目录
队列是什么?
队列的实现
队列的数据结构
队列的初始化
队列的插入
队列的删除
获取队列队头元素
获取队列队尾元素
获取队列元素个数
检查队列是否为空
队列的销毁
队列的使用
完整代码
队列是什么?
队列也是顺序表中的一种
队列和栈差不多,它们的插入和删除都是限定在特定位置的
栈是后进先出,队列则是先进先出
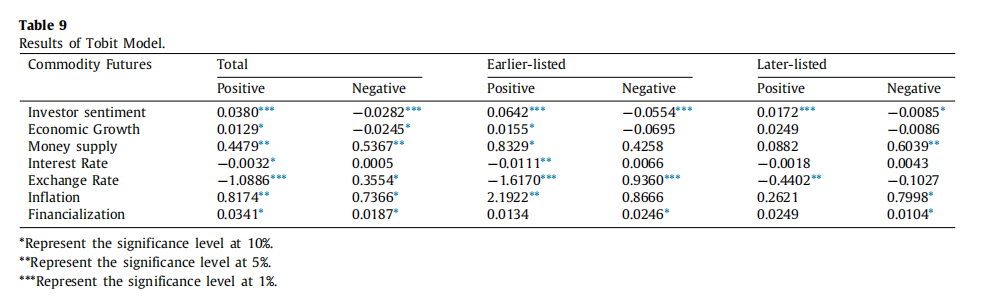
 栈只允许在队尾入数据,这叫入队
栈只允许在队尾入数据,这叫入队
栈只允许在队头出数据,这叫出队
队列的实现
队列这种特殊的结构既可以通过数组的方式实现,也可以链表的方式来实现,这时候就要考虑它两的优缺点来决定使用谁来实现了
根据队列的性质我们需要频繁的在队头和队尾插入删除数据,如果是使用数组来实现的话如果只是在数组队尾插入还很容易,但是如果在队头删除数据就需要整体往后挪一位,这样做效率是非常低下的
而如果是使用链表来实现对于插入删除并且是在头尾来说是非常easy的,所以这里队列的实现是使用的单链表实现
为什么不用双向链表?
双向链表也很好,但是我们需要多定义一个prev指针,我们在出队和入队的过程中并不是很需要这个prev指针(如果只是为了出队方便完全可以定义一个队头节点的指针一直指向队头即可), 如果多了一个prev指针那么就意味着我们需要多维护一个指针变量,并且还会多消耗一点空间
所以,相较来说使用单链表就足以轻松的完成队列的实现
链表不熟悉的可能需要先看看链表,可以看看下面的链接
C数据结构:单链表-CSDN博客
下面就开始使用单链表实现吧
队列的数据结构
typedef int QDataType;
typedef struct QueueNode
{
struct QueueNode* next;
QDataType val;
}QNode;
typedef struct Queue
{
QNode* phead;
QNode* ptail;
int size;
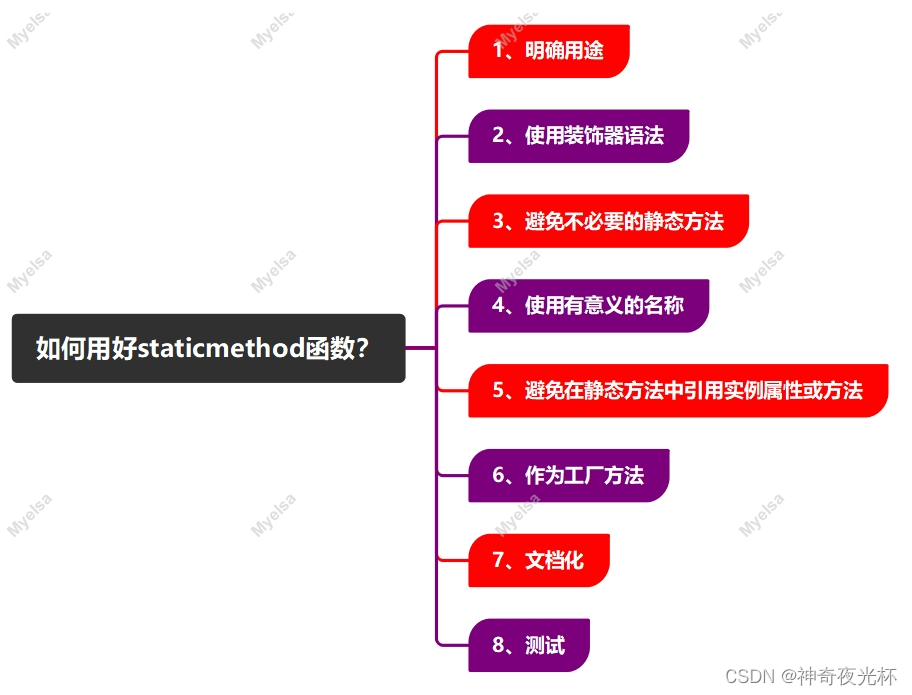
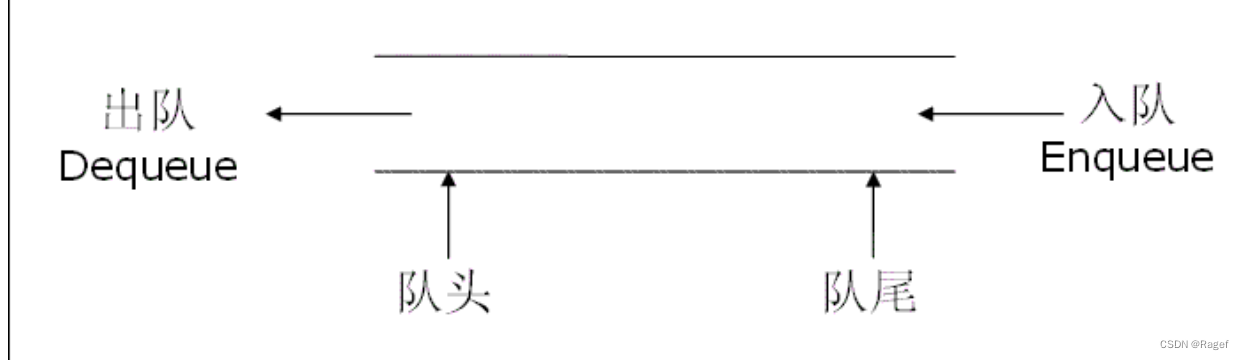
}Queue;如何来理解这个代码呢?请看下图
先看第一个struct
在这个QNode中有两个成员,一个是自己结构体的指针,一个是QDataType类型的val(这里的QDataType为int)
指针也就对应了图里这3个QNode指向对方的箭头,val就是里面的值
这个QNode是必须要定义的,这是链表的基础,为了完成我们的队列而创建的,这是我们底层的结构
而第二个struct
里面有两个QNode的指针,一个指向头,一个指向尾
定义Queue结构体的原因是:方便后续的插入和删除操作,现在定义一个size也是方便后续的函数能直接获取元素个数,到时候在主函数直接定义一个Queue的变量即可完成队列的操作
队列的初始化
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}初始化时队列里是一个节点都没有的,所以phead和ptail就为NULL,size为0
队列的插入
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
newnode->next = NULL;
newnode->val = x;
if (pq->phead == NULL)
{
pq->phead = pq->ptail = newnode;
}
else
{
pq->ptail->next = newnode;
pq->ptail = newnode;
}
pq->size++;
}队列的插入的第一步我们需要先创建一个QNode的节点
这里先定义了一个QNode指针newnode,并malloc开出一块充足的空间
下面的 if 语句就是每次动态扩容开辟完成后需要进行的检查扩容是否成功
若newnode为NULL,则扩容失败,直接返回
扩容失败的情况很少,一般正常扩容不会失败,若开的空间过大则可能失败
若扩容成功,那么我们需要对刚开出来的空间初始化,next=NULL,val=x
有了节点就该进行插入操作了
插入需要分两种情况,一种是第一次插入,还没有链表的时候,那么phead和ptai都指向newnode即可
否则,直接在ptai的后面插入即可,不要忘了让ptai往前走,ptai需要一直指向尾
最后size++即可
队列的删除
void QueuePop(Queue* pq)
{
assert(pq);
assert(pq->size > 0);
//一个节点
if (pq->phead == pq->ptail)
{
free(pq->phead);
pq->phead = pq->ptail = NULL;
}
else
{
QNode* next = pq->phead->next;
free(pq->phead);
pq->phead = next;
}
pq->size--;
}队列的删除也分两个情况
一种是只有一个节点的时候
这里使用了phead==ptail时则为只有一个节点,当然这并不是唯一的判断方法
也可以这样:phead->next == NULL
若只有一个节点,直接释放掉phead指向的那块空间即可
注意这里只能free(phead)或者free(ptail),不能两个同时进行,因为它两指向的都是同一块空间,free释放的并不是这个指针而是指针指向的空间,都释放就会报错
释放完后不要忘了让phead和ptail置NULL,防止变成野指针
若有多个节点
只需要先记住next位置,然后释放掉phead指向的空间,最后让phead走到next位置即可
最后不要忘了size--
获取队列队头元素
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(pq->phead);
return pq->phead->val;
}队头元素的获取就非常容易了
只需要返回phead指向的元素即可
获取队列队尾元素
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(pq->ptail);
return pq->ptail->val;
}和队头的获取一样
只需要返回ptail指向的元素即可
获取队列元素个数
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}这时候结构体里加的一个size成员的作用就体现出来了
如果没有size成员那么我们需要遍历一遍整个链表才能获取到数据,若我们需要多次调用这个QueueSize函数并且链表还长的话,我们就会浪费很多的时间在遍历链表上
所以这里直接返回size成员即可
检查队列是否为空
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
}若size为0,则队列为空
链表都为空了还能有队列嘛
队列的销毁
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->phead;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->phead = pq->ptail = NULL;
pq->size = 0;
}队列的销毁其实就和链表的销一致
定义一个cur遍历链表的同时释放掉当前的空间即可
最后也不要忘了将phead和ptai置NULL,防止变成野指针,size = 0
这样链表的实现就完成了
队列的使用
队列的使用和前面栈的使用思想差不多
int main()
{
Queue q;
QueueInit(&q);
QueuePush(&q, 1);
QueuePush(&q, 2);
QueuePush(&q, 3);
QueuePush(&q, 4);
while (!QueueEmpty(&q))
{
printf("%d ", QueueFront(&q));
QueuePop(&q);
}
QueueDestroy(&q);
return 0;
}当前main函数先定义了一个Queue的变量q
先是需要对q进行初始化,调用初始化函数
然后向队列中向队头插入了4个元素:1,2,3,4
当队列不为空时
打印队头的数据,打印后删除队头的数据
这样就完成了在队尾插入数据,在队头删除数据,所以队列是先进先出
最后不要忘了销毁队列,防止内存泄漏
完整代码
Queue.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
typedef int QDataType;
typedef struct QueueNode
{
struct QueueNode* next;
QDataType val;
}QNode;
typedef struct Queue
{
QNode* phead;
QNode* ptail;
int size;
}Queue;
void QueueInit(Queue* pq);
void QueueDestroy(Queue* pq);
// 队尾插入
void QueuePush(Queue* pq, QDataType x);
// 队头删除
void QueuePop(Queue* pq);
// 取队头的数据
QDataType QueueFront(Queue* pq);
// 取队尾的数据
QDataType QueueBack(Queue* pq);
int QueueSize(Queue* pq);
bool QueueEmpty(Queue* pq);Queue.c
#include "Queue.h"
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->phead;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->phead = pq->ptail = NULL;
pq->size = 0;
}
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
newnode->next = NULL;
newnode->val = x;
if (pq->phead == NULL)
{
pq->phead = pq->ptail = newnode;
}
else
{
pq->ptail->next = newnode;
pq->ptail = newnode;
}
pq->size++;
}
void QueuePop(Queue* pq)
{
assert(pq);
assert(pq->size > 0);
//一个节点
if (pq->phead == pq->ptail)
{
free(pq->phead);
pq->phead = pq->ptail = NULL;
}
else
{
QNode* next = pq->phead->next;
free(pq->phead);
pq->phead = next;
}
pq->size--;
}
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(pq->phead);
return pq->phead->val;
}
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(pq->ptail);
return pq->ptail->val;
}
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
}Test.c
#include "Queue.h"
int main()
{
Queue q;
QueueInit(&q);
QueuePush(&q, 1);
QueuePush(&q, 2);
QueuePush(&q, 3);
QueuePush(&q, 4);
while (!QueueEmpty(&q))
{
printf("%d ", QueueFront(&q));
QueuePop(&q);
}
QueueDestroy(&q);
return 0;
}完