写在文章开头
在之前的文章中笔者简单的介绍了sharding-jdbc的使用,而本文从日常使用的角度出发来剖析一下sharding-jdbc底层是如何实现分页查询的。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

详解sharding-jdbc分页查询
前置步骤
之前的文章已经介绍过sharding-jdbc底层会通过重写数据源对应的prepareStament完成分表查询逻辑,而分页插件则是拦截SQL语句实现分页查询,所以使用sharding-jdbc进行分页查询只需引入用户所需的分页插件即可,以笔者为例,这里就直接使用pagehelper:
<!-- pagehelper 插件-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
</dependency>
分页查询代码示例
本文中笔者配置的分页算法是通过id取模的方式,假设我们的对应的user数据id为1,按照我们的算法,它将被存至1%3=1即user_1表:
##使用哪一列用作计算分表策略,我们就使用id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
##具体的分表路由策略,我们有3个user表,使用主键id取余3,余数0/1/2分表对应表user_0,user_2,user_2
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{id % 3}
笔者在实验表中插入大约100w的数据,进行一次分页查询,其中分页算法为id%3
@Test
void selectByPage() {
//查询第2页的数据10条
PageHelper.startPage(2, 10, false);
//查询结果按照id升序排列
UserExample userExample = new UserExample();
userExample.setOrderByClause("id asc");
//输出查询结果
List<User> userList = userMapper.selectByExample(userExample);
userList.forEach(System.out::println);
}
最终结果如下,可以看到查询结果和单表情况下是一样的,即从11~20:
User(id=11, name=user11, phone=)
User(id=12, name=user12, phone=)
User(id=13, name=user13, phone=)
User(id=14, name=user14, phone=)
User(id=15, name=user15, phone=)
User(id=16, name=user16, phone=)
User(id=17, name=user17, phone=)
User(id=18, name=user18, phone=)
User(id=19, name=user19, phone=)
User(id=20, name=user20, phone=)
详解sharding-jdbc对于分页查询的底层实现
按照正常的单表查询逻辑,假设我们要查询第2页的数据10条,我们对应的SQL就是:
select * from user limit (page-1)*10,size =>select * from user limit 10,10
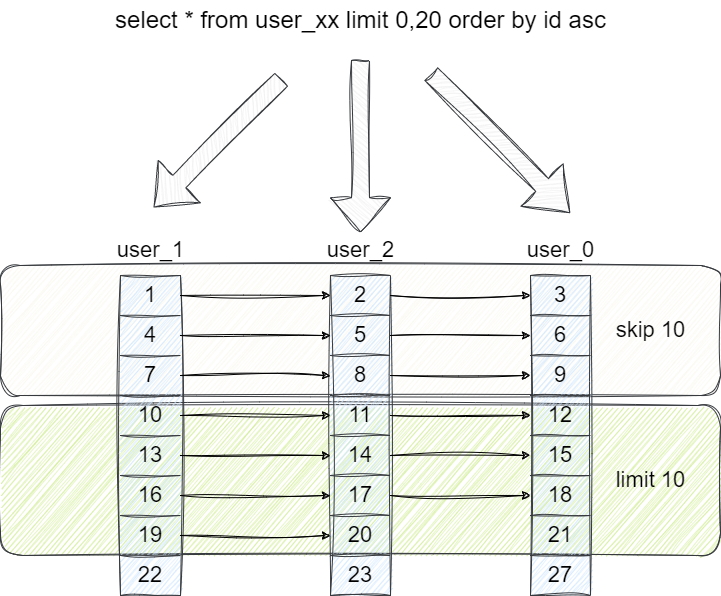
而sharding-jdbc分表分页查询则比较粗暴,它会将对应分页及之前的数据全部查询来,然后进行排序,跳过对应页码的数据后,再取出对应量级的数据返回。
以我们的分页查询为例,它会将每个分表的按照id进行升序排列之后取出各自的前20条数据,每张分表前20条数据之后,sharding-jdbc会根据我们的排序算法比对各张分表的第一条数据,很明显user_1对应的结果最小,所以按照此规则轮询分表的user_1、user_2、user_0以此将这3组结果存放至优先队列中。
基于这个队列,sharding-jdbc会按照分页查询的逻辑跳过10个,所以它会不断取出优先队列中的第一个元素,然后将这组分表结果再次存回队列,以我们的查询为例就是:
- 从
user_1取出id为1的值,作为skip的第一个元素。 - 将
user_1查询结果入队,因为头元素为4,和其他两组比最大,所以存放至队尾。 - 再次从优先队列中拿到
user_2的队首元素2,作为skip的第2个元素,然后再次存入队尾。 - 依次步骤完成跳过10个。
- 然后再按照这个规律筛选出10个,最终得到11~20。
源码印证
基于上述的图解,我们通过源码解析方式来印证,首先mybatis会基于我们的SQL调用execute方法获取查询结果,然后再通过handleResultSets生成列表并返回。
我们都知道sharding-jdbc通过自实现数据源的同时也给出对应的PreparedStatement即ShardingPreparedStatement,所以execute方法本质的执行者就是ShardingPreparedStatement,它会得到第2页之前的所有数据,然后通过handleResultSets进行skip和limit得到最终结果:
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
//调用sharding-jdbc的ShardingPreparedStatement的execute获取各个分表前2页的所有数据
ps.execute();
//通过skip结合limit得到所有结果
return resultSetHandler.handleResultSets(ps);
}
步入execute方法可以看到其内部本质是调用preparedStatementExecutor进行查询处理的:
@Override
public boolean execute() throws SQLException {
try {
clearPrevious();
//获取查询SQL
shard();
initPreparedStatementExecutor();
//执行SQL结果并返回
return preparedStatementExecutor.execute();
} finally {
clearBatch();
}
}
而该执行方法最终会走到ShardingExecuteEngine的parallelExecute方法,通过异步查询3张分表的结果,再通过外部传入的回调执行器处理这3个异步任务的查询结果:
private <I, O> List<O> parallelExecute(final Collection<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> firstCallback,
final ShardingGroupExecuteCallback<I, O> callback) throws SQLException {
Iterator<ShardingExecuteGroup<I>> inputGroupsIterator = inputGroups.iterator();
ShardingExecuteGroup<I> firstInputs = inputGroupsIterator.next();
//提交3个异步任务
Collection<ListenableFuture<Collection<O>>> restResultFutures = asyncGroupExecute(Lists.newArrayList(inputGroupsIterator), callback);
//通过回调执行器callback阻塞获取3个异步结果
return getGroupResults(syncGroupExecute(firstInputs, null == firstCallback ? callback : firstCallback), restResultFutures);
}
得到3张分表的数据之后,其内部逻辑最终会走到ShardingPreparedStatement的getResultSet方法,其内部会创建一个合并引擎DQLMergeEngine进行并调用getCurrentResultSet进行数据截取:
@Override
public ResultSet getResultSet() throws SQLException {
//......
if (routeResult.getSqlStatement() instanceof SelectStatement || routeResult.getSqlStatement() instanceof DALStatement) {
//反射创建分表合并引擎
MergeEngine mergeEngine = MergeEngineFactory.newInstance(connection.getShardingContext().getDatabaseType(),
connection.getShardingContext().getShardingRule(), routeResult, connection.getShardingContext().getMetaData().getTable(), queryResults);
//截取最终结果
currentResultSet = getCurrentResultSet(resultSets, mergeEngine);
}
return currentResultSet;
}
而该引擎就是DQLMergeEngine,进行合并操作时,会调用LimitDecoratorMergedResult跳过前10个元素:
private MergedResult decorate(final MergedResult mergedResult) throws SQLException {
Limit limit = routeResult.getLimit();
//......
//通过LimitDecoratorMergedResult跳过3张分表组合结果的前10个元素
if (DatabaseType.MySQL == databaseType || DatabaseType.PostgreSQL == databaseType || DatabaseType.H2 == databaseType) {
return new LimitDecoratorMergedResult(mergedResult, routeResult.getLimit());
}
//......
return mergedResult;
}
跳过的逻辑就比较简单了,LimitDecoratorMergedResult会调用合并引擎调用OrderByStreamMergedResult的next方法跳过前10个元素:
//LimitDecoratorMergedResult的skipOffset跳过10个元素
private boolean skipOffset() throws SQLException {
for (int i = 0; i < limit.getOffsetValue(); i++) {
//调用OrderByStreamMergedResult跳过组合结果的前10个元素
if (!getMergedResult().next()) {
return true;
}
}
rowNumber = 0;
return false;
}
可以看到OrderByStreamMergedResult的逻辑就是我们上文所说的取出队列中的第一组查询结果的第一个元素,然后再将其存入队(因为取出第一个元素后,队首元素最大,这组结果会存至队尾),不断循环跳够10个:
@Override
public boolean next() throws SQLException {
//......
//取出队列中第一组分表查询结果的第一个元素
OrderByValue firstOrderByValue = orderByValuesQueue.poll();
//如果这组分表结果还有元素则将这组分表结果入队,因为队首元素最大,所以会存放至队尾
if (firstOrderByValue.next()) {
orderByValuesQueue.offer(firstOrderByValue);
}
//......
return true;
}
经过上述步骤跳过10个元素后,就要截取第二页的10个数据了,代码再次回到PreparedStatementHandler的handleResultSets方法,该方法会调用到DefaultResultSetHandler的handleRowValuesForSimpleResultMap方法,该方法会循环10个,通过resultSet.next()移到下一条数据的游标,然后生成对象存储到resultHandler中,最终通过这个resultHandler就可以看到我们分页查询的List:
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
ResultSet resultSet = rsw.getResultSet();
skipRows(resultSet, rowBounds);
//通过resultSet.next()方法调用
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);
Object rowValue = getRowValue(rsw, discriminatedResultMap, null);
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
而next方法本质还是调用LimitDecoratorMergedResult的next方法,以rowNumber 来计数,调用mergedResult的next方法将游标移动到要返回的数据,
@Override
public boolean next() throws SQLException {
//......
//同样基于优先队列取够10个
return ++rowNumber <= limit.getRowCountValue() && getMergedResult().next();
}
而OrderByStreamMergedResult的next逻辑和之前差不多,就是通过轮询优先队列中的每一组分表对象的队首元素,将其存到currentQueryResult中,后续进行对象创建时就会从currentQueryResult中拿到这个结果生成User对象存入List中返回:
@Override
public boolean next() throws SQLException {
//......
//从优先队列orderByValuesQueue拿到队首的一组分表查询结果
OrderByValue firstOrderByValue = orderByValuesQueue.poll();
//移动当前队列游标
if (firstOrderByValue.next()) {
orderByValuesQueue.offer(firstOrderByValue);
}
if (orderByValuesQueue.isEmpty()) {
return false;
}
//将当前优先队列中的队首元素的queryResult作为本次的查询结果,作为后续创建User对象的数据
setCurrentQueryResult(orderByValuesQueue.peek().getQueryResult());
return true;
}
存在的问题
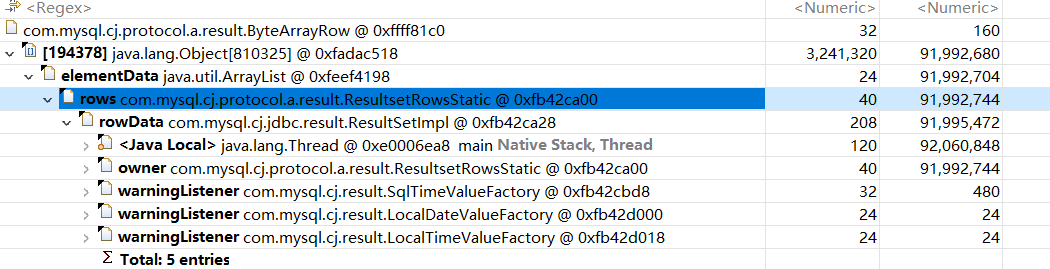
自此我们了解了sharding-jdbc分页查询的内部工作机制,这里我们顺便说一下这种算法的缺点,查阅官网说法是sharding-jdbc分页查询不会占用内存,说明查询结果仅仅记录的是游标:
首先,采用流式处理 + 归并排序的方式来避免内存的过量占用。由于SQL改写不可避免的占用了额外的带宽,但并不会导致内存暴涨。 与直觉不同,大多数人认为ShardingSphere会将1,000,010 * 2记录全部加载至内存,进而占用大量内存而导致内存溢出。 但由于每个结果集的记录是有序的,因此ShardingSphere每次比较仅获取各个分片的当前结果集记录,驻留在内存中的记录仅为当前路由到的分片的结果集的当前游标指向而已。 对于本身即有序的待排序对象,归并排序的时间复杂度仅为O(n),性能损耗很小。
但是笔者在使用过程中,打印内存快照时发现,进行500w数据的深分页查询发现,它的做法和我们上文源码所说的一致,就是将当前页以及之前的结果全部加载到内存中,所以笔者认为使用sharding-jdbc时还是需要注意一下对内存的监控:
小结
以上便是笔者对于sharding-jdbc分页查询的全部解析,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

参考
ShardingSphere分页查询官方文档:https://shardingsphere.apache.org/document/4.1.1/cn/features/sharding/use-norms/pagination/