数据分析的数据的导入和导出
- 前言
- 一、导入数据
- 导入Excel表格数据
- read_excel
- 示例
- 导入CSV格式数据
- read_csv()
- 示例
- 导入JSON格式数据
- JSON简介
- pandas导入JSON数据
- read_json()
- 导入txt文件
- read_table
- 示例
- 导入(爬取)网络数据
- read_html()
- 示例
- 二、输出数据
- CSV格式数据输出
- to_csv
- 示例
- xlsx格式数据输出
- to_excel
- 示例1
- 示例2
前言
数据分析的数据的导入和导出是数据分析流程中至关重要的两个环节,它们直接影响到数据分析的准确性和效率。在数据导入阶段,首先要确保数据的来源可靠、格式统一,并且能够满足分析需求。这通常涉及到数据清洗和预处理的工作,比如去除重复数据、处理缺失值、转换数据类型等,以确保数据的完整性和一致性。
导入数据后,接下来就需要进行数据的探索和分析。在这一阶段,分析师会利用各种统计方法和可视化工具来揭示数据背后的规律和趋势。通过对数据的深入挖掘,可以发现隐藏在数据中的有用信息,为决策提供支持。
然而,数据分析的目的不仅仅是为了理解和解释数据,更重要的是将数据转化为有价值的信息和知识。这就需要将分析结果以易于理解和使用的形式导出,供其他人使用。数据导出通常包括生成报告、制作图表、提供数据接口等方式,以便将分析结果直观地展示给决策者、业务人员或其他相关人员。
在数据导出时,还需要注意数据的安全性和隐私保护。对于敏感数据,要进行适当的脱敏处理,避免数据泄露和滥用。同时,导出的数据格式也要考虑接收方的需求和使用习惯,确保数据的可用性和易用性。
一、导入数据
导入Excel表格数据
Excel文件有两种格式,分别为xls格式和xlsx格式。这两种格式的文件都可以用Python的Pandas模块的read_excel方法导入。
read_excel
pandas库提供了多种方式来读取Excel文件,其中最常用的是read_excel()函数。该函数可以将Excel文件读取为一个DataFrame对象,具体用法如下:
import pandas as pd
# 导入Excel表格
data = pd.read_excel('文件路径/文件名.xlsx', sheet_name='工作表名称', header=行索引, index_col=列索引, skiprows=跳过行数, usecols=使用的列范围)
# 打印数据
print(data)
参数说明:
read_excel()函数的参数说明如下:
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, skip_footer=0, na_values=None, parse_dates=False, date_parser=None, thousands=None, decimal='.', keep_default_na=True, thousands=None, decimal='.', keep_default_na=True, thousands=None, decimal='.', keep_default_na=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal='.', keep_default_na=True, verbose=False, convert_float=True, has_index_names=None, converters=None, true_values=None, false_values=None, index_col=None, nrows=None, na_values=None, squeeze=False, skiprows=None, skip_footer=0, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal='.', keep_default_na=True, true_values=None, false_values=None, squeeze=False, parse_dates=False, date_parser=None, thousands=None, decimal='.', keep_default_na=True, converters=None, dtype=None, usecols=None, engine=None)
参数说明:
io:指定要读取的文件路径(字符串)、字节流对象、URL、ExcelFile对象或类似对象(如xlrd、openpyxl或pyxlsb)。sheet_name:指定要读取的工作表名称。可以是字符串、整数(表示工作表索引)或list(表示要读取的多个工作表)。header:指定哪一行作为列名。默认为0,表示第一行作为列名。可以设置为整数(表示第几行)或list(表示多级列名)。names:指定自定义列名。可以是list或None。index_col:指定哪一列作为行索引。默认为None,表示不设置行索引。可以是整数(表示第几列)或列名。usecols:指定要读取的列范围。可以是整数(表示第几列)或列名列表。例如,usecols='A:C'表示只读取A、B和C列。dtype:指定每列的数据类型。可以是字典(列名为键,数据类型为值)或None。skiprows:指定要跳过的行数。可以是整数(表示跳过多少行)或列表(表示要跳过的行号)。skip_footer:指定要跳过的末尾行数。默认为0,表示不跳过末尾行。na_values:指定要替换为NaN的值。可以是标量、字符串、列表或字典。parse_dates:指定是否解析日期列。默认为False。date_parser:指定用于解析日期的函数。默认为None。thousands:指定千分位分隔符的字符。默认为None,表示没有千分位分隔符。decimal:指定小数点字符。默认为’.'。converters:指定自定义的转换函数。可以是字典(列名为键,转换函数为值)或None。dtype:指定结果的数据类型。默认为None,表示按推断得出数据类型。verbose:指定是否显示详细信息。默认为False。
以上是read_excel()函数的一些常用参数,还有其他参数可以在需要时进行了解。
read_excel()函数还支持其他参数,例如sheet_name=None可以导入所有工作表,na_values可以指定要替换为NaN的值等。你可以查阅pandas官方文档了解更多详细信息。
ps:
read_excel方法返回的结果是DataFrame,DataFrame的一列对应着Excel的一列。
示例
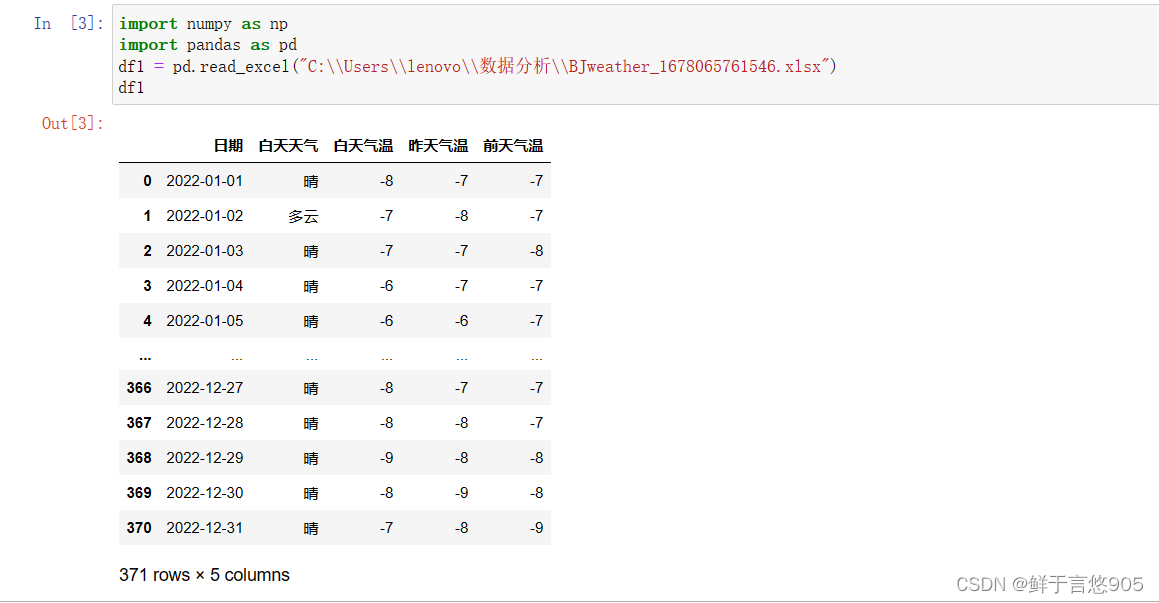
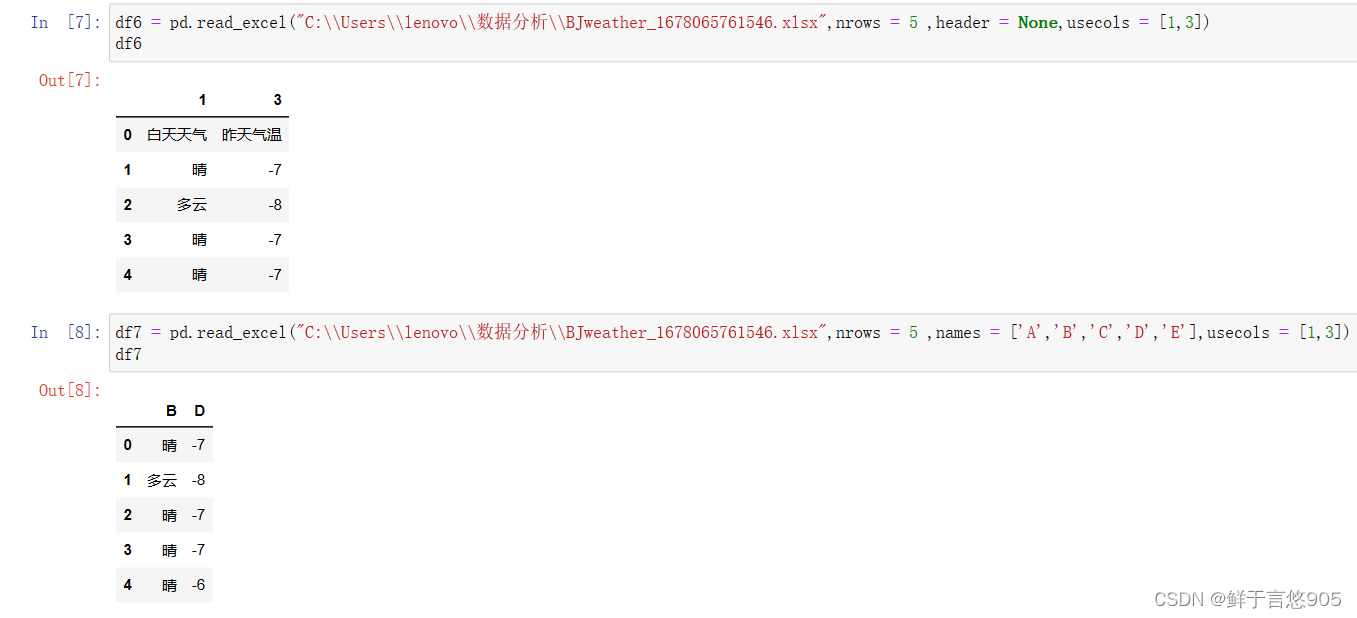
nrows 导入前5行数据
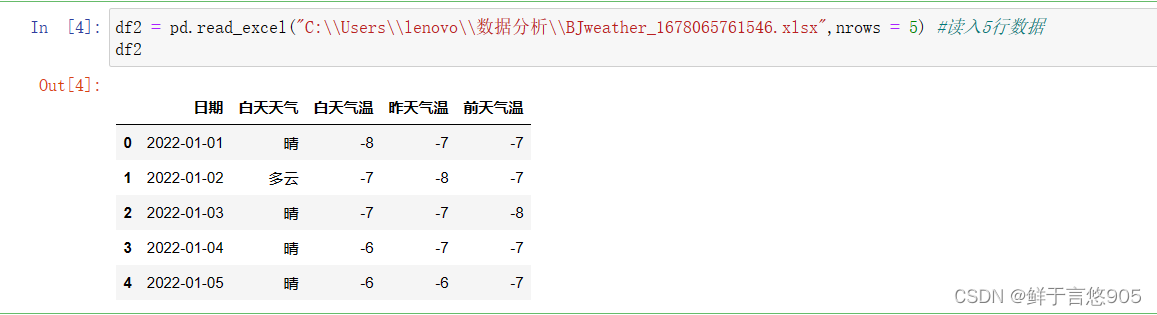
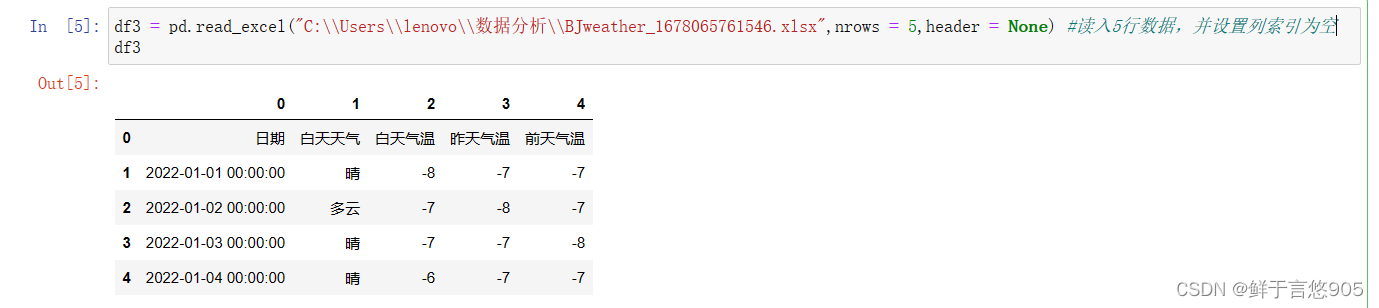
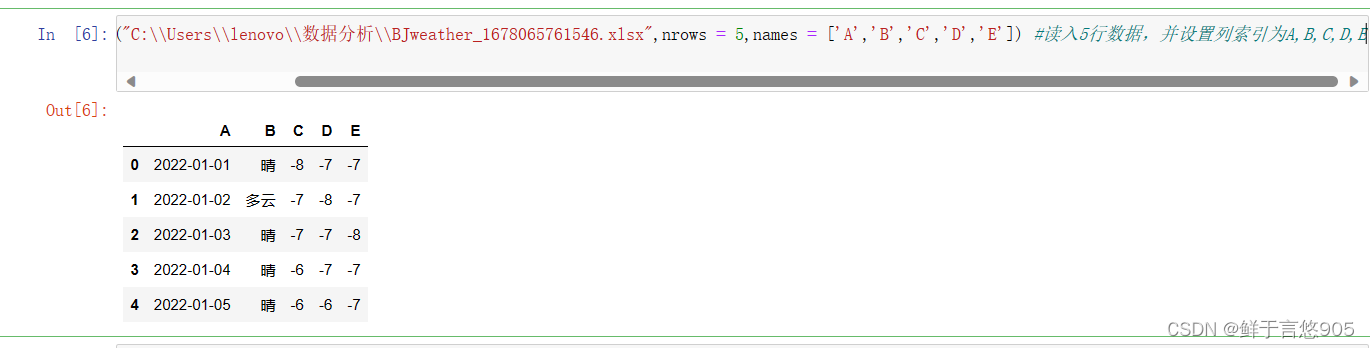
usecols 控制输入第一列和第三列
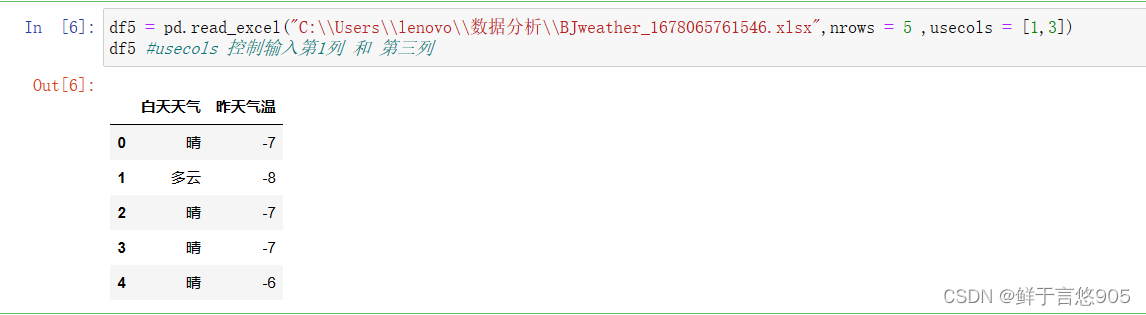
导入CSV格式数据
CSV是一种用分隔符分割的文件格式。由于Excel文件在存放巨量数据时会占用极大空间,且导入时也存在占用极大内存的缺点,因此,巨量数据常采用CSV格式。
read_csv()
在Python中,导入CSV格式数据通过调用pandas模块的read_csv方法实现。
read_csv()函数的参数说明如下:
-
filepath_or_buffer(必选):要读取的csv文件的路径或文件对象。可以是本地文件路径、URL、文件对象或包含以上类型的迭代器。 -
sep(可选,默认为逗号):指定csv文件中数据的分隔符。 -
delimiter(可选,默认为None):与sep参数功能相同,用于指定分隔符。 -
header(可选,默认为’infer’):指定csv文件中的行作为列名的行数,默认为第一行。如果设置为None,则表示文件没有列名。 -
names(可选,默认为None):用于指定列名的列表,如果header=None,则需要通过该参数来指定列名。 -
index_col(可选,默认为None):用于指定哪些列作为索引列,可以是单列索引或多列索引。 -
usecols(可选,默认为None):用于指定需要读取的列,可以是列名或列索引的列表。 -
squeeze(可选,默认为False):用于指定是否将只有一列的数据读取为Series对象而不是DataFrame对象。 -
prefix(可选,默认为None):用于给列名添加前缀。 -
mangle_dupe_cols(可选,默认为True):用于处理重复的列名。 -
dtype(可选,默认为None):用于指定每列的数据类型。可以是Python的基本数据类型或pandas的数据类型。 -
engine(可选,默认为’C’):用于指定用于解析的引擎。 -
converters(可选,默认为None):用于指定需要对某些列进行转换的函数。 -
true_values(可选,默认为None):用于指定哪些值表示True。 -
false_values(可选,默认为None):用于指定哪些值表示False。 -
skiprows(可选,默认为None):用于跳过指定的行数。 -
skipfooter(可选,默认为0):用于跳过文件末尾指定的行数。 -
nrows(可选,默认为None):用于限制读取的行数。 -
na_values(可选,默认为None):用于指定哪些值表示缺失值。 -
keep_default_na(可选,默认为True):用于指定是否保留默认的缺失值标识符。 -
na_filter(可选,默认为True):用于指定是否将缺失值解析为NaN。 -
verbose(可选,默认为False):用于指定是否打印读取过程中的详细信息。 -
parse_dates(可选,默认为False):用于指定需要解析为日期时间类型的列。 -
infer_datetime_format(可选,默认为False):用于是否尝试自动解析日期时间格式。 -
keep_date_col(可选,默认为False):用于指定是否保留原始日期列。 -
date_parser(可选,默认为None):用于指定自定义日期时间解析函数。 -
dayfirst(可选,默认为False):用于指定是否将日期中的天作为第一位。 -
cache_dates(可选,默认为True):用于指定是否缓存解析的日期时间数据。 -
thousands(可选,默认为None):用于指定千位分隔符。 -
decimal(可选,默认为’.'):用于指定小数点分隔符。 -
lineterminator(可选,默认为None):用于指定行终止符。 -
quotechar(可选,默认为’"'):用于指定引用字符。 -
quoting(可选,默认为0):用于指定引用的规则。 -
doublequote(可选,默认为True):用于指定是否将引用字符中的引号转义。 -
escapechar(可选,默认为None):用于指定转义字符。 -
comment(可选,默认为None):用于指定注释字符。 -
encoding(可选,默认为None):用于指定文件的编码格式。 -
dialect(可选,默认为None):用于指定CSV格式的方言。 -
error_bad_lines(可选,默认为True):用于指定是否跳过包含错误的行。 -
warn_bad_lines(可选,默认为True):用于指定是否显示跳过包含错误的行的警告信息。 -
on_bad_lines(可选,默认为’warn’):用于指定错误处理机制。 -
skip_blank_lines(可选,默认为True):用于指定是否跳过空行。 -
delimiter_whitespace(可选,默认为False):用于指定是否使用空格作为分隔符。 -
compression(可选,默认为’infer’):用于指定文件的压缩格式。
除了上述参数外,还有一些其他参数,可以通过查看pandas官方文档来获取更详细的信息。
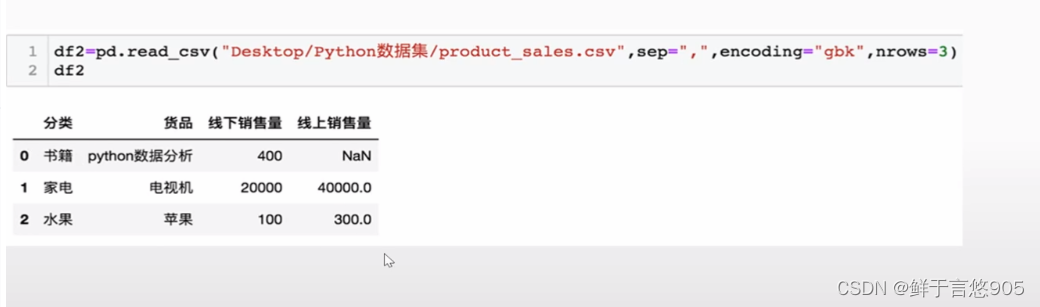
示例
假如encoding 如果是utf-8 的话就是乱码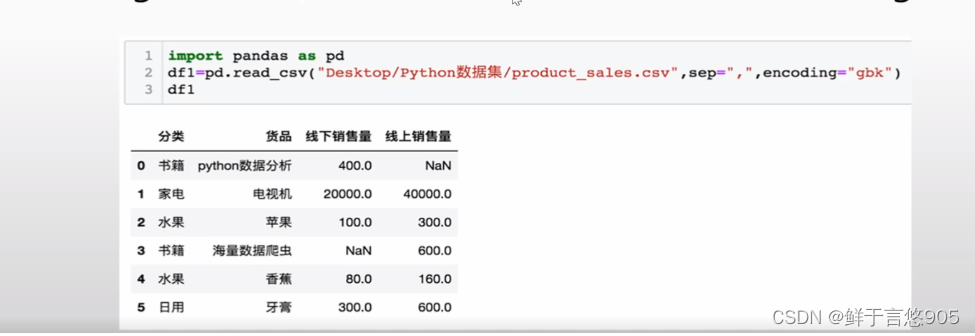
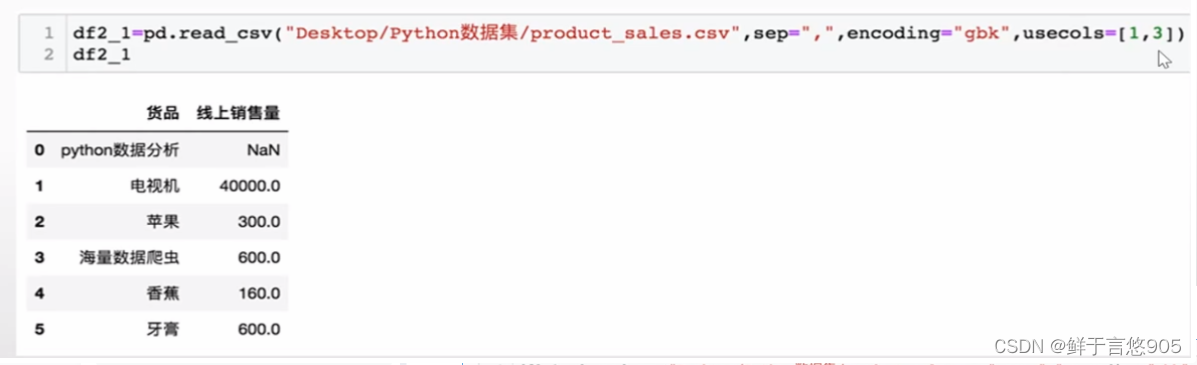
usecols控制输出第一列和第三列
列名重命名

导入JSON格式数据
JSON简介
JSON是一种轻量级的数据交换格式,容易阅读,也容易被机器扫描,在互联网应用中很常见。有时候从后台系统里导出来的数据就是JSON格式。
JSON文件实际存储的时一个JSON对象或者一个JSON数组。JSON对象是由多个键值对组成的,类似于Python的字典;
JSON数组由多个JSON对象组成,类似于Python列表。

pandas导入JSON数据
read_json()
read_json函数是一个读取JSON文件的函数。它的作用是将指定的JSON文件加载到内存中并将其解析成Python对象。这个函数通常用于读取存储数据的JSON文件,以便在程序中对数据进行操作和处理。
参数说明:
file_path:必需,一个字符串,表示要读取的JSON文件的路径。encoding:可选,一个字符串,表示要使用的编码方式。默认为'utf-8'。errors:可选,一个字符串,表示遇到解码错误时的处理方式。默认为'strict'。object_hook:可选,一个函数,用于将解析的JSON对象转换为自定义的Python对象。默认为None。parse_float:可选,一个函数,用于将解析的浮点数转换为自定义的Python对象。默认为None。parse_int:可选,一个函数,用于将解析的整数转换为自定义的Python对象。默认为None。parse_constant:可选,一个函数,用于将解析的JSON常量转换为自定义的Python对象。默认为None。object_pairs_hook:可选,一个函数,用于将解析的JSON键值对转换为自定义的Python对象。默认为None。**kw:可选,一些其他参数,用于控制解析过程的细节。例如,kw={'allow_comments': True}表示允许在JSON文件中包含注释。
返回值:
- Python对象:将JSON数据解析后得到的Python对象。
注意事项:
- 读取的JSON文件必须存在并且格式正确,否则函数将会抛出异常。
- JSON文件可以包含不同类型的数据,如字符串、数字、布尔值、列表、字典等。
- 解析后的Python对象的类型将根据JSON文件中的数据类型进行推断。
示例用法:
data = read_json("data.json")
print(data)
输出结果:
{
"name": "John",
"age": 25,
"is_student": true,
"courses": ["Math", "Science", "English"],
"address": {"street": "123 Main St", "city": "New York"}
}
导入txt文件
当需要导入存在于txt文件中的数据时,可以使用pandas模块中的read_table方法。它的参数和用法与read_csv方法类似。
read_table
read_table函数是pandas库中的一个函数,用于将一个表格文件读入为一个DataFrame对象。
函数语法:
pd.read_table(filepath_or_buffer, sep='\t', header='infer', names=None, index_col=None, dtype=None, na_values=None, converters=None, skiprows=None, skipfooter=0, nrows=None, quotechar=None, encoding=None, engine=None)
参数说明:
filepath_or_buffer:文件的路径或者打开的文件对象。sep:分隔符,默认为制表符(‘\t’)。header:指定数据中的哪一行作为表头,默认为‘infer’,表示自动推断。names:用于指定列名,默认为None,即使用表头作为列名。index_col:用于指定哪一列作为索引,默认为None,即不使用列作为索引。dtype:指定数据类型,默认为None。na_values:用于指定缺失值的表示方式,默认为None。converters:用于指定某些列的转换函数,默认为None。skiprows:用于指定需要跳过的行数,默认为None。skipfooter:用于指定需要跳过的尾部行数,默认为0。nrows:用于指定读取的行数,默认为None,表示读取所有行。quotechar: 用于指定字段值的引号,默认为None。encoding: 用于指定文件的编码,默认为None,表示使用系统默认编码。engine: 用于指定读取文件的引擎,默认为None,表示自动选择。
返回值:返回一个DataFrame对象,表示读取的表格数据。
示例
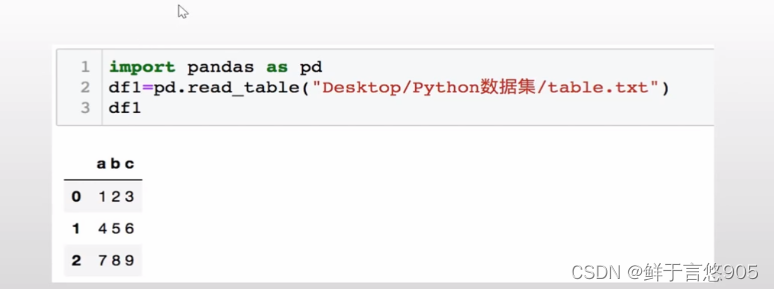
导入(爬取)网络数据
在Python的数据分析中,除了可以导入文件和数据库中的数据,还有一类非常重要的数据就是网络数据。网络中每天都会产生大量数据,这些数据具有实时性、种类丰富的特点,因此对于数据分析而言是十分重要的一类数据来源。
关键技术:爬取网络表格类数据, pandas库read_html()方法。
read_html()
read_html方法用于导入带有table标签的网页表格数据。
使用该方法前,首先要确定网页表格是否为table标签。
具体方法为,鼠标右键单击网页中的表格,在弹出的菜单中选择"查看元素”,查看代码中是否含有表格标签<table> </table>的字样,确定后才可以使用read_html方法。
read_html()函数是pandas库中的一个功能,它可以用于从HTML文件或URL中读取表格数据并将其转换为DataFrame对象。
函数的语法如下:
pandas.read_html(io, match=None, flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, thousands=',', encoding=None, decimal='.', converters=None, na_values=None)
参数说明:
io:可以是一个包含HTML文本的字符串、本地HTML文件的路径或URL。match:可以是一个字符串或正则表达式,用于匹配解析出的表格的名称。flavor:指定解析器的名称。可选值是"bs4"(使用BeautifulSoup解析器)或"html5lib"(使用html5lib解析器)。header:指定表格的表头行,默认为0,即第一行。index_col:设置作为索引列的列号或列名,默认为None,即不设置索引列。skiprows:指定要跳过的行数。可以是一个整数(表示跳过的行数)或一组整数(表示要跳过的行号)。attrs:一个字典,用于设置表格的属性。可以使用键值对指定属性名称和属性值。parse_dates:如果为True,则尝试解析日期并将其转换为datetime对象。thousands:设置千位分隔符的字符,默认为英文逗号","。encoding:指定文件的编码格式。decimal:设置小数点的字符,默认为英文句点"."。converters:一个字典,用于指定不同列的数据类型转换函数。na_values:一个列表或字符串,用于指定需要识别为缺失值的特殊字符串。
返回值:
- 如果HTML文件中只有一个表格,则返回一个
DataFrame对象。 - 如果HTML文件中有多个表格,则返回一个包含所有表格的列表,每个表格都以
DataFrame对象的形式存储在列表中。
使用read_html()函数可以方便地将HTML中的表格数据读取为DataFrame对象,以便进行后续的数据处理和分析。
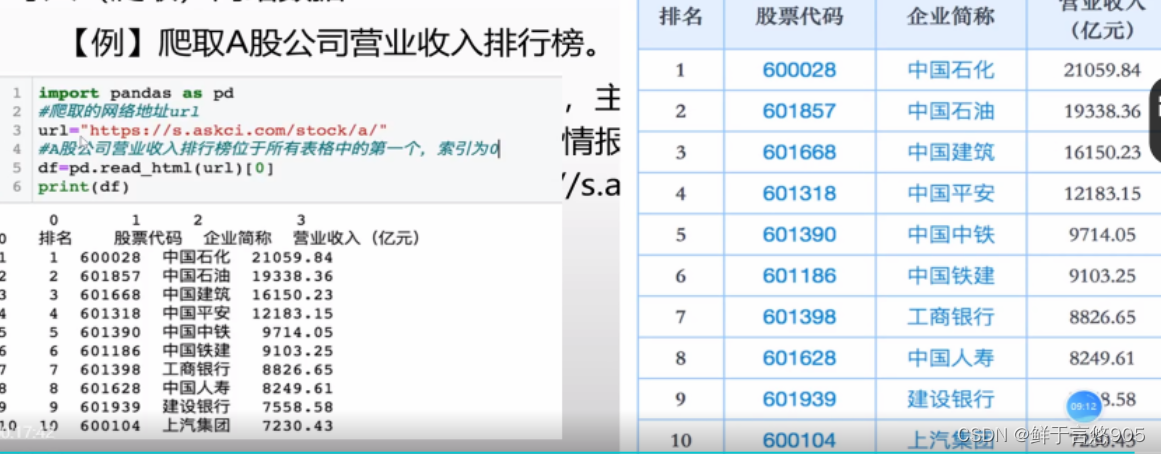
示例
【例】爬取A股公司营业收入排行榜。
中商情报网是专业的产业情报分享云平台,主要提供研究报告、行业分析、市场调研等数据。
在本案例中,通过爬取中商情报网中A股公司营业收入排行榜表格获取相应的金融数据,数据网址为
https://s.askci.com/stock/a/
二、输出数据
CSV格式数据输出
to_csv
to_csv函数是pandas库中的一个方法,用于将DataFrame对象保存为CSV文件。CSV文件是一种常用的文本文件格式,用于存储表格数据。该函数可以将DataFrame对象的数据保存为CSV文件,以便后续可以通过其他程序或工具进行读取和处理。
函数的语法如下:
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.', errors='strict')
参数说明:
path_or_buf:保存CSV文件的路径或文件对象(文件名、文件路径、文件描述符等)sep:指定数据字段之间的分隔符,默认为逗号(,)na_rep:在数据中代表缺失值的字符串,默认为空字符串float_format:浮点数格式,指定数据中浮点数的输出格式,默认为None(即按照默认格式输出)columns:指定保存的列,默认为None,表示保存所有列。也可以自己指定需要保存的列名列表header:是否保存列名,默认为Trueindex:是否保存行索引,默认为Trueindex_label:行索引列的列名,默认为Nonemode:文件打开模式,默认为’w’,即覆盖写入。也可以设置为’a’,表示在已有文件末尾追加写入encoding:文件编码格式,默认为None,即使用系统默认编码格式compression:文件压缩格式,默认为’infer’,表示自动推断。也可以设置为’gzip’、‘bz2’、'zip’等压缩格式quoting:控制CSV文件中的引号常量,默认为None,表示无引号。也可以设置为’none’、‘nonnumeric’、‘minimal’、'all’等quotechar:指定引号字符,默认为双引号(")line_terminator:行结束符,默认为None。可以设置为’\r\n’、‘\n’、'\r’等chunksize:一次性写入的行数,默认为None,表示全部写入date_format:日期格式,默认为None。可以设置为’%Y-%m-%d’等日期格式字符串doublequote:是否双引号转义,默认为Trueescapechar:转义字符,默认为Nonedecimal:浮点数输出的小数点分隔符,默认为点号(.)errors:报错模式,默认为’strict’,表示严格模式。也可以设置为’ignore’、'replace’等
示例
【例】导入sales.csv文件中的前10行数据,并将其导出为sales_new.csv文件。
关键技术: pandas库的to_csv方法。
在该例中,首先通过pandas库的read_csv方法导入sales.csv文件的前10行数据,然后使用pandas库的to_csv方法将导入的数据输出为sales_new.csv文件。
xlsx格式数据输出
to_excel
to_excel函数是pandas库中的一个方法,用于将DataFrame对象保存到Excel文件中。
函数的语法为:
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', index=True, header=True)
参数说明:
excel_writer:要保存的Excel文件名或文件路径,可以是字符串类型或ExcelWriter对象。sheet_name:要保存到的Sheet的名称,默认为’Sheet1’。index:是否保存索引列,默认为True。header:是否保存列名,默认为True。startrow:写入数据时的起始行位置,默认为0。startcol:写入数据时的起始列位置,默认为0。merge_cells:是否合并单元格,默认为False。encoding:保存Excel文件时的字符编码,默认为utf-8。engine:使用的Excel写入引擎,默认为None,表示使用pandas的默认引擎。
示例用法:
import pandas as pd
data = {'Name': ['John', 'Emily', 'Michael'],
'Age': [25, 30, 35],
'City': ['New York', 'Paris', 'London']}
df = pd.DataFrame(data)
df.to_excel('data.xlsx', sheet_name='Sheet1', index=False, header=True, startrow=2, startcol=1, merge_cells=True, encoding='utf-8', engine=None)
以上代码将DataFrame对象df保存为名为’data.xlsx'的Excel文件,在Sheet1中写入数据,不保存索引列,保存列名,数据从第3行第2列开始,合并单元格,使用utf-8编码,使用pandas的默认引擎。
另外,to_excel方法还支持其他参数,如startrow、startcol等,用于设置写入数据的起始行、起始列位置。详细使用方法可参考pandas官方文档。
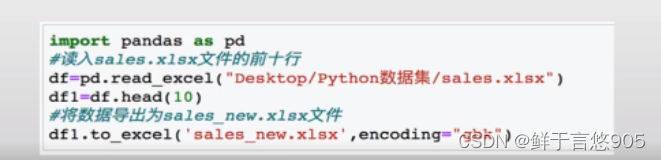
示例1
【例】如销售文件格式为sales.xlsx文件,这种情况下该如何处理?
关键技术: DataFrame对象的to_excel方法
与上例相似,该例首先利用Pandas库的read_excel方法读入sales.xlsx文件,然后使用to_excel方法导出新文件。
示例2
【例】将sales.xlsx文件中的前十行数据,导出到sales_new.xlsx文件中名为df1的sheet页中,将sales.xlsx文件中的后五行数据导出到sales_new.xlsx文件中名为df2的sheet页中。
关键技术: Pandas库中的ExcelWriter方法。
解决该问题,首先在sales_new.xlsx文件中建立名为df1和df2的sheet页,然后使用pd.ExcelWriter方法打开sales_new.xlsx文件,再使用to_excel方法将数据导入到指定的sheet页中。