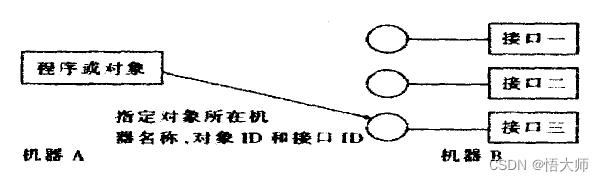
RFN-Nest
- Abstract
- Introduction
- Related works
- The proposed fusion framework
- The architecture of the fusion network
- Two-stage training strategy
论文: RFN-Nest: An end-to-end residual fusion network for infrared and visible images
代码: https://github.com/hli1221/imagefusion-rfn-nest
Abstract
- RFN-Nest是一种新的端到端融合网络架构,用于红外与可见光图像融合
- RFN-Nest提出了一种新的细节保持损失函数和特征增强损失函数来训练RFN,RFN 是一种基于残差结构的残差融合网络
- 该融合模型采用一种新的两阶段训练策略。在第一阶段,使用基于创新的nest连接概念训练一个自编码器;在第二阶段,则使用上述的损失函数训练RFN
Introduction
-
由于图像传感器的限制,很难捕捉到某一场景质量一致性良好的图像。在这种背景下,图像融合凸显出其重要性。图像融合的目的是从多个提供了关于视觉互补信息的样本中重建一个完美的场景图像,可以用于目标跟踪、自动驾驶和视频监控等等。
-
Image-fusion这一任务需要算法生成一幅图像,将不同源图像传递的互补信息融合在一起
-
图像融合的三个关键过程:特征提取、融合策略和重建
-
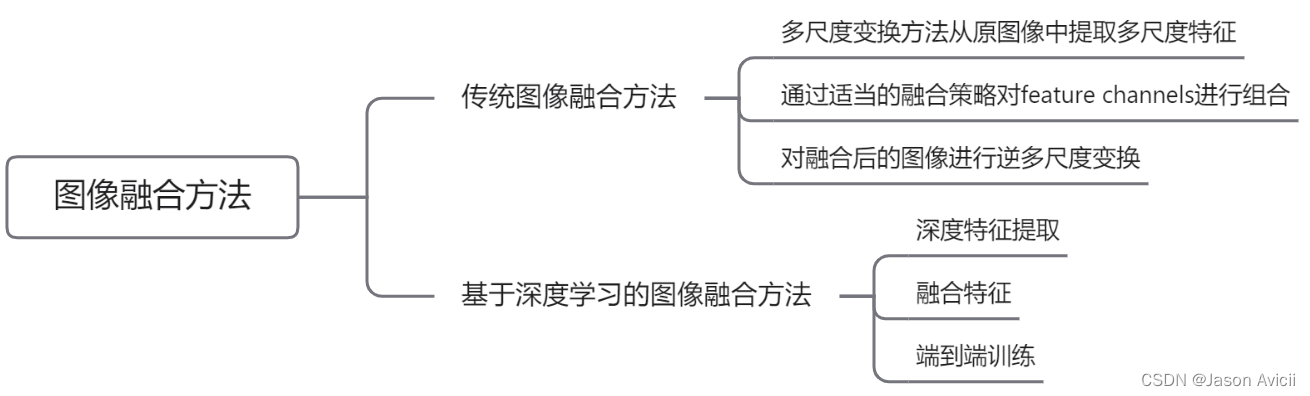
目前的图像融合方法主要分为两类:传统算法和基于深度学习的方法
-
传统方法:
- 传统融合算法利用稀疏表示(SR)和低秩表示(LRR)从原图像中提取特征
- 基于SR和LLR的融合方法中使用滑动窗口技术将源图像分解为image patch,利用reshape后的image patch构造一个矩阵,矩阵的每一列就是reshape后的image patch。将该矩阵输入SR 或者 LRR中,计算SR(LRR)系数。通过该运算,将图像融合问题转化为系数融合问题。通过适当的融合策略生成融合系数,并在SR(LRR)框架中用于重建融合图像
- 传统融合算法有一定的融合性能,同样存在着不足:
- 融合性能高度依赖手工特征,对于不同的融合任务很难找到一种通用的特征提取方法
- 不同的特征可能需要不同的融合策略
- 对于基于SR和LRR的方法,dictionary learning通常是需要花费时间的
- 传统融合算法在面对复杂源图像时收效甚微
-
基于深度学习的方法:
- 在特征提取方向上利用深度学习方法对源图像所传达的信息进行深度表征
- 为了重建融合后的图像,提出了不同的融合策略。在其他融合方法中,也使用深度学习来设计融合策略
- 比如,利用卷积稀疏表示和卷积神经网络对源图像生成决策图。利用学习到的决策图,经过适当的后处理得到融合图像 FusionGAN FusionGANv2 DDcGAN
- 优势:基于对抗学习,避免了手工特征和融合策略的缺点
- 劣势:面临着充分保存图像信息的挑战
- NestFuse的提出——基于nest连接的自编码器融合网络;尽管Nestfuse在细节信息保存方面取得了很好的效果,但是融合策略仍然是不可学习的
-
Paper方法——RFN-Nest
- RFN-Nest包含三个部分:编码器网络、用于提取融合的多尺度深度特征的残差融合网络以及基于nest连接的解码器网络
- 虽然所提出网络的编码器和解码器与NestFuse相似,但融合策略、训练策略和损失函数完全不同
- 首先,论文设计了几个简单而高效的可学习的融合网络(RFN),并将其插入到自编码器结构中,而不是融合NestFuse的手工功能。通过RFN,基于自编码的融合网络升级为端到端融合网络。
- 其次,由于RFN是一个可学习的结构,编码器和解码器具有强大的特征提取和特征重建能力,因此论文开发了一个两阶段训练策略来训练我们的融合网络(编码器、解码器和RFN网络)
- 在同时保留可见光图像的细节信息和红外图像的显著特征情况下,为了训练提出的RFN网络,论文提出了损失函数—— L R F N L_{RFN} LRFN
-
该篇Paper的Contributions:
- 提出了新的残差融合网络来取代手工融合策略
- 采用了两阶段训练策略来设计网络
- 设计了一个能够保存图像细节的损失函数和一个特征增强的损失函数来训练我们的RFN网络(更多的细节信息和图像显著性特征被保留在融合图像中)
- 融合性能更好
Related works
基于深度学习的图像融合方法大部分是基于CNN的,而这些方法又可以分为非端到端学习和端到端学习两类
-
非端到端方法
- 早期,深度学习神经网络被用于提取深度特征作为决策图库。
- Li等人提出了基于预训练网络的融合框架(VGG-19)。首先将源图像分解为显著部分(纹理和边缘)和基础部分(轮廓和亮度),然后利用VGG-19从显著部分提取多层次的深层特征,在每个层次上,从深层特征计算决策映射,并生成一个候选融合显著性部分,再采用合适的融合策略,将基础部分和融合的显著部分在融合,重建融合后的图像。
- 利用Resnet-50直接从源图像中提取深度特征,采用零相位分量分析(ZCA)和 l 1 n o r m l_1 norm l1norm得到决策图
- 基于PCANet的融合方法也遵循这一框架生成融合图像,其中提取特征的是PCANet,而不是VGG-19或ResNet-50
- 特征提取和融合策略用单个网络实现。其中一种,由经过训练的CNN在输入图像的多个模糊版本的image patch上生成决策映射;另一种利用卷积稀疏代替CNN提取特征并生成决策图。根据生成的决策图,可以很容易地重构融合图像
- 在上述方法的基础上,一种基于深度自编码器网络的融合框架。受DeepFuse的启发,作者提出了一种包含编码器、融合层和新型网络架构。采用基于dense block的编码器网络从源图像中提取出更多互补的深层特征。在这种框架中,融合策略变得非常重要
- Li等人受DenseFuse等的架构启发,提出了NestFuse,以保留更多可见光图像的背景信息,同时增强红外图像的详细背景信息,同时增强红外图像的显著特征。此外,设计了一种新的空间/通道注意模型来融合多尺度的深度特征。虽然这些框架都取得了很好的融合性能,但是很难找到一种有效的手工融合策略进行图像融合。
- 早期,深度学习神经网络被用于提取深度特征作为决策图库。
-
端到端方法
- 为了消除手工特征和融合策略,人们提出了几种端到端融合框架
- 一种基于GAN的融合框架引入到红外与可见光图像融合领域;generator network是计算融合图像的引擎,discrimiminator network约束融合图像包含可见光的细节信息。损失函数有两项:内容损失和鉴别器损失。由于内容的丢失,融合后的图像容易变得与红外相似,即使使用鉴别器网络也不能保持图像细节信息
- FusionGANv2——为了从可见图像中保存更详细的信息;版本2.0中作者深化了generator network和discrimiminator network,赋予他们更强大的特征表示能力。此外,提出了两种新的损失函数,即细节损失和目标边缘增强损失,以保留细节信息。通过这些改进,融合图像重建了更多的场景细节,并清晰地突出了更多场景细节,并清晰地突出了边缘锐化目标
- IFCNN——通用的端到端图像融合网络提出;在IFCNN中,利用两个卷积层从源图像中提取深度特征。采用元素级融合规则(元素级最大、元素级和、元素级平均)来融合深度特征。融合图像是由融合的深层特征通过两个卷积层生成的。尽管IFCNN在多个图像融合任务中都取得了令人满意的融合性能,但其架构过于简单,无法提取强大的深层特征,传统方法设计的融合策略也不是最优的
- 为了消除手工特征和融合策略,人们提出了几种端到端融合框架
The proposed fusion framework
The architecture of the fusion network

-
左边的部分是编码器;中间部分是 R F N 1 − 4 RFN_{1-4} RFN1−4(residual fusion network);右边部分是解码器
-
图例说明:3*3这种类似代表卷积核大小,(16,8)中16是输入,8是输出
-
利用编码器中的max-pooling,可以从源图像中提取多尺度的深度特征
-
RFN用于融合各尺度下提取的多模态深度特征;浅层特征保留更多的细节信息,深层特征传递语义信息,这对于重构显著特征很重要。
-
最后利用基于nest connection的解码器,充分利用特征的的多尺度结构,对融合后的图像进行重构
-
I i r I_{ir} Iir和 I v i I_{vi} Ivi分别代表红外图像和可见光图像的输入, O O O代表RFN-Nest的输出,即融合后的图像
-
R F N m RFN_m RFNm代表深度特征m的残差融合网络
-
整个编码器由四个RFN网络构成,有着同样的权重、不同的权重
-
RFN
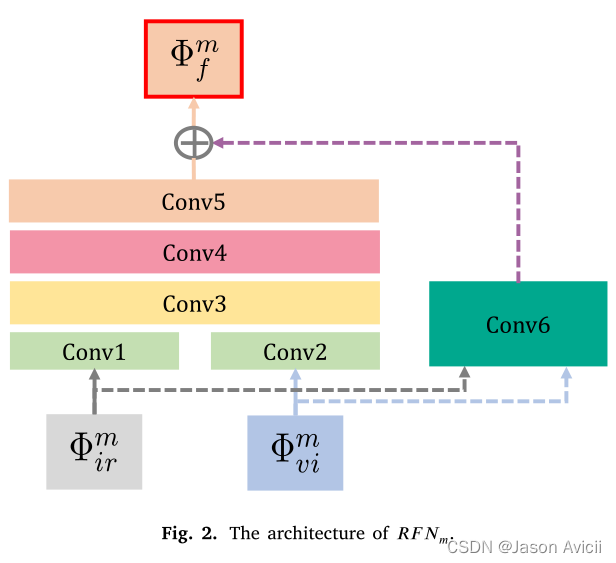
-
Φ i r m \Phi^m_{ir} Φirm和 Φ v i m \Phi^m_{vi} Φvim代表第m层被编码器提取的特征
-
C o n v 1 − 6 Conv1-6 Conv1−6代表RFN中的六个卷积层
-
将 C o n v 1 Conv1 Conv1和 C o n v 2 Conv2 Conv2输出串联作为 C o n v 3 Conv3 Conv3的输入
-
C o n v 6 Conv6 Conv6是生成初始融合特征的第一个融合层
-
ϕ f m \phi^m_{f} ϕfm是融合后的特征
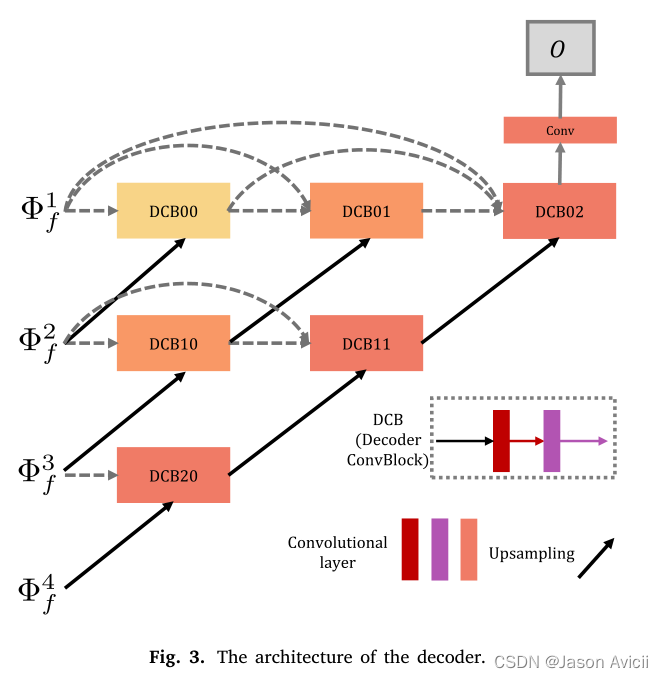
-
与Unet++相比,在图像融合任务上,我们简化了网络架构,使重构融合图像更加轻巧有效
-
DCB 表示一个解码器卷积块,它有两个卷积层。在每一行中,这些块通过类似于dense block的短连接
-
Two-stage training strategy
- 首先,将编码器和解码器训练作为一个自编码器网络来重建输入图像。在学习了编码器和解码器网络之后,在第二个训练阶段,训练几个RFN网络来融合多尺度深度特征

- 特征提取部分包括下采样操作(最大池化),它在四个尺度上提取深层特征。这些多尺度特征被输入到解码器网络中重建图像输入图像。通过短的跨层连接,充分利用多尺度深度特征对输入图像进行重构
- 自动编码器网络使用
L
a
u
t
o
L_{auto}
Lauto作为损失函数训练:
L a u t o = L p i x e l + λ L s s i m L_{auto} = L_{pixel} + \lambda L_{ssim} Lauto=Lpixel+λLssim
其中 L p i x e l L_{pixel} Lpixel代表像素级损失, L s s i m L_{ssim} Lssim结构相似度损失, λ \lambda λ是平衡参数- L p i x e l L_{pixel} Lpixel计算方法: L p i x e l = ∣ ∣ O u t p u t − I n p u t ∣ ∣ F 2 L_{pixel} = ||Output - Input||_F^2 Lpixel=∣∣Output−Input∣∣F2; L p i x e l L_{pixel} Lpixel约束重建图像在像素级上与输入图像相似
- L s s i m L_{ssim} Lssim计算方法: L s s i m = 1 − S S I M ( O u t p u t , I n p u t L_{ssim} = 1 - SSIM(Output,Input Lssim=1−SSIM(Output,Input; L s s i m L_{ssim} Lssim用于量化两幅图像的结构相似度
- RFN的训练:
- 在第二阶段,固定编码器和解码器,用适当的损失函数训练RFN
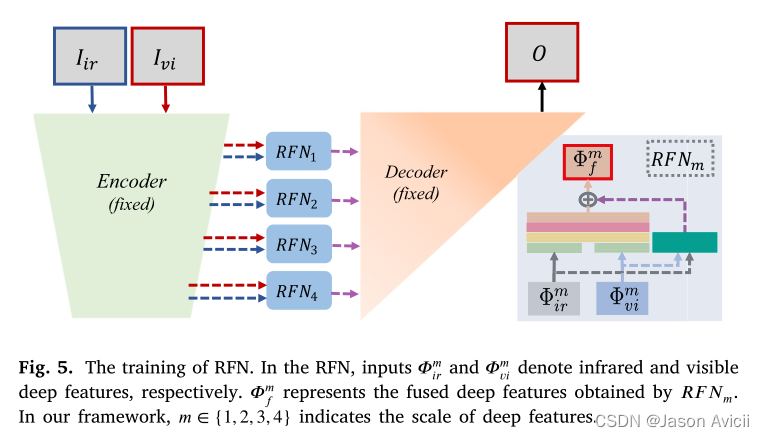
- 从源图像中提取多尺度深度特征( ϕ i r m \phi^m_{ir} ϕirm和 ϕ v i m \phi^m_{vi} ϕvim),对于每一个尺度,使用一个RFN来融合这些深层特征,然后融合的多尺度特征 ϕ f m \phi_f^m ϕfm送入固定的解码器网络中
-
L
R
F
N
L_{RFN}
LRFN作为RFN的损失函数:
L R F N = α L d e t a i l + L f e a t u r e L_{RFN} = \alpha L_{detail} + L_{feature} LRFN=αLdetail+Lfeature; L d e t a i l L_{detail} Ldetail表示背景细节保留损失函数, L f e a t u r e L_{feature} Lfeature表示目标增强损失函数, α \alpha α是平衡参数 - 在红外与可见光图像融合的情况下,大多数背景信息来自可见光图像
- L d e t a i l L_{detail} Ldetail计算方法: L d e t a i l = 1 − S S I M ( O , I v i ) L_{detail} = 1 - SSIM(O,I_{vi}) Ldetail=1−SSIM(O,Ivi); 目的是从可见光图像中保存细节信息和结构特征
-
L
f
e
a
t
u
r
e
L_{feature}
Lfeature 计算方法:
L
f
e
a
t
u
r
e
=
Σ
m
=
1
M
w
1
(
m
)
∣
∣
ϕ
f
m
−
(
w
v
i
ϕ
v
i
m
+
w
i
r
ϕ
f
m
)
∣
∣
F
2
L_{feature} = \Sigma_{m=1}^M{w_1(m)||\phi_f^m-(w_{vi}\phi_{vi}^m+w_{ir}\phi_f^m)||_F^2}
Lfeature=Σm=1Mw1(m)∣∣ϕfm−(wviϕvim+wirϕfm)∣∣F2;目的是为了限制融合的深层特征,以保留突出结构
w 1 w_1 w1是平衡损失大小的权衡参数向量。它假设有四个值{1,10,100,100}
w v i w_{vi} wvi和 w i r w_{ir} wir控制融合特征图中可见特征和红外特征的相对影响; w i r w_{ir} wir通常比 w v i w_{vi} wvi大
- 在第二阶段,固定编码器和解码器,用适当的损失函数训练RFN
![[Android Input系统]MotionEvent的序列化传送](https://img-blog.csdnimg.cn/img_convert/c53809dd73c581d0d3ecf30e4ebc77c0.png)