系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
AI大模型探索之路-训练篇14:大语言模型Transformer库-Trainer组件实践
AI大模型探索之路-训练篇15:大语言模型预训练之全量参数微调
AI大模型探索之路-训练篇16:大语言模型预训练-微调技术之LoRA
AI大模型探索之路-训练篇17:大语言模型预训练-微调技术之QLoRA
AI大模型探索之路-训练篇18:大语言模型预训练-微调技术之Prompt Tuning
AI大模型探索之路-训练篇19:大语言模型预训练-微调技术之Prefix Tuning
目录
- 系列篇章💥
- 前言
- 一、各大语言模型对比
- 1、因果语言模型
- 2、条件生成模型
- 3、序列分类模型
- 4、文生图模型
- 5、图片分类模型
- 6、图生文模型
- 二、LoRA技术对比
- 1)优点
- 2)缺点
- 三、P-Tuning V2技术对比
- 1)优点
- 2)缺点
- 总结
前言
随着人工智能的迅猛发展,自然语言处理(NLP)在近年来取得了显著的进展。大型语言模型(LLMs)在多种NLP任务中展现了卓越的性能,这得益于它们在大规模文本数据集上进行的预训练和随后的微调过程。这些模型不仅能够理解和生成自然语言,还能在特定任务上通过微调达到令人印象深刻的精度和鲁棒性。本文将深入探讨几种重要的预训练模型,并细致比较目前广泛使用的两种先进微调技术——LoRA和P-Tuning V2。我们将从专业角度分析各自的优势和局限性,并提供一个全景视角,以助开发人员和实践者在选择适合其特定需求的微调策略时做出明智的决策。
一、各大语言模型对比
开发人员可以通过Github和Hugging Face平台访问和了解各种由PEFT支持的预训练语言模型。
通过Github平台,开发者可以访问到PEFT的源代码,深入了解其内部工作原理,并参与到模型优化和改进的过程中。此外,Hugging
Face提供的用户友好界面,不仅使得获取由PEFT支持的预训练语言模型变得异常简单,还提供了丰富的文档和教程,帮助开发者快速上手并应用这些模型。
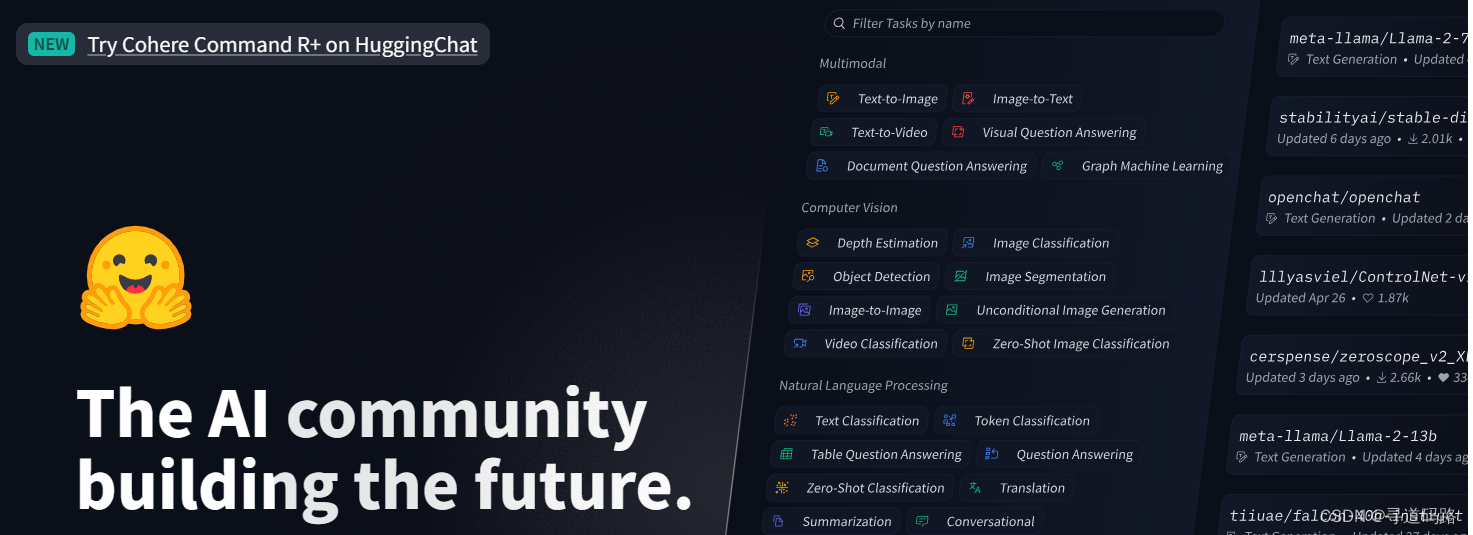
在Hugging Face平台上,开发者可以轻松地浏览各种由PEFT支持的预训练模型,包括它们在不同的自然语言理解任务上的表现。这些模型覆盖了从通用语言理解到特定领域任务的广泛应用,并且通常包含了详细的模型规格、预训练数据来源以及优化策略的描述。
1、因果语言模型
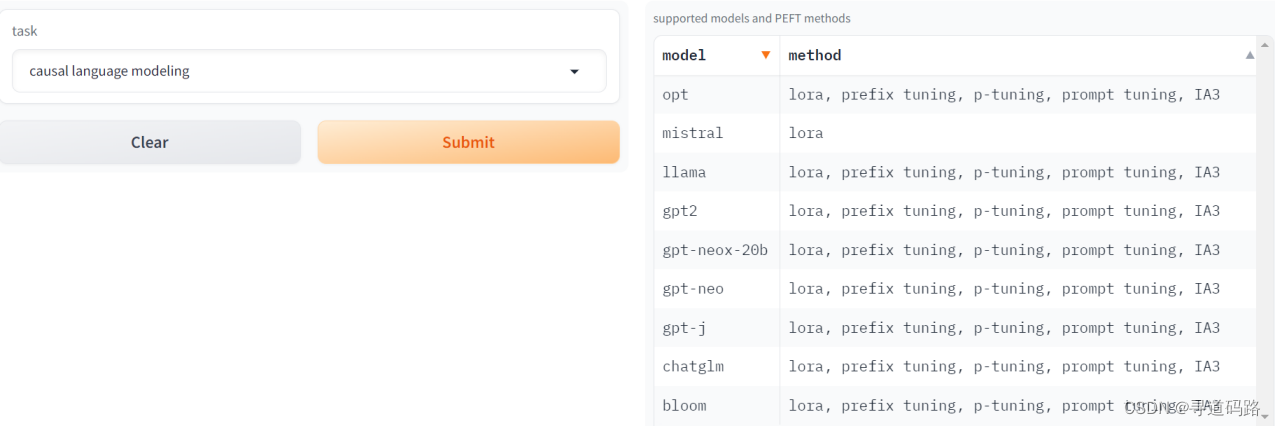
Causal Language Modeling(因果语言模型)主要的任务是根据当前的上下文预测下一个单词。它是一种生成模型,能够生成类似人类的文本。因果语言模型在处理序列数据时,会考虑前面的上下文信息,但是不会看到未来的信息。
例如,给定一句话的前半部分 "The quick brown fox jumps over ...", 因果语言模型的任务是预测接下来可能出现的词,比如 "the"。这个预测是基于给定上下文的条件概率分布来进行的。
这种模型在很多应用中都非常有用,比如机器翻译、语音识别和文本生成等。
2、条件生成模型

Conditional Generation(条件生成)的模型,主要是在给定一定条件或上下文的情况下,生成特定的输出。在自然语言处理中,条件生成模型常常用来生成符合特定条件的文本。
以**机器翻译**为例,给定一个源语言(例如英语)的句子,条件生成模型的任务就是生成目标语言(例如中文)的句子。这里的“条件” 就是源语言的句子,而生成的目标就是目标语言的句子。 又如**文本摘要**任务,给定一个长篇文章,条件生成模型的任务就是生成该文章的摘要。这里的“条件”就是原始的长篇文章,生成的目标就是简短的摘要。
条件生成模型的一个关键特性是它能够根据不同的输入条件生成不同的输出,因此它在许多需要个性化输出的场景中有广泛的应用,如推荐系统、个性化新闻生成等。
3、序列分类模型
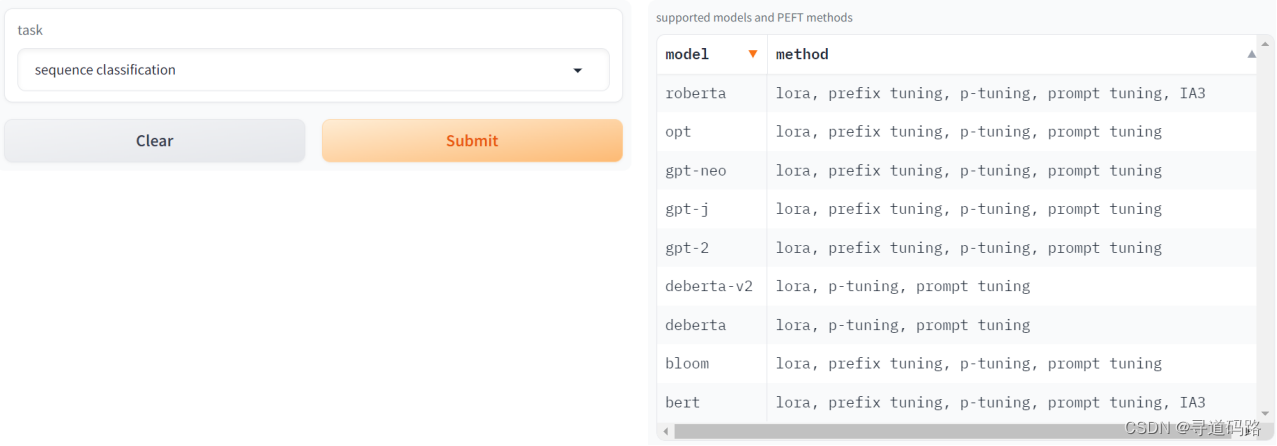
Sequence Classification(序列分类)模型的主要任务是对整个序列进行分类。在这个上下文中,序列可以是一系列的单词(文本数据)、声音信号、时间序列数据等。模型的目标是将输入的序列映射到预定义的类别标签上。
一个典型的例子是情感分析任务。在这个任务中,给定一个文本序列(如一句话或一段评论),序列分类模型会判断这段文本的情感倾向,比如将其分类为“正面”、“负面”或“中立”。这里的序列就是文本中的单词序列,而分类的目标是情感倾向的类别。
其他序列分类的例子还包括:
1)垃圾邮件检测:将邮件序列分类为“垃圾邮件”或“非垃圾邮件”。
2)文本主题分类:将新闻文章、科学论文或其他文档分类到预设的主题类别,
如“体育”、“政治”、“科技”等。
3)蛋白质功能分类:将蛋白质序列根据其生物学功能分类到不同的功能类别
中。
4、文生图模型

文本到图像(Text-to-Image)模型能够将文字描述转化为相应的图像。在这类模型中,一个预训练好的语言模型被用来理解文本内容,并提取关键信息。然后,这些信息被传递至一个图像生成网络,该网络负责根据解析出的文本内容合成图像。这种跨模态的能力使得文生图模型在创意设计、游戏开发、在线教育以及提供视觉障碍人士的辅助技术等领域展现出巨大潜力。
5、图片分类模型

图像分类(Image Classification)模型负责将图像归入预定的类别。通常,这涉及到一个复杂的卷积神经网络(CNN),它能够从图像中提取特征,并将这些特征映射到一个或多个类别标签上。图像分类技术已广泛应用于面部识别、物体识别、医学影像分析以及自动驾驶车辆中的环境感知等领域。
6、图生文模型

图像到文本(Image-to-Text)模型旨在描述或解释给定的图像内容。逆向于文生图模型,图生文模型首先通过一个图像识别网络识别和解析图像中的关键元素和场景语境,接着用语言模型生成描述这些元素的文本。这种技术在视觉受损辅助工具、社交媒体图像的自动化标注以及在法律和医疗领域的文档编录中有着至关重要的应用。
二、LoRA技术对比
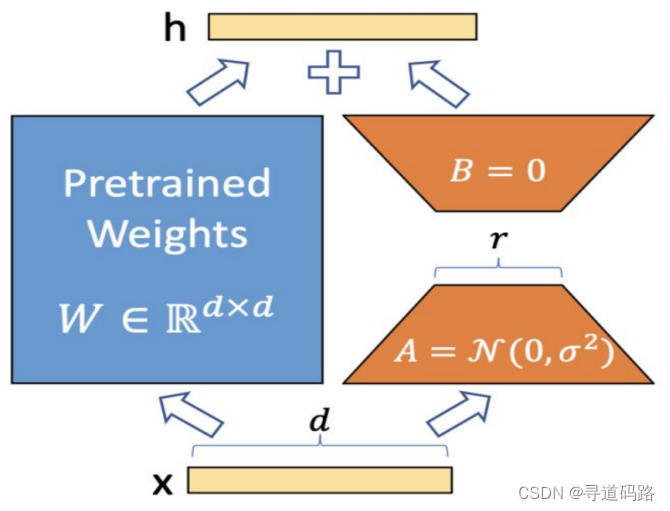
1)优点
LoRA(Low-Rank Adaptation)技术以其对大型语言模型进行高效微调的能力而受到关注。以下是LoRA的几个专业层面的优点:
-
参数化效率:LoRA通过引入低秩分解的矩阵,将原始的密集参数矩阵分解为两个低秩矩阵的乘积。这种方法大幅减少了微调过程中所需优化的参数数量,从而降低了模型的内存占用和训练成本,同时加速了训练过程。这对于硬件资源有限的场景尤其有利。
-
推理时间优化:LoRA允许在不牺牲推理速度的前提下进行微调。它通过将训练时引入的低秩因子与冻结的原始参数矩阵结合,避免了额外的推理延迟,这对于需要实时响应的应用至关重要。
-
通用性和兼容性:LoRA的设计使其能够与多种预训练模型以及各类任务兼容,这意味着它可以应用于不同的NLP场景而无需重大改动。此外,LoRA可以与其他微调技术叠加使用,进一步提升模型性能。
2)缺点
尽管LoRA提供了一种高效的微调方法,但它也有一些局限性:
-
超参数选择:确定最优的矩阵秩是一个挑战,因为它与模型的参数规模、微调数据集的大小和任务类型紧密相关。选择较小的秩可能会限制模型的容量,导致次优的微调效果;而较大的秩可能会增加计算开销并导致过拟合。这通常需要通过实验来平衡和确定。
-
稳定性与鲁棒性:虽然LoRA可以提高模型的适应性,但在某些情况下,低秩结构可能影响模型的稳定性和泛化能力。因此,在关键任务中采用LoRA时,需要仔细评估其对模型鲁棒性的影响。
-
调优复杂度:为了获得最佳性能,开发人员可能需要针对特定任务进行多次实验,以找到最佳的低秩分解策略和超参数设置,这可能增加开发和维护的复杂性。
三、P-Tuning V2技术对比
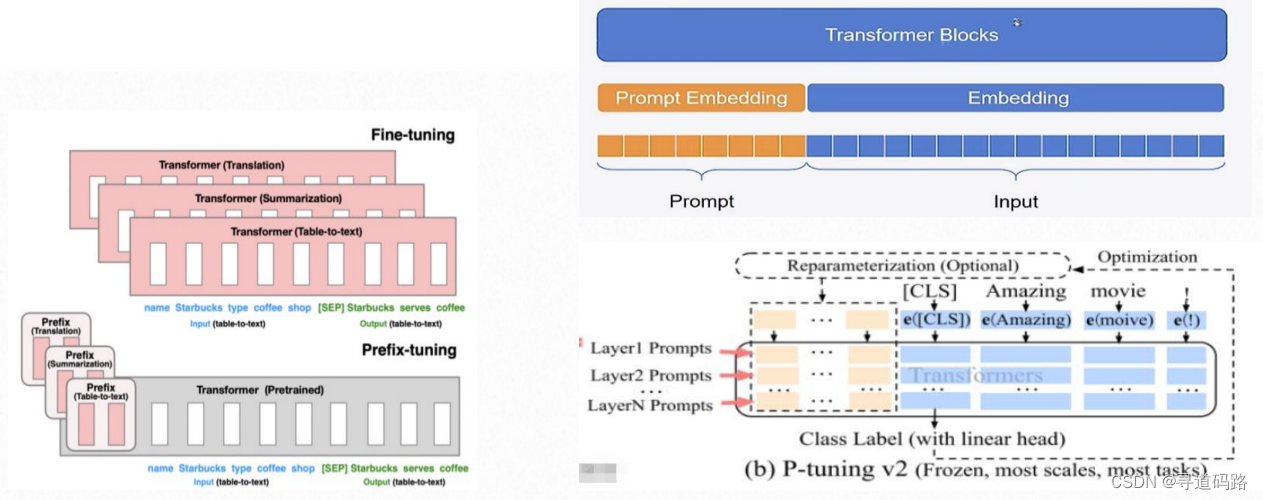
1)优点
P-Tuning V2是一种先进的微调技术,它在P-Tuning的基础上进行了改进,具有以下优点:
-
性能提升:相比于P-Tuning和Prefix-Tuning,P-Tuning V2通过更精细的Prompt设计和调整,实现了更稳定的性能提升。它通过增加Prompt的可学习参数,使模型能够更好地适应微调任务,从而提高了模型的准确性和鲁棒性。
-
灵活性:P-Tuning V2的设计允许在不同任务中灵活地调整Prompt的长度和结构,这为各种规模的模型和任务提供了更多的定制选项。
-
通用性:虽然P-Tuning V2仍然需要考虑不同任务的特点来设计Prompt,但其改进的结构使得它能够适用于更广泛的任务类型,提高了技术的普适性。
2)缺点
尽管P-Tuning V2在多个方面展现了优势,但它仍然面临一些挑战:
-
任务适配:为了达到最佳效果,P-Tuning V2需要针对每个新任务设计合适的Prompt,这可能涉及大量的实验和调整。这一过程对于某些快速变化或特定的任务来说可能是时间和资源上的负担。
-
规模调整:对于不同的模型规模和任务类型,需要精心设计Prompt的长度和结构。这不仅增加了微调的复杂性,也可能影响到模型的扩展性和可迁移性。
-
资源消耗:尽管P-Tuning V2在参数效率上有所提高,但对于大规模模型和数据集,Prompt调整和优化过程仍然可能需要大量的计算资源和时间。
总结
在本文中,我们深入探讨了大型语言模型的预训练和微调技术,特别是LoRA和P-Tuning V2两种先进的参数高效微调方法。通过对比分析,我们发现这些技术在减少计算和存储成本的同时,能够保持或接近全参数微调的性能。此外,我们还提供了实际应用案例,展示了这些技术在具体任务中的应用和效果。
微调技术的选择应基于具体任务的需求、可用资源以及性能目标。LoRA和P-Tuning V2各有优势,适用于不同的场景和需求。随着NLP领域的不断发展,未来可能会出现更多创新的微调技术,为开发者提供更多的选择和可能性。同时,我们也应关注技术的跨领域应用和跨模态学习,以进一步扩展大型语言模型的应用范围和能力。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!