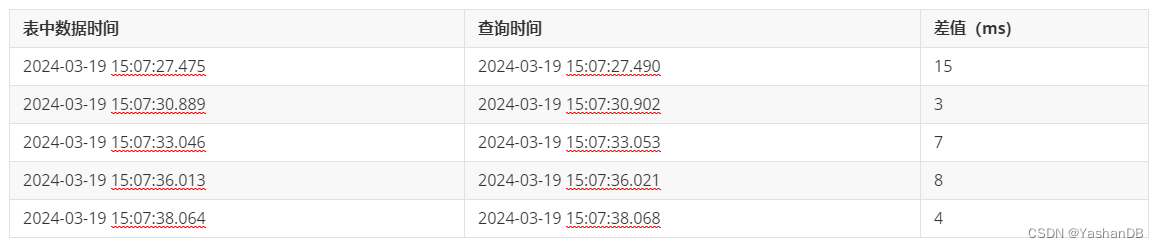
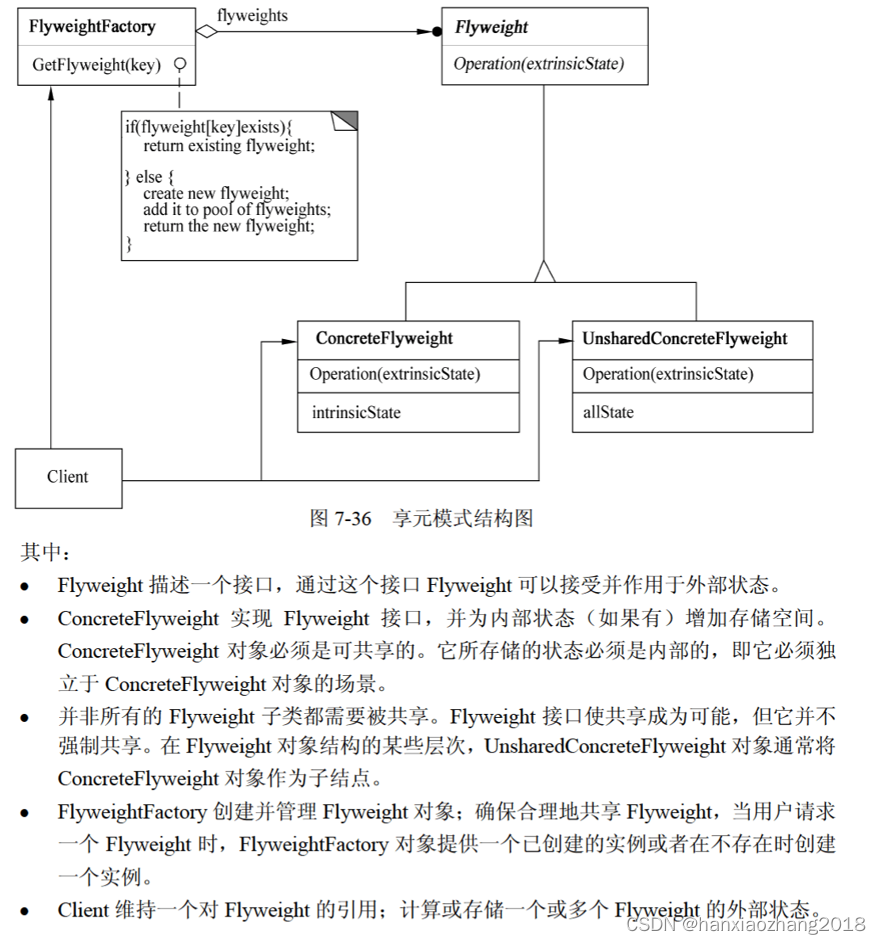
多模态融合致力于整合来自多种模态的信息,目的是实现更准确的预测。在包括自动驾驶和医疗诊断等广泛的场景中,多模态融合已取得显著进展。然而,在低质量数据环境下,多模态融合的可靠性大部分仍未被探索。本文综述了开放多模态融合面临的常见挑战和最新进展,并将它们呈现在一个全面的分类体系中。从数据中心的视角,我们确定了低质量数据上多模态融合面临的四个主要挑战,即(1)噪声多模态数据,它们被不同种类的噪声污染;(2)不完整的多模态数据,某些模态缺失;(3)不平衡的多模态数据,不同模态的质量或属性有显著差异;以及(4)质量变化的多模态数据,每种模态的质量会根据不同样本动态变化。这一新的分类体系将使研究人员能够理解该领域的现状,并识别出几个潜在的研究方向。我们还讨论了这一领域的开放问题以及有趣的未来研究方向。
论文:https://arxiv.org/abs/2404.18947
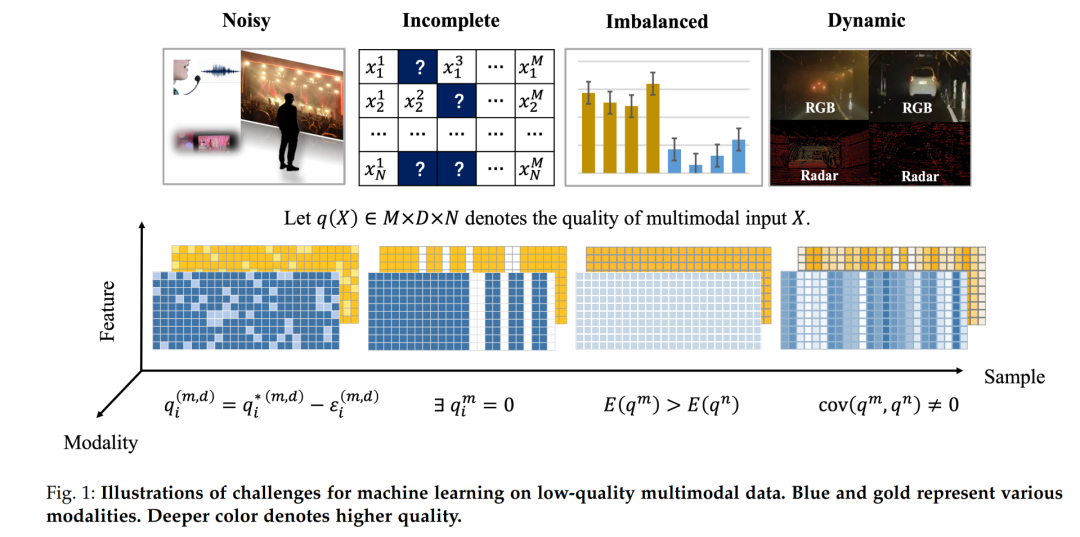
我们对世界的感知基于多种模态,例如触觉、视觉、听觉、嗅觉和味觉。即使某些感官信号不可靠,人类也能从不完美的多模态输入中提取有用线索,并进一步拼凑出正在发生事件的整个场景【1】。随着感知技术的发展,我们可以轻松收集各种形式的数据进行分析。为了充分释放每种模式的价值,多模态融合作为一种有前景的范式出现,通过整合所有可用线索进行下游分析任务,以获得精确和可靠的预测,例如医学图像分析、自动驾驶车辆【2】【3】和情感识别【4】【5】【6】。直观地说,融合来自不同模式的信息提供了探索跨模态相关性并获得更好性能的可能性。然而,人们越来越认识到,广泛使用的AI模型常常被低质量数据中的假相关性和偏见所误导。在现实世界中,由于意外的环境因素或传感器问题,不同模态的质量通常存在差异。一些最近的研究实证和理论上表明,传统的多模态融合可能在野外的低质量多模态数据上失败,例如不平衡【7】【8】【9】【10】、噪声【11】或甚至损坏【12】的多模态数据。为了克服这一限制,并向实际应用中强大且通用的多模态学习迈进一步,我们确定了低质量多模态数据的特性,并专注于现实世界多模态机器融合的一些独特挑战。我们还强调了可能有助于使多模态融合在开放环境中更加可靠和值得信赖的技术进展。在本文中,我们识别并探索了围绕低质量多模态数据的多模态融合的四个核心技术挑战。它们总结如下(也在图1中直观展示):
(1) 噪声多模态数据。第一个基本挑战是学习如何减轻多模态数据中任意噪声的潜在影响。高维多模态数据往往包含复杂的噪声。多模态数据的异质性使得识别和减少潜在噪声成为挑战,同时也提供了通过探索不同模态之间的相关性来识别和减少噪声的机会。
(2) 不完整的多模态数据。第二个基本挑战是如何学习带有部分缺失模态的多模态数据(即不完整的多模态数据)。例如,在医疗领域,即使是患有同一疾病的患者也可能选择不同的医疗检查,产生不完整的多模态数据。开发能够处理不完整多模态数据的灵活且可靠的多模态学习方法是一个具有挑战性但充满希望的研究方向。
(3) 不平衡的多模态数据。第三个基本挑战是如何减轻模态间偏差和差异的影响。例如,视觉模态通常比听觉模态更有效,导致模型采取捷径且缺乏对音频的探索。尽管现有融合方法表现出有希望的性能,但它们可能无法在某些偏好特定模态的应用上比单模态主导模型表现更好。
(4) 质量动态变化的多模态数据。第四个基本挑战是如何适应多模态数据的质量动态变化性质。在实践中,由于不可预见的环境因素或传感器问题,一个模态的质量通常会因不同样本而变化。例如,在低光或逆光条件下,RGB图像的信息量不如热成像模态。因此,在实际应用中,意识到融合中的质量变化并动态整合多模态数据是必要的。
为了应对这些日益重要的多模态融合问题,本研究系统地组织了通过几个分类体系的关键挑战。与以往讨论各种多模态学习任务【13】【14】的相关工作不同,这项综述主要关注多模态学习中最基本的问题以及在下游任务中低质量多模态数据所引起的独特挑战,包括聚类、分类、对象检测和语义分割。在以下部分中,我们通过最近的进展和多模态融合面临的技术挑战详细介绍了这一领域:在噪声多模态数据上的学习(第2节)、缺失模态插补(第3节)、平衡多模态融合(第4节)和动态多模态融合(第5节)。第6节提供了一个作为结论的讨论。
在噪声多模态数据上的学习
在现实世界场景中收集高质量的多模态数据不可避免地面临着由噪声带来的重大挑战。多模态数据【15】的噪声可能源于传感器错误【16】、环境干扰或传输损失。对于视觉模态,传感器中的电子噪声会导致细节丢失。此外,音频模态可能因环境因素受到意外的扭曲。更糟糕的是,弱对齐甚至未对齐的多模态样本也常见,这存在于更高级别的语义空间中。幸运的是,考虑多模态之间的相关性或更好地利用多模态数据可以帮助融合噪声多模态数据。各种相关工作【16】【17】【18】表明,多模态模型超越了它们的单模态对应物。这可以归因于多模态数据利用不同模态之间的相关性,识别和减轻潜在噪声的能力。
多模态噪声大致可以根据其来源分为两类:1) 模态特定噪声,来源于各个模态的传感器错误、环境因素或传输;2) 跨模态噪声,来源于未对齐的多模态对,可以被视为语义级别的噪声。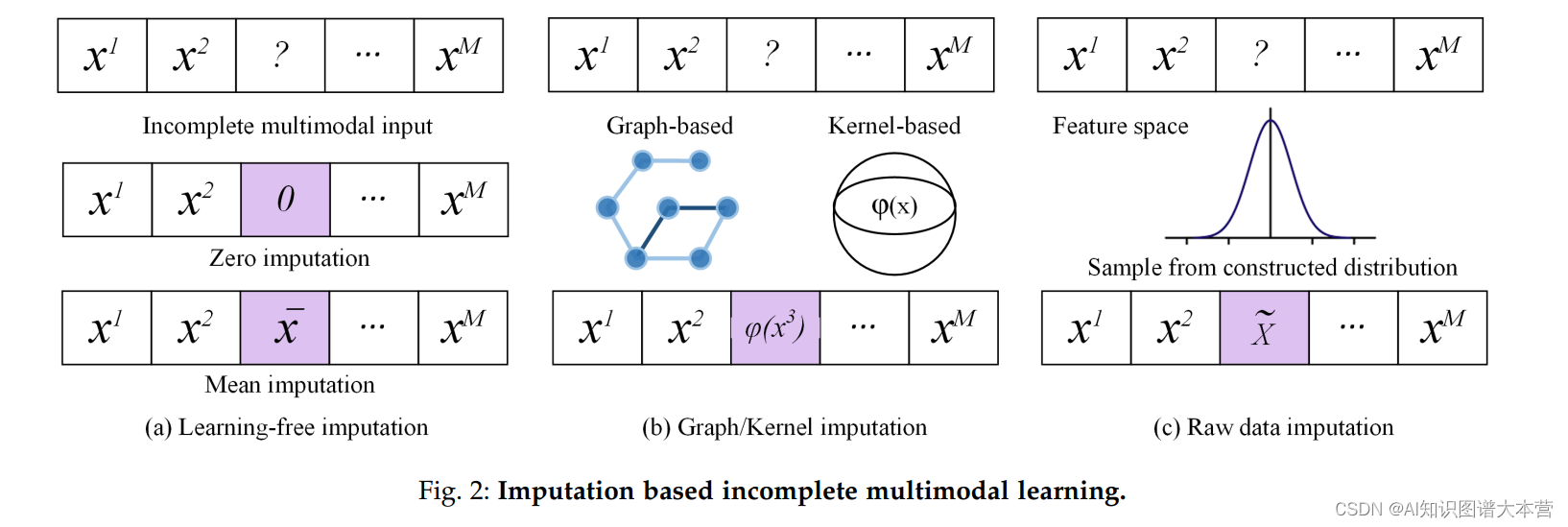
不完整多模态学习
在真实应用中收集的多模态数据常常不完整,某些样本的部分模态因意外因素(如设备损坏、数据传输和存储损失)而缺失。例如,在面向用户的推荐系统中,浏览行为历史和信用评分信息可能并不总是对某些用户可用【48】。同样地,虽然结合多种模态的数据,例如磁共振成像(MRI)扫描、正电子发射断层扫描(PET)和脑脊液(CSF)信息,可以为阿尔茨海默病提供更准确的诊断【49】【50】,但由于PET扫描的高测量成本和CSF的不适感侵入性测试,一些患者可能拒绝进行这些检查。因此,在阿尔茨海默病诊断中常见不完整的多模态数据【51】。通常,传统的多模态学习模型假设多模态数据的完整性,因此不能直接适用于部分模态缺失的情况。针对这一问题,旨在探索具有部分缺失模态的不完整多模态数据的信息的不完整多模态学习出现,并在近年来获得了越来越多的研究关注【52】。在本节中,我们主要关注不完整多模态学习研究的当前进展。从是否对缺失数据进行插补的角度来看,我们将现有方法分为两大类,包括基于插补的和无插补的不完整多模态学习,其中基于插补的方法进一步分为两组,如图2所示,包括实例和模态级别的插补。
平衡多模态学习
不同的模态之间紧密相关,因为它们从不同的视角描述同一概念。这一属性激发了多模态学习的兴盛,其中多种模态被整合,旨在增强对相关事件或对象的理解。然而,尽管存在自然的跨模态相关性,每种模态都有其独特的数据来源和形式。例如,音频数据通常表现为一维波形,而视觉数据则由像素组成的图像构成。一方面,这种差异赋予了每种模态不同的属性,如收敛速度,然后使得同时处理和学习所有模态变得困难,给联合多模态学习带来了难度。另一方面,这种差异也反映在单模态数据的质量上。尽管所有模态描述相同的概念,它们与目标事件或对象相关的信息量不同。例如,考虑一个标有会议的音视觉样本,视觉数据明显显示了会议的视觉内容,这很容易被识别(见图1c)。而相应的音频数据是嘈杂的街道汽车声,很难与会议标签建立联系。视觉模态的信息量显然比音频模态多。由于深度神经网络的贪婪本性【9】,多模态模型倾向于仅依赖具有充足与目标相关信息的高质量模态,同时对其他模态欠拟合。为了应对这些挑战并提高多模态模型的效能,最近的研究集中于策略上,以平衡模态之间的差异并增强模型的整体性能。
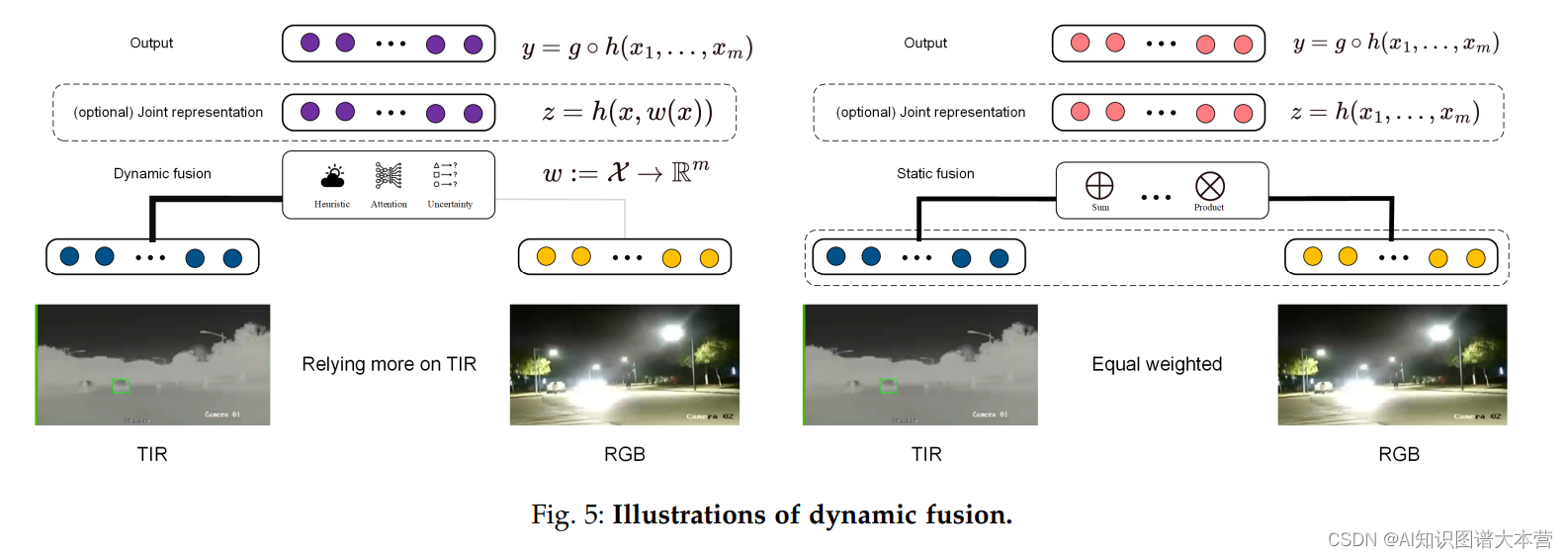
动态多模态融合
当前的多模态融合方法常基于一种假设,即多模态数据的质量是静态的,这在现实世界场景中并不总是成立的。处理具有动态变化质量的多模态数据是多模态智能系统不可避免的问题。由于意外的环境因素和传感器问题,一些模态可能会遭受可靠性差和丢失任务特定信息的问题。此外,不同模态的质量会根据场景动态变化,如图5所示。这一现象激发了一种新的多模态学习范式,即动态多模态融合,其目标是适应多模态数据质量的动态变化并有选择性地整合任务特定信息。在本节中,我们关注动态多模态融合的挑战,并将当前文献中的进展分类为三个主要方向,包括启发式、基于注意力和意识到不确定性的动态融合。