本文首发于公众号:机器感知
Imagine Flash、StyleMamba 、FlexControl、Multi-Scene T2V、TexControl

You Only Cache Once: Decoder-Decoder Architectures for Language Models
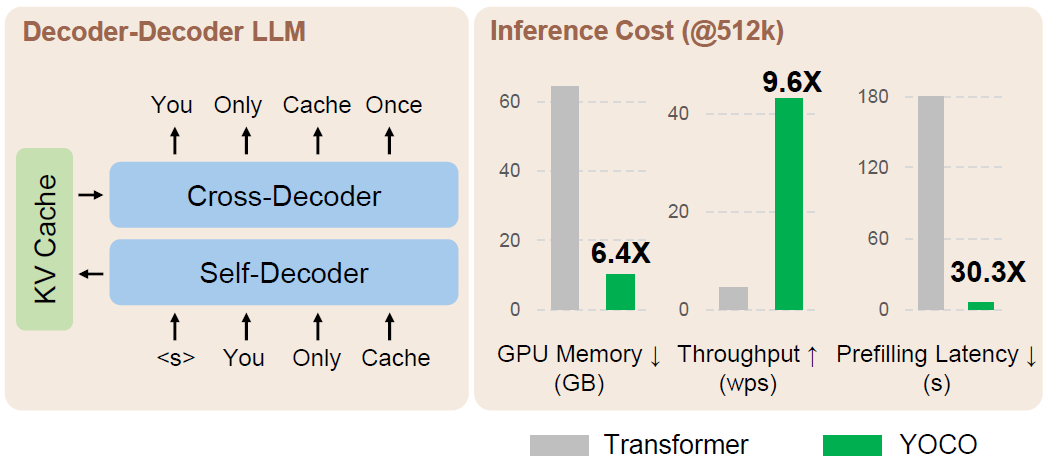
We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. The self-decoder efficiently encodes global key-value (KV) caches that are reused by the cross-decoder via cross-attention. The overall model behaves like a decoder-only Transformer, although YOCO only caches once. The design substantially reduces GPU memory demands, yet retains global attention capability. Additionally, the computation flow enables prefilling to early exit without changing the final output, thereby significantly speeding up the prefill stage. Experimental results demonstrate that YOCO achieves favorable performance compared to Transformer in various settings of scaling up model size and number of training tokens. We also extend YOCO to 1M context length with near-perfect needle retrieval accuracy. The profiling results show that YOCO improves inference memory, p......
Attention-Driven Training-Free Efficiency Enhancement of Diffusion Models

Diffusion Models (DMs) have exhibited superior performance in generating high-quality and diverse images. However, this exceptional performance comes at the cost of expensive architectural design, particularly due to the attention module heavily used in leading models. Existing works mainly adopt a retraining process to enhance DM efficiency. This is computationally expensive and not very scalable. To this end, we introduce the Attention-driven Training-free Efficient Diffusion Model (AT-EDM) framework that leverages attention maps to perform run-time pruning of redundant tokens, without the need for any retraining. Specifically, for single-denoising-step pruning, we develop a novel ranking algorithm, Generalized Weighted Page Rank (G-WPR), to identify redundant tokens, and a similarity-based recovery method to restore tokens for the convolution operation. In addition, we propose a Denoising-Steps-Aware Pruning (DSAP) approach to adjust the pruning budget across different den......
Imagine Flash: Accelerating Emu Diffusion Models with Backward Distillation
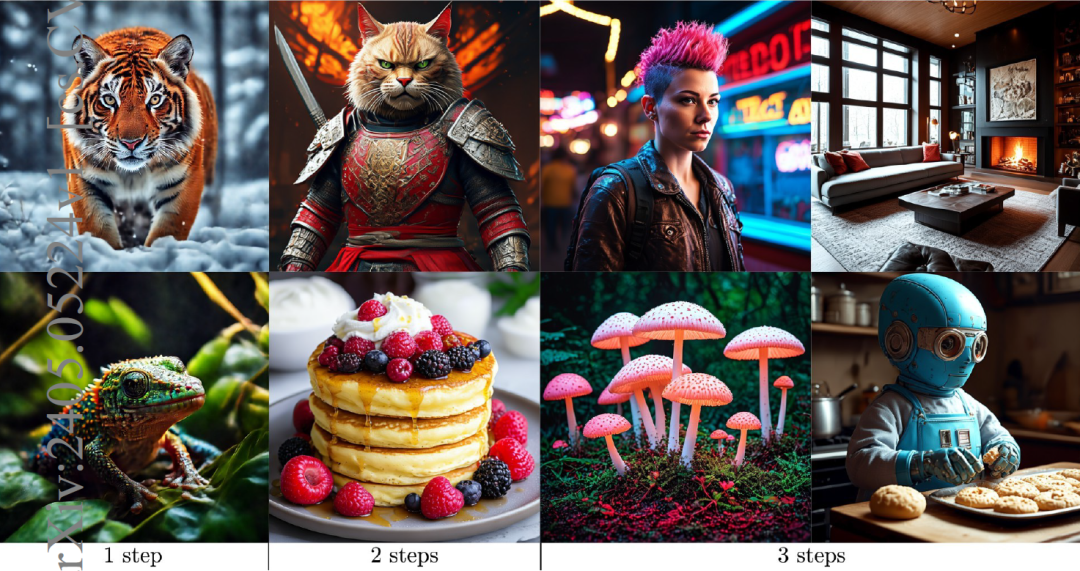
Diffusion models are a powerful generative framework, but come with expensive inference. Existing acceleration methods often compromise image quality or fail under complex conditioning when operating in an extremely low-step regime. In this work, we propose a novel distillation framework tailored to enable high-fidelity, diverse sample generation using just one to three steps. Our approach comprises three key components: (i) Backward Distillation, which mitigates training-inference discrepancies by calibrating the student on its own backward trajectory; (ii) Shifted Reconstruction Loss that dynamically adapts knowledge transfer based on the current time step; and (iii) Noise Correction, an inference-time technique that enhances sample quality by addressing singularities in noise prediction. Through extensive experiments, we demonstrate that our method outperforms existing competitors in quantitative metrics and human evaluations. Remarkably, it achieves performance comparable......
Reviewing Intelligent Cinematography: AI research for camera-based video production
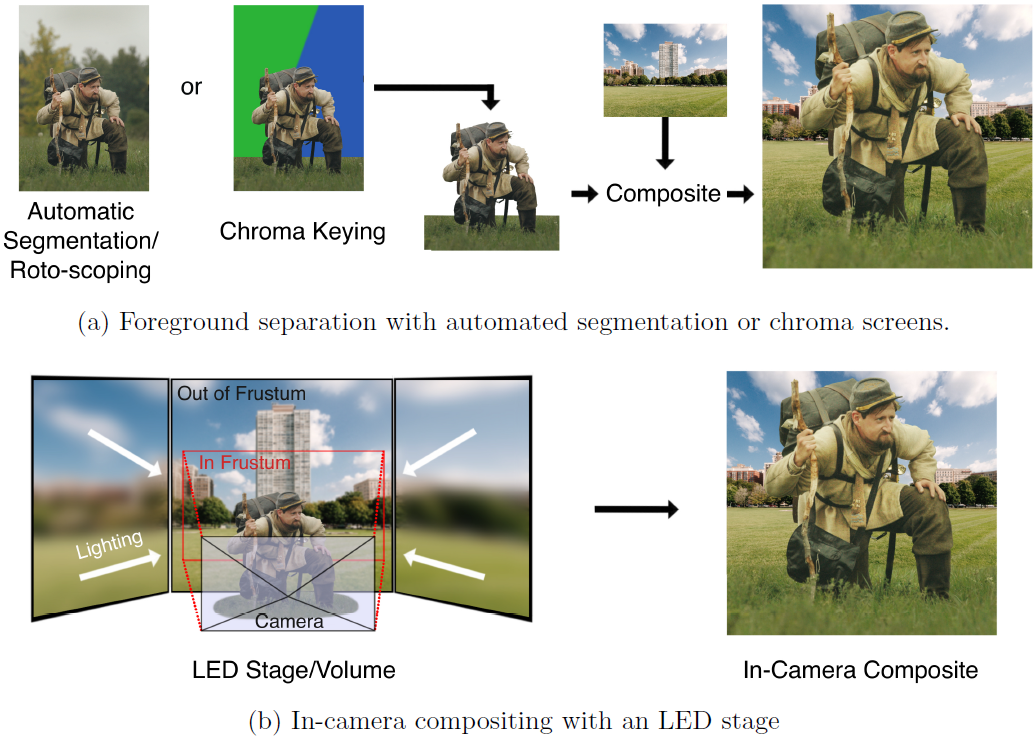
This paper offers a comprehensive review of artificial intelligence (AI) research in the context of real camera content acquisition for entertainment purposes and is aimed at both researchers and cinematographers. Considering the breadth of computer vision research and the lack of review papers tied to intelligent cinematography (IC), this review introduces a holistic view of the IC landscape while providing the technical insight for experts across across disciplines. We preface the main discussion with technical background on generative AI, object detection, automated camera calibration and 3-D content acquisition, and link explanatory articles to assist non-technical readers. The main discussion categorizes work by four production types: General Production, Virtual Production, Live Production and Aerial Production. Note that for Virtual Production we do not discuss research relating to virtual content acquisition, including work on automated video generation, like Stable Di......
StyleMamba : State Space Model for Efficient Text-driven Image Style Transfer

We present StyleMamba, an efficient image style transfer framework that translates text prompts into corresponding visual styles while preserving the content integrity of the original images. Existing text-guided stylization requires hundreds of training iterations and takes a lot of computing resources. To speed up the process, we propose a conditional State Space Model for Efficient Text-driven Image Style Transfer, dubbed StyleMamba, that sequentially aligns the image features to the target text prompts. To enhance the local and global style consistency between text and image, we propose masked and second-order directional losses to optimize the stylization direction to significantly reduce the training iterations by 5 times and the inference time by 3 times. Extensive experiments and qualitative evaluation confirm the robust and superior stylization performance of our methods compared to the existing baselines.......
FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation

Controllable text-to-image (T2I) diffusion models generate images conditioned on both text prompts and semantic inputs of other modalities like edge maps. Nevertheless, current controllable T2I methods commonly face challenges related to efficiency and faithfulness, especially when conditioning on multiple inputs from either the same or diverse modalities. In this paper, we propose a novel Flexible and Efficient method, FlexEControl, for controllable T2I generation. At the core of FlexEControl is a unique weight decomposition strategy, which allows for streamlined integration of various input types. This approach not only enhances the faithfulness of the generated image to the control, but also significantly reduces the computational overhead typically associated with multimodal conditioning. Our approach achieves a reduction of 41% in trainable parameters and 30% in memory usage compared with Uni-ControlNet. Moreover, it doubles data efficiency and can flexibly generate imag......
TALC: Time-Aligned Captions for Multi-Scene Text-to-Video Generation

Recent advances in diffusion-based generative modeling have led to the development of text-to-video (T2V) models that can generate high-quality videos conditioned on a text prompt. Most of these T2V models often produce single-scene video clips that depict an entity performing a particular action (e.g., `a red panda climbing a tree'). However, it is pertinent to generate multi-scene videos since they are ubiquitous in the real-world (e.g., `a red panda climbing a tree' followed by `the red panda sleeps on the top of the tree'). To generate multi-scene videos from the pretrained T2V model, we introduce Time-Aligned Captions (TALC) framework. Specifically, we enhance the text-conditioning mechanism in the T2V architecture to recognize the temporal alignment between the video scenes and scene descriptions. For instance, we condition the visual features of the earlier and later scenes of the generated video with the representations of the first scene description (e.g., `a red pan......
TexControl: Sketch-Based Two-Stage Fashion Image Generation Using Diffusion Model
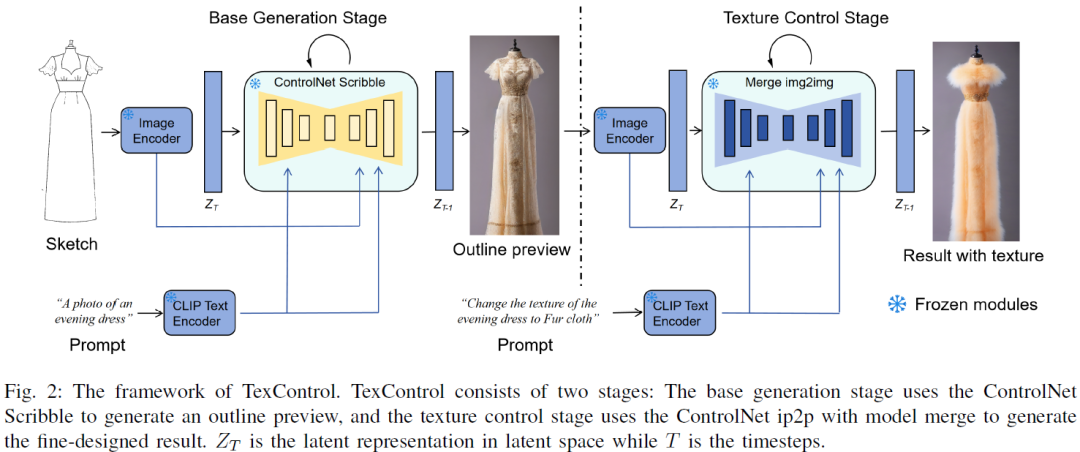
Deep learning-based sketch-to-clothing image generation provides the initial designs and inspiration in the fashion design processes. However, clothing generation from freehand drawing is challenging due to the sparse and ambiguous information from the drawn sketches. The current generation models may have difficulty generating detailed texture information. In this work, we propose TexControl, a sketch-based fashion generation framework that uses a two-stage pipeline to generate the fashion image corresponding to the sketch input. First, we adopt ControlNet to generate the fashion image from sketch and keep the image outline stable. Then, we use an image-to-image method to optimize the detailed textures of the generated images and obtain the final results. The evaluation results show that TexControl can generate fashion images with high-quality texture as fine-grained image generation.......