编者按: 大模型的出现为构建更智能、更复杂的人工智能系统带来了新的契机。然而,单一的大模型难以应对现实世界中错综复杂的问题,需要与其他模块相结合,构建出复合人工智能系统(Compound AI Systems)。
本文作者深耕人工智能领域多年,洞见独到。文中系统性地介绍了四种常见的 Compound AI Systems 部署模式:RAG 系统、Conversational AI 系统、Multi-Agent 系统和 CoPilot 系统。作者阐明了这些部署模式的工作原理、模块间的交互方式,并深入探讨了“Agentic”理念、模块化设计的优势等核心概念,为读者构建 Compound AI Systems 提供了宝贵的理论经验。相信通过学习本文,读者们能够对如何构建 Compound AI Systems 有更深入的认识,为后续的工程实践奠定扎实的基础。
作者 | Raunak Jain
编译 | 岳扬
如何使用开源工具构建可根据特定需求定制的工作流(configurable flows)和由多个不同模块组合而成的复合人工智能系统(compound AI systems)。
01 什么是 compound AI systems ?
最近,伯克利大学(Berkeley)的研究人员撰写了一篇文章《The Shift from Models to Compound AI Systems》,他们在这篇文章中梳理了 LLM apps 的发展进程,并强调complex pipelines 具备不断发展和演化的特性,这些 pipelines 由多个组件共同协作来构建智能系统(intelligent systems),而非依赖于某一个闭源模型。虽然最终的 compound AI systems 可能使用的底层模型(如 GPT4)相同,但是根据不同的具体提示词(prompting)和上下文(context),系统中的各个组件可能会被视为是不同的组件。
Compound AI systems 在现实场景的一些常见落地部署模式如下:
- RAG(检索(retrieval)和理解(understanding)至关重要 —— 具有模拟人类思维过程或根据先前的学习产生新的想法、根据逻辑、规则或先前的知识进行推理和分析、阅读相关背景信息的能力,他们可以 self-reflect (译者注:分析自己的运行方式、决策过程或者与用户交互的方式,并据此进行调整或改进)并尝试通过分析语境、推理、模式识别等方式理解用户的意图,并作出相应的模型响应或行为。在这种情境下,最理想的配置或解决方案是使用 Agent Assist System 。 (译者注:利用人工智能技术,如自然语言处理、推荐算法等,来分析和理解用户的需求,并根据这些需求为用户提供帮助。)当与面向用户的模型/系统(如对话模型)结合使用时,RAG 系统可以成为 Conversational AI 或 CoPilot system 的一部分。
- Multi — Agent Problem Solvers(各个 Agent 通过扮演不同的角色进行协作来共同解决问题至关重要) —— 这些系统中的各个 Agent 都有明确定义的角色和目的,相互协作,根据彼此的输出,自动构建解决方案。每个 Agent 都能使用自己的一套工具,并且在推理(reasoning)和规划自己的行为时(planning it’s actions)可以承担非常明确具体的角色。
- Conversational AI(对话(dialogue)是关键) —— 自动化软件(automation softwares)(例如客户服务 agents)可在应用程序/生态系统(app / ecosystem)内与人类进行交互,并可根据系统接收的数据或信息、以及对这些数据的验证执行可以反复进行的任务。这种部署模式最重要的是 conversational memory(译者注:系统进行对话时记忆和保留的信息) 和 dialogue generation(译者注:系统能够自动地生成对话文本,以回应用户的 query 或提出新的对话话题) ,使得用户感觉在与一个人类进行对话。 对话模型(Dialogue Model)可以访问底层的 RAG 系统或 Multi-Agent problem solver 。
- CoPilots(人机交互界面是关键) —— 借助系统内提供的工具、用于分析、学习或支持决策的数据、系统具备的推理和规划能力以及专业的配置文件,这些系统可以独立地与人类互动,同时通过一系列固定的步骤或规则来解决有明确的、已知的解决方法的问题。要想部署一个成功的 CoPilot ,关键在于能否理解人类的工作环境。例如 MetaGPT Researcher: Search Web and Write Reports[1],A measured take on Devin[2],Let’s build something with CrewAI[3],Autogen Studio[4]。
注意事项: 根据我部署完成几个集成 LLM 的系统后获得的经验,我可以肯定地说,这些系统并非每个人都想要的万能解决方案(silver bullet) 。和其他 AI System 一样,我们需要围绕 LLM 进行大量的工程设计,才能让它们能够完成基本任务,即便如此,这些系统也不能保证性能完全可靠且具备可扩展性。
光明大道: LLMs 在软件生态系统(ecosystem)中的主要价值在于赋能机器学习的应用和发展(enable Machine Learning),即 识别出系统存在的问题、缺陷或哪些地方存在进一步改进的空间,并将数据反馈回流至系统中重新学习,帮助系统不断地优化和适应用户需求。 想象一下,是否可以使用 LLMs 自动化标注数据或减轻标注员的工作负担。在 closed systems (译者注:这种系统的内部数据不与外部环境进行交换或交互。)中,我们可以测试和评估 LLM 的输出内容,它可能在执行任务时表现出令人出乎意料的能力!但相应需要付出的代价也很大,不过这个过程会产生大量的数据,这些数据可以用来改进和训练 LLMs 。
- )
LLMs 能够通过不断地分析和处理数据,并将这些数据反馈回系统,从而使系统能够不断地学习和改进,这是 LLMs 带来的最大价值。
02 复杂系统中各组件间的交互机制及其构筑途径
Compound AI systems 通常将这些“模块”相互连接,让他们共同协作。这些模块都能够完成某一些特定任务(certain tasks),它们相互依赖,根据需求被动态地组合和调整,执行预定义的设计模式(design patterns)。
此处的“模块”指的是系统中的单个组件,这些模块具有清晰而明确定义的功能或任务,它们能够独立执行这些任务,也可以在需要时在搜索引擎、LLM 等 underlying system 的支持下完成任务。一些常见的“模块”包括数据生成器(generator)、数据检索器(retriever)、数据排序器(ranker)、数据分类器(classifier) 等,在 NLP 领域中,它们通常统称为 tasks 。这些都是针对特定领域的概念抽象(例如,NLP 模块的抽象模块可能与计算机视觉领域或推荐系统领域不同,但它们可能都依赖于相同的底层模型服务或搜索引擎)。
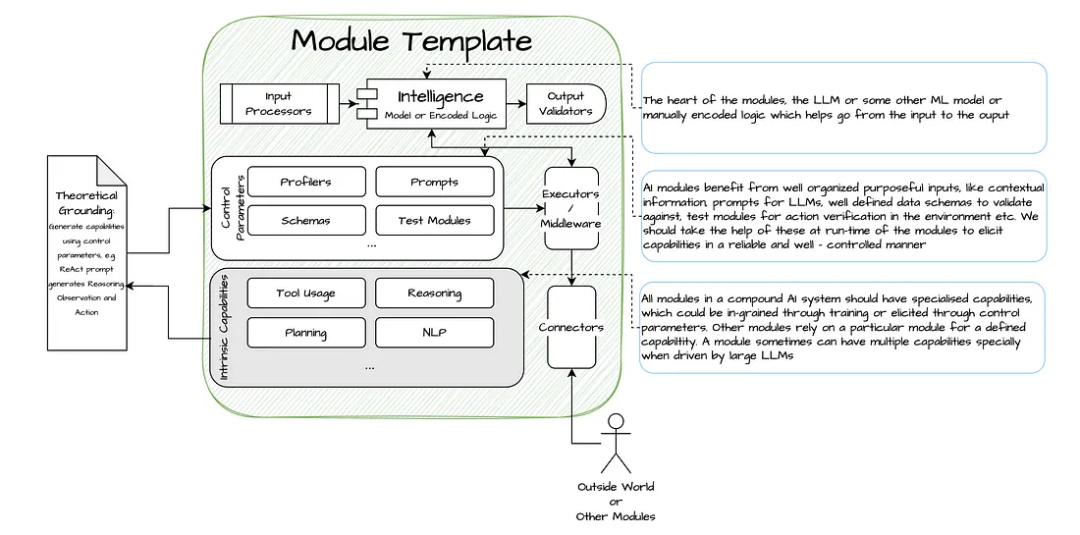
图 1 :“模块”的关键组成部分
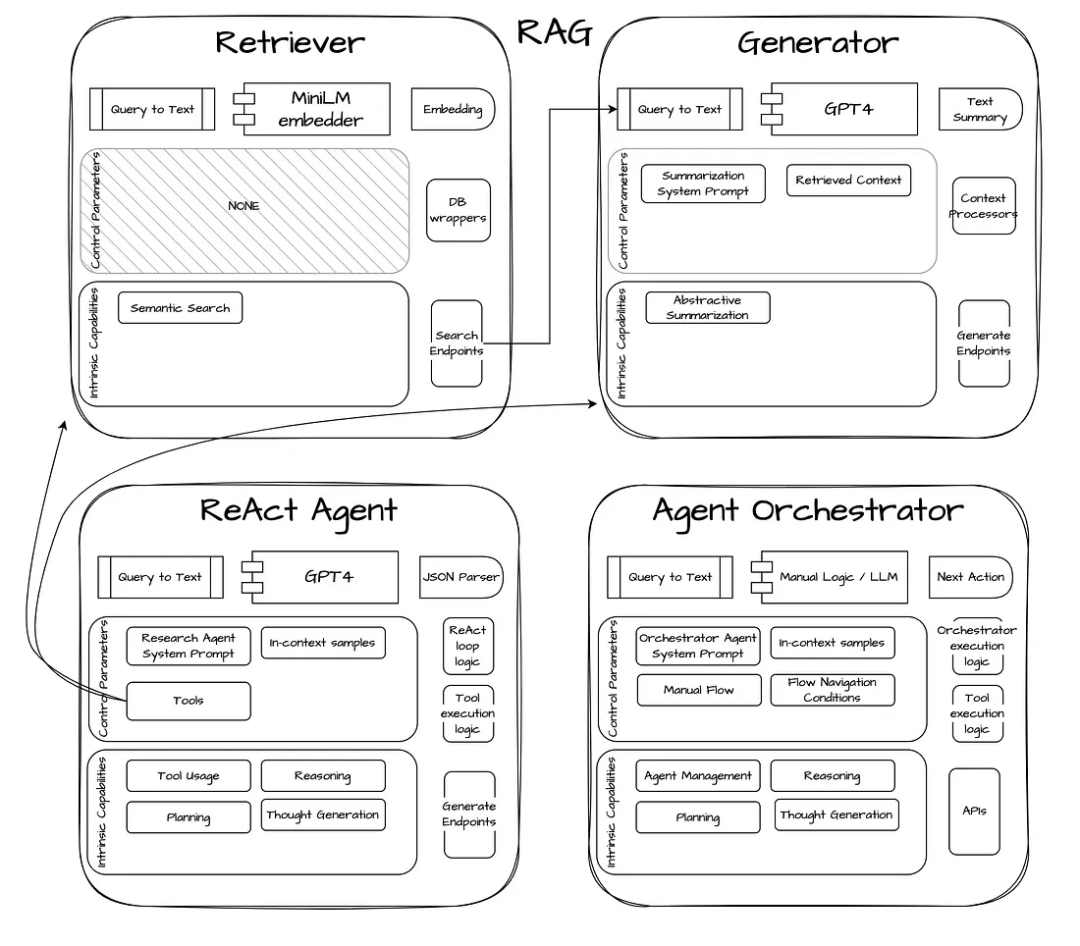
图 2 :其他通用模块
在人工智能主流文化中,大家习惯使用像 “Tools[5]”、“Agents[6]”、“Components[7]” 这样的术语,这些都可以被视为“模块”。
03 基于 LLM 的 Autonomous Agents —— Compound AI systems 中的关键模块
还有一种“模块”的形式是 Autonomous Agent[8] (译者注:这种 Agent 能够自主对环境进行感知、分析和响应,无需持续的人类干预。),它可以在 LLM 的帮助下自主进行推理(reason)和规划(plan)。Autonomous Agent 可以依赖一系列子模块来决定在与环境交互时如何推理和规划行为。
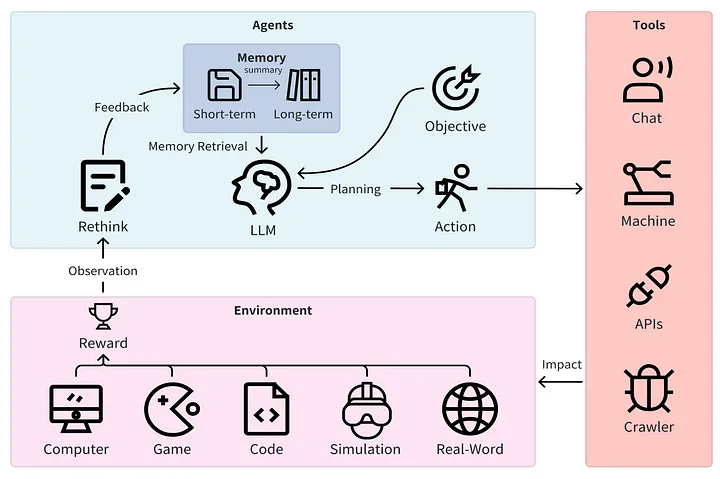
source: https://arxiv.org/pdf/2401.03428.pdf
3.1 Autonomous Agent 子模块的主要技能:
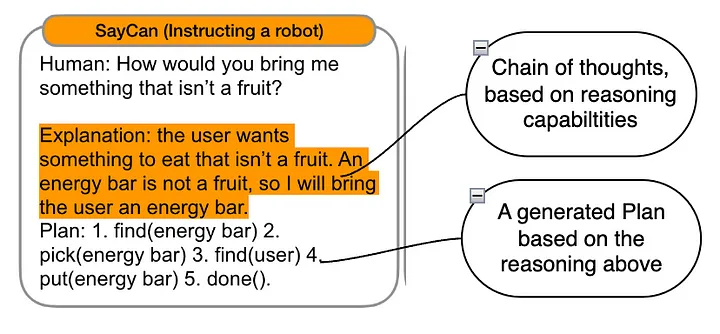
Agent 能够使用其推理能力来思考和分析问题,然后形成一系列相关的思考步骤,最终制定出一个行动计划来解决问题或实现目标任务。
- 推理(Reasoning) —— 通过观察、提出假设并基于数据进行验证等逻辑方法来解决问题。
- 思考(Thought) —— 是对推理(Reasoning)的应用,生成连贯的因果关系。
- 思维链(Chain of thought) —— 将一连串相关的思考过程串联起来,通过逐步进行推理和逻辑分析,将整个解决方案分解为一系列有序的推理步骤。
- 规划(Planning) —— 这是一种一种决策过程,需要制定具体的子目标,对可用的选项进行评估和比较,以确定达到目标的最佳路径。通常需要访问 underlying environment 以制定更有效的决策方案和行为计划,并通过与环境的互动,从经验中学习。点击此处[9]了解更多有关 LLM Planning 的信息。
- 工具(Tools) —— 这是让 Agent 能够根据指令与外部世界(译者注:external world,可指人类所处的自然环境、计算机程序所运行的操作系统或网络环境、机器人所处的物理空间,或者其他外部环境。)进行交互的子模块。
- 行为(Action) —— 顾名思义,这是 Agent 在通过规划(Planning)实现目标时所采取的决定性步骤。在执行某个行为(Action)之前,可能需要调用一个工具(Tools)来触发或执行该行为(Action),行为(Action)可能会影响到环境(Environment)的状态,也可能可能会受到环境(Environment)的影响(Actions are made in the environment)。
- 环境(Environment) —— external world 是行为(Action)和奖励(Rewards)的来源,如根据特定需求或要求定制开发的应用程序(如Microsoft Word、Coding Environment)或者游戏环境,甚至是物理世界模拟环境等。
3.2 这种技术是不是只是“Stochastic Parrots(随机鹦鹉🦜)”
注意:虽然有很多理论研究都在探讨 LLMs 缺乏推理和规划能力这一问题,可以参考这两篇文章[10][11],但很明显,大语言模型可以很好地像鹦鹉一样学舌,说出“解决问题的方法”。这意味着,如果给定一个要解决的问题,并给出一些以前关于这个问题的解决方案,那么 LLM 就可以很好地复制这个逻辑思考过程。至于这样能否实现泛化,在此我们就不关心了,但正如 Yann Le Cunn 所说,自回归模型是注定要失败的[12]!
而在企业环境中,需要的只是可靠地重复任务,并从以往的经验中学习,而不需要太多创造性能力。
3.3 这些“鹦鹉🦜”究竟是如何规划任务解决流程的?
根据这篇 survey [9],LLM 似乎能够通过以下方式有效地为 Autonomous Agents 赋能:
- 分解任务解决步骤(Task decomposition) —— 现实生活中的任务通常复杂且步骤繁多,给解决方案的规划带来了极大的困难。这种方法采用分而治之的思想,将复杂的任务分解为多个子任务,然后按顺序对每个子任务进行规划,如 TDAG[13]。
- 生成多种备选解决方案(Multi-plan selection) —— 这种方法侧重于引导 LLM 多“思考(think)”,为目标任务生成各种备选计划。然后采用与目标任务相关的搜索算法(比如 ReWoo),来挑选一个要执行的方案。
- 利用外部模块来辅助进行规划(External module-aided planning) —— 也就是从存储的计划库或历史记录中检索出以前制定的计划或解决方案(plan retrieval)。
- 反思和完善(Reflection and Refinement) —— 这种方法论强调通过反思和完善来提高方案规划能力。鼓励 LLM 对失败进行反思,然后不断完善解决方案的规划。
- 通过额外的存储模块来增强解决方案的规划。(Memory-Augmented Planning) —— 这种方法通过额外的存储模块(memory module)来增强解决方案的规划能力,存储模块中存储了各种有价值的信息,如常识性知识(commonsense knowledge)、以往的宝贵经验(past experiences)、特定垂直领域知识(domain-specific knowledge)等。
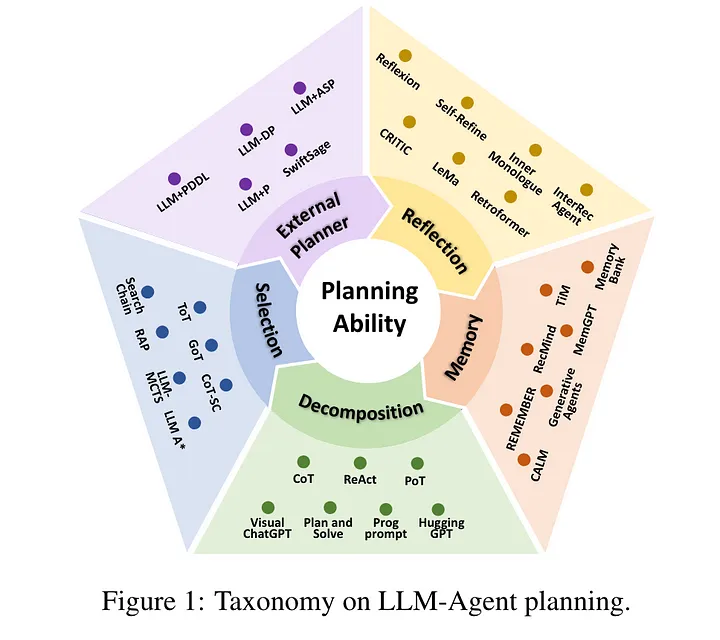
《Understanding the planning of LLM agents: A survey》[9]
如何训练前文提到的各种能力,特别是针对 RAG 这种模式?欲了解更多,请参阅《Fine-tuning LLMs for Enterprise RAG — A design perspective》[14],深入了解。
通过 module abstraction (译者注:module abstraction,将系统中的各种功能和能力抽象成独立的模块,以便于对其进行训练、优化和整合。)的方式,我们可以开发不同的设计模式(design patterns)来解决对话式 AI(Conversational AI)、RAG(检索增强生成)系统和 CoPilot 系统在处理复杂问题时面临的挑战。
04 Compound AI systems 的设计模式
4.1 阅读本节需要掌握的相关概念或相关术语
由于当下人工智能领域存在着一种类似于 “pop culture”(译者注:更加通俗化、商业化、娱乐化,并被大众广泛接受和追捧的文化形态,贴近普通大众的生活方式和审美趣味。) 的氛围,导致一些术语被曲解和误解,因此在进一步讨论之前需要先澄清、阐明一些概念。
1). 什么是 “Agentic” 模式?
Autonomous Agent 的核心优势在于它可以自行决定采取何种流程来完成任务。如果我们必须手动定义任务流程(manually define a flow)或进行决策(decisions),那么它只是一个 intelligent workflow (译者注:与传统的工作流程相比,intelligent workflow 能够根据输入的数据和条件自动进行决策,并且可以根据反馈和学习不断优化和改进执行过程。)。但如果系统的处理流程没有被预先定义,而是通过利用前面提到的那些能力(分解任务解决步骤、生成多种备选解决方案等),综合使用各种工具(tools)和行为(actions),实现自主决策,那就属于 “Agentic” 模式。 例如,在 Agentic RAG 中,模块可以访问搜索工具,并自动生成复杂的搜索流程,而无需任何预定义的处理步骤。
2). 什么是 “工作流(workflow)”?
简单地说,workflow 就是指在执行之前,已经事先编写并手动指定了所有的步骤、决策和操作,以可预测和可重复的方式解决问题。
3). 什么是 “multi-agent”?
在一个 AI 系统中,不同的模块承担不同的角色和责任,相互影响,根据彼此的输出结果协同解决问题[15]。
4.2 选择合适的设计模式前的需要考虑的因素
要抽象出并定义可用于开发 RAG 、 Conversational AI (对话式人工智能)、CoPilots (译者注:协作式的人工智能系统,能够辅助人类完成工作的伙伴或助手。)和Complex Problem Solvers (译者注:具有一定智能和学习能力的系统或 Agent ,能够处理各种复杂的现实世界问题,并提供有效的解决方案。),我们需要提出以下问题:
1). 模块之间的工作流程是明确预先定义好的(well defined)还是由系统自主决定的(autonomous)?即为 Engineered flow(译者注:经过工程化设计的工作流程,可能是根据先前的实践经验进行规划和优化的) vs Agent System(译者注:由多个 Agent 组成的系统,这些 Agent 之间可能相互交互、协作或竞争,为了实现某个目标或解决某个问题共同奋斗。)。
2). 工作流程是定向的(directional)还是通过“消息传递机制(message passing)”进行通信和协作的?系统中各模块是合作性的(co-operative)还是竞争性的(competitive)?参考Agent Modulo[10]
3). 工作流程是否可自学习(self learnable)?自我反思(self-reflection)和修正(correction)功能是否重要?
- 系统是否能够通过推理(reasoning)得出结论,并采取相应的行为(action)来执行任务。
- 模块之间是否可以相互影响?
4). 系统的每个组件或模块生成的结果是否可以在实际环境中进行验证和评估?
5). 在工作流程的执行过程中是否会保存一些信息或上下文,并且用户的输入可能会影响工作流程的执行路径或执行结果。
05 部署模式 1 —— RAG / 对话式 RAG
下面这张图片展示了 RAG 系统 / 对话式 RAG 系统中各模块的主要功能职责。RAG / 对话式 RAG 过去被归类为信息检索(IR)领域,最初通过神经搜索(Neural Search)、知识图谱(Knowledge Graphs)进行改进,后面才是基于 generative loop(译者注:通过反复生成文本或其他类型的输出,并根据生成结果的反馈进行调整改进,不断提高系统性能。) 的方法(使用 LLMs)进一步提升。Conversational IR[16] 是当信息检索(IR)和对话系统(Dialogue systems)融合在一起时,这种系统的另一个视角。在这种视角下,queries(译者注:用户想要获取所需信息或服务时向系统发出的请求或命令。) 被视为在对话过程中会发生变化的上下文对象(contextual objects)。
要让 RAG 系统取得成功,关键是要理解用户的 query ,并将其映射到底层知识(结构化的或非结构化的),然后将其与合适的指令性指导内容(instructions)一起反馈给生成器(Generator)/对话管理器(Dialogue Manager)。 这些都可以使用明确定义的工作流程来执行,或者使用 Agent 模块,由其动态决定要执行哪些步骤(在下一节中将更详细地阐述)。
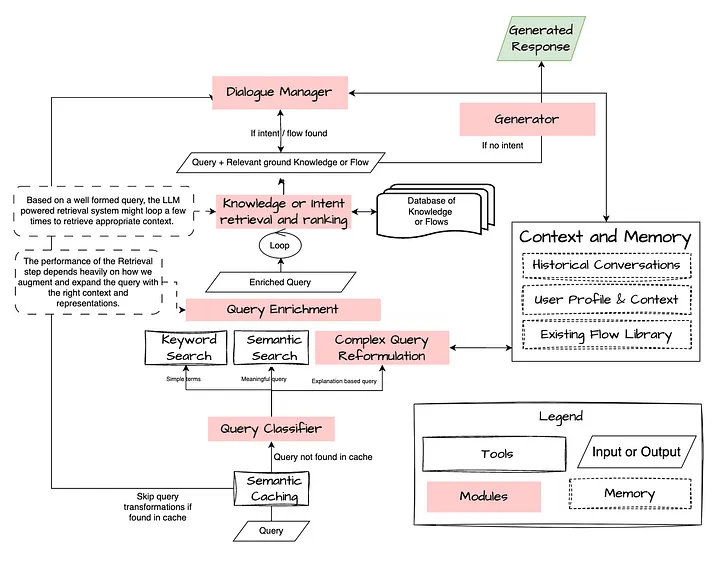
RAG 的工作流程,与对话管理器(Dialogue Manager)交接 —— 如果对话管理器是一个 Agent,RAG 就可以算做是一项工具
让我们来看一些中间模块 / 工具(intermediate modules / tools),它们可以让 Agent 在这个复杂的 RAG 世界中游刃有余。
5.1 Query的理解与重构
Query expansion / Multi — query 技术
当使用传统的倒排索引和查询-文档匹配方法的检索器和基于统计模型的检索器(sparse and statistical retrievers)时,利用 LLMs 来扩展 query[17] 可以改善检索结果。
Query rewriting / Self — Query 技术
自查询检索器(self-querying retriever)顾名思义,就是具有 query itself 能力的检索器(译者注:这种检索器能够使用自然语言构建 query 并使用,而非依赖于外部数据源或其他系统。)。具体而言,对于任何自然语言 query ,检索器都会使用语言模型来理解 query ,并将其转换为结构化的 query ,然后将该结构化的 query 应用于其底层 VectorStore(译者注:用于存储这些向量表征的数据结构)。这样,检索器不仅能使用用户输入的 query 与存储文档的内容进行语义相似性比较,还能从用户 query 中提取出存储文档元数据的过滤条件(filters),并使用这些过滤条件(filters)对存储的文档进行筛选。
Entity recognition 技术
(译者注:能够从自然语言文本中识别出实体并进行分类,如人名、地名、组织机构名等。有助于理解用户意图,为后续的信息提取、关系抽取等任务提供帮助。)
5.2 Query Enrichment
(译者注:利用外部知识源(如知识库、语料库)来补充和扩展原始 query,从而获得更丰富、更具语义的 query ,从而更好地匹配文档库中的内容,并提高搜索结果的相关性和准确性。)
5.3 Knowledge or Intent retrieval
Multi — Document Search 技术
(译者注:能够同时跨越多个语料文档进行复合检索,获取更全面的信息,应对复杂的 query 。)
Dialogue Management 技术
(译者注:对话管理模块需要追踪对话状态、上下文,决策对话的下一步走向,尽可能保证交互的自然与连贯。)
Response Generation 技术
(译者注:生成高质量、连贯的自然语言响应,回答用户的 query 。包括从事先定义的模板中选择合适的回复、使用自然语言生成模型生成文本、基于规则或模式匹配生成模型响应等方法。)
5.4 Agentic RAG
Agentic RAG 是一种设计模式,这种模式拥有一个由 LLM 驱动的模块,能够根据其可用的工具集来推理和规划如何回答问题。在具有更多挑战和复杂性的情况下,我们还可以连接多个 Agent ,以创造性的方式解决 RAG 问题,这些 Agent 不仅可以检索内容,而且还具有验证(verify)、总结(summarize)等功能。有关此内容的更多信息,请参阅 Multi — agent 部分。
需要细化的关键步骤和关键组件包括:
- 规划(Plan)应基于推理(reasoning)、将大任务分解为子任务,并系统性地安排执行顺序。
- 根据自身的知识和相关约束条件,检查输出结果是否与事实存在矛盾或不一致的地方(self-consistency),并进行自我校正,生成多条备选路径并融入规划机制(planning)的 RAG 方法(如ReWoo和Plan+)工作效果更优于单纯依赖推理(reasoning)但缺乏规划(planning)的方法(如ReAct)。
- 根据执行情况动态调整的能力,体现一种去中心化、模块化、动态交互的 “multi-agent” 设计理念。
通常使用下文所述模式(patterns)来执行这些操作。
5.5 Reasoning based Agentic RAG 基于 Agentic RAG 的推理方法
相关论文:https://arxiv.org/pdf/2210.03629.pdf

系统通过对可用的搜索工具进行推理和分析,然后根据推理结果采取相应的行为来解决问题或完成任务。
5.6 Planning based Agentic RAG 基于 Agentic RAG 的解决方案规划方法
相关文档:https://blog.langchain.dev/planning-agents/
相关论文:https://arxiv.org/abs/2305.18323
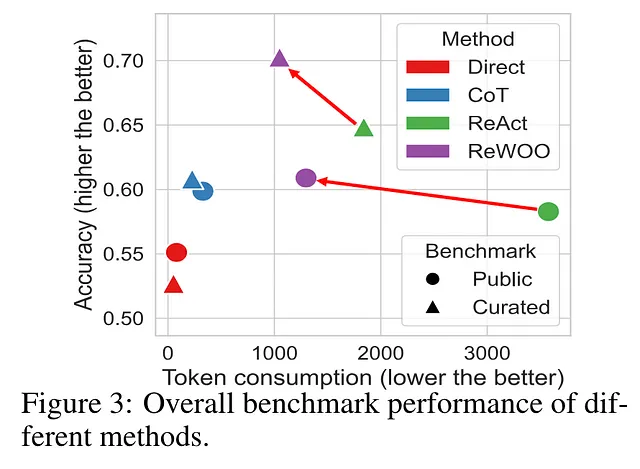
与 ReAct 方法相比,ReWoo 这种 RAG 方法在生成输出时能够产生更精简、高效的 token 序列,有效提高计算效率、避免冗余,但信息量可能会有所折损。
有关 ReAct 为何比 ReWoo 糟糕的更多详情,请参阅此文[18]。
相关论文:https://openreview.net/forum?id=4sajV6NEnWE
它由两部分组成:首先制定解决方案,将整个任务划分为较小的子任务,然后按照规划的解决方案执行子任务。
相关论文:https://arxiv.org/abs/2305.04091
06 部署模式 2 —— 对话式人工智能(Conversational AI)
传统上,对话流程(conversational flows)的高度脚本化的“机器人说”->“人类说”->“机器人说”…这种形式,假设可能发生的各种不同现实场景(hypothetical real world scenarios),Rasa 开发人员称之为“故事(Stories)”。根据用户的状态和互动情况,每个用户的意图都可以表达为上百个“故事(Stories)”(译者注:Stories 指预定义的对话场景或交互模式),机器人会采取相应的行为(actions)执行定义的故事(story),并以预制的回复进行回应。例如,如果用户想订阅一份时事通讯(newsletter),可能会出现两种情况:
- 用户已订阅
- 用户未订阅

source: https://rasa.com/blog/designing-rasa-training-stories/
如果用户输入 “How do I subscribe to the newsletter(如何订阅通讯)” 被机器人识别而触发了预定义的用户意图(intent),机器人需要检查用户是否已经订阅,然后采取合适的下一步措施。这种 “what to do next(下一步应该做什么)” 的决策是人工预先设置的一条 path (译者注:用于引导系统如何处理用户的不同意图或请求,以及如何生成相应的模型响应。)。如果偏离了这条路径,机器人应该说,“Sorry, I am still learning, I can help you with xyz…(抱歉,我还在学习中,我可以帮你处理 xyz…)”。
构建和维护机器人真正需要耗费的成本来自于这些“stories”(译者注:预定义的对话场景或交互模式)。之所以要采用上述这种繁琐乏味的模式,是为了让机器人能够应对各种多样的现实世界场景,并且可以有组织的、有条不紊地添加新的路径 path (译者注:用于引导系统如何处理用户的不同意图或请求,以及如何生成相应的模型响应。)。但是,path 的编写者始终将一些“需要检查的条件”、“需要执行的操作”和“发起对话时希望达到的最终状态或结果”放在脑海中,从而有目的性地执行脚本。
有了 LLMs,我们可以尝试使用 LLMs 的“推理(Reasoning)”和“规划(Planning)”能力来自动化完成脚本的编写或行为路径的规划([19]可以了解更多信息),并在 loop system(译者注:系统不断地接收用户的输入并生成相应的模型响应,然后等待下一轮用户输入。这种系统可以用于持续地对话交互,直到达到预设的结束条件或目标。) 中加入强大的人工智能。
假设你是一个用于客户服务的 Agent,一位用户向你提出同样的请求 —— “我该如何订阅你们的服务?”,你会如何决定接下来应该采取什么行为?是否可以在没有明确定义的约束条件下进行?很可能不行,但为了控制成本,也不能像上面那样大量编写脚本。如果我交代给你如下内容:
Condition — if email exists, user can subscribe
(如果输入的电子邮件是存在的,用户可以订阅)
Tools — check_subscription, add_subscription
(检查订阅功能、添加订阅功能)
如果你有能力和信心思考出解决方案并付诸行动,你应该能够在脑海中编织出像下面这样的 stories :
- 用户想要订阅服务:基于用户的陈述 — “我要如何订阅?”
- 询问用户的电子邮件信息:“请问您的电子邮件是什么?”
- 如果他提供了有效的电子邮件,触发调用工具 —— check_subscription
- 如果该用户尚未订阅,则触发调用 add_subscription
- 反馈订阅成功或订阅失败。
这就是我们希望 LLM 做的事情,即生成 “计划”,将其作为蓝图并在系统运行时执行。有关 planning 和 reasoning 的更多信息,请点击此处[18]了解。
回过头看看该模块化系统的蓝图,让我们看看规划器(planner)是什么样子的:
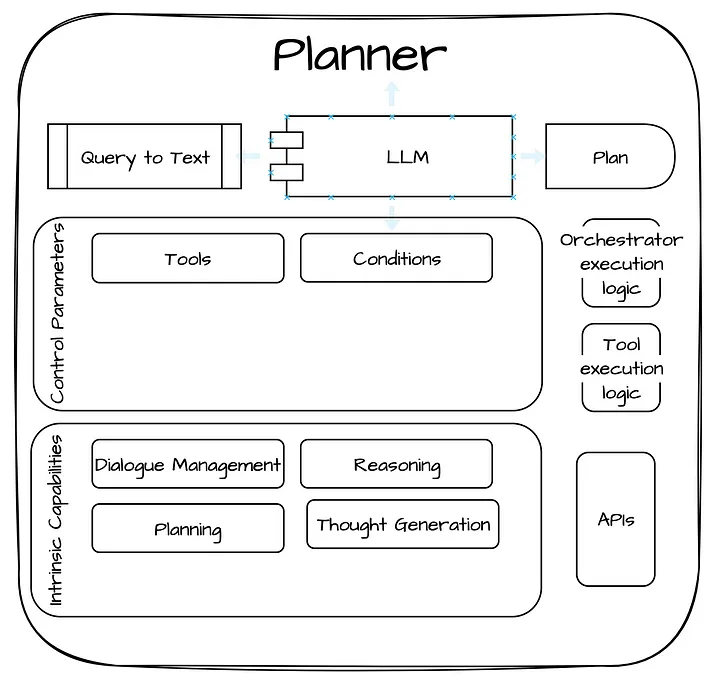
上面的规划器(planner)可以在设计时或运行时使用工具(tools)和约束条件(conditions)来构建 plans 或 stories。让我们看看研究中的一个真实例子:
相关论文:https://arxiv.org/abs/2403.03101
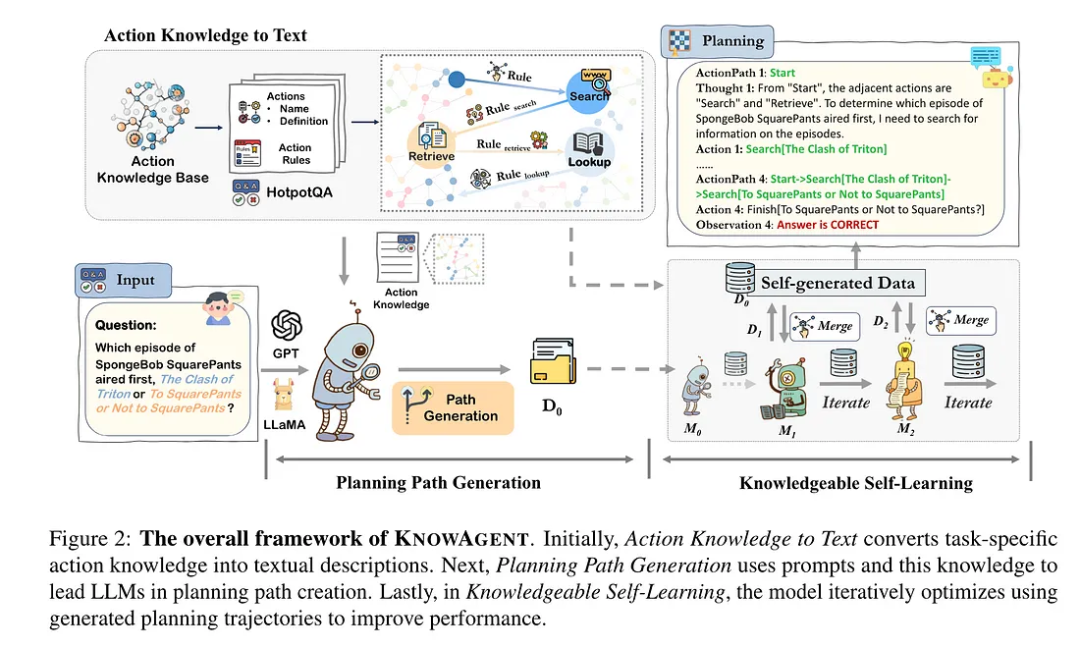
KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents, https://arxiv.org/pdf/2403.03101.pdf
有一些工具可以帮助规划器(planner)以可靠的推理方式决定运行路径(path),其中包括:
- 通过查看先前类似语句所触发的运行路径(path)和行为,规划器(planner)可以借鉴以前的经验,并根据这些信息来决定当前的运行路径(path)。
- 建立企业级的行为图谱(Enterprise graph of actions)以及各种行为(actions)之间的依赖关系。 这有助于规划器确定某个行为是否会产生预期的结果,从而决定下一步该选择采取什么行为,如此反复,递归地解决问题。有关知识图谱(knowledge graphs)和行为规划(planning)与 Neo4J 和 Langchain** 在现实世界中的整合,请参考阅读此文,但不一定与行为路径的规划(planning paths)相关。
- 了解用户或对话的当前状态可以帮助规划器(planner)根据当前情况做出决策,并相应地调整行为路径或相应的规划。
07 部署模式 3 —— Multi — Agent
multi-agent 的配置、优化目标是:为那些由大语言模型驱动的生成器模块(generators)明确定义其角色和职责,并为不同的 Agent 模块提供定制化的功能支持,使它们能够协同工作,最终给出智能的答复/解决方案(answer / solution)。
由于角色设定(roles)和基础模型(underlying models)定义明确,每个 Agent 都可以将某一个子目标或“行为规划”的一部分委托给“专家”(译者注:Expert,指系统中在特定领域或任务上具有专业知识或专长的某个模块、算法或特定功能),然后使用输出结果来决定下一步该做什么。更多相关详细信息,请参考文章结尾处的 GPTPilot 示例。
相关论文:https://arxiv.org/abs/2401.03428
上面提到的那些模式(patterns),是通过使用以下的通信模式(communication patterns)来执行的,这些通信模式控制着在行为执行链(chain of execution)中定义下一行为步骤的权限。更多详情,请参阅 “协调代理系统”(Orchestrating Agentic Systems)[20]。
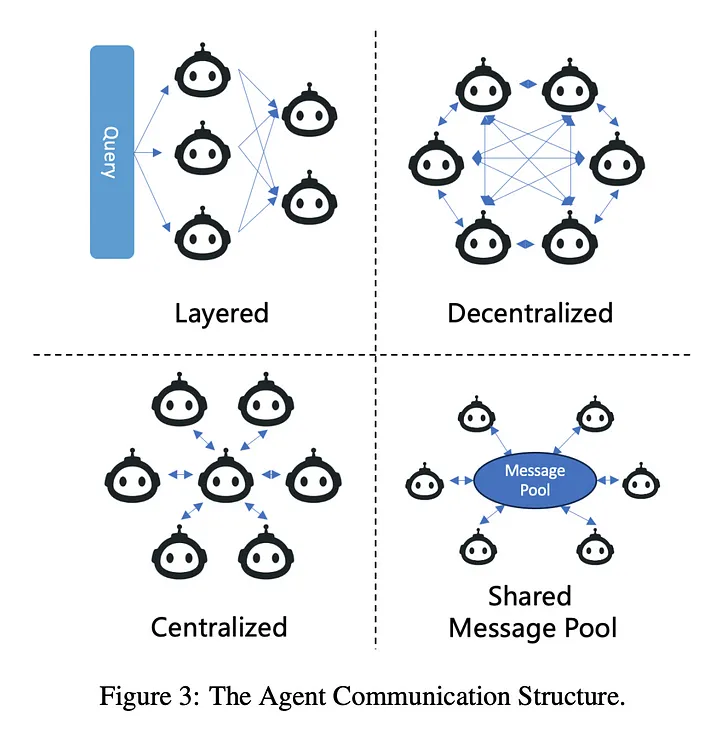
在构建面向现实世界应用的协作智能体(CoPilots)系统时,不同的智能体/模块是如何进行通信和协作的。https://arxiv.org/pdf/2402.01680v1.pdf
Multi-Agent 设计模式的优点[21]如下:
- Separation of concerns(分工明确) :
每个智能体模块(agent)都可以拥有自己专门的指导性指令(instructions)和只包含少量样本的示例数据集(few-shot examples),他们由独立微调过的语言模型驱动,同时还拥有各种工具的配套支持。每个 Agent 模块都被赋予了明确的分工,只需专注于自身的特定任务,而不需要从大量的辅助资源和工具中进行选择和调配。
- Modularity(模块化) :
Multi-agent 这种设计模式允许将复杂的问题分解为易于管理的工作单元,由专门的智能体和语言模型来处理。 这种设计模式能让我们对每个智能体单独进行评估和改进,而不会干扰整个应用程序。将工具和职责进行分组可以带来更好的结果。当智能体专注于某项特定任务时,更有可能取得成功。
- Diversity(多样性) :
在构建智能体团队(agent-teams)时,应当确保团队内部存在足够的多样性,包括不同的模型、知识源、任务视角等。 多样性有助于团队从不同角度思考问题,相互印证和完善结果,降低系统产生幻觉或偏见的风险。这与人类团队中应该拥有多元背景和观点的理念是一致的,体现了这种设计模式的人性化特征。
- Reusability(可复用性) :
一旦构建了智能体,就有机会将这些智能体在不同的使用场景中重复使用,并可以尝试构建一个智能体生态系统,通过合适的编排/协调框架(如 AutoGen、Crew.ai 等)共同解决问题。
08 部署模式 4 —— CoPilot
在我看来,CoPilot系统通过与外界(用户、测试工具…)的互动获取新知识这一点,是它与其他 AI 系统最大的区别和优势所在。
8.1 CoPilot 的构建框架介绍与 CoPilot 的实现方法
在构建这些协同智能助手(CoPilot)时,最重要的是要区分构建 CoPilot 的框架和协同智能助手的实现方法(如GPTPilot和Aider)。在大多数情况下,没有任何开源的协同智能助手是基于这些框架开发的,都是从零开始开发的。
回顾一下当下流行的 CoPilot 实现方法:OpenDevin(https://github.com/OpenDevin/OpenDevin) 、 GPT Pilot(https://github.com/Pythagora-io/gpt-pilot/tree/main)
回顾一下当下流行的相关研究论文:AutoDev(https://arxiv.org/pdf/2403.08299.pdf) 、AgentCoder(https://arxiv.org/pdf/2312.13010.pdf)
当下流行的 CoPilot 构建框架:Fabric(https://github.com/danielmiessler/fabric) 、LangGraph(https://python.langchain.com/docs/langgraph)、 DSPy(https://github.com/stanfordnlp/dspy) 、CrewAI(https://github.com/joaomdmoura/crewAI) 、AutoGen(https://microsoft.github.io/autogen/docs/Getting-Started/) 、MetaGPT、SuperAGI等
09 Deep Dive — apps
9.1 GPT Pilot
GPT Pilot 项目是一个表现出色的经典案例,它以 “layered” flow (译者注:将任务分解为较小的子任务,并在不同的层次或级别中处理这些子任务,逐步实现任务。)的方式执行看似复杂的任务,使用具有创造性的提示词来引导语言模型生成特定类型的模型输出,并将多个模型的响应拼接在一起,执行目标任务或生成复杂的内容输出。
系统中的不同配置文件(profiles)或角色以分层通信的方式工作,请浏览下面的绿色矩形框:
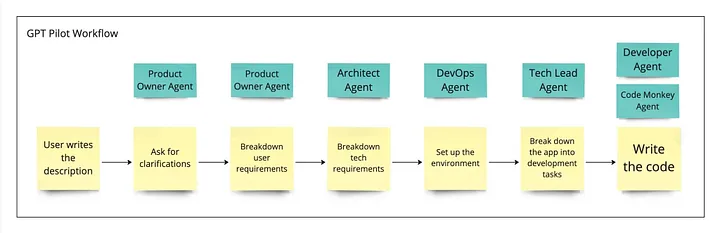
https://www.reddit.com/r/MachineLearning/comments/165gqam/p_i_created_gpt_pilot_a_research_project_for_a/
系统中各个独立的 Agent 以一种分层的方式相互交互,各agent按顺序相继被触发,在整个系统中不存在中心决策的agent。
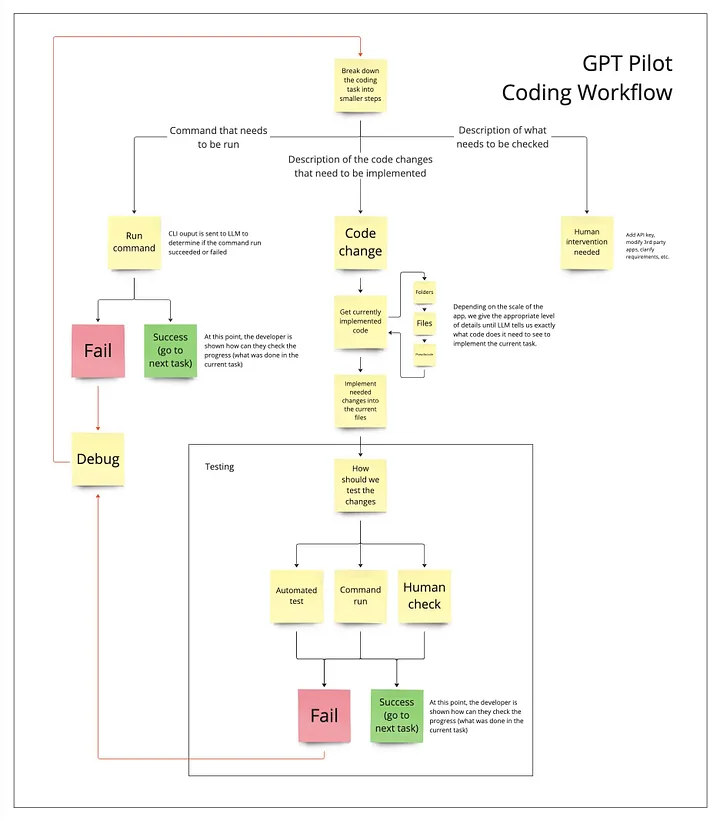
产品在部署时采用了一些很好的设计原则,这些设计原则使得该产品在实际运行时表现出色:
- 将复杂的任务分解成更简单、更易管理的部分,每个部分都可以通过 LLM 生成相应的实现代码。
- 采取了 Test driven development"(TDD) 开发方法,从人类用户处收集优质产品需求和功能期望,以便并在开发过程中准确验证和迭代产品。
- 上下文回溯(译者注:Context rewinding,在处理任务或生成代码时,回顾先前的上下文。)和代码摘要(译者注:Code summarization,将一段代码或代码块简化为其核心要点,使得 LLM 可以生成更具概括性和易读性的代码,而不是生成冗长或复杂的代码。)。
尽管本文介绍的提示词工程和工作流设计都很复杂,但对每个 Agent 进行微调,对于降低使用成本和提高 AI 系统准确性的好处是不言而喻的。
Thanks for reading!
Raunak Jain
Seeking patterns and building abstractions
END
参考资料
[1]https://docs.deepwisdom.ai/main/en/guide/use_cases/agent/researcher.html
[2]https://www.youtube.com/watch?v=m8VSYcLqaLQ
[3]https://www.youtube.com/watch?v=8R7QOJgGyIQ
[4]https://www.youtube.com/watch?v=Cl19yWHhc2g
[5]https://python.langchain.com/docs/modules/tools/
[6]https://microsoft.github.io/autogen/docs/Use-Cases/agent_chat
[7]https://docs.haystack.deepset.ai/docs/components
[8]https://www.sciencedirect.com/science/article/abs/pii/B0080430767005349
[9]https://arxiv.org/pdf/2402.02716.pdf
[10]https://arxiv.org/abs/2402.01817
[11]https://aiguide.substack.com/p/can-large-language-models-reason
[12]https://www.ece.uw.edu/wp-content/uploads/2024/01/lecun-20240124-uw-lyttle.pdf
[13]https://arxiv.org/abs/2402.10178
[14]https://medium.com/@raunak-jain/fine-tuning-llms-for-enterprise-rag-8c1eb3ac6b32
[15]https://arxiv.org/abs/1612.01294
[16]https://arxiv.org/abs/2201.05176
[17]https://arxiv.org/pdf/2305.03653.pdf
[18]https://medium.com/@raunakjain_25605/path-to-production-for-llm-agents-f0a9cafd2398
[19]https://medium.com/@raunak-jain/llm-driven-planning-and-reasoning-for-enterprise-ai-09bf6b5e1965
[20]https://medium.com/@raunak-jain/orchestrating-agentic-systems-eb945d305083
[21]https://abvijaykumar.medium.com/multi-agent-architectures-e09c53c7fe0d
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://medium.com/@raunak-jain/design-patterns-for-compound-ai-systems-copilot-rag-fa911c7a62e0