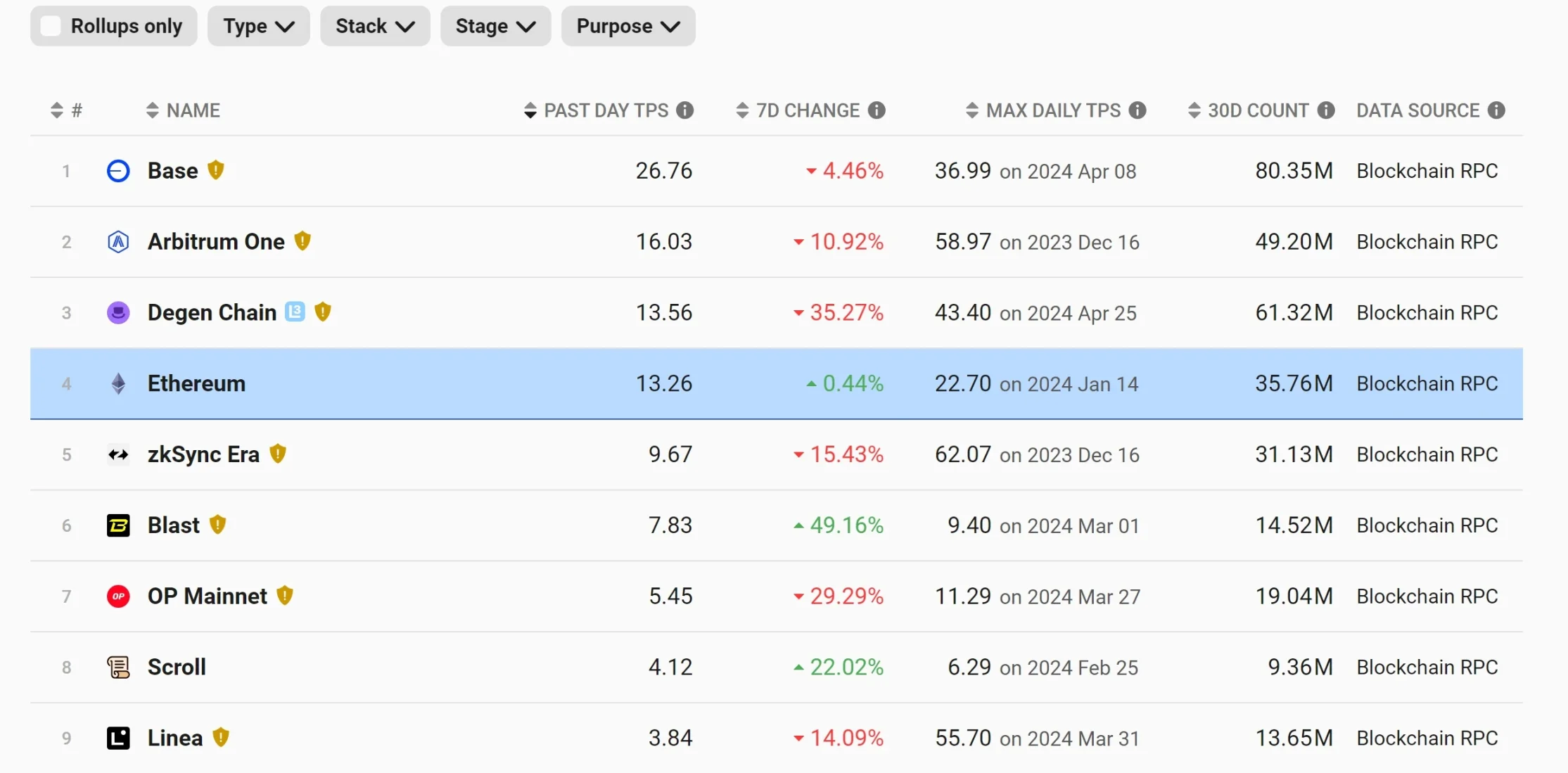
⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计10182字,阅读大概需要10分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
个人网站:https://jerry-jy.co/❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
基于TF的简易关键字语音识别
- 基于TF的简易关键字语音识别
- 一、任务需求
- 二、任务目标
- 1、掌握TensorFlow操作方法
- 2、掌握频谱图
- 3、掌握模型构建、训练、预测、评估方法
- 三、任务环境
- 1、jupyter开发环境
- 2、python3.6
- 3、tensorflow2.4
- 四、任务实施过程
- 1、导入工具
- 2、导入语音命令数据集
- 3、读取音频文件及其标签
- 4、频谱图
- 5、构建和训练模型
- 6、评估测试集性能
- 7、显示混淆矩阵
- 8、对音频文件运行推理
- 五、任务小结
- 说明
基于TF的简易关键字语音识别
一、任务需求
本实验主要展示如何构建一个能够识别十个不同单词的基本语音识别网络。当然,真实的语音和音频识别系统要复杂得多,但就像图像的 MNIST 一样,本实验主要目的是对所语音识别涉及的技术有基本的了解。
完成本教程后,我们将拥有一个可以识别简单语音命令的模型,该模型尝试将一秒钟的音频剪辑分类为“向下”、“前进”、“向左”、“否”、“向右”、“停止”、“向上” “ 是的”。
要求:利用TensorFlow生成简易关键字语音识别模型
二、任务目标
1、掌握TensorFlow操作方法
2、掌握频谱图
3、掌握模型构建、训练、预测、评估方法
三、任务环境
1、jupyter开发环境
2、python3.6
3、tensorflow2.4
四、任务实施过程
1、导入工具
导入必要的模块和依赖项
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras.layers.experimental import preprocessing
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
import pickle
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
2、导入语音命令数据集
原始数据集包含超过 105,000 个 WAV 音频文件,其中包含人们说 30 个不同单词的内容。
我们将只使用数据集的一部分,称为mini_speech_commands,来节省数据加载时间。
data_dir = pathlib.Path('/home/jovyan/datas/mini_speech_commands')
检查有关数据集的基本统计信息。
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: [‘left’ ‘no’ ‘yes’ ‘right’ ‘up’ ‘go’ ‘down’ ‘stop’]
将音频文件提取到列表中并随机打散。
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000
Number of examples per label: 1000
Example file tensor: tf.Tensor(b'/home/jovyan/datas/mini_speech_commands/up/692a88e6_nohash_4.wav', shape=(), dtype=string)
分别使用 80:10:10 的比例将文件拆分为训练集、验证集和测试集。
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400
Validation set size 800
Test set size 800
3、读取音频文件及其标签
音频文件最初将作为二进制文件读取,然后我们将其转换为tensor。
我们使用tf.audio.decode_wav加载音频文件,它将 WAV 编码的音频作为张量和采样率返回。
WAV 文件包含时间序列数据,每秒采样数设定。每个样本代表该特定时间音频信号的幅度。在 16 位系统中,如mini_speech_commands中的文件,取值范围从 -32768 到 32767。此数据集的采样率为 16kHz。需要注意的是,当我们使用tf.audio.decode_wav会将值标准化到范围 [-1.0, 1.0]。
def decode_audio(audio_binary):
audio, _ = tf.audio.decode_wav(audio_binary)
return tf.squeeze(audio, axis=-1)
每个 WAV 文件的标签是其父目录名。
def get_label(file_path):
parts = tf.strings.split(file_path, os.path.sep)
# 在此处使用索引而不是元组解包,以使其能够在 TensorFlow 图中工作。
return parts[-2]
接下来定义一个方法,该方法将接受 WAV 文件的文件名并输出一个包含音频和标签的元组,用于监督训练。
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
对数据集使用map方法,应用自定义的get_waveform_and_label函数。
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(get_waveform_and_label, num_parallel_calls=AUTOTUNE)
检查一些带有相应标签的音频波形。
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
这是一些样本对应的发音波形图,从波形图上可以看出,不同语音的波形图形态差异很大,相同语音的波形图,也不尽相同。
4、频谱图
在这一部分,我们将波形转换为频谱图,该频谱图显示频率随时间的变化并可表示为 2D 图像。这通过应用短时傅立叶变换 (STFT) 将音频转换到时频域来实现。
傅立叶变换 ( tf.signal.fft) 将信号转换为其分量频率,但会丢失所有时间信息。STFT ( tf.signal.stft) 将信号分成时间窗口,并对每个窗口运行傅立叶变换,保留一些时间信息,并返回一个可以运行标准卷积的二维张量。
STFT 生成表示幅度和相位的复数数组。但是,本实验中只需要幅度,这可以通过在tf.signal.stft的输出上应用tf.abs来得到。
选择frame_length和frame_step参数使得生成的频谱图“图像”几乎是方形的。
同时我们还希望波形具有相同的长度,以便将其转换为频谱图图像时,结果将具有相似的维度。这可以通过简单地对短于一秒的音频剪辑进行零填充来完成,所以你会看到有些音频频谱图存在空白。
def get_spectrogram(waveform):
# 使用Padding填充小于16000个样本的文件
zero_padding = tf.zeros([16000] - tf.shape(waveform), dtype=tf.float32)
# 用填充连接音频,使所有音频剪辑的长度相同
waveform = tf.cast(waveform, tf.float32)
equal_length = tf.concat([waveform, zero_padding], 0)
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
spectrogram = tf.abs(spectrogram)
return spectrogram
接下来,我们将探索数据。比较数据集的一个示例样本的波形、频谱图和实际音频。
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: up
Waveform shape: (16000,)
Spectrogram shape: (124, 129)
Audio playback
自定义函数,用于绘制波形图和对数频谱图
def plot_spectrogram(spectrogram, ax):
# 转换为频率的对数尺度和转置,使时间表示在x轴
log_spec = np.log(spectrogram.T+1e-8)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec,shading='nearest')
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
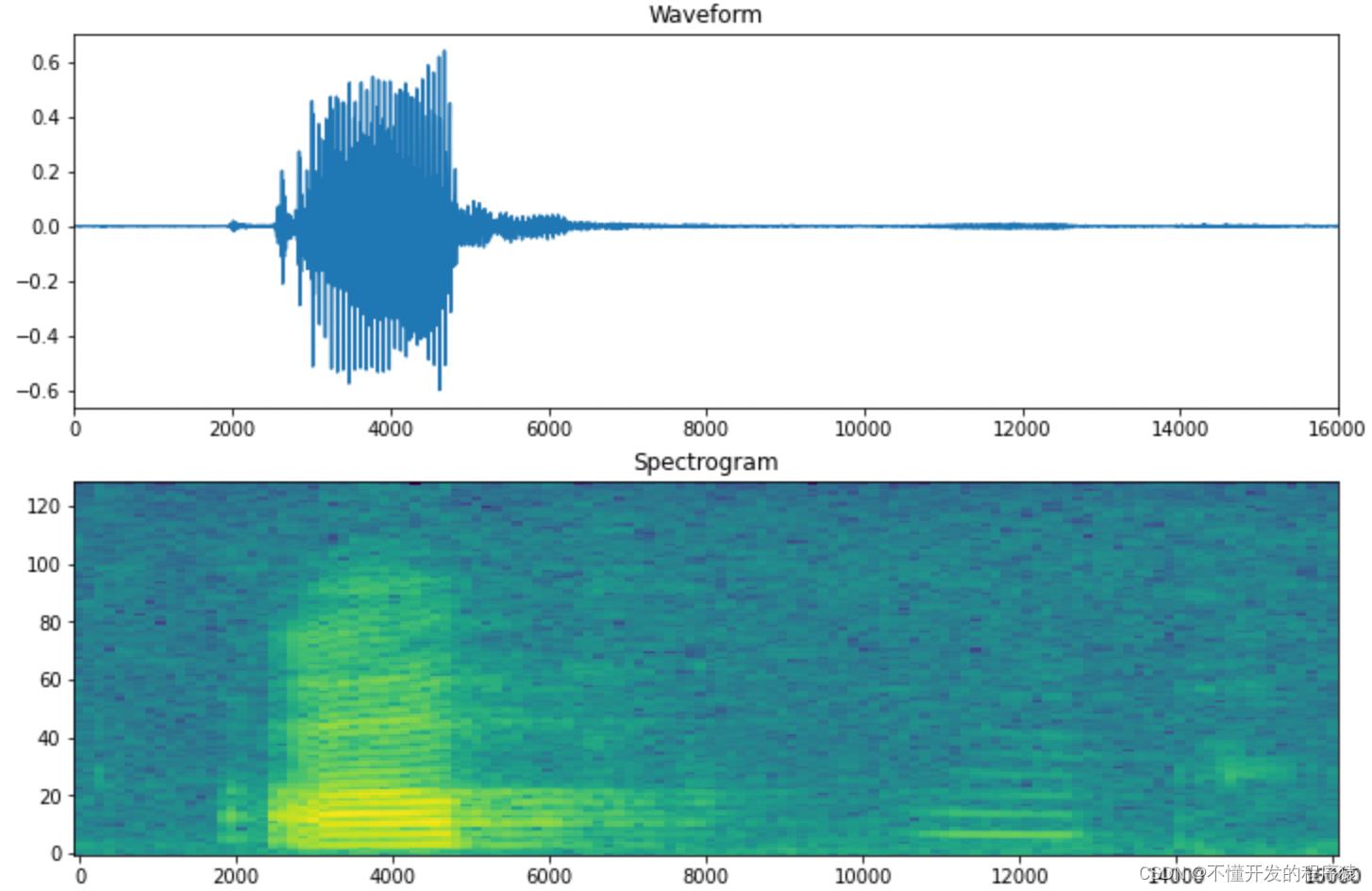
第一幅图是波形图,第二幅图是对数频谱图,我们要做的,就是根据频谱图形,训练网络模型,识别语音命令。
现在将波形数据集转换为具有作为整数 ID 的频谱图图像及其相应标签。
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
spectrogram = tf.expand_dims(spectrogram, -1)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
spectrogram_ds = waveform_ds.map(
get_spectrogram_and_label_id, num_parallel_calls=AUTOTUNE)
检查数据集不同样本的频谱图图像。
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(np.squeeze(spectrogram.numpy()), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
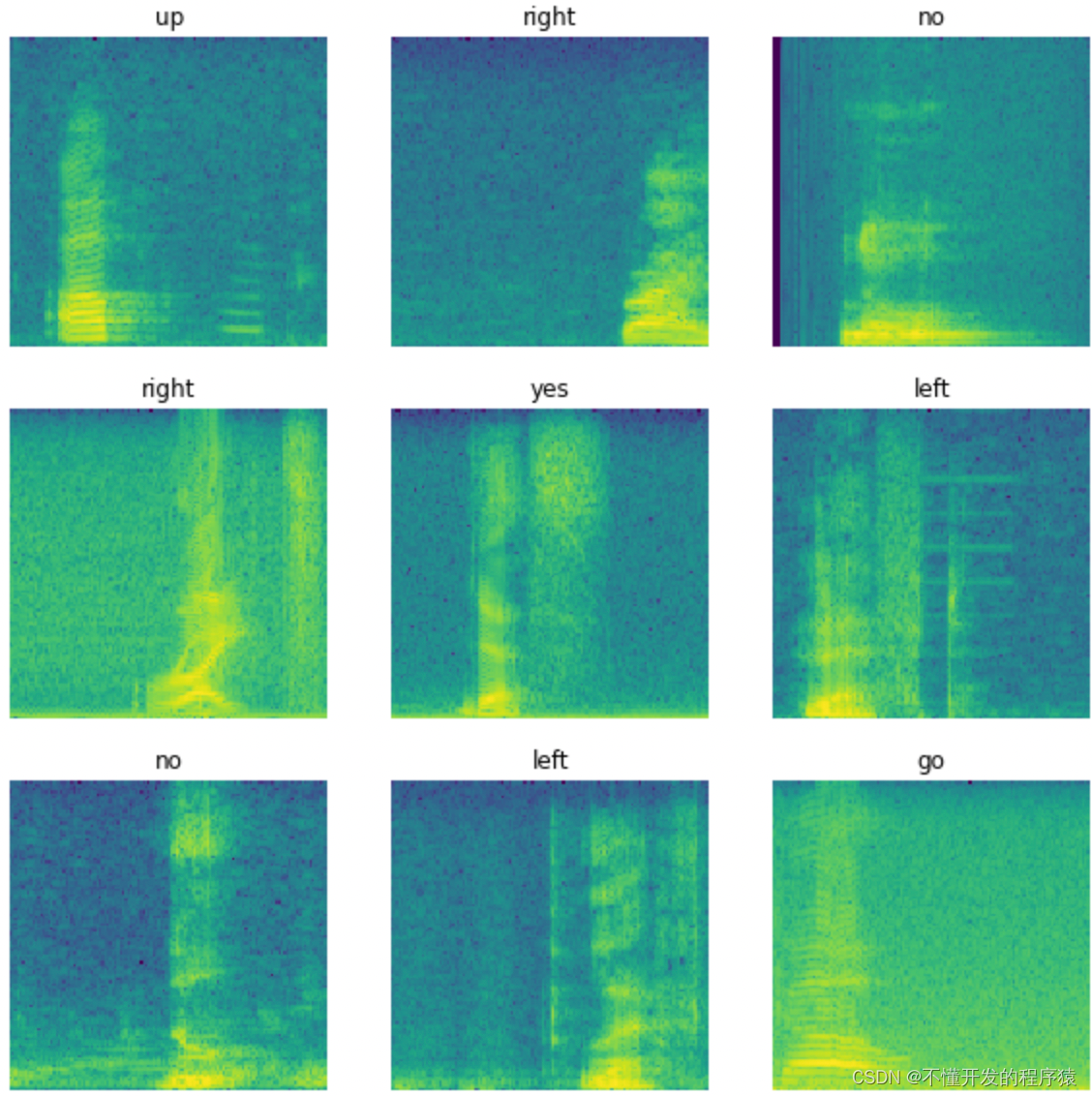
从图中可以看出,我们的代码能够正确运行,并且不同命令对应的频谱图差异较大,相同命令则比较相似。
5、构建和训练模型
现在我们可以构建和训练模型。但在此之前,还需要在验证集和测试集上重复训练集的预处理过程。
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(get_waveform_and_label, num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
get_spectrogram_and_label_id, num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
对数据做batch处理,这里测试集不需要处理
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
添加数据集cache()和prefetch()操作以在训练模型时减少读取延迟。
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
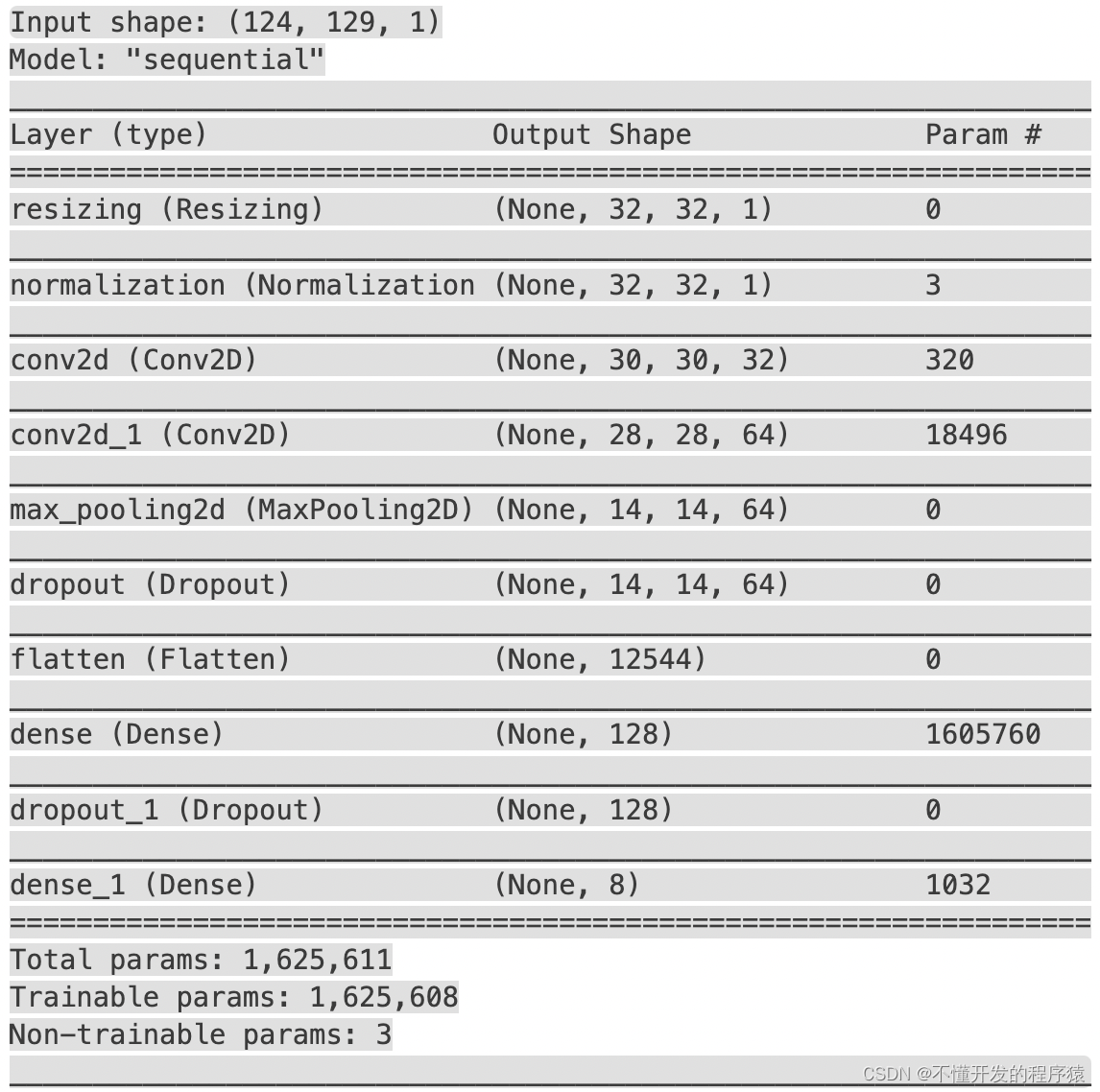
对于模型,您将使用一个简单的卷积神经网络 (CNN),因为您已将音频文件转换为频谱图图像。该模型还有以下额外的预处理层:
- Resizing层到下采样输入,以使模型训练速度更快。
- Normalization根据平均值和标准偏差对图像中的每个像素进行归一化的层。
对于Normalization层,首先需要在训练数据上应用adapt,来计算聚合统计数据(即均值和标准差)。
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
norm_layer = preprocessing.Normalization()
norm_layer.adapt(spectrogram_ds.map(lambda x, _: x))
model = models.Sequential([
layers.Input(shape=input_shape),
preprocessing.Resizing(32, 32),
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
接下来我们将使用训练集训练模型,并使用验证集验证。由于训练时间可能较长,因此我们把训练代码放在markdown代码中,然后将训练结果保存起来,这样你就不用花费大量时间重新训练模型,只需在使用时加载这些模型即可。如果你想体验模型训练过程,把下列代码复制进来就可以了。
[Input]
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
[Output]
Epoch 1/10
100/100 [==============================] - 80s 791ms/step - loss: 1.9188 - accuracy: 0.2723 - val_loss: 1.2747 - val_accuracy: 0.5987
...
Epoch 10/10
100/100 [==============================] - 44s 442ms/step - loss: 0.3792 - accuracy: 0.8680 - val_loss: 0.4814 - val_accuracy: 0.8350
然后我们把模型权重和训练过程的产出物history保存起来。
[Input]
model.save_weights('weights.h5')
with open('./trainHistoryDict', 'wb') as file_pi:
pickle.dump(history.history, file_pi)
这样模型权重就被保存到weights.h5中,history被保存到trainHistoryDict中
model.load_weights('weights.h5')
history = pickle.load(open('./trainHistoryDict', "rb"))
检查训练集和验证集的损失曲线,看看模型在训练过程中是如何改进的。
history.keys()
dict_keys([‘loss’, ‘accuracy’, ‘val_loss’, ‘val_accuracy’])
plt.plot(range(10),history['loss'], history['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()
可以看到,模型在训练集和验证集上的损失快速下降,并且训练集上下降的速度更快。
6、评估测试集性能
让我们在测试集上运行模型并检查性能。
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 91%
7、显示混淆矩阵
混淆矩阵有助于查看模型在测试集中的每个命令上的表现如何。
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx, xticklabels=commands, yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
最终语音预测结果还是比较准确的,大部分语音内容都能够正确识别。错误比较多的情况出现在“go”和“no”上,这也正常,毕竟人耳听起来也非常相似,很容易弄混。
8、对音频文件运行推理
最后,使用某个“不”的输入音频文件验证模型的预测输出。
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()
可以看到我们的模型非常清楚地将音频命令识别为“no”。
五、任务小结
本实验操作完成一个能够识别十个不同单词的基本语音识别网络,该模型将一秒钟的音频剪辑分类为“向下”、“前进”、“向左”、“否”、“向右”、“停止”、“向上” “ 是的”。
通过本实验我们学习到了语音识别与命令控制相关知识,需要掌握以下知识点:
- tensorflow的使用
- 频谱图数据的构建
- 模型构建与训练
- 模型性能评估
–end–
说明
本实验(项目)/论文若有需要,请后台私信或【文末】个人微信公众号联系我