一、前提--StatefuSet特性
1.1 有状态的节点控制器 -- StatefulSet 及其网络状态
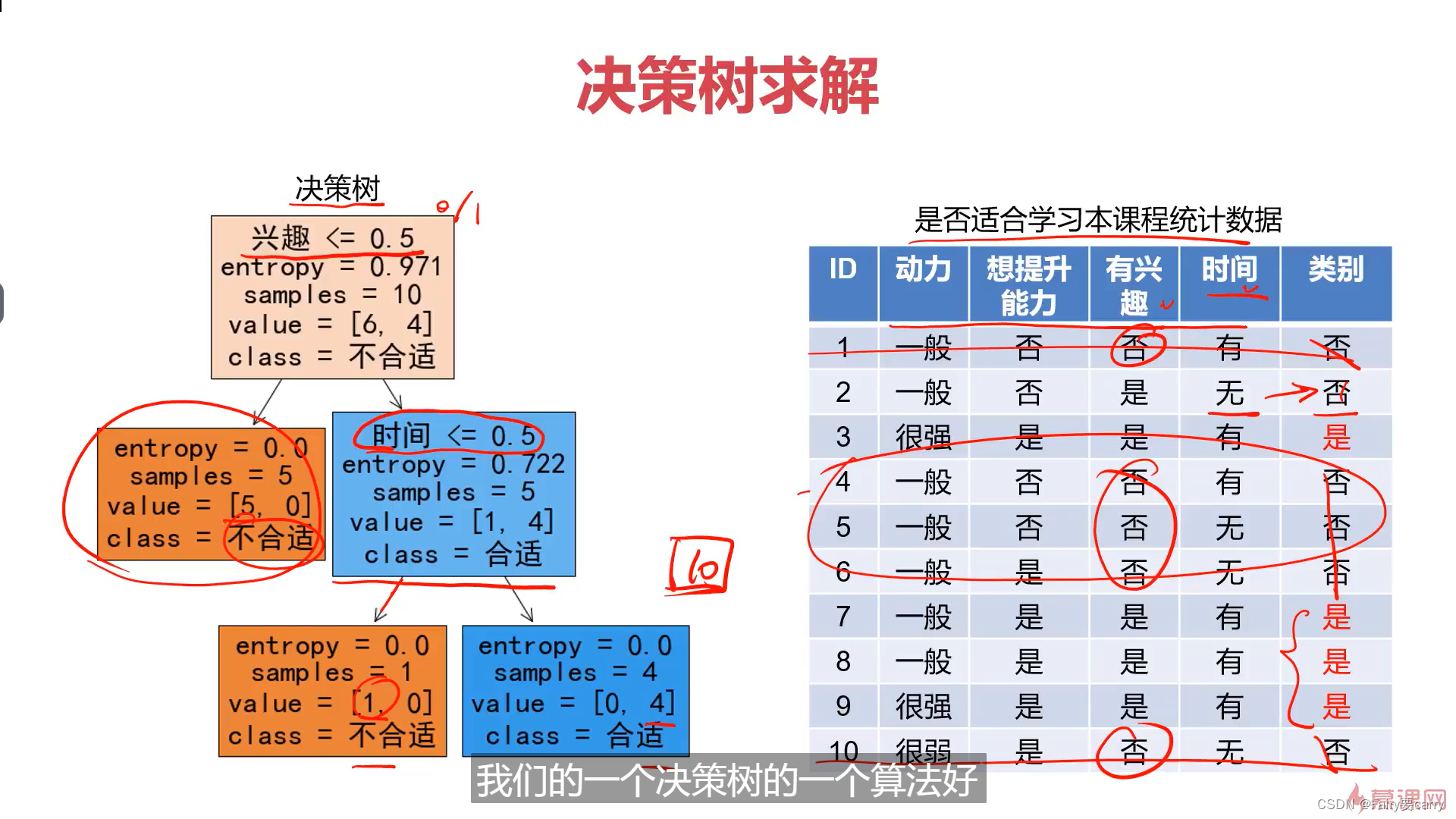
容器的解决方案是针对无状态应用场景的最佳实践,但对于有状态应用来说,就并非如此了。Kubernetes 用 StatefulSet 解决了有状态应用编排的问题,本文我们就来初步认识一下 StatefulSet。
StatefulSet 将应用设计抽象为了两种状态:
拓扑状态:
应用的多个实例必须按照某种顺序启动,并且必须成组存在,例如一个应用中必须存在一个 A Pod 和两个 B Pod,且 A Pod 必须先于 B Pod 启动的场景。
存储状态:
应用存在多个实例,但每个实例绑定的存储数据不同,那么对于一个 Pod 来说,无论它是否被重新创建,它读到的数据状态应该是一致的。
Kubernetes 的 Service 就是对外提供的可访问服务,它有两种访问方式:
-
VIP 方式:它是 Virtual IP 的缩写,通过将服务绑定到 Kubernetes 虚拟的 IP 地址,提供给外部调用,通过虚拟 IP 地址隐藏了服务的具体实现与地址。
-
DNS 方式:与虚拟 IP 地址类似,外部通过访问 DNS 记录的方式实现对具体 Service 的转发。
DNS 的两种处理方式
-
Normal Service:将 DNS 地址绑定到虚拟 IP 地址,从而复用虚拟 IP 地址的设计和逻辑;
-
Headless Service:将 DNS 地址直接代理到 Pod。
clusterIP 设置为了 None,表示不为这个 Service 分配 VIP,而是通过 Headless DNS 的方式来处理该 Service 的调用。
<pod-name>.<svc-name>.<namespace>.svc.cluster.local这个 DNS 就是 Kubernetes 为 Pod 分配的唯一可解析身份,这样一来,只要有了 Pod 的名字和 Service 的名字,我们就能唯一确定一个能够访问这个 Pod 的 DNS 地址了。
只要我们使用 DNS 记录来访问 StatefulSet 控制器控制下的 Pod,即使 Pod 发生了宕机和重启,DNS 记录对应的Pod记录本身是不会发生变化的,同一个“名字-编号”组合的 Pod 在 StatefulSet 中总是稳定地对外提供服务的,进而实现了整个“网络状态”的稳定。
1.2 有状态的节点控制器 StatefulSet 的存储状态
StatefulSet 通过为每一个 pod 分配有粘性的 ID,并且在 pod 发生变更时,维持 ID 的稳定,从而保证了网络状态下不对等关系的各个 Pod 在启动、删除和重建过程中能够始终保持稳定。
但在实际的使用场景中,我们不仅仅需要维护网络拓扑的稳定性,Pod 与分布式存储的存储节点之间关系的稳定性往往也是非常重要的,而这也正是 StatefulSet 的另一个优势。
对于一个 Pod 来说,它需要挂载和使用的分布式存储节点必须是稳定的。Id 为 web-0 的 Pod 如果在某一时刻挂载了 web-1 Pod 对应的存储资源,结果可能是不堪设想的。
StatefulSet 控制器通过 volumeClaimTemplates 解决了这一问题。
如果我们为一个 StatefulSet 配置了 volumeClaimTemplates,那么就意味着,这个控制器中管理的每个 Pod 都会自动声明一个自己 ID 所对应的 PVC,而这个 PVC 定义所需的属性,则均来自于 volumeClaimTemplates 中的声明。
StatefuSet里声明了volumeClaimTemplates后,该StatefulSet 创建出来的所有 Pod,都会声明使用编号的 PVC。比如,在名叫 web-0 的 Pod 的 volumes 字段,它会声明使用名叫 www-web-0 的 PVC,从而挂载到这个 PVC 所绑定的 PV。
当 web-0 Pod 向挂载给他的 PV 节点中写入数据后,即使 web-0 Pod 发生宕机或重启,从而被一个全新的同样 ID 为 web-0 的 Pod 替换后,由于新的 Pod 挂载的仍然是 Id 为 www-web-0 的 PVC,所以,它依然可以读取到此前 web-0 Pod 写入的数据。
二、有状态应用典型案例--MySQL主从
mysql 集群是一个非常典型的有状态应用,怎么在kubernetes集群上部署mysql集群,就需要使用statefuset控制器和持久数据PV、PVC。
对于 mysql 集群来说,我们首先要选取主节点,并且启动它,如果这是一个已有数据 mysql 节点,还需要考虑如何备份 mysql 主节点上的数据。
此后,我们需要用另一套配置来启动若干从节点,并且在这些从节点上恢复上一步中主节点上的备份数据。
完成上述配置之后,我们还必须考虑如何保证只让主节点处理写请求,而读请求则可以在任意节点上执行。
由此可见,mysql 主从集群的构建具有网络状态 -- 主节点必须先行启动,并且具有存储状态 -- 每个节点需要有自己独立的存储,很显然,用 Deployment 作为控制器来进行 mysql 集群的搭建是无法实现的,而这恰恰是 StatefulSet 擅长处理的场景。
三、主从节点的区分 -- 配置与读写
3.1 主从节点不同的配置文件
mysql 主节点与从节点拥有完全不同的配置,主节点需要开启 log-bin 通过二进制的方式导出 bin-log 来实现主从复制,从节点需要配置主节点的信息外,还需要配置 super-read-only 来实现从节点的只读。
在 Kubernetes 中我们只需要在 ConfigMap 中定义两套配置,然后在 pod 描述中依据不同的 pod 序号选择挂载不同的配置即可。
下面是一个 ConfigMap 的示例:
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
# 主节点MySQL的配置文件
[mysqld]
log-bin
slave.cnf: |
# 从节点MySQL的配置文件
[mysqld]
super-read-only
3.2 用 Service 实现主从的读写分离
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysql
由于第一个 Service 配置了 clusterIP: None,所以它是一个 Headless Service,我们只用它代理编号为 0 的节点,也就是主节点。
而第二个 Service,由于在 selector 中指定了 app: mysql,所以它会代理所有具有这个 label 的节点,也就是集群中的所有节点。
四、集群初始化
集群启动前,集群初始化步骤有:
-
各个节点正确获取对应的 ConfigMap 中的配置文件,并且放置在 mysql 配置文件所在的路径。
-
如果节点是从节点,那么需要先将主节点的数据全量拷贝到对应路径下。
-
在从节点上执行数据初始化命令。
这些操作我们可以通过定义一系列 InitContainers 来实现。
4.1 根据pod节点名称获取对应的配置文件
对于 StatefulSet 而言,每个 pod 各自的 hostname 中所具有的序号就是它们的唯一 id,因此我们可以通过正则表达式来获取这个 id,并且规定 id 为 0 表示主节点,于是,通过判断 server 的 id,就可以对 ConfigMap 中不同的配置进行获取:
initContainers:
- name: init-mysql
image: harbor.jnlikai.cc/mysql/mysql:5.7.36
command:
- bash
- "-c"
- |
set -ex
# 从 Pod 的序号,生成 server-id
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# 由于 server-id=0 有特殊含义,我们给 ID 加 100 来避开 0
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# 如果Pod序号是0,说明它是Master节点,拷贝 master 配置
# 否则,拷贝 Slave 的配置
[[ $ordinal -eq 0 ]] && cp /mnt/config-map/master.cnf /mnt/conf.d/ || cp /mnt/config-map/slave.cnf /mnt/conf.d/
volumeMounts:
- name: conf
mountPath: /mnt/conf.d
- name: config-map
mountPath: /mnt/config-map4.2 从节点copy前一个节点上的全量数据
- name: clone-mysql
image: harbor.jnlikai.cc/mysql/xtrabackup:1.0
command:
- bash
- "-c"
- |
set -ex
# 拷贝操作只需要在第一次启动时进行,所以如果数据已经存在,跳过
[[ -d /var/lib/mysql/mysql ]] && exit 0
# Master节点(序号为0)不需要做这个操作
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# 使用ncat指令,远程地从前一个节点拷贝数据到本地
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# 执行--prepare,这样拷贝来的数据就可以用作恢复了
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
在这一部分,我们使用了 ncat 命令实现从上一个已经启动的节点拷贝数据到当前节点,并且使用了第三方的备份还原工具 xtrabackup 来实现数据的恢复。
五、MySQL容器启动
5.1 从节点上数据恢复和每个节点上开启实时同步的端口
在 initContainers 中,我们实现了在从节点中,将上一个节点的备份数据拷贝到当前节点的工作,那么,接下来我们就要去恢复这个数据了。
与此同时,我们还需要在 mysql 的实际运行中实时执行数据的同步、恢复与备份工作。上文提到的 xtrabackup 很方便地实现了这一系列功能。我们可以将这个集成工具作为一个 sidecar 启动,完成上述这些操作:
- name: xtrabackup
image: harbor.jnlikai.cc/mysql/xtrabackup:1.0
ports:
- name: xtrabackup
containerPort: 3307
command:
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# 从备份信息文件里读取MASTER_LOG_FILEM和MASTER_LOG_POS这两个字段的值,用来拼装集群初始化SQL
if [[ -f xtrabackup_slave_info ]]; then
# 如果xtrabackup_slave_info文件存在,说明这个备份数据来自于另一个Slave节点。这种情况下,XtraBackup工具在备份的时候,就已经在这个文件里自动生成了"CHANGE MASTER TO" SQL语句。所以,我们只需要把这个文件重命名为change_master_to.sql.in,后面直接使用即可
mv xtrabackup_slave_info change_master_to.sql.in
# 所以在这个示例中,我们使用了 ncat 命令实现从上一个已经启动的节点拷贝数据到当前节点,并且使用了第三方的备份还原工具 xtrabackup 来实现数据的恢复。,也就用不着xtra backup_binlog_info了
rm -f xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# 如果只存在xtrabackup_binlog_inf文件,那说明备份来自于Master节点,我们就需要解析这个备份信息文件,读取所需的两个字段的值
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm xtrabackup_binlog_info
# 把两个字段的值拼装成SQL,写入change_master_to.sql.in文件
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# 如果change_master_to.sql.in,就意味着需要做集群初始化工作
if [[ -f change_master_to.sql.in ]]; then
# 但一定要先等MySQL容器启动之后才能进行下一步连接MySQL的操作
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
# 将文件change_master_to.sql.in改个名字,防止这个Container重启的时候,因为又找到了change_master_to.sql.in,从而重复执行一遍这个初始化流程
mv change_master_to.sql.in change_master_to.sql.orig
# 使用change_master_to.sql.orig的内容,也是就是前面拼装的SQL,组成一个完整的初始化和启动Slave的SQL语句
mysql -h 127.0.0.1 <<EOF
$(<change_master_to.sql.orig),
MASTER_HOST='mysql-0.mysql',
MASTER_USER='root',
MASTER_PASSWORD='',
MASTER_CONNECT_RETRY=10;
START SLAVE;
EOF
fi
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d5.2 MySQL业务容器启动
- name: mysql
image: harbor.jnlikai.cc/mysql/mysql:5.7.36
env:
- name: MYSQL_ALLOW_EMPTY_PASSWORD
value: "1"
ports:
- name: mysql
containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 500m
memory: 1Gi
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
# 通过TCP连接的方式进行健康检查
command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 2
timeoutSeconds: 1
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mysql
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi业务容器里会用到PVC,所以在启动此statefuset控制器之前需要先创建足够的PV,使用NFS server做数据存储端,在10.49.33.147机器上NFS共享如下目录;
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql
spec:
capacity:
storage: 50Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /data/mysql
server: 10.49.33.147
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql1
spec:
capacity:
storage: 50Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /data/mysql1
server: 10.49.33.147六、测试MySQL集群高可用
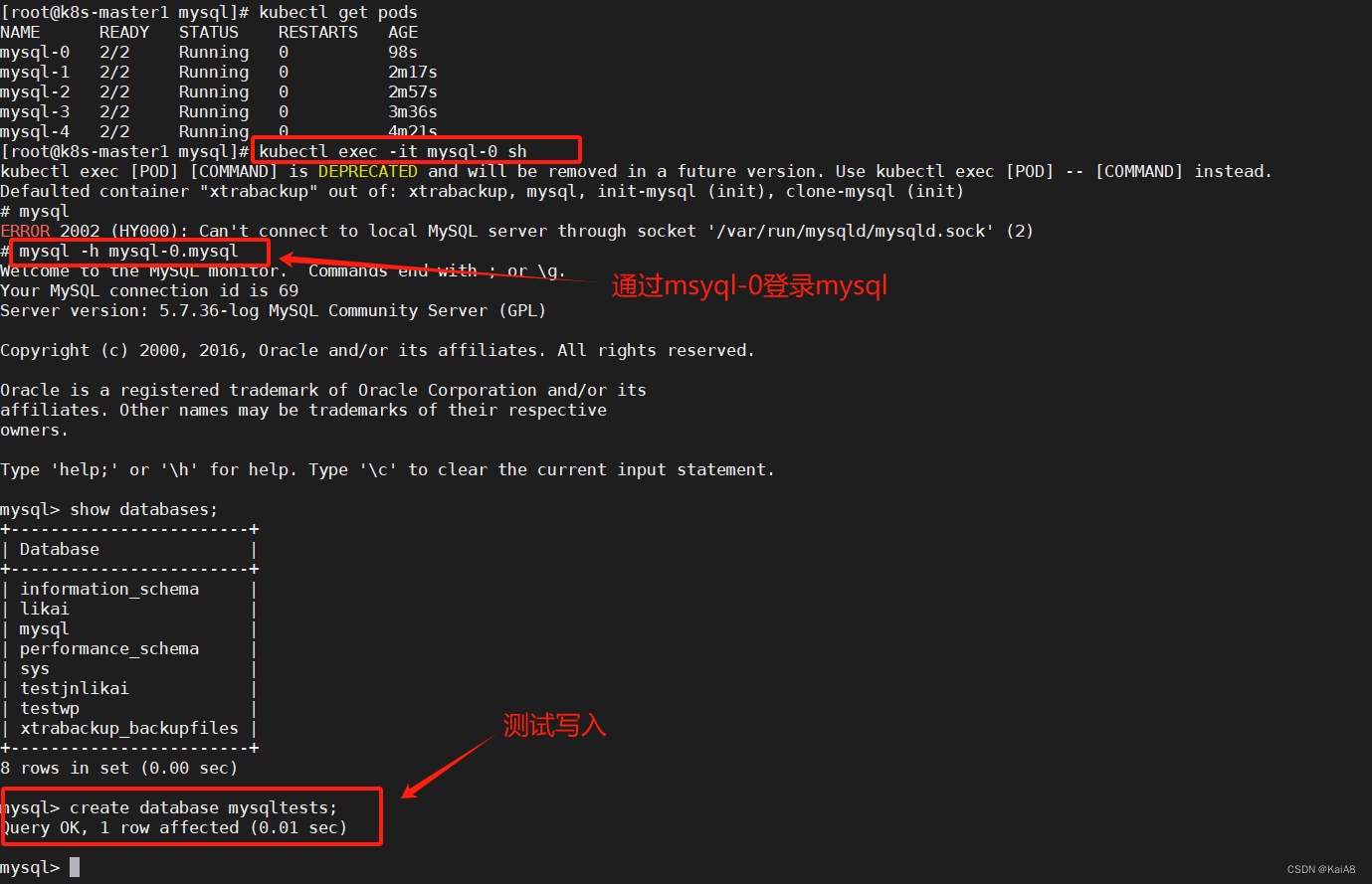
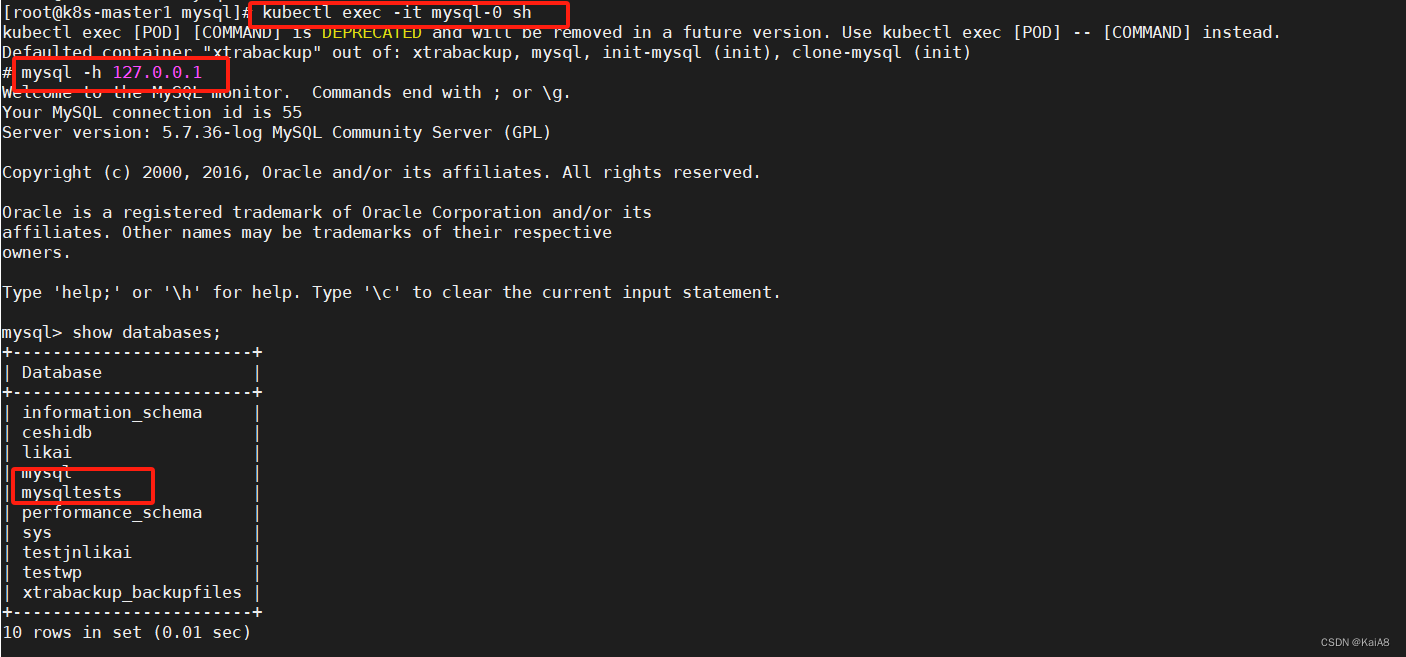
测试登录mysql-1可以看到刚才在msyql-0上创建的数据库mysqltests
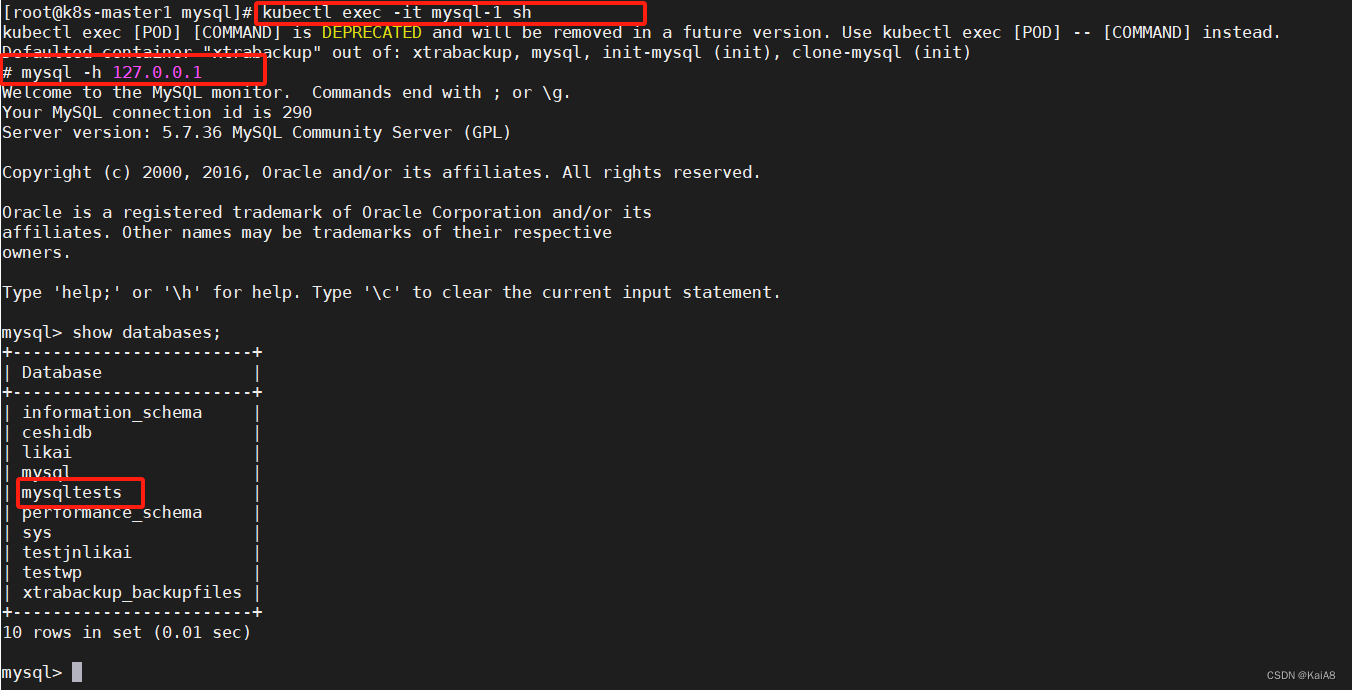 在从节点上测试写入会报错:
在从节点上测试写入会报错:
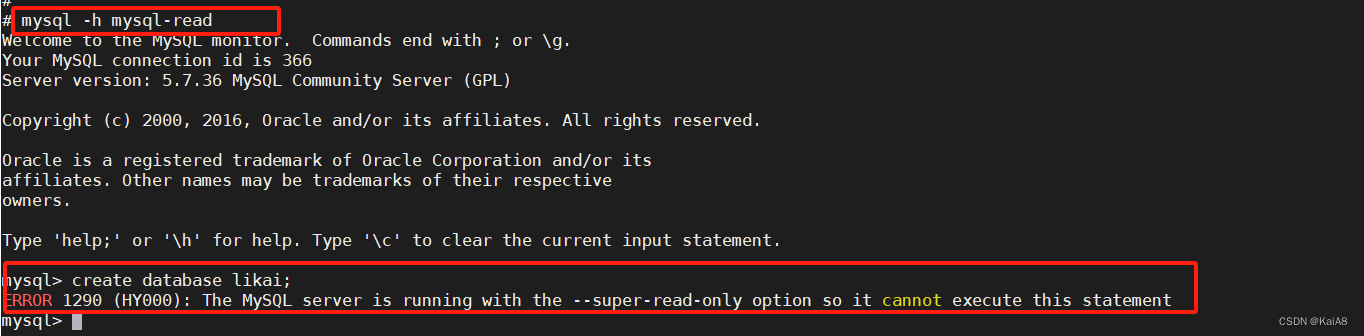
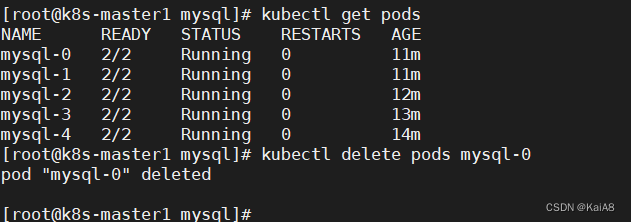
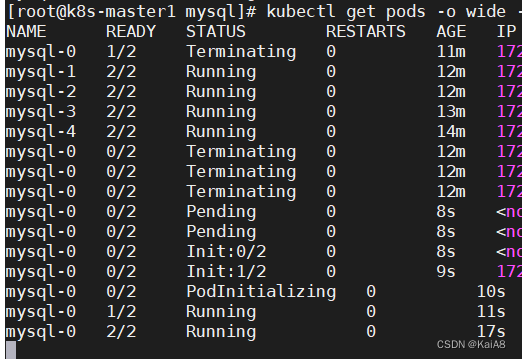
手动删除mysql-0 statefuset控制器会立即重建mysql-0,重建之后数据还会存在,因为重建的mysql-0还会挂载原来的PVC
参考文章:
实战 Kubernetes StatefulSet -- MySQL 主从集群搭建