两个月前,接到一个粉丝的要求,说希望在我之前编写的一个python编写的文件同步脚本(Python编写的简易文件同步工具(已解决大文件同步时内存溢出问题)![]() https://blog.csdn.net/donglxd/article/details/131225175)上加入多线程复制文件的功能,前段时间一直在忙工作也没时间弄,但是还是先答应了他的要求。工作一直忙到4月底总算抽出一部分时间弄这个东西,python多线程一直没好好研究过,这次就下决心,深入学习下,这个代码大概有400行不到,断断续续弄了1个多礼拜左右,如果这位粉丝还在关注我,请见谅,拖了这么久-_-!
https://blog.csdn.net/donglxd/article/details/131225175)上加入多线程复制文件的功能,前段时间一直在忙工作也没时间弄,但是还是先答应了他的要求。工作一直忙到4月底总算抽出一部分时间弄这个东西,python多线程一直没好好研究过,这次就下决心,深入学习下,这个代码大概有400行不到,断断续续弄了1个多礼拜左右,如果这位粉丝还在关注我,请见谅,拖了这么久-_-!
如果我直接放代码,大部分的人是喜欢的,但是看到这篇文章抬头,点进来的各位,难道心里就没有一点点想学习下python多进程、多线程、多协程的区别和作用吗?不好奇它们怎么同时调用而不互相影响吗? 实话说写代码的过程中,我是很享受的,一点点的代码堆积,也是一点点的知识、经验累积,现在GPT之类AI横行的时代,我们除了享受快消的红利外,是不是也应该提高、培养自己的编程思路,AI只是释放我们的劳动力,而不是限制了我们的想象,AI替代不了我们思考,大家不觉得吗?下面我来带大家解析下我的程序,我会分块进行下去,尽量拆成小块给大家好消化点.
一、首先,先讲讲python多进程、多线程、多协程的区别和作用。
1.多进程程序,顾名思义就是开了多个python进程一起计算,所以在python有GIL锁(不了解的小伙伴请看以下博文深入理解Python中的GIL(全局解释器锁)![]() https://zhuanlan.zhihu.com/p/75780308)的前提下,使用多进程计算CPU密集型程序是最佳选择,这也是我把源文件和复制文件校验对比时,使用多进程的原因。
https://zhuanlan.zhihu.com/p/75780308)的前提下,使用多进程计算CPU密集型程序是最佳选择,这也是我把源文件和复制文件校验对比时,使用多进程的原因。
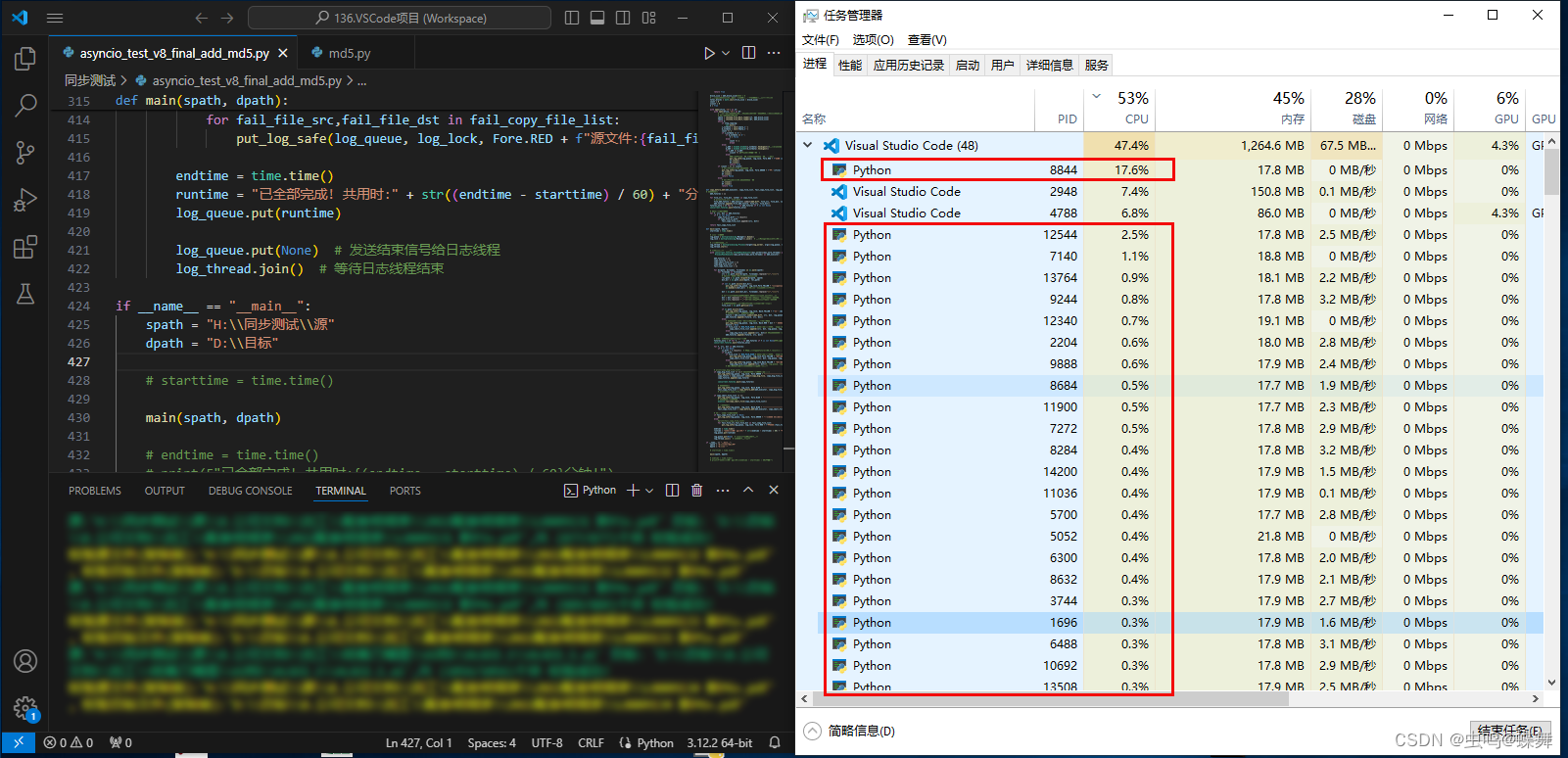
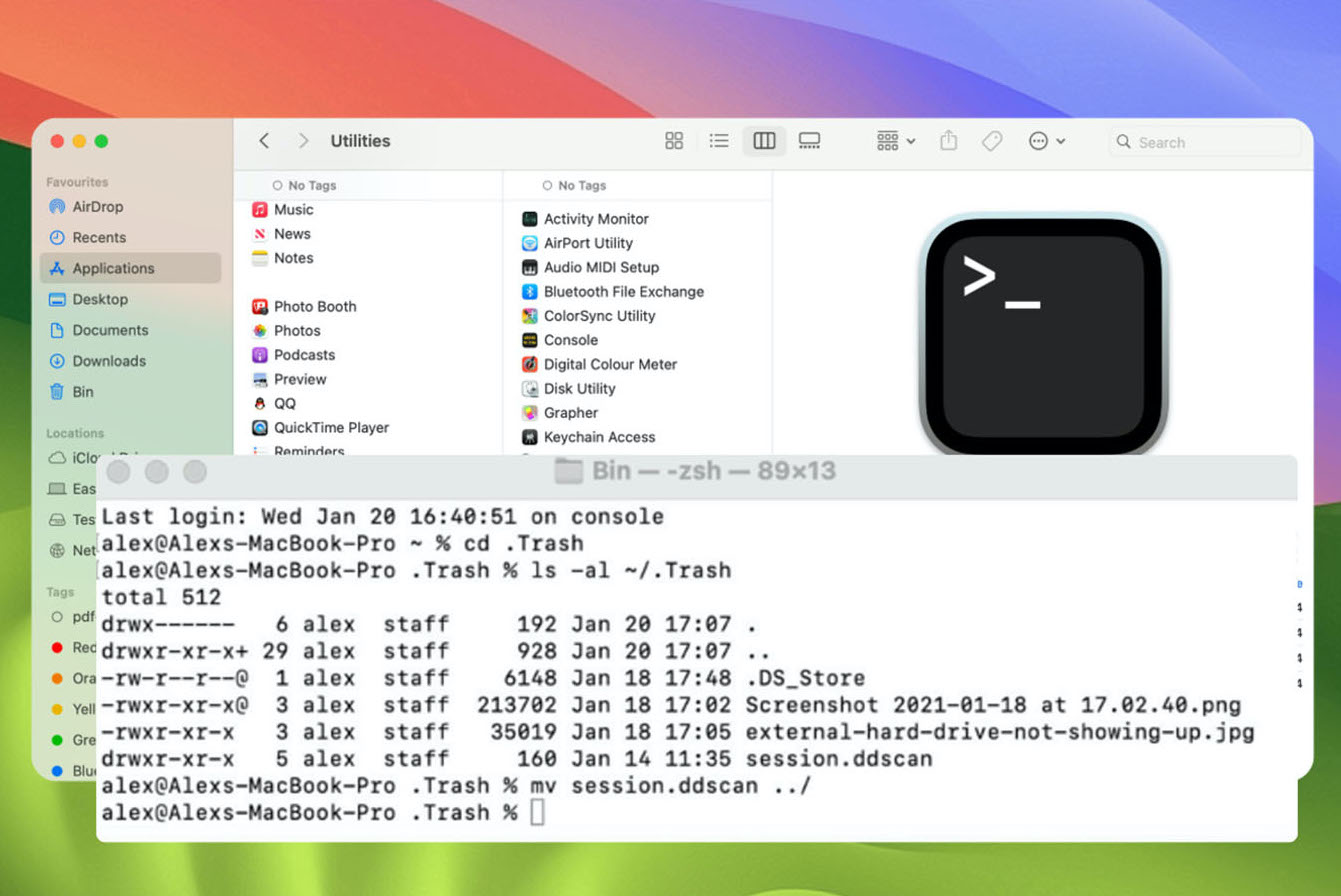
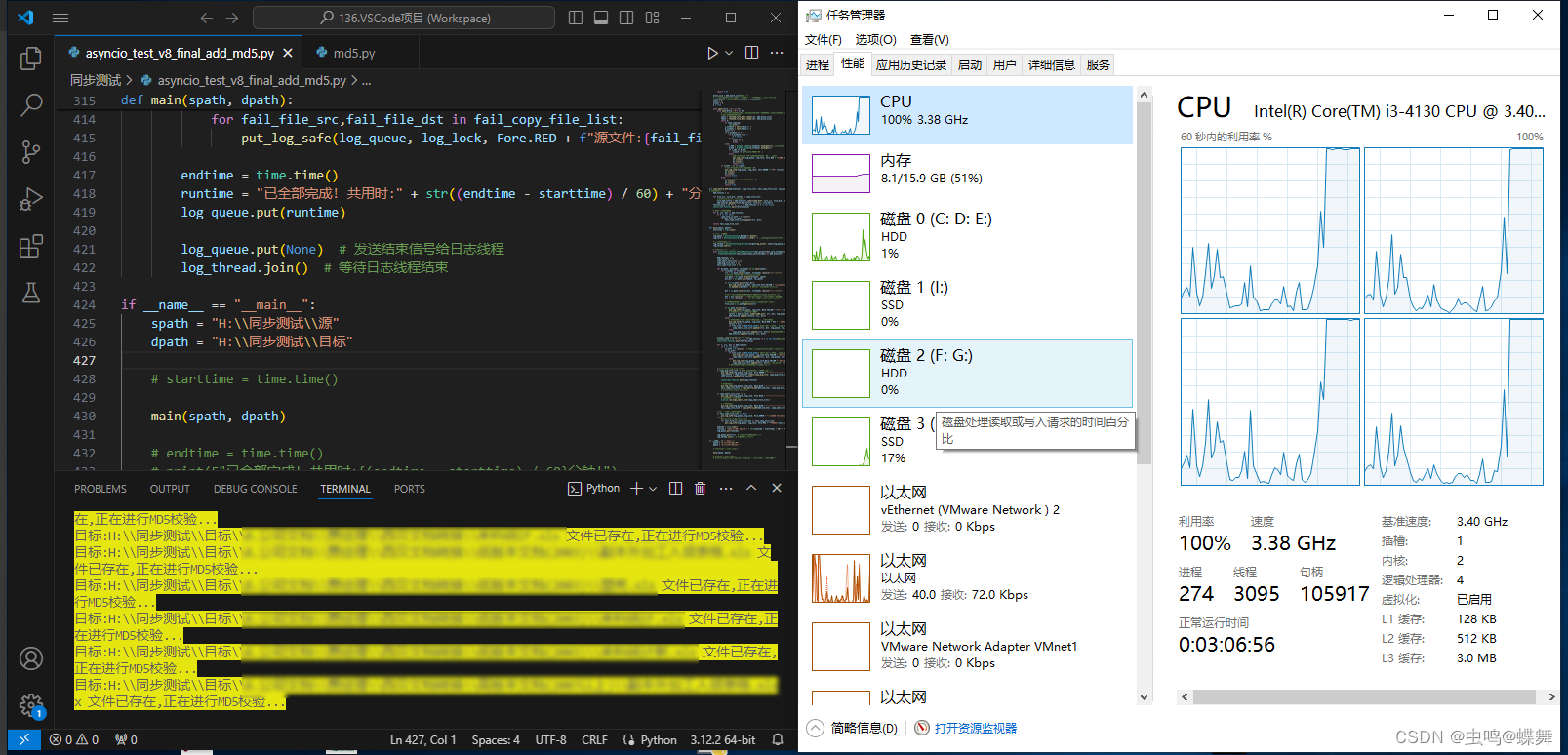
可以看到上图是多进程校验时的系统占用截图,可以看到任务管理器中产生了很多Python进程,而且在CPU占用一列也有百分比占用,这时有人问,为什么你的多进程程序,只有53%的CPU占用,这是因为我想解释另一个多进程效率低的问题,你们可以发现图片中最上一行的VScode的磁盘占用数时60多MB/S,而我为了演示这个问题,使用了机械硬盘,这也是我多次测试的经验。因为是机械硬盘,所以读写能力一共才100+MB/S,所以MD5校验时,机械磁盘(磁盘0)的占用已经满了,导致了多进程代码没有足够的数据计算,所以CPU占用没有跑满。
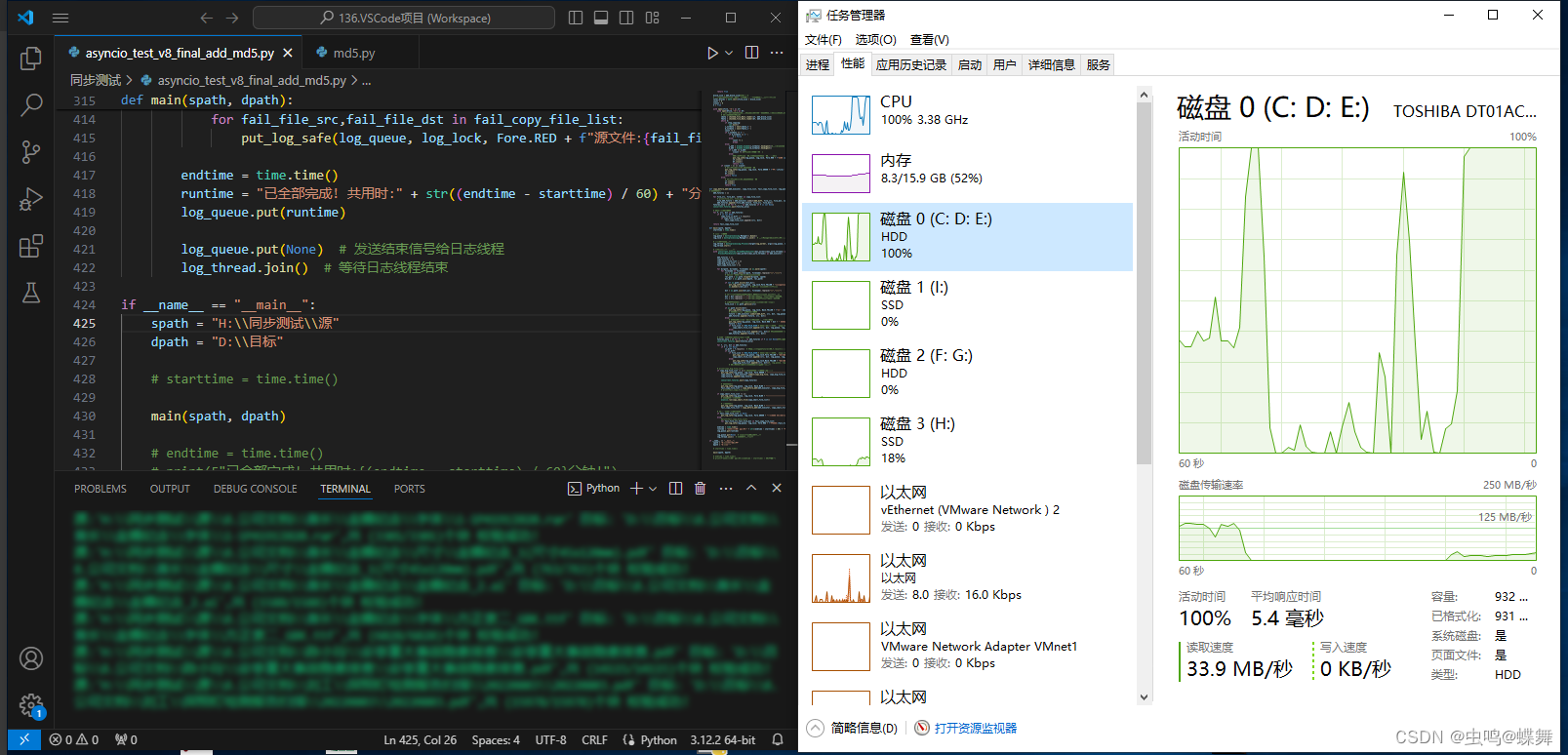
如果复制的源文件和目标文件都是在固态硬盘上,也就没有磁盘占用的局限,多进程的代码可以跑足CPU100%,如下图:
因此大家如果在机械硬盘上没有跑满CPU占用,不要疑惑代码的问题。
多进程的代码如下:
from concurrent.futures import ProcessPoolExecutor
def main():
max_work_threads = 30
with ProcessPoolExecutor(max_workers=max_work_threads) as md5_executor:
src = "H:\\同步测试\\源"
dst = "H:\\同步测试\\目标"
md5_future = md5_executor.submit(md5_diff, src, dst)
concurrent.futures.wait([md5_future])
if __name__ == "__main__":
main()先用with ProcessPoolExecutor(max_workers=max_work_threads) as md5_executor:定义一个md5的多进程运算集合,其中的max_workers控制生成的计算进程总数,实际不用这么多,我是考虑到有些小伙伴电脑性能OK,所以多加的,如上面的截图中,很多python进程都没有跑满。然后使用md5_future = md5_executor.submit(md5_diff, src, dst),这句调用md5_diff校验子函数,来创建多个包含md5_diff校验计算的进程,这样就实现了多进程MD5校验。
2.多线程程序,适合使用在IO计算密集型的程序上,所以我们的大文件复制可以使用它,和多进程程序差不多可以用如下代码创建:
import concurrent.futures
def main():
max_work_threads = 30
with concurrent.futures.ThreadPoolExecutor(max_workers=max_work_threads) as copy_executor
src = "H:\\同步测试\\源"
dst = "H:\\同步测试\\目标"
copy_big_future = md5_executor.submit(copy_big_file, src, dst)
concurrent.futures.wait(copy_big_future)
if __name__ == "__main__":
main()需要注意的concurrent.futures.wait里传入的copy_big_future是一个多进程或多线程的future对象,所以如果你的copy_big_file或md5_diff函数有返回值,需要用future.result()得到,如下所示:
is_diff = f.result()# is_diff是MD5校验后的返回值3.多协程程序,因为协程可以建立很多,甚至可以生成上万个协程,所以比较适合复制小文件,简单的使用例子如下:
使用前请先安装:
pip install aiofiles
#asyncio python3.5以上已包含,没有请更新python到3.5以上多协程示例代码如下:
import asyncio
import aiofiles
# ======================异步复制小文件函数开始===================================
async def copy_small_file_async(src, dst):
# 使用多协程复制单个小文件
async with aiofiles.open(src, 'rb') as fs:
filedata = await fs.read()
async with aiofiles.open(dst, 'wb') as fd:
await fd.write(filedata)
async def copy_small_file(file_tasks):
tasks = [copy_small_file_async(src, dst, log_queue, log_lock) for src, dst, log_queue, log_lock in file_tasks]
await asyncio.gather(*tasks)
# ======================异步复制小文件函数结束===================================
def main(spath, dpath):
copy_small_file_list = []
#注意这里我为了简化例子方便学习copy_small_file_list为空,实际需要加for循环历遍源目录后如下赋值
# for dirpath, dirnames, filenames in os.walk(spath):
# for filename in filenames:
# src = os.path.join(dirpath, filename).replace("\\","\\\\")
# # 构建目标文件路径,保留相对目录结构
# rel_path = os.path.relpath(dirpath, spath)
# dst_dir = os.path.join(dpath, rel_path)
# copy_small_file_list.append((src, dst))
asyncio.run(copy_small_file(copy_small_file_list))
if __name__ == "__main__":
spath = "H:\\同步测试\\源"
dpath = "H:\\同步测试\\目标"
main(spath, dpath)二、然后我讲以下我编写多线程大文件复制函数时的一些思路,给大家借鉴:
因为考虑到机械硬盘的性能,所以判断到底是大文件还是小文件的分界线大小,我通过代码开头的公共变量BIG_FILE_SIZE = 50 * 1024 * 1024 # 50MB(大文件复制区块大小)控制,也就是50MB,大于50MB走大文件复制的代码,小于的话就走多协程复制的代码,为什么是50MB而不是100MB,是因为如果同一个机械硬盘对拷,势必会读和写一起操作在同硬盘上,所以大小取机械硬盘的50%读写性能。
基于上所述,我举例说明下我的大文件复制函数的思路,首先,在复制前的第一遍校验时,先以50MB大小判断把大文件的源路径和复制路径放入一个copy_big_file_list,在第一遍校验完成后,我们就有了两个列表,即大、小文件目录列表(小文件列表为:copy_small_file_list),然后我们为了程序的效率,把大文件和小文件们分开复制,大文件列表copy_big_file_list传入如下的copy_big_file主复制函数:
def copy_big_file(copy_big_file_list, log_queue, log_lock):
# 复制大文件时的主函数,此函数的作用是,把copy_big_file_list传入的包含源文件和对象文件目录解析后,循环多线程分割合并
for src, dst in copy_big_file_list:
print(f'大文件复制: 源: "{src}" , 目标:"{dst}" 开始...')
# Manager字典,用于跟踪文件合并进度
manager = multiprocessing.Manager()
progress_dict = manager.dict()
# 分小块读取复制
temp_files = create_chunks_and_copy(src, dst, BIG_FILE_SIZE, log_queue, log_lock)
# 小区块合并到4个大区块
intermediate_files = partitioned_merge(src, dst, temp_files, log_queue, log_lock, progress_dict)
# 4个大区块合并成完整文件
final_merge(src, dst, intermediate_files, log_queue, log_lock, progress_dict)可以看到这个copy_big_file函数通过历遍copy_big_file_list(大文件列表),把每个大文件传入下面的3个子函数中,其中create_chunks_and_copy是分小块读取复制,partitioned_merge是小区块合并到4个大区块,final_merge是4个大区块合并成完整文件,以下是这3个子函数和它们的子函数的代码:
def copy_chunk(src, dst, start, size):
# 单个块复制函数(大文件分割后的单个块复制)
with open(src, 'rb') as fs:
fs.seek(start)
chunk = fs.read(size)
with open(dst, 'wb') as fd:
fd.write(chunk)
def create_chunks_and_copy(src, dst_prefix, chunk_size, log_queue, log_lock):
# 创建并复制块到临时文件
# 函数作用:先通过获得源文件的大小,计算出每个块(50MB 代码开头处的公共变量BIG_FILE_SIZE定义)的起始大小,如第一个为FILE_00000.tmp
# FILE就是目标文件的名称,根据父函数决定,这里不是简化表示以下,关键是之后的_00000.tmp,表示第一个文件的起始地址是0,那么依此推理,
# 第二个文件就是50*1024*1024(50MB)=52428800,所以第二个文件的命名就是FILE_52428800.tmp,这样命名的好处是,拼接多区块时,可以直接
# 把每个文件的拼接起始地址,传递给拼接函数merge_files.
file_size = os.path.getsize(src)
chunks = [(i, dst_prefix + f'_{i:05d}.tmp') for i in range(0, file_size, chunk_size)]
# 此代码返回50mb分割后的区块名称数组chunks,并用分割的起始字节命名(如:FILE_00000.tmp、FILE_52428800.tmp....)
put_log_safe(log_queue, log_lock, Back.YELLOW + f'开始多线程分割大文件: "{src}"')
with concurrent.futures.ThreadPoolExecutor() as executor:
# 创建多线程运行上面的copy_chunk单个块复制子函数
futures = [executor.submit(copy_chunk, src, dst, start, chunk_size)
for start, dst in chunks]
concurrent.futures.wait(futures)
return [dst for start, dst in chunks]
def merge_files(files, dst_filename, dst, log_queue, log_lock, isBigSmallBlock, progress_dict):
# 合并多个文件到一个目标文件
# 拼接区块函数:两种调用方式,通过isBigSmallBlock布尔变量控制,
# 拼接方式:
# 1. isBigSmallBlock=False 小区块合并,把FILE_00000.tmp、FILE_52428800.tmp....这样的小区块通过多线程
# 合并成FILE_1.tmp、FILE_2.tmp、FILE_3.tmp、FILE_4.tmp,为什么是4个?因为是由下面的父函数partitioned_merge
# 中的num_mergers=4定义了分割线程数,这个可以根据需求修改,如是固态硬盘,考虑到磁盘利用率,不需要分太多线程,因为线程越多,
# 每个线程读取的文件大小分配的越小,导致磁盘利用率上不去。
# 2. isBigSmallBlock=Ture 大区块合并,把上面生成的FILE_1.tmp、FILE_2.tmp、FILE_3.tmp、FILE_4.tmp合并成完整的FILE.tmp
dstPath = os.path.dirname(dst)
fileBasePath = dstPath + "\\" if isBigSmallBlock else ""
with open(dstPath + "\\" + dst_filename, 'wb') as fd:
for idx, file in enumerate(files):
with open(fileBasePath + file, 'rb') as f:
data = f.read()
fd.write(data)
# 更新进度
# 此处的progress_dict由以下两句创建manager = multiprocessing.Manager() progress_dict = manager.dict()
# 这个多进程字典的作用是,在这个多线程拼接子函数中更新4个拼接线程单独的文件拼接进度,如下这样的:
# 正在合并小区块: "5.avi_1.tmp" ...已完成(1/3)
# 正在合并小区块: "5.avi_2.tmp" ...已完成(1/3)
# 正在合并小区块: "5.avi_3.tmp" ...已完成(1/3)
# 正在合并小区块: "5.avi_4.tmp" ...已完成(1/3)
# 正在合并小区块: "5.avi_1.tmp" ...已完成(2/3)
# 正在合并小区块: "5.avi_2.tmp" ...已完成(2/3)
# 正在合并小区块: "5.avi_3.tmp" ...已完成(2/3)
# 正在合并小区块: "5.avi_4.tmp" ...已完成(2/3)
# 正在合并小区块: "5.avi_1.tmp" ...已完成(3/3)
# 正在合并小区块: "5.avi_2.tmp" ...已完成(3/3)
# 正在合并小区块: "5.avi_3.tmp" ...已完成(3/3)
# 正在合并小区块: "5.avi_4.tmp" ...已完成(3/3)
# 如上可以看到"5.avi_1.tmp"之后的已完成数一共有3个,分别是(1/3)、(2/3)、(3/3),这只是上面说的4个分割线程数中的一个线程,它
# 的工作就是FILE_00000.tmp、FILE_52428800.tmp....这样的所有小区块,分4份,用4个线程,分开合并成"5.avi_1.tmp" 、"5.avi_2.tmp"、
# "5.avi_3.tmp" 、 "5.avi_4.tmp"这4个大区块。而这个progress_dict就是存储其中合并"5.avi_1.tmp"这个线程的当前进度的字典变量
# 也就是如下中的1、2、3序列:
# "5.avi_1.tmp" ...已完成(1/3)
# "5.avi_1.tmp" ...已完成(2/3)
# "5.avi_1.tmp" ...已完成(3/3)
progress_dict[dst_filename] = idx + 1 # idx+1 表示已完成的文件数
# 计算进度条信息
progress_info = f"{progress_dict[dst_filename]}/{len(files)}"
logForBlockTxt = "大区块" if isBigSmallBlock else "小区块" #根据isBigSmallBlock变量来输出到底是大区块消息,还是小区块消息
logColor = Back.BLUE if isBigSmallBlock else Back.GREEN
put_log_safe(log_queue, log_lock, logColor + f'正在合并{logForBlockTxt}: "{dst_filename}" ...已完成({progress_info})')
os.remove(fileBasePath + file) # 合并后删除临时文件
def partitioned_merge(src, dst, temp_files, log_queue, log_lock, progress_dict, num_mergers=4):
# 小分区合并文件父函数
# 此函数控制了上面的合并函数merge_files,并可以修改合并的线程数
filename = os.path.basename(src)
if len(temp_files) < 4:#排除分小区块后,小区块总数小于4个,不能分4线程的问题.
partition_size = len(temp_files)
else:#以下是正常的大于4个小区块,分4线程大量复制
partition_size = len(temp_files) // num_mergers
partitions = [temp_files[i:i + partition_size] for i in range(0, len(temp_files), partition_size)]
if len(partitions) > num_mergers:#如果文件大小不能被4线程整除,最后的部分的处理情况
last = partitions.pop()
partitions[-1].extend(last)
intermediate_files = []
total_size = sum(os.path.getsize(f) for f in temp_files)
put_log_safe(log_queue, log_lock, Back.BLUE + f'正在合并小区块: "{dst}" ...')
with concurrent.futures.ThreadPoolExecutor() as executor: #创建多线程调用合并函数merge_files
futures = []
for i, partition in enumerate(partitions):
intermediate_file = f'{filename}_{i+1}.tmp'#根据设定的分割线程数,建立"5.avi_1.tmp" 、"5.avi_2.tmp"、"5.avi_3.tmp" 、 "5.avi_4.tmp"这样的大分区块
isBigSmallBlock = False
future = executor.submit(merge_files, partition, intermediate_file, dst, log_queue, log_lock, isBigSmallBlock, progress_dict)
futures.append(future)
intermediate_files.append(intermediate_file)
concurrent.futures.wait(futures)
return intermediate_files#返回这些大分区块的名称,方便之后合并.
def final_merge(src, dst, intermediate_files, log_queue, log_lock, progress_dict):
# 最终合并所有分区文件到一个大文件,并重命名,显示进度
final_tmp = os.path.basename(dst + '.tmp')
dstPath = os.path.dirname(dst)
total_size = sum(os.path.getsize(dstPath + "\\" + f) for f in intermediate_files)
put_log_safe(log_queue, log_lock, Back.BLUE + f'开始合并大区块: "{dst}" ...')
isBigSmallBlock = True
merge_files(intermediate_files, final_tmp, dst, log_queue, log_lock, isBigSmallBlock, progress_dict)
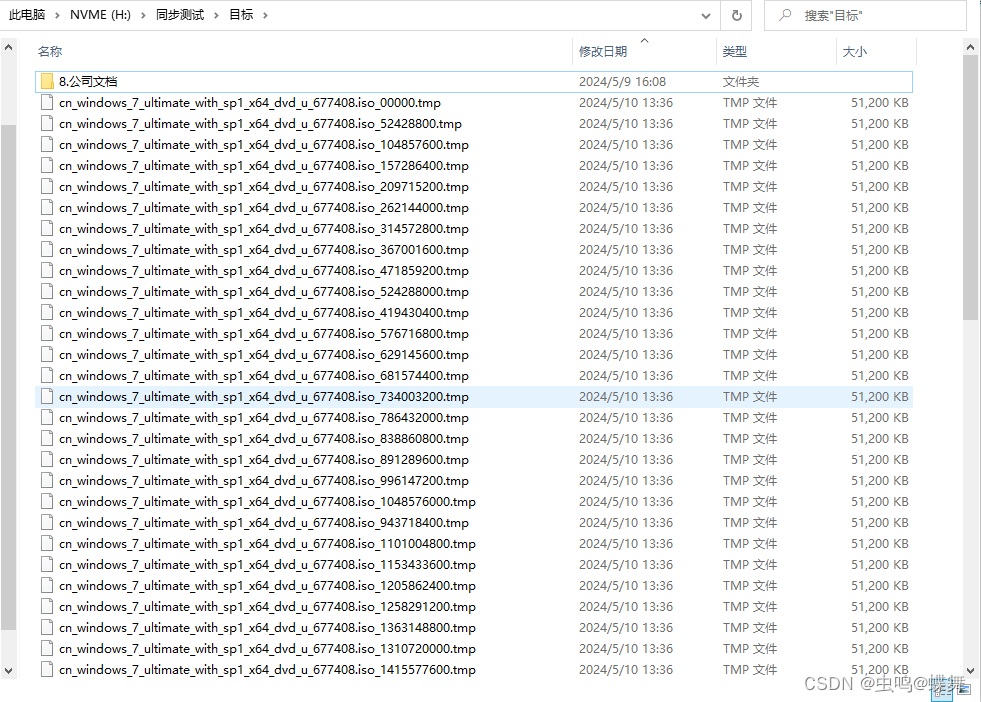
os.rename(dstPath + "\\" + final_tmp,dst)上面函数的具体功能,我在代码中都一一注释了,简单说一下吧!其实当我的代码拿到一个大文件的目录后,就会把这个大文件分割成很多个50MB大小的小区块文件,命名方式就是FILE_00000.tmp、FILE_52428800.tmp,这里的52428800就是50*1024*1024(50MB)=52428800计算而来,所以下面的FILE_104857600.tmp就是100*1024*1024(100MB)=104857600,但是记住这个数字只是文件合并的起始地址,文件的大小还是50MB
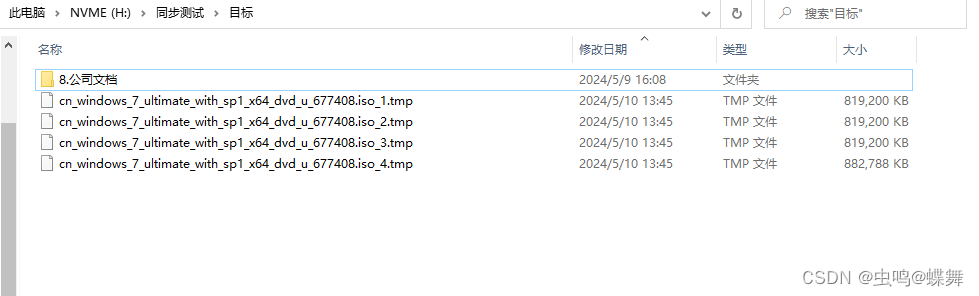
然后把所有的小区块通过partitioned_merge函数调用merge_files子函数,用4个线程合并到4个大区块上,如下图所示:
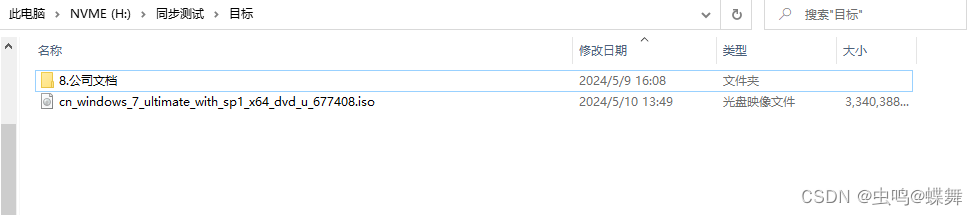
最后使用final_merge合并成完整的大文件,如下图:
 三、这个脚本还有一个我认为值得研究的就是显示输出消息功能,之前有用rich.progress的进程条尝试编写,发现运行效率太差,因为rich.progress的多线程是自动加锁同步的,导致运行速度很慢,并且不能用在多进程上,所以改用文本输出窗口,因为多进程、多线程、多协程运行输出消息很快,导致消息和混乱,所以使用带彩色输出文本的colorama库,安装方法如下:
三、这个脚本还有一个我认为值得研究的就是显示输出消息功能,之前有用rich.progress的进程条尝试编写,发现运行效率太差,因为rich.progress的多线程是自动加锁同步的,导致运行速度很慢,并且不能用在多进程上,所以改用文本输出窗口,因为多进程、多线程、多协程运行输出消息很快,导致消息和混乱,所以使用带彩色输出文本的colorama库,安装方法如下:
pip install colorama然后使用如下的代码重新定义print输出函数:
from colorama import init, Fore, Back, Style
init(autoreset=True)
# ======================多进程输出Log函数开始==========================
def put_log_safe(log_queue, log_lock, message):
# 函数作用:输入消息队列
# 把带有进程锁的入栈消息的功能封装在这个函数中,方便程序运行时,随时存取消息队列用
# 注意:log_queue队列是多进程消息队列,不是多线程消息队列,因为我的main函数中定义有多进程代码,导致使用多线程消息队列时,并不能输出消息队列,
# 但是使用multiprocessing.Manager().Queue()定义的多进程消息队列,可以很好的运行在多进程和多线程代码中传输消息
"""
安全地向日志队列添加一条消息。
Args:
log_queue (multiprocessing.Queue): 被用来添加日志的队列。
log_lock (multiprocessing.Lock): 控制队列访问的锁。
message (str): 要添加到日志队列的消息。
"""
log_lock.acquire()
try:
log_queue.put(message)
finally:
log_lock.release()
def log_worker(log_queue, print_lock):
# 输出消息队列到消息窗口,并记录到log_output.txt文件中
with open("log_output.txt", "a", encoding="utf-8") as f:
while True:
log_entry = log_queue.get()
if log_entry is None: # 接收到结束信号:收到结束信号,停止输出消息
f.close()
break
if log_entry.strip():
print_lock.acquire() # 获取打印锁:加锁是防止输出消息时,多线程引起的随机空行的问题
try:
print(log_entry,flush=True)
if log_entry[0] == "":
log_entry = log_entry[5:]
f.write(log_entry + "\n")#.replace("","").replace("[","").replace("41","").replace("43","").replace("42","").replace("31","").replace("32","").replace("33","").replace("34","") + "\n") # 去除程序中print输出杂乱的颜色的代码(如:Back.GREEN),使输入到日志文件中的消息更清楚
f.flush() # 确保即时写入文件
finally:
print_lock.release() # 释放打印锁
f.close()
# ======================多进程输出Log函数结束====================================在所有的需要输出消息的函数中使用如下命令,带颜色输出:
put_log_safe(log_queue, log_lock, Back.BLUE + f'源:"{src}" 到 目标:"{dst}" 复制成功!')你可能奇怪put_log_safe中的log_queue, log_lock这两个参数是什么作用?其实因为是多进程、多线程、多协程程序,一开始编写输出我就遇到了很奇怪的Bug,就是运行程序,输出消息后,有随机产生空行的问题,通过GPT知道,在调用print时,这些多进程之类的程序会把print里的字符缓冲空间覆写掉,所以需要一把锁,锁住这个缓冲区,需要建立一个多进程消息队列(log_queue)和多进程锁(log_lock),这两个东西同样可以用在多线程和多协程中,具体的使用方式如下:
def main(spath, dpath):
starttime = time.time()
# 创建一个队列
log_queue = multiprocessing.Manager().Queue()
log_lock = multiprocessing.Manager().Lock() # 使用Manager的Lock以兼容多进程、多线程、多协程
# 启动日志处理线程
log_thread = multiprocessing.Process(target=log_worker, args=(log_queue, log_lock))
log_thread.start()
# 你的代码可以写在这里
# 这个区域的代码里都能使用这个put_log_safe函数彩色输出消息
log_queue.put(None) # 发送结束信号给日志线程
log_thread.join() # 等待日志线程结束这个colorama库支持多种文本颜色输出,包括字体颜色、字体背景颜色等,有兴趣的朋友可以研究下,本人测试在VScode下显示很完美。
1.多进程消息(校验程序)输出:
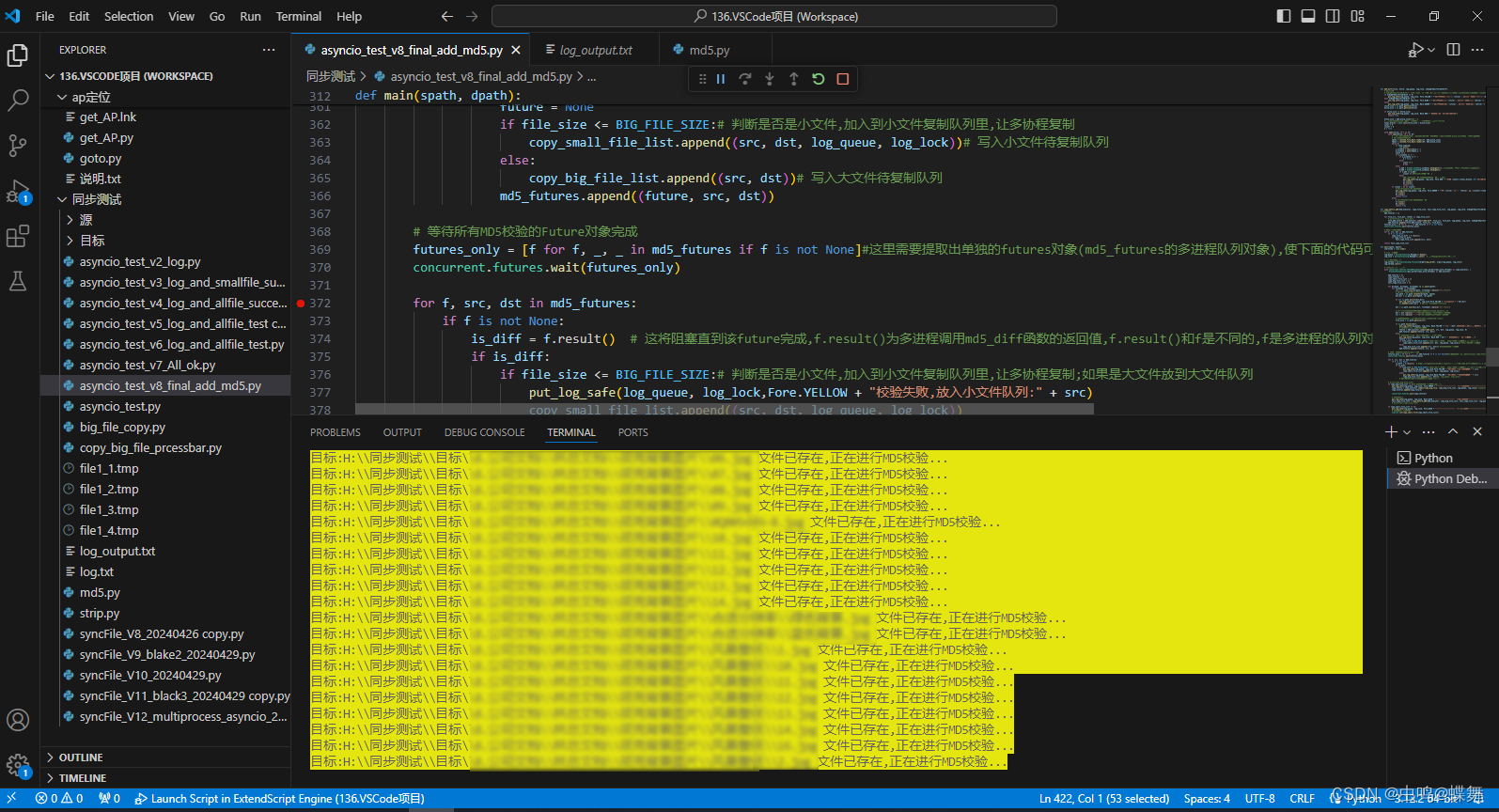
2.多线程消息(大文件复制)输出:
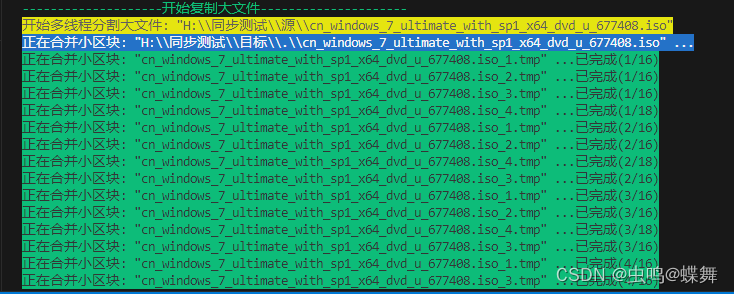 3.多协程消息(大量小文件复制)输出:
3.多协程消息(大量小文件复制)输出:

四、最后说一下关于md5校验,因为是之前版本的就有的函数,我就不做过多说明,还是沿用之前的分小区块读取校验的策略,防止因为过大文件读取导致物理内存溢出的问题,更新的功能是加入了blake3校验方式,是速度较快的新版哈希加密算法,见如下GPT简介:
BLAKE3 是一种加密哈希函数,它基于早期的 BLAKE2 算法,并融合了一些其他设计元素,
特别是来自于“Merkle tree”的概念。BLAKE3 主要目标是提供极高的性能和多功能性,同
时保持了加密安全性。它由 Jack O'Connor, Samuel Neves, Jean-Philippe Aumasson,
和 Zooko Wilcox-O'Hearn 共同设计,并在 2020 年正式发布。
主要特性
高性能:BLAKE3 显著优于其他流行的加密哈希函数(如 SHA-256, SHA-3, 和 BLAKE2)
在速度上,尤其在支持 SIMD 指令集的现代处理器上。这得益于它的并行化设计,可以在
多核处理器上实现线性的速度提升。
并行计算:BLAKE3 的设计自然支持并行处理,使得它在多核心系统上能够高效地处理大量
数据。
多功能性:
除了基本的哈希功能外,BLAKE3 还可以用作密钥派生函数(KDF)、伪随机数生
成器(PRNG)、消息认证码(MAC)等。
简化的API:BLAKE3 提供了一个简洁的 API,使得它在多种场景下都容易使用。
设计和结构
BLAKE3 的哈希函数是基于 Merkle tree 的结构设计的。这意味着数据被分割成多个块,
每个块独立哈希,然后这些哈希值再递归地组合起来,最终形成一个单一的哈希值。这种
结构不仅支持数据的并行处理,也使得可以在不重新计算整个文件的情况下快速验证数据块。
安全性
BLAKE3 的设计继承了 BLAKE2 的安全性,后者已经被证明是非常安全的,并且在密码学社
区中得到了广泛的接受。同时,BLAKE3 进行了一些设计上的调整,以提高其对未来潜在攻
击的抵抗力。
应用场景
BLAKE3 由于其高效的性能和广泛的功能性,非常适合用在需要处理大量数据的场景,例如
文件存储、数据库管理、网络通信等。同时,它的密钥派生和认证功能也使得它可以被用于
加密和安全验证场景。
总之,BLAKE3 是一种现代、高效、多用途的加密哈希算法,适用于多种计算密集型应用,
提供了极高的性能和良好的安全性。安装方式如下:
pip install blake3好了,代码我分析完了,我想看过的朋友应该都有一定收获吧!
所有完整代码如下:
import asyncio
import aiofiles
import concurrent.futures
from concurrent.futures import ProcessPoolExecutor
import os
import time
import math
import blake3
import sys
from colorama import init, Fore, Back, Style
import multiprocessing
import threading
from multiprocessing import Lock
max_work_threads = 30
md5_block_size = 1024 * 1
BIG_FILE_SIZE = 50 * 1024 * 1024 # 50MB(大文件复制区块大小)
stop_copying = False
init(autoreset=True)
# ======================多进程输出Log函数开始==========================
def put_log_safe(log_queue, log_lock, message):
# 函数作用:输入消息队列
# 把带有进程锁的入栈消息的功能封装在这个函数中,方便程序运行时,随时存取消息队列用
# 注意:log_queue队列是多进程消息队列,不是多线程消息队列,因为我的main函数中定义有多进程代码,导致使用多线程消息队列时,并不能输出消息队列,
# 但是使用multiprocessing.Manager().Queue()定义的多进程消息队列,可以很好的运行在多进程和多线程代码中传输消息
"""
安全地向日志队列添加一条消息。
Args:
log_queue (multiprocessing.Queue): 被用来添加日志的队列。
log_lock (multiprocessing.Lock): 控制队列访问的锁。
message (str): 要添加到日志队列的消息。
"""
log_lock.acquire()
try:
log_queue.put(message)
finally:
log_lock.release()
def log_worker(log_queue, print_lock):
# 输出消息队列到消息窗口,并记录到log_output.txt文件中
with open("log_output.txt", "a", encoding="utf-8") as f:
while True:
log_entry = log_queue.get()
if log_entry is None: # 接收到结束信号:收到结束信号,停止输出消息
f.close()
break
if log_entry.strip():
print_lock.acquire() # 获取打印锁:加锁是防止输出消息时,多线程引起的随机空行的问题
try:
print(log_entry,flush=True)
if log_entry[0] == "":
log_entry = log_entry[5:]
f.write(log_entry + "\n")#.replace("","").replace("[","").replace("41","").replace("43","").replace("42","").replace("31","").replace("32","").replace("33","").replace("34","") + "\n") # 去除程序中print输出杂乱的颜色的代码(如:Back.GREEN),使输入到日志文件中的消息更清楚
f.flush() # 确保即时写入文件
finally:
print_lock.release() # 释放打印锁
f.close()
# ======================多进程输出Log函数结束====================================
# ======================异步复制小文件函数开始===================================
async def copy_small_file_async(src, dst, log_queue, log_lock):
# 使用多协程复制单个小文件
async with aiofiles.open(src, 'rb') as fs:
filedata = await fs.read()
async with aiofiles.open(dst, 'wb') as fd:
await fd.write(filedata)
put_log_safe(log_queue, log_lock, Back.GREEN + "已复制小文件:" + src)
async def copy_small_file(file_tasks):
tasks = [copy_small_file_async(src, dst, log_queue, log_lock) for src, dst, log_queue, log_lock in file_tasks]
await asyncio.gather(*tasks)
# ======================异步复制小文件函数结束===================================
# ======================单个大文件处理代码开始====================================
def copy_chunk(src, dst, start, size):
# 单个块复制函数(大文件分割后的单个块复制)
with open(src, 'rb') as fs:
fs.seek(start)
chunk = fs.read(size)
with open(dst, 'wb') as fd:
fd.write(chunk)
def create_chunks_and_copy(src, dst_prefix, chunk_size, log_queue, log_lock):
# 创建并复制块到临时文件
# 函数作用:先通过获得源文件的大小,计算出每个块(50MB 代码开头处的公共变量BIG_FILE_SIZE定义)的起始大小,如第一个为FILE_00000.tmp
# FILE就是目标文件的名称,根据父函数决定,这里不是简化表示以下,关键是之后的_00000.tmp,表示第一个文件的起始地址是0,那么依此推理,
# 第二个文件就是50*1024*1024(50MB)=52428800,所以第二个文件的命名就是FILE_52428800.tmp,这样命名的好处是,拼接多区块时,可以直接
# 把每个文件的拼接起始地址,传递给拼接函数merge_files.
file_size = os.path.getsize(src)
chunks = [(i, dst_prefix + f'_{i:05d}.tmp') for i in range(0, file_size, chunk_size)]
# 此代码返回50mb分割后的区块名称数组chunks,并用分割的起始字节命名(如:FILE_00000.tmp、FILE_52428800.tmp....)
put_log_safe(log_queue, log_lock, Back.YELLOW + f'开始多线程分割大文件: "{src}"')
with concurrent.futures.ThreadPoolExecutor() as executor:
# 创建多线程运行上面的copy_chunk单个块复制子函数
futures = [executor.submit(copy_chunk, src, dst, start, chunk_size)
for start, dst in chunks]
concurrent.futures.wait(futures)
return [dst for start, dst in chunks]
def merge_files(files, dst_filename, dst, log_queue, log_lock, isBigSmallBlock, progress_dict):
# 合并多个文件到一个目标文件
# 拼接区块函数:两种调用方式,通过isBigSmallBlock布尔变量控制,
# 拼接方式:
# 1. isBigSmallBlock=False 小区块合并,把FILE_00000.tmp、FILE_52428800.tmp....这样的小区块通过多线程
# 合并成FILE_1.tmp、FILE_2.tmp、FILE_3.tmp、FILE_4.tmp,为什么是4个?因为是由下面的父函数partitioned_merge
# 中的num_mergers=4定义了分割线程数,这个可以根据需求修改,如是固态硬盘,考虑到磁盘利用率,不需要分太多线程,因为线程越多,
# 每个线程读取的文件大小分配的越小,导致磁盘利用率上不去。
# 2. isBigSmallBlock=Ture 大区块合并,把上面生成的FILE_1.tmp、FILE_2.tmp、FILE_3.tmp、FILE_4.tmp合并成完整的FILE.tmp
dstPath = os.path.dirname(dst)
fileBasePath = dstPath + "\\" if isBigSmallBlock else ""
with open(dstPath + "\\" + dst_filename, 'wb') as fd:
for idx, file in enumerate(files):
with open(fileBasePath + file, 'rb') as f:
data = f.read()
fd.write(data)
# 更新进度
# 此处的progress_dict由以下两句创建manager = multiprocessing.Manager() progress_dict = manager.dict()
# 这个多进程字典的作用是,在这个多线程拼接子函数中更新4个拼接线程单独的文件拼接进度,如下这样的:
# 正在合并小区块: "5.avi_1.tmp" ...已完成(1/3)
# 正在合并小区块: "5.avi_2.tmp" ...已完成(1/3)
# 正在合并小区块: "5.avi_3.tmp" ...已完成(1/3)
# 正在合并小区块: "5.avi_4.tmp" ...已完成(1/3)
# 正在合并小区块: "5.avi_1.tmp" ...已完成(2/3)
# 正在合并小区块: "5.avi_2.tmp" ...已完成(2/3)
# 正在合并小区块: "5.avi_3.tmp" ...已完成(2/3)
# 正在合并小区块: "5.avi_4.tmp" ...已完成(2/3)
# 正在合并小区块: "5.avi_1.tmp" ...已完成(3/3)
# 正在合并小区块: "5.avi_2.tmp" ...已完成(3/3)
# 正在合并小区块: "5.avi_3.tmp" ...已完成(3/3)
# 正在合并小区块: "5.avi_4.tmp" ...已完成(3/3)
# 如上可以看到"5.avi_1.tmp"之后的已完成数一共有3个,分别是(1/3)、(2/3)、(3/3),这只是上面说的4个分割线程数中的一个线程,它
# 的工作就是FILE_00000.tmp、FILE_52428800.tmp....这样的所有小区块,分4份,用4个线程,分开合并成"5.avi_1.tmp" 、"5.avi_2.tmp"、
# "5.avi_3.tmp" 、 "5.avi_4.tmp"这4个大区块。而这个progress_dict就是存储其中合并"5.avi_1.tmp"这个线程的当前进度的字典变量
# 也就是如下中的1、2、3序列:
# "5.avi_1.tmp" ...已完成(1/3)
# "5.avi_1.tmp" ...已完成(2/3)
# "5.avi_1.tmp" ...已完成(3/3)
progress_dict[dst_filename] = idx + 1 # idx+1 表示已完成的文件数
# 计算进度条信息
progress_info = f"{progress_dict[dst_filename]}/{len(files)}"
logForBlockTxt = "大区块" if isBigSmallBlock else "小区块" #根据isBigSmallBlock变量来输出到底是大区块消息,还是小区块消息
logColor = Back.BLUE if isBigSmallBlock else Back.GREEN
put_log_safe(log_queue, log_lock, logColor + f'正在合并{logForBlockTxt}: "{dst_filename}" ...已完成({progress_info})')
os.remove(fileBasePath + file) # 合并后删除临时文件
def partitioned_merge(src, dst, temp_files, log_queue, log_lock, progress_dict, num_mergers=4):
# 小分区合并文件父函数
# 此函数控制了上面的合并函数merge_files,并可以修改合并的线程数
filename = os.path.basename(src)
if len(temp_files) < 4:#排除分小区块后,小区块总数小于4个,不能分4线程的问题.
partition_size = len(temp_files)
else:#以下是正常的大于4个小区块,分4线程大量复制
partition_size = len(temp_files) // num_mergers
partitions = [temp_files[i:i + partition_size] for i in range(0, len(temp_files), partition_size)]
if len(partitions) > num_mergers:#如果文件大小不能被4线程整除,最后的部分的处理情况
last = partitions.pop()
partitions[-1].extend(last)
intermediate_files = []
total_size = sum(os.path.getsize(f) for f in temp_files)
put_log_safe(log_queue, log_lock, Back.BLUE + f'正在合并小区块: "{dst}" ...')
with concurrent.futures.ThreadPoolExecutor() as executor: #创建多线程调用合并函数merge_files
futures = []
for i, partition in enumerate(partitions):
intermediate_file = f'{filename}_{i+1}.tmp'#根据设定的分割线程数,建立"5.avi_1.tmp" 、"5.avi_2.tmp"、"5.avi_3.tmp" 、 "5.avi_4.tmp"这样的大分区块
isBigSmallBlock = False
future = executor.submit(merge_files, partition, intermediate_file, dst, log_queue, log_lock, isBigSmallBlock, progress_dict)
futures.append(future)
intermediate_files.append(intermediate_file)
concurrent.futures.wait(futures)
return intermediate_files#返回这些大分区块的名称,方便之后合并.
def final_merge(src, dst, intermediate_files, log_queue, log_lock, progress_dict):
# 最终合并所有分区文件到一个大文件,并重命名,显示进度
final_tmp = os.path.basename(dst + '.tmp')
dstPath = os.path.dirname(dst)
total_size = sum(os.path.getsize(dstPath + "\\" + f) for f in intermediate_files)
put_log_safe(log_queue, log_lock, Back.BLUE + f'开始合并大区块: "{dst}" ...')
isBigSmallBlock = True
merge_files(intermediate_files, final_tmp, dst, log_queue, log_lock, isBigSmallBlock, progress_dict)
os.rename(dstPath + "\\" + final_tmp,dst)
def copy_big_file(copy_big_file_list, log_queue, log_lock):
# 复制大文件时的主函数,此函数的作用是,把copy_big_file_list传入的包含源文件和对象文件目录解析后,循环多线程分割合并
for src, dst in copy_big_file_list:
print(f'大文件复制: 源: "{src}" , 目标:"{dst}" 开始...')
# Manager字典,用于跟踪文件合并进度
manager = multiprocessing.Manager()
progress_dict = manager.dict()
temp_files = create_chunks_and_copy(src, dst, BIG_FILE_SIZE, log_queue, log_lock)
intermediate_files = partitioned_merge(src, dst, temp_files, log_queue, log_lock, progress_dict)
final_merge(src, dst, intermediate_files, log_queue, log_lock, progress_dict)
put_log_safe(log_queue, log_lock, Back.BLUE + f'源:"{src}" 到 目标:"{dst}" 复制成功!')
# # 检查MD5
# src, dst, is_diff = md5_diff(src, dst, log_queue, log_lock, 2)
# if not is_diff:
# put_log_safe(log_queue, log_lock,Back.GREEN + f"完成大文件复制: {src} -> {dst}")
# return True
# else:
# put_log_safe(log_queue, log_lock,Back.RED + f"复制失败, MD5校验不通过: {src}")
# return False
# =====================单个大文件处理代码结束======================
def chunked_file_Next_reader(file,block_size=md5_block_size):
#分小段读取校验的文件
while True:
yield file.read(block_size)
def md5_diff(sfile, dfile, log_queue, log_lock, IsBigOrSmallFileOrDiff):
# 校验函数
# IsBigOrSmallFileOrDiff是一个输出信息开关 设置为0=为未复制前md5比较;1=小文件复制后比较md5;2=大文件复制后比较md5
if IsBigOrSmallFileOrDiff == 0:
put_log_safe(log_queue, log_lock, Fore.YELLOW + f"校验源文件(复制前):'{sfile}', 校验目标文件(复制前):'{dfile}'")
elif IsBigOrSmallFileOrDiff == 1:
put_log_safe(log_queue, log_lock, Fore.BLUE + f"校验源文件(小):'{sfile}', 校验目标文件(小):'{dfile}'")
else:
put_log_safe(log_queue, log_lock, Back.GREEN + f"校验源文件(大):'{sfile}', 校验目标文件(大):'{dfile}'")
sfile_size = os.path.getsize(sfile)
dfile_size = os.path.getsize(dfile)
if sfile_size != dfile_size:
put_log_safe(log_queue, log_lock, Back.RED + "文件大小不一致,校验失败。")
return True
block_size = md5_block_size#1024 * 8
# 使用向上取整确保即使最后一个区块小于标准区块大小也能被计算在内
total_blocks = math.ceil(sfile_size / block_size)
count = 0
scount = 0
k = True
with open(sfile,'rb') as sf:
with open(dfile,'rb') as df:
# 为防止校验的文件太大,而引起的读取内存过大的问题,每次只读取md5_block_size(代码开头的公共变量)
# 大小的文件内容对比
sdata = chunked_file_Next_reader(sf, md5_block_size)
fdata = chunked_file_Next_reader(df, md5_block_size)
while k:
if stop_copying:
sys.exit()
s_nxtdata = next(sdata,b'')
d_nxtdata = next(fdata,b'')
count += 1
if s_nxtdata == b'':
if d_nxtdata == b'':
k = False
else:
count += 1
break
else:
s_md5 = blake3.blake3(s_nxtdata).hexdigest()#使用blake3的加密方式,分段比较每段的hash值
d_md5 = blake3.blake3(d_nxtdata).hexdigest()
if s_md5 == d_md5:
scount += 1#分段校验成功计数加1
else:
#如果此分段不一样,直接判断文件不一样,退出校验
put_log_safe(log_queue, log_lock, Fore.RED + f"区块 {count}/{total_blocks:.0f} 校验失败。s_md5: {s_md5}, d_md5: {d_md5}")
sf.close()
df.close()
return True
if (count - 1) == scount:
# 全部分段校验完毕,判断文件一样
put_log_safe(log_queue, log_lock, Fore.GREEN + f"源:'{sfile}' 目标: '{dfile}',共 ({scount}/{total_blocks})个块 校验成功!")
sf.close()
df.close()
return False
else:
# 全部分段校验完毕,判断文件不一样
sf.close()
df.close()
return True
def copy_before_md5(md5_executor, copy_file_list, fail_copy_file_list, log_queue, log_lock, IsBigOrSmallFileOrDiff):
# 大文件校验
md5_futures = []
for file_src, file_dst, *other in copy_file_list:
# print(file_src, file_dst)
file_md5_future = md5_executor.submit(md5_diff, file_src, file_dst, log_queue, log_lock, IsBigOrSmallFileOrDiff)
md5_futures.append((file_md5_future, file_src, file_dst))
futures_only = [f for f, _, _ in md5_futures if f is not None]
concurrent.futures.wait(futures_only)
# 存入复制失败列表
for f, src, dst in md5_futures:
if f is not None:
copy_file_is_diff = f.result()
if copy_file_is_diff:
fail_copy_file_list.append((src, dst))
return fail_copy_file_list
def main(spath, dpath):
starttime = time.time()
# 创建一个队列
log_queue = multiprocessing.Manager().Queue()
log_lock = multiprocessing.Manager().Lock() # 使用Manager的Lock以兼容多进程
# 启动日志处理线程
log_thread = multiprocessing.Process(target=log_worker, args=(log_queue, log_lock))
log_thread.start()
# 同时创建进程池和线程池
with concurrent.futures.ThreadPoolExecutor(max_workers=max_work_threads) as copy_executor, \
ProcessPoolExecutor(max_workers=max_work_threads) as md5_executor:
md5_futures = []
copy_futures = []
copy_small_file_list = []
copy_big_file_list = []
fail_copy_file_list = []
for dirpath, dirnames, filenames in os.walk(spath):
for filename in filenames:
src = os.path.join(dirpath, filename).replace("\\","\\\\")
# 构建目标文件路径,保留相对目录结构
rel_path = os.path.relpath(dirpath, spath)
dst_dir = os.path.join(dpath, rel_path)
if not os.path.exists(dst_dir):
put_log_safe(log_queue, log_lock,Fore.YELLOW + "创建新目录:" + dst_dir)
os.makedirs(dst_dir) # 如果目标目录不存在,则创建
dst = os.path.join(dst_dir, filename).replace("\\","\\\\")
# 防止非法字符引起的写入失败,如还有其他特例,请读者自行添加
dst = dst.replace('"',"")#替换掉拖到目标目录字符串中的引号,
src = src.replace('"',"")#替换掉拖到源目录字符串中的引号
# 获得源文件大小,方便之后根据大小选择不同的复制方式
file_size = os.path.getsize(src)
if os.path.exists(dst):
put_log_safe(log_queue, log_lock, Back.YELLOW + f"目标:{dst} 文件已存在,正在进行MD5校验...")
# 文件存在,添加到MD5校验队列
future = md5_executor.submit(md5_diff, src, dst, log_queue, log_lock, 0)
md5_futures.append((future, src, dst))
else:
# 文件不存在,跳过校验,写入md5多线程返回数组
put_log_safe(log_queue, log_lock, Back.RED + dst + " 文件不存在!加入复制队列...")
future = None
if file_size <= BIG_FILE_SIZE:# 判断是否是小文件,加入到小文件复制队列里,让多协程复制
copy_small_file_list.append((src, dst, log_queue, log_lock))# 写入小文件待复制队列
else:
copy_big_file_list.append((src, dst))# 写入大文件待复制队列
md5_futures.append((future, src, dst))
# 等待所有MD5校验的Future对象完成
futures_only = [f for f, _, _ in md5_futures if f is not None]#这里需要提取出单独的futures对象(md5_futures的多进程队列对象),使下面的代码可以等待所有文件校验完成后,再执行大小文件的分步复制操作.
concurrent.futures.wait(futures_only)
for f, src, dst in md5_futures:
if f is not None:
is_diff = f.result() # 这将阻塞直到该future完成,f.result()为多进程调用md5_diff函数的返回值,f.result()和f是不同的,f是多进程的队列对象,而f.result()是f对象调用的md5_diff函数返回值
if is_diff:
if file_size <= BIG_FILE_SIZE:# 判断是否是小文件,加入到小文件复制队列里,让多协程复制;如果是大文件放到大文件队列
put_log_safe(log_queue, log_lock,Fore.YELLOW + "校验失败,放入小文件队列:" + src)
copy_small_file_list.append((src, dst, log_queue, log_lock))
else:
put_log_safe(log_queue, log_lock,Back.YELLOW + "校验失败,放入大文件队列:" + src)
copy_big_file_list.append((src, dst))#, log_queue, log_lock))
# 如果MD5校验失败,即文件不同,提交复制任务
# print(copy_big_file_list)
if copy_big_file_list != []:# 判断大文件复制列表是否为空\
put_log_safe(log_queue, log_lock, Fore.GREEN + "--------------------开始复制大文件---------------------")
copy_future = copy_executor.submit(copy_big_file, copy_big_file_list, log_queue, log_lock)# 我已经把copy_big_file写入了复制后校验的功能,所以此函数返回后就校验完成了.
copy_futures.append(copy_future)
concurrent.futures.wait(copy_futures)
# 大文件校验
put_log_safe(log_queue, log_lock, Back.BLUE + "--------------------开始校验大文件---------------------")
fail_copy_file_list = copy_before_md5(md5_executor, copy_big_file_list, fail_copy_file_list, log_queue, log_lock, 2)
# print(fail_copy_file_list)
if copy_small_file_list != []:
put_log_safe(log_queue, log_lock, Fore.BLUE + "--------------------开始复制小文件---------------------")
# 处理需要复制的文件
asyncio.run(copy_small_file(copy_small_file_list))
# 小文件校验
put_log_safe(log_queue, log_lock, Back.BLUE + "--------------------开始校验小文件---------------------")
fail_copy_file_list = copy_before_md5(md5_executor, copy_small_file_list, fail_copy_file_list, log_queue, log_lock, 1)
# 输出所有的复制失败文件
if fail_copy_file_list is None:
put_log_safe(log_queue, log_lock, Fore.GREEN + "复制文件 全部校验通过!")
else:
#print(fail_copy_file_list)
for fail_file_src,fail_file_dst in fail_copy_file_list:
put_log_safe(log_queue, log_lock, Fore.RED + f"源文件:{fail_file_src} 复制到 目标文件:{fail_file_dst} 校验不通过!")
endtime = time.time()
runtime = "已全部完成! 共用时:" + str((endtime - starttime) / 60) + "分钟!"
log_queue.put(runtime)
log_queue.put(None) # 发送结束信号给日志线程
log_thread.join() # 等待日志线程结束
if __name__ == "__main__":
spath = "H:\\同步测试\\源"# 这里修改成你要复制的原文件目录
dpath = "H:\\同步测试\\目标"# 这里修改成你要复制的目标文件目录
main(spath, dpath)运行脚本前,请确认所有库已安装,不确认是否安装过,请在VScode或python环境下,运行如下pip命令安装库:
pip install aiofiles blake3 colorama使用脚本的方式也很简单:
修改最后的代码,修改成你需要的目录即可,修改spath(原目录)和dpath(复制到的目录)变量的值即可。
spath = "H:\\同步测试\\源"# 这里修改成你要复制的原文件目录
dpath = "H:\\同步测试\\目标"# 这里修改成你要复制的目标文件目录谢谢大家的观看,下次见!