感谢阅读
- LangChain介绍
- 百度文心API申请
- 申请百度智能云
- 创建应用
- LLMChain demo以及伪幻觉问题
- 多轮对话的实现
- Sequential Chains
- SimpleSequentialChain
- SequentialChain
- Router Chain
- Documents Chain
- StuffDocumentsChain
- RefineDocumentsChain
- MapReduceDocumentsChain
- MapRerankDocumentsChain
- Document Loaders
- Agent
LangChain介绍
LangChain是一个基于大语言模型(如ChatGPT)的Python框架,专为构建端到端语言模型应用而设计。它提供了一套全面的工具、组件和接口,旨在简化与大型语言模型(LLM)和聊天模型的交互过程,从而轻松创建出功能强大的应用程序。LangChain不仅方便管理语言模型的交互,还能将多个组件灵活链接,满足各种应用场景的需求。使用LangChain,您可以更加高效地构建出具有创新性和实用性的语言模型应用。(这个就是langchain配合文心生成的介绍)
百度文心API申请
申请百度智能云
点我申请
创建应用
点我创建
LLMChain demo以及伪幻觉问题
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain_wenxin.chat_models import ChatWenxin
from langchain.schema import HumanMessage
WENXIN_APP_Key = "你自己的KEY"
WENXIN_APP_SECRET = "你自己的SECRET"
chat = ChatWenxin(
temperature=0.9,
model="ernie-bot-turbo",
baidu_api_key=WENXIN_APP_Key,
baidu_secret_key=WENXIN_APP_SECRET,
verbose=True,
)
def 基本调用(input):
template = f"描述我的{input}一个最佳名字是什么?只返回一个答案,答案限定为3到5字"
prompt = PromptTemplate(input_variables=["input"], template=template)
llm_chain = LLMChain(prompt=prompt, llm=chat)
res = llm_chain.run(product=input)
print(res)
def main():
基本调用("狗狗")
基本调用("宠物公司")
return 0
if __name__ == '__main__':
main()
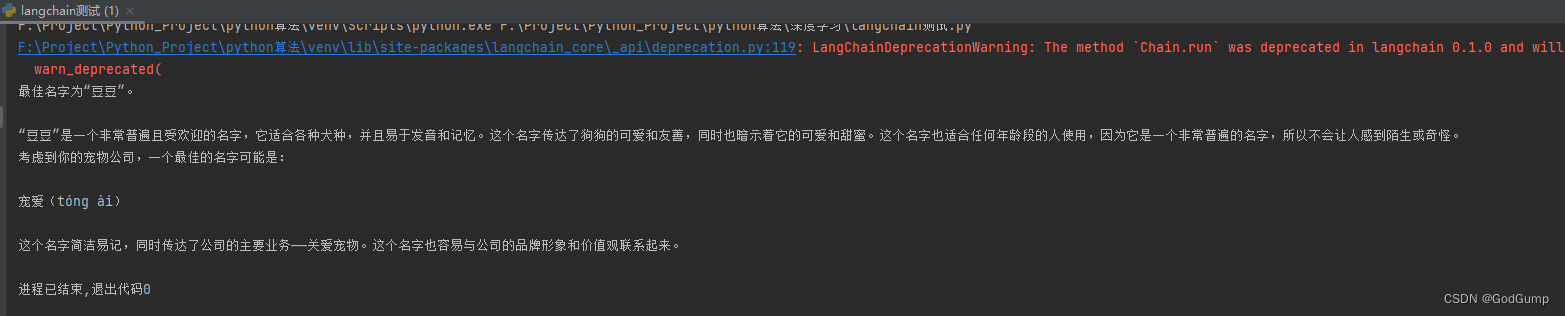
我们上面代码用的是LLMChain通过prompt+input给模型,然后接受返回模型返回。结果如下图:
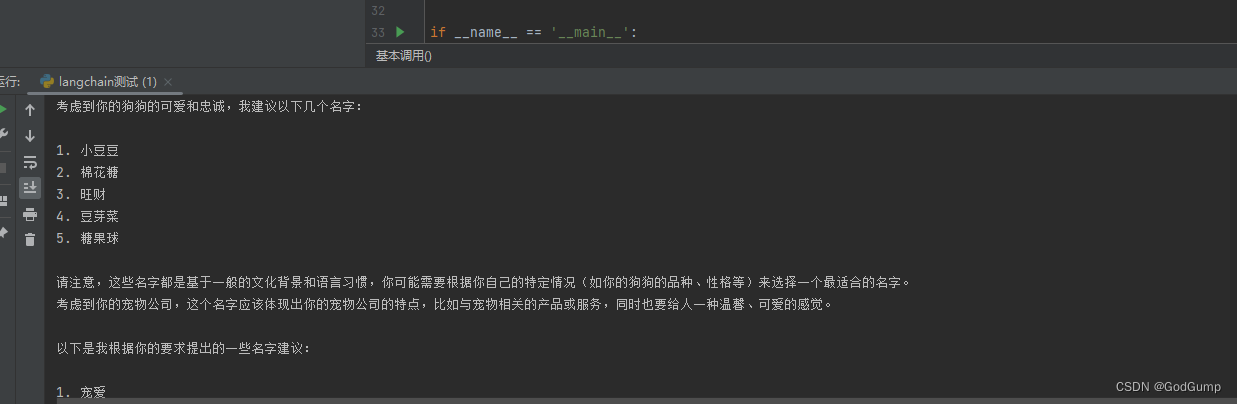
那么真的就这么简单吗?其实我们只需要改一下prompt就可以让模型出现伪幻觉,为什么是伪幻觉?因为这并不是真正的幻觉,而是模型推理的时候由于升维目标可能的维度太多导致模型要去考虑大多数情况而忽略了原本的束缚。我们修改如下:
def 基本调用(input):
# template = f"描述我的{input}一个最佳名字是什么?只返回一个答案,答案限定为3到5字"
template = f"给我的{input}起一个名字?只返回一个答案,答案限定为3到5字"
prompt = PromptTemplate(input_variables=["input"], template=template)
llm_chain = LLMChain(prompt=prompt, llm=chat)
res = llm_chain.run(product=input)
print(res)
def main():
基本调用("狗狗")
基本调用("宠物公司")
return 0
可以看到结果并不是要求的 “只会返回一个” 答案
多轮对话的实现
通过在prompt template里引入{chat_history}变量以及memory机制,Langchain可以实现多轮对话。我们做个示例,那么这个有没有问题呢?当然有,就和人一样,太久的东西会忘记(对于机器来说老早之前的文本历史被舍弃了)。还有就是人有的时候会不会胡乱联想,AI也会(这个才是幻觉问题的一种)。当然会很多。下面是正常的代码:
def 多轮对话():
template = """You are a chatbot having a conversation with a human. Please answer as briefly as possible.
{chat_history}
Human: {human_input}
Chatbot:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history")
llm_chain = LLMChain(
llm=chat,
prompt=prompt,
verbose=False,
memory=memory,
)
res = llm_chain.run(human_input="诸葛亮是谁")
print(res)
res = llm_chain.run(human_input="他有没有老婆")
print(res)
def main():
# 基本调用("狗狗")
# 基本调用("宠物公司")
多轮对话()
return 0
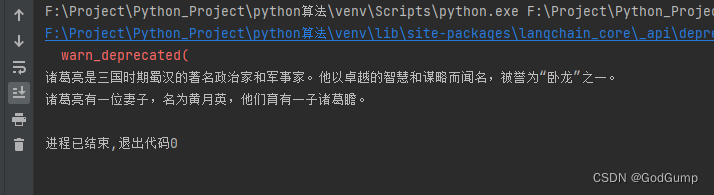
运行结果如下:
Sequential Chains
SimpleSequentialChain
SimpleSequentialChain是最基本的一种Sequential Chains,因为它只有一个输入和一个输出,其中前一个chain的输出为后一个chain的输入。有啥意义?通用模型拿到常识结果,然后找擅长这个领域的专家模型进行解决。是不是可以加大模型的准确率。
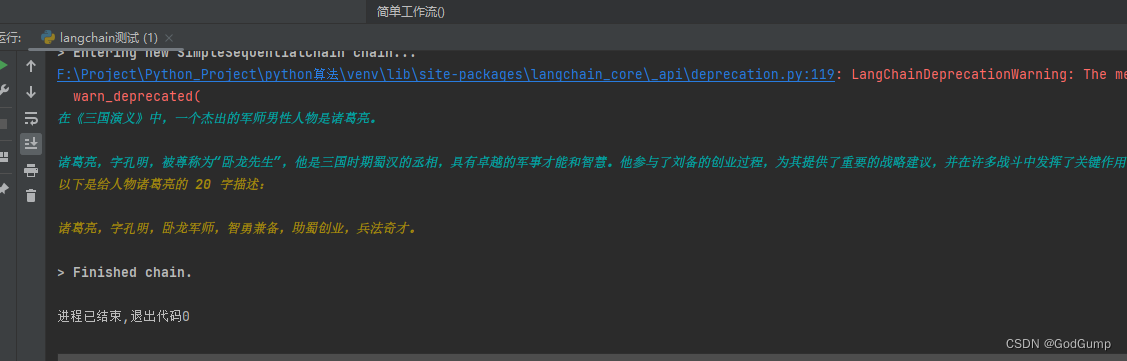
假如我想让第一个模型得到三国演义的一个人物,第二个模型拿到该人物并进行分析。怎么操作呢?如下:
def 简单工作流(input):
# prompt template 1
first_prompt = ChatPromptTemplate.from_template(
"{input}中的一个杰出人物,要求男,军师。只要一个结果"
)
# Chain 1
chain_one = LLMChain(llm=chat, prompt=first_prompt, output_key="person")
# prompt template 2
second_prompt = ChatPromptTemplate.from_template(
"为该人物编写 20 个字的描述:{person}"
)
# chain 2
chain_two = LLMChain(llm=chat, prompt=second_prompt)
# 将chain1和chain2组合在一起生成一个新的chain.
overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two],
verbose=True
)
# 执行新的chain
res = overall_simple_chain.run(input)
# print(res)
def main():
# 基本调用("狗狗")
# 基本调用("宠物公司")
# 多轮对话()
简单工作流("三国演义")
return 0
运行结果
SequentialChain
SequentialChain与SimpleSequentialChain的区别在于它可以有多个输入和输出,而SimpleSequentialChain只有一个输入和输出。
为啥要搞这个?比如你是跨境电商。那么将会面临两个痛点,第一就是不是所有语言我们都掌握。第二个就是由于时差,可能会导致回复消息或者查看评论不及时降低服务分。怎么办?AI来帮你搞定。那么需要AI完成这些事情:
1.将用户评论翻译成中文(机器翻译)
2.概括评论(可以参考文本摘要)
3.识别出用户评论使用的语言(机器翻译)
4.根据2 3的结果按原始评论语言生成回复(文本生成)
5.将回复翻译成中文(机器翻译)
为啥不一个AI,可以说专业的人干专业的事情。AI也一样。下面是以回复评论为列子的代码:
def 多输入单输出():
# prompt template 1: 将评论翻译成中文
first_prompt = ChatPromptTemplate.from_template(
"将下面的评论翻译成中文:"
"\n\n{Review}"
)
# chain 1: input= Review and output= Chinese_Review
chain_one = LLMChain(llm=chat, prompt=first_prompt,
output_key="Chinese_Review"
)
# 概括评论
second_prompt = ChatPromptTemplate.from_template(
"你能用 1 句话概括以下评论吗:"
"\n\n{Chinese_Review}"
)
# chain 2: input= Chinese_Review and output= summary
chain_two = LLMChain(llm=chat, prompt=second_prompt,
output_key="summary"
)
# prompt template 3: 识别评论使用的语言
third_prompt = ChatPromptTemplate.from_template(
"下面的评论使用的是什么语言?:\n\n{Review}"
)
# chain 3: input= Review and output= language
chain_three = LLMChain(llm=chat, prompt=third_prompt,
output_key="language"
)
# prompt template 4: 生成回复信息
fourth_prompt = ChatPromptTemplate.from_template(
"编写对以下摘要的后续回复:"
"\n\n摘要:{summary}"
)
# chain 4: input= summary, language and output= followup_message
chain_four = LLMChain(llm=chat, prompt=fourth_prompt,
output_key="followup_message"
)
# prompt template 5: 将回复信息翻译成英文
five_prompt = ChatPromptTemplate.from_template(
"将下面的评论翻译成英文:"
"\n\n{followup_message}"
)
# chain 5: input= followup_message and output= Chinese_followup_message
chain_five = LLMChain(llm=chat, prompt=five_prompt,
output_key="English_followup_message"
)
overall_chain = SequentialChain(
chains=[chain_one, chain_two, chain_three, chain_four, chain_five],
input_variables=["Review"],
output_variables=["language", "Chinese_Review", "summary",
"followup_message", "English_followup_message"],
verbose=True
)
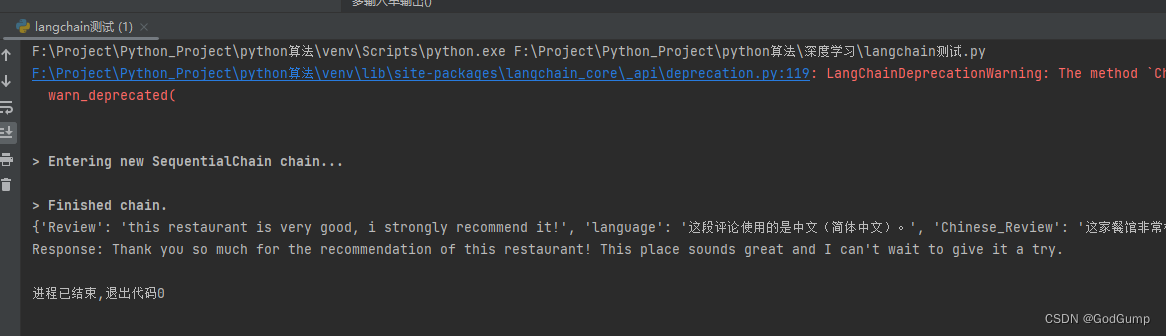
review = "this restaurant is very good, i strongly recommend it!"
res = overall_chain(review)
print(res)
print(res["English_followup_message"])
return 0
def main():
# 基本调用("狗狗")
# 基本调用("宠物公司")
# 多轮对话()
# 简单工作流("三国演义")
多输入单输出()
return 0
Router Chain
根据信息的内容将其传送到不同的chain,而每个chain的职能是只擅长回答自己所属领域的问题,那么在这种场景下就需要一种具有"路由器"功能的chain来将信息传输到不同职能的chain。能不能实现呢?
刚才讲了多对一,有没有一对多来解决这个问题。
在正式代码之前,先看用大模型调用小模型而不进行解析会出现什么情况:
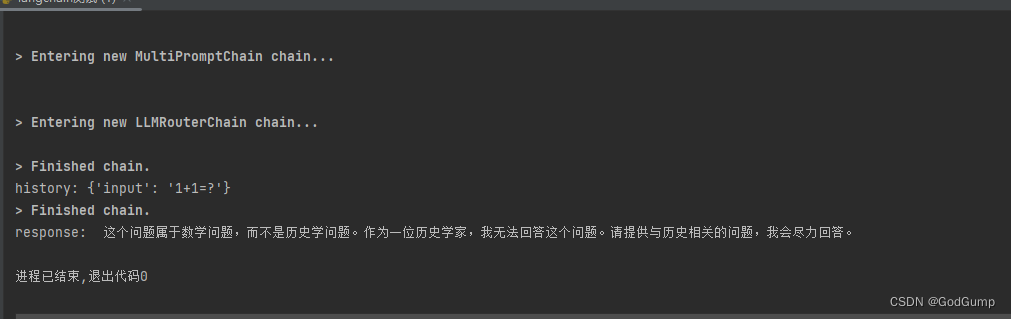
加了解析以后,我们就可以得到正确结果
加了解析的完整代码如下:
def 单输入多输出():
physics_template = """你是一位非常聪明的物理学教授。\
你擅长以简洁易懂的方式回答有关物理的问题。 \
当你不知道某个问题的答案时,你就承认你不知道。
这里有一个问题:
{input}"""
math_template = """你是一位非常优秀的数学家。\
你很擅长回答数学问题。 \
你之所以如此出色,是因为你能够将难题分解为各个组成部分,\
回答各个组成部分,然后将它们组合起来回答更广泛的问题。
这里有一个问题:
{input}"""
history_template = """你是一位非常优秀的历史学家。\
你对各个历史时期的人物、事件和背景有深入的了解和理解。 \
你有能力思考、反思、辩论、讨论和评价过去。 \
你尊重历史证据,并有能力利用它来支持你的解释和判断。
这里有一个问题:
{input}"""
computerscience_template = """你是一位成功的计算机科学家。\
你有创造力,协作精神,前瞻性思维,自信,有很强的解决问题的能力,\
对理论和算法的理解,以及出色的沟通能力。\
你很擅长回答编程问题。
你是如此优秀,因为你知道如何通过描述一个机器可以很容易理解的命令步骤来解决问题,\
你知道如何选择一个解决方案,在时间复杂度和空间复杂度之间取得良好的平衡。
这里有一个问题:
{input}"""
prompt_infos = [
{
"name": "physics",
"description": "擅长回答有关物理方面的问题",
"prompt_template": physics_template
},
{
"name": "math",
"description": "擅长回答有关数学方面的问题",
"prompt_template": math_template
},
{
"name": "history",
"description": "擅长回答有关历史方面的问题",
"prompt_template": history_template
},
{
"name": "computer science",
"description": "擅长回答有关计算机科学方面的问题",
"prompt_template": computerscience_template
}
]
# 创建目标chain {'name': chain}
destination_chains = {}
for p_info in prompt_infos:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = ChatPromptTemplate.from_template(template=prompt_template)
chain = LLMChain(llm=chat, prompt=prompt)
destination_chains[name] = chain
# print(destination_chains)
# 创建要写入prompt的chain string
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
# print("destinations: \n", destinations)
destinations_str = "\n".join(destinations)
# print(destinations_str)
# default prompt,无法被route的input,用default LLM来处理
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(llm=chat, prompt=default_prompt)
MULTI_PROMPT_ROUTER_TEMPLATE = """
给定一个原始文本输入到一个语言模型并且选择最适合输入的模型提示语。你会获得可用的提示语的名称以及该提示语最合适的描述。
记住:任何情况下都要使用原始文本输入。
<< FORMATTING >>
返回一个 Markdown 代码片段,其中 JSON 对象的格式如下:
```json
{{{{
"destination": string
"next_inputs": string
}}}}
```
记住: "destination"的值需要从下面"CANDIDATE PROMPTS"里挑选一个和原始文本输入内容最匹配的值。如果没有匹配的则把值设为"default"
记住: "next_inputs"的值就是给定的原始文本输入
<< CANDIDATE PROMPTS >>
{destinations}
<< INPUT >>
{{input}}
<< OUTPUT (must include ```json at the start of the response) >>
<< OUTPUT (must end with ```) >>
"""
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
destinations=destinations_str
)
# print(router_template)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
# print("\n router_prompt: \n", router_prompt)
# 创建route chain
router_chain = LLMRouterChain.from_llm(chat, router_prompt, verbose=True)
chain = MultiPromptChain(router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain, verbose=True
)
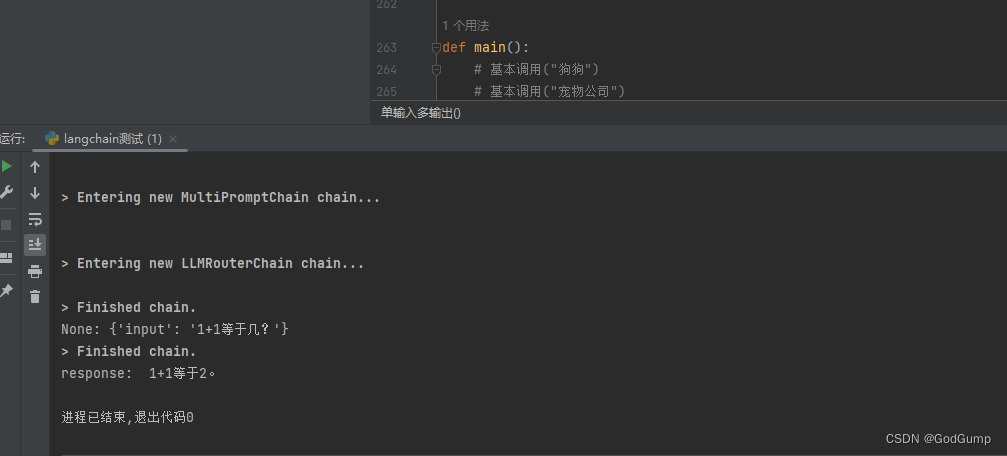
response = chain.run("1+1等于几?")
# response = chain.run("牛顿第一定律?")
# response = chain.run("武则天是谁?")
# response = chain.run("python编程语言有什么特点?")
# response = chain.run("爱情是什么?")
print("response: ", response)
return 0
def main():
# 基本调用("狗狗")
# 基本调用("宠物公司")
# 多轮对话()
# 简单工作流("三国演义")
# 多输入单输出()
单输入多输出()
return 0
Documents Chain
这个主要适用于文档(建议doc,不建议其他格式。如果其他格式比如PDF可以用工具转doc)
下面的 4 种 Chain 主要用于 Document 的处理,在基于文档生成摘要、基于文档的问答等场景中经常会用到。
StuffDocumentsChain
这种链最简单直接,是将所有获取到的文档作为 context 放入到 Prompt 中,传递到 LLM 获取答案。
RefineDocumentsChain
通过迭代更新的方式获取答案。先处理第一个文档,作为 context 传递给 llm,获取中间结果 intermediate answer。然后将第一个文档的中间结果以及第二个文档发给 llm 进行处理,后续的文档类似处理。
MapReduceDocumentsChain
先通过 LLM 对每个 document 进行处理,然后将所有文档的答案在通过 LLM 进行合并处理,得到最终的结果。
MapRerankDocumentsChain
和MapReduceDocumentsChain 类似,先通过 LLM 对每个 document 进行处理,每个答案都会返回一个 score,最后选择 score 最高的答案。
Document Loaders
LangChain 通过 Loader 加载外部的文档,转化为标准的 Document 类型。langchain提供了很多文档加载的类,以便进行不同的文件加载,这些类都通过 langchain.document_loaders 引入。
例如加载文本:UnstructuredFileLoader(txt文件读取)、UnstructuredFileLoader(word文件读取)、MarkdownTextSplitter(markdown文件读取)、UnstructuredPDFLoader(PDF文件读取)
Agent
Agents可以看做是一个智能化的流程封装。它基于LLM的CoT能力,动态串联多个Tool或Chain,完成对复杂问题的自动推导和执行解决。