1. 前言
上文我们讲到了单行函数.实际上SQL还有一类叫做聚合函数, 它是对一组数组进行汇总的函数, 输入的是一组数据的集合, 输出的是单个值.
2. 聚合函数
用于处理一组数据, 并对一组数据返回一个值.
有如下几种聚合函数 : AVG(), SUM(), MAX(), MIN(), COUNT().
3. AVG()与SUM()
该可以对数值型数据使用AVG和SUM函数.计算一列数据的平均值/总和.
例 :

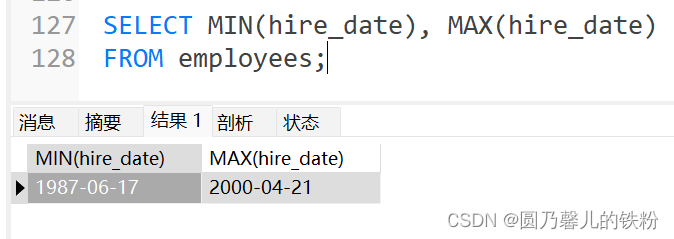
4. MIN()与MAX()
可以对任意数据类型的数据使用MIN与MAX函数,如日期类型,字符串类型的数据.
例 :
5. COUNT()
COUNT(*)是SQL92定义的标准统计行数的语法,其用于返回表中记录的总数,适用于任何数据类型.而COUNT(expr)返回表中expr不为空的记录总数.
例 :
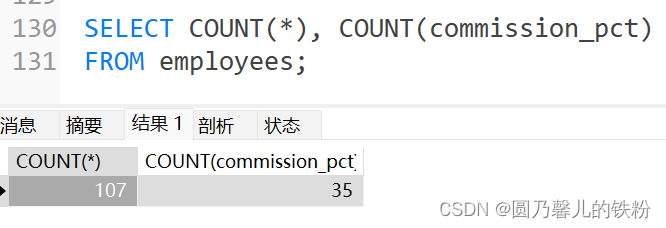
该表中字段有为空的记录,所以要比第一种情况的结果要少.
6. GROUP BY(分组)
我们可以使用GROUP BY子句将表中数据分为若干组.
注 :
- 在SELECT列表中所有未包含在组函数中的列都应该包含在GROUP BY中.
- 但包含在GROUP BY子句中的列不必包含在SELECT子句中.
例 :
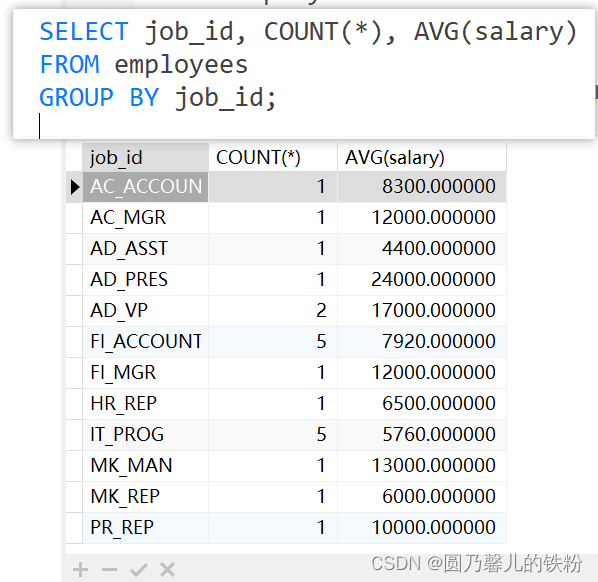
GROUP BY子句将表中记录依据jobid分组,AVG(salary)计算每组的salary总和的平均值.
7. 多列分组
例 :
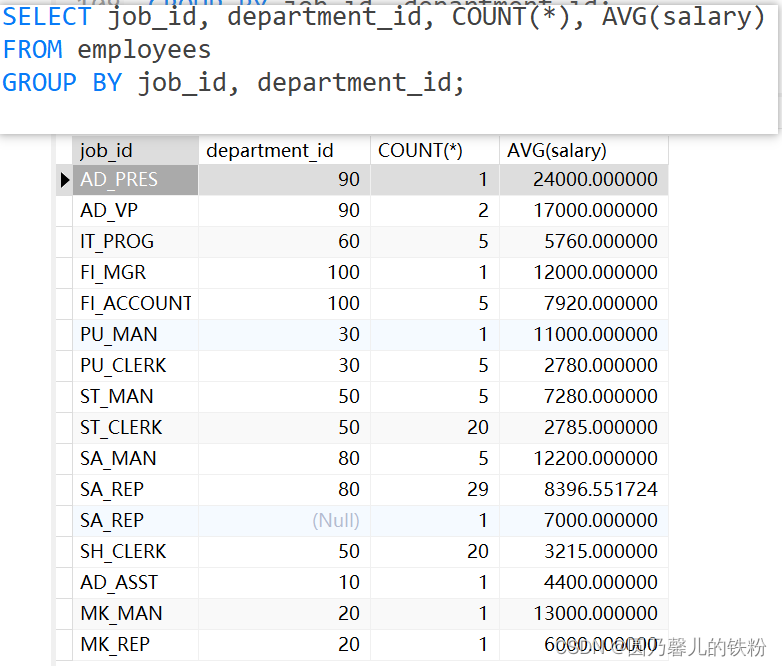
GROUP BY子句将表中记录依据该二者分组,只有不同记录中该二者字段均相等的记录才能被分为一组.
注 :
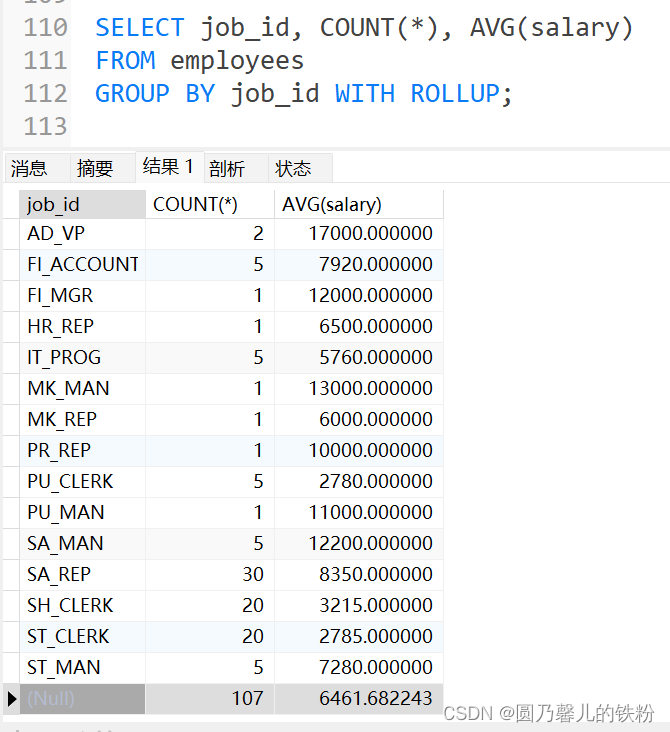
- 使用WITH ROLLUP关键字之后,在所有查询的分组记录之后增加一条记录,该记录计算查询出所有记录的总和,即统计记录数量.
- 使用WITH ROLLUP关键字就不能使用ORDER BY关键字,即二者是互斥的.
例 :
8. HAVING关键字
过滤分组 : HAVING子句
- 行已经被分组.
- 使用了聚合函数
- 满足HAVING子句中条件的分组将被显示.
- HAVING不能单独使用,必须配合GROUP BY一起使用.
例 : 用来过滤已分组的记录
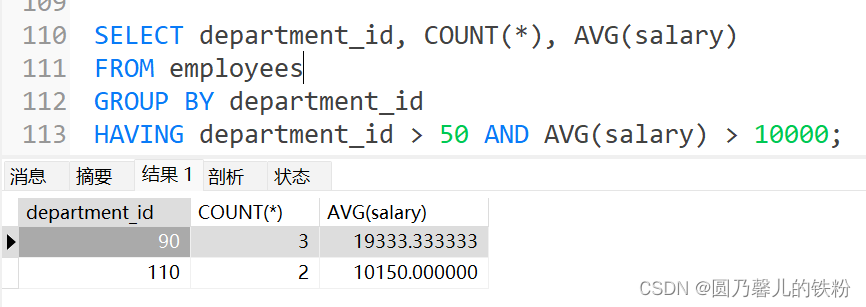
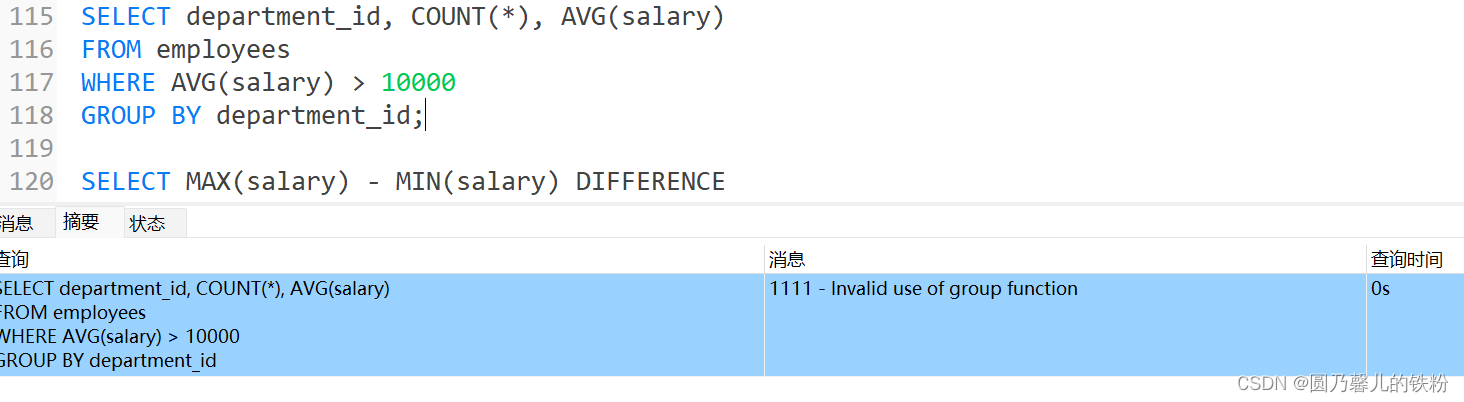
可以在HAVING子句中使用聚合函数,但在WHERE子句中不允许这么做.
例 :
9. WHERE与HAVING的对比
(1). 区别1:
- HERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。
- 这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。另外,WHERE排除的记录不再包括在分组中。
(2). 区别2:
- 如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。
- 这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高.HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
(3). 小结 :
WHERE 先筛选数据再关联,执行效率高 不能使用分组中的计算函数进行筛选
HAVING 可以使用分组中的计算函数 在最后的结果集中进行筛选, 执行效率较低(4). 选择 :
WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。
![[Scrcpy]数据线连接安卓手机投屏windows电脑[win控制安卓手机]比Samsung Dex好用](https://img-blog.csdnimg.cn/img_convert/fbccfa1c2987a5bae16a89b10a3cf31f.png)






![[蓝桥杯]真题讲解:班级活动(贪心)](https://img-blog.csdnimg.cn/direct/1d9e87f0d59b457fbade46069f56c543.png)