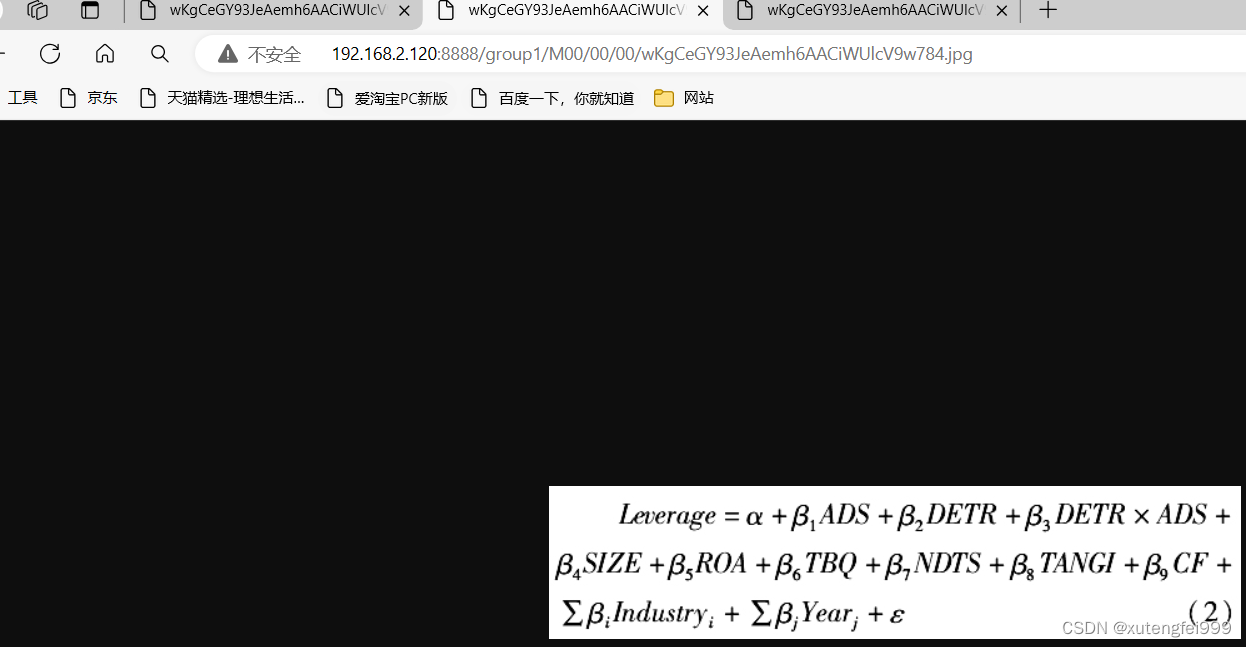
通过5个条件判定一件事情是否会发生,5个条件对这件事情是否发生的影响力不同,计算每个条件对这件事情发生的影响力多大,写一个多层感知机模型pytorch程序,最后打印5个条件分别的影响力。
一
在多层感知机(MLP)模型中,输入特征(本例中的5个条件)通过多个全连接层进行非线性变换,最终产生输出。与线性模型不同,MLP能够学习特征之间的复杂交互,并且通过隐藏层的激活函数引入非线性。
影响力或特征重要性的概念在MLP中并不像在线性模型中那样直接。不过,我们可以通过查看训练后模型的权重来尝试理解每个输入特征对输出的相对贡献。然而,必须注意,单个权重的解释性有限,因为它们在多层网络中与其他权重和激活函数共同作用。
以下是一个使用PyTorch实现的简单多层感知机模型,该模型通过5个条件来预测一件事情是否会发生,并在训练结束后打印出第一层全连接层的权重,作为每个条件对输出的相对重要性的近似。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# 假设有5个条件作为输入特征
num_conditions = 5
# 隐藏层的大小
hidden_size = 10
# 输出层的大小(二分类问题,所以输出为1)
num_classes = 1
# 使用sigmoid激活函数将输出限制在0和1之间
# 生成一些模拟数据
np.random.seed(0)
X = np.random.randn(100, num_conditions) # 100个样本,每个样本有5个条件
y = (np.random.randn(100, num_classes) > 0).astype(float) # 100个样本的随机二分类标签
# 转换为PyTorch张量
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32)
# 定义多层感知机模型
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
return out
# 实例化模型
model = MLP(num_conditions, hidden_size, num_classes)
# 定义损失函数和优化器
criterion = nn.BCELoss() # 二元交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_tensor)
loss = criterion(outputs, y_tensor)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 打印第一层全连接层的权重,作为每个条件对输出的相对重要性的近似
print("Approximate influence of each condition (based on first layer weights):")
for i, weight in enumerate(model.fc1.weight.data.mean(dim=0)):
print(f"Condition {i+1}: {weight.item()}")在这个例子中,我们训练了一个简单的MLP模型,并在训练结束后打印了第一层全连接层的权重平均值。这个平均值可以作为每个条件对最终输出重要性的一个粗略估计,但必须注意这种方法有很多局限性,并不能提供准确的影响力计算。
实际上,理解神经网络中特征的重要性是一个活跃的研究领域,涉及更复杂的技术,如梯度解释(Gradient-based explanation)、置换特征重要性(Permutation Feature Importance)或部分依赖图(Partial Dependency Plots)等。这些方法可以提供更准确的特征重要性估计,但通常需要额外的计算和分析步骤。

二
在多层感知机(MLP)模型中,输入特征(在本例中是5个条件)通过一系列全连接的隐藏层进行变换,最终产生一个输出。与线性模型不同,MLP能够学习特征之间的非线性关系。然而,直接解释MLP中每个输入特征对输出的影响力是困难的,因为特征在隐藏层中被非线性地组合和变换。
尽管如此,我们可以通过查看训练后的模型权重来尝试理解每个输入特征的重要性。一种常见的方法是计算每个特征的权重绝对值之和,这可以作为该特征在模型中总体影响力的粗略估计。但是,这种方法并不完美,因为它忽略了不同层之间的权重交互和非线性激活函数的影响。
下面是一个使用PyTorch实现的简单MLP模型,该模型通过5个条件来预测一件事情是否会发生,并在训练结束后打印出每个条件的影响力估计。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 假设5个条件作为输入特征
num_input_features = 5
# 隐藏层大小
hidden_size = 10
# 输出层大小(二分类问题,使用单个输出单元和sigmoid激活函数)
num_output_features = 1
# 生成一些模拟数据
# 注意:这里我们使用随机数据,但在实际应用中应该使用真实数据
num_samples = 100
X = torch.randn(num_samples, num_input_features)
y = torch.randint(0, 2, (num_samples, num_output_features)).float()
# 定义MLP模型
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = torch.sigmoid(self.fc2(x))
return x
# 实例化模型
model = MLP(num_input_features, hidden_size, num_output_features)
# 定义损失函数和优化器
criterion = nn.BCELoss() # 二元交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
# 前向传播
outputs = model(X)
loss = criterion(outputs, y)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 估计每个条件的影响力
# 通过计算每个输入特征对应权重的绝对值之和
influences = []
for i in range(num_input_features):
# 考虑到第一层权重和第二层权重的组合效应是很难的,
# 这里我们只计算第一层权重的影响力作为简化示例
influence = torch.sum(torch.abs(model.fc1.weight.data[i]))
influences.append(influence.item())
# 打印每个条件的影响力估计
print("Estimated influence of each condition:")
for i, influence in enumerate(influences):
print(f"Condition {i+1}: {influence}")请注意,这个程序使用了一个非常简化的方法来估计每个输入条件的影响力,即通过计算第一层权重中每个输入特征对应权重的绝对值之和。这种方法忽略了网络中后续层的权重和激活函数的影响,因此只能作为影响力的粗略估计。
在实际应用中,可能需要使用更复杂的方法来解释MLP模型中的特征重要性,例如通过梯度解释方法(如Integrated Gradients或Gradient * Input)或模型无关的解释方法(如LIME或SHAP)。这些方法可以提供更准确的特征重要性估计,但它们通常需要额外的计算和分析步骤。

三
要计算每个条件对一件事情是否发生的影响力,我们可以使用多层感知机(MLP)模型。在训练完模型后,我们可以通过查看输入层到第一隐藏层的权重来近似估计每个条件的影响力。这些权重表示了网络如何根据输入条件来调整其内部的表示,并进而影响最终的输出。
以下是一个使用PyTorch实现的多层感知机模型的示例程序。这个程序将训练一个MLP来对5个条件进行建模,并在训练结束后打印出输入层到第一隐藏层的权重,作为每个条件影响力的近似。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# 假设我们有5个条件作为输入特征
num_conditions = 5
# 隐藏层的大小
hidden_size = 10
# 输出层的大小(二分类问题,所以输出为1)
output_size = 1
# 生成一些模拟数据
np.random.seed(0)
X = np.random.randn(1000, num_conditions) # 1000个样本,每个样本有5个条件
y = np.random.randint(2, size=(1000, output_size)) # 1000个样本的随机二分类标签
# 转换为PyTorch张量,并将标签转换为float类型以计算损失
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32)
# 定义多层感知机模型
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
return out
# 实例化模型
model = MLP(num_conditions, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.BCELoss() # 使用二元交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_tensor)
loss = criterion(outputs, y_tensor)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 打印输入层到第一隐藏层的权重,作为每个条件影响力的近似
print("Approximate influence of each condition (based on input layer weights):")
for i, weight in enumerate(model.fc1.weight.data):
print(f"Condition {i+1}: {weight.mean().item()}") # 取权重的平均值作为影响力的近似
# 注意:这里取权重的平均值只是一种简化的表示方法,实际上每个隐藏节点都可能对不同的条件有不同的敏感性。
# 更精确的影响力分析可能需要更复杂的技术,如梯度解释或置换特征重要性。
请注意,这个程序使用了模拟数据,并且输出的影响力只是基于权重的简单近似。在实际应用中,你可能需要使用真实的数据集,并且可能需要更复杂的方法来准确地量化每个条件的影响力,例如通过计算每个条件对模型输出的梯度。此外,由于神经网络的非线性性质,输入层到第一隐藏层的权重只能提供有限的洞察力,因为后续层可能会以复杂的方式组合和转换这些输入。

四
多层感知机(MLP)是一个基础的神经网络模型,它可以学习输入特征的非线性组合以进行预测。在MLP中,输入层与隐藏层之间以及隐藏层与输出层之间的权重可以被解释为特征的重要性,但要注意这种解释是间接的,因为神经网络的权重是高度交互的。
要评估每个条件对输出的影响力,一种方法是计算每个输入特征的梯度,这表示了当该特征发生微小变化时输出将如何变化。这种方法通常用于解释神经网络决策的依据,称为敏感性分析或梯度解释。
下面是一个使用PyTorch实现的多层感知机模型的示例程序,该程序通过5个条件来预测一件事情是否会发生,并在训练结束后计算并打印每个条件的影响力(通过计算梯度得到)。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 假设我们有5个条件作为输入特征
num_features = 5
# 假设输出是一个二分类问题(事情发生/不发生)
num_classes = 1
# 生成一些模拟数据
# 这里我们使用随机数据,但在实际应用中应该使用真实数据
X = torch.randn(100, num_features) # 100个样本,每个样本有5个条件
y = torch.randint(0, 2, (100, num_classes)).float() # 100个样本的随机二分类标签
# 定义多层感知机模型
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
return out
# 实例化模型、损失函数和优化器
model = MLP(num_features, 10, num_classes)
criterion = nn.BCELoss() # 使用二元交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
# 将模型设置为评估模式(关闭dropout等)
model.eval()
# 选择一个样本来计算条件的影响力
sample = X[0].unsqueeze(0)
sample.requires_grad_(True) # 启用梯度计算
# 获取模型预测
output = model(sample)
# 进行反向传播前确认梯度清零。但在这里,由于是新的变量,可以不进行清零操作。
# 如果存在旧的梯度,先清零。
if sample.grad is not None:
sample.grad.zero_()
# 计算输出关于输入的梯度
output.backward(torch.ones_like(output))
# 打印每个条件的影响力(通过梯度)
print("Influence of each condition (based on gradients):")
for i, grad in enumerate(sample.grad.data.flatten()):
print(f"Condition {i+1}: {grad.item()}")请注意,梯度的大小和方向可以解释为条件对输出的影响力。在这个例子中,我们计算了模型输出关于输入条件的梯度,并将其作为每个条件对输出发生概率的影响力。这种方法提供了一种局部的解释,即在给定样本附近,每个条件是如何影响模型预测的。
然而,这种方法有一些局限性:
梯度的大小和方向可能会随着输入样本的变化而变化。
由于神经网络的高度非线性,梯度可能只提供了局部的解释。
梯度可能会受到饱和区域(例如,sigmoid激活函数的极端值)的影响,导致梯度消失或爆炸。
因此,当使用梯度来解释神经网络决策时,应该谨慎,并结合其他解释性技术一起使用。

五
多层感知机(MLP)是一个由多个全连接层组成的神经网络,它可以学习输入特征的非线性组合以进行预测。在MLP中,每个输入特征(在本例中是5个条件)通过隐藏层被非线性地变换,并且每一层的权重表示了特征或变换后的特征在下一层中的重要性。然而,直接解释MLP中单个输入特征对输出的影响力是复杂的,因为特征在隐藏层中被组合和变换。
尽管如此,一种近似的方法是通过查看训练好的MLP模型中第一层的权重来估计每个输入条件的影响力。这些权重可以被视为网络如何初始地结合条件来形成后续层输入的表示。但请注意,这只是影响力的一个非常粗糙的估计,因为它不考虑后续层中的复杂交互和非线性变换。
以下是一个使用PyTorch实现的多层感知机模型的示例,该模型接受5个条件作为输入,并输出一个预测值,表示事情发生的可能性。在训练结束后,我们将打印出第一层的权重作为每个条件影响力的近似。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
# 假设我们有5个条件作为输入特征
num_conditions = 5
# 隐藏层的大小
hidden_size = 10
# 输出层的大小(二分类问题,所以输出为1)
output_size = 1
# 生成一些模拟数据
np.random.seed(0)
X = np.random.randn(100, num_conditions) # 100个样本,每个样本有5个条件
y = np.random.randint(2, size=(100, output_size)) # 100个样本的随机二分类标签
# 将numpy数组转换为PyTorch张量
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32).view(-1, 1)
# 定义多层感知机模型
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size) # 第一层全连接
self.fc2 = nn.Linear(hidden_size, output_size) # 第二层全连接
def forward(self, x):
x = F.relu(self.fc1(x)) # 第一层后使用ReLU激活函数
x = torch.sigmoid(self.fc2(x)) # 输出层使用sigmoid激活函数,将输出限制在0和1之间
return x
# 实例化模型
model = MLP(num_conditions, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.BCELoss() # 使用二元交叉熵作为损失函数
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_tensor)
loss = criterion(outputs, y_tensor)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 训练完成后,打印第一层的权重作为每个条件影响力的近似
print("Approximate influence of each condition (based on first layer weights):")
for i, weight in enumerate(model.fc1.weight.data.mean(dim=0)):
print(f"Condition {i+1}: {weight.item()}")请注意,这个例子中的“影响力”是通过取第一层权重矩阵每一列的平均值来计算的。这只是一种启发式方法,并不准确反映每个条件对最终输出的实际影响力,因为它忽略了网络中后续层的复杂性和非线性。在实际应用中,可能需要使用更复杂的方法来分析神经网络中的特征重要性,如集成梯度(Integrated Gradients)或排列特征重要性(Permutation Feature Importance)。










![[图解]分层架构是DDD提出的吗](https://img-blog.csdnimg.cn/direct/08a7fdb1cf1a483994e15e3580c28066.png)