前期准备
这边使用《程序员的自我修养》中的例子
//a.cpp
extern int shared;
void swap(int* a, int *b);
int main(){
int a = 100;
swap(&a, &shared);
}//b.cpp
int shared = 1;
void swap(int* a, int* b){
*a ^= *b ^= *a ^= *b;
}通过gcc -c 命令编译出相对应的.o文件,通过使用realelf对这些.o文件进行分析,可以看到b.o中有定义两个全局符号,一个是shared的变量,一个是_Z4swapPiS_的函数。而a.o中可以看到对这两个符号的引用。
接下来要分析如何将这两个文件合并成一个可执行文件。
空间地址的分配
链接器的主要功能就是将多个输入文件进行加工,然后输出到一个文件中。而静态链接是如何做到将不同目标文件的各个段进行合并的呢?
按序叠加
首先可以想到一种最简单的方法,就是按顺序叠加,即将各个目标文件依次进行合并

这种方式看起来简单易于实现,但会有一个问题,那就是在目标文件数量很多的情况下,链接形成的可执行文件会有非常非常多的段,而对于x86的机器来说,段加载到虚拟空间后的对齐单位是按页来的,也就是说这么多的段会占用非常大的空间。
这边所讲到的空间有两个意思:
一个是可执行文件的磁盘空间
一个是可执行文件被装载之后的虚拟地址空间
这边分析的时候指的都是第2个意思,即指只分析被加载之后的空间地址分配。
相似段合并
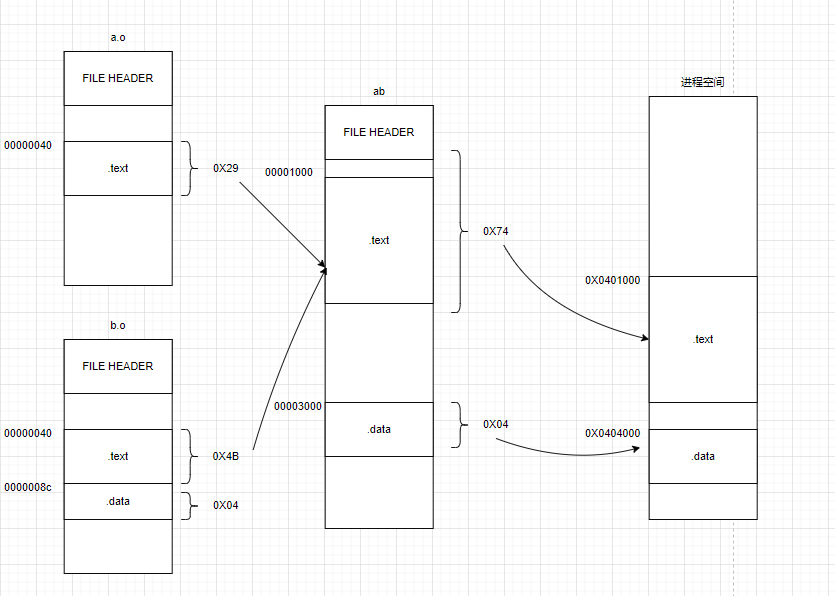
基于上面的空间浪费,另一种更好的解决方法的是将相同性质的段进行合并。比如将a.o 和b.o的.text段合成成一个.text,这样就可以减少内存碎片的产生。

链接过程
实际上现在链接器基本上也是采用相似段合并这种方式。这种方式的链接会分成两个部分
空间与地址分配: 扫描所有输入的文件,获取各个文件中段的属性,如长度、位置等。然后将所有目标文件的符号表的定义和引用收集起来放到统一的全局符号表中。在这一步,链接器就能进行合并相似段的合并。
符号解析与重定位:使用第一步收集到的信息,读取收集到的数据、重定位信息等,进行符号解析与重定位、调整代码中的地址等。第二部实际上是链接过程的核心,特别是重定位过程。
使用ld链接器将a.o 和 b.o链接起来:
ld a.o b.o -e main -o ab
// -e 选项是选择main作为程序入口,默认使用的程序入口是_start
// -o 表示链接输出的文件时ab.
可以通过objdump来链接前后各个段的属性
>>> objdump -h a.o
a.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000029 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000069 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0
>>> objdump -h b.o
b.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 0000004b 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000004 0000000000000000 0000000000000000 0000008c 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000090 2**0
ALLOC
>>> objdump -h ab
ab: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .note.gnu.property 00000020 0000000000400190 0000000000400190 00000190 2**3
CONTENTS, ALLOC, LOAD, READONLY, DATA
1 .text 00000074 0000000000401000 0000000000401000 00001000 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
2 .eh_frame 00000058 0000000000402000 0000000000402000 00002000 2**3
CONTENTS, ALLOC, LOAD, READONLY, DATA
3 .data 00000004 0000000000404000 0000000000404000 00003000 2**2
CONTENTS, ALLOC, LOAD, DATA
4 .comment 0000001c 0000000000000000 0000000000000000 00003004 2**0
CONTENTS, READONLYVMA(virtual memory address, 虚拟地址) 和 LMA(load memory address,加载地址) 一般来说是一样的,但在某些嵌入式系统中是由区别的,具体可以看https://github.com/cisen/blog/issues/887这篇帖子的解释。
这边只关心VMA 和 SIZE即可,从上面的例子中可以看到链接之前各个段的VMA是0,这是因为虚拟地址还没确定;而在链接之后VMA就由对应的值了, .text段被分配到0X0000000000401000这个地址了(因为编译环境是64位,所以和书上略由出入),大小为0X74个字节(0X4B+0X29)。.date段被分配到0000000000404000这个地址中,大小为0X4个字节。
符号解析与重定位
首先看一下在编译之前,a.o中是如何使用swap函数 和 变量share,使用objdump -d 可以看到a.o的 main的反编译代码。
>>> objdump -d a.o
a.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: c7 45 fc 64 00 00 00 movl $0x64,-0x4(%rbp)
f: 48 8d 45 fc lea -0x4(%rbp),%rax
13: 48 8d 35 00 00 00 00 lea 0x0(%rip),%rsi # 1a <main+0x1a>
1a: 48 89 c7 mov %rax,%rdi
1d: e8 00 00 00 00 callq 22 <main+0x22>
22: b8 00 00 00 00 mov $0x0,%eax
27: c9 leaveq
28: c3 retq
可以看到main函数一共41(0X29)个字节,在0X16~0X19个字节就是对share 变量的引用(也就是 #1a<main + 0x1a>的那行), 而 0X1E出就是对函数swap的引用(也就是<main + 0x22>的位置)。 因为a.o中还不知道这些需要重定位对象的地址,所以引用的地址都先赋值成0。
然后在对ab使用objdump,查看ab重定位之后的反汇编代码。
>>> objdump -d ab
ab: file format elf64-x86-64
Disassembly of section .text:
0000000000401000 <main>:
401000: 55 push %rbp
401001: 48 89 e5 mov %rsp,%rbp
401004: 48 83 ec 10 sub $0x10,%rsp
401008: c7 45 fc 64 00 00 00 movl $0x64,-0x4(%rbp)
40100f: 48 8d 45 fc lea -0x4(%rbp),%rax
401013: 48 8d 35 e6 2f 00 00 lea 0x2fe6(%rip),%rsi # 404000 <shared>
40101a: 48 89 c7 mov %rax,%rdi
40101d: e8 07 00 00 00 callq 401029 <_Z4swapPiS_>
401022: b8 00 00 00 00 mov $0x0,%eax
401027: c9 leaveq
401028: c3 retq
0000000000401029 <_Z4swapPiS_>:
401029: 55 push %rbp
........可以看到在main中,已经将之前不知道的函数和变量重新进行了定位,将正确的地址填入了之前都是0的位置。
重定位表
编译器将需要重新定位的变量或者函数统一放在一个位置中,用一个结构进行管理,这个位置结构就是重定位表,在ELF文件中,它会是一个或者多个的section,比如.rel.text就是对.text的重定位表。
使用readelf -r 或者objdump -r 可以看到所有重定位表的内容
>>> readelf -r a.o
Relocation section '.rela.text' at offset 0x430 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000000016 000e00000002 R_X86_64_PC32 0000000000000000 shared - 4
00000000001e 001000000004 R_X86_64_PLT32 0000000000000000 _Z4swapPiS_ - 4
...重定位表根据section 的类型决定使用使什么样的结构进行存储
/* Relocation table entry without addend (in section of type SHT_REL). */
typedef struct
{
Elf32_Addr r_offset; /* Address */
Elf32_Word r_info; /* Relocation type and symbol index */
} Elf32_Rel;
typedef struct
{
Elf64_Addr r_offset; /* Address */
Elf64_Xword r_info; /* Relocation type and symbol index */
} Elf64_Rel;
/* Relocation table entry with addend (in section of type SHT_RELA). */
typedef struct
{
Elf32_Addr r_offset; /* Address */
Elf32_Word r_info; /* Relocation type and symbol index */
Elf32_Sword r_addend; /* Addend */
} Elf32_Rela;
typedef struct
{
Elf64_Addr r_offset; /* Address */
Elf64_Xword r_info; /* Relocation type and symbol index */
Elf64_Sxword r_addend; /* Addend */
} Elf64_Rela;当section的类型是SHT_RELA 的时候,使用的是Elf32_Rela/Elf64_Rela进行存储;当secion的类型是SHT_REL的时候,使用的是Elf32_Rel/Elf64_Rel进行存储。
r_offset对于目标文件来说,就是重定位符号在对应段中的偏移,相当于readelf中的Offset;而对于动态库文件来说,是需要重定位符号的第一个字节的虚拟地址。
r_info 在32位的情况下,低8位是符号的重定位方式,高24位是符号在符号表中的下标;而在64位的情况下,低32位是 符号的重定位方式,高32位是符号在符号表中的下标。
r_append是在SHT_RELA中计算重定位偏移的时候使用的。
重定位修正
这边定义三个符号:
A:保存在被修正位置的值,当重定位项是RELA类型时,这个值被保存在r_append中
P:被修正位置的地址
S:符号的实际地址
修正指令的方式分为两种,一种是是相对寻址修正,一种是绝对寻址修正。
绝对地址修正公式: S + A
相对地址修正公式: S + A - P
分析ab的重定位过程
先通过readelf -s得到符号的实际地址
>>> readelf -s ab
Symbol table '.symtab' contains 19 entries:
Num: Value Size Type Bind Vis Ndx Name
......
11: 0000000000000000 0 FILE LOCAL DEFAULT ABS b.cpp
12: 0000000000000000 0 FILE LOCAL DEFAULT ABS a.cpp
13: 0000000000401029 75 FUNC GLOBAL DEFAULT 2 _Z4swapPiS_
14: 0000000000404000 4 OBJECT GLOBAL DEFAULT 4 shared
15: 0000000000404004 0 NOTYPE GLOBAL DEFAULT 4 __bss_start
16: 0000000000401000 41 FUNC GLOBAL DEFAULT 2 main
....
可以知道shared的实际地址是0X404000,由之前的重定位表可知,shared的重定位类型是R_X86_64_PC32,这个类型的寻址方式是相对寻址,所以重新修正位置应该填入的值为:0X404000- 0x4 - 0X401016 = 2FE6.可以看到0X401016这个位置被修正后确实是2FE6的小端序存储。
接下来是_Z4swapPiS_函数的重定位,_Z4swapPiS_函数的实际地址是0X401029, 重定位类型是R_X86_64_PLT32,这个类型也是一个相对寻址,所以重新修正位置应该填入的值为:0X401029- 0x4 - 0X40101e = 0X7.
总结
这边通过一系列的实验来分析了静态链接时链接器要做的主要的事情,其中重定位是链接过程中比较重要的过程。
这边实验的平台使用的X64环境下的, 与书中的环境不太一致,所以导致readelf -r的输出的重定位类型不太一样,但基本结果还是服合预期的。