在数字化的时代浪潮中,人工智能技术正以前所未有的速度蓬勃发展,而大模型作为其中的翘楚,以生成式对话技术逐渐成为推动行业乃至整个社会进步的核心力量。再往近一点来说,在公司,不少产品都戴上了人工智能的帽子,各种高大上人工对话界面,作为一个已经工作8年的老程序员来说,一种压力感扑面而来,这使得我不得不去接受新的东西,在学习和使用Prompt、function-call和Rag后发现了一个对AI初学者极其友好的框架——Langchain,帮助我更好更快的使用大模型。
在接下来的文章里,我将带着大家来分析和感受LangChain的发展和应用。通过深入了解,我们可以更好地利用LangChain的优势和避免它的不足之处。
LangChain总结
面向大模型的开发框架(SDK)
LangChain是一套被设计成易于使用的软件工具集,专门为程序员提供了使用大型模型的能力。它的主要目的是帮助程序员减少开发工作量,并且将底层的复杂和重复性工作封装起来。使用LangChain,你可以简单方便地利用这些封装好的功能来开发软件。这个框架的初衷就是让你能够更加高效地开发,并且更加轻松地使用大型模型的能力。
基于软件工程思维,要更关注接口变更
使用这套框架确实需要一定的代码能力,因为这个框架的设计本质是基于软件工程思路的,对编程基础有一定要求。另外,大模型技术和辅助工具正处于一个初级阶段,发展时间并不长,大模型诞生也就好一年多的时间。因此,在学习这些工具时,我们最好不要过于专注于每个接口的具体用法,例如像前端框架vue对于这个功能怎么实现,这类工具不能这么学,因为大模型技术目前还处于初级阶段,未来仍会有很多变化。我们更应该关注这些框架的设计思路和模块结构,因为它们的模块大部分可能不会改变,只是接口可能会有一些细微的调整。更应该关注它的设计思路在你的实际工作中能否得到参考,通过这些思考我到底是直接拿它来用,还是参考它来设计,还是完全做一个更新的设计,这些都会在实际开发中大有裨益。
AGI 时代软件工程的一个探索和原型,迭代速度快
LangChain的迭代速度明显快于Semantic Kernel,几乎每天都有一个新版本发布。LangChain的发展是一个学习和探索的过程,在早期存在许多不成熟的接口,以及一些设计过于复杂的函数或流程。但是通过这么多次的迭代,几乎所有的问题都得到了修复,可以说它的成熟度是与日俱增的,目前来看,LangChain已经具备了一定的可用性的。一些模块在设计上非常成熟,具备拿来就用的,甚至在生产机使用时没问题的,而有些模块设计的还是很粗糙,例如第三方功能实现的一些模块,不建议使用的。还有一些模块在设计上没有问题,但在实际工作中可能并不是必需的,完全取决于你的需求。接下来我将带着大家来分析和感受。
与其他开发框架的对比

数据来源:GitHub Star History
Github的平行树的对比,LangChain的欢迎程度明显还是遥遥领先的,之所以会形成这个情况,是因为LangChain最早期设计是比较简单易懂,不像Semantic-kernel是有一套宏大的理念导致整个抽象程度太高,导致它的可读性或感受上很晦涩。所以Langchain比较方便大家知道怎么用,拿来就知道好不好用,都能很直接的评估出来。
LangChain 的核心组件
模型 I/O 封装
- LLMs:大语言模型,因为它对模型、检索都做了统一的封装,调用llama或其他大模型实现本地的Rag会更加简单。
- Chat Models:一般基于 LLMs,但按对话结构重新封装,
- PromptTemple:提示词模板,对提示词模板的操作给以了封装。
- OutputParser:解析输出,模型的输出结果,给了不同的解析工具,这个是Semantic-kernel所没有的,也是它方便使用的功能之一。
数据连接封装
- Document Loaders:如何加载各种格式文档,集结了各种格式文件的加载器。
- Document Transformers:封装了对文档的常用操作工具,如:split, filter, translate, extract metadata, etc
- Text Embedding Models:对不同的embedding模型做了统一的封装,不管你底层是什么,基本都是统一的接口都可以去使用。然后对各种各样的三方的向量数据库做了封装,也就是说你不用太关心,背后向量数据库到底是啥,通过Langchain的统一的接口去调用。文本向量化表示,用于检索等操作。
- Verctorstores: (面向检索的)向量的存储,就是将向量数据库的封装后转成一个检索器
- Retrievers: 向量的检索,一个用于检索的工具。
记忆封装
- Memory:这里不是物理内存,从文本的角度,可以理解为“上文”、“历史记录”或者说“记忆力”的管理。对上下文的管理做了一层封装或赋予了一组工具。
架构封装
最核心的是在架构上做了一层封装,包括了调用一系列组合的pipeline。
- Chain:实现一个功能或者一系列顺序功能组合,pipeline顺序调用。
- Agent:智能体架构的封装,根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能
- Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell 等等
- Toolkits:操作某软件的一组工具集,例如:操作 DB、操作 Gmail 等等
Callbacks
他每个模块内部到底发生了什么,它都给了你一些Callback事件。具体可参考官网,里面有更为详细的讲解。
可参考官网:Callbacks | 🦜️🔗 LangChain
主要用途
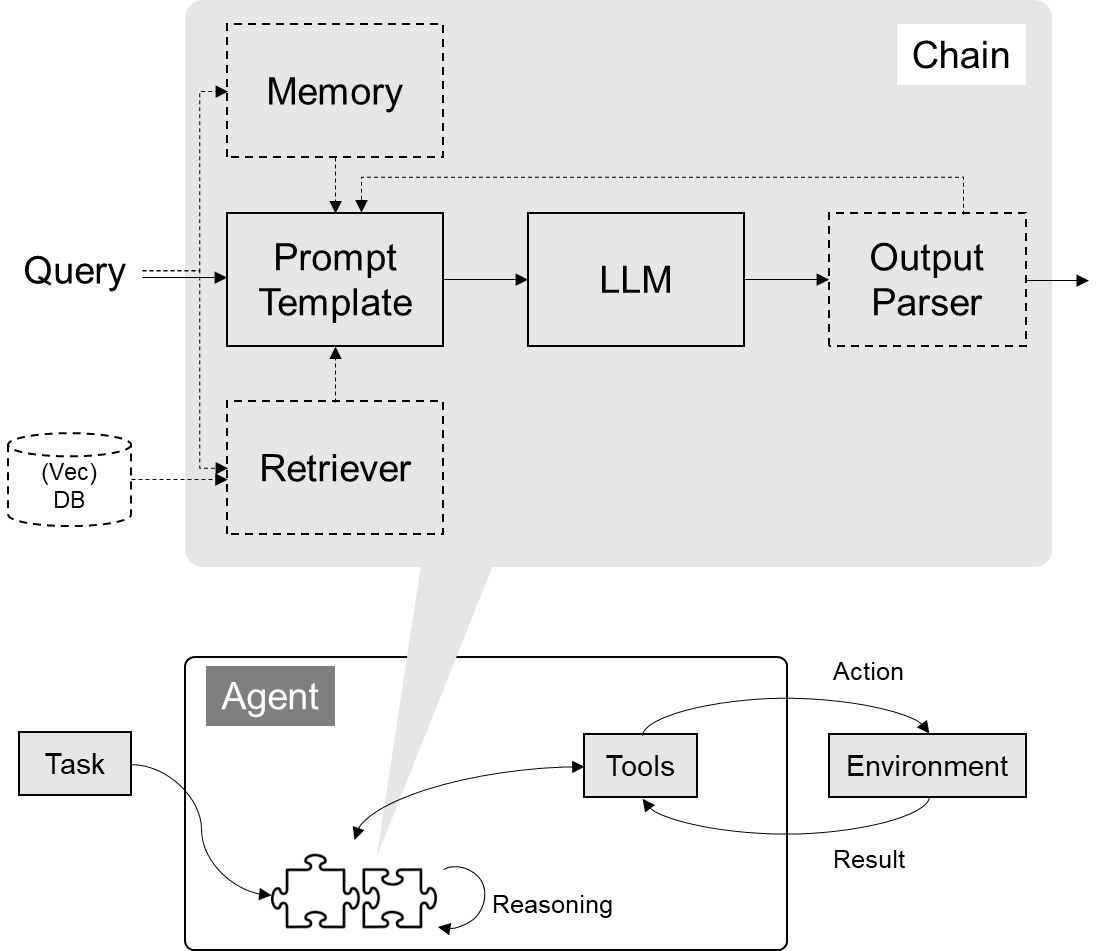
解决Chain的问题
以一个Pipline (一种既定流程去调用不同组件) 的维度去看。核心解决的是一个查询(Query)进来后,可以将问题填充到提示词(Prompt)模板中去,然后通过Prompt去调用大语言模型(LLM)输出的模型结果,其结果(Json / List / Text / Code ...)可以通过Output Parser进行解析提取核心数据放到下个输入环节中,以填充新的Prompt模板,如此反复,不断提炼输出内容。
在前面套流程之上还赋予了上下文管理(Memory)能力和连接外部数据(Retriever)能力及工具。连接外部数据最典型的方式就是以向量数据进行向量检索。核心利用了这几大模块,解决了和大模型打交道常见的功能,然后将这些功能做了统一的封装。做了统一封装的好处就是语言模型我可以换不同的模型的同时还不用该接口,整个代码不用变我就把这个大预言模型就给换了。
构成智能体(Agent)
智能体就是经过自己反复思考,选择不同的工具,通过多步(调用工具 -> 拿到工具结果 ->分析结果 -> 选择工具)处理一个复杂任务,这样一个流程作为大模型诞生后的一个新的模式。而里面一个反复思考都是在调用大模型(LLM),这个调用流程其实就是用上面的Chain来进行封装组成的,而LangChain也对智能体架构也做了一个标准化的封装。
相关文档(以 Python 版为例)
官方文档还是比较清晰的,Docs是LangChain自己提供的核心组件所有得文档和例子;Integrations是所有跟三方的服务和组件的连接,比如你要连接各种各种的语言模型Llama,或不同的向量数据等都在这里面可以找到;Use cases则是Langchain封装好的流程和功能,例如怎么实现Rag、怎么实现Sql查数据库、怎么实现checkout和怎么实现摘要这类的例子;更深一点比如说怎么做debugging、调试部署、评估这类相关的文档里没有的技巧和方法都在Guides里边。
主要几大核心文档
- 功能模块:主要模块有Model I/O、Retrieval、Agents、Chains、Memory、Callbacks这类

直通车:https://python.langchain.com/docs/get_started/introduction
- API 文档:针对以上更细的内容,如每个函数、每个类,参数、响应的接口文档描述。

直通车:https://api.python.langchain.com/en/latest/langchain_api_reference.html
- 三方组件集成:提供程序具有独立的langchain-{provider}包,用于改进版本控制、依赖关系管理和测试。
直通车:https://python.langchain.com/docs/integrations/platforms/
- 官方应用案例:包含常见对接技术和例子
直通车:https://python.langchain.com/docs/use_cases
- 调试部署等指导:https://python.langchain.com/docs/guides/debugging
小试牛刀
安装最新LangChain依赖
pip install --upgrade langchain
pip install --upgrade langchain-openai # v0.1.0新增的底包
pip install qianfan #安装文言千帆模型ApiOpenAI vs Langchain
接下来会用以下这两个例子对比Langchain的优势。
多轮对话实现
OpenAI
原生的Openai通过一个json数组,每一轮都一个任务一个content来去表示一个对话上下文。
# 加载 .env 文件到环境变量
from dotenv import load_dotenv, find_dotenv
from openai import OpenAI
_ = load_dotenv(find_dotenv())
# 初始化 OpenAI 服务。会自动从环境变量加载 OPENAI_API_KEY 和 OPENAI_BASE_URL
client = OpenAI()
# 消息格式
messages = [
{
"role": "system",
"content": "你是AI助手小京。"
},
{
"role": "human",
"content": "我是Csdn的一名博主,我叫Muller"
},
{
"role": "assistant",
"content": "欢迎!"
},
{
"role": "user",
"content": "我是谁?"
},
]
# 调用 GPT-3.5
chat_completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
# 输出回复
print(chat_completion.choices[0].message.content)
# 您自己告诉我您是CSDN的博主Muller。Langchian
那么在langchain的框架下,可以通过它定义的结构来去表示一个对话。然后呢我们还是把这个对话通过invoke接口来传给大模型。
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain_openai import ChatOpenAI
llm = ChatOpenAI() # 默认是gpt-3.5-turbo
from langchain.schema import (
AIMessage, #等价于OpenAI接口中的assistant role
HumanMessage, #等价于OpenAI接口中的user role
SystemMessage #等价于OpenAI接口中的system role
)
messages = [
SystemMessage(content="从现在开始你叫AI助手-小京。"),
HumanMessage(content="我是Csdn的一名博主,我叫Muller"),
AIMessage(content="欢迎!"),
HumanMessage(content="我是谁")
]
response = llm.invoke(messages)
print(response.content)
#你是Muller,一名CSDN的博主。Langchains实现会更加的简洁,且可以轻松实现一个Pipline。
国产模型调用
OpenAi
import json
import requests
import os
# 通过鉴权接口获取 access token
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": "ERNIE_CLIENT_ID",
"client_secret": "ERNIE_CLIENT_SECRET"
}
return str(requests.post(url, params=params).json().get("access_token"))
# 调用文心4.0对话接口
def get_completion_ernie(prompt):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions_pro?access_token=" + get_access_token()
payload = json.dumps({
"messages": [
{
"role": "user",
"content": prompt
}
]
})
headers = {'Content-Type': 'application/json'}
response = requests.request(
"POST", url, headers=headers, data=payload).json()
return response["result"]
class RAG_Bot:
def __init__(self, llm_api, n_results=2):
self.llm_api = llm_api
self.n_results = n_results
def chat(self, user_query):
# 3. 调用 LLM
response = self.llm_api(user_query)
return response
# 创建一个RAG机器人
new_bot = RAG_Bot(
llm_api=get_completion_ernie
)
user_query = "你是谁?"
response = new_bot.chat(user_query)
print(response)Langchain
# 其它模型分装在 langchain_community 底包中
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_core.messages import HumanMessage
import os
llm = QianfanChatEndpoint(
qianfan_ak=os.getenv('ERNIE_CLIENT_ID'),
qianfan_sk=os.getenv('ERNIE_CLIENT_SECRET')
)
messages = [
HumanMessage(content="你是谁")
]
ret = llm.invoke(messages)
print(ret.content)通过模型封装,实现不同模型的统一接口调用