详细介绍
ForkJoinPool 是 Java 并发包 (java.util.concurrent) 中的一个特殊线程池,专为分治算法设计,能够高效地处理大量可分解的并行任务。它基于工作窃取(work-stealing)算法,当一个工作线程的任务队列为空时,它会尝试从其他工作线程的任务队列中“窃取”任务来执行,从而提高了线程的利用率和系统的整体性能。

ForkJoinPool 使用场景详析
ForkJoinPool 以其独特的分治策略和工作窃取机制,非常适合处理特定类型的任务,以下是几个典型的应用场景:
1. 大规模数据处理
-
数据分析与统计:在大数据分析场景中,如处理海量日志数据、用户行为分析等,可以将数据集切分为小块,对每个小块并行处理后再合并结果,大大加快处理速度。
-
图像处理:图片分割成小块分别处理,如像素级别的滤镜应用、图像识别等,然后合并结果。
2. 树形结构遍历
-
文件系统遍历:在文件系统搜索、文件备份或整理中,可以将目录树分割为多个分支并行遍历,提高搜索效率。
-
DOM 树处理:XML 或 HTML 文件解析,可以将DOM树分解成多个节点进行并行处理,如查找特定标签、修改属性等。
3. 递归算法并行化
-
排序算法:快速排序、归并排序等算法天然适合分治,可以将数组分成若干段并行排序,最后合并结果。
-
图算法:如Dijkstra算法求最短路径、广度优先搜索(BFS)等,可以将图分割成多个部分并行搜索,再合并结果。
4. 科学计算与模拟
-
数值计算:在大规模矩阵运算、蒙特卡洛模拟等场景中,可以将计算任务分解为小规模计算任务并行执行,提高计算效率。
-
物理或化学模拟:模拟分子动力学、天体运动等,通过分解空间或时间序列进行并行模拟,加速模拟过程。
5. 并行算法研究与实现
-
学术研究:在计算机科学领域,研究并行算法时,ForkJoinPool提供了一个实现和测试分治算法的高效平台。
-
教育实践:教学中展示并行计算概念,如课程项目中实现并行搜索算法、并行排序等,帮助学生理解并行计算原理。
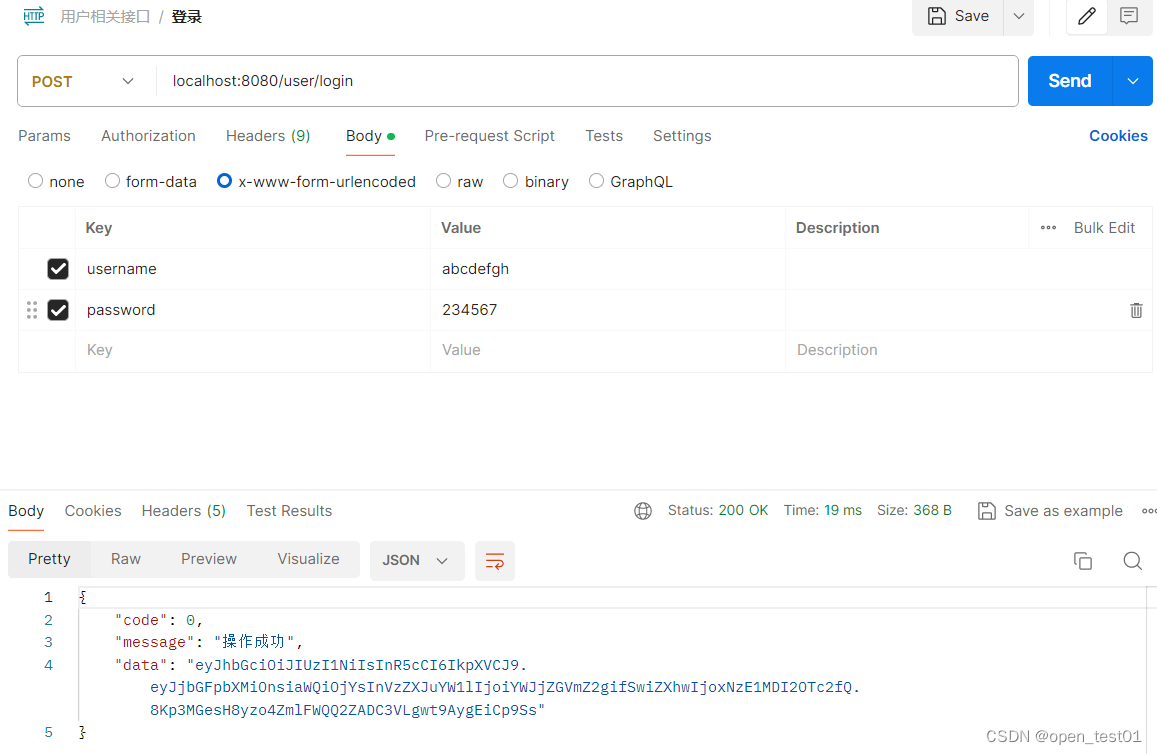
使用示例(Java):
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class ForkJoinPoolExample {
static class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) {
this.n = n;
}
protected Integer compute() {
if (n <= 1)
return n;
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
return f2.compute() + f1.join();
}
}
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
Fibonacci task = new Fibonacci(20);
int result = pool.invoke(task);
System.out.println("Fibonacci of 20 is " + result);
pool.shutdown();
}
}实际开发中使用ForkJoinPool的注意事项
1. 任务设计
- 可分解性:确保任务能被有效分解为子任务,且每个子任务都是独立可执行的,这是使用ForkJoinPool的前提。
- 避免过细分解:虽然细粒度任务有利于并行,但过度分解会增加任务调度和管理的开销,寻找最优分解粒度至关重要。
- 任务大小估计:尽量让子任务大小大致相等,这有助于平衡负载,避免某些线程过早空闲,而其他线程还在处理大量任务。
2. 资源与线程数配置
- 默认线程数:ForkJoinPool的默认构造函数会根据运行环境自动设置线程数,通常等于可用处理器数量。针对特定需求,可以使用
ForkJoinPool(int parallelism)构造函数自定义线程数。 - 自适应线程池:对于不确定任务数量或类型变化较大的场景,可以使用
ForkJoinPool.commonPool(),它会根据运行时条件动态调整线程数。
3. 避免死锁与活锁
- 任务依赖:在设计任务时,避免形成循环依赖,这可能导致死锁。
- 任务窃取机制:理解并利用好工作窃取机制,避免长时间运行的任务阻碍其他任务的执行,必要时可以设计自定义的窃取策略。
4. 资源管理
- 及时关闭:使用完毕后,调用
shutdown()或shutdownNow()方法关闭线程池,避免资源泄露。 - 异常处理:在任务中合理捕获和处理异常,避免异常导致的线程终止,影响整个任务的执行。
5. 性能监控与调优
- 性能监控:利用Java内置工具(如VisualVM)监控ForkJoinPool的工作状态,包括任务队列长度、线程使用情况等,以便及时发现问题。
- 调优:根据监控数据调整线程数、任务分解策略等,不断迭代优化性能。
6. 内存管理
- 任务对象复用:为减少垃圾回收压力,可以考虑使用对象池来复用任务对象,尤其是大量相似任务时。
- 避免内存泄漏:确保任务执行完毕后,释放所有资源,特别是当任务持有外部资源时,如数据库连接、文件句柄等。
7. 并发数据结构
- 安全的数据访问:如果任务间有共享数据,确保使用线程安全的数据结构,如
ConcurrentHashMap,或者通过锁机制保护共享数据的访问。
8. 测试与验证
- 并行测试:并行任务的正确性和性能往往更难预测,需要进行全面的测试,包括单元测试、性能测试和压力测试。
- 边界条件测试:特别关注任务数量极少、任务数据量极大等情况下的表现。
优缺点
优点
-
高效利用多核资源:通过分治策略和工作窃取算法,ForkJoinPool能有效分配和利用多核处理器,尤其在CPU密集型任务中表现突出。
-
动态负载平衡:工作窃取机制允许空闲线程主动从忙碌线程的任务队列中“窃取”任务,自动平衡了任务的分配,减少了线程等待时间。
-
简化并行编程:Fork/Join框架提供了一种高层抽象,使得开发者可以相对容易地实现并行算法,无需直接处理线程创建、同步等底层细节。
-
自适应线程管理:
ForkJoinPool.commonPool()提供了一个共享的、根据系统负载自动调整线程数的线程池,减少了手动配置的复杂度。 -
深度优化:Java库和JVM层面针对ForkJoinPool进行了优化,如减少上下文切换开销、特殊化的任务队列等,进一步提高了执行效率。
缺点
-
任务分解复杂度:为了利用ForkJoinPool,任务需要设计成可分解的,这对于一些非自然分解的任务来说,设计成本较高,可能还不如传统的线程池直接。
-
过度细分问题:如果任务分解得太细,任务创建和调度的开销可能会超过任务执行本身的开销,反而降低效率。
-
内存消耗:ForkJoinPool在处理大量小任务时,由于每个任务都有自己的栈空间,可能会导致较高的内存消耗,尤其是在深度递归场景下。
-
死锁与活锁风险:虽然工作窃取机制减少了死锁的可能性,但不恰当的任务设计仍然可能导致死锁或活锁,尤其是在有任务依赖的情况下。
-
调试与监控挑战:并行程序的调试和性能监控通常比串行程序复杂,ForkJoinPool也不例外,开发者需要更多工具和技巧来定位问题和性能瓶颈。
-
不适合I/O密集型任务:由于工作窃取机制主要优化了CPU密集型任务,对于I/O密集型任务,线程在等待I/O时,其他线程也无法通过工作窃取机制有效利用这些线程,此时传统的线程池可能更为适合。
使用示例:
import java.util.Arrays;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
public class QuickSortForkJoin extends RecursiveAction {
private final int[] array;
private final int low;
private final int high;
public QuickSortForkJoin(int[] array, int low, int high) {
this.array = array;
this.low = low;
this.high = high;
}
@Override
protected void compute() {
if (low < high) {
int pivotIndex = partition(array, low, high);
invokeAll(new QuickSortForkJoin(array, low, pivotIndex - 1),
new QuickSortForkJoin(array, pivotIndex + 1, high));
}
}
private int partition(int[] array, int low, int high) {
int pivot = array[high];
int i = low - 1;
for (int j = low; j < high; j++) {
if (array[j] < pivot) {
i++;
swap(array, i, j);
}
}
swap(array, i + 1, high);
return i + 1;
}
private void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
int[] numbers = {9, 7, 5, 11, 12, 2, 14, 3, 10, 6};
forkJoinPool.invoke(new QuickSortForkJoin(numbers, 0, numbers.length - 1));
System.out.println(Arrays.toString(numbers));
forkJoinPool.shutdown();
}
}可能遇到的问题及解决方案
1. 任务分解不当
问题描述:如果任务分解不合理,例如分解得太细,可能会导致任务调度的开销大于执行开销,反而降低效率;分解得太大,则无法充分利用多核处理器的并行能力。
解决方案:
- 优化分解策略:根据任务特性仔细权衡任务分解的粒度,确保每个子任务既能够独立执行,又不至于过于微小。
- 性能测试:通过实际运行并监控性能,不断调整任务分解策略,找到最佳的分解粒度。
2. 资源竞争与死锁
问题描述:在多线程环境下,不恰当的资源共享或同步可能会导致线程间的竞争,严重时甚至引起死锁。
解决方案:
- 最小化共享:尽量减少任务间共享资源,使用局部变量代替全局变量。
- 使用锁与并发工具:对于必须共享的资源,使用显式锁(如
ReentrantLock)或Java并发包中的原子类、并发集合等工具,确保线程安全。 - 避免循环等待:设计任务执行逻辑时,确保任务间的依赖关系不会形成环状,以预防死锁。
3. 内存泄漏
问题描述:任务对象或其引用未被正确清理,可能导致内存泄漏,长期运行的服务中尤其需要注意。
解决方案:
- 任务对象生命周期管理:确保任务执行完成后,相关资源被释放,如使用try-with-resources语句管理资源。
- 使用弱引用或软引用:对于任务中持有的外部资源,可以考虑使用弱引用或软引用,以便垃圾回收器在内存紧张时回收这些对象。
4. 任务调度不均
问题描述:在某些情况下,可能会出现任务分配不均,部分线程忙于处理任务,而其他线程空闲,影响整体效率。
解决方案:
- 平衡任务分配:尽量使任务的粒度和复杂度均匀,减少极端情况的发生。
- 自定义工作窃取策略:在极端情况下,可根据具体情况自定义任务窃取逻辑,比如优先从处理任务最少的线程窃取。
5. 线程池参数配置不当
问题描述:线程池大小设置不当,如设置过小可能导致任务排队等待,过大则可能造成资源浪费。
解决方案:
- 动态调整线程池大小:根据实际负载动态调整线程池大小,使用如
ForkJoinPool的commonPool()自动调整线程数。 - 性能监控:定期监控线程池的运行状态,如任务队列长度、线程使用率等,根据监控数据调整参数。
6. 异常处理不当
问题描述:任务执行中未妥善处理异常,可能导致任务中断或线程池异常终止。
解决方案:
- 全面异常捕获:在任务执行逻辑中全面捕获异常,确保异常不会导致线程意外终止。
- 记录与重试:记录异常信息,并根据情况决定是否重试失败的任务,或是将任务移至异常处理队列。
ForkJoinPool 是处理可分解任务的强大工具,但在使用时需充分考虑任务特性,合理设计任务分解策略,以充分发挥其并行处理的优势。整体来说,ForkJoinPool在处理大量可并行的、CPU密集型任务时表现优异,但在使用时需要根据任务特性仔细设计任务分解策略,避免过度分解和资源浪费。同时,对于特定类型的任务和环境,可能需要权衡其优缺点,选择最适合的并发模型。