⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计3077字,阅读大概需要3分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
个人网站:https://jerry-jy.co/❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
语音识别--kNN语音指令识别
- kNN语音指令识别
- 一、任务需求
- 二、任务目标
- 1、学习MFCC
- 2、根据MFCC计算DTW
- 3、根据DTW训练kNN分类器
- 三、任务环境
- 1、jupyter开发环境
- 2、python3.6
- 3、tensorflow2.4
- 四、任务实施过程
- 1、加载工具
- 2、了解什么是MFCC
- 3、根据MFCC计算DTW
- 4、训练kNN分类器模型
- 五、任务小结
- 说明
kNN语音指令识别
一、任务需求
我们希望得到一个分类器,它可以识别简单的’a’/'b’两个命令。
kNN分类器使用样本之间的距离做为分类标准。
kNN分类器的训练数据,可以是特征和标签,也可以是样本间的距离矩阵和标签。
要求:创建一个能识别简单语音指令(字母’a’/‘b’)的kNN分类器。
二、任务目标
1、学习MFCC
2、根据MFCC计算DTW
3、根据DTW训练kNN分类器
三、任务环境
1、jupyter开发环境
2、python3.6
3、tensorflow2.4
四、任务实施过程
1、加载工具
首先加载实验所需要用到的工具,首先将/home/jovyan/dependences/添加到环境变量中,该文件夹存放了我们自定义的,用于计算动态时间扭曲距离的工具。
import sys
sys.path.append('/home/jovyan/dependences/')
# 过滤警告信息
import warnings
warnings.filterwarnings('ignore')
import time # 时间相关
import librosa # 音频和音乐分析工具
from dtw import dtw # 自定义的动态时间扭曲距离函数,用于衡量声音之间的距离
import librosa.display # librosa的演示函数
import matplotlib.pyplot as plt
import numpy as np
import IPython.display as ipd
2、了解什么是MFCC
MFCC(Mel-frequency cepstral coefficients):梅尔频率倒谱系数。梅尔频率是基于人耳听觉特性提出来的, 它与Hz频率成非线性对应关系。梅尔频率倒谱系数(MFCC)则是利用它们之间的这种关系,计算得到的Hz频谱特征。主要用于语音数据特征提取和降低运算维度。
梅尔频率倒谱的频带划分是在梅尔刻度上等距划分的,它比用于正常的对数倒频谱中的线性间隔的频带更能近似人类的听觉系统。
接下来我们看看如何得到MFCC图。首先随意加载两个音频进来,方便我们观察学习MFCC。
# 命令“a”
y1, sr1 = librosa.load('/home/jovyan/datas/train/fcmc0-a1-t.wav')
# 命令“b”
y2, sr2 = librosa.load('/home/jovyan/datas/train/fcmc0-b1-t.wav')
首先观察音频命令“a”
# 演示播放“a”
ipd.Audio(y1, rate=sr1)
# 观察“a”的声波图
plt.figure(figsize=(15, 5))
librosa.display.waveplot(y1, sr1, alpha=0.8)
这是语音a对应的波形图
利用librosa可以很方便的提取音频对应的MFCC,提取方式如下
import matplotlib.pyplot as plt
import librosa.display
%matplotlib inline
mfcc1 = librosa.feature.mfcc(y1, sr1)
librosa.display.specshow(mfcc1)
这是语音a对应的MFCC特征矩阵
接下来观察音频命令“b”
plt.figure(figsize=(15, 5))
librosa.display.waveplot(y2, sr2, alpha=0.8)
<matplotlib.collections.PolyCollection at 0x7f459ce44e80>
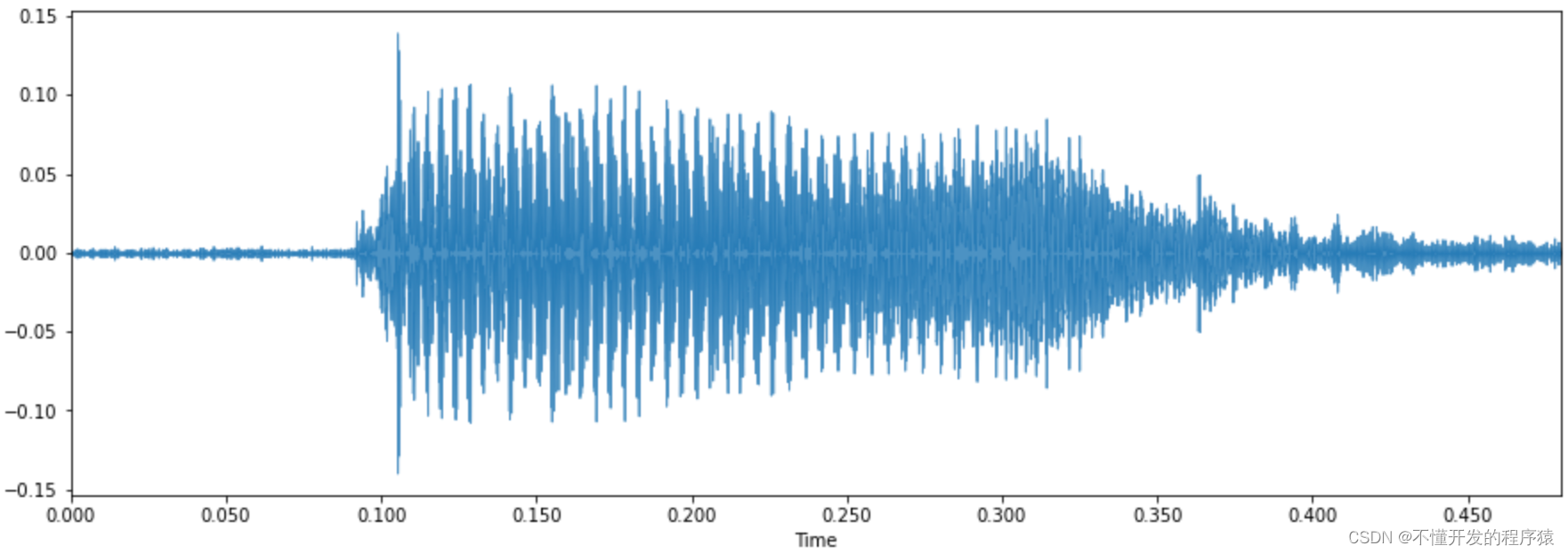
这是语音b对应的波形图
import matplotlib.pyplot as plt
import librosa.display
%matplotlib inline
mfcc2 = librosa.feature.mfcc(y2, sr2)
librosa.display.specshow(mfcc2)
<matplotlib.collections.QuadMesh at 0x7f459c762668>
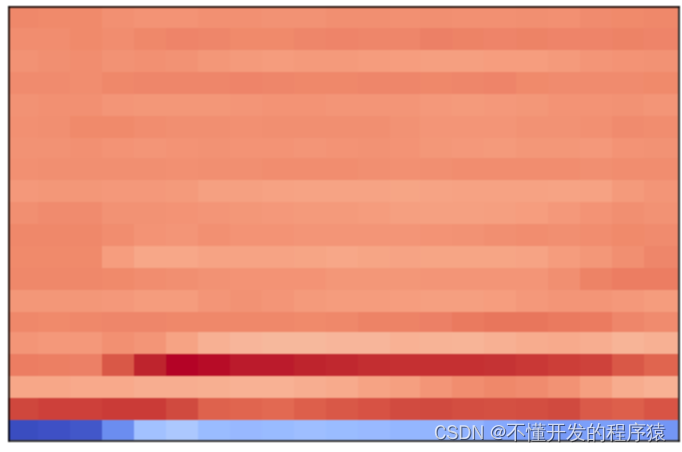
这是语音b对应的MFCC特征矩阵
把“a”“b”的MFCC图放在一起比较
plt.subplot(1, 2, 1)
mfcc1 = librosa.feature.mfcc(y1, sr1)
librosa.display.specshow(mfcc1)
plt.title('a')
plt.subplot(1, 2, 2)
mfcc2 = librosa.feature.mfcc(y2, sr2)
librosa.display.specshow(mfcc2)
plt.title('b')
从MFCC图中我们能看出来,两个音频命令确实存在差别,这种差别有多大呢?我们可以使用DTW来进行度量
3、根据MFCC计算DTW
如果你接触过机器学习,或sklearn工具包,你可能更习惯使用样本属性x和标签y训练模型,例如model.fit(x,y)。实际上,kNN分类器是基于距离度量的模型,我们可以使用样本点两两之间的距离组成的距离矩阵进行训练,即model.fit(distances,y)。
因此,当我们可以度量两个声音之间的距离时,就可以训练kNN分类器。因此接下来我们将根据上一步计算的MFCC,使用“DTW(Dynamic Time Warping)”方法,计算声音之间的距离。
dist, cost, path, _ = dtw(mfcc1.T, mfcc2.T, dist=lambda x, y: np.linalg.norm(x - y, ord=1))
print('Normalized distance between the two sounds:', dist)
Normalized distance between the two sounds: 25.370310163497926
通过DTW函数,我们可以计算声音之间的距离。考虑到kNN模型原理,接下来我们还需要得到训练集各样本点之间的距离。
首先获取训练集中的所有文件名:
import os
dirname = "/home/jovyan/datas/train"
files = [f for f in os.listdir(dirname) if not f.startswith('.')]
# 对文件名进行排序,避免不同系统平台对文件的排序方式不一样
files = list(sorted(files))
使用for循环计算训练集各音频样本点之间的距离,得到样本的距离矩阵distances和标签y。
这一步可能消耗时间比较长,如果不想等待,你可以跳过这一步,直接加载计算好的距离矩阵。
'''
start = time.clock()
minval = 200
distances = np.ones((len(files), len(files)))
y = np.ones(len(files))
for i in range(len(files)):
y1, sr1 = librosa.load(dirname+"/"+files[i])
mfcc1 = librosa.feature.mfcc(y1, sr1)
for j in range(len(files)):
y2, sr2 = librosa.load(dirname+"/"+files[j])
mfcc2 = librosa.feature.mfcc(y2, sr2)
dist, _, _, _ = dtw(mfcc1.T, mfcc2.T, dist=lambda x, y: np.linalg.norm(x - y, ord=1))
distances[i,j] = dist
if i%2==0:
y[i] = 0 #'a'
else:
y[i] = 1 #'b'
print("Time used: {}s".format(time.clock()-start))
np.save('/home/jovyan/datas/distances.npy',distances)
'''
# 加载计算好的距离矩阵
distances = np.load('/home/jovyan/datas/distances.npy')
# 定义标签
y = [0,1]*12
label = ['a','b']
4、训练kNN分类器模型
得到距离矩阵和标签以后,我们就可以使用距离矩阵和标签训练kNN分类器了。
from sklearn.neighbors import KNeighborsClassifier
# 设置邻居数量为5,距离度量方式为欧氏距离
classifier = KNeighborsClassifier(n_neighbors=5,metric='euclidean')
classifier.fit(distances, y)
KNeighborsClassifier(metric='euclidean')
加载测试集样本,查看分类器效果
y, sr = librosa.load('/home/jovyan/datas/test/farw0-b1-t.wav')
# 为了确认是否真的是语音"b",我们将其播放出来听一听
ipd.Audio(y, rate=sr)
由于模型训练时,使用的是距离矩阵,因此预测时,使用的也应当是测试样本点到训练集各个样本点之间的距离。
因此我们需要依次计算测试集样本距离其他样本点的距离。
mfcc = librosa.feature.mfcc(y, sr)
distanceTest = []
for i in range(len(files)):
y1, sr1 = librosa.load(dirname+"/"+files[i])
mfcc1 = librosa.feature.mfcc(y1, sr1)
dist, _, _, _ = dtw(mfcc.T, mfcc1.T, dist=lambda x, y: np.linalg.norm(x - y, ord=1))
distanceTest.append(dist)
pre = classifier.predict([distanceTest])[0]
print(pre,label[int(pre)])
1 b
从结果上看,我们成功的预测该样本标签为1,即声音“b”。
五、任务小结
本实验完成kNN分类器实现简单的语音识别,主要应用MFCC和DTW等方法。通过本实验我们学习到了KNN和语音距离计算以及MFCC的相关知识,需要掌握以下知识点:
- 提取语音特征(与其他语音的动态时间扭曲距离)
- 根据距离,使用kNN分类器识别语音
–end–
说明
本实验(项目)/论文若有需要,请后台私信或【文末】个人微信公众号联系我