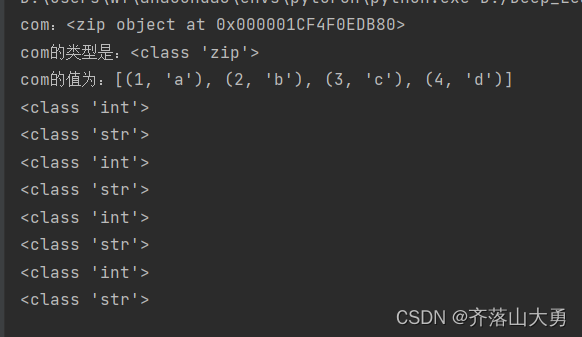
新数据类型-Hyperloglog
简介
在我们做站点流量统计的时候一般会统计页面UV(独立访客:unique visitor)和PV(即页面浏览量:page view)。
什么是基数?
数据集{1,2,5,7,5,7,9},那么这个数据集的基数集为{1,2,5,7,9},基数(不重复元 素)为5,基数估计就是在误差可接受范围内,快速计算基数。
如果是通过Redis来处理,我们可以使用String类型然后自增计数即可达到统计PV,统计UV可以使用 Set,每个用户id是唯一的可以放到这个集合里。
以上方案虽然结果准确,但随着数据不断增加,导致占用的内存空间越来越大,对于非常大的数据集是 不合适的。
Hyperloglog 是一种基数估算统计,在输入元素的数量特别巨大时,计算基数所需的空间是固定的,并 且很小。
在Redis中,每个Hyperloglog 只占用12KB内存,就可以计算接近 2 64 2^{64} 264个不同元素的基数。
因为HyperLogLog 只会更具输入元素来计算基数,而不会存储输入元素本身,所以Hyperloglog 不能像 集合那样,返回输入的各个元素。
常用命令
-
pfadd key element1 element2……将所有元素参数添加到 Hyperloglog 数据结构中。
如果至少有个元素被添加返回 1, 否则返回 0。
pfadd book1 python sql 添加两个元素,当前book1数量为2 pfadd book1 python js 添加一个元素,当前book1数量为3
-
pfcount key1 key2……计算Hyperloglog 近似基数,可以计算多个Hyperloglog ,统计基数总 数。
pfcount book1 计算book1的基数,结果为3 pfadd book2 html css 添加两个元素到book2中 pfcount book1 book2 统计两个key的基数总数,结果为5
-
pfmerge destkey sourcekey1 sourcekey2……将一个或多个Hyperloglog(sourcekey1) 合并 成一个Hyperloglog (destkey )。
比如每月活跃用户可用每天活跃用户合并后计算。
pfmerge book book1 book2 将book1和book2合并成book,结果为5