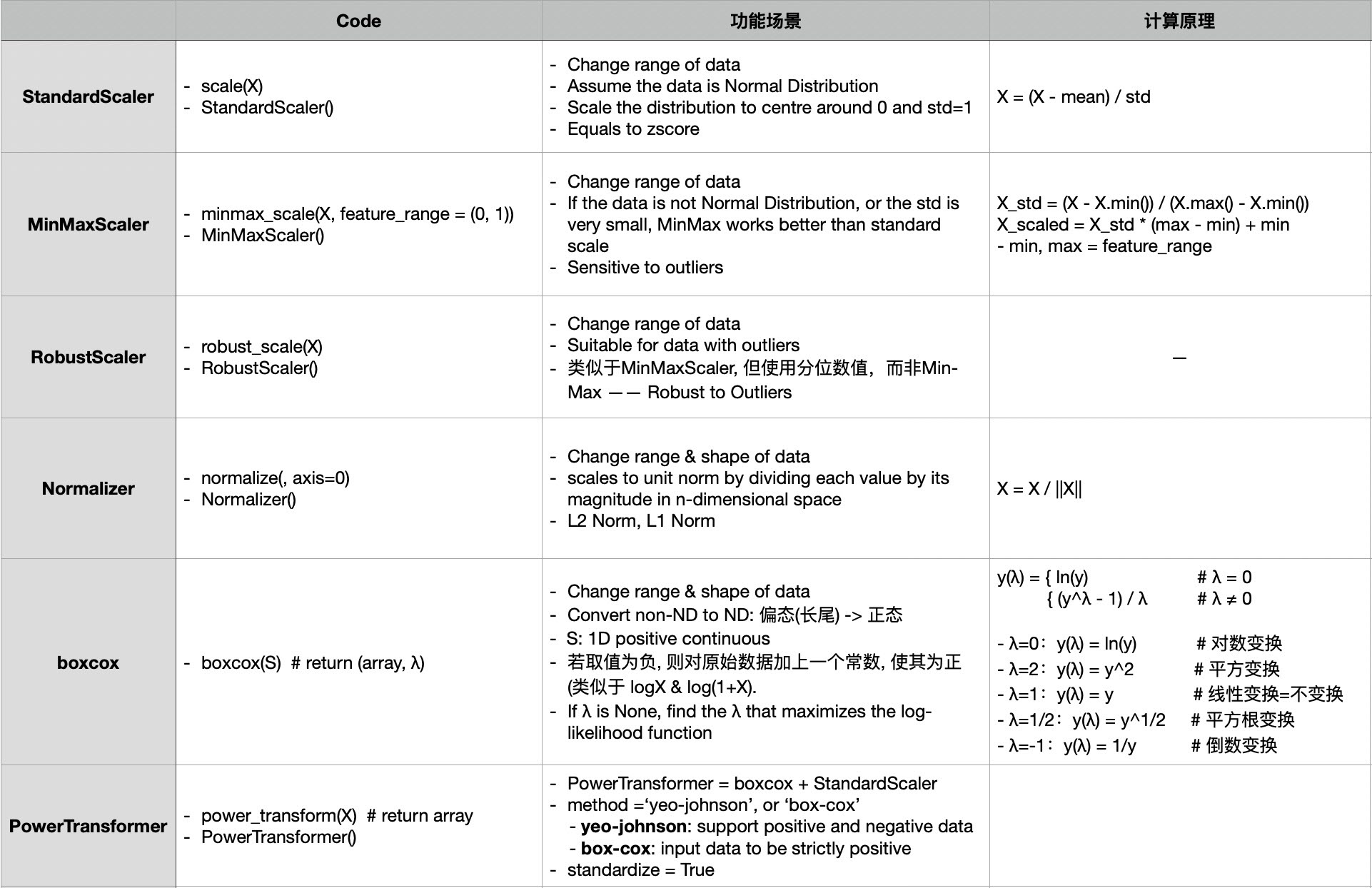
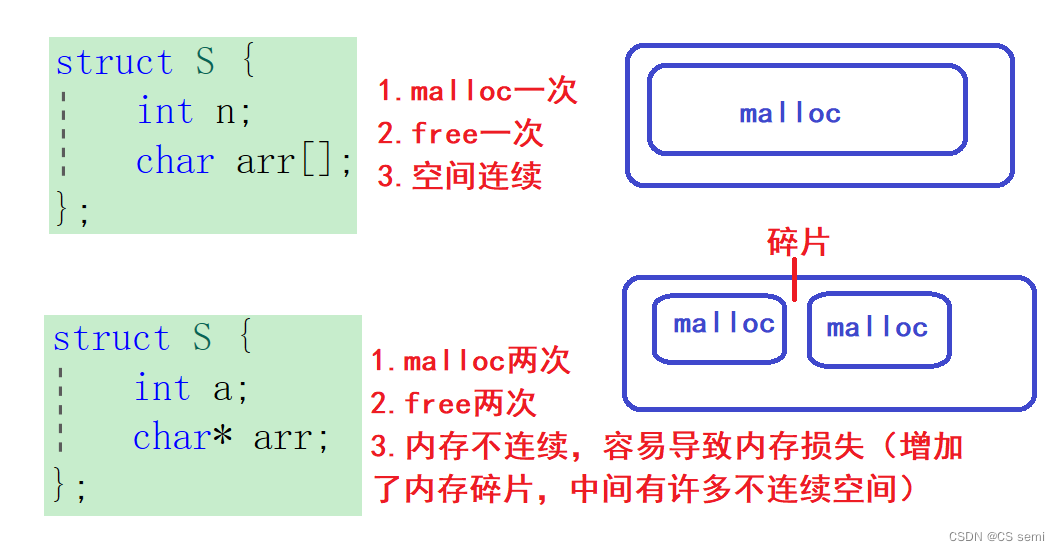
accelerate 是huggingface开源的一个方便将pytorch模型迁移到 GPU/multi-GPUs/TPU/fp16 模式下训练的小巧工具。
和标准的 pytorch 方法相比,使用accelerate 进行多GPU DDP模式/TPU/fp16 训练你的模型变得非常简单(只需要在标准的pytorch训练代码中改动不几行代码就可以适应于cpu/单GPU/多GPU的DDP模式/TPU 等不同的训练环境),而且速度与原生pytorch相当,非常之快。
官方范例:https://github.com/huggingface/accelerate/tree/main/examples
本文将以一个图片分类模型为例,演示在accelerate的帮助下使用pytorch编写一套可以在 cpu/单GPU/多GPU(DDP)模式/TPU 下通用的训练代码。
在我们的演示范例中,在kaggle的双GPU环境下,双GPU的DDP模式是单GPU训练速度的1.6倍,加速效果非常明显。
公众号算法美食屋后台回复关键词:ddp 获取本教程完整jupyter notebook代码和B站视频演示范例。
DP和DDP的区别
DP(DataParallel):实现简单但更慢。只能单机多卡使用。GPU分成server节点和worker节点,有负载不均衡。
DDP(DistributedDataParallel):更快但实现麻烦。可单机多卡也可多机多卡。各个GPU是平等的,无负载不均衡。
参考文章:《pytorch中的分布式训练之DP VS DDP》https://zhuanlan.zhihu.com/p/356967195
#从git安装最新的accelerate仓库
!pip install git+https://github.com/huggingface/accelerate一,使用 CPU/单GPU 训练你的pytorch模型
当系统存在GPU时,accelerate 会自动使用GPU训练你的pytorch模型,否则会使用CPU训练模型。
import os,PIL
import numpy as np
from torch.utils.data import DataLoader, Dataset
import torch
from torch import nn
import torchvision
from torchvision import transforms
import datetime
#======================================================================
# import accelerate
from accelerate import Accelerator
from accelerate.utils import set_seed
#======================================================================
def create_dataloaders(batch_size=64):
transform = transforms.Compose([transforms.ToTensor()])
ds_train = torchvision.datasets.MNIST(root="./minist/",train=True,download=True,transform=transform)
ds_val = torchvision.datasets.MNIST(root="./minist/",train=False,download=True,transform=transform)
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=batch_size, shuffle=True,
num_workers=2,drop_last=True)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=batch_size, shuffle=False,
num_workers=2,drop_last=True)
return dl_train,dl_val
def create_net():
net = nn.Sequential()
net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=512,kernel_size = 3))
net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("conv2",nn.Conv2d(in_channels=512,out_channels=256,kernel_size = 5))
net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("dropout",nn.Dropout2d(p = 0.1))
net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
net.add_module("flatten",nn.Flatten())
net.add_module("linear1",nn.Linear(256,128))
net.add_module("relu",nn.ReLU())
net.add_module("linear2",nn.Linear(128,10))
return net
def training_loop(epochs = 5,
lr = 1e-3,
batch_size= 1024,
ckpt_path = "checkpoint.pt",
mixed_precision="no", #'fp16'
):
train_dataloader, eval_dataloader = create_dataloaders(batch_size)
model = create_net()
optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)
lr_scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer=optimizer, max_lr=25*lr,
epochs=epochs, steps_per_epoch=len(train_dataloader))
#======================================================================
# initialize accelerator and auto move data/model to accelerator.device
set_seed(42)
accelerator = Accelerator(mixed_precision=mixed_precision)
accelerator.print(f'device {str(accelerator.device)} is used!')
model, optimizer,lr_scheduler, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer,lr_scheduler, train_dataloader, eval_dataloader)
#======================================================================
for epoch in range(epochs):
model.train()
for step, batch in enumerate(train_dataloader):
features,labels = batch
preds = model(features)
loss = nn.CrossEntropyLoss()(preds,labels)
#======================================================================
#attention here!
accelerator.backward(loss) #loss.backward()
#======================================================================
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
accurate = 0
num_elems = 0
for _, batch in enumerate(eval_dataloader):
features,labels = batch
with torch.no_grad():
preds = model(features)
predictions = preds.argmax(dim=-1)
#======================================================================
#gather data from multi-gpus (used when in ddp mode)
predictions = accelerator.gather(predictions)
labels = accelerator.gather(labels)
#======================================================================
accurate_preds = (predictions==labels)
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.long().sum()
eval_metric = accurate.item() / num_elems
#======================================================================
#print logs and save ckpt
accelerator.wait_for_everyone()
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
accelerator.print(f"epoch【{epoch}】@{nowtime} --> eval_metric= {100 * eval_metric:.2f}%")
unwrapped_net = accelerator.unwrap_model(model)
accelerator.save(unwrapped_net.state_dict(),ckpt_path+"_"+str(epoch))
#======================================================================
#training_loop(epochs = 5,lr = 1e-3,batch_size= 1024,ckpt_path = "checkpoint.pt",
# mixed_precision="no") #mixed_precision='fp16'training_loop(epochs = 5,lr = 1e-4,batch_size= 1024,
ckpt_path = "checkpoint.pt",
mixed_precision="no") #mixed_precision='fp16'device cuda is used!
epoch【0】@2023-01-15 12:06:45 --> eval_metric= 95.20%
epoch【1】@2023-01-15 12:07:01 --> eval_metric= 96.79%
epoch【2】@2023-01-15 12:07:17 --> eval_metric= 98.47%
epoch【3】@2023-01-15 12:07:34 --> eval_metric= 98.78%
epoch【4】@2023-01-15 12:07:51 --> eval_metric= 98.87%二,使用多GPU DDP模式训练你的pytorch模型
Kaggle中右边settings 中的 ACCELERATOR选择 GPU T4x2。
1,设置config
import os
from accelerate.utils import write_basic_config
write_basic_config() # Write a config file
os._exit(0) # Restart the notebook to reload info from the latest config file# or answer some question to create a config
#!accelerate config2,训练代码
与之前代码完全一致。
如果是脚本方式启动,需要将训练代码写入到脚本文件中,如cv_example.py
%%writefile cv_example.py
import os,PIL
import numpy as np
from torch.utils.data import DataLoader, Dataset
import torch
from torch import nn
import torchvision
from torchvision import transforms
import datetime
#======================================================================
# import accelerate
from accelerate import Accelerator
from accelerate.utils import set_seed
#======================================================================
def create_dataloaders(batch_size=64):
transform = transforms.Compose([transforms.ToTensor()])
ds_train = torchvision.datasets.MNIST(root="./minist/",train=True,download=True,transform=transform)
ds_val = torchvision.datasets.MNIST(root="./minist/",train=False,download=True,transform=transform)
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=batch_size, shuffle=True,
num_workers=2,drop_last=True)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=batch_size, shuffle=False,
num_workers=2,drop_last=True)
return dl_train,dl_val
def create_net():
net = nn.Sequential()
net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=512,kernel_size = 3))
net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("conv2",nn.Conv2d(in_channels=512,out_channels=256,kernel_size = 5))
net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("dropout",nn.Dropout2d(p = 0.1))
net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
net.add_module("flatten",nn.Flatten())
net.add_module("linear1",nn.Linear(256,128))
net.add_module("relu",nn.ReLU())
net.add_module("linear2",nn.Linear(128,10))
return net
def training_loop(epochs = 5,
lr = 1e-3,
batch_size= 1024,
ckpt_path = "checkpoint.pt",
mixed_precision="no", #'fp16'
):
train_dataloader, eval_dataloader = create_dataloaders(batch_size)
model = create_net()
optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)
lr_scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer=optimizer, max_lr=25*lr,
epochs=epochs, steps_per_epoch=len(train_dataloader))
#======================================================================
# initialize accelerator and auto move data/model to accelerator.device
set_seed(42)
accelerator = Accelerator(mixed_precision=mixed_precision)
accelerator.print(f'device {str(accelerator.device)} is used!')
model, optimizer,lr_scheduler, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer,lr_scheduler, train_dataloader, eval_dataloader)
#======================================================================
for epoch in range(epochs):
model.train()
for step, batch in enumerate(train_dataloader):
features,labels = batch
preds = model(features)
loss = nn.CrossEntropyLoss()(preds,labels)
#======================================================================
#attention here!
accelerator.backward(loss) #loss.backward()
#======================================================================
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
accurate = 0
num_elems = 0
for _, batch in enumerate(eval_dataloader):
features,labels = batch
with torch.no_grad():
preds = model(features)
predictions = preds.argmax(dim=-1)
#======================================================================
#gather data from multi-gpus (used when in ddp mode)
predictions = accelerator.gather(predictions)
labels = accelerator.gather(labels)
#======================================================================
accurate_preds = (predictions==labels)
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.long().sum()
eval_metric = accurate.item() / num_elems
#======================================================================
#print logs and save ckpt
accelerator.wait_for_everyone()
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
accelerator.print(f"epoch【{epoch}】@{nowtime} --> eval_metric= {100 * eval_metric:.2f}%")
unwrapped_net = accelerator.unwrap_model(model)
accelerator.save(unwrapped_net.state_dict(),ckpt_path+"_"+str(epoch))
#======================================================================
training_loop(epochs = 5,lr = 1e-4,batch_size= 1024,ckpt_path = "checkpoint.pt",
mixed_precision="no") #mixed_precision='fp16'3,执行代码
方式1,在notebook中启动
from accelerate import notebook_launcher
#args = (5,1e-4,1024,'checkpoint.pt','no')
args = dict(epochs = 5,
lr = 1e-4,
batch_size= 1024,
ckpt_path = "checkpoint.pt",
mixed_precision="no").values()
notebook_launcher(training_loop, args, num_processes=2)Launching training on 2 GPUs.
device cuda:0 is used!
epoch【0】@2023-01-15 12:10:48 --> eval_metric= 89.18%
epoch【1】@2023-01-15 12:10:58 --> eval_metric= 97.20%
epoch【2】@2023-01-15 12:11:08 --> eval_metric= 98.03%
epoch【3】@2023-01-15 12:11:19 --> eval_metric= 98.16%
epoch【4】@2023-01-15 12:11:30 --> eval_metric= 98.32%方式2,accelerate方式执行脚本
!accelerate launch ./cv_example.py方式3,torch方式执行脚本
# or traditional pytorch style
!python -m torch.distributed.launch --nproc_per_node 2 --use_env ./cv_example.pydevice cuda:0 is used!
epoch【0】@2023-01-15 12:18:26 --> eval_metric= 94.79%
epoch【1】@2023-01-15 12:18:37 --> eval_metric= 96.44%
epoch【2】@2023-01-15 12:18:48 --> eval_metric= 98.34%
epoch【3】@2023-01-15 12:18:59 --> eval_metric= 98.41%
epoch【4】@2023-01-15 12:19:10 --> eval_metric= 98.51%三,使用TPU加速你的pytorch模型
Kaggle中右边settings 中的 ACCELERATOR选择 TPU v3-8。
1,安装torch_xla
#安装torch_xla支持
!pip uninstall -y torch torch_xla
!pip install torch==1.8.2+cpu -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html
!pip install cloud-tpu-client==0.10 https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.8-cp37-cp37m-linux_x86_64.whl#从git安装最新的accelerate仓库
!pip install git+https://github.com/huggingface/accelerate#检查是否成功安装 torch_xla
import torch_xla2,训练代码
和之前代码完全一样。
import os,PIL
import numpy as np
from torch.utils.data import DataLoader, Dataset
import torch
from torch import nn
import torchvision
from torchvision import transforms
import datetime
#======================================================================
# import accelerate
from accelerate import Accelerator
from accelerate.utils import set_seed
#======================================================================
def create_dataloaders(batch_size=64):
transform = transforms.Compose([transforms.ToTensor()])
ds_train = torchvision.datasets.MNIST(root="./minist/",train=True,download=True,transform=transform)
ds_val = torchvision.datasets.MNIST(root="./minist/",train=False,download=True,transform=transform)
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=batch_size, shuffle=True,
num_workers=2,drop_last=True)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=batch_size, shuffle=False,
num_workers=2,drop_last=True)
return dl_train,dl_val
def create_net():
net = nn.Sequential()
net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=512,kernel_size = 3))
net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("conv2",nn.Conv2d(in_channels=512,out_channels=256,kernel_size = 5))
net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("dropout",nn.Dropout2d(p = 0.1))
net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
net.add_module("flatten",nn.Flatten())
net.add_module("linear1",nn.Linear(256,128))
net.add_module("relu",nn.ReLU())
net.add_module("linear2",nn.Linear(128,10))
return net
def training_loop(epochs = 5,
lr = 1e-3,
batch_size= 1024,
ckpt_path = "checkpoint.pt",
mixed_precision="no", #'fp16'
):
train_dataloader, eval_dataloader = create_dataloaders(batch_size)
model = create_net()
optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)
lr_scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer=optimizer, max_lr=25*lr,
epochs=epochs, steps_per_epoch=len(train_dataloader))
#======================================================================
# initialize accelerator and auto move data/model to accelerator.device
set_seed(42)
accelerator = Accelerator(mixed_precision=mixed_precision)
accelerator.print(f'device {str(accelerator.device)} is used!')
model, optimizer,lr_scheduler, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer,lr_scheduler, train_dataloader, eval_dataloader)
#======================================================================
for epoch in range(epochs):
model.train()
for step, batch in enumerate(train_dataloader):
features,labels = batch
preds = model(features)
loss = nn.CrossEntropyLoss()(preds,labels)
#======================================================================
#attention here!
accelerator.backward(loss) #loss.backward()
#======================================================================
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
accurate = 0
num_elems = 0
for _, batch in enumerate(eval_dataloader):
features,labels = batch
with torch.no_grad():
preds = model(features)
predictions = preds.argmax(dim=-1)
#======================================================================
#gather data from multi-gpus (used when in ddp mode)
predictions = accelerator.gather(predictions)
labels = accelerator.gather(labels)
#======================================================================
accurate_preds = (predictions==labels)
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.long().sum()
eval_metric = accurate.item() / num_elems
#======================================================================
#print logs and save ckpt
accelerator.wait_for_everyone()
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
accelerator.print(f"epoch【{epoch}】@{nowtime} --> eval_metric= {100 * eval_metric:.2f}%")
unwrapped_net = accelerator.unwrap_model(model)
accelerator.save(unwrapped_net.state_dict(),ckpt_path+"_"+str(epoch))
#======================================================================3,启动训练
from accelerate import notebook_launcher
#args = (5,1e-4,1024,'checkpoint.pt','no')
args = dict(epochs = 5,
lr = 1e-4,
batch_size= 1024,
ckpt_path = "checkpoint.pt",
mixed_precision="no").values()
notebook_launcher(training_loop, args, num_processes=8)






![[LeetCode周赛复盘] 第 328 场周赛20230115](https://img-blog.csdnimg.cn/48ea9bfa27f643ee86be72bb22f40b2a.png)