文章目录
- 线性回归
- 概念
- 使用sklearn实现上证中立指数预测
- 内置数据集的加载与处理
- 外部数据集的加载和处理
- 数据内容
- 数据加载和处理
- 开始预测
- 分割数据集
- 导入线性回归模型
- 查看线性回归模型的系数
- 绘制预测结果
- 预测效果评估
- 最终代码
线性回归
线性回归(Linear Regression)模型是最简单的线性模型之一,很具代表性
概念
我们在高中时代其实就学过使用最小二乘法进行线性回归分析
这实际上是统计学部分的内容,会有大量的自变量,或者说解释变量,还有就是对应的因变量,也就是输出结果,回归分析就是找出他们对应的关系,并且使用某个模型描述出来,这样一来给出新的变量,就能利用模型实现预测
这也就是我们一开始介绍机器学习说明的过程,给出输入和输出,找到一个模型T能够很好的拟合这些数据,从而使用T就能预测结果了
从几何层面,回归就是找到具有代表性的直线、曲线、甚至是面,来进行拟合
回归的种类有很多,一元和多元,那么一元其实就是线性回归。我们这里先讨论线性回归,而且我们假设因变量和自变量之间是满足线性关系的,也就是 y = w 0 + w 1 x y=w_0+w_1x y=w0+w1x
这里的 w 0 w_0 w0和 w 1 w_1 w1我们称之为回归系数,我们需要拟合的,求出来的就是这两个权值,一个经典的示意图是这样的
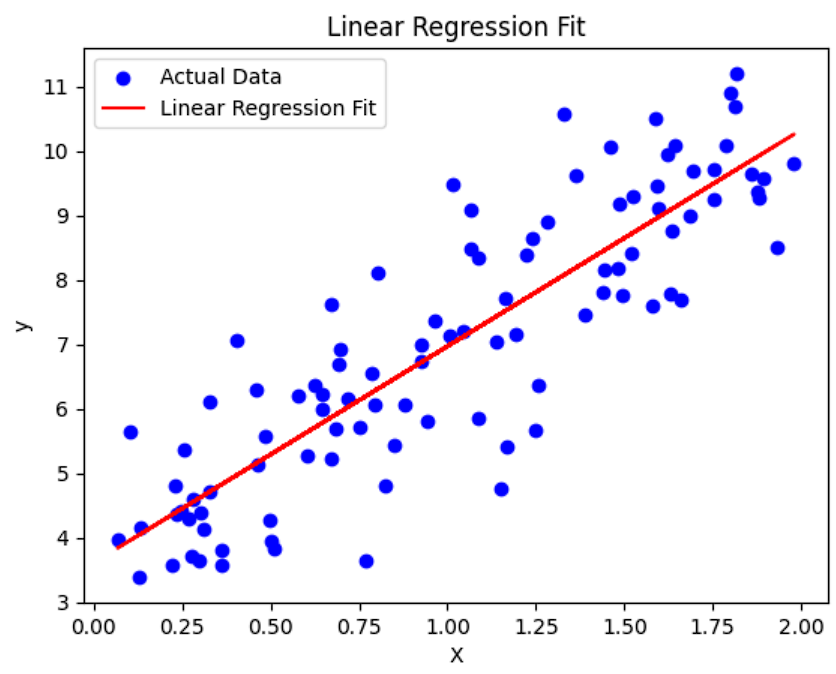
这里的每一个点就是实际的数据,红色的线是我们拟合出来的,很容易可以看得到,有些点离线近,有些点离线远,我们使用残差(Residual)来描述这里的远和近,也就是误差,简单说就是从点向x轴做垂线与拟合线相交的点的距离就是残差, ϵ = ∣ y ^ i − y i ∣ \epsilon=|\hat y_i-y_i| ϵ=∣y^i−yi∣
这里的小帽子表示的是预测数据,就是不准的意思,没啥难理解的
那么我们的目标就变成了,要求一条拟合的线,让所有的误差最小
这里的思想就是使用最小二乘法(Ordinary Least Squares,OLS)了,就是要让残差的平方和最小即可,那我们的损失函数就可以变成这样了 H = ∑ i = 1 m ( y ^ i − y i ) 2 = ∑ i = 1 m ( y i − w 1 x i − w 0 ) 2 H=\sum_{i=1}^{m}(\hat y_i-y_i)^2=\sum_{i=1}^{m}(y_i-w_1x_i-w_0)^2 H=∑i=1m(y^i−yi)2=∑i=1m(yi−w1xi−w0)2
以上就是求解这两个参数,也就是求一个二元函数 H ( w 0 , w 1 ) H(w_0,w_1) H(w0,w1)的最小值,然后取出对应的 w 0 w_0 w0和 w 1 w_1 w1即可
事实上我们也可以利用优化算法(随机梯度下降法、牛顿迭代法)来快速逼近最优参数
使用sklearn实现上证中立指数预测
内置数据集的加载与处理
以导入波士顿房价数据集为例
form sklearn.datasets import load_boston
这里的boston可以换成别的数据集
| 名称 | 数据集 |
|---|---|
| load_boston | 波士顿房价 |
| load_breast_cancer | 乳腺癌 |
| load_iris | 鸢尾花 |
| load_diabetes | 糖尿病 |
| load_linnerud | 体能训练 |
| load_wine | 红酒品类 |
然后对应的就是数据处理的部分了
boston = load_boston() # boston是一个字典对象,我们可以使用key方法查看他对应的属性值
在取出来字典之后,我们就可以进行数据预处理和分析了
外部数据集的加载和处理
我们首先需要收集数据,这里我们直接在官网可以下载上证红利指数
数据内容
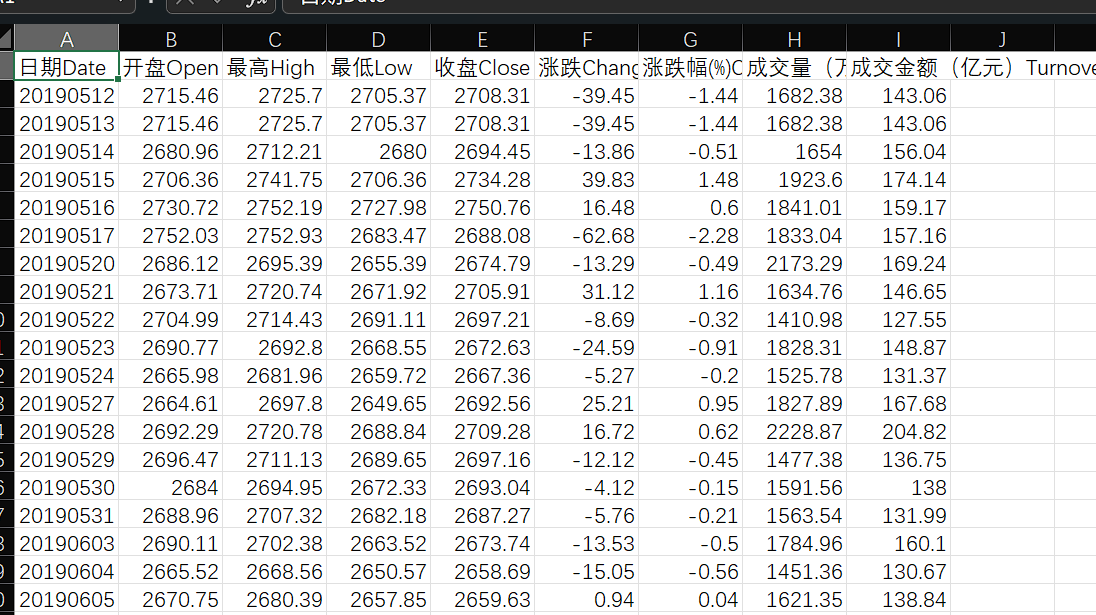
这里我把所有的非数值类型的数据全部删除了,这里是五年的数据
那么这里的特征值有,开盘,最高,最低,收盘,涨跌,涨跌幅,成交量,成交金额
数据加载和处理
下载之后我们获取到的就是一份表格文件了,下载可能是xlsx格式的,可以另存为csv格式的,方便处理
我这里使用pandas进行读取和预处理工作
import pandas as pd
file_path = './000015perf.csv'
data = pd.read_csv(file_path)
这里使用read_csv直接读取的data是DataFrame类型的数据了
如果我们使用的是内置数据,就要通过pd.DataFrame(boston.data)来转换成DataFrame类型
之后我们可以给他加上标签,数据清洗等操作
# 删除含有缺失值的行
data_clean = data.dropna()
我们直接把有缺失的情况给扔掉
开始预测
分割数据集
正如我们前面所说,我们至少要把整个数据集分割成两部分,训练集和测试集,为了保证数据分割的随机性和专业性,sklearn提供了专门的分割函数,train_test_split
我们直接读取的内容是预测的结果y,我们称之为标签数据,和特征值x,我们称之为特征数据
这个专门的分割函数是要求特征数据和标签数据必须是分开的,我们可以使用pandas的drop方法去除
X = data_clean.drop(columns=['日期Date', '涨跌Change', '涨跌幅(%)Change(%)'])
y = data_clean['涨跌Change']
这里我们删除了日期,因为没啥太大作用,还有可能影响预测结果的涨跌和涨跌幅度,并且把涨跌作为预测的对象
有一个细节是特征数据一般用大写的X,特征值一般用小写的y
接下来就是进行训练集和测试集的分割
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=20)
test_size是表示测试集合所占的比例,random_state表示随机的状态
这里的随机状态其实是相反的意思,就是为了保证某些数据是固定的,因为一旦全随机可能会导致预测不够准确,从而无法调参,而固定下一部分数据作为训练集和测试集的话是提供了一定的稳定性,这种稳定性也方便了调参的进行
导入线性回归模型
在数据分割完成之后,我们就可以导入线性回归模型,训练数据并且进行模型预测了
from sklearn.linear_model import LinearRegression
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 使用模型进行预测
y_pred = model.predict(X_test)
在sklearn中,训练模型的方法统称为fit
回归分析属于监督学习,所以fit提供两个参数,前者是特征数据,后者是标签数据
查看线性回归模型的系数
线性回归的核心目的就是找到关键的参数,我们可以通过print直接输出查看每个特征的权值
print("w0 = ", model.intercept_)
print("W = ", model.coef_)

我们之前所有的特征值去除影响之后共计6个特征,所以至少有6个权值,再加上w0是截距,应该是7个权值
对于这些权值我们也可以做出一些解释,例如第一个权值对应的是开盘价格,那其实说明开盘价格越高跌的概率就越大,第四个是收盘价格,那其实也很好说明问题了
出现这样直白的结果其实是由于我们特征数据类型收集的不够多,或者是不够具备我们想要研究的特征数据
绘制预测结果
我们可以使用matplotlib来进行预测涨跌和实际涨跌的对比
plt.figure(figsize=(10, 6))
sns.regplot(x=y_test.values, y=y_pred, scatter_kws={'color': 'blue'}, line_kws={'color': 'red', 'linewidth': 2})
plt.xlabel('Actual Stock Change')
plt.ylabel('Predicted Stock Change')
plt.title('Seaborn Regression Plot of Actual vs Predicted Stock Change')
plt.grid(True)
plt.show()
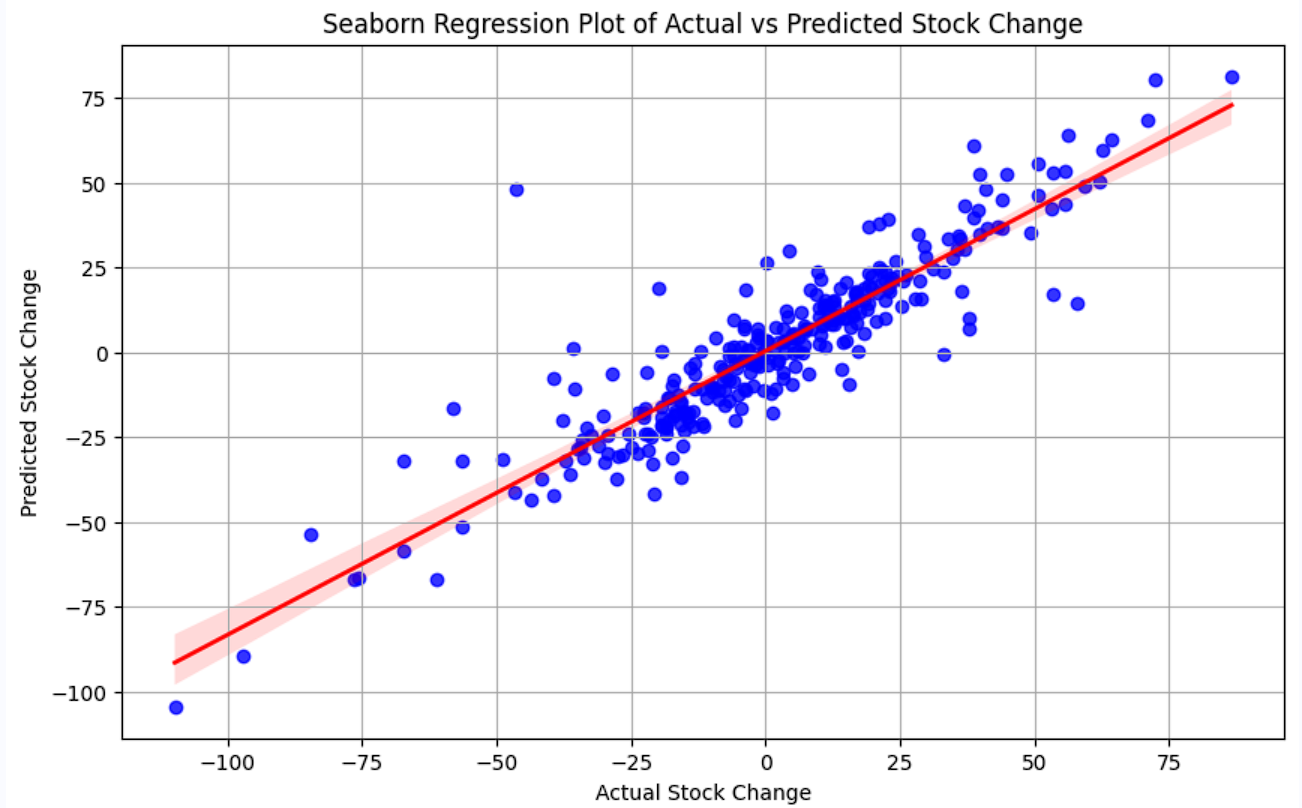
从结果上看基本都集中在直线附近,还是比较准确的
预测效果评估
由于回归分析的目标值是连续的,所以我们不能用准确率来评估,而应该比较预测值和实际值的差值评估,其中均方根误差(root-mean-square error、RMSE)是最常见的评估标准之一
R M S E = ∑ i = 1 n ( P r e d i c t i − A c t u a l i ) 2 n RMSE=\sqrt\frac{\sum_{i=1}^{n}(Predict_i-Actual_i)^2}{n} RMSE=n∑i=1n(Predicti−Actuali)2
还有一个是R方分数,表示预测数据和实际数据的相关性,范围是从0到1,越大表示相关性越好
$ R^2 = 1 - \frac{SS_{res}}{SS_{tot}} $
其中:
- ( S S r e s SS_{res} SSres ) 是残差平方和(Sum of Squares of the Residuals),它衡量了模型预测值与实际值之间的差异。
- (
S
t
o
t
S_{tot}
Stot ) 是总平方和(Total Sum of Squares),它衡量了实际值与平均值之间的差异。
更具体地说,这些平方和的计算方式如下:
S S r e s = ∑ ( y i − y ^ i ) 2 SS_{res} = \sum (y_i - \hat{y}_i)^2 SSres=∑(yi−y^i)2
S S t o t = ∑ ( y i − y ˉ ) 2 SS_{tot} = \sum (y_i - \bar{y})^2 SStot=∑(yi−yˉ)2
from sklearn.metrics import mean_squared_error, r2_score
print(f'Mean Squared Error (MSE): {mse}')
print(f'R^2 Score: {r2}')

当然如果我们想查看线性回归输出的预测涨跌和实际涨跌的对比情况,也可以很容易的实现
df = pd.DataFrame({'实际涨跌':y_test, '预测涨跌':y_pred})
print(df)

最终代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
import seaborn as sns
file_path = './000015perf.csv'
data = pd.read_csv(file_path)
# 删除含有缺失值的行
data_clean = data.dropna()
# 删除日期列,因为它对预测可能没有直接作用
X = data_clean.drop(columns=['日期Date', '涨跌Change', '涨跌幅(%)Change(%)'])
y = data_clean['涨跌Change']
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=20)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 使用模型进行预测
y_pred = model.predict(X_test)
# 计算预测的均方误差和R^2分数
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
plt.figure(figsize=(10, 6))
sns.regplot(x=y_test.values, y=y_pred, scatter_kws={'color': 'blue'}, line_kws={'color': 'red', 'linewidth': 2})
plt.xlabel('Actual Stock Change')
plt.ylabel('Predicted Stock Change')
plt.title('Seaborn Regression Plot of Actual vs Predicted Stock Change')
plt.grid(True)
plt.show()
print("w0 = ", model.intercept_)
print("W = ", model.coef_)
print(f'Mean Squared Error (MSE): {mse}')
print(f'R^2 Score: {r2}')
df = pd.DataFrame({'实际涨跌':y_test, '预测涨跌':y_pred})
print(df)