文章目录
- 🎯 引言
- 🛠️ 内存基础
- 什么是内存❓
- 内存的工作原理 🎯
- 📦 数组(Array)
- 📖 什么是数组
- 🌀 数组的存储
- 📝 示例代码(go语言)
- 🎯 执行增加操作
- 🎯 执行删除操作
- 📊 优缺点分析
- 🔗 链表(Linked List)
- 📖 什么是链表
- 🌀 链表的存储
- 📝 示例代码(go语言)
- 📊 优缺点分析
- 📊 数组与链表的对比
- 🎯 访问速度
- 🎯 插入与删除效率
- 🎯 空间利用效率
- 🎯 应用场景
- 📚 小结
🎯 引言
在编程的奇妙世界里,数组和链表作为两种基础且重要的数据结构,各自扮演着不可替代的角色。它们在存储和管理数据方面展现出了不同的优势和局限。本文将带领你深入了解
数组(Array)与链表(Linked List)的奥秘🚀
🛠️ 内存基础
什么是内存❓
内存,尤其是随机存取存储器(RAM),是计算机中用于临时存储数据和程序指令的部分。与硬盘相比,内存访问速度快,但信息非持久保存。
想象一下,当你在解决一个复杂的算法问题时,那些数字、字符,乃至复杂的数据结构,都需要一个地方暂时停留和操作——这个地方就是内存
内存的工作原理 🎯
内存由一系列连续或非连续的存储单元组成,每个单元都有一个独一无二的地址。通过地址,CPU(中央处理器)可以迅速找到所需的数据。
就好比内存是一个储物柜,你将东西放进去后会给你一个号码,通过号码你可以快速找到你存储物品的柜子。
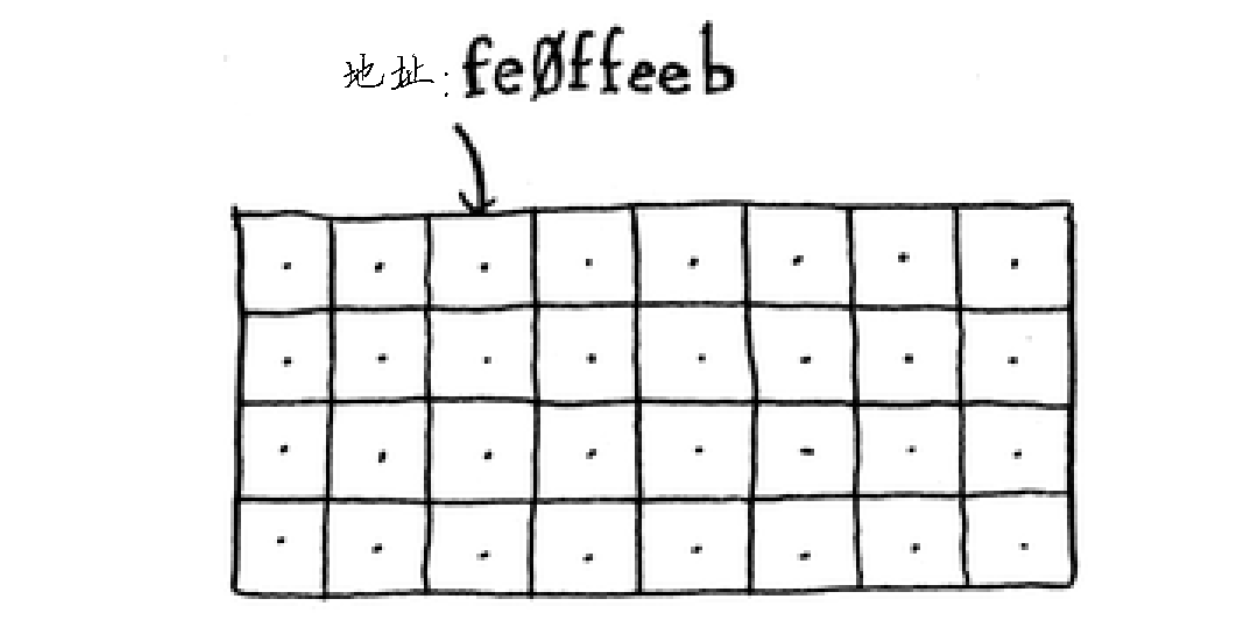
需要将数据存储到内存时,你请求计算机提供存储空间,计算机给你一个存储地址。需要存储多项数据时,有两种基本方式——数组和链表。
📦 数组(Array)
📖 什么是数组
数组是一种线性数据结构,它将元素按照一定的顺序存储在一块连续的内存区域中。每个元素都有一个索引(从0开始),通过索引可以快速访问数组中的任意元素。但是对于插入和删除,特别是当位置不在末尾时,可能需要移动后续的所有元素,以保持连续性,导致最坏情况下的时间复杂度为O(n)。
+---+---+---+---+
| 1 | 2 | 3 | 4 |
+---+---+---+---+
^ ^
| |
索引0 索引3
🌀 数组的存储
数组在创建时会一次性申请足够的内存空间进行存储。这意味着数组的大小是固定的,一旦声明,不能轻易改变。
如果需要在数组中添加新元素很麻烦,因为数组必须是连续的。比如你和3个朋友一起去看电影,已经选好了连坐的4个位置并且付款。此时又有一个朋友要与你们一起看,你们想要连排座,但是你们已经选好的这4个位置旁边没有了空位,所以你们只能放弃这4个位置进行退款,然后重新选择有5个连坐的位置。如果又来了一位朋友,而当前坐的地方也没有空位,你们就得再次转移!真是太麻烦了。如果没有了空间,就得移到内存的其他地方,因此添加新元素的速度会很慢。
而此时如果中间某个人不看电影了,那么后面的人就需要向前靠拢和大家坐在一起,即在数组中删除元素,就需要移动后面的所有元素。
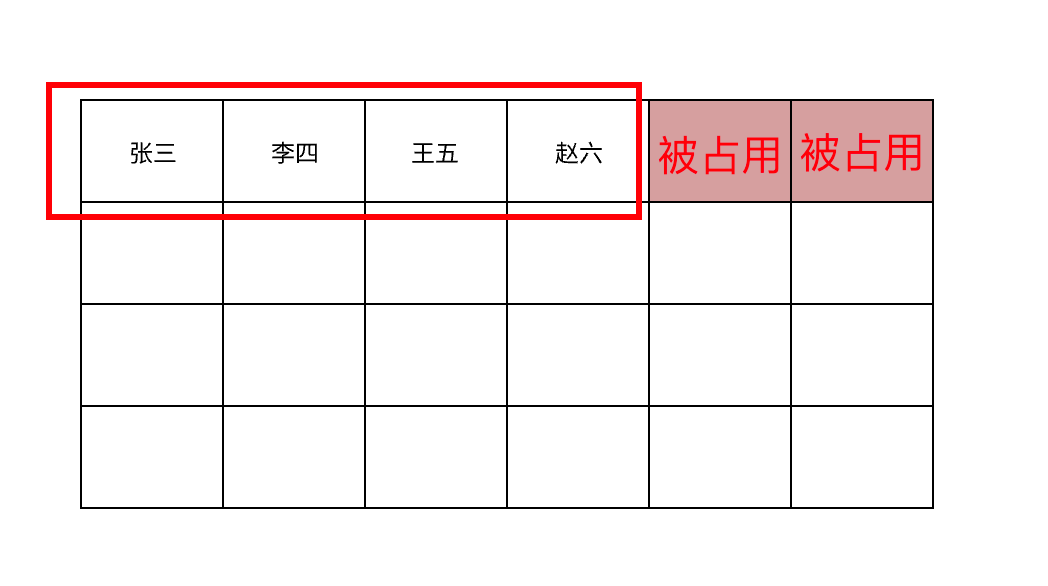
如上图,此时如果再来一个人,只能舍弃原本的四个位置,去重新找有五个连续的位置。如果此时’王五‘不看电影了,那右边的赵六就需要向左边坐一个位置与大家靠拢。
📝 示例代码(go语言)
package main
import "fmt"
func main() {
// 定义一个整型切片
arr := []int{1, 2, 3, 4, 5}
temp := []int{10, 11}
// 遍历切片并打印每个元素及其地址
for i := range arr {
fmt.Printf("Element: %d, Address: %p\n", arr[i], &arr[i])
}
for i := range temp {
fmt.Printf("temp: %d, Address: %p\n", temp[i], &temp[i])
}
// 添加一个元素
arr = append(arr, 6)
// 删除索引为3的元素(值为4)
//arr = append(arr[:3], arr[4:]...)
// 遍历切片并打印每个元素及其地址
fmt.Printf("-----\n")
for i := range arr {
fmt.Printf("Element: %d, Address: %p\n", arr[i], &arr[i])
}
for i := range temp {
fmt.Printf("temp: %d, Address: %p\n", temp[i], &temp[i])
}
}
在Go语言中,数组和切片的处理方式有所不同。首先,理解一下基本概念:
- 数组:固定大小的元素序列,分配一块连续的内存。
- 切片:是对数组的一个引用,包含指向底层数组的指针、长度和容量信息。切片本身是轻量级的,修改切片(如追加、删除)操作可能引起底层数组的重新分配。
这段代码中,arr 是一个切片,但它的初始化方式 [1, 2, 3, 4, 5] 实际上创建了一个底层数组,并用这个数组来初始化切片。而 temp 同样是一个基于数组初始化的切片。
假设初始时,arr 的底层数组在内存中的布局如下(简化表示):
| arr[0]: 1 | arr[1]: 2 | arr[2]: 3 | arr[3]: 4 | arr[4]: 5 |
每个元素旁边标注的是其值和大致的内存地址(实际地址会更复杂,但这里为了简化说明)。注意,
&arr[i]获取的是元素的地址,对于切片中的元素,这实际上是底层数组中相应元素的地址。
🎯 执行增加操作
Element: 1, Address: 0x14000016180
Element: 2, Address: 0x14000016188
Element: 3, Address: 0x14000016190
Element: 4, Address: 0x14000016198
Element: 5, Address: 0x140000161a0
temp: 10, Address: 0x1400000e0a0
temp: 11, Address: 0x1400000e0a8
-----
Element: 1, Address: 0x1400001c140
Element: 2, Address: 0x1400001c148
Element: 3, Address: 0x1400001c150
Element: 4, Address: 0x1400001c158
Element: 5, Address: 0x1400001c160
Element: 6, Address: 0x1400001c168
temp: 10, Address: 0x1400000e0a0
temp: 11, Address: 0x1400000e0a8
如上输出结果所示,增加元素时数组的地址全部发生了变化。
在Go语言中,当你对切片(slice)执行append操作时,如果切片的容量(cap)不足以容纳新的元素,Go会执行以下步骤:
-
检查容量: 首先,Go检查切片的当前容量是否足够容纳新元素。如果足够,切片会在原地扩展,也就是直接在现有底层数组的末尾添加新元素,此时原有元素的地址不会改变。
-
容量不足时的处理: 如果当前切片的容量不足以容纳新元素,Go会创建一个新的、容量更大的底层数组。然后,它会将原切片中的所有元素复制到新数组中,再在新数组的末尾追加新元素。这意味着所有元素都会被移动到新的内存位置,因此它们的地址会改变。
在代码示例中,由于初始时没有明确指定切片的容量,切片会有一个默认的容量。当你调用append添加第六个元素时,如果这个操作导致需要更多空间超出了切片的当前容量,Go就会执行上述的第二步,即创建新的底层数组并复制元素。因此,追加元素后你会观察到每个元素的地址都发生了变化,因为它们都被移到了新的内存位置上。
总结来说,切片追加元素后地址变化的原因在于添加操作导致了底层数组的重新分配,从而引发了元素地址的更新。
🎯 执行删除操作
Element: 1, Address: 0x140000b6030
Element: 2, Address: 0x140000b6038
Element: 3, Address: 0x140000b6040
Element: 4, Address: 0x140000b6048
Element: 5, Address: 0x140000b6050
temp: 10, Address: 0x140000a4020
temp: 11, Address: 0x140000a4028
-----
Element: 1, Address: 0x140000b6030
Element: 2, Address: 0x140000b6038
Element: 3, Address: 0x140000b6040
Element: 5, Address: 0x140000b6048
temp: 10, Address: 0x140000a4020
temp: 11, Address: 0x140000a4028
如上输出结果所示,当删除数组一个元素时(此时删除了索引为3的元素),后续数组的所有元素都向前移动。
当执行 arr = append(arr[:3], arr[4:]...) 这行代码时,Go的切片操作实际上做了以下几步:
- 切片操作:首先,它创建了两个新的切片,一个包含从开始到索引3(不包括3)的元素,另一个包含从索引4开始到最后的元素。
- 合并与重新分配:然后,使用
append函数将这两个切片的内容合并。由于原切片的连续性被打破(需要“跳过”索引3的元素),append可能会检查当前切片的容量是否足够存放新数据。如果不够,它可能会分配一个新的足够大的底层数组来存储合并后的结果;如果当前切片的剩余容量足够,则直接在原有底层数组的基础上进行操作。
删除元素并重新分配内存后,arr 中剩余元素的地址发生了改变,因为它们现在位于一个全新的、连续的内存区域。当打印出每个元素的地址时,你会发现从原来索引3之后的所有元素的地址相比之前都“向前移动”了,这是因为它们现在位于一个起始位置更早的连续块中。
而对于 temp 切片,因为它没有进行任何删除或添加操作,所以其元素的地址保持不变。每次打印 temp 的元素地址时,你会看到相同的地址输出,因为这部分内存没有被重新分配。
总之,删除切片中的元素并导致元素地址“向前移动”的根本原因,在于append操作可能触发的底层数组的重新分配和数据复制到新位置的过程,以维持切片元素的连续性。
📊 优缺点分析
-
优点:
- 随机访问: 直接通过索引访问,时间复杂度为O(1)。
- 简单易用: 大多数编程语言内置支持,易于理解和实现。
-
缺点:
- 插入与删除: 在数组中插入或删除元素需要移动元素,最坏情况下时间复杂度为O(n)。
- 固定大小限制: 传统数组大小固定,动态数组虽然可以自动扩容,但在扩容时可能会导致性能开销。
🔗 链表(Linked List)
📖 什么是链表
链表也是一种线性数据结构,但与数组不同,链表中的元素在内存中并不是顺序存放的,而是通过存在元素中的指针链接起来。每个链表节点包含两个部分:数据域和指针域。
链表访问某个元素需要从头节点开始,沿着指针一步步遍历,最坏情况下时间复杂度为O(n),意味着数据越大,查找越慢。但是在插入和删除操作上链表表现出色,特别是在链表的头部或尾部进行时,只需调整相邻节点的指针即可,时间复杂度为O(1),即使在中间操作,也仅需改动少量指针,避免了大量数据移动。
🌀 链表的存储
链表中的元素可存储在内存的任何地方,因为链表的每个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串在一起。

这犹如寻宝游戏。你前往第一个地址,那里有一张纸条写着“下一个元素的地址为 123”。因此,你前往地址 123,那里又有一张纸条,写着“下一个元素的地址为 847”,以此类推。在链表中添加元素很容易:只需将其放入内存,并将其地址存储到前一个元素中。
因此使用链表时,根本就不需要移动元素,只要有足够的内存空间,就能为链表分配内存。
📝 示例代码(go语言)
package main
import (
"fmt"
)
// ListNode 定义链表节点
type ListNode struct {
Value int
Next *ListNode
}
// LinkedList 定义链表结构
type LinkedList struct {
Head *ListNode
}
// NewListNode 创建新节点
func NewListNode(value int) *ListNode {
return &ListNode{Value: value}
}
// Append 向链表末尾追加节点
func (list *LinkedList) Append(value int) {
newNode := NewListNode(value)
if list.Head == nil {
list.Head = newNode
} else {
current := list.Head
for current.Next != nil {
current = current.Next
}
current.Next = newNode
}
}
// Delete 删除链表中第一个匹配值的节点
func (list *LinkedList) Delete(value int) {
if list.Head == nil {
return
}
if list.Head.Value == value {
list.Head = list.Head.Next
return
}
current := list.Head
for current.Next != nil && current.Next.Value != value {
current = current.Next
}
if current.Next != nil {
current.Next = current.Next.Next
}
}
// PrintListWithAddresses 打印链表节点值和地址
func (list *LinkedList) PrintListWithAddresses() {
current := list.Head
for current != nil {
fmt.Printf("Value: %d, Address: %p -> ", current.Value, current)
current = current.Next
}
fmt.Println("nil")
}
func main() {
// 创建链表实例
linkedList := &LinkedList{}
// 增加节点
linkedList.Append(1)
linkedList.Append(2)
linkedList.Append(3)
fmt.Println("增加前:")
linkedList.PrintListWithAddresses()
// 删除索引为1的元素(值为2)
linkedList.Delete(2)
fmt.Println("删除后:")
linkedList.PrintListWithAddresses()
// 再次增加节点
linkedList.Append(4)
fmt.Println("增加后:")
linkedList.PrintListWithAddresses()
}
增加前:
Value: 1, Address: 0x1400010a240 -> Value: 2, Address: 0x1400010a250 -> Value: 3, Address: 0x1400010a260 -> nil
删除后:
Value: 1, Address: 0x1400010a240 -> Value: 3, Address: 0x1400010a260 -> nil
增加后:
Value: 1, Address: 0x1400010a240 -> Value: 3, Address: 0x1400010a260 -> Value: 4, Address: 0x1400010a270 -> nil
这是一个简单的Go语言示例,模拟演示了链表的创建、增加节点、删除节点以及输出节点值和地址的操作。从上述输出结果可以看见,不管是增加还是删除,改变的只有元素的指向,并没有修改其内存地址,删除也没有移动其他元素的内存地址。
📊 优缺点分析
-
优点:
- 动态大小: 链表的长度可以在运行时动态改变,无需担心预先分配内存的问题。
- 高效插入删除: 在链表中插入或删除元素只需要修改相邻节点的指针,时间复杂度为O(1)(在有指针的情况下)。
-
缺点:
- 访问速度: 不能直接通过索引访问,需要从头节点开始遍历,时间复杂度为O(n)。
- 额外空间开销: 每个节点除了存储数据,还需要存储指向下一个节点的指针。
📊 数组与链表的对比
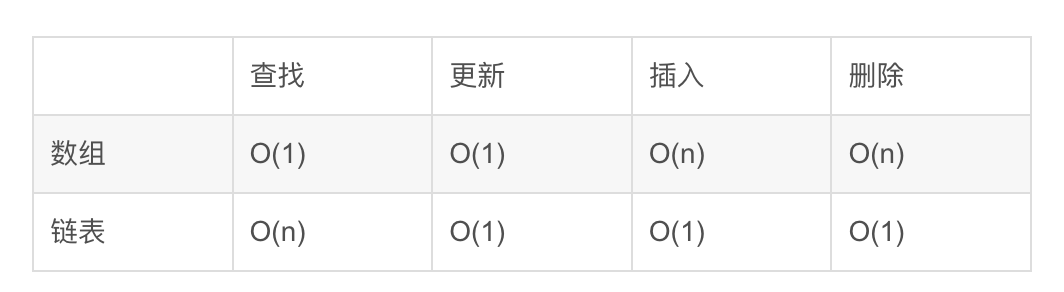
🎯 访问速度
- 数组: 🏆 胜出在于其提供了常数时间O(1)的访问速度。由于元素在内存中连续存储,给定索引后,计算元素地址简单直接,瞬间定位。
- 链表: 访问某个元素需要从头节点开始,沿着指针一步步遍历,最坏情况下时间复杂度为O(n),意味着数据越大,查找越慢。
🎯 插入与删除效率
- 链表: 🏆 在插入和删除操作上表现出色,特别是在链表的头部或尾部进行时,只需调整相邻节点的指针即可,时间复杂度为O(1)。即使在中间操作,也仅需改动少量指针,避免了大量数据移动。
- 数组: 对于插入和删除,特别是当位置不在末尾时,可能需要移动后续的所有元素,以保持连续性,导致最坏情况下的时间复杂度为O(n)。
🎯 空间利用效率
- 数组: 可能导致内存浪费。预先分配固定大小的内存空间,如果未填满,则有未使用的空间。不过,对于确切知道大小的数据集,这不构成太大问题。
- 链表: 每个节点除了存储数据外,还需要额外的内存来存储指向下一个节点的指针,这构成了空间上的开销。然而,链表能够根据需要动态调整大小,避免了预分配过大内存的问题。
🎯 应用场景
- 数组: 非常适合于需要快速随机访问数据的场景,例如图像处理、音频数据、大规模科学计算等,其中数据一旦加载,就频繁查询而很少修改。
- 链表: 在频繁进行插入和删除操作的场景中大放异彩,如实现动态数据结构(如队列、栈)、构建更复杂的数据结构(如哈希表的链地址法解决冲突、图的邻接表表示)或者处理不确定长度的数据流。
📚 小结
数组与链表各有千秋,选择合适的工具对于提高程序性能至关重要。理解它们的底层原理,能帮助我们在面对具体问题时做出明智的选择。希望这篇学习笔记能加深你对这两种基础数据结构的理解,为你的编程之旅增添一份助力!✨