一、前言
代码专家模型是基于人工智能的先进技术,它能够自动分析和理解大量的代码库,并从中学习常见的编码模式和最佳实践。这种模型可以提供准确而高效的代码建议,帮助开发人员在编写代码时避免常见的错误和陷阱。
通过学习代码专家模型,开发人员可以获得高效、准确和个性化的代码支持。这不仅可以提高工作效率,还可以在不同的技术环境中简化软件开发工作流程。代码专家模型的引入将为开发人员带来更多的机会去关注创造性的编程任务,从而推动软件开发的创新和进步。
开源模型应用落地-CodeQwen模型小试-小试牛刀(一)
开源模型应用落地-CodeQwen模型小试-SQL专家测试(二)
二、术语
2.1.CodeQwen1.5
基于 Qwen 语言模型初始化,拥有 7B 参数的模型,其拥有 GQA 架构,经过了 ~3T tokens 代码相关的数据进行预训练,共计支持 92 种编程语言、且最长支持 64K 的上下文输入。效果方面,CodeQwen1.5 展现出了非凡的代码生成、长序列建模、代码修改、SQL 能力等,该模型可以大大提高开发人员的工作效率,并在不同的技术环境中简化软件开发工作流程。
CodeQwen 是基础的 Coder
代码生成是大语言模型的关键能力之一,期待模型将自然语言指令转换为具有精确的、可执行的代码。仅拥有 70 亿参数的 CodeQwen1.5 在基础代码生成能力上已经超过了更尺寸的模型,进一步缩小了开源 CodeLLM 和 GPT-4 之间编码能力的差距。
CodeQwen 是长序列 Coder
长序列能力对于代码模型来说至关重要,是理解仓库级别代码、成为 Code Agent 的核心能力。而当前的代码模型对于长度的支持仍然非常有限,阻碍了其实际应用的潜力。CodeQwen1.5 希望进一步推进开源代码模型在长序列建模上的进展,我们收集并构造了仓库级别的长序列代码数据进行预训练,通过精细的数据配比和组织方式,使其最终可以最长支持 64K 的输入长度。
CodeQwen 是优秀的代码修改者
一个好的代码助手不仅可以根据指令生成代码,还能够针对已有代码或者新的需求进行修改或错误修复。
CodeQwen 是出色的 SQL 专家
CodeQwen1.5 可以作为一个智能的 SQL 专家,弥合了非编程专业人士与高效数据交互之间的差距。它通过自然语言使无编程专业知识的用户能够查询数据库,从而缓解了与SQL相关的陡峭学习曲线。
2.2.CodeQwen1.5-7B-Chat
CodeQwen1.5 is the Code-Specific version of Qwen1.5. It is a transformer-based decoder-only language model pretrained on a large amount of data of codes.
- Strong code generation capabilities and competitve performance across a series of benchmarks;
- Supporting long context understanding and generation with the context length of 64K tokens;
- Supporting 92 coding languages
- Excellent performance in text-to-SQL, bug fix, etc.
三、前置条件
3.1.基础环境
操作系统:centos7
Tesla V100-SXM2-32GB CUDA Version: 12.2
3.2.下载模型
huggingface:
https://huggingface.co/Qwen/CodeQwen1.5-7B-Chat/tree/main

ModelScope:
git clone https://www.modelscope.cn/qwen/CodeQwen1.5-7B-Chat.git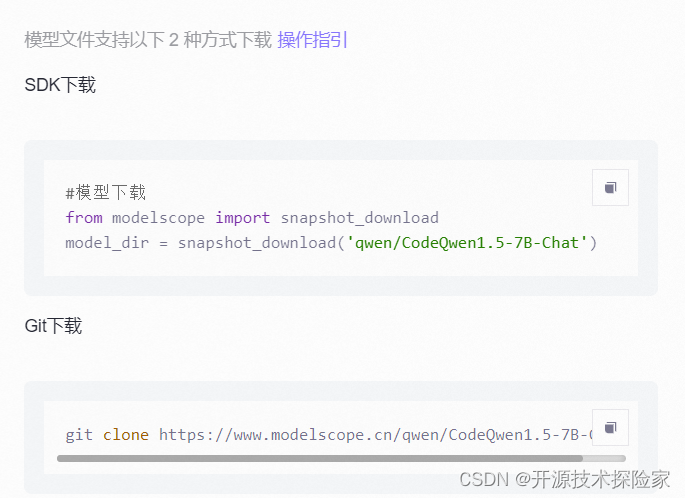
PS:
1. 根据实际情况选择不同规格的模型
3.3.更新transformers库

pip install --upgrade transformers==4.38.1四、使用方式
4.1.基础代码
# -*- coding = utf-8 -*-
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
device = "cuda"
modelPath='/model/CodeQwen1.5-7B-Chat'
def loadTokenizer():
# print("loadTokenizer: ", modelPath)
tokenizer = AutoTokenizer.from_pretrained(modelPath)
return tokenizer
def loadModel(config):
# print("loadModel: ",modelPath)
model = AutoModelForCausalLM.from_pretrained(
modelPath,
torch_dtype="auto",
device_map="auto"
)
model.generation_config = config
return model
if __name__ == '__main__':
prompt = '需要替换哦'
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
]
config = GenerationConfig.from_pretrained(modelPath, top_p=0.85, temperature=0.1, repetition_penalty=1.1,do_sample=True, max_new_tokens=8192)
tokenizer = loadTokenizer()
model = loadModel(config)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)4.2.安全漏洞检测
把基础代码的prompt替换成以下文本
'''
请分析下面代码,是否存在安全漏洞,具体代码如下:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class UserLogin {
public static void main(String[] args) {
String username = "admin";
String password = "password";
try {
// 建立数据库连接
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydatabase", "root", "password");
// 执行查询
Statement statement = connection.createStatement();
String query = "SELECT * FROM users WHERE username='" + username + "' AND password='" + password + "'";
ResultSet resultSet = statement.executeQuery(query);
// 处理查询结果
if (resultSet.next()) {
System.out.println("登录成功");
} else {
System.out.println("登录失败");
}
// 关闭连接
resultSet.close();
statement.close();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
'''调用结果:

结论:
模型能分析出代码漏洞并给出优化建议
4.3.优化代码性能
把基础代码的prompt替换成以下文本
'''
请优化下面代码,提升运行性能,具体代码如下:
public class StringConcatenation {
public static void main(String[] args) {
int n = 10000;
String result = "";
for (int i = 0; i < n; i++) {
result += " " + i;
}
System.out.println(result);
}
}
'''调用结果:



结论:
模型能分析出循环拼接字符串带来的性能问题,并给出更优的实现方式
4.4.代码翻译
把基础代码的prompt替换成以下文本
'''
请用Java语言改写下面代码,并实现一致的功能,具体代码如下:
def bubble_sort(arr):
n = len(arr)
# 遍历所有数组元素
for i in range(n):
# Last i elements are already in place
for j in range(0, n-i-1):
# 遍历数组从 0 到 n-i-1
# 交换如果元素发现大于下一个元素
if arr[j] > arr[j+1] :
arr[j], arr[j+1] = arr[j+1], arr[j]
# 示例
arr = [64, 34, 25, 12, 22, 11, 90]
bubble_sort(arr)
print("排序后的数组为:")
for i in range(len(arr)):
print("%d" %arr[i], end=" ")
'''调用结果:

结论:
模型能理解基于python语言实现的冒泡算法,并转换成Java语言实现类似功能
4.5.生成代码注释
把基础代码的prompt替换成以下文本
'''
请分析下面代码,给出每行的代码注释,具体代码如下:
def train_step(self, batch: Dict, batch_n_steps: int, step: int, loader_start_time: float) -> Tuple[Dict, Dict]:
self.callbacks.on_train_step_start(self)
# format data
batch = self.format_batch(batch)
loader_time = time.time() - loader_start_time
# conteainers to hold model outputs and losses for each optimizer.
outputs_per_optimizer = None
loss_dict = {}
# OPTIMIZATION
if isimplemented(self.model, "optimize"): # pylint: disable=too-many-nested-blocks
# custom optimize for the model
step_time = time.time()
device, dtype = self._get_autocast_args(self.config.mixed_precision, self.config.precision)
with torch.autocast(device_type=device, dtype=dtype, enabled=self.config.mixed_precision):
outputs, loss_dict_new = self.model.optimize(
batch,
self,
)
step_time = time.time() - step_time
# If None, skip the step
if outputs is None:
return None, None
# TODO: find a way to log grad_norm for custom optimize
loss_dict_new = self.detach_loss_dict(loss_dict_new, True, None, None)
loss_dict.update(loss_dict_new)
else:
# gradient accumulation
# TODO: grad accumulation for each optimizer
step_optimizer = True
if ((step + 1) % self.grad_accum_steps != 0) and (step + 1 != batch_n_steps):
step_optimizer = False
if not isinstance(self.optimizer, list):
# auto training with a single optimizer
outputs, loss_dict_new, step_time = self.optimize(
batch,
self.model,
self.optimizer,
self.scaler,
self.criterion,
self.scheduler,
self.config,
step_optimizer=step_optimizer,
num_optimizers=1,
)
loss_dict.update(loss_dict_new)
else:
# auto training with multiple optimizers (e.g. GAN)
outputs_per_optimizer = [None] * len(self.optimizer)
total_step_time = 0
for idx, optimizer in enumerate(self.optimizer):
criterion = self.criterion
# scaler = self.scaler[idx] if self.use_amp_scaler else None
scaler = self.scaler
scheduler = None
if self.scheduler is not None:
scheduler = self.scheduler[idx]
outputs, loss_dict_new, step_time = self.optimize(
batch,
self.model,
optimizer,
scaler,
criterion,
scheduler,
self.config,
idx,
step_optimizer=step_optimizer,
num_optimizers=len(self.optimizer),
)
# skip the rest if the model returns None
total_step_time += step_time
outputs_per_optimizer[idx] = outputs
# merge loss_dicts from each optimizer
# rename duplicates with the optimizer idx
# if None, model skipped this optimizer
if loss_dict_new is not None:
for k, v in loss_dict_new.items():
if k in loss_dict:
loss_dict[f"{k}-{idx}"] = v
else:
loss_dict[k] = v
step_time = total_step_time
outputs = outputs_per_optimizer
# clear any pesky gradients after gradient accumulation
if step_optimizer:
self.model.zero_grad(set_to_none=True)
# update avg runtime stats
keep_avg_update = {}
keep_avg_update["avg_loader_time"] = loader_time
keep_avg_update["avg_step_time"] = step_time
self.keep_avg_train.update_values(keep_avg_update)
# update avg loss stats
update_eval_values = {}
for key, value in loss_dict.items():
update_eval_values["avg_" + key] = value
self.keep_avg_train.update_values(update_eval_values)
# print training progress
if self.total_steps_done % self.config.print_step == 0:
# log learning rates
lrs = {}
if isinstance(self.optimizer, list):
for idx, optimizer in enumerate(self.optimizer):
current_lr = self.optimizer[idx].param_groups[0]["lr"]
lrs.update({f"current_lr_{idx}": current_lr})
elif isinstance(self.optimizer, dict):
for key, optimizer in self.optimizer.items():
current_lr = self.optimizer[key].param_groups[0]["lr"]
lrs.update({f"current_lr_{key}": current_lr})
else:
current_lr = self.optimizer.param_groups[0]["lr"]
lrs = {"current_lr": current_lr}
# log run-time stats
loss_dict.update(lrs)
loss_dict.update(
{
"step_time": round(step_time, 4),
"loader_time": round(loader_time, 4),
}
)
self.c_logger.print_train_step(
batch_n_steps,
step,
self.total_steps_done,
loss_dict,
self.keep_avg_train.avg_values,
)
if self.args.rank == 0:
# Plot Training Iter Stats
# reduce TB load and don't log every step
if self.total_steps_done % self.config.plot_step == 0:
self.dashboard_logger.train_step_stats(self.total_steps_done, loss_dict)
if self.total_steps_done % self.config.save_step == 0 and self.total_steps_done != 0:
if self.config.save_checkpoints:
# checkpoint the model
self.save_checkpoint()
if self.total_steps_done % self.config.log_model_step == 0:
# log checkpoint as artifact
self.update_training_dashboard_logger(batch=batch, outputs=outputs)
self.dashboard_logger.flush()
self.total_steps_done += 1
self.callbacks.on_train_step_end(self)
return outputs, loss_dict
'''调用结果:



![]()
结论:
模型能理解代码逻辑,并给出关键代码的注释
五、附带说明
5.1.代码专家模型适用的使用场景
-
代码自动补全和建议:根据输入的代码片段或上下文,提供下一个可能的代码补全或建议,帮助开发人员提高编码效率。
-
代码错误检测和修复:分析代码,并根据语法规则和最佳实践检测潜在的错误或问题,并提供修复建议。
-
代码重构和优化:分析现有的代码,并提供重构建议,帮助改进代码结构、提高性能或可读性。
-
代码文档生成:根据代码片段或函数、方法等的名称和注释生成相应的文档,提供代码的说明和用法示例。
-
代码解释和教学:根据代码片段或问题,解释代码的功能和工作原理,并提供相应的教学示例和资源。
-
代码安全分析:帮助检测潜在的安全漏洞和弱点,并提供相应的建议和解决方案,以提高代码的安全性。
-
代码翻译和跨语言支持:将一种编程语言的代码翻译成另一种编程语言,帮助开发人员在不同的语言之间进行转换和迁移。
![[法规规划|数据概念]金融行业数据资产和安全管理系列文件解析(2)](https://img-blog.csdnimg.cn/img_convert/5a6602f5c7f382c2bb6b1364d22a3565.jpeg)





![DMAR: [INTR-REMAP] Present field in the IRTE entry is clear 的解决办法](https://img-blog.csdnimg.cn/direct/10c186405a1a47d78303ee8d067b38c4.png)