文章目录
- 1.CrushMap规则拓扑结构
- 1.1.集群默认的CrushMap规则拓补图
- 1.2.自定义的CrushMap规则拓补图
- 2.定制CrushMap规则的方法以及注意事项
- 3.通过二进制文件编写一套CrushMap规则
- 3.1.将系统默认的CrushMap规则导出
- 3.2.根据需求编写CrushMap规则
- 3.3.将编写好的规则导入到集群中
- 3.4.查看新的CrushMap规则
- 3.5.创建Pool资源池写入数据观察存储效果
- 扩展:在定制的CrushMap规则之上添加默认的CrushMap规则
- 4.通过命令的方式创建一套CrushMap规则
- 4.1.首先将CrushMap规则还原
- 4.2.分别创建ssd和hdd两种磁盘类型的CrushMap
- 4.3.创建ssd以及hdd两种磁盘类型的Bucket
- 4.4.将同一类型的Bucket移动到一个CrushMap中
- 4.5.将OSD移动到对应的Bucket中
- 4.6.创建ssd以及hdd两种类型的Rule规则
- 4.7.将资源池应用的rule规则进行调整观察数据分布效果
- 5.CrushMap逻辑图
- 6.验证当OSD异常重启后会对CrushMap列表产生影响
- 7.报错现象
1.CrushMap规则拓扑结构
1.1.集群默认的CrushMap规则拓补图
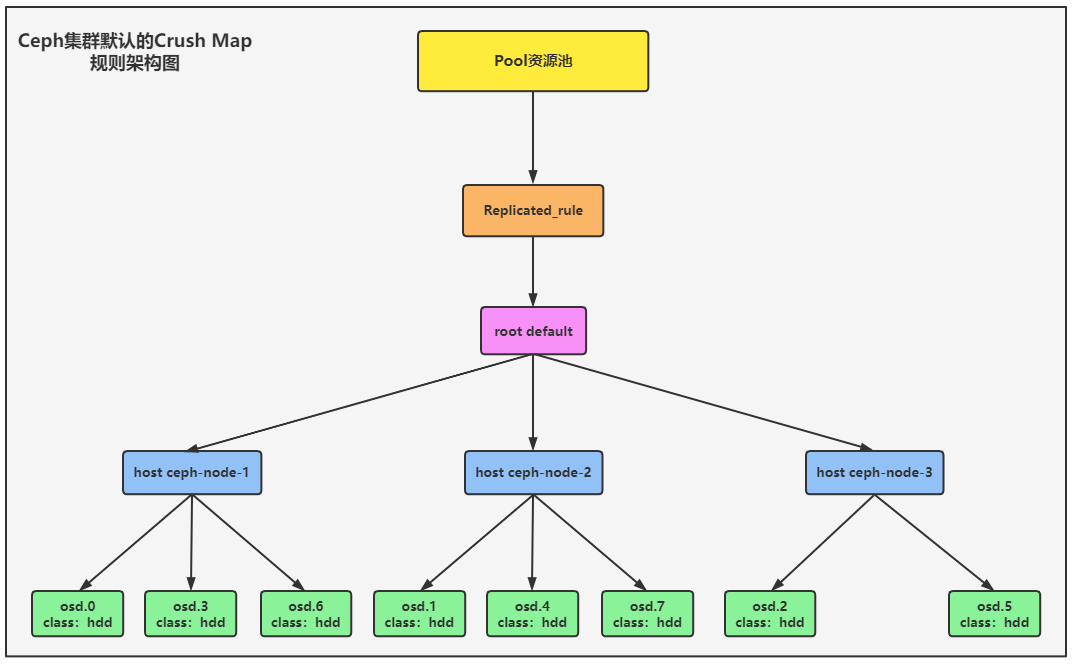
下图所展示的是Ceph集群默认的CrushMap规则的拓步结构,CrushMap使用的数据保护类型为root,名称叫做default,在这个CrushMap中是以Host集群节点来充当Bucket,每一个Bucket下都有很多的OSD。这个CrushMap被Replicated_rule角色进行关联。
创建Pool资源池的时候默认使用的就是这个角色,将来自己定制的一套CrushMap规则,如果想让所有的资源池都应用这个规则,可以将角色的名称设置为Replicated_rule,从而覆盖掉默认的规则。
1.2.自定义的CrushMap规则拓补图
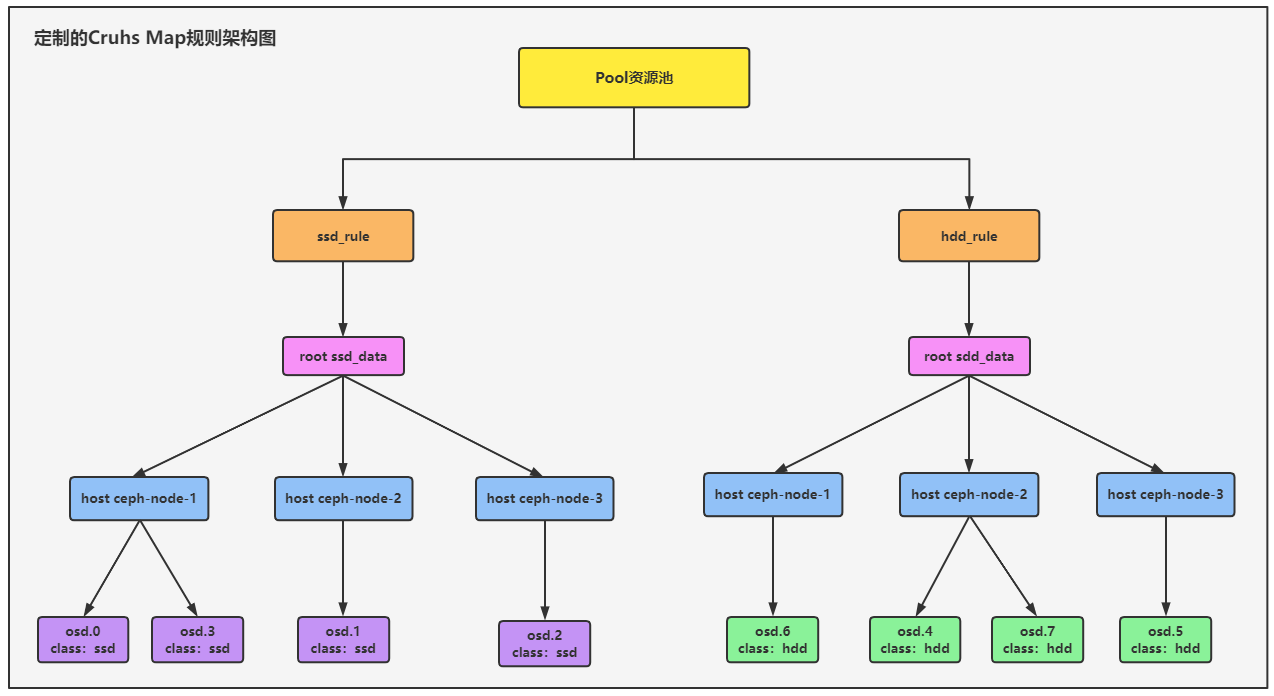
现在集群中有8个OSD,其中四个OSD是ssd的磁盘,另外四个OSD是hdd的磁盘,接下来我们会定义两套CrushMap规则,根据数据的重要性分别应用不同的CrushMap规则。
- 规则名称:ssd_data
- 该CrushMap规则会关联各个Ceph节点上类型是ssd磁盘的OSD,OSD的磁盘类型可以在Class类中定义,该条CrushMap规则会与ssd_rule角色进行关联,将数据重要性较高的Pool资源池应用ssd_rule这个角色,就可以将数据只落在ssd类型的OSD中。
- 规则名称:hdd_data
- 该CrushMap规则会关联各个Ceph节点上类型是hdd磁盘的OSD,OSD的磁盘类型可以在Class类中定义,该条CrushMap规则会与hdd_rule角色进行关联,将数据重要性一般的Pool资源池应用hdd_rule这个角色,就可以将数据只落在hdd类型的OSD中。
2.定制CrushMap规则的方法以及注意事项
定制CrushMap规则的方法:
手动编写CrushMap规则有两种方式:
- 将现有的CrushMap规则导出成二进制文件,然后反编译成文本文本,在文本文件中调整规则参数,最后在编译成二进制文件,导入到集群中。
- 通过命令来编写CrushMap规则,更倾向于前者。
定制CrushMap规则的注意事项:
-
CrushMap改动之前先备份!!!
-
CrushMap规则变动对数据影响比较大,最好在部署好集群无数据时就将CrushMap规则规划好,当集群中有数据之后,不要再去动Crush Map规则。
-
手动配置的CrushMap规则,当某个OSD重启或者发生了变化,都会影响整个Crush Map列表,这个OSD原本是属于我们新建的CrushMap规则,但是当该OSD重启后,会将该OSD自动移动到默认的CrushMap中,这个影响是非常大的。
-
解决方法就是配置一个OSD的参数,当OSD发生了变化不要去刷新CrushMap列表即可
1.在配置文件中增加这个osd的参数 [root@ceph-node-1 ~]# cd /data/ceph-deploy/ [root@ceph-node-1 ceph-deploy]# vim ceph.conf [osd] osd crush update on start = false 2.使用ceph-deploy工具推送到各个节点上 [root@ceph-node-1 ceph-deploy]# ceph-deploy --overwrite-conf config push ceph-node-1 ceph-node-2 ceph-node-3 3.重启所有节点的osd [root@ceph-node-1 ceph-deploy]# for i in {1..3}; do ssh ceph-node-${i} "systemctl restart ceph-osd.target" ; done -
配置完成后,当再有OSD发生变化时,都不会影响CrushMap列表。
-
-
当新的OSD加入集群后,不会自动添加到Bucket里,需要我们手动移动至对应的Bucket。
3.通过二进制文件编写一套CrushMap规则
推荐使用二进制文件的方式编写CrushMap规则,清晰明了,有备份。
通过二进制文件编写的CrushMap规则依赖于系统现有的CrushMap规则,需要先将默认的CrushMap导出成二进制文件,然后反编译成文本文件,在默认的规则文件中根据需求编写出新的CrushMap规则。
我们定制的CrushMap规则需求就是1.2中的拓补图,分为两种策略和两种规则,数据重要性较高的存储在ssd磁盘类型的OSD中,数据重要性一般的存储在hdd磁盘类型的OSD中。
3.1.将系统默认的CrushMap规则导出
1.导出系统默认的CrushMap规则
[root@ceph-node-1 ~]# ceph osd getcrushmap -o crushmap.bin
28
2.将二进制文件反编译成文本文件
[root@ceph-node-1 ~]# crushtool -d crushmap.bin -o crushmap.txt
3.2.根据需求编写CrushMap规则
打开规则文件后会发现和ceph osd crush dump命令显示的信息基本一样,涵盖五个主要组成部分,只不过导出来的文件都是参数并不是json格式了,更加清晰明了、方便我们配置。
CrushMap规则编写其实很简单:
1)首先将OSD设备在devices中进行定义,并为每一个OSD设置一个Class类。
2)然后定义Bucket列表,将每一个节点中不同类型的OSD都进行详细的划分。
3)将同一种OSD类型的Bucket组成一个逻辑分组,也就是CrushMap策略。
4)最后定义一个规则与CrushMap进行关联即可。
CrushMap规则每一部分定义的概念都进行了详细的解释。
[root@ceph-node-1 ~]# cat crushmap.txt
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
#在devices中配置集群的OSD设备,将磁盘类型为ssd的OSD配置Class类为ssd,磁盘类型为hdd的OSD配置Class类为hdd。
#根据拓补图,将osd0/1/2/3的class类配置成ssd,将osd4/5/6/7的class类设置成hdd。
device 0 osd.0 class ssd
device 1 osd.1 class ssd
device 2 osd.2 class ssd
device 3 osd.3 class ssd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
# types
#可配置的数据保护类型,不需要懂。
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
#bucket类型使用的是Host节点类型,在bucket中定义各个节点和OSD的信息
#每个节点的ID号可以手动配置也可以删除字段,由Ceph自己生成。
host ceph-node-1-ssd { #bucket的名称,每个节点中都有ssd和hdd的盘,因此起名字的时候依旧是以节点名称+ssd进行命名的
id -13 #id可以自定义也可以自动生成
id -14 class ssd #这里的class类是为ceph-node-1-ssd bucket设置的,不会覆盖osd设置的class
# weight 0.029 #权重直接注释,由ceph自动分配
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.010 #在item中填写这个bucket要管理的osd信息,将这个节点的ssd类型的osd都添加进来
item osd.3 weight 0.010
}
#下面的bucket的配置思路都是如此↑↑↑↑↑↑↑↑↑↑↑↑↑
host ceph-node-2-ssd {
id -15
id -16 class ssd
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.1 weight 0.010
}
host ceph-node-3-ssd {
id -17
id -18 class ssd
# weight 0.020
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.010
}
#下面的三个bucket就是hdd类型的OSD配置。
host ceph-node-1-hdd {
id -23
id -24 class hdd
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.6 weight 0.010
}
host ceph-node-2-hdd {
id -25
id -26 class hdd
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.4 weight 0.010
item osd.7 weight 0.010
}
host ceph-node-3-hdd {
id -27
id -28 class hdd
# weight 0.020
alg straw2
hash 0 # rjenkins1
item osd.5 weight 0.010
}
#map
#定义完bucket后,需要定义一组CrushMap,相当于路由分组策略,将同一类的bucket集合在一起。
root ssd_data { #定义分组的名称也就是crushmap的名称,这一组是关于ssd磁盘类型
#id -11 #id都可以注释掉,由系统生成
#id -12 class sdd #这里的class不配置系统也会自动生成
# weight 0.078
alg straw2
hash 0 # rjenkins1
item ceph-node-1-ssd #weight 0.029 #在item中关联这个分组下的bucket
item ceph-node-2-ssd #weight 0.029
item ceph-node-3-ssd #weight 0.020
}
root hdd_data { #hdd磁盘类型的crushmap
# weight 0.078
alg straw2
hash 0 # rjenkins1
item ceph-node-1-hdd #weight 0.029 #关联hdd类型的bucket
item ceph-node-2-hdd #weight 0.029
item ceph-node-3-hdd #weight 0.020
}
# rules
#pool资源池最终使用哪一个crushmap策略存储数据主要是通过rule规则来指定的,因此还需要将crushmap与具体的rule规则进行绑定。
rule ssd_rule { #ssd类型的rule规则
id 0 #rule的id必须指定,并且必须有一个rule的id为0,因为现有pool关联的规则id就是0,如果没有id为0的rule,新规则将无法导入。
type replicated
min_size 1
max_size 10
step take ssd_data #关联ssd类型的crushmap
step chooseleaf firstn 0 type host
step emit
}
rule hdd_rule { #hdd类型的rule规则
id 40
type replicated
min_size 1
max_size 10
step take hdd_data #关联hdd类型的crushmap
step chooseleaf firstn 0 type host
step emit
}
# end crush map
3.3.将编写好的规则导入到集群中
将新规则导入到集群之前,先将默认规则备份好,以便出现问题及时还原。
1.将文本文件编译成二进制文件
[root@ceph-node-1 ~]# crushtool -c crushmap.txt -o crushmap-new.bin
2.将规则导入到系统中
[root@ceph-node-1 ~]# ceph osd setcrushmap -i crushmap-new.bin
3.4.查看新的CrushMap规则
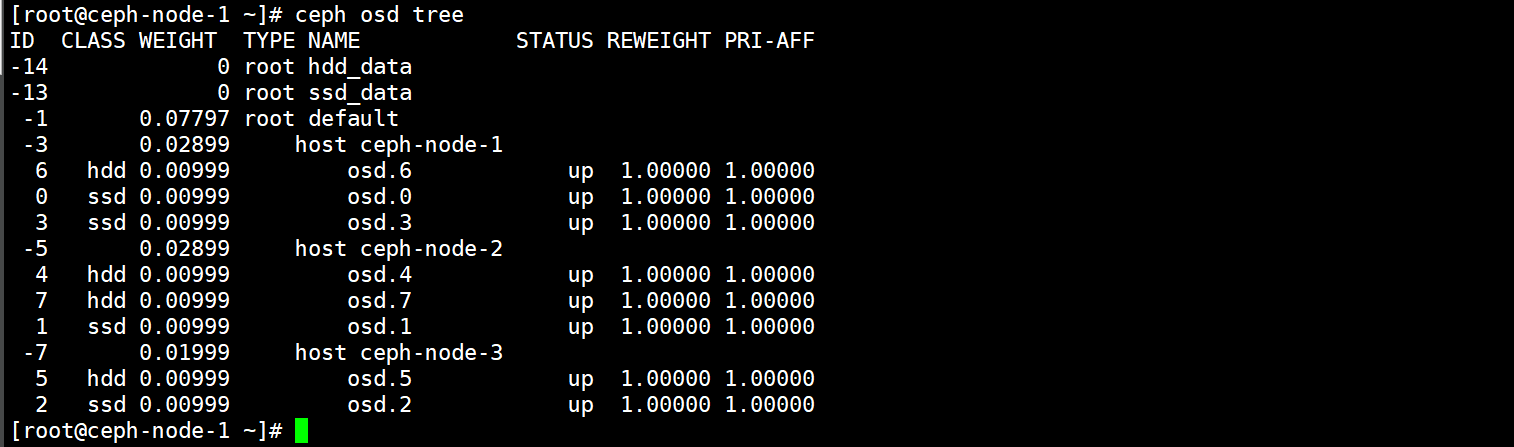
已经是应用上新的CrushMap规则了,两种CrushMap规则以及六个Bucket列表。
[root@ceph-node-1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-2 0.03998 root hdd_data
-23 0.00999 host ceph-node-1-hdd
6 hdd 0.00999 osd.6 up 1.00000 1.00000
-25 0.01999 host ceph-node-2-hdd
4 hdd 0.00999 osd.4 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
-27 0.00999 host ceph-node-3-hdd
5 hdd 0.00999 osd.5 up 1.00000 1.00000
-1 0.03998 root ssd_data
-13 0.01999 host ceph-node-1-ssd
0 ssd 0.00999 osd.0 up 1.00000 1.00000
3 ssd 0.00999 osd.3 up 1.00000 1.00000
-15 0.00999 host ceph-node-2-ssd
1 ssd 0.00999 osd.1 up 1.00000 1.00000
-17 0.00999 host ceph-node-3-ssd
2 ssd 0.00999 osd.2 up 1.00000 1.00000
并且角色也是我们定义的ssd_rule和hdd_rule两个。
[root@ceph-node-1 ~]# ceph osd crush rule ls
ssd_rule
hdd_rule
由于定义规则是ssd_data角色的id设置的是0,应用新规则后,Pool资源池关联的角色也会随之发生变化。
[root@ceph-node-1 ~]# ceph osd pool get cephfs_data crush_rule
crush_rule: ssd_rule
到这里可以看到,系统默认的规则已经被覆盖掉了,所以在应用新规则之前先将默认的备份。
切换新规则后,Ceph中的数据会进行同步应用此规则,因此一定要在系统没有数据的情况下改变CrushMap规则。
3.5.创建Pool资源池写入数据观察存储效果
1)在应用ssd_data角色的Pool资源池中写入数据观察分布效果
ssd_data角色的ID为0,现在所有的Pool资源池都应用的这个角色,随便找一个资源池创建一个块设备文件就可以看到数据的分布效果了。
1.写入文件
[root@ceph-node-1 ~]# rbd create cephfs_data/test.img --size 1G
2.查看CrushMap规则
[root@ceph-node-1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-2 0.03998 root hdd_data
-23 0.00999 host ceph-node-1-hdd
6 hdd 0.00999 osd.6 up 1.00000 1.00000
-25 0.01999 host ceph-node-2-hdd
4 hdd 0.00999 osd.4 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
-27 0.00999 host ceph-node-3-hdd
5 hdd 0.00999 osd.5 up 1.00000 1.00000
-1 0.03998 root ssd_data
-13 0.01999 host ceph-node-1-ssd
0 ssd 0.00999 osd.0 up 1.00000 1.00000
3 ssd 0.00999 osd.3 up 1.00000 1.00000
-15 0.00999 host ceph-node-2-ssd
1 ssd 0.00999 osd.1 up 1.00000 1.00000
-17 0.00999 host ceph-node-3-ssd
2 ssd 0.00999 osd.2 up 1.00000 1.00000
3.查看数据的分布情况
[root@ceph-node-1 ~]# ceph osd map cephfs_data test.img
osdmap e897 pool 'cephfs_data' (9) object 'test.img' -> pg 9.bfa48b9e (9.e) -> up ([2,0,1], p2) acting ([2,0,1], p2)
通过查看数据的分布情况,就可以看到数据由3个副本,这三个副本分布写入在了ID为2、0、1这三个OSD中,这三个OSD就属于ssd_rule这个角色所关联的crush map。
2)在应用hdd_data角色的Pool资源池中写入数据观察分布效果
1.创建一个pool关联hdd_data角色
[root@ceph-node-1 ~]# ceph osd pool create pool-test 10 10
pool 'pool-test' created
[root@ceph-node-1 ~]# ceph osd pool set pool-test crush_rule hdd_rule
set pool 11 crush_rule to hdd_rule
2.写入数据
[root@ceph-node-1 ~]# rbd create pool-test/test.img --size 1G
3.查看数据的分布情况
[root@ceph-node-1 ~]# ceph osd map pool-test test.img
osdmap e905 pool 'pool-test' (11) object 'test.img' -> pg 11.bfa48b9e (11.6) -> up ([6,4,5], p6) acting ([6,4,5], p6)
pool-test资源池应用hdd_rule角色后,在资源池中写入的数据最终落入到了ID为6、4、5的OSD中,这三个OSD都属于hdd类型的OSD,到此也验证了可以根据数据的重要程度,在创建资源池时就指定应用那种类型的CrushMap,对数据进行合理的分布式存储。
扩展:在定制的CrushMap规则之上添加默认的CrushMap规则
我们可以在CrushMap中即添加自定义的规则也可以保留默认的CrushMap规则,创建的Pool自动应用默认规则,根据数据的特殊性再选择不同的CrushMap算法。
完整的文件内容:
[root@ceph-node-1 ~]# cat crushmap-default.txt
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class ssd
device 1 osd.1 class ssd
device 2 osd.2 class ssd
device 3 osd.3 class ssd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host ceph-node-1-ssd {
id -13 # do not change unnecessarily
id -14 class ssd # do not change unnecessarily
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.010
item osd.3 weight 0.010
}
host ceph-node-2-ssd {
id -15 # do not change unnecessarily
id -16 class ssd # do not change unnecessarily
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.1 weight 0.010
}
host ceph-node-3-ssd {
id -17 # do not change unnecessarily
id -18 class ssd # do not change unnecessarily
# weight 0.020
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.010
}
host ceph-node-1-hdd {
id -23 # do not change unnecessarily
id -24 class hdd # do not change unnecessarily
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.6 weight 0.010
}
host ceph-node-2-hdd {
id -25 # do not change unnecessarily
id -26 class hdd # do not change unnecessarily
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.4 weight 0.010
item osd.7 weight 0.010
}
host ceph-node-3-hdd {
id -27 # do not change unnecessarily
id -28 class hdd # do not change unnecessarily
# weight 0.020
alg straw2
hash 0 # rjenkins1
item osd.5 weight 0.010
}
###########################默认bucket###########################
host ceph-node-1 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.010
item osd.3 weight 0.010
item osd.6 weight 0.010
}
host ceph-node-2 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.1 weight 0.010
item osd.4 weight 0.010
item osd.7 weight 0.010
}
host ceph-node-3 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 0.020
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.010
item osd.5 weight 0.010
}
#map
root ssd_data {
#id -11 # do not change unnecessarily
#id -12 class sdd # do not change unnecessarily
# weight 0.078
alg straw2
hash 0 # rjenkins1
item ceph-node-1-ssd #weight 0.029
item ceph-node-2-ssd #weight 0.029
item ceph-node-3-ssd #weight 0.020
}
root hdd_data {
# weight 0.078
alg straw2
hash 0 # rjenkins1
item ceph-node-1-hdd #weight 0.029
item ceph-node-2-hdd #weight 0.029
item ceph-node-3-hdd #weight 0.020
}
###########################默认map###########################
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.078
alg straw2
hash 0 # rjenkins1
item ceph-node-1 weight 0.029
item ceph-node-2 weight 0.029
item ceph-node-3 weight 0.020
}
# rules
rule ssd_rule {
id 30
type replicated
min_size 1
max_size 10
step take ssd_data
step chooseleaf firstn 0 type host
step emit
}
rule hdd_rule {
id 40
type replicated
min_size 1
max_size 10
step take hdd_data
step chooseleaf firstn 0 type host
step emit
}
###########################默认rule###########################
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush map
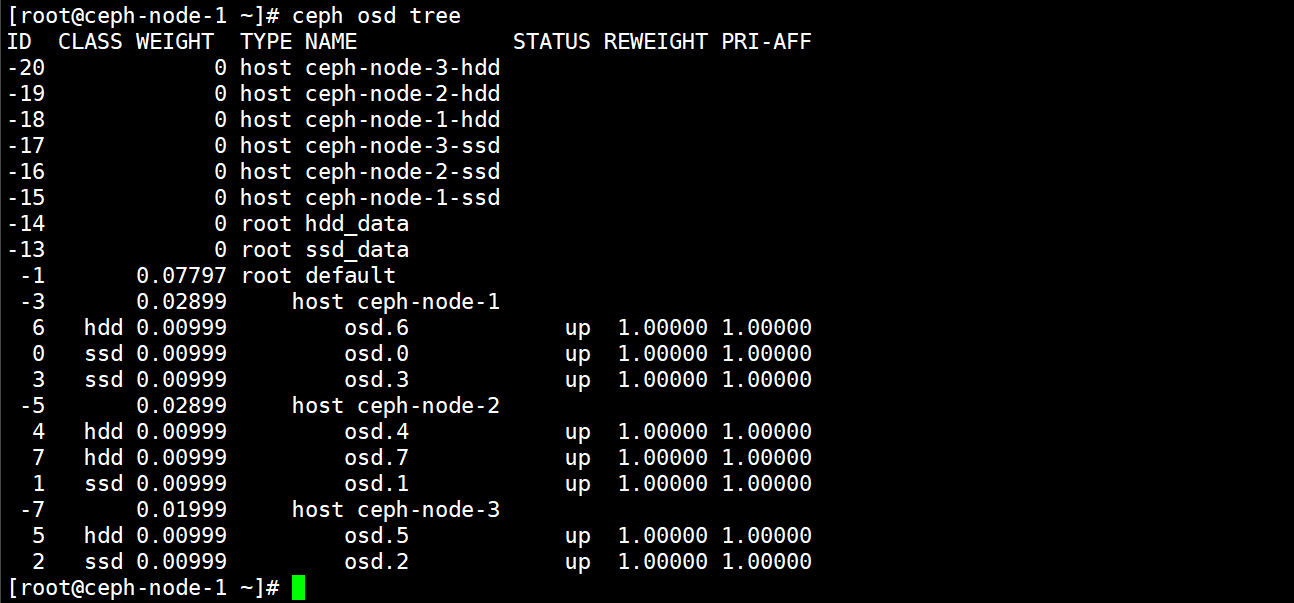
导入系统后CrushMap列表如下所示,既包含默认的CrushMap又包含自定义的CrushMap。
[root@ceph-node-1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-10 0.03998 root hdd_data
-23 0.00999 host ceph-node-1-hdd
6 hdd 0.00999 osd.6 up 1.00000 1.00000
-25 0.01999 host ceph-node-2-hdd
4 hdd 0.00999 osd.4 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
-27 0.00999 host ceph-node-3-hdd
5 hdd 0.00999 osd.5 up 1.00000 1.00000
-9 0.03998 root ssd_data
-13 0.01999 host ceph-node-1-ssd
0 ssd 0.00999 osd.0 up 1.00000 1.00000
3 ssd 0.00999 osd.3 up 1.00000 1.00000
-15 0.00999 host ceph-node-2-ssd
1 ssd 0.00999 osd.1 up 1.00000 1.00000
-17 0.00999 host ceph-node-3-ssd
2 ssd 0.00999 osd.2 up 1.00000 1.00000
-1 0.07797 root default
-3 0.02899 host ceph-node-1
6 hdd 0.00999 osd.6 up 1.00000 1.00000
0 ssd 0.00999 osd.0 up 1.00000 1.00000
3 ssd 0.00999 osd.3 up 1.00000 1.00000
-5 0.02899 host ceph-node-2
4 hdd 0.00999 osd.4 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
1 ssd 0.00999 osd.1 up 1.00000 1.00000
-7 0.01999 host ceph-node-3
5 hdd 0.00999 osd.5 up 1.00000 1.00000
2 ssd 0.00999 osd.2 up 1.00000 1.00000
4.通过命令的方式创建一套CrushMap规则
拓补图:
通过命令创建CrushMap的步骤:
1)首先创建出root类型的Bucket充当CrushMap。
2)在CrsuhMap下添加节点类型的Bucket。
3)将OSD移动到对应的Bucket下。
4)创建Rule规则关联上对应的CrushMap。
4.1.首先将CrushMap规则还原
[root@ceph-node-1 ~]#ceph osd setcrushmap -i crushmap-new.bin
4.2.分别创建ssd和hdd两种磁盘类型的CrushMap
首先将CrushMap创建出来,CrushMap相当于Bucket的分组,现有组,再有成员。
命令格式:ceph osd crush add-bucket {crushmap_name} {保护类型}
创建CrushMap和创建Bucket的命令一样,那是因为CrushMap也可以是一个Bucket,只不过CrushMap的类型一般都会设置成root,顶级,其余的Bucket都是root以下级别的类型,也就是说其他的类型的Bucket都可以加入到这个root类型的Bucket中,从而这个Bucket就成为了Bucket中的管理者,也就成为了CrushMap。
1.创建ssd的CrushMap
[root@ceph-node-1 ~]# ceph osd crush add-bucket ssd_data root
added bucket ssd_data type root to crush map
2.创建hdd的CrushMap
[root@ceph-node-1 ~]# ceph osd crush add-bucket hdd_data root
added bucket hdd_data type root to crush map
两种类型的CrushMap创建完成。
4.3.创建ssd以及hdd两种磁盘类型的Bucket
命令格式和CrushMap一致。
每个节点中都有ssd和hdd两种磁盘类型的OSD,因此要对每个节点都创建出Bucket,以主机类型定义。
1.创建ssd磁盘类型的主机bucket
[root@ceph-node-1 ~]# ceph osd crush add-bucket ceph-node-1-ssd host
added bucket ceph-node-1-ssd type host to crush map
[root@ceph-node-1 ~]# ceph osd crush add-bucket ceph-node-2-ssd host
added bucket ceph-node-2-ssd type host to crush map
[root@ceph-node-1 ~]# ceph osd crush add-bucket ceph-node-3-ssd host
added bucket ceph-node-3-ssd type host to crush map
2.创建hdd磁盘类型的主机bucket
[root@ceph-node-1 ~]# ceph osd crush add-bucket ceph-node-1-hdd host
added bucket ceph-node-1-hdd type host to crush map
[root@ceph-node-1 ~]# ceph osd crush add-bucket ceph-node-2-hdd host
added bucket ceph-node-2-hdd type host to crush map
[root@ceph-node-1 ~]# ceph osd crush add-bucket ceph-node-3-hdd host
added bucket ceph-node-3-hdd type host to crush map
每种类型的Bucket都已经创建了,但是这些Bucket都人为自己就是一个CrushMap,我们需要将同一种类的Bucket移动到一个CrushMap中。
4.4.将同一类型的Bucket移动到一个CrushMap中
CrushMap是Bucket的管理者,将ssd类型的磁盘所在节点Bucket移动到ssd的Crush Map中,将hdd类型的磁盘所在节点Bucket移动到hdd的Crush Map中。
只有将这些Bucket放到CrushMap逻辑分组下,才能被Rule规则进行关联,将数据按着规则存储在CrushMap关联的多个OSD中。
命令格式:ceph osd crush move {bucket_name} root={crushmap_name}
1.将ssd类型的Bucket移动到ssd的CrushMap中
[root@ceph-node-1 ~]# ceph osd crush move ceph-node-1-ssd root=ssd_data
moved item id -15 name 'ceph-node-1-ssd' to location {root=ssd_data} in crush map
[root@ceph-node-1 ~]# ceph osd crush move ceph-node-2-ssd root=ssd_data
moved item id -16 name 'ceph-node-2-ssd' to location {root=ssd_data} in crush map
[root@ceph-node-1 ~]# ceph osd crush move ceph-node-3-ssd root=ssd_data
moved item id -17 name 'ceph-node-3-ssd' to location {root=ssd_data} in crush map
1.将hdd类型的Bucket移动到hdd的CrushMap中
[root@ceph-node-1 ~]# ceph osd crush move ceph-node-1-hdd root=hdd_data
moved item id -18 name 'ceph-node-1-hdd' to location {root=hdd_data} in crush map
[root@ceph-node-1 ~]# ceph osd crush move ceph-node-2-hdd root=hdd_data
moved item id -19 name 'ceph-node-2-hdd' to location {root=hdd_data} in crush map
[root@ceph-node-1 ~]# ceph osd crush move ceph-node-3-hdd root=hdd_data
moved item id -20 name 'ceph-node-3-hdd' to location {root=hdd_data} in crush map
注意:这里执行移动命令时,是将host类型的bucket移动到了root类型的bucket里,root类型的bucket是顶级根,相当于组长,其余任何类型的bucket都可以移动到root类型的bucket中,root类型的bucket无法再次移动,因为已经是最顶级。
再次观察CrushMap列表,会发现规则基本成型,就剩下添加OSD了。
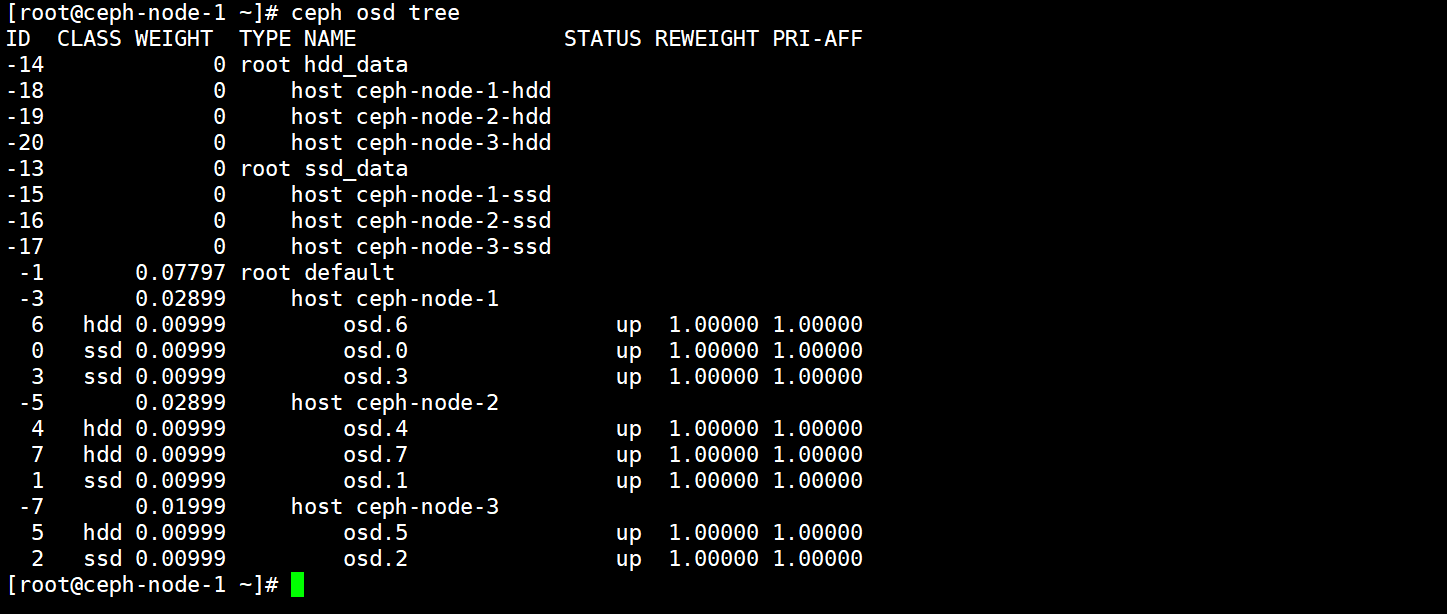
4.5.将OSD移动到对应的Bucket中
通过命令创建的CrushMap规则,一个OSD只能放在一个Bucket中,通过二进制文件创建的CrushMap,一个OSD可以与多个Bucket进行绑定。
两种将OSD移动到对应Bucket的方法:
-
通过创建的方式,使用命令管理OSD时,创建就相当于移动,因为OSD已经是在CrushMap中了,通过创建的方式也可以将OSD移动到对应的Bucket中。
-
命令格式:
ceph osd crush set {osc_name} {weight} root={crushmap_name} host={host_name} -
例子:
-
ceph osd crush set osd.0 0.00999 root=ssd_data host=ceph-node-1-ssd
-
-
-
直接使用移动命令。
- 命令格式:
ceph osd crush move {osd_name} root={crushmap_name} host={host_name}
- 命令格式:
下面分别通过这两种方式将OSD移动到对应的Bucket中。
1)将ssd类型的OSD移动到ssd类型的Bucket中
ssd类型的osd有0、3、1、4这四个,ID为0、3的两个OSD位于ceph-node-1节点,其余两个分别在ceph-node-2和ceph-node-3中。
使用创建OSD的方式将OSD添加到对应的Bucket中。
#ceph-node-1 Bucket
[root@ceph-node-1 ~]# ceph osd crush set osd.0 0.00999 root=ssd_data host=ceph-node-1-ssd
set item id 0 name 'osd.0' weight 0.00999 at location {host=ceph-node-1-ssd,root=ssd_data} to crush map
[root@ceph-node-1 ~]# ceph osd crush set osd.3 0.00999 root=ssd_data host=ceph-node-1-ssd
set item id 3 name 'osd.3' weight 0.00999 at location {host=ceph-node-1-ssd,root=ssd_data} to crush map
#ceph-node-2 Bucket
[root@ceph-node-1 ~]# ceph osd crush set osd.1 0.00999 root=ssd_data host=ceph-node-2-ssd
#ceph-node-3 Bucket
[root@ceph-node-1 ~]# ceph osd crush set osd.2 0.00999 root=ssd_data host=ceph-node-3-ssd
set item id 2 name 'osd.2' weight 0.00999 at location {host=ceph-node-3-ssd,root=ssd_data} to crush map
2)将hdd类型的OSD移动到hdd类型的Bucket中
hdd类型的osd有6、4、7、5这四个,ID为4、7的两个OSD位于ceph-node-2节点,其余两个分别在ceph-node-1和ceph-node-3中。
使用移动OSD的方式将OSD添加到对应的Bucket中。
#ceph-node-1 Bucket
[root@ceph-node-1 ~]# ceph osd crush move osd.6 root=hdd_data host=ceph-node-1-hdd
moved item id 6 name 'osd.6' to location {host=ceph-node-1-hdd,root=hdd_data} in crush map
#ceph-node-2 Bucket
[root@ceph-node-1 ~]# ceph osd crush move osd.4 root=hdd_data host=ceph-node-2-hdd
Dmoved item id 4 name 'osd.4' to location {host=ceph-node-2-hdd,root=hdd_data} in crush map
[root@ceph-node-1 ~]# ceph osd crush move osd.7 root=hdd_data host=ceph-node-2-hdd
moved item id 7 name 'osd.7' to location {host=ceph-node-2-hdd,root=hdd_data} in crush map
#ceph-node-3 Bucket
[root@ceph-node-1 ~]# ceph osd crush move osd.5 root=hdd_data host=ceph-node-3-hdd
moved item id 5 name 'osd.5' to location {host=ceph-node-3-hdd,root=hdd_data} in crush map
到此为止CrushMap就创建完成了,可以看到默认的CrushMap中已经没有可用的OSD了,OSD已经被移动到了Bucket了。】
到目前为止可以说默认的Crush已经是不可用的了,因为没有OSD提供存储了,集群状态也会显示异常。
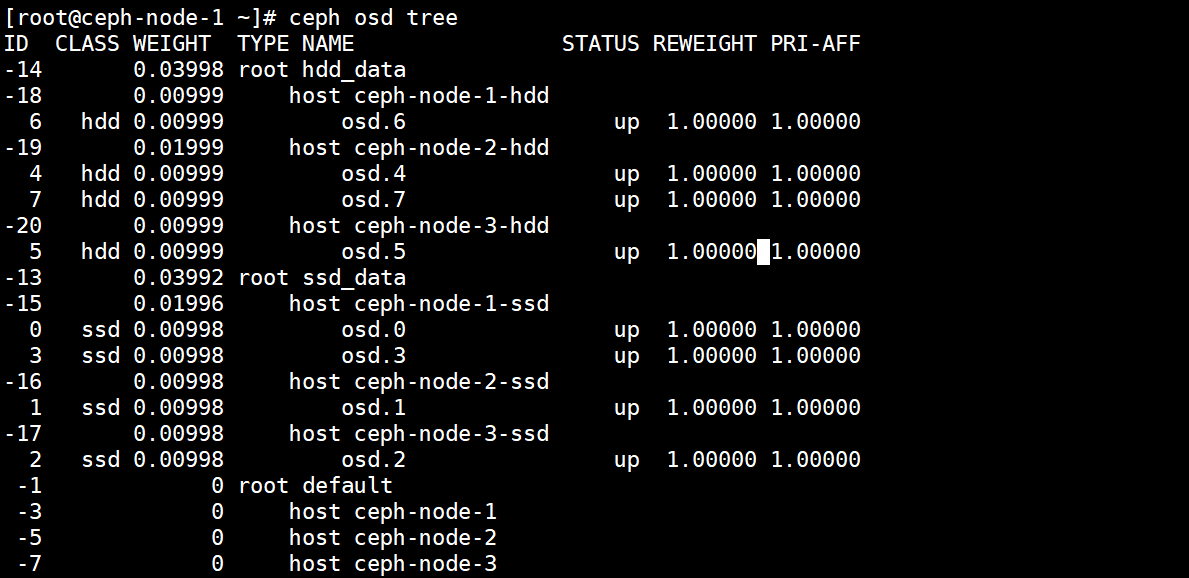
4.6.创建ssd以及hdd两种类型的Rule规则
创建Rule规则与CrushMap进行关联。
命令格式:ceph osd crush rule create-replicated {rule_name} {root_name也就是crushmap的名称} {数据保护类型} {class_name}
1.创建ssd类型的rule规则
[root@ceph-node-1 ~]# ceph osd crush rule create-replicated ssd_rule ssd_data host ssd
2.创建hdd类型的rule规则
[root@ceph-node-1 ~]# ceph osd crush rule create-replicated hdd_rule hdd_data host hdd
3.查看创建的rule规则
[root@ceph-node-1 ~]# ceph osd crush rule ls
ssd_rule
hdd_rule
replicated_rule
4.7.将资源池应用的rule规则进行调整观察数据分布效果
到此为止CrushMap已经全部创建完成了,可以将一个资源池的rule规则调整为新建的Rule规则,观察数据分布效果。
1.修改资源池的rule规则
[root@ceph-node-1 ~]# ceph osd pool set pool-test crush_rule ssd_rule
set pool 11 crush_rule to ssd_rule
2.观察数据分布效果
[root@ceph-node-1 ~]# ceph osd map pool-test test.img
osdmap e1163 pool 'pool-test' (11) object 'test.img' -> pg 11.bfa48b9e (11.6) -> up ([0,1,2], p0) acting ([0,1,2], p0)
ID0-4的都是SSD类型的OSD,数据分布正常。
5.CrushMap逻辑图
类型为root的Bucket负责管理类型为节点或者其他的Bucket,每个Bucket会对应多个OSD,类型为root的Bucket除外,类型为root的Bucket充当管理者,也就是CrushMap,Rule规则需要与CrushMap管理,最后由Pool去应用Rule规则。
可以将CrushMap规则看成是一个目录关系:
root是根目录
bucket是二级目录
osd是三级目录
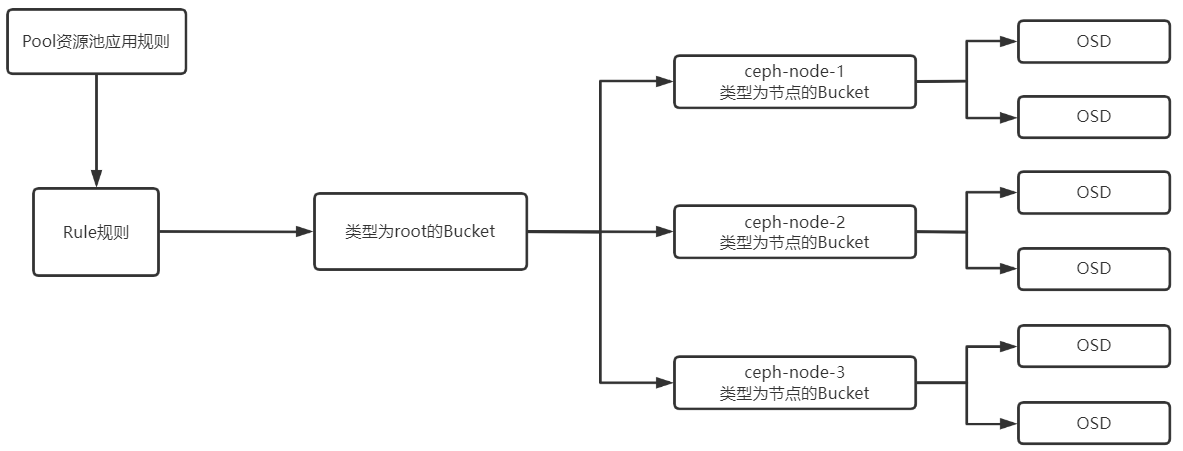
6.验证当OSD异常重启后会对CrushMap列表产生影响
1)停止一个OSD节点。
[root@ceph-node-1 ~]# systemctl stop ceph-osd@0
2)会发现该OSD异常后,会被刷到默认的CrushMap规则中,此时由于OSD的挪动,就会对集群的数据产生影响。
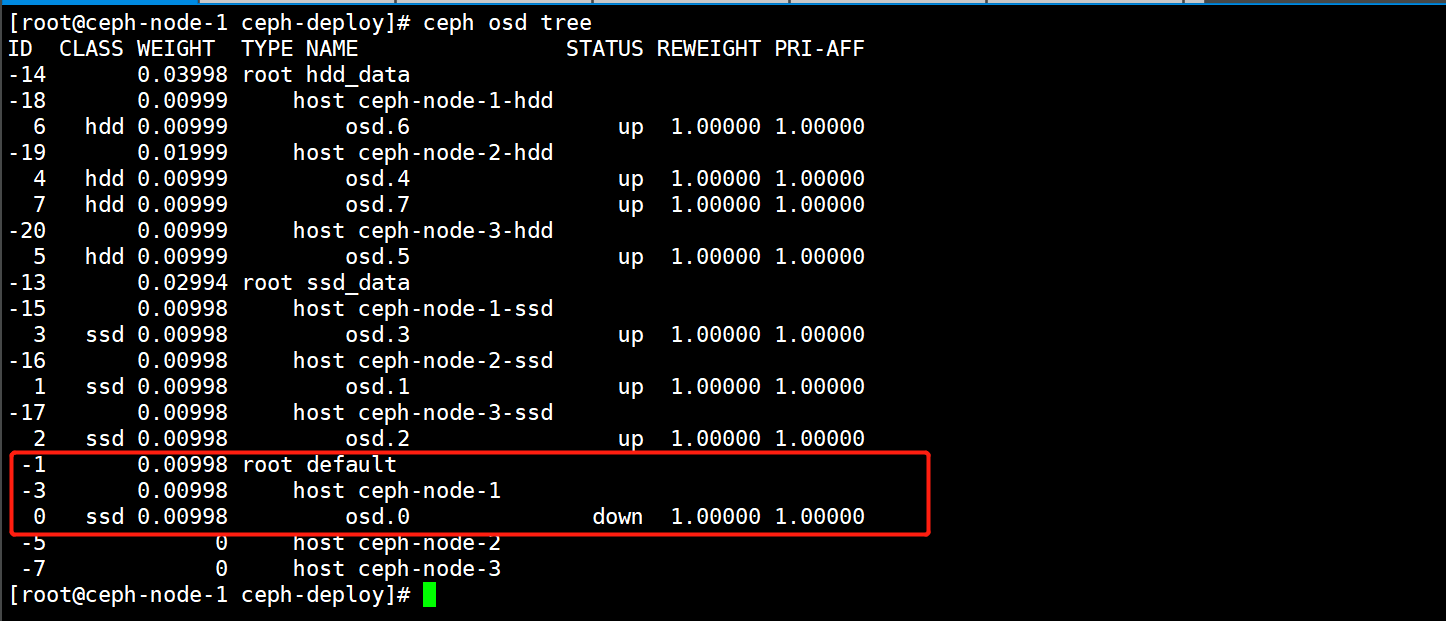
3)OSD恢复后也不会加入到原来的CrushMap中,需要手动移动。
[root@ceph-node-1 ~]# ceph osd crush move osd.0 root=hdd_data host=ceph-node-1-ssd
4)通过配置OSD的一个参数,即使OSD发生了变化也不更新CrushMap列表,来避免OSD被挪动。
1.在配置文件中增加这个osd的参数
[root@ceph-node-1 ~]# cd /data/ceph-deploy/
[root@ceph-node-1 ceph-deploy]# vim ceph.conf
[osd]
osd crush update on start = false
2.使用ceph-deploy工具推送到各个节点上
[root@ceph-node-1 ceph-deploy]# ceph-deploy --overwrite-conf config push ceph-node-1 ceph-node-2 ceph-node-3
3.重启所有节点的osd
[root@ceph-node-1 ceph-deploy]# for i in {1..3}; do ssh ceph-node-${i} "systemctl restart ceph-osd.target" ; done
配置完成后就会发现无论OSD状态如何异常,都不会对CrushMap造成影响。
如果使用的是二进制方式配置的CrushMap则不会出现这种情况,因为是写死的,基于安全起见,建议将这个OSD的参数进行调整。
7.报错现象
[root@ceph-node-1 ~]# ceph osd setcrushmap -i crushmap-new.bin
Error EINVAL: pool 11 references crush_rule 1 but it is not present
如果上面的这个报错,那么就表示有Pool资源池应用了ID为1的Rule,二进制文件中的RuleID都不是1导致的,将文件中Rule的ID配置成1即可解决。
rule replicated_rule {
id 1
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}