📚博客主页:knighthood2001
✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下)
🎃知识星球:【认知up吧|成长|副业】介绍
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏笔者水平有限,欢迎各位大佬指点,相互学习进步!
获取一篇文章的图片
比如下面的的小红书链接
100篇阅读理解刷爆大纲5500词|2001年Text3 - 小红书
https://www.xiaohongshu.com/explore/66074a84000000001a01577
我需要将其中的图片下载下来,并且还是无水印的。
前言
右键检查,可以发现图片一般有专门的网址,并且点击进去后是无水印的。
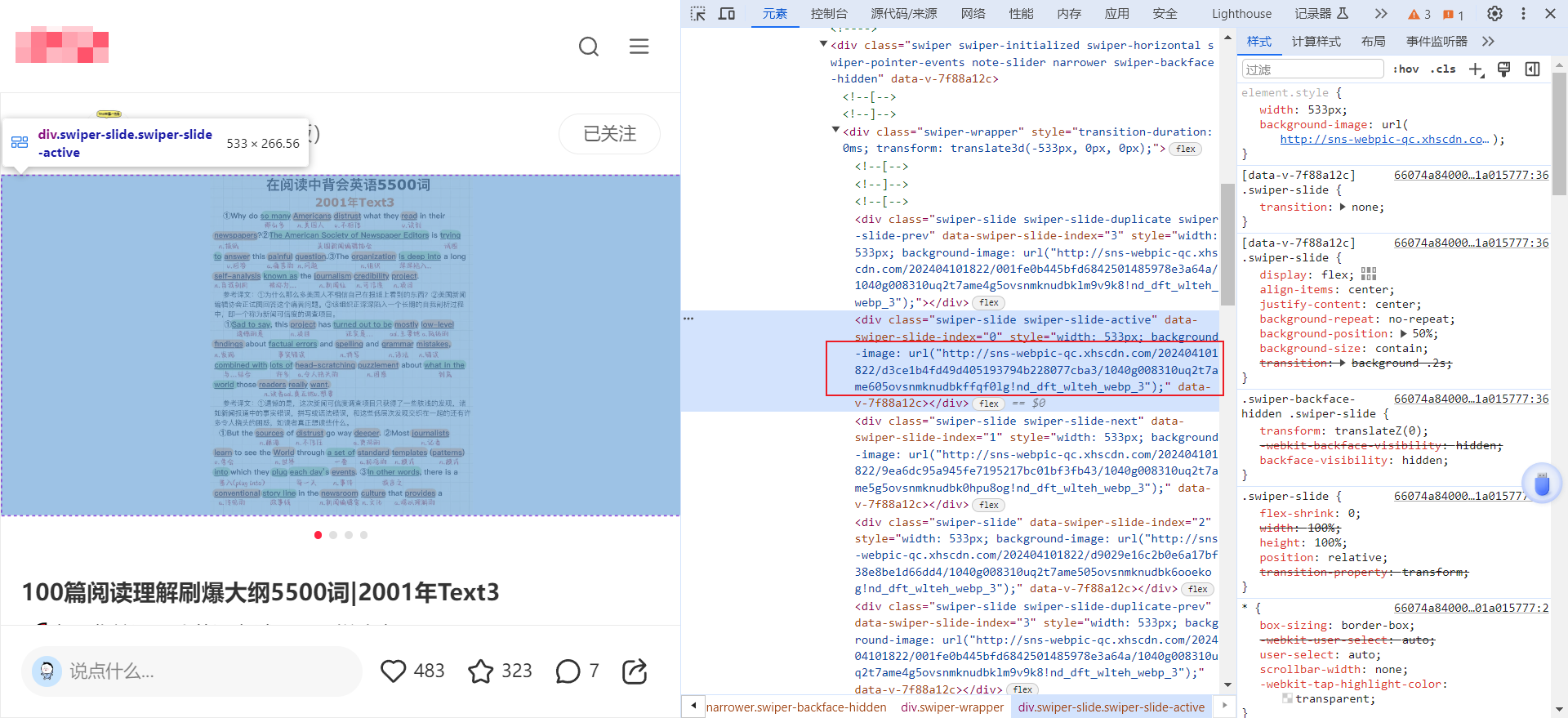
你可以自己多研究一下
然后右键,查看网页源代码,可以发现图片链接都在这个地方出现。
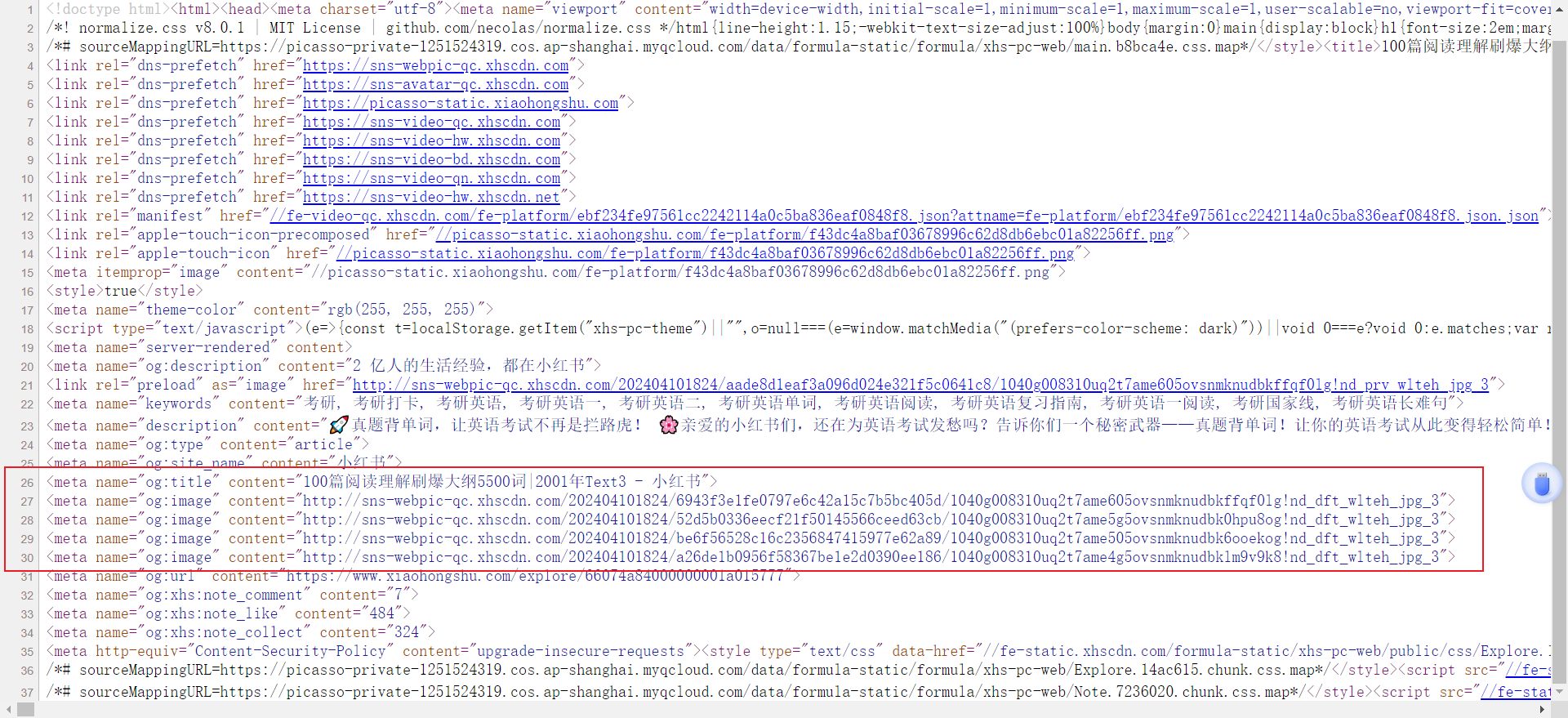
因此你可以通过正则表达式进行图片链接的提取。
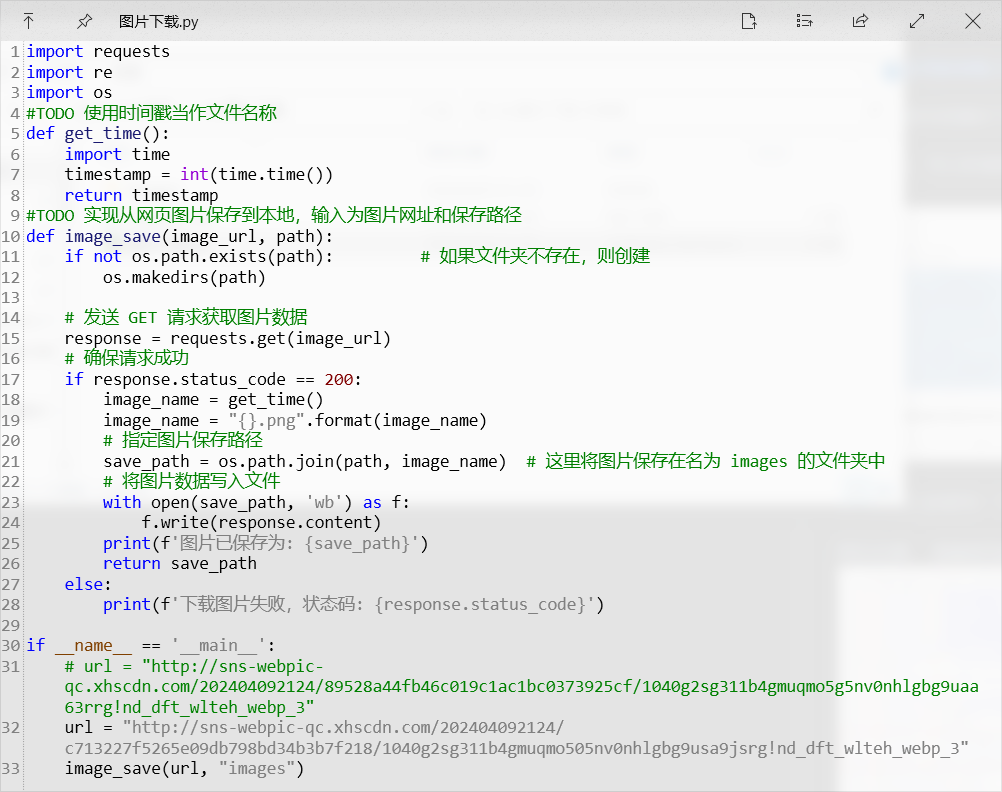
下面这张图片中的代码就是将图片链接保存为本地图片。这也是我之前讲过的内容,相对于这些都是可以即插即用的模板。
因此实现爬取小红书指定文章的图片的一般步骤就是:
获取网页源代码->使用正则表达式筛选出图片链接->将图片链接的内容保存为本地图片
编写代码
#TODO 该函数用于返回网页源代码,输入的是xhs链接
def get_html_code(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
content = response.content.decode()
return content
这段代码获取网页源代码。有了这个后,才可以使用正则进行数据的筛选。
在讲解正则提取之前,我需要讲一下图片链接保存为本地图片,因为这与之前不太一样。
#TODO 实现从网页图片保存到本地,输入为图片网址和保存路径
def image_save(image_url, path):
if not os.path.exists(path): # 如果文件夹不存在,则创建
os.makedirs(path)
# 发送 GET 请求获取图片数据
response = requests.get(image_url)
# 确保请求成功
if response.status_code == 200:
image_name = get_time()
image_name = "{}.png".format(image_name)
# 指定图片保存路径
save_path = os.path.join(path, image_name) # 这里将图片保存在名为 images 的文件夹中
# 将图片数据写入文件
with open(save_path, 'wb') as f:
f.write(response.content)
print(f'图片已保存为: {save_path}')
return save_path
else:
print(f'下载图片失败,状态码: {response.status_code}')
以上这段代码就是将图片链接的图片保存为本地图片。
但是这次代码,相对于我上面那个即插即用的模板来说,不太一样。因为我上面的那个模板,每次保存图片,由于时间戳一样,就会导致即使有多个图片链接,但是最后都是以一个时间戳命名,最后就保存为1张照片(被反复覆盖了)。
因此我需要进行代码的重构,我的想法是把for循环遍历放到保存图片中,原先保存图片是传入的一个链接,我这时候传入的是一个列表,然后通过for循环进行图片的保存。
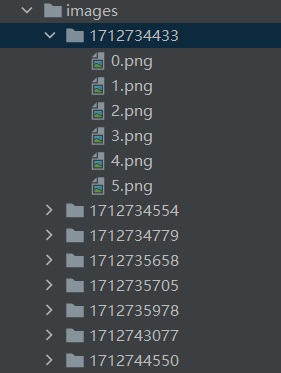
并且图片的上一级目录还有一个时间戳,可以帮助你排序,分辨下载先后顺序。
这一部分的代码,和之前版本来说,还是有较大区别的。
#TODO 实现输入一个图片url列表,将其中的图片保存到目录中,并按照1-nums排序,这样可以保证下载下来的图片顺序不乱。
#TODO 比如输入[图片链接1,图片链接2,图片链接3]和"image",最后就会生成image/时间戳的目录,然后在里面保存1.png,2.png,3.png
def image_save_batch(image_urls, save_dir):
time_path = get_time()
path = os.path.join(save_dir, str(time_path))
if not os.path.exists(path):
os.makedirs(path)
for i, url in enumerate(image_urls):
# 发送 GET 请求获取图片数据
response = requests.get(url)
# 确保请求成功
if response.status_code == 200:
# 生成图片文件名
image_name = f"{time_path}/{i}.png"
# 拼接图片保存路径
save_path = os.path.join(save_dir, image_name)
# 将图片数据写入文件
with open(save_path, 'wb') as f:
f.write(response.content)
print(f'图片{i+1}已保存为: {save_path}')
else:
print(f'下载图片{i+1}失败,状态码: {response.status_code}')
def get_img_url_list(content, path="images"):
# 使用正则表达式提取网址
url_pattern = re.compile(r'<meta name="og:image" content="(.*?)">')
matches = url_pattern.findall(content)
if matches:
# 去重+顺序
# unique_matches = list(set(matches)) # 会乱序
unique_matches = list(Counter(matches))
nums = len(unique_matches)
print(f"图片数量:{nums}, 图片去重数量:{len(matches)-nums}")
print(unique_matches)
# # 打印每个网址
# for i in range(nums):
# print(unique_matches[i])
# image_save(unique_matches[i], "images")
image_save_batch(unique_matches, path)
else:
print("No URL found.")
需要注意的一点是,matches中的图片链接有时候会有重复,因此需要去重操作,但是set函数的去重操作是无序的,会导致最终图片保存顺序为乱序。
因此我这里采用调用collections的Counter,解决去重+乱序的问题。
全部代码
import requests
import re
import os
from collections import Counter # 解决去重+乱序问题
#TODO 该函数用于返回网页源代码,输入的是xhs链接
def get_html_code(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
content = response.content.decode()
return content
# 获取当前时间戳
def get_time():
import time
timestamp = int(time.time())
return timestamp
#TODO 实现输入一个图片url列表,将其中的图片保存到目录中,并按照1-nums排序,这样可以保证下载下来的图片顺序不乱。
#TODO 比如输入[图片链接1,图片链接2,图片链接3]和"image",最后就会生成image/时间戳的目录,然后在里面保存1.png,2.png,3.png
def image_save_batch(image_urls, save_dir):
time_path = get_time()
path = os.path.join(save_dir, str(time_path))
if not os.path.exists(path):
os.makedirs(path)
for i, url in enumerate(image_urls):
# 发送 GET 请求获取图片数据
response = requests.get(url)
# 确保请求成功
if response.status_code == 200:
# 生成图片文件名
image_name = f"{time_path}/{i}.png"
# 拼接图片保存路径
save_path = os.path.join(save_dir, image_name)
# 将图片数据写入文件
with open(save_path, 'wb') as f:
f.write(response.content)
print(f'图片{i+1}已保存为: {save_path}')
else:
print(f'下载图片{i+1}失败,状态码: {response.status_code}')
def get_img_url_list(content, path="images"):
# 使用正则表达式提取网址
url_pattern = re.compile(r'<meta name="og:image" content="(.*?)">')
matches = url_pattern.findall(content)
if matches:
# 去重+顺序
# unique_matches = list(set(matches)) # 会乱序
unique_matches = list(Counter(matches))
nums = len(unique_matches)
print(f"图片数量:{nums}, 图片去重数量:{len(matches)-nums}")
print(unique_matches)
# # 打印每个网址
# for i in range(nums):
# print(unique_matches[i])
# image_save(unique_matches[i], "images")
image_save_batch(unique_matches, path)
else:
print("No URL found.")
if __name__ == '__main__':
url = "https://www.xiaohongshu.com/explore/661216c7000000000401818d"
page_source = get_html_code(url)
get_img_url_list(page_source)
最后
这个项目也算是搭积木吧,但是我觉得应该挺多人需要。因为有时候一张一张手动保存有水印的小红书图片,慢且有水印。
当然,代码中有一些细节,我并没有讲到,因为我发现,写文档真的太折磨人了。有问题的可以问我。
此外,我本来是使用的selenium免登录操作的,后来发现xhs在爬取图片这方面,反爬不是特别严重,因此可以用这个方法。









![[ue5]编译报错:使用未定义的 struct“FPointDamageEvent“](https://img-blog.csdnimg.cn/direct/a38082293b114764a5b4108e5160f6b0.png)