前言
通过前面几篇文章,已经完成数据集制作和环境配置(服务器),接下来将继续实践如何开始训练自己数据集~
往期回顾
YOLOv5入门(一)利用Labelimg标注自己数据集
YOLOv5入门(二)处理自己数据集(标签统计、数据集划分、数据增强)
YOLOv5入门(三)使用云服务器autoDL、VSCode连接和WinSCP文件上传
YOLOv5入门(四)训练公共数据集KITTI实践
目录
- 一、修改配置文件
- 二、模型训练
- 三、模型测试
- 四、模型推理
前期准备
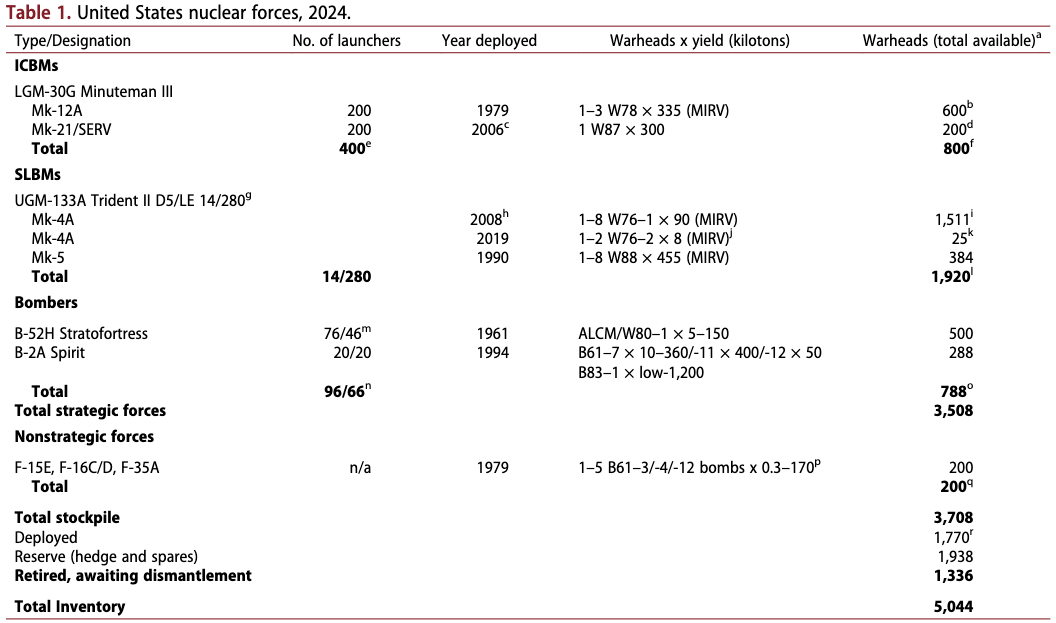
将处理好的数据集通过WinSCP上传到服务器中,下面为上传之后文件的结构:
一、修改配置文件
第一步:修改数据集配置文件,复制COCO128.yaml文件后重命名
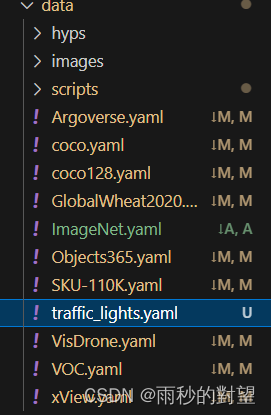
第二步:修改重命名后文件的路径和参数
- train:划分好的训练集文件路径
- val:划分好的验证集文件路径
- test:划分好的测试集文件路径
- names:存放目标检测目标类别的名字
第三步:修改模型配置文件
使用yolov5s.pt预训练权重,将yolov5s.yaml文件复制一份后重命名
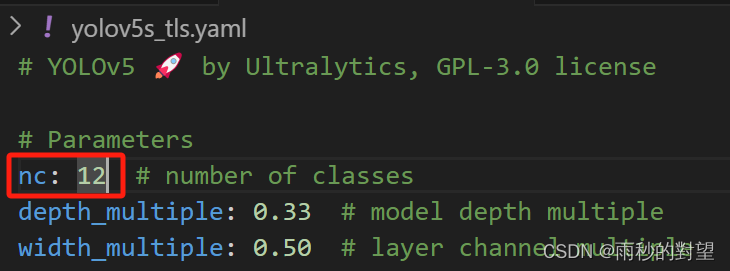
第四步:修改目标类别个数nc
二、模型训练
1、训练模型通过运行train.py文件,运行前需修改相关参数
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
首先看下opt参数解析
- weights:模型权重文件的路径,默认为YOLOv5s的权重文件路径
- cfg:存储模型结构的配置文件
- data:数据集文件的路径,默认为COCO128数据集的配置文件路径
- hyp:用于指定超参数配置文件的路径
- epochs:指的就是训练过程中整个数据集将被迭代多少次,显卡不行就调小点
- batch-size :用于指定训练批量的大小,默认设置为 16 ,表示每次都从训练集中取 16 个训练样本放入模型进行训练。
- imgsz:输入图像的大小,默认为640×640
- rect :用于确定是否用矩阵推理的方式去训练模型
- resume :用于确定是否进行断点续训,也就是从上一个训练任务中断的地方继续训练,直至训练完成,默认值为 False
- nosave :用于确认是否只保存最后一轮训练的 .pt 权重文件,默认是False
- noval:用于确认是否只在最后一轮训练进行验证,默认是False
- noautoanchor :用于确认是否禁用自动计算锚框的功能,默认是False
- evolve: 用于确认是否使用超参数优化算法进行自动调参,默认False
- bucket :用于在谷歌云盘中下载或者上传数据
- cache: 用于确定是否提前将数据集图片缓存到内存,加快数据加载和训练速度,默认值为 False
- image-weights :用于确认是否对数据集图片进行加权训练,主要为了解决样本不平衡的问题,默认值为 False
- device:使用的设备类型,默认为空,表示自动选择最合适的设备
- multi-scale :用于确认是否启用多尺度训练
- single-cls: 用于设定训练数据集是单类别还是多类别,默认值为 False
- optimizer:选择训练使用的优化器,默认使用SGD
- sync-bn :用于确定是否开启跨卡 同步批量归一化 ,默认是False
- workers :用于设置 Dataloader 使用的最大 numworkers(加载和处理数据的线程数),默认值为 8 ,建议改为 0 ,表示不使用多线程,只使用主线程进行数据加载和处理
- project :用于指定训练好的模型的保存路径,默认在 runs / train
- name :用于指定保存模型的文件夹名,默认为 exp
- exist-ok :用于确定是否覆盖同名的训练结果保存路径,默认是False
- quad :用于确认是否使用 quad dataloader 数据加载器,默认是False
- cos-lr :参数用于对学习速率进行调整,默认值为 False
- label-smoothing :用于对标签进行平滑处理,防止在分类算法过程中产生过拟合问题,默认是False
- save_period :参数用于设置每隔多少个 epoch 保存一次训练权重,默认是False
2、修改以下部分:
- 1、weights:选用官方的yolov5s.pt权重
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
- 2、cfg:模型配置文件路径
parser.add_argument('--cfg', type=str, default='/root/yolov5/models/yolov5s_tls.yaml', help='model.yaml path')
- 3、data:数据集配置文件路径
parser.add_argument('--data', type=str, default=ROOT / 'data/traffic_lights.yaml', help='dataset.yaml path')
- 4、epoch:数据集训练轮数
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
- 5、bitch-size:训练批量的大小
parser.add_argument('--batch-size', type=int, default=128, help='total batch size for all GPUs, -1 for autobatch')
3、开始训练
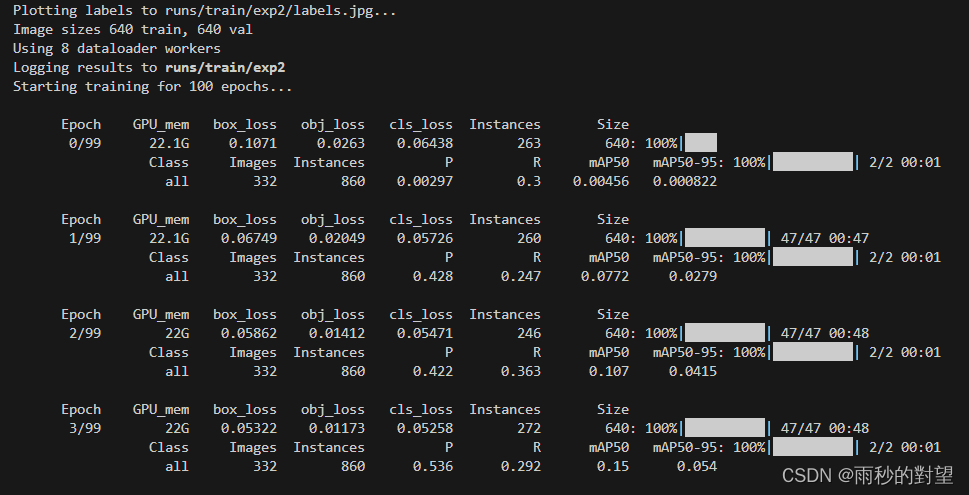
以上内容设置完成后运行python train.py开始训练:
训练结果保存到run/train下
三、模型测试
验证部分val.py主要是train.py每一轮训练结束后,用val.py去验证当前模型的mAP、混淆矩阵等指标以及各个超参数是否是最佳,不是最佳的话就去修改train.py里面的结构,再用detect.py去泛化使用。
三个文件的区别:
- train.py:模型训练。读取数据集,加载模型并训练
- val.py:模型验证。获取当前数据集上的最佳验证结果
- detect.py:模型推理。获取实际中最佳推理结果
1、验证模型通过运行val.py文件,运行前需修改相关参数
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
parser.add_argument('--batch-size', type=int, default=32, help='batch size')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=300, help='maximum detections per image')
parser.add_argument('--task', default='val', help='train, val, test, speed or study')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--verbose', action='store_true', help='report mAP by class')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.data = check_yaml(opt.data) # check YAML
opt.save_json |= opt.data.endswith('coco.yaml')
opt.save_txt |= opt.save_hybrid
print_args(vars(opt))
return opt
查看opt参数解析:
- data:数据集配置文件地址 包含数据集的路径、类别个数、类名、下载地址等信息
- weights:模型的权重文件地址yolov5s.pt
- batch-size:用于指定训练批量的大小,默认设置为 32
- imgsz:输入网络的图片分辨率 默认640
- conf-thres :object置信度阈值 默认0.001
- iou-thres :进行NMS时IOU的阈值 默认0.6
- task :设置测试的类型 有train, val, test, speed or study几种 默认val
- device:使用的设备类型,默认为空,表示自动选择最合适的设备练
- single-cls: 用于设定训练数据集是单类别还是多类别,默认值为 False
- augment :测试是否使用TTA Test Time Augment 默认False
- verbose :是否打印出每个类别的mAP 默认False
- save-txt :是否以txt文件的形式保存模型预测的框坐标, 默认False
- save-hybrid :保存label+prediction杂交结果到对应.txt,默认False
- save-json :是否按照coco的json格式保存预测框,并且使用cocoapi做评估(需要同样coco的json格式的标签) 默认False
- project :测试保存的源文件 默认runs/val
- name :测试保存的文件地址 默认exp 保存在runs/val/exp下
- exist-ok :是否存在当前文件 默认False 一般是 no exist-ok 连用 所以一般都要重新创建文件夹
- dnn :是否使用 OpenCV DNN对ONNX 模型推理
2、修改以下部分:
- 1、data:数据集配置文件路径
parser.add_argument('--data', type=str, default=ROOT / '/root/yolov5-7.0/data/traffic_lights.yaml', help='dataset.yaml path')
- 2、weights:换成我们训练完成后最好的权重
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / '/root/yolov5-7.0/runs/train/exp3/weights/best.pt', help='model path(s)')
3、开始验证
运行:python val.py
查看检测效果:

四、模型推理
最后,在没有标注的数据集上进行推理
1、验证模型通过运行detect.py.py文件,运行前需修改相关参数
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(vars(opt))
return opt
查看opt参数解析:
- weights:用于检测的模型路径
- source:检测的路径,可以是图片,视频,文件夹,也可以是摄像头(‘0’)
- data:数据集的配置文件,用于获取类别名称,和训练时的一样
- imgsz:网络输入的图片大小,默认为640
- conf-thres:置信度阈值,大于该阈值的框才会被保留
- iou-thres: NMS的阈值,大于该阈值的框会被合并,小于该阈值的框会被保留,一般设置为0.45
- max-det: 每张图片最多检测的目标数,默认为1000
- device:检测的设备,可以是cpu,也可以是gpu,可以不用设置,会自动选择
- view-img:是否显示检测结果,默认为False
- save-txt: 是否将检测结果保存为txt文件,包括类别,框的坐标,默认为False
- save-conf:是否将检测结果保存为txt文件,包括类别,框的坐标,置信度,默认为False
- save-crop: 是否保存裁剪预测框的图片,默认为False
- nosave: 不保存检测结果,默认为False
- classes: 检测的类别,默认为None,即检测所有类别,如果设置了该参数,则只检测该参数指定的类别
- agnostic-nms: 进行NMS去除不同类别之间的框,默认为False
- augment: 推理时是否进行TTA数据增强,默认为False
- update: 是否更新模型,默认为False,如果设置为True,则会更新模型,对模型进行剪枝,去除不必要的参数
- project: 检测结果保存的文件夹,默认为runs/detect
- name: 检测结果保存的文件夹,默认为exp
- exist-ok: 如果检测结果保存的文件夹已经存在,是否覆盖,默认为False
- line-thickness: 框的线宽,默认为3
- hide-labels: 是否隐藏类别,默认为False
- hide-conf: 是否隐藏置信度,默认为False
- half: 是否使用半精度推理,默认为False
- dnn: 是否使用OpenCV的DNN模块进行推理,默认为False
- vid-stride: 视频帧采样间隔,默认为1,即每一帧都进行检测
2、修改opt中以下部分:
- 1、weights:换成自己训练最好的权重文件
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / '/root/yolov5-7.0/runs/train/exp3/weights/best.pt', help='model path(s)')
- 2、source:换成没有标注的数据集
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
- 3、data:数据集配置文件路径
parser.add_argument('--data', type=str, default=ROOT / '/root/yolov5-7.0/data/traffic_lights.yaml', help='(optional) dataset.yaml path')
3、修改run中以下部分:
def run(
weights=ROOT / 'yolov5s.pt', # model path or triton URL
source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
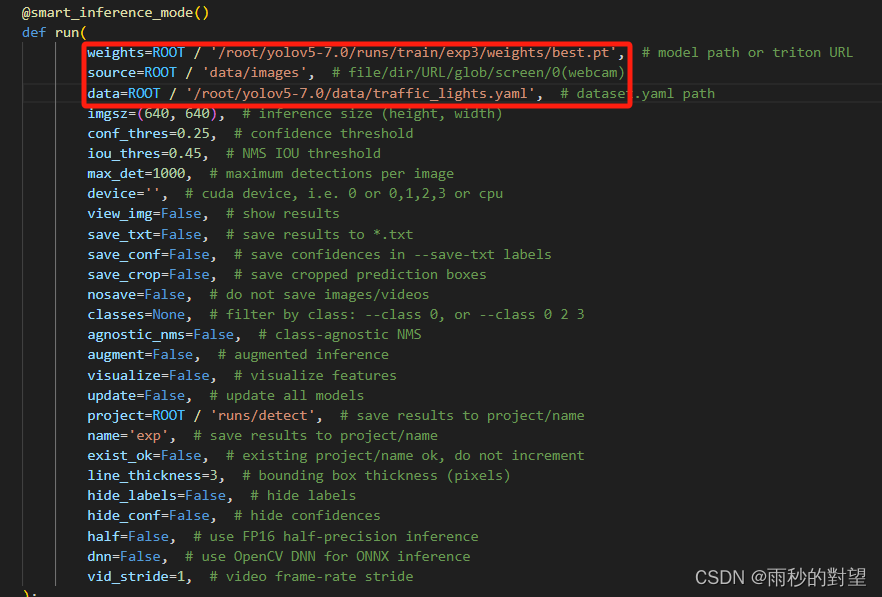
4、开始推理
运行:python detect.py
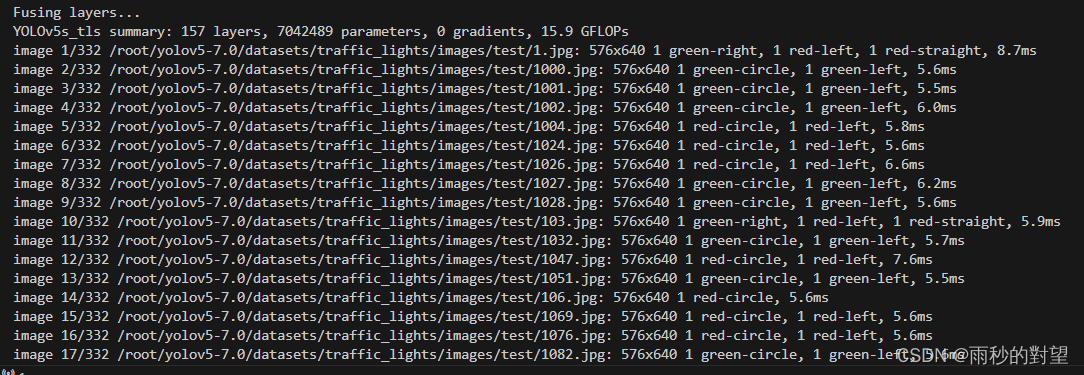
查看推理效果:

好了,到这一步模型的训练、验证和推理已基本完成!
![C++进阶 | [3] 搜索二叉树](https://img-blog.csdnimg.cn/direct/3c36f415464c466e821c201e522f0055.png)