文章目录
- 优先级队列的使用
- 大堆
- 小堆
- **注意**
- 优先级队列的模拟实现
- push
- pop
- size
- empty
- top
- 仿函数
- 仿函数是什么
- push
- pop
- 仿函数结合优先级队列的优势
优先级队列的使用
优先级队列本质是就是完全二叉树,是个堆.我们可以用优先级队列来取出一段序列中的前N个最大值.

priority_queue<int> pq;
第一个模板参数是数据类型,第二个是容器适配器,通俗点来讲就是这个堆用什么容器来实现,第三个就是排序方式(用仿函数来实现),这个能决定这个堆是大堆还是小堆.
大堆
#include<iostream>
#include<vector>
#include<queue>
using namespace std;
int main()
{
priority_queue<int> pq;
pq.push(1);
pq.push(100);
pq.push(66);
pq.push(9);
pq.push(20);
pq.push(2);
pq.push(8);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
return 0;
}
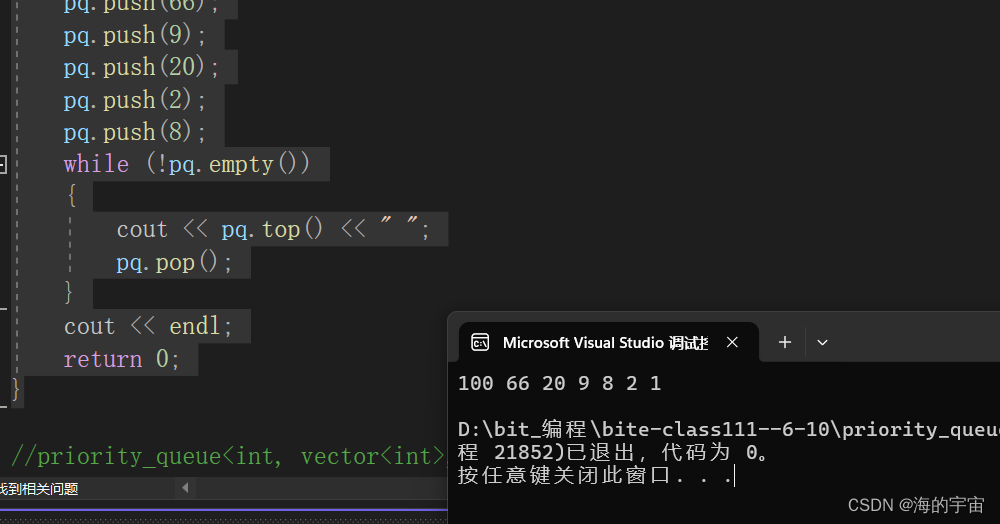
将一些无序的数据存到优先级队列里面,它会给数据排成一个堆,我们可以依次取出数据,然后删除.
默认是大堆
小堆
priority_queue<int, vector<int>, greater<int>> pq;
只需要在定义时声明就行.
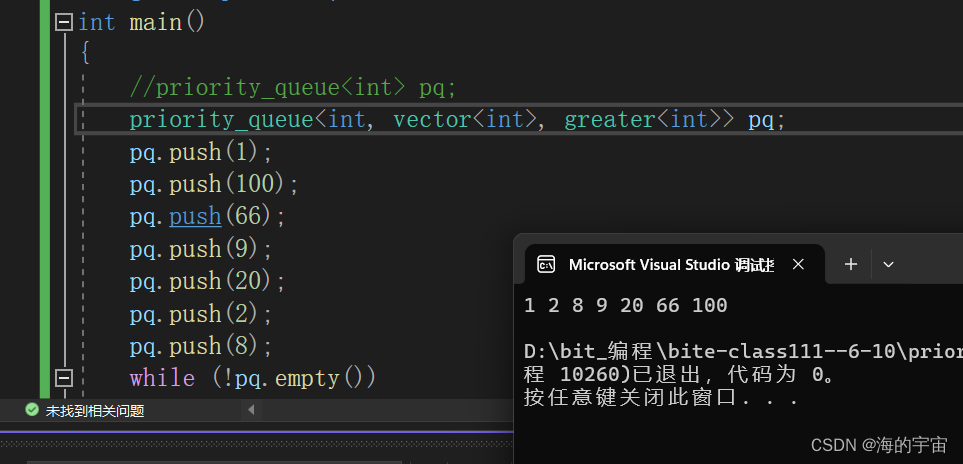
注意
greater是小堆,less是大堆
优先级队列的模拟实现
这里我们先实现一个大堆
template<class T, class Container = vector<T>>
class priority_queue
{
private:
Container _con;
}
因为二叉树push数据的时候经常要交换位置,我们经常要访问它的父亲节点和子节点,所以默认的容器适配器是vector,你也可以改成deque(双向队列)
push
void push(const T& val)
{
_con.push_back(val);
adjust_up(_con.size() - 1);
}
堆的插入是尾插,然后再把这个数据向上调整
void adjust_up(size_t child)
{
size_t parent = (child - 1) / 2;
while (child > 0)
{
if(_con[child] > _con[parent])
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
比较逻辑:找到父亲节点,将父亲节点和子节点比较,如果子节点>父亲节点,交换,然后更新节点.
注意:父亲节点=(子节点-1)/2
pop
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}
在删除节点的时候,为了效率.我们把第一个节点和最后一个节点交换,删除最后一个节点(此时堆的最大值).再把第一个节点(原来的最后一个节点)向下调整.
void adjust_down(size_t parent)
{
size_t child = parent * 2 + 1;
if (child + 1 < _con.size() && _con[child] < _con[child + 1])
child++;
while (child < _con.size())
{
if (_con[parent]<_con[child])
{
swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
向下调整的过程中,如果满足父亲节点<子节点,二者交换.直到父亲节点>子节点或者子节点越界.
注意在向下调整的过程中始终选择大的孩子进行比较,这是为了满足大堆的性质,父亲节点一定>=子节点.
左孩子=父亲节点2+1,右孩子=父亲节点2+2
size
size_t size()
{
return _con.size();
}
size和empty都可以复用vector里面的函数,但是我们要在前面包上vector的头文件
empty
bool empty()
{
return _con.empty();
}
top
const T& top()
{
return _con[0];
}
堆的头就是数组里面的第一个数据
仿函数
我们如果要改变大小堆的话,其实只需要把小于改成大于,大于改成小于就行.但如果每次都这么改,会大大增加我们的工作量,在c语言中,我们可以使用函数指针来解决.在c++中,祖师爷设计了一种更方便的做法,也就是仿函数.
仿函数是什么
仿函数本质上是一个类,这个类能模拟函数的行为.实现内置类型或者自定义类型的比较
template<class T>
struct Less
{
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
int main()
{
Less<int> func;
cout << func(1, 2) << endl;
cout << func.operator()(1, 2) << endl;
return 0;
}

func(1,2)看起来是不是跟我们平时调用函数一样,传两个参数.实际上,Less仿函数里对()进行操作符重载,让我们可以比较两个数的大小
这个做法衍生到堆上面,我们可以传两个仿函数,一个大于,一个小于.然后在堆里面实例化出对象.
template<class T>
struct greater
{
bool operator()(const T& t1,const T& t2)
{
return t1 > t2;
}
};
template<class T>
struct less
{
bool operator()(const T& t1, const T& t2)
{
return t1 < t2;
}
};
push
void adjust_up(size_t child)
{
Compare com;
size_t parent = (child - 1) / 2;
while (child > 0)
{
//if(_con[child] > _con[parent])
//if(_con[parent] < _con[child])
if (com(_con[parent], _con[child]))
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T& val)
{
_con.push_back(val);
adjust_up(_con.size() - 1);
}
pop
void adjust_down(size_t parent)
{
Compare com;
size_t child = parent * 2 + 1;
if (child + 1 < _con.size() && com(_con[child], _con[child + 1]))
child++;
while (child < _con.size())
{
//if (_con[parent] < _con[sun])
if (com(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}
仿函数结合优先级队列的优势
priority_queue<int> pq;
priority_queue<int,vector<int>,greater<int>> pq;
首先我们可以自己控制大堆/小堆.
其次在面对商品等复杂类型中,需要我们根据价格,评价,销量等等进行排序时.单靠商品类里面的一个操作符重载小于或者大于是不够的,我们可以写多个仿函数,争对价格,评价等进行比较.









![[Cpp]类和对象 | 实现日期类](https://img-blog.csdnimg.cn/direct/ba4e5f8af0ac441d9320898b60730aeb.png)