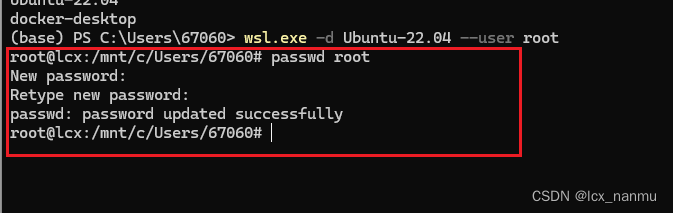
随着大数据时代的到来,传统的数据存储和管理方式已经无法满足日益增长的数据处理需求。HDFS(Hadoop Distributed File System)作为Apache Hadoop项目的一部分,以其高度的容错性、可扩展性和高吞吐量,成为了处理大规模数据集的首选分布式文件系统。本文将详细介绍HDFS的基本概念、适用场景和基本架构。
🔍 HDFS是什么?
HDFS(Hadoop Distributed File System)基于Google发布的GFS论文设计开发。它是Apache Hadoop生态系统中的一个关键组件,旨在存储和管理大规模数据集。
HDFS的设计初衷是解决传统存储系统无法处理的PB级别数据的存储和处理问题,它采用了分布式存储的架构,将数据分散存储在集群的多个节点上,通过横向扩展来提供高性能、高可靠性的数据存储服务,为处理大规模数据集提供了理想的解决方案。
👍 适合做什么?
| 场景 | 说明 |
|---|---|
| 大规模数据集存储 | HDFS可以存储PB级别的数据,适合大规模数据集的存储和管理。 |
| 高吞吐量计算 | HDFS优化了数据访问模式,支持高吞吐量的数据读写。 |
| 数据密集型应用 | 对于需要频繁访问大量数据的应用,如数据挖掘、机器学习和分析处理,HDFS提供了高效的数据访问。 |
| 分布式处理 | HDFS与MapReduce等分布式计算框架配合使用,可以高效地处理分布式数据。 |
❎ 不适合做什么?
低延迟数据访问:HDFS的设计目标不是提供低延迟的数据访问,而是高吞吐量的数据访问。因此,对于需要毫秒级响应时间的应用程序,HDFS可能不是最佳选择。大量小文件:由于HDFS的元数据存储在NameNode中,存储大量小文件会消耗大量的NameNode内存。因此,HDFS不适合用于处理大量小文件。
🎬 应用场景
| 场景 | 说明 |
|---|---|
| 数据湖 | 组织可以将各种结构化和非结构化数据存储在HDFS中,构建数据湖来支持数据分析、机器学习等任务。 |
| 日志处理 | 大型网络服务和系统可以使用HDFS来存储海量的日志数据,以便后续分析、监控和故障排查。 |
| 数据仓库 | HDFS可作为数据仓库的底层存储,用于存储企业数据的历史记录和分析数据。 |
| 批处理任务 | 对于需要处理大规模数据集的批处理任务,如ETL(Extract-Transform-Load)过程,HDFS提供了高吞吐量和可扩展性,使得这些任务能够高效完成。 |
| 数据备份与归档 | HDFS提供了数据备份和归档的解决方案,可以确保数据的安全性和可靠性。 |
💎 架构简介
HDFS 架构采用主从(Master/Slave)模式,主要由Namenode和Datanode节点组成:
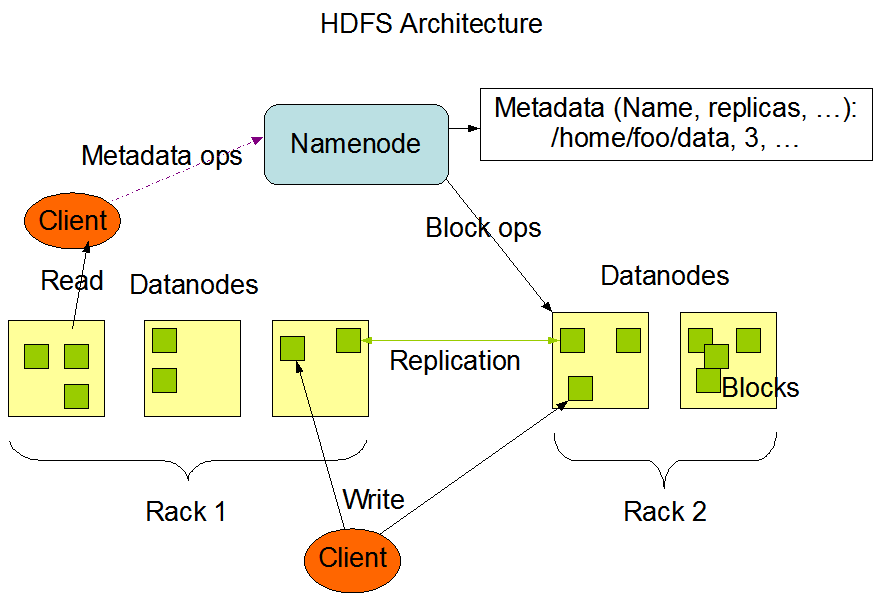
名称节点(NameNode): 维护整个文件系统的元数据信息,包括文件和目录的层次结构、存储位置等。
负责以下功能:
- 存储文件和目录的层次结构信息
- 跟踪数据块的存储位置和副本情况
- 处理文件和目录的创建、重命名、删除等操作
数据节点(Datanode): 负责存储实际的数据块,并执行数据块的读写操作。
负责以下功能:
- 存储数据块
- 接收来自客户端的数据写入请求,并将数据写入本地磁盘
- 接收来自客户端的数据读取请求,并从本地磁盘读取数据返回给客户端
- 定期向 NameNode 汇报自身状态和数据块信息
除了上述核心组件外,HDFS还包括一些辅助组件,如Secondary NameNode、Balancer等,用于增强系统的功能和性能。
HDFS作为Apache Hadoop生态系统的核心组件之一,为处理大规模数据集提供了高性能、高可靠性的解决方案。它的设计理念和架构使其在多种应用场景下都能发挥重要作用,成为大数据处理和分析的重要基础设施之一。希望本文能够为大家在实践中更好地理解和使用HDFS提供指导和帮助。
更多信息可访问官网:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
当然,您也可以关注我,关注后续相关博文。
往期精彩内容推荐
云原生:10分钟了解一下Kubernetes架构
云原生:5分钟了解一下Kubernetes是什么
「快速部署」第二期清单
「快速部署」第一期清单