪙1.定义
Java中的HashSet是一个实现了Set接口的集合类,它提供了一种存储不可重复元素的高效数据结构。HashSet的实现基于HashMap,这意味着它内部使用了哈希表来管理元素,这使得HashSet能够提供快速的插入、删除和查找操作。以下是关于HashSet的一些关键特性和内部工作原理的详细说明:
💵2.操作
| 方法 | 解释 |
| boolean add(E e) | 添加元素,但重复元素不会被添加成功 |
| void clear() | 清空集合 |
| boolean contains(Object o) | 判断 o 是否在集合中 |
| Iterator<E> iterator() | 返回迭代器 |
| boolean remove(Object o) | 删除集合中的 o |
| int size() | 返回set中元素的个数 |
| boolean isEmpty() | 检测set是否为空,空返回true,否则返回false |
| Object[] toArray() | 将set中的元素转换为数组返回 |
| boolean containsAll(Collection<?> c) | 集合c中的元素是否在set中全部存在,是返回true,否则返回 false |
| boolean addAll(Collection<? extends E> c) | 将集合c中的元素添加到set中,可以达到去重的效果 |
源代码
import java.util.HashSet;
public class HashSetExample {
public static void main(String[] args) {
// 创建一个HashSet实例
HashSet<String> myHashSet = new HashSet<>();
// 添加元素
myHashSet.add("Apple");
myHashSet.add("Banana");
myHashSet.add("Cherry");
System.out.println("HashSet after adding elements: " + myHashSet);
// 检查元素是否存在
boolean isPresent = myHashSet.contains("Banana");
System.out.println("Is 'Banana' in the HashSet? " + isPresent);
// 尝试添加重复元素
myHashSet.add("Apple");
System.out.println("HashSet after trying to add duplicate 'Apple': " + myHashSet);
// 删除元素
boolean isRemoved = myHashSet.remove("Banana");
System.out.println("Is 'Banana' removed? " + isRemoved);
System.out.println("HashSet after removing 'Banana': " + myHashSet);
// 遍历HashSet
System.out.println("Iterating over HashSet:");
for (String fruit : myHashSet) {
System.out.println(fruit);
}
// 清空HashSet
myHashSet.clear();
System.out.println("HashSet after clearing: " + myHashSet);
}
}💶3.特性
-
无序性:HashSet不保证元素的插入顺序,每次遍历HashSet时,元素的顺序可能不同。这是因为HashSet在内部使用哈希表,元素的存储位置由其哈希值决定。
-
不允许重复:HashSet中不能包含重复的元素。这是通过比较元素的哈希值以及
equals()方法来实现的。如果两个元素的哈希值相同,并且通过equals()方法比较也认为是相等的,则视为重复元素,后者将不会被加入集合中。 -
允许null值:HashSet允许存储一个null元素,因为HashMap允许一个键为null。
-
非线程安全:HashSet不是线程安全的。如果多个线程同时访问一个HashSet,且至少有一个线程修改了HashSet,则必须通过外部同步来保证线程安全。
💷4.内部实现
-
基于HashMap:HashSet实际上是一个包装器,它将每个元素作为HashMap的键,并且所有元素共享一个静态的、唯一的值对象作为映射的值。这意味着HashSet中元素的添加、删除等操作实际上是在操作底层的HashMap。
-
哈希值与索引:当向HashSet添加元素时,首先调用该元素的
hashCode()方法计算哈希值,然后使用哈希值来确定元素在底层数组中的索引位置。如果该位置已有元素(哈希冲突),则使用链地址法(在JDK 7及以前是单向链表,在JDK 8中引入了红黑树,当链表长度超过8时会转换为红黑树)来存储多个具有相同索引的元素。 -
扩容机制:当HashSet中的元素数量超过其当前容量乘以负载因子时,HashSet会自动进行扩容,以减少哈希冲突并保持高效的查找性能。扩容包括创建一个新的更大的数组,并将原数组中的所有元素重新哈希到新数组中。
- 重写equals()与hashCode():为了确保HashSet能正确识别重复元素,存储在HashSet中的自定义对象必须正确重写
equals()和hashCode()方法,保证相等的对象具有相同的哈希值,并且通过equals()方法判断也为相等。
💳5.应用场景
Java中的HashSet是一个高效无序且不允许重复元素的集合类,基于HashMap实现。
- 它的核心应用场景包括数据去重、集合运算、缓存实现、快速查找成员、统计唯一元素、辅助高级数据结构及游戏开发中的对象管理等。
- HashSet利用哈希机制提供快速的插入、删除和查找功能,特别适合需要高效率集合操作的场景。
HashSet是Java集合框架中一个非常实用的类,特别适用于需要快速插入、删除和查找,且不需要维护元素插入顺序的场景。理解其基于HashMap的实现以及如何利用哈希机制来管理元素,对于高效使用HashSet至关重要。
✏️五.HashMap
此部分建议,对照上一篇来学习 Java 【数据结构】 TreeSet&TreeMap(二叉搜索树详解)【神装】
✒️1.定义
Java中的HashMap是一个实现Map接口的类,它提供了一个存储键值对(key-value pairs)的数据结构。HashMap允许使用唯一的键来映射到特定的值,并且能够高效地进行插入、删除和查找操作。键值对之间没有特定的顺序,HashMap也不是线程安全的。
🖋️2.操作
| 方法 | 解释 |
| V get(Object key) | 返回 key 对应的 value |
| V getOrDefault(Object key, V defaultValue) | 返回 key 对应的 value,key 不存在,返回默认值 |
| V put(K key, V value) | 设置 key 对应的 value |
| V remove(Object key) | 删除 key 对应的映射关系 |
| Set<K> keySet() | 返回所有 key 的不重复集合 |
| Collection<V> values() | 返回所有 value 的可重复集合 |
| Set<Map.Entry<K, V>> entrySet() | 返回所有的 key-value 映射关系 |
| boolean containsKey(Object key) | 判断是否包含 key |
| boolean containsValue(Object value) | 判断是否包含 value |
源代码
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
// 创建一个HashMap实例
HashMap<String, Integer> myHashMap = new HashMap<>();
// 添加键值对
myHashMap.put("Apple", 1);
myHashMap.put("Banana", 2);
myHashMap.put("Cherry", 3);
System.out.println("HashMap after adding elements: " + myHashMap);
// 更新键对应的值
myHashMap.put("Apple", 4);
System.out.println("HashMap after updating 'Apple': " + myHashMap);
// 检查键是否存在
boolean isPresent = myHashMap.containsKey("Banana");
System.out.println("Is 'Banana' a key in the HashMap? " + isPresent);
// 删除键值对
myHashMap.remove("Banana");
System.out.println("HashMap after removing 'Banana': " + myHashMap);
// 遍历HashMap
System.out.println("Iterating over HashMap:");
for (Map.Entry<String, Integer> entry : myHashMap.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
// 获取特定键的值
Integer appleValue = myHashMap.get("Apple");
System.out.println("Value of 'Apple': " + appleValue);
// 检查一个键是否存在且获取其值
Integer orangeValue = myHashMap.getOrDefault("Orange", -1); // 如果没有找到键'Orange',则返回-1
System.out.println("Value of 'Orange' or default: " + orangeValue);
}
}🖊️3.特性
- 键值关联:HashMap存储的是键值对,其中键是唯一的,而值可以重复。
- 无序性:HashMap中的元素没有特定的顺序,迭代时的顺序并不反映插入时的顺序。
- 允许null值和null键:HashMap是少数几个可以接受null键和null值的Java集合之一,但每个HashMap只能有一个null键。
- 线程不安全:HashMap不是线程安全的,多线程环境下若不采取额外的同步措施,可能导致数据不一致性。
- 可调整大小:随着元素的增加,HashMap会自动扩容来维持其性能,通过重新哈希所有元素到更大的数组中实现。
- 性能:平均情况下,HashMap提供O(1)的时间复杂度进行插入、删除和查找操作。
🖍️4.内部实现
-
哈希表:HashMap的底层实现是一个哈希表,它由一个动态调整大小的数组(称为桶或bin)组成,数组的每个位置可以是一个链表或红黑树(JDK 8开始)。
-
哈希函数:HashMap使用哈希函数将键转换成数组的索引。哈希冲突通过链地址法解决,即在同一索引位置的多个元素通过链表或红黑树链接起来。
-
负载因子:HashMap有一个负载因子,默认为0.75,它决定了HashMap何时进行扩容。当HashMap中的元素数量超过当前容量乘以负载因子时,HashMap会自动扩容,一般扩容为原来的两倍。
-
扩容机制:扩容时,HashMap会创建一个新的更大容量的数组,并将原数组中的所有元素重新哈希到新数组中,这个过程涉及到重新计算哈希值和重新分配。
🖌️5.应用场景
- 缓存:HashMap非常适合做轻量级的缓存,快速存取热点数据。
- 数据映射:在需要快速根据键查找相关联值的场景,如配置参数管理。
- 计数:可以用HashMap统计元素出现的频率,键是元素,值是出现次数。
- 去重:虽然HashSet更直接,但在需要存储额外信息或自定义比较逻辑时,HashMap可以用来去重。
- 图的邻接表表示:在图算法中,HashMap可以用来表示顶点的邻接关系,键是顶点,值是一个列表或集合,包含与该顶点相邻的所有顶点。
综上,HashMap凭借其高效的查找和灵活的键值对存储机制,在众多Java应用中扮演着核心角色。
📝六.对比
Set
| Set底层结构 | TreeSet |
HashSet
|
| 底层结构 | 红黑树 |
哈希桶
|
| 插入/删除/查找时间 复杂度 | O(log N) |
O(1)
|
| 是否有序 | 关于Key有序 |
不一定有序
|
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 按照红黑树的特性来进行插入和删除 |
1.
先计算
key
哈希地址
2.
然后进行插入和删除
|
| 比较与覆写 | key必须能够比较,否则会抛出 ClassCastException异常 |
自定义类型需要覆写
equals
和
hashCode
方法
|
| 应用场景 | 需要Key有序场景下 |
Key
是否有序不关心,需要更高的
时间性能
|
Map
| Map底层结构 | TreeMap |
HashMap
|
| 底层结构 | 红黑树 |
哈希桶
|
| 插入/删除/查找时间 复杂度 | O(log N) | O(1) |
| 是否有序 | 关于Key有序 |
无序
|
| 线程安全 | 不安全 |
不安全
|
| 插入/删除/查找区别 | 需要进行元素比较 |
通过哈希函数计算哈希地址
|
| 比较与覆写 | key必须能够比较,否则会抛出 ClassCastException异常 |
自定义类型需要覆写
equals
和
hashCode
方法
|
| 应用场景 | 需要Key有序场景下 |
Key
是否有序不关心,需要更高的
时间性能
|
💼七.总结与反思
盛年不重来,一日难再晨,及时当勉励,岁月不待人。——陶渊明
HashSet学习总结
HashSet是Java集合框架中实现Set接口的一个重要类,它提供了一种无序且不重复元素的集合。HashSet的核心特点是:
- 不重复性:HashSet不允许存储重复的元素,这是通过调用元素的
hashCode()和equals()方法来确保的。这两个方法共同决定元素的唯一性。 - 无序性:HashSet不保证元素的插入顺序,遍历HashSet时得到的顺序可能与插入顺序不同。
- 基于HashMap实现:HashSet实际上是对HashMap的一种包装,它将元素作为HashMap的键,而值统一设为一个固定对象(如
PRESENT常量),从而达到只关心键的目的。 - 性能优势:得益于HashMap的哈希表实现,HashSet提供了高效的添加、删除和查找操作,平均时间复杂度接近O(1)。
- 注意事项:使用自定义对象作为HashSet的元素时,必须重写
hashCode()和equals()方法,确保逻辑上相同(根据业务定义)的对象具有相同的哈希值和相等性判断。
HashMap学习总结
HashMap是Java中最常用的键值对集合,它实现了Map接口,提供了一种快速存取键值对的方式。HashMap的主要特征有:
- 键值对存储:每个元素由一个键和一个值组成,键是唯一的,值可以重复。
- 哈希表结构:内部使用哈希表实现,通过哈希函数将键映射到数组的特定索引,解决冲突的方法是链地址法(JDK 7及以前是链表,JDK 8引入了链表/红黑树的结构转换)。
- 线性探测法和扩容:当哈希碰撞导致冲突时,通过开放寻址法(如线性探测)或链表/红黑树解决。当HashMap的填充程度达到一定阈值(由负载因子控制,默认0.75),会触发扩容,以保持高效性能。
- 线程不安全:HashMap在多线程环境下不是线程安全的,若在并发环境中使用,推荐使用
ConcurrentHashMap。 - null值处理:HashMap允许一个null键和多个null值,这是与某些其他集合类不同的地方。
反思
- 理解哈希机制的重要性:深入理解哈希函数、冲突解决策略对于高效使用HashSet和HashMap至关重要。实际开发中,合理的重写
hashCode()和equals()方法能够显著提升集合操作的性能。 - 并发使用的风险:在多线程环境下,直接使用HashMap可能导致数据不一致。意识到这一点后,未来在设计系统时,应当优先考虑线程安全的集合类,如
ConcurrentHashMap。 - 性能与内存权衡:虽然HashMap提供了快速的访问速度,但其内存占用相对较高,尤其是在高负载因子下。在内存敏感的应用中,应权衡性能与内存消耗,选择合适的集合类型或调整集合参数。
- API的深入理解:HashMap和HashSet提供了丰富的API,如
computeIfAbsent()、putIfAbsent()等,这些方法在特定场景下能够简化代码,提高效率。掌握并合理利用这些高级API能够提升代码质量。
总之,深入学习HashSet和HashMap不仅要求理解其底层数据结构和实现原理,还需关注其在具体应用环境下的适用性和限制,通过实践不断加深理解,并灵活运用到项目开发中。
🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀
以上,就是本期的全部内容啦,若有错误疏忽希望各位大佬及时指出💐
制作不易,希望能对各位提供微小的帮助,可否留下你免费的赞呢🌸