AlexNet
参考资料:
(1)ImageNet十年历任霸主之AlexNet - 知乎 (zhihu.com)
(2)AlexNet - Wikipedia
引入
AlexNet在2012年以第一名在Top-1分类精度霸榜ImageNet,并超过第二名近10个百分点,并且值得说明的是,霸榜2013年的ZFNet也就是对AlexNet进行调参后得到了更好的结果。相比于古早的LeNet实现的十分类,AlexNet能够成功进行一千分类并且达到了一个新高度。此外,AlexNet证明了神经网络的深度对模型效果至关重要,并且可以利用GPU大大加速这一过程。AlexNet虽然相比于VGG的热度和知名度没有那么高(值得说明的是已经相当高了),但是个人认为其里程碑的意义要比VGG高。其效果虽然逊于VGG,但是无论是归一化的思想,还是Dropout、ReLU的应用,亦或是深层网络利用GPU加速,为后续各项研究提供了一个很好的研究基础。
模型结构

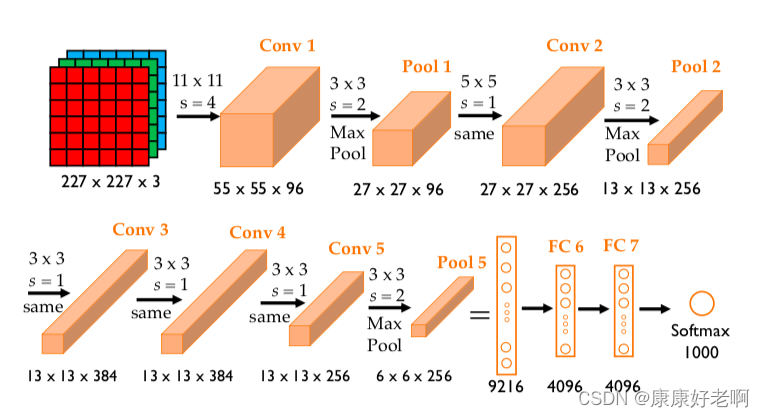
AlexNet 包含八层:前五层是卷积层,其中一些是最大池化层,后三层是全连接层。除最后一层外,网络被拆分为两个部分,每个部分在一个 GPU 上运行。整个结构可以写成:
(
C
N
N
→
L
R
N
→
M
P
)
2
→
(
C
N
N
3
→
M
P
)
→
(
F
C
→
D
O
)
2
→
L
i
n
e
a
r
→
S
o
f
t
m
a
x
(CNN→LRN→MP)^2→(CNN^3→MP)→(FC→DO)^2→Linear→Softmax
(CNN→LRN→MP)2→(CNN3→MP)→(FC→DO)2→Linear→Softmax
其中各个字母分别代表着:
- CNN = 卷积层(后面紧接着激活函数 ReLU)
- LRN = 局部响应归一化(Local Response Normalization)
- MP = 最大池化(Maxpooling)
- FC = 全连接层(后面紧接着激活函数 ReLU)
- 线性 = 全连接层(未激活)
- DO = 随机丢失(Dropout)
更为详细的结构图如下图所示:
Local Response Normalization
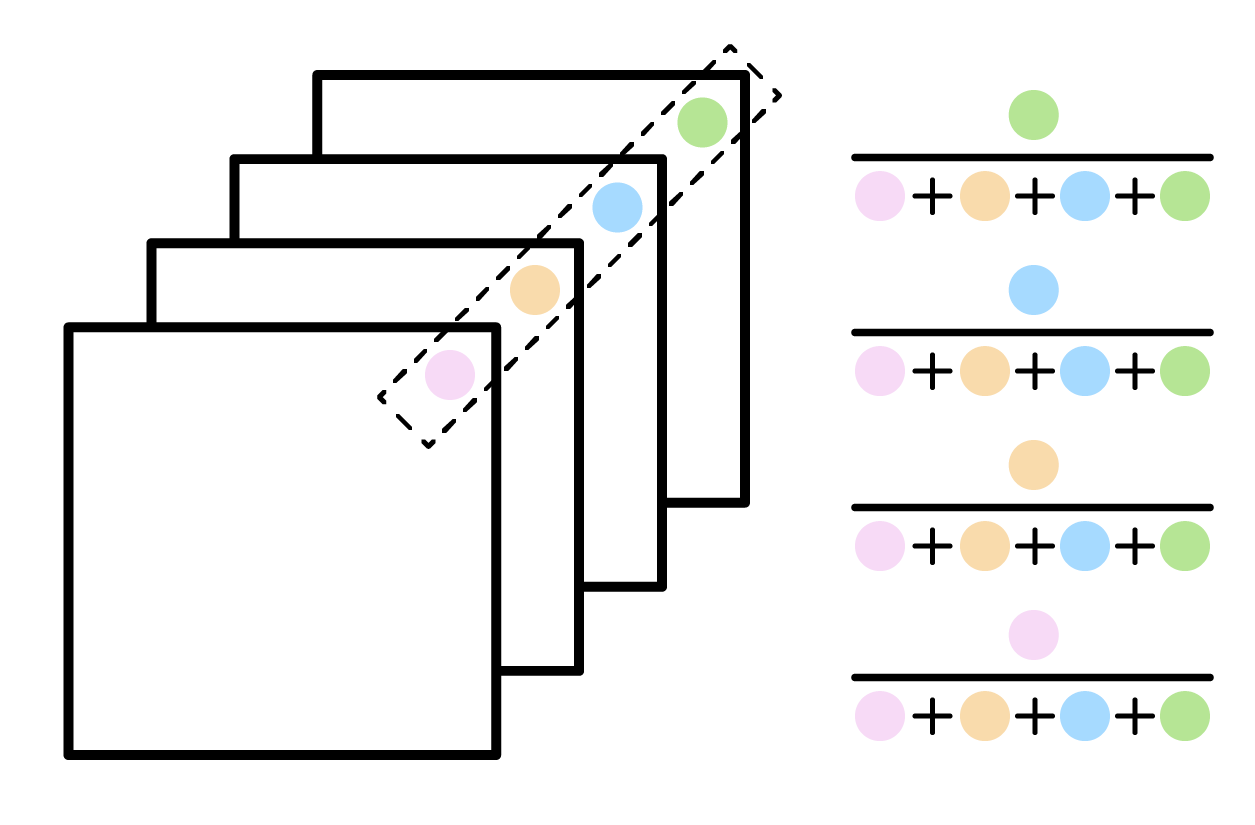
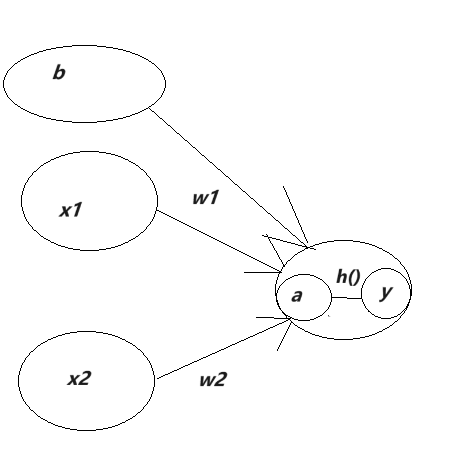
Local Response Normalization是一种归一化方式,主要针对的是卷积核不同通道上相同位置的参数。用数学公式表示就是:
b
x
,
y
i
=
a
x
,
y
i
/
(
k
+
α
∑
j
=
m
a
x
(
0
,
i
−
n
2
)
j
=
m
i
n
(
N
−
1
,
i
+
n
2
)
a
x
,
y
j
2
)
β
b^i_{x,y}=a^i_{x,y}/(k+\alpha\sum_{j=max(0,i-\frac{n}{2})}^{j=min(N-1,i+\frac{n}{2})}{a^j_{x,y}}^2)^\beta
bx,yi=ax,yi/(k+αj=max(0,i−2n)∑j=min(N−1,i+2n)ax,yj2)β
其中
a
x
,
y
i
a^i_{x,y}
ax,yi是第
i
i
i个卷积核上位置为
(
x
,
y
)
(x,y)
(x,y)的输入参数,
b
x
,
y
i
b^i_{x,y}
bx,yi是第
i
i
i个卷积核上位置为
(
x
,
y
)
(x,y)
(x,y)的输出参数,
N
N
N是总卷积核的数量,
n
n
n是归一化邻居数量(因为可能不是同时对所有卷积核/通道进行归一化),
α
,
β
,
k
\alpha,\beta,k
α,β,k是超参数。在论文中,采用的是𝑘=2, 𝑛=5, 𝛼=0.0001, 𝛽=0.75的值。
这一操作对于像AlexNet这种深层次网络比较必要,因为AlexNet会使用上百个通道,使用这种归一化可以一定程度上帮助模型收敛(类似于数据预处理中的归一化的作用)。从神经科学角度上来看,归一化可以看成是神经元群体之前相互抑制作用。
ReLU
ReLU是由一个分段函数组成的,在自变量小于0的部分恒等于0,在自变量大于0的部分等于自变量,即 R e L U = m a x ( 0 , x ) ReLU=max(0,x) ReLU=max(0,x)。相比于Sigmoid,ReLU更容易收敛,且由于梯度比较容易求(大于0的导数恒为1)。当因变量很大的时候,经过Sigmoid激活后基本都接近于1,导致梯度消失,而ReLU会避免这种情况。
Dropout
Dropout即在训练过程中(注意预测的时候不使用),按照特定概率随机丢失一定的神经元数据,这样可以有效降低过拟合,但是其代价是可能会导致模型收敛的epoch数更多。
实现代码
Pytorch框架中的torchvision库可以很方便的对其进行调用和实现。模型结构如下:
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
值得说明的是,现在Pytorch库中的AlexNet并不是原论文提出的模型,而是一种经过参数调整后效果更好一些的模型。如果要封装成一个类,并控制输出的维度,可以使用如下代码:
import torch.nn as nn
import torchvision.models as models
from torchvision.models.alexnet import AlexNet_Weights
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.alexnet = models.alexnet(weights=AlexNet_Weights.IMAGENET1K_V1)
self.dim_feat = 1000
self.alexnet.classifier[2] = nn.Linear(4096, 1000)
def forward(self, x):
output = self.alexnet(x)
return output