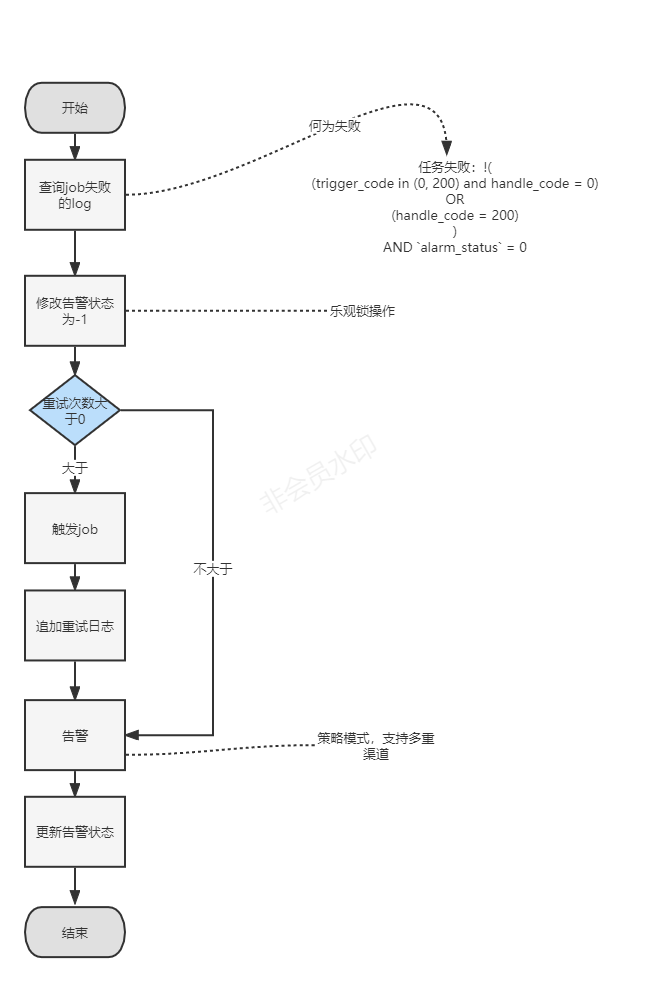
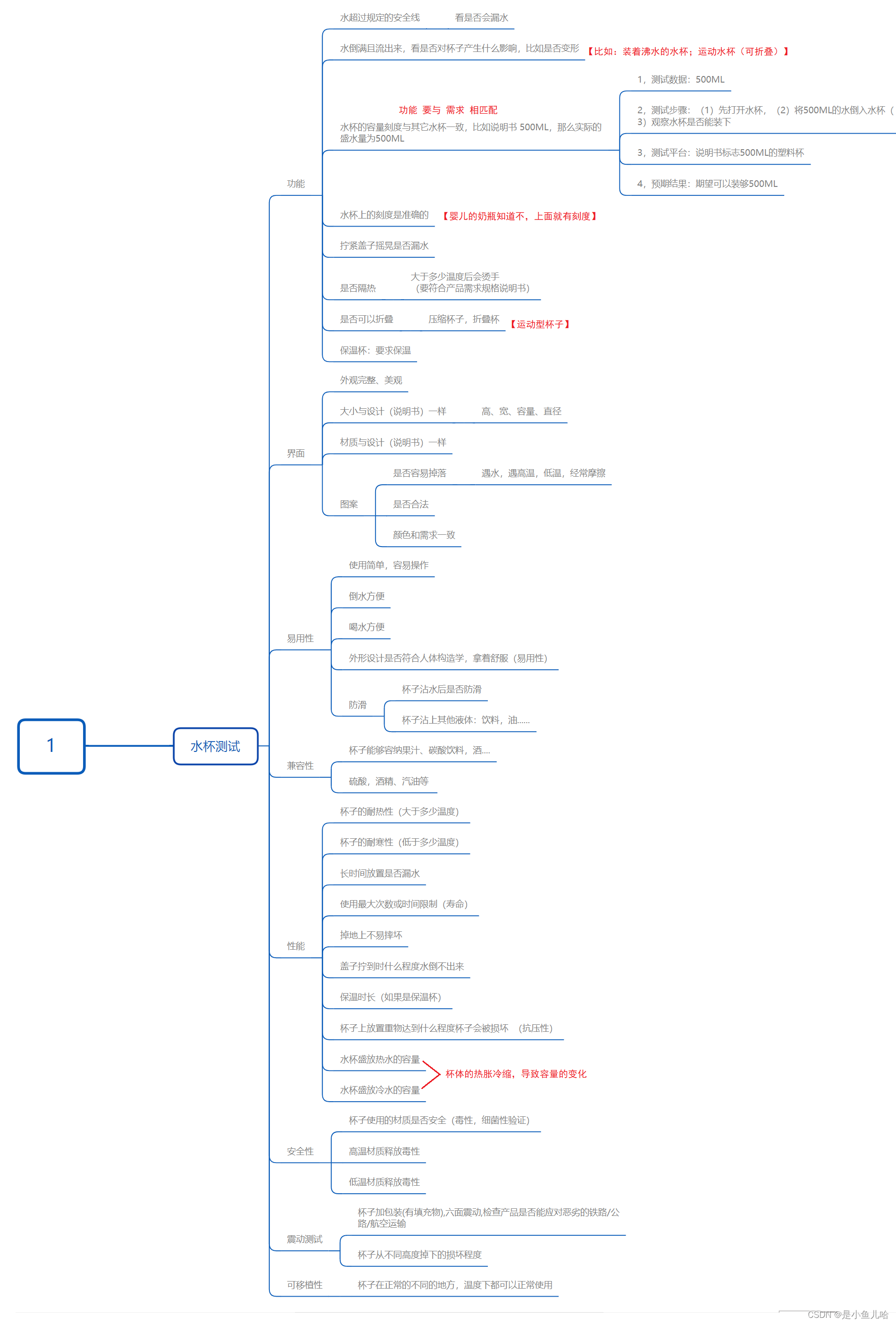
一:概述
当你想训练好一个神经网络时,你需要做好三件事情:一个合适的网络结构,一个合适的训练算法,一个合适的训练技巧:
合适的网络结构:包括网络结构和激活函数,你可以选择更深的卷积网络,然后引入残差连接。可以选择relu做为激活函数,也可以选择tanh,swish等。
合适的训练算法:通常采用SGD,也可以引入动量和自适应学习速率,也许可以取得更好的效果。
合适的训练技巧:合理的初始化,对于较深的网络引入残差连接,归一化等操作。
二:SGD
三:SGD with Momentum
动量梯度下降法的一个本质,就是它们能够最小化碗状函数,
Why momentum?
Momentum项相当于速度,因为β稍小于1,表现出一些摩擦力,所以球不会无限加速下去,所以不像梯度下降法,每一步都独立于之前的步骤,你的球可以向下滚,获得动量,可以从碗向下加速获得动量。
有两个超参数,学习率a以及参数\beta,\beta控制着指数加权平均数。\beta最常用的值是0.9
四: Adagrad
1.其实就是给SGD加了一个分母。
AdaGrad算法就是将每一个参数的每一次迭代的梯度取平方累加后在开方,用全局学习率除以这个数,作为学习率的动态更新。
2.why 要这样?
在实际应用中,各个参数的重要性肯定是不一样的,所以我们对于不同的参数要动态的采取不同的学习率,让目标函数更快的收敛。
3.Adagrad算法分析
(1)学习率变化过程
随着算法不断迭代,r会越来越大,整体的学习率会越来越小。所以,一般来说AdaGrad算法一开始是激励收敛,到了后面就慢慢变成惩罚收敛,速度越来越慢。
(2)学习率减少
在SGD中,随着梯度的增大,我们的学习步长应该是增大的。但是在AdaGrad中,随着梯度g的增大,我们的r也在逐渐的增大,且在梯度更新时r在分母上,也就是整个学习率是减少的,这是为什么呢?
这是因为随着更新次数的增大,我们希望学习率越来越慢。因为我们认为在学习率的最初阶段,我们距离损失函数最优解还很远,随着更新次数的增加,越来越接近最优解,所以学习率也随之变慢。
(3)不是很好
经验上已经发现,对于训练深度神经网络模型而言,从训练开始时积累梯度平方会导致有效学习率过早和过量的减小。
五:RMSprop
1.全称:Root Mean Sqaure prop
同使用动量的梯度下降一样,RMSprop的目的也是为了消除垂直方向的抖动,使梯度下降快速收敛
2.实际上是平方版本的指数加权平均,将导数看作水平方向上的w和垂直方向上的b,更新时b变小了,w变化不大
3.RMSprop计算方法
六:Adam:SGDM+RMSProp
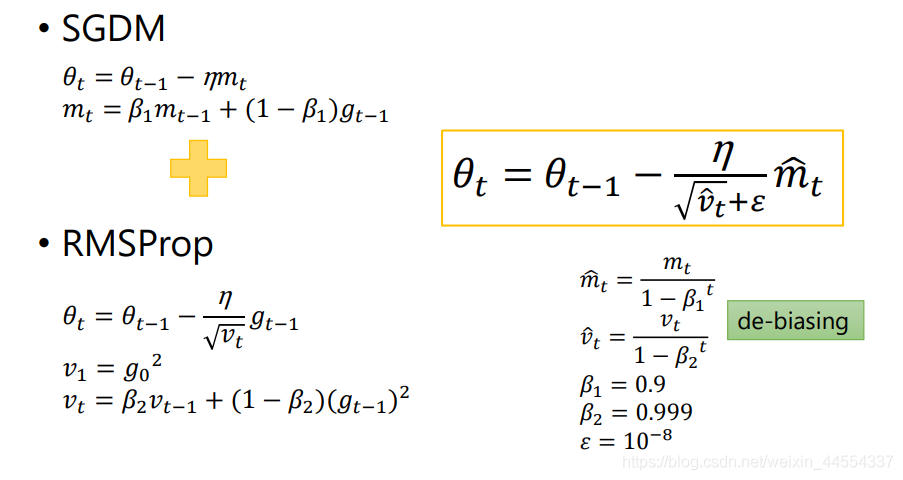
为了解决SGD卡在grad为0.
就是在 RMSprop 的基础上加了 bias-correction 和 momentum,随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
对比:
1.SGD:卡在grand为0
SGD 因为更新比较频繁,会造成 cost function 有严重的震荡。
BGD 可以收敛到局部极小值,当然 SGD 的震荡可能会跳到更好的局部极小值处。当我们稍微减小 learning rate,SGD 和 BGD 的收敛性是一样的。
2. Adagrad:大到小,带了个分母
对低频的参数做较大的更新,对高频的做较小的更新,也因此,对于稀疏的数据它的表现很好,很好地提高了 SGD 的鲁棒性,例如识别 Youtube 视频里面的猫,训练 GloVe word embeddings,因为它们都是需要在低频的特征上有更大的更新。
Adagrad 的优点是减少了学习率的手动调节
它的缺点是分母会不断积累,这样学习率就会收缩并最终会变得非常小。
3.RMSprop:也带分母
为了解决 Adagrad 学习率急剧下降问题的,
yolo是SGDM
总结
Adam比较快,SGDM比较稳
两者结合,SWATS,(begin with Adam ,end with SGDM)
warm-up:针对学习率的优化方式
WARM UP
1.概念
Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。
2.为什么使用Warmup?
由于刚开始训练时,模型的权重(weights)是随机初始化的,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
3.Warmup的改进
不足之处:从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。
改进:从最初的小学习率开始,每个step增大一点点,直到达到最初设置的比较大的学习率



![误删照片音视频文件不要担心 几种方法解救慌乱的你 别再病急乱投医啦 [附软件]](https://img-blog.csdnimg.cn/71564d2e102942a5b7c9368343f666db.png)