在 10 月份的一次周会结束后,我提到 SFT 训练后的 Loss 曲线呈现阶梯状,至于为什么,并没有人有合理的解释,加上当时的重心是提升次日留存率,Loss 曲线呈现阶梯状与次日留存率的关系还太远,即使有问题,起码次日留存率是逐渐在提升。
幸运的是,在一次逛论坛时发现了一篇博客 Can LLMs learn from a single example?,也是我这篇博客的标题名称由来,在其基础上结合了公司业务的一些现状和我个人的思考。
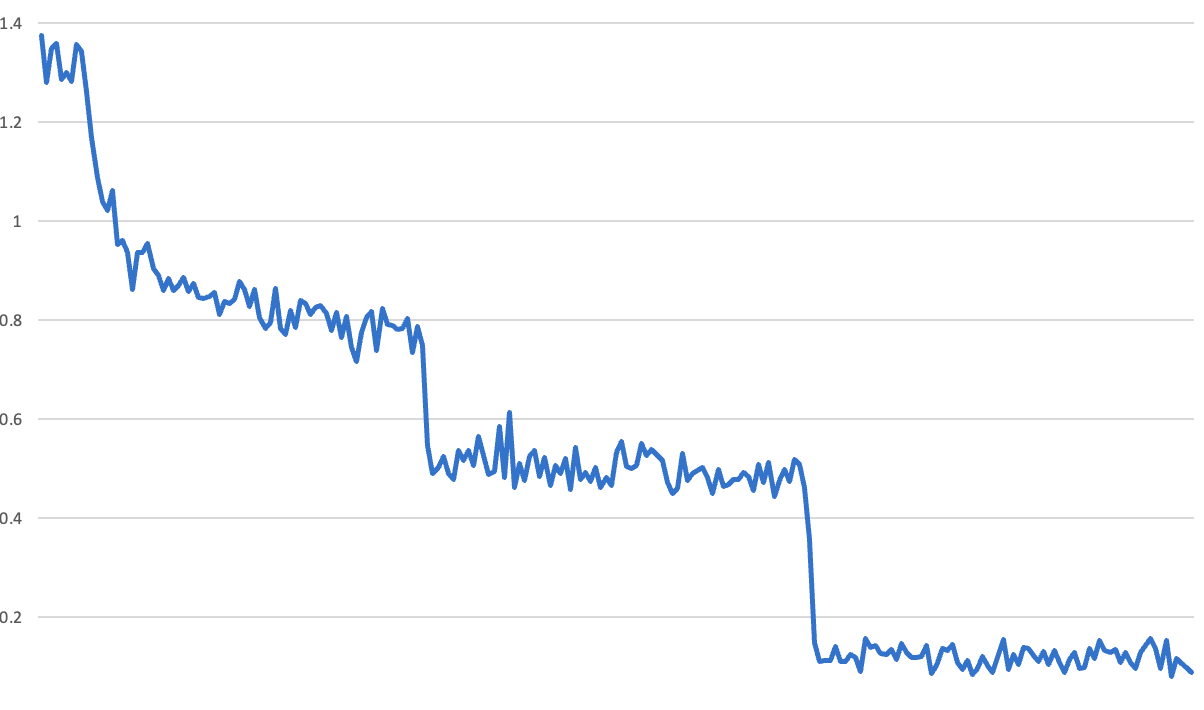
可以清楚地看到每个 epoch 的终点——loss 突然向下跳。我们以前也见过类似的损失曲线,但都是由于错误造成的。例如,在评估验证集时,很容易意外地让模型继续学习——这样在验证之后,模型就会突然变得更好。因此,开始寻找训练过程中的错误。
发现该“问题”的时间,恰好与单句重复问题同一时期(9 月份),于是推测是不是 context length 从 2k 变到 4k 所致,以及 Transformers 库和 RoPE 位置编码的问题。在开始逐步修改代码的同时,在 Alignment Lab AI Discord 上看到他人反馈的类似的奇怪 loss 曲线,并且每个回复的人也都在使用 Trainer,这在当时加深了我认为 Transformers 库存在问题的猜测,甚至我还去询问了同事李老师是否有同样的问题,以及 load model 时的 warning。
9 月中旬,老板要求我们加上验证 loss,于是出现了如下图所示的 eval loss 曲线。
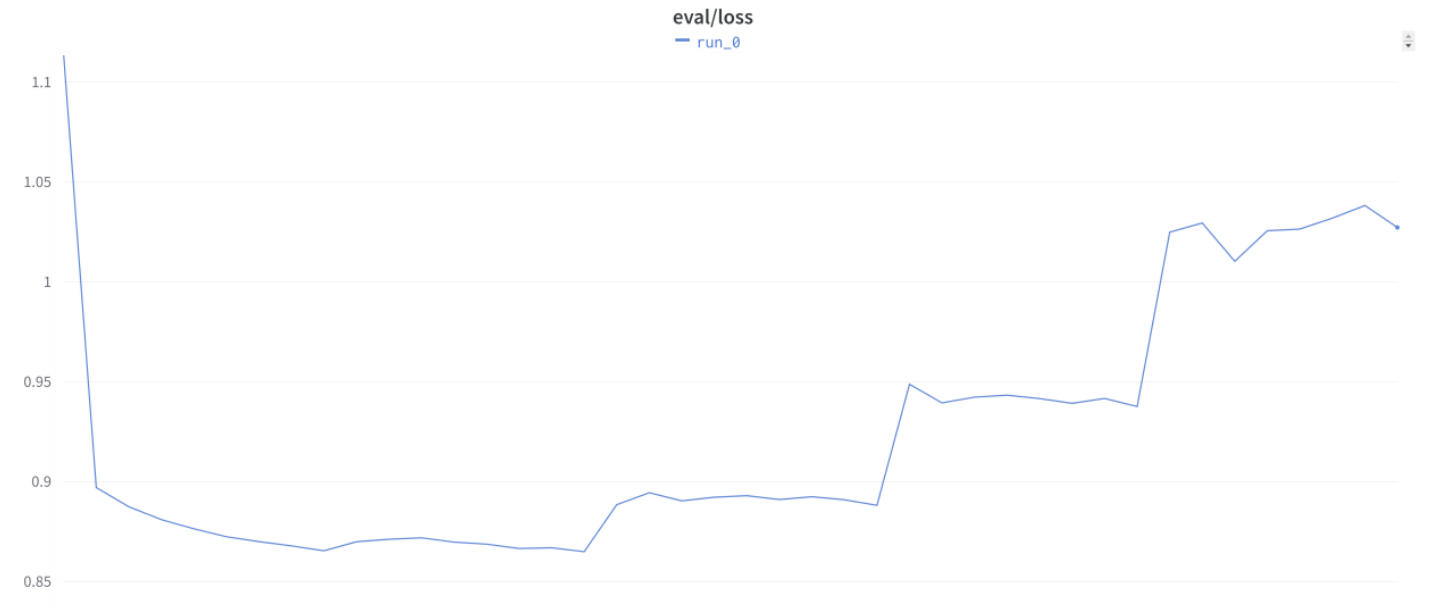
该问题在 Discord 上讨论得越来越激烈,也有人反映在不使用 Trainer 的情况下,也会出现阶梯状的 loss 曲线。
查阅资料,看到一种假设:即这些训练曲线实际上显示了过拟合。起初,这似乎是不可能的。这意味着模型正在学习识别来自一个或两个示例的输入。如果回过头来看我们展示的第一条曲线,就会发现 loss 在第二和第三个 epoch 期间,它根本没有学习到任何新东西。因此,除了在第一个 epoch 开始时的初始学习(学习了多轮对话的对齐方式)外,几乎所有表面上的学习都是(根据这一理论)对训练集的记忆。此外,对于每个问题,它只能获得极少量的信号:它对答案的猜测与真实标签的比较。
资料提到了一项实验:使用以下学习率计划,对 Kaggle 模型进行了两个 epoch 的训练:
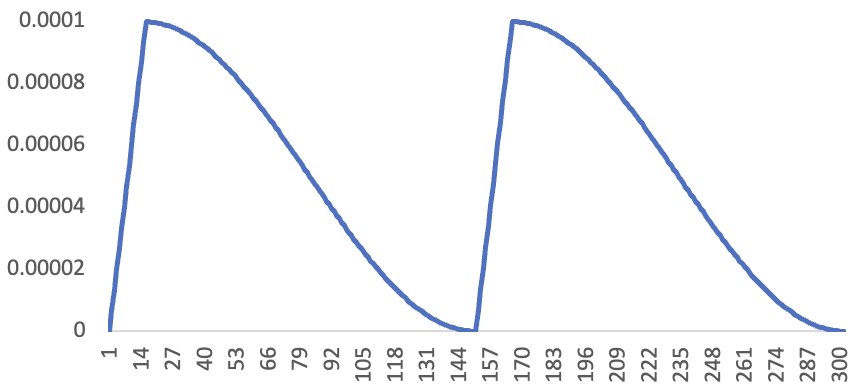
如今,这种 schedule 并不常见,但莱斯利-史密斯(Leslie Smith)在 2015 年发表的论文《训练神经网络的循环学习率》(Cyclical Learning Rates for Training Neural Networks)中讨论了这种方法,并取得了很大成功。
下面就是我们因此而看到的看起来很疯狂的训练和验证损失曲线:
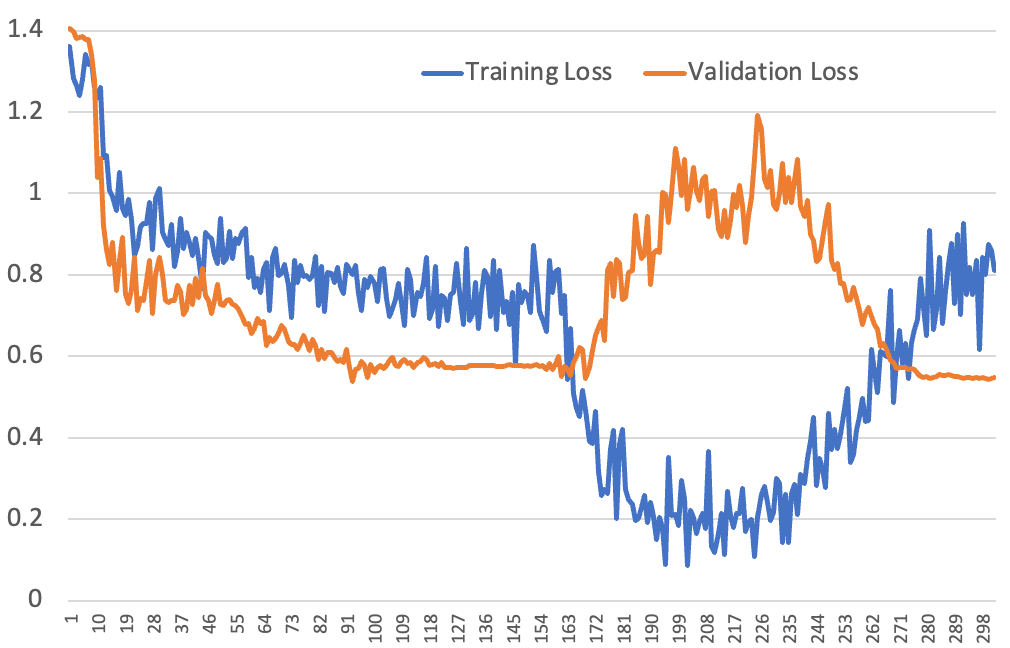
到目前为止,我们唯一能完全解释这种情况的方法就是假设是正确的:模型正在快速学习识别实例,即使只看到一次。让我们依次查看 loss 曲线的各个部分:
- 从第一个 epoch 来看,这是一条非常标准的 loss 曲线。在第一个 10% 的 epoch 中,学习率开始升温,一旦达到温度后,训练和验证 loss 就会迅速降低;然后按照余弦曲线逐渐下降,两者都会放缓。
- 第二个 epoch 才是我们感兴趣的地方。我们并没有在 epoch 开始时重新 shuffle 数据集,因此第二个 epoch 的第一批数据是学习率仍在预热的时候。这就是为什么在我们展示的第一条 loss 曲线中,没有看到像从 epoch 2 到 epoch 3 那样的直接阶跃变化——这些批次只有在学习率较低时才会出现,所以它学不到太多东西。在 epoch 2 开始 10% 时,训练 loss 急剧下降,因为在第一个 epoch 中看到这些批次时,学习率很高,模型已经知道了它们的样子,因此它可以非常自信地猜出正确答案。但在此期间,验证 loss 会受到影响。这是因为虽然模型变得非常自信,但实际上它的预测能力并没有提高。它只是记住了数据集(早期没有清洗掉训练数据中的保底回复以及一些涉及到公司信息的关键词,模型会输出这些内容,甚至会将原样的超时保底回复输出),但并没有提高泛化能力。过于自信的预测会导致验证损失变大,因为损失函数会对更自信的错误进行更高的惩罚。
- 曲线的末端是特别有趣的地方。训练 loss 开始变得越来越大,而这是绝对不应该发生的!事实上,我还从未在使用合理的学习率时遇到过这种情况。根据记忆假说,这完全说得通:这些批次是模型在学习率再次下降时看到的,因此它无法有效地记忆这些批次。但模型仍然过于自信,因为它刚刚得到了一大堆几乎完全正确的批次,还没有适应现在看到的批次没有机会学得那么好这一事实。它会逐渐重新校准到一个更合理的置信度水平,但这需要一段时间,因为学习率越来越低。在重新校准的过程中,验证 loss 会再次下降。
记忆假说很有可能是真的。按照先前小模型时代的训练经验,我们往往需要大量的数据来让模型学习输入分布和模式。使用随机梯度下降法(SGD)导航的损失面太崎岖,无法一下子跳得很远。不过,有些东西可以让损失面变得更平滑,比如使用残差连接,如经典论文《可视化神经网络的损失景观》(Li et al,2018)中所示。
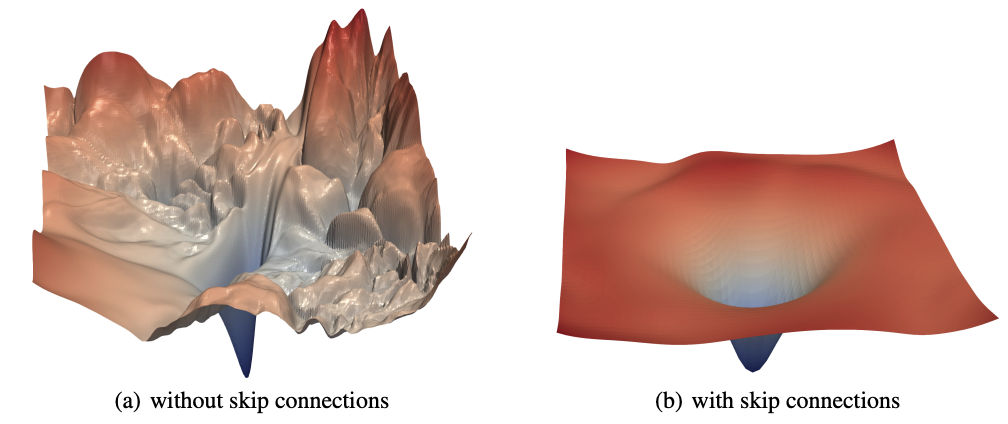
很可能的情况是,预训练的大语言模型在接近最小损失的区域具有极其平滑的损失面,而开源社区所做的大量微调工作都是在这一区域。这是基于最初开发微调通用语言模型的基本前提。简单来说,我们的训练数据并不能够让模型跳出该平滑的损失面,只是让模型记住了 BOT 的回复、以及通过几个数据就让模型学到了说话风格。
如果以上猜测都属实,这不是什么糟糕的事情,拥有一个学习速度非常快、且能够举一反三的模型是一件非常棒的事情。同时,这也佐证了《LIMA:Less Is More for Alignment》、《A Few More Examples May Be Worth Billions of Parameters》、《Maybe only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning》等一系列证明少量优质、多样性丰富的指令数据就能让模型有很强指令遵循的论文的有效性。以及最近出现的一系列关于指令数据集子集选择的论文,例如《Smaller Language Models are capable of selecting Instruction-Tuning Training Data for Larger Language Models》、《LESS: Selecting Influential Data for Targeted Instruction Tuning》。这些论文提到经过他们方法挑选出来的子集,在该子集上训练出来的模型比在全量数据集上微调的模型效果要更好。
我统计了从 7 月 到 11 月份所训练模型的 Loss 曲线是否呈现阶梯状,正常表示平滑下降,不正常表示阶梯下降(在每个 epoch 交界处骤降)。早期训练的模型的 loss 曲线都是正常,可惜的是早期的训练数据被删了,无法准确地判断是数据质量的因素,还是基底模型的因素。
早期训练遵循多阶段的方式,即先在 continual pretrain 得到的 base 模型上用 GPT4all 数据集以及一个闲聊场景的对话集进行训练,然后再用高质量的对话数据集再次微调。以此得到的模型表现平常,虽不会犯错,但也没有新意,不能提升平均对话轮数,因此后续我们不再进行 base model -> GPT4all + 闲聊数据集 -> 高质量对话数据集的多段式 SFT,而是直接在 base model 上用高质量对话数据集进行 SFT。在这之后训练的模型的 loss 曲线都是阶梯状,按照记忆假说和先前分析的内容来看,llama2、vicuna-13b-v1.5 等模型的对话、闲聊能力得到了提升(也有可能是 GPT4all 数据集让模型闲聊能力下降),在我们所认为的“高质量”数据集上进行训练,模型只是记住了对话内容,而非真正意义上地学习(训练数据集对于模型来说非常简单)。
PS:我没有否认和贬低这种方式,当模型的“脑容量”(记忆力)大到能够将我们提供的优质回复都记住,并且在合适的场景输出,这在业务上完全没有问题。在复读机问题上,将高质量数据集从 4k 扩充至 26k 后,的确减少了该问题的频次。
一个猜想:当模型的学习速度如此之快时,灾难性遗忘问题可能会突然变得明显得多。例如,如果一个模型看到了十个非常常见关系的示例,然后又看到了一个不太常见的反例,那么它很可能会记住这个反例,而不仅仅是稍微降低它对原来十个示例的记忆权重。
在 6 月下旬时,老板询问我为什么模型的效果不太好时,我想了想说是灾难性遗忘(找的理由)。现在看来,似乎的确大概率是这个原因。沿着 base model -> GPT4all + 闲聊数据集 -> 高质量数据集训练的路径,希望模型能够不断地进化,但实际上 base model 原先的知识和 GPT4all 数据集中的内容都遗忘得差不多。因此,不要多阶段 SFT,而是将每个阶段的训练数据进行混合,可以减少灾难性遗忘的影响,这或许就是后来尝试数据混合方案后,能够提升次日留存率的一个原因?
此外,我们还需要审视,对于模型来说,什么是高质量的数据集。










![[已解决]ModuleNotFoundError: No module named ‘tqdm‘](https://img-blog.csdnimg.cn/direct/1545896e0e954d64b40ef3e4b4ffc355.png)