深度学习论文: SuperPoint: Self-Supervised Interest Point Detection and Description
SuperPoint: Self-Supervised Interest Point Detection and Description
PDF: https://arxiv.org/pdf/1712.07629
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
本文提出了一个自监督框架,用于训练适用于计算机视觉中多视图几何问题的兴趣点检测器和描述符。全卷积模型在完整图像上操作,联合计算兴趣点位置和描述符。通过引入单应性适应方法,提升兴趣点检测的重复性和跨域适应性。在MS-COCO数据集上训练后,提出的模型在HPatches上实现了最先进的单应性估计结果。

为了生成伪真实兴趣点,首先在“合成形状”数据集上训练了一个全卷积神经网络,得到了MagicPoint检测器。尽管它在真实图像上表现良好,但仍存在不足。为了改进在真实图像上的性能,采用单应性适应技术,通过多次扭曲输入图像来帮助检测器从多个视角和尺度观察场景。结合单应性适应和MagicPoint检测器,得到了性能更优越的SuperPoint检测器。最后,为了进行更高级别的任务,将SuperPoint与描述符子网络结合使用。
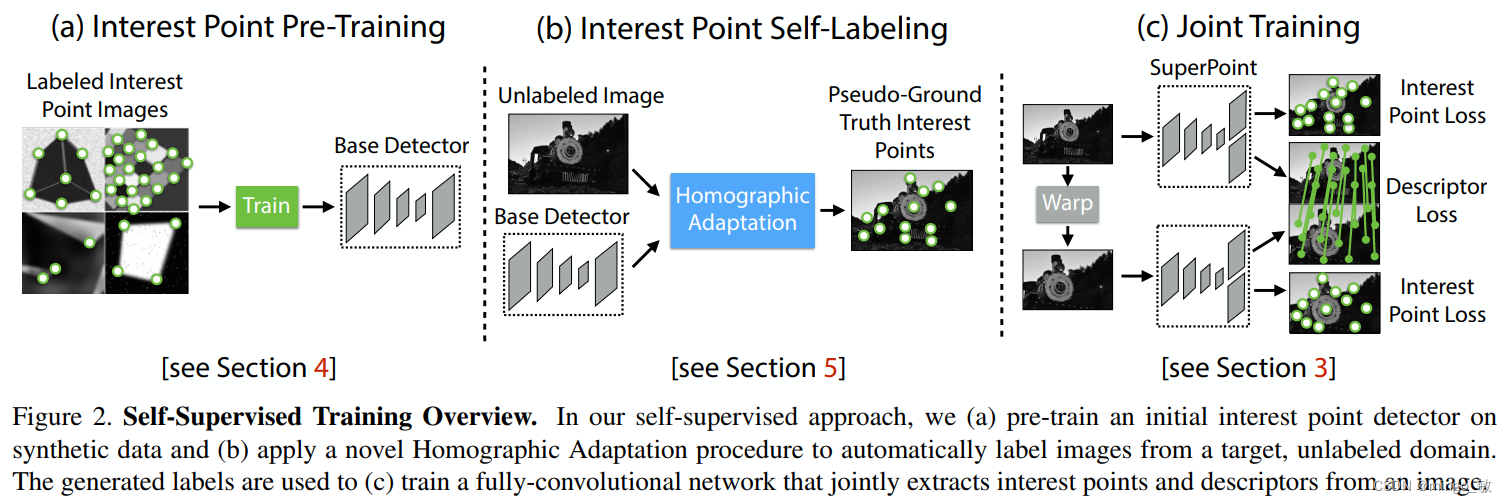
2 SuperPoint Architecture
SuperPoint,一个全卷积神经网络架构,能够在一次前向传播中处理全尺寸图像,并同时实现兴趣点检测与固定长度描述符的生成。该模型的核心是一个共享的编码器,用于降低输入图像的维度。之后,架构分为两个解码器头:兴趣点检测头和描述符头。

Shared Encoder: SuperPoint采用VGG风格的编码器,通过卷积层、最大池化层和非线性激活函数来降低图像维度。编码器的输出是一个中间张量,具有较小的空间维度(
H
c
=
H
/
8
H_{c} = H / 8
Hc=H/8 and
W
c
=
W
/
8
W_{c} = W / 8
Wc=W/8)和较大的通道深度(64 + 1)。
Interest Point Decoder: 兴趣点解码器输出一个张量,其中每个像素表示输入图像中对应位置的“点性”概率。为每个8×8像素网格区域加上一个“无兴趣点”选项,通过softmax操作,移除“无兴趣点”并最终得到一个全分辨率的兴趣点概率图。
Descriptor Decoder: 描述符头生成一个密集的描述符图,首先输出一个半密集的描述符网格,然后通过双三次插值和L2归一化,得到固定长度且单位长度的描述符。这种设计减少了训练内存需求并保持了运行时的可行性。
3 Synthetic Pre-Training
由于没有大规模带有兴趣点标签的图像数据库,因此创建了一个包含简化二维几何形状(如四边形、三角形、线条和椭圆)的合成数据集“合成形状”来启动深度兴趣点检测器。通过将这些形状建模为特定的交点和小元素中心,解决了标签歧义问题。随后,应用单应性变换增加训练样本,实时生成数据,避免网络重复看到相同样本。尽管这些合成兴趣点仅代表真实世界中的一部分,但在实践中用于训练兴趣点检测器时表现良好。
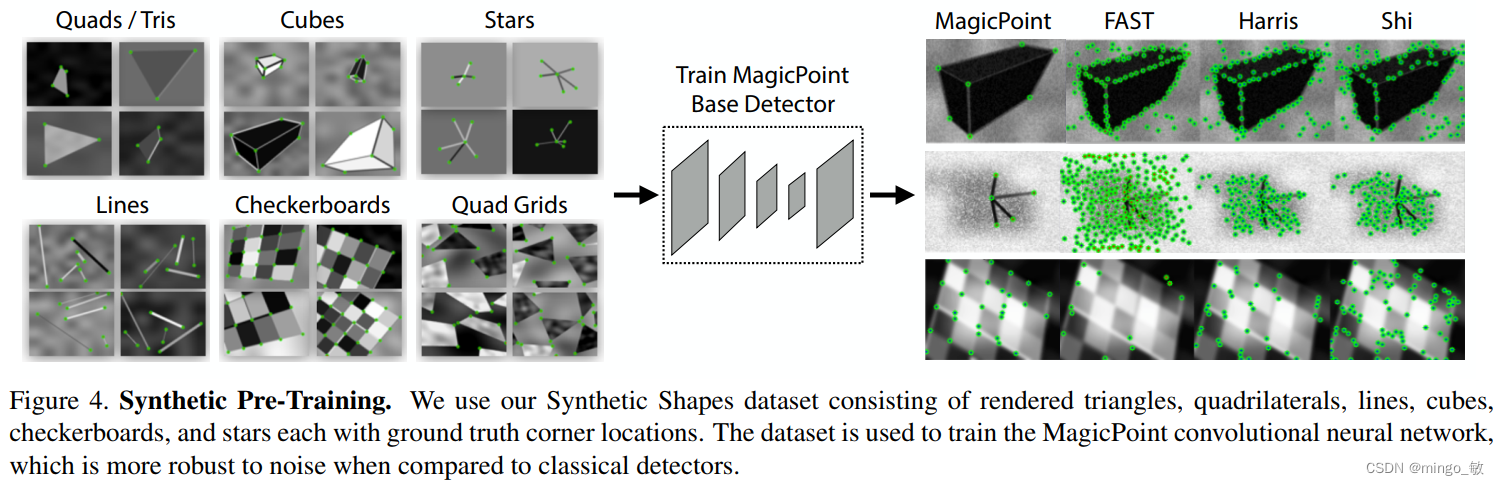
MagicPoint在合成形状上表现佳,但泛化到真实图像时效果一般,尤其在具有角状结构的场景中表现尚可。然而,与经典检测器相比,它在自然图像中的视角变化下表现较差。因此提出了在真实图像上进行自监督训练的“单应性适应”方法。
4 Homographic Adaptation
Homographic Adaptation的基本思想是在足够大的随机H样本上进行经验性求和(或平均)。即,系统首先为每个目标域图像生成一组伪真实兴趣点位置,通过对输入图像的扭曲副本应用随机单应性变换并综合结果。
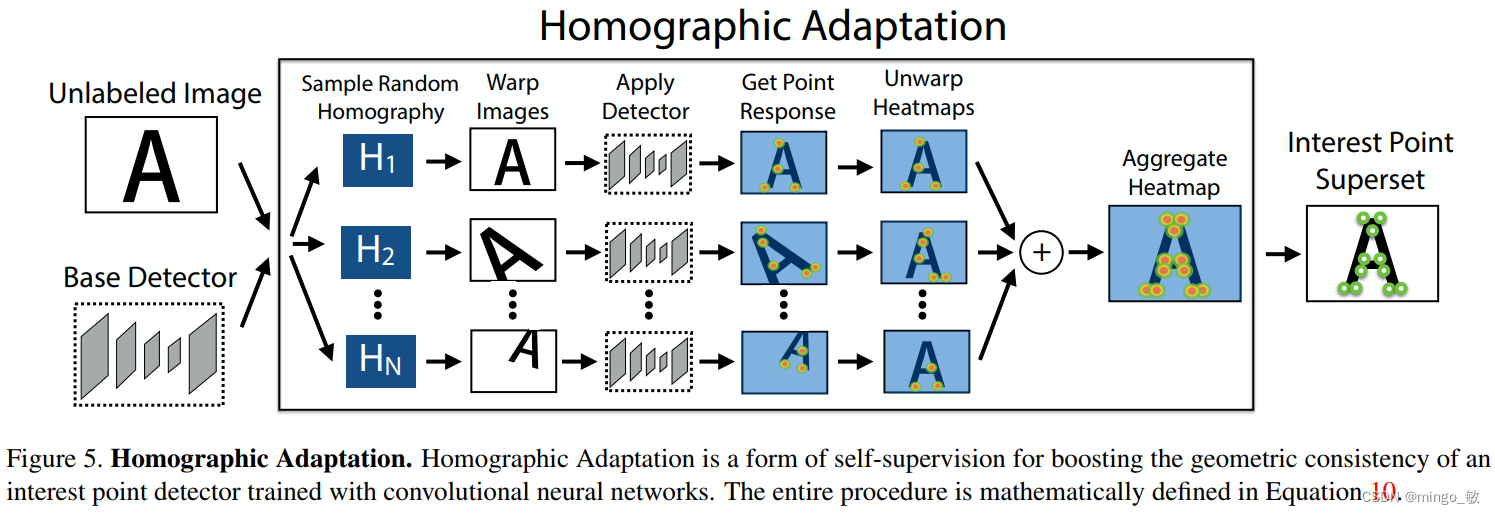
并非所有3x3矩阵都适合单应性适应。本文将其分解为更简单的变换类,并在预定范围内采样。通过组合初始裁剪与平移、缩放、旋转和透视畸变变换,同时避免了边界伪影。

单应性适应技术可以迭代进行,以持续进行自我监督并改进兴趣点检测器。

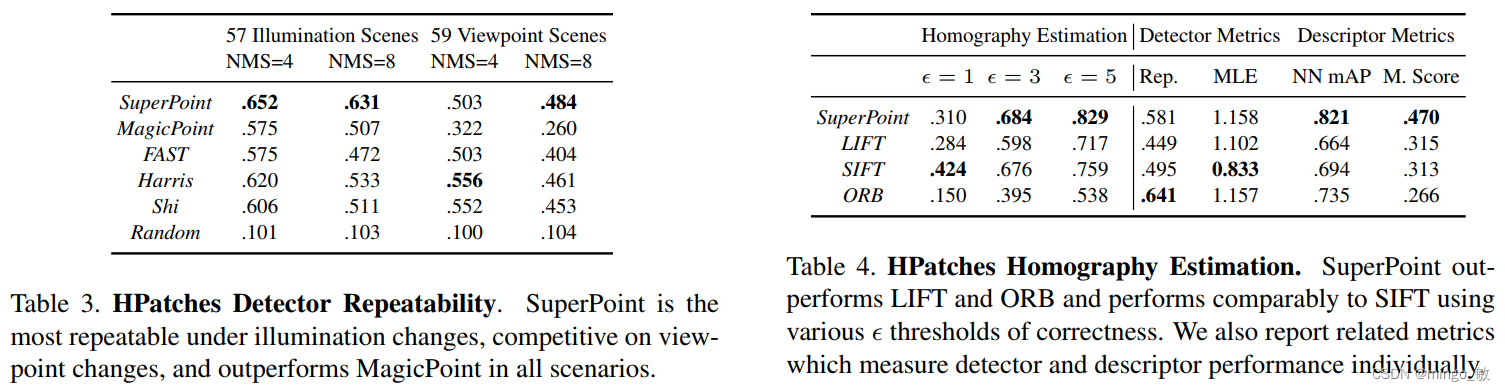
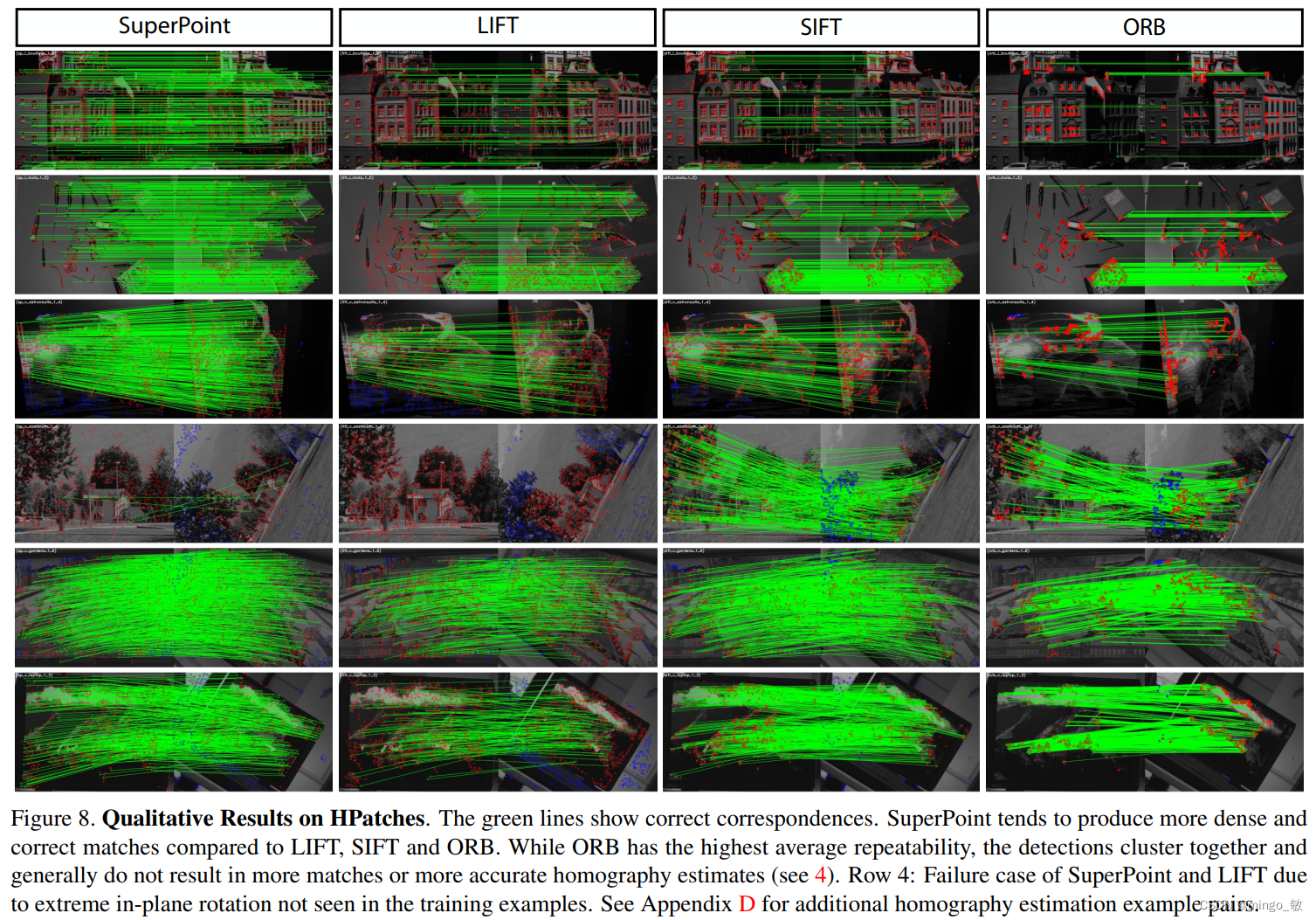
5 Experiments