本文来自公众号“AI大道理”
正则化作为减少过拟合的手段被大量的使用,那么为什么会出现过拟合呢?正则化又是什么?是怎么样发挥作用的呢?

1、过拟合是什么?
过拟合是指模型在训练集上取得很高的识别性能,但在测试集上的识别性能偏低的现象。
过拟合使模型泛化能力低下,模型陷入局部最优。
过拟合使模型仅学习到局部数据的特点,而不是事物的本质特征。

为什么会过拟合?
1、一方面是数据过少且训练过度,小批量数据的特点无法代表总体;
2、另一方面是模型复杂度高,拟合能力过强,陷入了局部最优。比如一条直线就可以区分的,模型拟合成凹凹凸凸的曲线。
在参数更新过程中,w的更新是没有限制的,w的值可以很大。
w值很大,使得拟合出来的曲线非常不平滑,起伏很大。
这样的好处是在训练集中可以很好的表征数据,但是在测试集中可能表现就很差。
如图:


实际上,训练的数据集只是整体的一部分,如果局限于这一部分的特征,犹如井底之蛙一般。
过拟合就是太过于关注训练集这一小部分数据了,导致对未知的数据无法正常预测。
实际上真实的数据可能是这样的:


这样,虽然训练的时候有些数据是错误的,但是做大事者,不拘小节,要顾全大局。
在未知全貌的情况下,一个理论在一个局部很对,在全局是不一定很对的,甚至错的离谱。
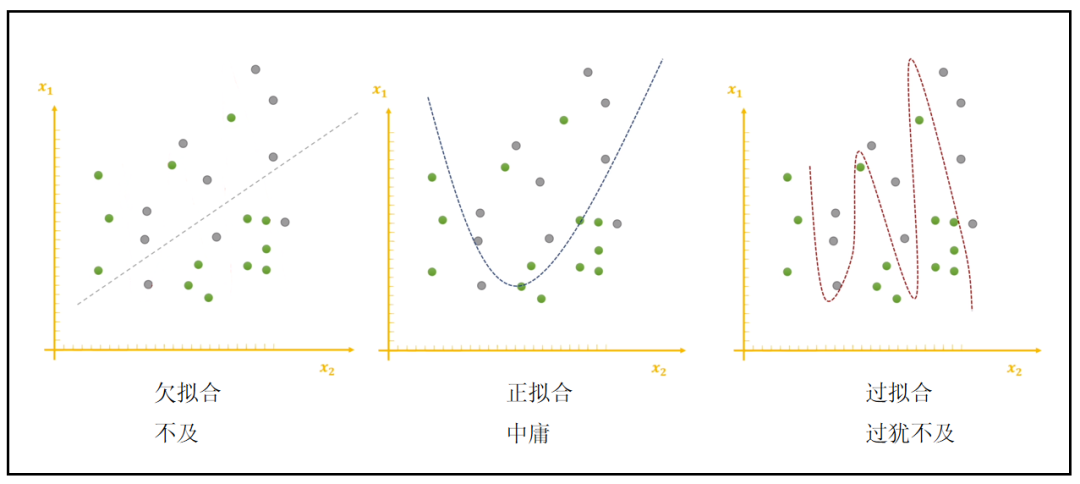
再举一个过拟合的例子:
假如要识别"人",拟合人的特征,但是数据集只有中国人,却要拿这个数据集的训练出来的模型来判断全世界的人是不是人。
中国人的特征有很多:手、脚、眼睛、鼻子、头、黄皮肤等等等,用这些特征来描述一个人。
问题来了。
用到的特征太少,比如只用了手、脚、头,很可能导致欠拟合。
可能把一个猩猩识别成人,因为猩猩也有手、脚、头嘛,虽然这些有点差异,但是可能会识别错误。
用到的特征太多,比如手、脚、眼睛、鼻子、头、黄皮肤等,几乎用掉了能描述人的所有特征,这里是中国人的所有特征,那很可能就导致了过拟合。
可能把非洲人识别成不是人,因为非洲人是黑皮肤的嘛,你用了大量的黄皮肤的人训练出来,就很可能识别出错。
如果用到的特征不多不少,比如用到手、脚、眼睛、鼻子、头,而没有用到肤色,那非洲人也能正确识别为人。

灵魂的拷问:过拟合一定会存在吗?无法避免吗?
过拟合是站在模型不对应的角度说的,局部不能代表整体。
拿中国人训练的模型去预测全世界的人就是一种不对应。
拿部分中国人训练的模型预测全部中国人同样存在一种不对应,因为你训练集没有包含每个中国人,训练集不是中国人的全集。
因此,只要模型不对应,就存在过拟合。
逆向思维:
过拟合在什么情况下是不存在的?
模型真正对应的情况只有一种。
1、训练的模型拿来预测训练的数据,这是不存在过拟合的。
本质上模型对训练数据效果是最好的,这样的情况可以极致的追求准确率。
2、训练集就是全集,这也是不存在过拟合的,这其实就是第一种情况。
当训练集是全集的时候,要预测的数据就已经没有额外没有见过的了。
当然这种情况一般不会出现,我们拿到的训练集可以说几乎都是小集合,我们也只能以小博大,自然就照成模型的不对应问题,一般都是向外兼容,也就是模型的泛化问题。
因此,过拟合的情况是一定会存在的。
我们能做的就是减少过拟合,而不是根除过拟合。

2、如何减少过拟合?
1、数据增强。将训练集逼近全集。
2、特征丢弃。丢弃一些不能帮助我们正确预测的特征,可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙,比如PCA。
3、L1、L2正则化。保留所有特征,但是减少参数的大小,减少模型复杂度。
4、dropout。通过随机使神经元死亡达到减少模型复杂度的效果。
5、Early stopping。减少模型复杂度。
6、权重衰减。限制参数大小。

3、正则化是什么意思?
正则化,regularizer ,就是规则项。
规则化就是向你的模型加入某些规则,加入先验,缩小解空间,减小求出错误解的可能性。
在深度学习中,降低泛化误差而不是训练误差的方法都可以叫”正则化“方法。
降低泛化误差的方法就是减少过拟合的方法,或者说减少过拟合的一套规则,一套算法,一种手段。
L1和L2正则化就是利用L1和L2范数来规范模型参数的一种方法,是针对模型参数w的,而不是针对b的。

4、范数是什么?
向量的范数:
范数是抽象的长度概念,根据范数可以衡量空间中两个“点”之间的距离。
范数就是把空间中两点的距离这个概念进行了扩充,是一类数的集合。
范数也是一种长度。
L0范数:
向量中非0元素的个数,就是L0范数。
零范数即是当p趋于零,可以证明这时候的极限
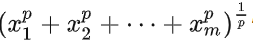
恰好是向量

非零元素的个数。
例如:

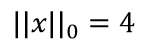
L1范数:

即向量元素绝对值之和,x 到零点的曼哈顿距离。
L1范数就是所有元素绝对值的和。
把L1范数相同的点组和在一起就是一个正方形。

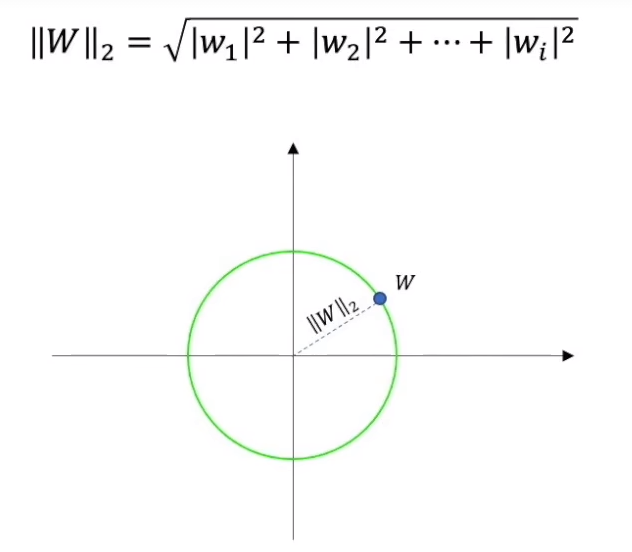
L2范数:
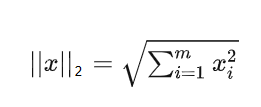
权重w可以看做一个高维的向量,高维空间中的一个点到原点的距离如果是欧式距离,就是L2范数。
即向量元素绝对值的平方和再开方,表示x到零点的欧式距离。
即用高维的勾股定理得到的。
把L2范数相同的点都画出来,就是一个圆。
Lp范数:

即向量元素绝对值的p次方和的1/p次幂,表示x到零点的p阶闵氏距离。


范数:
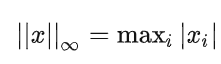
当p趋向于正无穷时,即所有向量元素绝对值中的最大值。
范数:
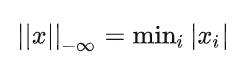
当p趋向于负无穷时,即所有向量元素绝对值中的最小值。
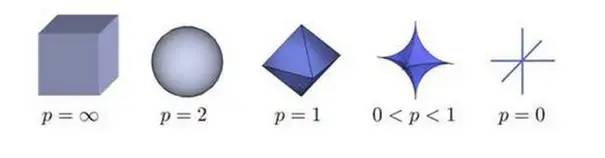
可见,当p大于等于0的时候,才是一个凸集,就有了凸优化问题。

5、L1正则化
添加L1正则化的损失函数为:
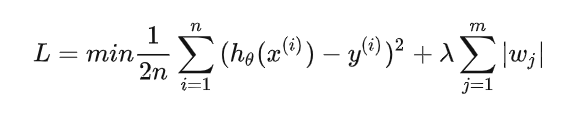
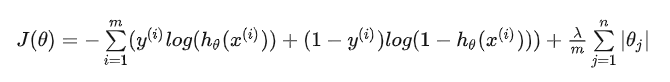
其中,后面这项就是L1范数,也就是原来损失函数的惩罚项。
所谓惩罚项,其实就是和原来的损失函数竞争,现在要满足两者的最小值才是真正的最小值。
其中,L1正则化项的损失函数是一个个正方形,而原来的损失函数是一个个椭圆,只有两者的交点才使得整体损失最小。


6、L2正则化
添加L2正则化的损失函数为:
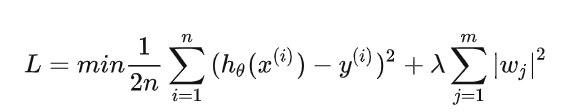
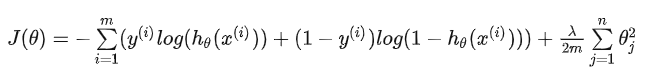
其中,后面这项就是L2范数,也就是原来损失函数的惩罚项。


7、正则化为什么能减少过拟合?
1、拉格朗日乘数法(拔河比赛)
2、泰勒公式(函数拟合)
3、权重衰减(w更新)
4、贝叶斯概率(先验分布)
5、结构风险最小化(模型复杂度)
(一)拉格朗日乘数法
理解一:添加正则项相当于添加了拔河对手,对原来损失函数的最小值进行拉扯。
在数学上,要求一个函数在某个限制条件下的极值点,我们可以引入额外的参数,然后构造拉格朗日函数来求解。
实际上就是既要满足函数,又要满足限制条件,还要是极值,就这要求两者一定是要相交的。

对应到正则化问题,就是损失函数在正则项约束下的最小值。

L1正则项就是添加了L1范数,而L1范数的图形由上面已经知道。同样得到L2范数的图形。
二维图(w其实是很多维的):
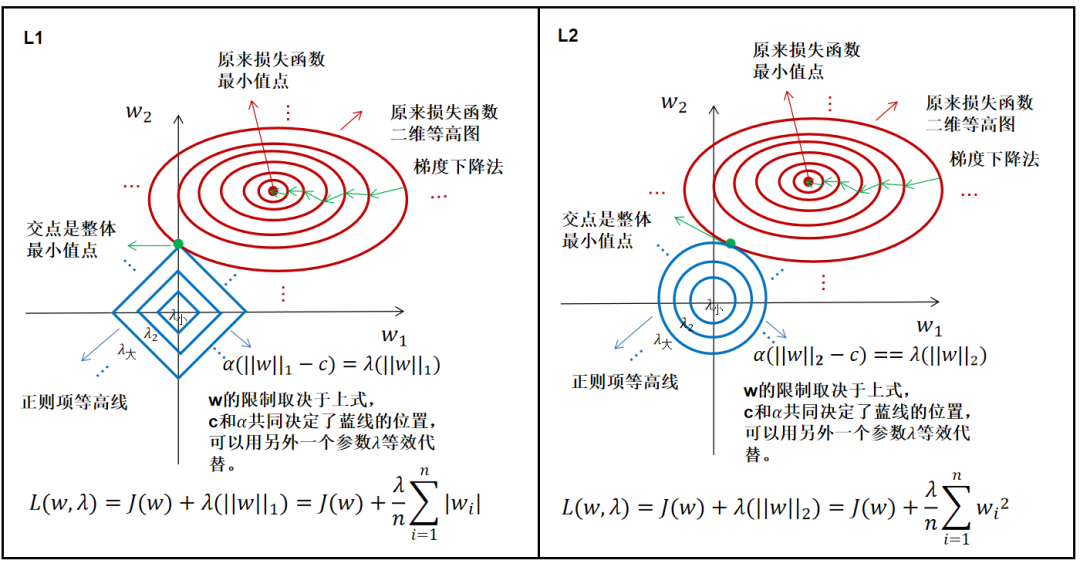
正则项图形大小由λ调节,L1更容易得到稀疏解,L2得不到稀疏解,但也减小了w的值。
当惩罚力度大,相当于正则化这个拔河对手力气很大,最小值点就被正则项拉的偏离原来的最小值点很远。
当惩罚力度小,相当于正则化这个拔河对手力气不是很大,最小值点就被正则项拉的偏离的不是很远。
损失函数高维映射图:

总结:
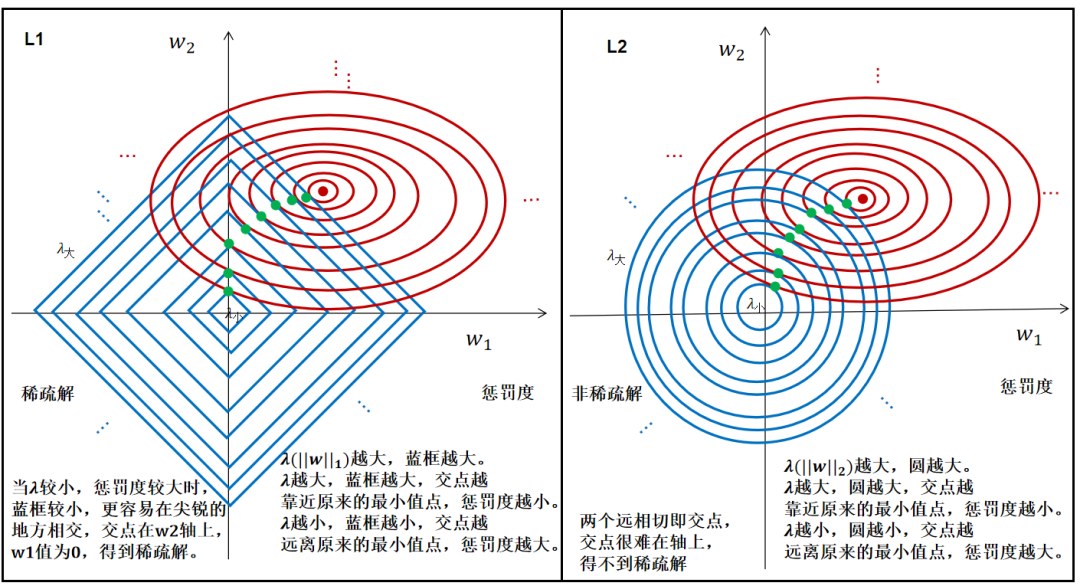
1、由拉格朗日乘数法得到L1、L2的正则化后的整体损失函数的最小值点是交点。
2、L1交点更多在轴上,可以得到稀疏解,L2交点得不到稀疏解。
3、从拉格朗日乘数法角度看,最小值点变成了正则项和原来损失函数的争夺点,谁争夺的力量大,最小值点就往谁那边偏离,就像拔河比赛一样,现在加入正则项,显然是增加了一个拔河对手,不管对手强弱,都能使得原来的最小值点偏离。
4、为什么最小值偏离能减少过拟合,原因就是局部最佳不代表全局最佳,而偏离出来的最小值其实也未必就是全局最佳,只是一种可能。
(二)泰勒公式
理解二:正则项使得拟合出来的曲线平滑。
根据泰勒公式,对于一个函数,我们可以使用任意次的多项式来近似。
神经网络训练出来的模型即在拟合一个函数。
将拟合出来的函数进行泰勒展开:

其中,n越大,x高次项越多,表示函数越复杂,越弯弯绕绕。
当y=a+bx时,就是一条直线。
y=ax+bx^2+c时,就是一个抛物线。

过拟合就是拟合出来的曲线太弯弯绕绕了。
因此,为了缓解过拟合,我们就要减少高次项,或者使高此项前面的系数变小。
L1的稀疏解就是让某些w变为0,就是使得某些高次项为0,从而简化了函数的表达,当然w的值也是在变小的。
而L2是减小高项前面的系数,使得弯弯绕绕的没有那么剧烈,也就是使得模型没有那么复杂。

(三)权重衰减(weight decay)
理解三:L2正则化可以达到权重衰减的效果。
L2在SGD优化器下可以达到权重衰减的效果。
跟优化器有关,对于非自适应的优化器(SGD),L2正则和权重衰减等价;对于自适应的优化器(Adam),L2正则和权重衰减不等价。
那么w是如何变小的呢?
在训练过程中L1、L2的w是如何进行更新的呢?

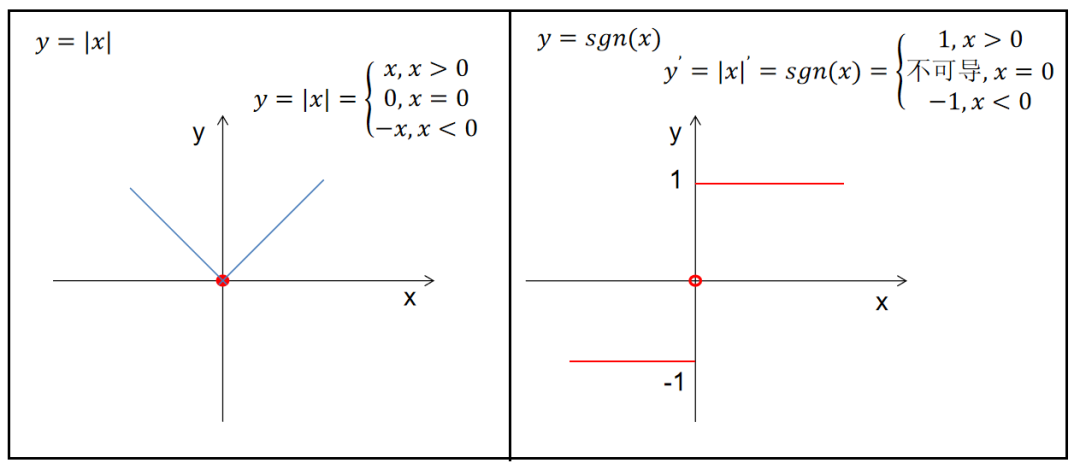

由此可见,L2正则化后w的更新的时候先对w进行衰减,再减掉一个量,这个操作和权重衰减是一样的效果。
而L1则不然,只是减掉的量变化了而已,导致可以更快的达到0值。
加入L1正则项后,训练好的权重和没有加正则项训练好的权重的关系如下:
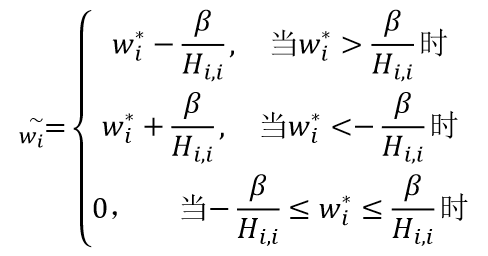
即:
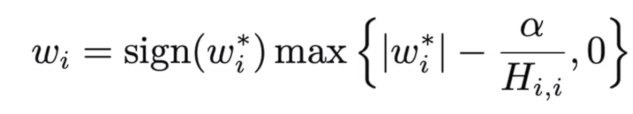
加入L2正则项后,训练好的权重和没有加正则项训练好的权重的关系如下:

为什么稀疏解?
在L1中,原来的权重没有变化,后来的权重比之前减的更多了,也更容易等于0,即得到稀疏解,会把不重要的特征直接置零。
从训练好后的权重结果看,当之前的w在一定范围内,之后都会变为0。
在L2中,先对原来的权重进行衰减,再减掉一个量。
从训练好后的权重结果看,除非权重本来就是0,否则不会是0。
为什么唯一解?
看上述式子可知,L2的w和未正则化之前是有唯一一个对应关系的,即唯一解;
而L1的w的对应情况就要分情况而定了,因此不是唯一解。
常说L2正则化等价于权重衰减,不过等价只在SGD优化器成立,对于自适应学习率的优化器RMSProp、Adam等是不成立的。
尽管权值衰减和L2正则化在某些条件下可以达到等价,但概念上还是有细微的不同,应该区别对待。
引问:本来自由自在的w可以满世界乱跑的,现在正则项对w进行限制,那么究竟限制成什么样呢?
(四)贝叶斯概率(先验分布)
理解四:正则项是先验分布项。
极大似然估计:
通过已知观察数据来推断模型参数的过程。
利用已知的样本,找出最有可能生成该样本的参数。
利用已知的样本信息,反推一个模型,模型的参数会使得这些样本出现的概率最大。
最大似然估计是一种确定模型参数值的方法。找到参数值以使它们最大化由模型描述的过程产生实际观察到的数据的可能性。
模型训练也是如此,在全集中,我们拿到一些训练集就是抽样,利用这些训练集来训练模型参数,确定一些参数使得看见这些训练集的概率最大。
但是,明显,这个求得的值和真实的情况未必相等,只是极大的似然。
似然:
和概率相反,根据结果,推出导致这个结果的因素的概率,即参数还不知道,模型还未确定,根据观察结果确定模型,使得观察结果概率最大。
概率:
依据因素,推出某个结果的概率,即参数都知道了,模型已经确定了,求某个发生的概率。
在统计学上,基于某些模型的参数(粗略地说,我们可以认为参数决定了模型),观测到某数据的概率称为概率;而已经观测到某数据,模型的参数取特定值的概率称为似然。



没有加正则项相当于在求最大似然概率,加了正则项相当与在求最大后验概率。
L1正则项相当于是给了一个先验概率,使得w的分布,满足拉普拉斯分布。
L2正则项相当于是给了一个先验概率,使得w的分布,满足正态分布;
最大似然概率就是从抽样样本(训练集)中求一个模型的参数,这个参数使得出现训练样本的概率最大,也就是最大程度拟合训练集。
最大后验概率是给定一个参数的先验分布,根据训练集不断调整这个参数,使得后验概率最大。

(五)结构风险最小化(模型复杂度)
理解五:正则项是对模型复杂度的度量。
vc维:
模型f的VC维,即空间中的点在经过排列之后,能够被模型f打散(shatter)的最大数量。
更正式的表述,它是某个点集的基数,这个点集是所有能够被 f 打散的点集中基数最大的一个。
VC能刻画假设空间的复杂度。

未加正则化,其实就是采用经验风险最小化策略,加入正则化就是采用结构风险最小化策略。
正则项相当于是模型复杂度的度量。
加上正则化之后可以让VC维变小,使得模型复杂度变低,有机会使得结构风险最小。
8、总结
由于我们的训练样本只能是局部而不是全局,导致过拟合必然存在,且无法彻底根除,只能尝试缓解。
正则化是缓解过拟合的常规手段。
正则化能使得原来的最小值点偏离。
正则化能限制权重的大小,使得拟合出来的曲线趋于平滑。
L2正则化能达到权重衰减的效果。
正则化相当于给w一个先验分布。
正则化之后就是采用结构风险最小化策略。



![[C/Linux练习]进度条小程序](https://img-blog.csdnimg.cn/faa6a50787284655bf47be032f2de273.gif)