1.性能测试的意义
1.1.现状
互联网行业发展快,用户量大大增加;
业务和系统架构越来越复杂,数据越来越多,用户不仅仅满足于功能的实现,在某些场景下,更 在意系统性能。
1.2.什么是性能测试
通过一定的手段,在多并发下情况下,获取被测系统的各项性能指标,验证被测系统在高并发下 的处理能力、响应能力,稳定性等,能否满足预期。定位性能瓶颈,排查性能隐患,保障系统的 质量,提升用户体验。
2.什么样的系统需要做性能测试
- 用户量大,PV比较高的系统
- 系统核心模块/接口
- 业务逻辑/算法比较复杂
- 促销/活动推广计划
- 新系统,新项目
- 线上性能问题验证和调优
- 新技术选型
- 日常系统性能回归
3.性能测试关键指标
3.1.并发用户数
同时向服务器发送请求的用户数。
其它容易混淆的概念:
注册用户:在系统中注册成功的用户数量,也就是数据库里存储的用户数量
在线用户:同时处于在线状态的用户数量,也就是已经登录成功的用户数量
并发用户:同时向服务器发送请求的用户数量,也就是正在做同一个业务的用户数。
以银行来举例,注册用户就是银行的开卡用户数;在线用户就是进到银行内部的用户数,但是有些用户可 能正在里面休息,不办业务,并不会对银行造成压力,并发用户就是正在办理取款业务的用户数。
注册用户>在线用户>并发用户
3.2.TPS(每秒钟处理的事务数)
TPS:Transaction Per Second,每秒钟处理的事务数。
在服务端接口性能测试中,事务Transaction可以理解成一次接口调用,所以TPS其实就 是服务端每秒钟处理多少次接口调用。如果TPS越高,证明服务端项目的处理能力就越好, 性能就越好。
还是以银行来举例,如果有很多财务人员同时来银行办业务,假设银行每秒能处理1000笔 业务,那就可以说银行业务的TPS=1000,这个数值越大,证明银行单位时间内能办的 业务就越多,性能就越好。
3.3.响应时间
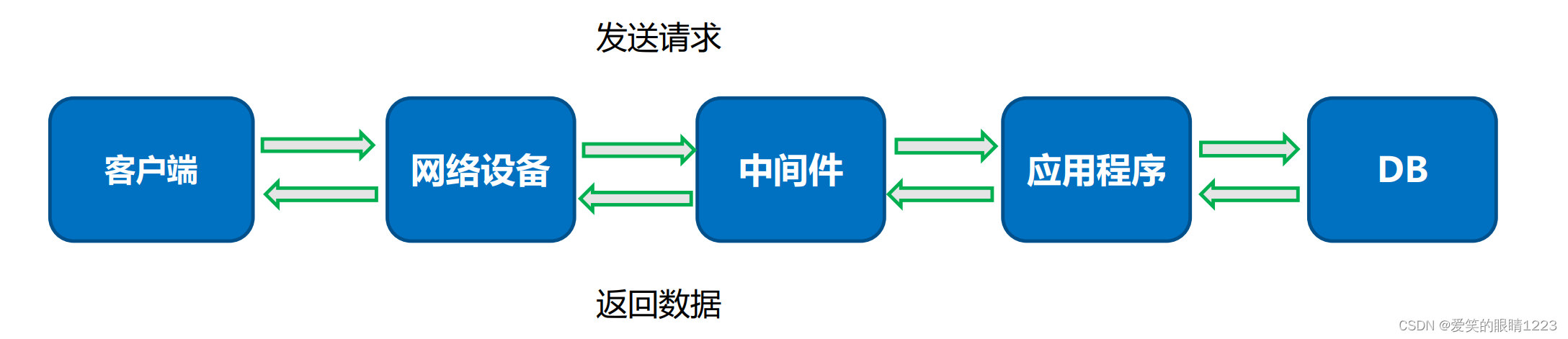
响应时间=网络传输的总时间+各组件业务处理时间
3.3.1平均响应时间
响应时间Response Time,简称RT,指的是服务端处理完一个请求所花费的时间,通常时间单位为毫秒ms。 平均响应时间就是n多个请求响应时间的平均值。 平均响应时间越短,代表性能越好,TPS就越高。 银行办理业务的速度越快,单位时间内处理的业务量越多,因此性能就越好。
3.2.2.TOP响应时间
将所有请求的响应时间先从大到小进行排序,计算指定比例的请求都是小于某个时间。该指标统计 的是大多数请求的耗时。 Tp90(90%响应时间):90%的请求耗时都低于某个时间 Tp95(95%响应时间):95%的请求耗时都低于某个时间 Tp99(99%响应时间):99%的请求耗时都低于某个时间,top响应时间各个工具一般都会自己计算。
同时有平均响应时间和top响应时间,一般情况下以平均响应时间为主,top响应时间最大值和平均响应时间相差较大的时候需要关注top响应时间。
3.4.TPS、响应时间和并发数的关系
还是银行的例子,站在银行的角度来看,随着办业务的人越多,那同一时刻银行的处理业务量就越大,但是银行的处理能力总有 一个上限,当用户量达到某个值后,处理能力就能达到巅峰。此时如果再来更多的用户,银行的处理能力也不会增加了。 在系统达到性能瓶颈之前,TPS和并发数成正比关系,即并发数越高,TPS越高;达到瓶颈后,并发数增加,TPS不会继续增高 (甚至会下降),这个最高的tps出现的点,叫做 拐点 。TPS和平均响应时间成反比关系,即平均响应时间越小,TPS就越高。
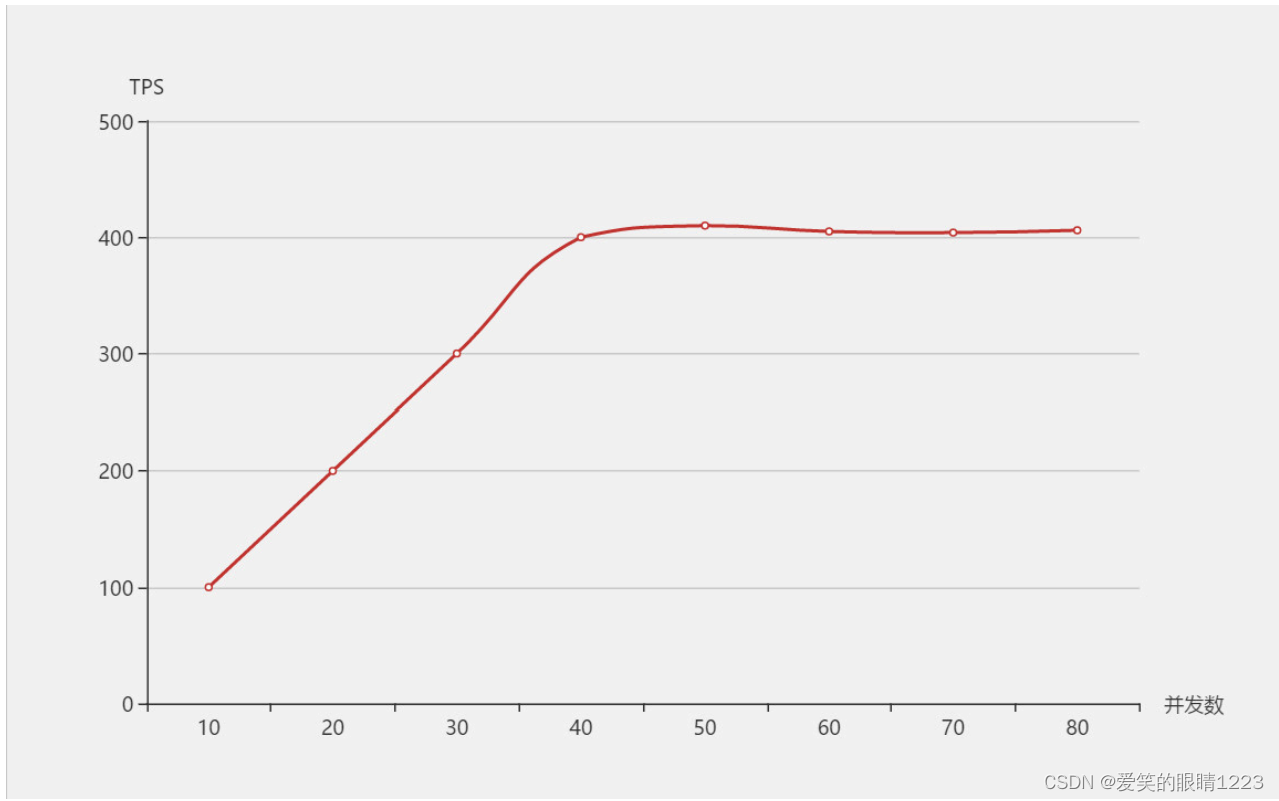
响应时间单位为秒的情况下
TPS = 1 / 响应时间 * 并发数
TPS = 并发数 / 响应时间
3.5.其它性能测试指标
成功率:请求的成功率
PV(Page View) :页面/接口的访问量
UV(Unique Visitor) :页面/接口的每日唯一访客
吞吐量:网络中上行和下行的流量总和,吞吐量代表网络的流量,TPS越高,吞吐量越大
4.性能监控指标
操作系统级别监控
CPU使用率、内存使用率、网络IO(input/output)、磁盘(read/write/util)
中间件监控
连接数、长短连接、使用内存
应用层监控
线程状态、JVM参数、GC频率、锁
DB层监控
连接数、锁、缓存、内存、SQL效率
5.性能测试流程
- 需求调研
- 测试计划
- 环境搭建
- 数据准备
- 脚本编写
- 压测执行
- 调优回归
- 测试报告
6.性能测试工具
- Loadrunner(功能强大、重量级、商业软件)
- Jmeter(小巧灵活、轻量级、开源)
- locust(Python开源框架)
- Ngrinder( 开源压测平台)
下一篇将主要介绍下性能测试流程。