线性回归:揭秘房价预测的黑科技
- 一、引言
- 二、线性回归概述
- 三、房价预测实例
- 数据收集与预处理
- 特征选择与建模
- 模型评估与优化
- 四、总结与展望
一、引言
在数字化时代,数据科学已成为推动社会进步的重要引擎。其中,线性回归作为数据科学中的基础算法之一,因其简单易懂、效果显著而备受青睐。今天,我们就来探讨一下线性回归在房价预测中的应用,看看这一黑科技是如何为我们揭示房价背后的奥秘的。
二、线性回归概述
线性回归是一种通过拟合自变量(特征)与因变量(目标)之间的线性关系,来预测目标变量值的统计方法。在房价预测中,自变量可能包括房屋的面积、卧室数量、地理位置等,而因变量则是房价。通过收集大量数据,我们可以使用线性回归算法来建立自变量与房价之间的数学模型,进而预测新的房屋价格。
三、房价预测实例
为了更好地理解线性回归在房价预测中的应用,我们将通过一个具体的实例来展开说明。
数据收集与预处理
首先,我们需要收集一定数量的房屋数据,包括房屋的面积、卧室数量、地理位置等信息以及对应的房价。在收集数据时,我们需要注意数据的来源和质量,确保数据的真实性和可靠性。
接下来,我们需要对数据进行预处理。这包括数据清洗(去除缺失值和异常值)、数据转换(如将分类变量转换为数值变量)以及数据标准化(使不同特征之间的量纲统一)等步骤。通过预处理,我们可以提高数据的质量和模型的准确性。
特征选择与建模
在特征选择阶段,我们需要根据业务需求和数据特点,选择对房价有显著影响的特征作为自变量。例如,在房价预测中,房屋的面积和卧室数量通常被认为是影响房价的重要因素。
然后,我们可以使用线性回归算法来建立自变量与房价之间的数学模型。在Python中,我们可以使用scikit-learn库中的LinearRegression类来实现线性回归建模。以下是一个简单的代码示例:
python
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import pandas as pd
# 加载数据(假设数据已保存在CSV文件中)
data = pd.read_csv('house_data.csv')
# 选择特征和目标变量
X = data[['area', 'bedrooms', 'location']] # 特征变量(房屋面积、卧室数量、地理位置)
y = data['price'] # 目标变量(房价)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集房价
y_pred = model.predict(X_test)
# 计算预测误差
mse = mean_squared_error(y_test, y_pred)
print(f'均方误差(MSE): {mse}')
在上述代码中,我们首先加载了包含房屋数据的CSV文件,并选择了特征变量和目标变量。然后,我们将数据集划分为训练集和测试集,其中测试集占20%。接下来,我们创建了一个LinearRegression对象作为线性回归模型,并使用训练集数据对模型进行训练。最后,我们使用训练好的模型对测试集进行预测,并计算了预测结果的均方误差(MSE)。
模型评估与优化
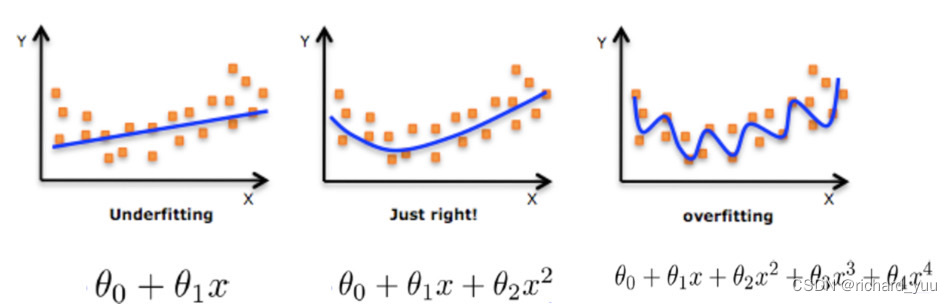
在得到预测结果后,我们需要对模型进行评估和优化。评估模型的方法有很多种,如计算预测误差、绘制残差图等。通过评估,我们可以了解模型的性能表现,发现模型存在的问题,并针对性地进行优化。
在优化模型时,我们可以考虑添加更多的特征、改变特征的选择方式、调整模型的参数等方法。通过不断优化,我们可以提高模型的预测准确性,使其更好地适应实际业务需求。
四、总结与展望
通过本文的介绍,我们了解了线性回归在房价预测中的应用。通过收集数据、预处理数据、选择特征、建模、评估与优化等步骤,我们可以建立一个准确的房价预测模型。这一模型不仅可以为我们提供有价值的房价预测信息,还可以为房地产开发商、投资者等提供决策支持。
未来,随着数据科学和人工智能技术的不断发展,线性回归等算法将在更多领域得到应用。我们有理由相信,在不久的将来,这些黑科技将为我们揭示更多隐藏在数据背后的奥秘。



![[muduo网络库]——muduo库三大核心组件之 Poller/EpollPoller类(剖析muduo网络库核心部分、设计思想)](https://img-blog.csdnimg.cn/direct/c835e66dd7f3493e94b40369c641205e.png)