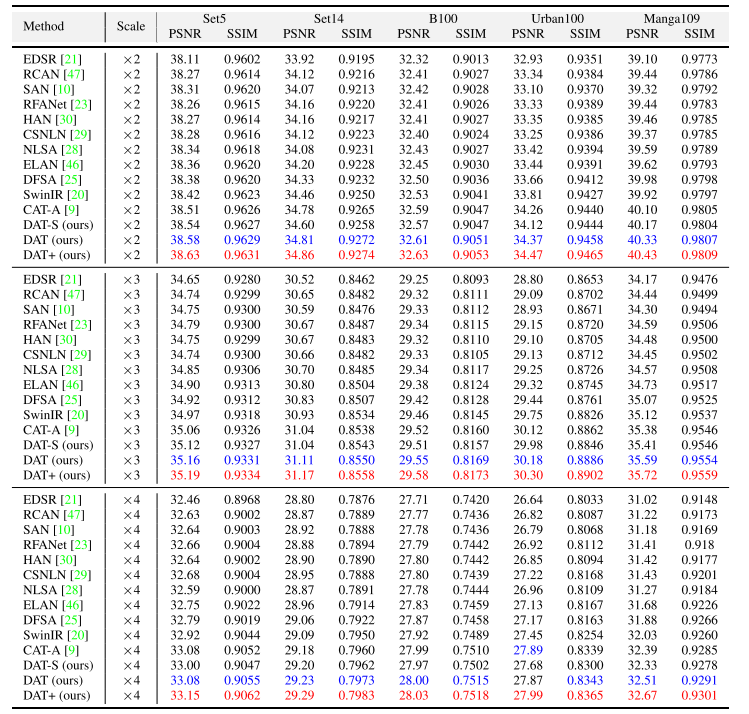
背景
三台CentOS 7.6.1虚拟机,
每台虚拟机上启动一个ElasticSearch 7.17.3(下面简称ES)实例
即每台虚拟机上一个ES进程(每台虚拟机上一个ES节点)
情况是:
之前集群是搭建成功的,
但是今天有一个节点一直加入集群失败。
节点3加入到集群失败
三个节点的配置文件的集群配置是没有任何问题的,也就是理论上三个节点启动,都加入到当前集群中才对。
cluster.name: es-cluster
node.name: node-1 # 节点1配的node-1,节点2配的node-2,节点3配的node-3
node.master: true
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
path.data: /home/es/elasticsearch-7.17.3/data-cluster
path.logs: /home/es/elasticsearch-7.17.3/logs-cluster
network.host: 0.0.0.0
discovery.seed_hosts: ["es-node1","es-node2","es-node3"]
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]可是,问题是node-1和node-2两个节点加入到了集群中,node-3加入失败。

每个节点配置的ip与域名对应关系如下
vim /etc/hosts
192.168.43.69 es-node1
192.168.43.133 es-node2
192.168.43.225 es-node3查看节点3的日志
[2024-05-10T10:45:47,816][INFO ][o.e.n.Node ] [node-3] initialized
[2024-05-10T10:45:47,817][INFO ][o.e.n.Node ] [node-3] starting ...
[2024-05-10T10:45:47,836][INFO ][o.e.x.s.c.f.PersistentCache] [node-3] persistent cache index loaded
[2024-05-10T10:45:47,838][INFO ][o.e.x.d.l.DeprecationIndexingComponent] [node-3] deprecation component started
[2024-05-10T10:45:58,158][INFO ][o.e.t.TransportService ] [node-3] publish_address {192.168.25.74:9300}, bound_addresses {[::]:9300}
[2024-05-10T10:45:58,993][INFO ][o.e.b.BootstrapChecks ] [node-3] bound or publishing to a non-loopback address, enforcing bootstrap checks
[2024-05-10T10:45:59,022][INFO ][o.e.c.c.Coordinator ] [node-3] cluster UUID [wXqPgoxHQVa5bb0DnbWPhw]
[2024-05-10T10:46:09,070][WARN ][o.e.c.c.ClusterFormationFailureHelper] [node-3] master not discovered or elected yet, an election requires at least 2 nodes with ids from [3O6pOnEdRm2jiOXGp8irVg, 4nzHPJBXR_yDSMlAoEhHIQ, YZVPiIHtRu6_QWGM7e7G5g], have discovered possible quorum [{node-3}{3O6pOnEdRm2jiOXGp8irVg}{DL7t-rT3SpKZfJe52Go_NA}{192.168.25.74}{192.168.25.74:9300}{cdfhilmrstw}, {node-1}{YZVPiIHtRu6_QWGM7e7G5g}{Dyo-oM3OTwiLLhvHst4_oQ}{192.168.43.69}{192.168.43.69:9300}{cdfhilmrstw}, {node-2}{4nzHPJBXR_yDSMlAoEhHIQ}{QfPfoN5AQCuip_eNwxd7JQ}{192.168.43.133}{192.168.43.133:9300}{cdfhilmrstw}]; discovery will continue using [192.168.43.69:9300, 192.168.43.133:9300, 192.168.43.225:9300] from hosts providers and [{node-3}{3O6pOnEdRm2jiOXGp8irVg}{DL7t-rT3SpKZfJe52Go_NA}{192.168.25.74}{192.168.25.74:9300}{cdfhilmrstw}] from last-known cluster state; node term 4, last-accepted version 117 in term 3
node-3 实际节点机器局域网内ip是192.168.43.225,通过ifconfig命令查看网卡信息,ip也是192.168.43.225,可是日志中 publish_address {192.168.25.74:9300},明显publish_address的ip与机器网卡ip不一致,猜测着是这里的问题,publish_address中的ip就不是当前局域网下同一子网下的ip,必然不能与其他节点通信,但正常情况下没关注过这个属性,ES配置文件里也没有这个属性
尝试解决:网络重连、机器重启
1. 尝试断开虚拟机右下角的网络连接然后重连

2. 还执行了重启节点3所在虚拟机
未果
查看ip没有变化,是节点3的ip,这没问题,之前也是通过这个ip XShell连接的虚拟机

然后发现还是不行,启动es时候[node-3] publish_address {192.168.25.74:9200}, bound_addresses {[::]:9200},它不是机器ip 192.168.43.225,搞不清楚这个ip哪来的
下面是截取的部分日志
tail -f logs-cluster/es-cluster.log[2024-05-10T10:58:21,328][INFO ][o.e.n.Node ] [node-3] initialized
[2024-05-10T10:58:21,328][INFO ][o.e.n.Node ] [node-3] starting ...
[2024-05-10T10:58:21,360][INFO ][o.e.x.s.c.f.PersistentCache] [node-3] persistent cache index loaded
[2024-05-10T10:58:21,362][INFO ][o.e.x.d.l.DeprecationIndexingComponent] [node-3] deprecation component started
[2024-05-10T10:58:31,624][INFO ][o.e.t.TransportService ] [node-3] publish_address {192.168.25.74:9300}, bound_addresses {[::]:9300}
[2024-05-10T10:58:32,294][INFO ][o.e.b.BootstrapChecks ] [node-3] bound or publishing to a non-loopback address, enforcing bootstrap checks
[2024-05-10T10:58:32,372][INFO ][o.e.c.c.Coordinator ] [node-3] cluster UUID [wXqPgoxHQVa5bb0DnbWPhw]
[2024-05-10T10:58:42,387][WARN ][o.e.c.c.ClusterFormationFailureHelper] [node-3] master not discovered or elected yet, an election requires at least 2 nodes with ids from [3O6pOnEdRm2jiOXGp8irVg, 4nzHPJBXR_yDSMlAoEhHIQ, YZVPiIHtRu6_QWGM7e7G5g], have discovered possible quorum [{node-3}{3O6pOnEdRm2jiOXGp8irVg}{NckXxN_XTl2S0DYe5UXRng}{192.168.25.74}{192.168.25.74:9300}{cdfhilmrstw}, {node-1}{YZVPiIHtRu6_QWGM7e7G5g}{Dyo-oM3OTwiLLhvHst4_oQ}{192.168.43.69}{192.168.43.69:9300}{cdfhilmrstw}, {node-2}{4nzHPJBXR_yDSMlAoEhHIQ}{QfPfoN5AQCuip_eNwxd7JQ}{192.168.43.133}{192.168.43.133:9300}{cdfhilmrstw}]; discovery will continue using [192.168.43.69:9300, 192.168.43.133:9300, 192.168.43.225:9300] from hosts providers and [{node-3}{3O6pOnEdRm2jiOXGp8irVg}{NckXxN_XTl2S0DYe5UXRng}{192.168.25.74}{192.168.25.74:9300}{cdfhilmrstw}] from last-known cluster state; node term 4, last-accepted version 117 in term 3
[2024-05-10T10:58:52,390][WARN ][o.e.c.c.ClusterFormationFailureHelper] [node-3] master not discovered or elected yet, an election requires at least 2 nodes with ids from [3O6pOnEdRm2jiOXGp8irVg, 4nzHPJBXR_yDSMlAoEhHIQ, YZVPiIHtRu6_QWGM7e7G5g], have discovered possible quorum [{node-3}{3O6pOnEdRm2jiOXGp8irVg}{NckXxN_XTl2S0DYe5UXRng}{192.168.25.74}{192.168.25.74:9300}{cdfhilmrstw}, {node-1}{YZVPiIHtRu6_QWGM7e7G5g}{Dyo-oM3OTwiLLhvHst4_oQ}{192.168.43.69}{192.168.43.69:9300}{cdfhilmrstw}, {node-2}{4nzHPJBXR_yDSMlAoEhHIQ}{QfPfoN5AQCuip_eNwxd7JQ}{192.168.43.133}{192.168.43.133:9300}{cdfhilmrstw}]; discovery will continue using [192.168.43.69:9300, 192.168.43.133:9300, 192.168.43.225:9300] from hosts providers and [{node-3}{3O6pOnEdRm2jiOXGp8irVg}{NckXxN_XTl2S0DYe5UXRng}{192.168.25.74}{192.168.25.74:9300}{cdfhilmrstw}] from last-known cluster state; node term 4, last-accepted version 117 in term 3
[2024-05-10T10:59:02,394][WARN ][o.e.c.c.ClusterFormationFailureHelper] [node-3] master not discovered or elected yet, an election requires at least 2 nodes with ids from [3O6pOnEdRm2jiOXGp8irVg, 4nzHPJBXR_yDSMlAoEhHIQ, YZVPiIHtRu6_QWGM7e7G5g], have discovered possible quorum [{node-3}{3O6pOnEdRm2jiOXGp8irVg}{NckXxN_XTl2S0DYe5UXRng}{192.168.25.74}{192.168.25.74:9300}{cdfhilmrstw}, {node-1}{YZVPiIHtRu6_QWGM7e7G5g}{Dyo-oM3OTwiLLhvHst4_oQ}{192.168.43.69}{192.168.43.69:9300}{cdfhilmrstw}, {node-2}{4nzHPJBXR_yDSMlAoEhHIQ}{QfPfoN5AQCuip_eNwxd7JQ}{192.168.43.133}{192.168.43.133:9300}{cdfhilmrstw}]; discovery will continue using [192.168.43.69:9300, 192.168.43.133:9300, 192.168.43.225:9300] from hosts providers and [{node-3}{3O6pOnEdRm2jiOXGp8irVg}{NckXxN_XTl2S0DYe5UXRng}{192.168.25.74}{192.168.25.74:9300}{cdfhilmrstw}] from last-known cluster state; node term 4, last-accepted version 117 in term 3
[2024-05-10T10:59:02,397][WARN ][o.e.n.Node ] [node-3] timed out while waiting for initial discovery state - timeout: 30s
[2024-05-10T10:59:02,420][INFO ][o.e.h.AbstractHttpServerTransport] [node-3] publish_address {192.168.25.74:9200}, bound_addresses {[::]:9200}
[2024-05-10T10:59:02,421][INFO ][o.e.n.Node ] [node-3] started
[2024-05-10T10:59:02,585][INFO ][o.e.c.c.JoinHelper ] [node-3] failed to join {node-2}{4nzHPJBXR_yDSMlAoEhHIQ}{QfPfoN5AQCuip_eNwxd7JQ}{192.168.43.133}{192.168.43.133:9300}{cdfhilmrstw}{ml.machine_memory=1907970048, ml.max_open_jobs=512, xpack.installed=true, ml.max_jvm_size=1073741824, transform.node=true} with JoinRequest{sourceNode={node-3}{3O6pOnEdRm2jiOXGp8irVg}{NckXxN_XTl2S0DYe5UXRng}{192.168.25.74}{192.168.25.74:9300}{cdfhilmrstw}{ml.machine_memory=1907970048, xpack.installed=true, transform.node=true, ml.max_open_jobs=512, ml.max_jvm_size=1073741824}, minimumTerm=4, optionalJoin=Optional.empty}
org.elasticsearch.transport.RemoteTransportException: [node-2][192.168.43.133:9300][internal:cluster/coordination/join]
Caused by: org.elasticsearch.transport.ConnectTransportException: [node-3][192.168.25.74:9300] connect_exception
at org.elasticsearch.transport.TcpTransport$ChannelsConnectedListener.onFailure(TcpTransport.java:1047) ~[elasticsearch-7.17.3.jar:7.17.3]
at org.elasticsearch.action.ActionListener.lambda$toBiConsumer$0(ActionListener.java:279) ~[elasticsearch-7.17.3.jar:7.17.3]
at org.elasticsearch.core.CompletableContext.lambda$addListener$0(CompletableContext.java:31) ~[elasticsearch-core-7.17.3.jar:7.17.3]
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:863) ~[?:?]
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:841) ~[?:?]
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:510) ~[?:?]
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:2162) ~[?:?]
at org.elasticsearch.core.CompletableContext.completeExceptionally(CompletableContext.java:46) ~[elasticsearch-core-7.17.3.jar:7.17.3]
at org.elasticsearch.transport.netty4.Netty4TcpChannel.lambda$addListener$0(Netty4TcpChannel.java:58) ~[transport-netty4-client-7.17.3.jar:7.17.3]
at io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:578) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.DefaultPromise.notifyListeners0(DefaultPromise.java:571) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:550) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:491) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.DefaultPromise.setValue0(DefaultPromise.java:616) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.DefaultPromise.setFailure0(DefaultPromise.java:609) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.DefaultPromise.tryFailure(DefaultPromise.java:117) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe$1.run(AbstractNioChannel.java:262) ~[netty-transport-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.PromiseTask.runTask(PromiseTask.java:98) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.ScheduledFutureTask.run(ScheduledFutureTask.java:170) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:164) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:469) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:500) [netty-transport-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:986) [netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) [netty-common-4.1.66.Final.jar:4.1.66.Final]
at java.lang.Thread.run(Thread.java:833) [?:?]
Caused by: java.io.IOException: connection timed out: 192.168.25.74/192.168.25.74:9300
at io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe$1.run(AbstractNioChannel.java:261) ~[netty-transport-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.PromiseTask.runTask(PromiseTask.java:98) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.ScheduledFutureTask.run(ScheduledFutureTask.java:170) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:164) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:469) ~[netty-common-4.1.66.Final.jar:4.1.66.Final]
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:500) [netty-transport-4.1.66.Final.jar:4.1.66.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:986) ~[?:?]
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) ~[?:?]
at java.lang.Thread.run(Thread.java:833) ~[?:?]
插一嘴:选举过程
插个题外话,从报错信息中,也可以发现他的选举过程,
当前因为它没加入到集群(由于网络问题),它当前是一个单点,
因此提示master节点就未发现或者未选举出来,
需要至少俩能够参与选举master的节点,才能选出 master节点,
此时他就会从配置的服务发现的域名中尝试与配的其他节点进行联系,但是因为这里网络不通,它无法与另外两个ES节点通信,于是他就一直继续尝试再次与其他节点发起联系
[2024-05-10T10:59:02,394][WARN ][o.e.c.c.ClusterFormationFailureHelper] [node-3] master not discovered or elected yet, an election requires at least 2 nodes with ids from [3O6pOnEdRm2jiOXGp8irVg, 4nzHPJBXR_yDSMlAoEhHIQ, YZVPiIHtRu6_QWGM7e7G5g], have discovered possible quorum [{node-3}{3O6pOnEdRm2jiOXGp8irVg}{NckXxN_XTl2S0DYe5UXRng}{192.168.25.74}{192.168.25.74:9300}{cdfhilmrstw}, {node-1}{YZVPiIHtRu6_QWGM7e7G5g}{Dyo-oM3OTwiLLhvHst4_oQ}{192.168.43.69}{192.168.43.69:9300}{cdfhilmrstw}, {node-2}{4nzHPJBXR_yDSMlAoEhHIQ}{QfPfoN5AQCuip_eNwxd7JQ}{192.168.43.133}{192.168.43.133:9300}{cdfhilmrstw}]; discovery will continue using [192.168.43.69:9300, 192.168.43.133:9300, 192.168.43.225:9300] from hosts providers and [{node-3}{3O6pOnEdRm2jiOXGp8irVg}{NckXxN_XTl2S0DYe5UXRng}{192.168.25.74}{192.168.25.74:9300}{cdfhilmrstw}] from last-known cluster state; node term 4, last-accepted version 117 in term 3可以单独对外服务
然后,它还可以被外部客户端访问,就是无法加入集群,还在一直与其他两节点努力联系中
可以对外服务可以理解因为配置的0.0.0.0监听所有网卡,而虚拟机的ip在局域网同一子网内,因此可以访问


现在重点是研究下publish_address属性
希望从这个属性,找到点答案,或者启发,让我发现这个不知道的ip是哪来的。
从官网找到相关的内容
Networking
Each Elasticsearch node has two different network interfaces. Clients send requests to Elasticsearch’s REST APIs using its HTTP interface, but nodes communicate with other nodes using the transport interface. The transport interface is also used for communication with remote clusters.
You can configure both of these interfaces at the same time using the network.* settings. If you have a more complicated network, you might need to configure the interfaces independently using the http.* and transport.* settings. Where possible, use the network.* settings that apply to both interfaces to simplify your configuration and reduce duplication.
By default Elasticsearch binds only to localhost which means it cannot be accessed remotely. This configuration is sufficient for a local development cluster made of one or more nodes all running on the same host. To form a cluster across multiple hosts, or which is accessible to remote clients, you must adjust some network settings such as network.host.
Be careful with the network configuration!
Never expose an unprotected node to the public internet. If you do, you are permitting anyone in the world to download, modify, or delete any of the data in your cluster.
ES有两个不通的网络通信接口,
用于提供给客户端请求的REST API网络接口HTTP interface(也就是默认开放出来的9200端口)
但是,ES集群节点间通信使用的是transport interface(传输接口),这个传输接口也用于与remote clusters(远程的ES集群)进行通信;
你可以同时配置Rest API网络接口(9200对外服务接口)与节点间通信接口(9300内部通信端口),使用network.*配置,
但如果你有更复杂的网络环境(比如你有多块网卡共同分担网络流量,比如你想要将对外服务网络流量与节点间内部通信的网络流量分离开),你可以使用http.* 和 transport.*单独配置他们
(个人理解这可能在网卡是瓶颈的情况下,分离流量以提高性能的一种方式,但一般情况会通过network.*一起配置了)
默认情况,ES绑定到localhost监听本地访问,不可远程访问,这在所有节点运行在同一台机器(host)的场景下是可行的。但是一般情况下,或者生产环境必然是节点分布在不同服务器,而且,有远程客户端请求的需要,因此必须修改ES网络配置,比如:network.host
结合我这里的情况说明下就是:
我这里配置network.host: 0.0.0.0监听所有网卡ip,且我这刚好只有一个桥接网卡,那么对外服务的客户端rest请求(port:9200 default)以及节点间通信(port:9300 default)都会走这个网卡,ip就是局域网内的手动配置的ip或者DHCP动态拨号分配的ip.
官网提示:注意网络配置!
切勿将未受保护的节点暴露给公共 Internet。如果你这样做了,你就是允许世界上任何人下载、修改或删除任何在集群中的数据。
Commonly used network settings
Binding and publishing
Binding and publishingedit
Elasticsearch uses network addresses for two distinct purposes known as binding and publishing. Most nodes will use the same address for everything, but more complicated setups may need to configure different addresses for different purposes.
When an application such as Elasticsearch wishes to receive network communications, it must indicate to the operating system the address or addresses whose traffic it should receive. This is known as binding to those addresses. Elasticsearch can bind to more than one address if needed, but most nodes only bind to a single address. Elasticsearch can only bind to an address if it is running on a host that has a network interface with that address. If necessary, you can configure the transport and HTTP interfaces to bind to different addresses.
Each Elasticsearch node has an address at which clients and other nodes can contact it, known as its publish address. Each node has one publish address for its HTTP interface and one for its transport interface. These two addresses can be anything, and don’t need to be addresses of the network interfaces on the host. The only requirements are that each node must be:
Accessible at its transport publish address by all other nodes in its cluster, and by any remote clusters that will discover it using Sniff mode.
Accessible at its HTTP publish address by all clients that will discover it using sniffing.在绑定和发布部分
说明了
接收网络通信,接收流量的地址,就是熟知的绑定地址,ES可以绑定到多个地址,但是通常只绑定到一个地址(ip地址)
ES只会绑定到运行在主机上的网络接口可用的地址(解释下也就是局域网内的同一子网中的一个ip)
如果有需要,可以配置传输接口和rest客户端服务接口绑定到不同的地址(这应该就是说如果你有多块网卡,虚拟机环境下可能是多块虚拟网卡,都是可用的话,那么你有特殊场景的需要可以配置不通的地址)
ES节点有一个客户端和其他节点与它能够通信的地址,称作publish address.
这里出现了我们找到关键词publish address.
这就是上面报错中的publish_address,每个 Elasticsearch 节点都有一个地址,客户端和其他节点可以通过该地址联系它, 称为其发布地址。
每个节点都有一个 HTTP 发布地址 接口,一个用于其传输接口。这两个地址可以是 任何内容,并且不需要是主机上网络接口的地址。 唯一的要求是每个节点必须:
- 所有其他用户可在其传输发布地址访问 其集群中的节点,以及将使用 Sniff 模式发现它的任何远程集群。
- 所有客户端都可在其 HTTP 发布地址访问 这将使用嗅探来发现它。
这有个关键:
每个节点都有一个 HTTP 发布地址 接口,一个用于其传输接口。这两个地址可以是 任何内容,并且不需要是主机上网络接口的地址。
这也就是上面我那个发布地址可以不是局域网内的ip的原因。
由于不是局域网内同一子网下的ip,所以加入集群失败。
揭秘
然后,我突然想到了,我的三台机器是克隆来的,然后
终于想到了这个ip哪里的了:
因为启动能够自动分配ip,后来我就懒得手动改网卡,也能通过连接工具连接虚拟机,ip就是初次连接wifi分配的(比如我是开的手机热点,连接后分配的ip即使断开连接再重连还会是那个之前分配的那个ip)
那也就是说,ES确实是去读网卡ip了,但是它读的不是实际运行的ip,而是网卡配置文件中的ip,而,从上面官方描述中“不需要是主机上网络接口的地址”。因此,它不影响该节点单独运行,且由于配置监听所有ip,所以单节点可用对外服务,只是一直努力这尝试去和其他两个节点通信而不通。
然而
这台虚拟机的实际在局域网内的ip地址和配置文件中可以不一致,还能正常运行这是怎么回事?
我猜测啊,机器启动确实去读网卡手动配置的ip,然后他不在局域网内,然后自动桥接模式自动给分配了一个可用的ip
问题解决
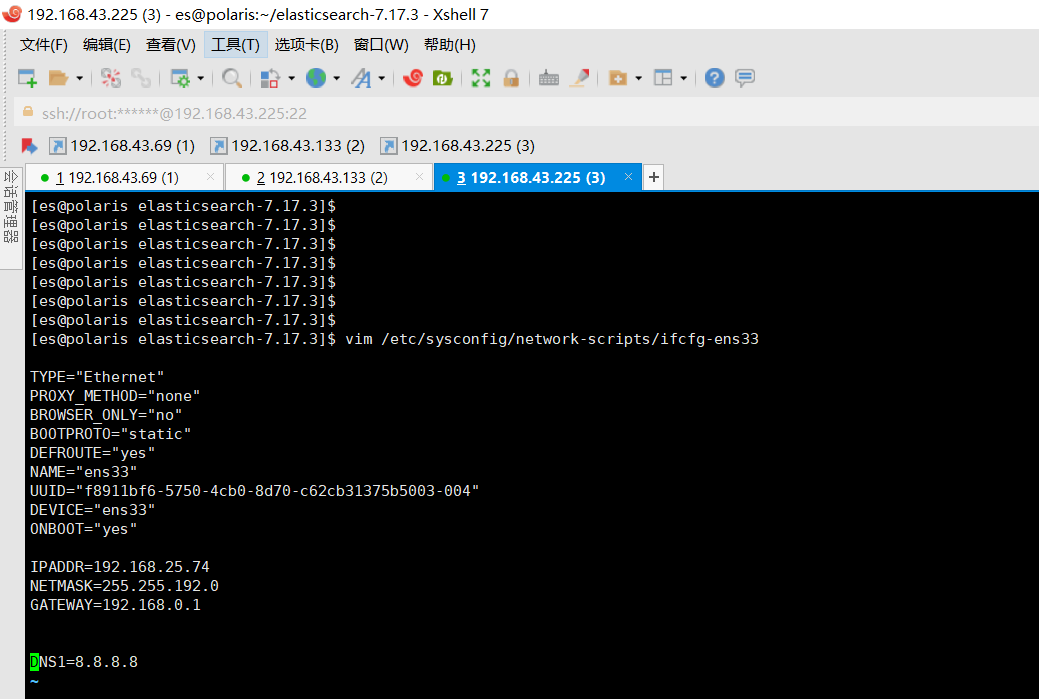
修改网卡ip
这里对照主机ip信息,以及自动给虚拟机分配的ip,手动改下网卡ip,然后重启网络服务,之后再重启ES

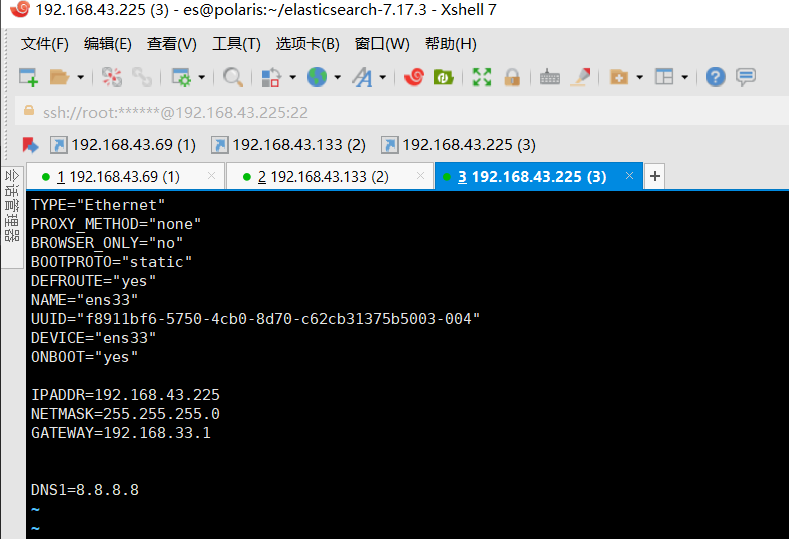
vim /etc/sysconfig/network-scripts/ifcfg-ens33
service network restart网络重连生效
重启node-3
即使网络重启了之后,启动es,publish_address还是之前手动配的网卡ip 192.168.25.74:9200
可能得重连生效吧
[node-3] publish_address {192.168.25.74:9200}, bound_addresses {[::]:9200}于是虚拟机右下角电脑图标-表示网络,重连下
然后再重启es,搞定了!
publish_address已经是当前虚拟机局域网下ip地址了

现在publish_address终于是当前机器在局域网中的ip地址了
[2024-05-10T12:14:44,902][INFO ][o.e.n.Node ] [node-3] starting ...
[2024-05-10T12:14:44,922][INFO ][o.e.x.s.c.f.PersistentCache] [node-3] persistent cache index loaded
[2024-05-10T12:14:44,924][INFO ][o.e.x.d.l.DeprecationIndexingComponent] [node-3] deprecation component started
[2024-05-10T12:14:45,283][INFO ][o.e.t.TransportService ] [node-3] publish_address {192.168.43.225:9300}, bound_addresses {[::]:9300}
[2024-05-10T12:14:46,178][INFO ][o.e.b.BootstrapChecks ] [node-3] bound or publishing to a non-loopback address, enforcing bootstrap checks
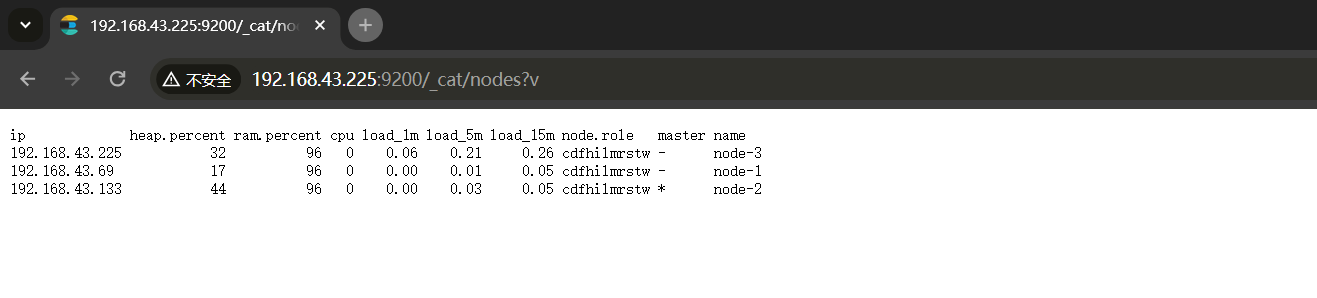
[2024-05-10T12:14:46,214][INFO ][o.e.c.c.Coordinator ] [node-3] cluster UUID [wXqPgoxHQVa5bb0DnbWPhw]查看集群节点
现在再来查看集群所有节点,node-3已经加入进来了

结论
手动配置网卡ip是必要的,即使它能自动拨号DHCP,分配ip,
但是有可能程序运行就是读的网卡文件中的ip信息,
不手动修改虚拟机网卡IP,实际运行ip与网卡配置ip(可能是之前手动配置的)就有可能不一致
这样不在一个局域网子网,就在局域网内不能通信。