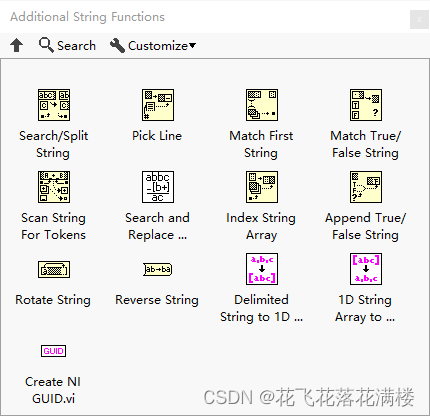
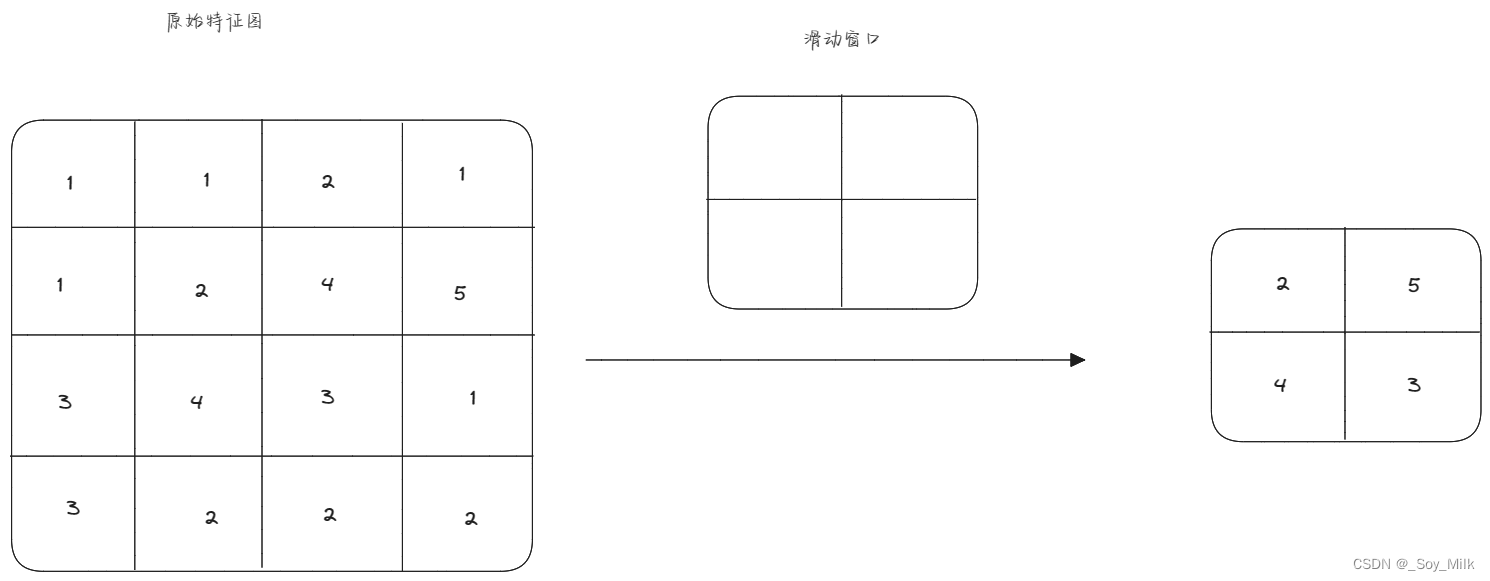
介绍
在Java编程中,Stream流是Java 8引入的一个重要概念,它提供了一种新的处理集合的方式,可以更加简洁、高效地进行数据操作。Stream流支持各种常见的操作,比如过滤、映射、排序、聚合等,同时也支持并行处理,可以充分利用多核处理器的性能优势。
Stream流通常采用延迟执行的策略,即在调用流操作方法时,并不会立即执行,而是会生成一系列的中间操作对象,这些操作对象会按照声明的顺序组成一个流水线。只有在遇到终止操作时,才会触发实际的计算。中间操作可以是过滤、映射、排序等,而终止操作可以是收集结果、聚合操作等。这种流水线的设计可以将多个操作串联起来,形成一个完整的数据处理流程。
在底层实现上,Java的Stream流通常会使用迭代器、函数式接口、Lambda表达式等技术来实现各种操作。通过合理地利用这些技术,可以实现高效、灵活的数据处理流程。
Stream流和SQL之间有一些相似之处,这主要是因为它们都提供了一种声明式的方式来处理数据
另外他们俩的惰性求值 和 数据流水线 过滤操作都及其类似
使用

流
流水线
先得到流水线 把数据都放上面去
在利用Stream流中的API进行操作

用集合去调用stream()方法
获得流水线 并把集合里面的数据放到流水线上

链式编程

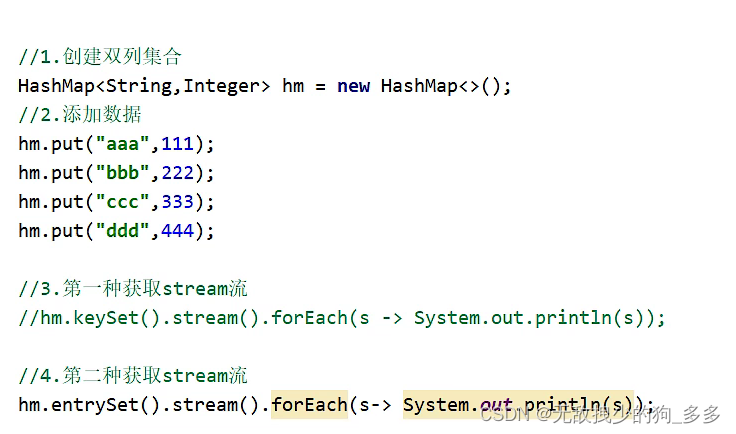
双列集合
数组

一堆零散数据

静态方法of细节
方法的形参是一个可变参数,可以传递一堆零散的数据,也可以传递数组
但是数组必须是引用数据类型
如果传递基本数据类型,是会把整个数组当做一个元素放到Stream里
我们要做的是把数据放到Stream流里

中间方法

过滤

stream流关闭后不可再使用
优先使用链式编程
获取前几个元素

跳过前几个元素

练习
import java.util.ArrayList;
import java.util.Collections;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
ArrayList<String>list=new ArrayList<>();
Collections.addAll(list,"张无忌","周正若","赵敏","张强",
"张三丰","张翠山","张良","王二麻子","谢广坤");
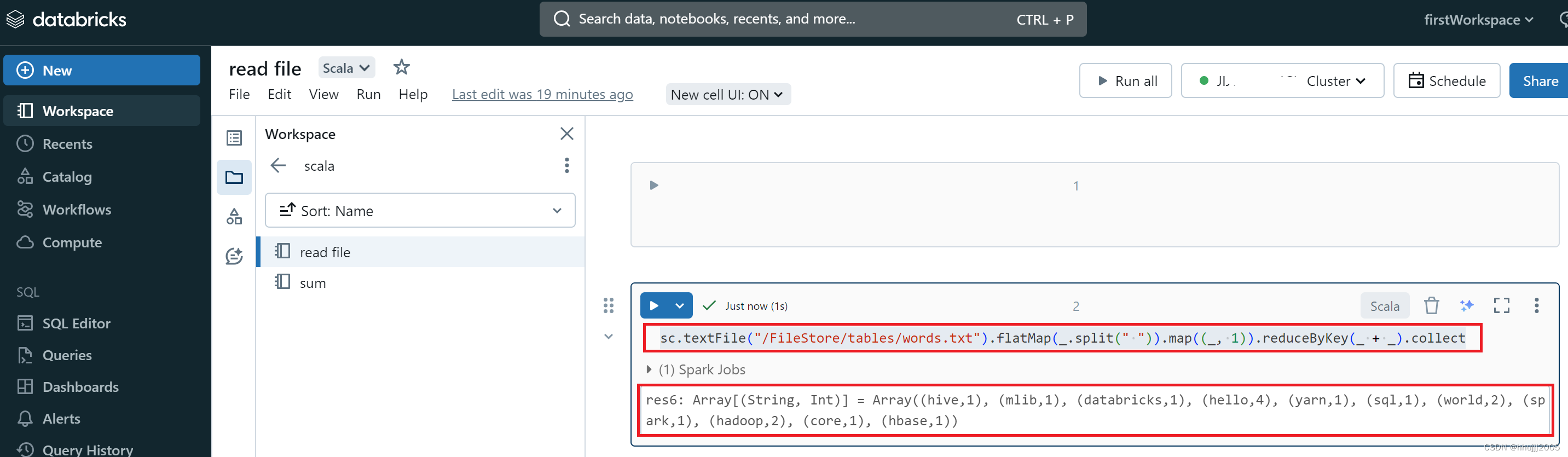
list.stream()
.skip(3)
.filter(s ->s.startsWith("张"))
.forEach(s -> System.out.println(s));
//"张强","张三丰","张翠山","张良"
}
}import java.util.ArrayList;
import java.util.Collections;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
ArrayList<String>list=new ArrayList<>();
Collections.addAll(list,"张无忌","周正若","赵敏","张强",
"张三丰","张翠山","张良","王二麻子","谢广坤");
list.stream()
.skip(3)
.limit(4)
.forEach(s -> System.out.println(s));
//"张强","张三丰","张翠山","张良"
}
}去重

合并

转换流里面的数据类型
map方法
当map方法执行完毕之后,流上的数据就变成了整数
所以在下面的forEach当中
s依次表示流里面的每一个数据

等价于

终结方法

流里面的最后一步
之后就不能再使用流里面的其他方法了

收集方法collect
收集流中的数据,放到集合中
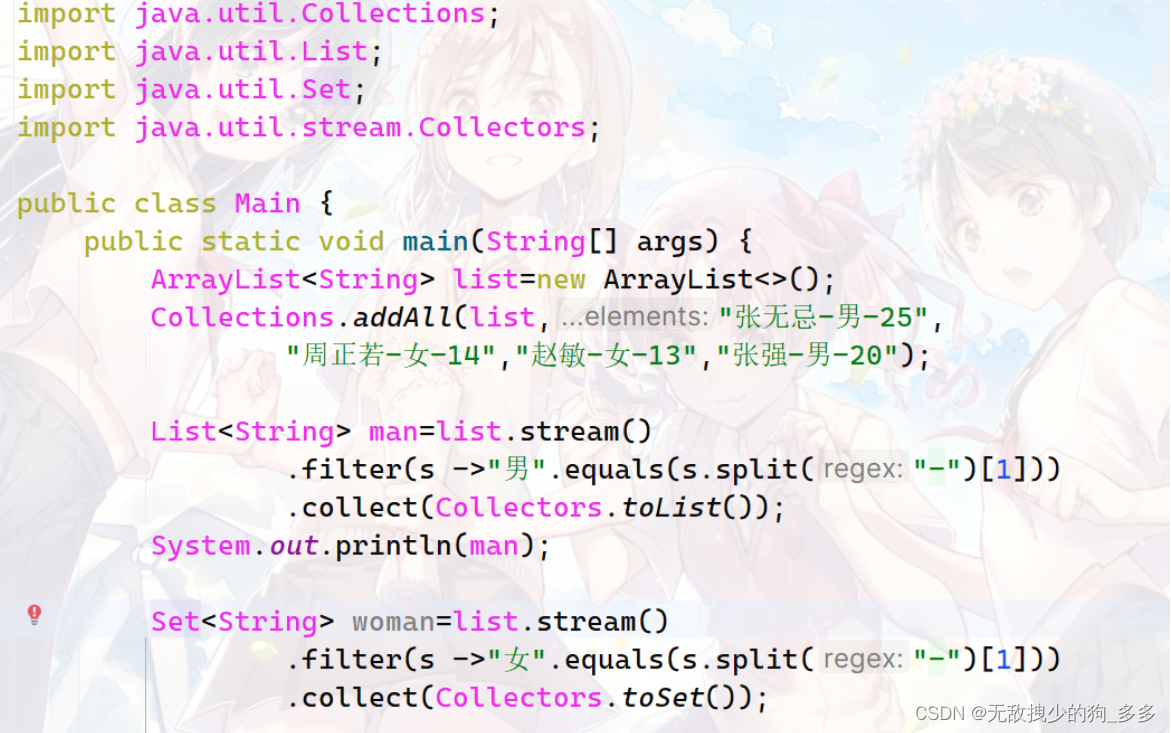
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
public class Main {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"张无忌-男-25",
"周正若-女-14","赵敏-女-13","张强-男-20");
List<String> man=list.stream()
.filter(s ->"男".equals(s.split("-")[1]))
.collect(Collectors.toList());
System.out.println(man);
Set<String> woman=list.stream()
.filter(s ->"女".equals(s.split("-")[1]))
.collect(Collectors.toSet());
}
}
搜集到HashSet集合里面时
会去掉重复的元素
收集使用了collect这个方法
当收集到Map双列集合里的时候
键和值的规则要分别书写
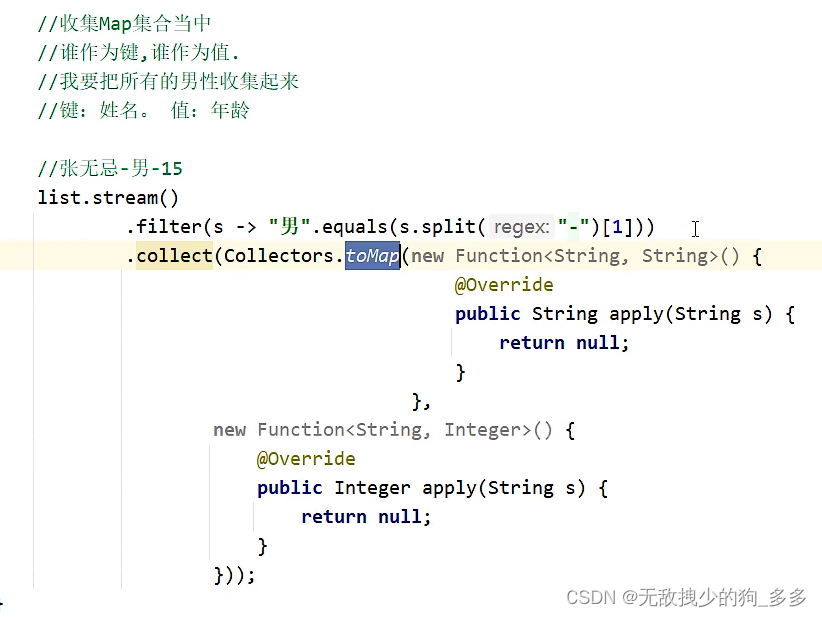


收集到Map集合中,键是不能重复的
不然就会报错
完整版



转化成lambda表达式

总结