文章目录
- 一、爬取需求
- 二、所需第三方库
- 2.1 简介
- 三、实战案例
- 四、完整代码
一、爬取需求
目标网站:
http://www.weather.com.cn/textFC/hb.shtml
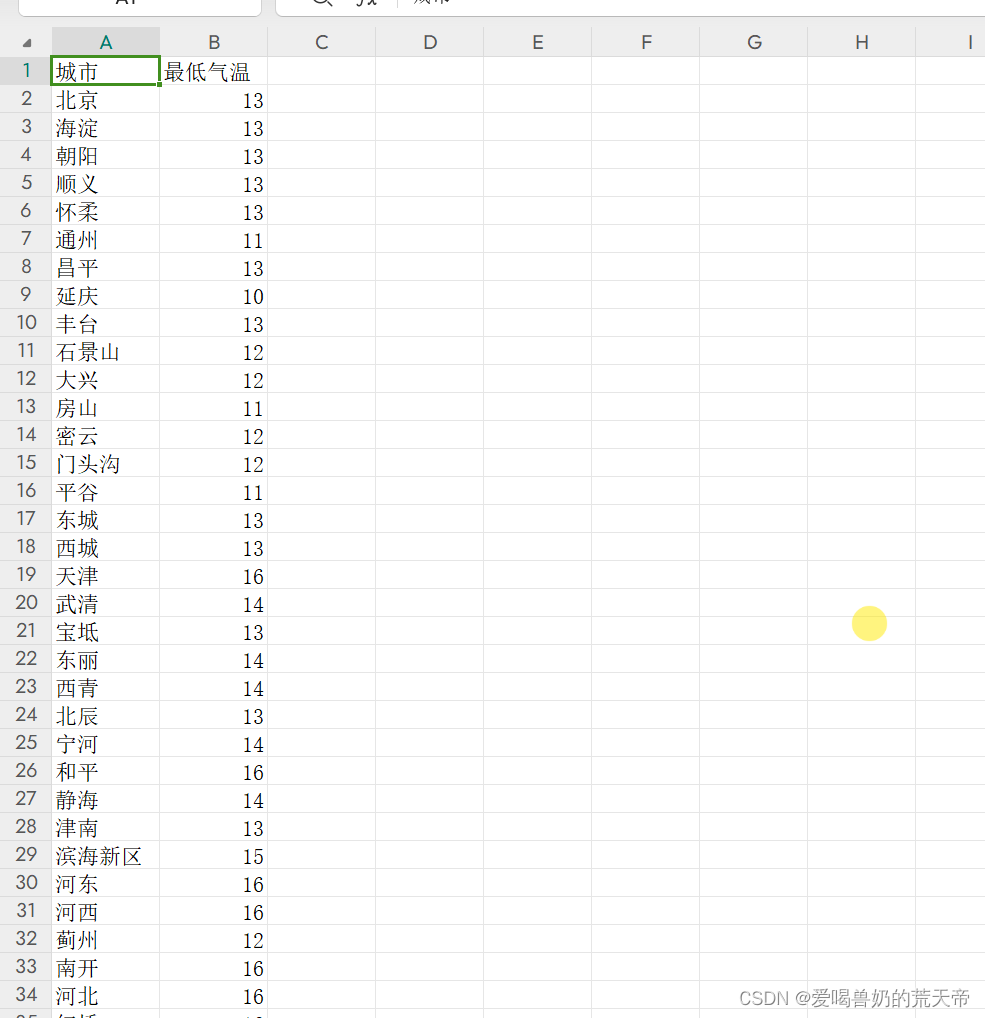
需求:爬取全国的天气(获取城市以及最低气温)
目标url:http://www.weather.com.cn/textFC/hz.shtml
二、所需第三方库
requests
BeautifulSoup4
安装
requests:
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
BeautifulSoup4:pip install BeautifulSoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
2.1 简介
requests模块
官方文档:
https://requests.readthedocs.io/projects/cn/zh-cn/latest/
requests 是 Python 编程语言中一个常用的第三方库,它可以帮助我们向 HTTP 服务器发送各种类型的请求,并处理响应。
- 向 Web 服务器发送 GET、POST 等请求方法;
- 在请求中添加自定义标头(headers)、URL 参数、请求体等;
- 自动处理 cookies;
- 返回响应内容,并对其进行解码;
- 处理重定向和跳转等操作;
- 检查响应状态码以及请求所消耗的时间等信息。
BeautifulSoup4模块
官方文档:
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
Beautiful Soup 是一个 可以从 HTML 或 XML 文件中提取数据的 Python 库。它能用你喜欢的解析器和习惯的方式实现 文档树的导航、查找、和修改。
下表描述了几种解析器的优缺点:
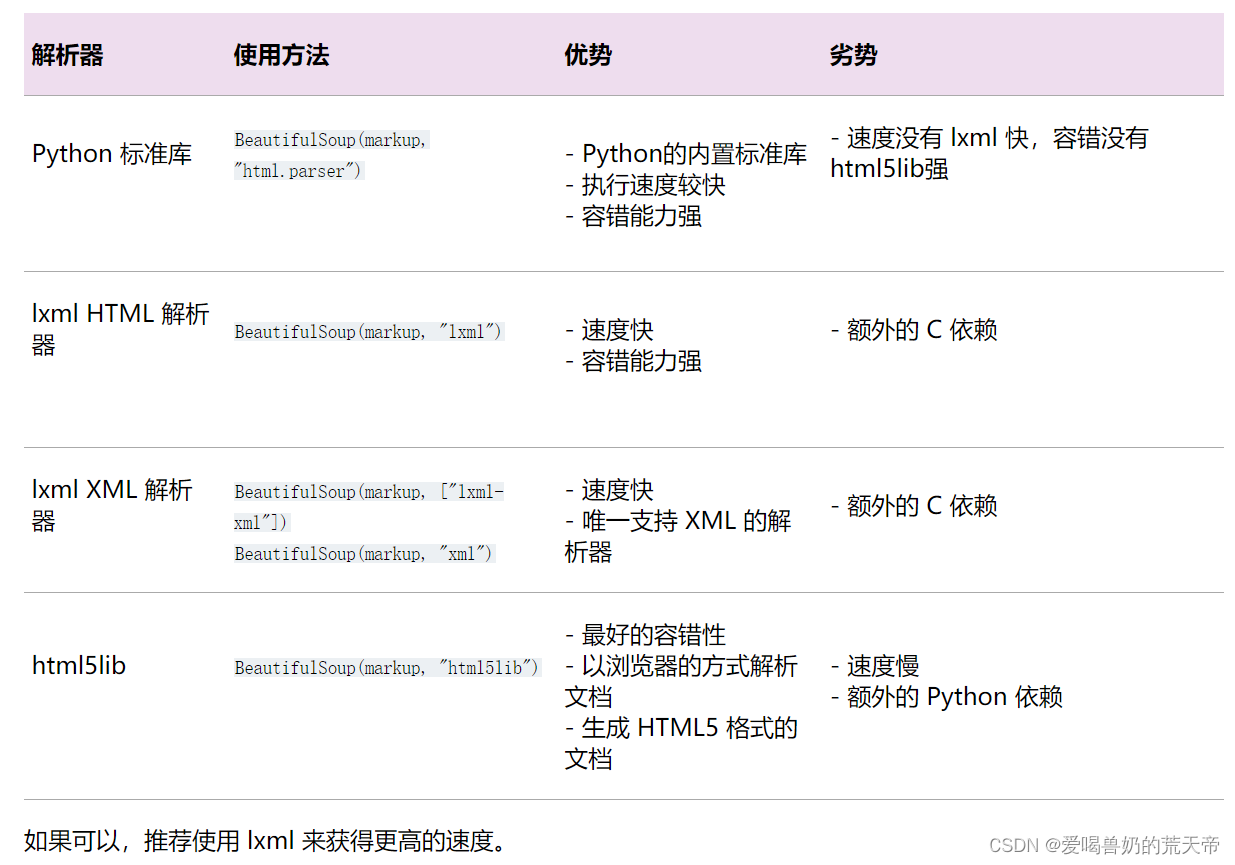
注意:如果一段文档格式不标准,那么在不同解析器生成的 Beautiful Soup 数可能不一样。 查看 解析器之间的区别 了解更多细节。
数据提取之CSS选择器:
- 熟悉前端的同学对 css 选择器一定不会陌生,比如 jquery 中通过各种 css 选择器语法进行 DOM 操作等
- 学习网站:
http://www.w3cmap.com/cssref/css-selectors.html
在爬虫中使用css选择器,代码教程:
>>> from requests_html import session
# 返回一个Response对象
>>> r = session.get('https://python.org/')
# 获取所有链接
>>> r.html.links
{'/users/membership/', '/about/gettingstarted/'}
# 使用css选择器的方式获取某个元素
>>> about = r.html.find('#about')[0]
>>> print(about.text)
About
Applications
Quotes
Getting Started
Help
Python Brochure
三、实战案例
目标网站:http://www.weather.com.cn/textFC/hb.shtml
思路分析:
- 通过find方法,定位的div class=conMidtab2
- 通过find_all方法,找所有的tr标签
函数功能
- 得到网页源码
- 解析数据
- 保存数据
- 主函数
程序框架
import requests
from bs4 import BeautifulSoup
# 获取网页源码
def get_html():
pass
# 解析数据
def parse_html():
pass
# 保存数据
def save_data():
pass
# 主函数
def main():
pass
获取网页源码
在主函数中进行传参调用
# 获取网页源码
def get_html(url):
html = requests.get(url)
html.encoding = 'utf-8'
# print(html.text)
return html.text
# 主函数
def main():
url = 'http://www.weather.com.cn/textFC/hz.shtml'
html = get_html(url)
main()
解析数据
将get_html函数的返回值(网页源码)作为参数传给parse_html函数
# 主函数
def main():
url = 'http://www.weather.com.cn/textFC/hz.shtml'
html = get_html(url)
parse_html(html)
main()
对于parse_html函数,要将传入的网页源码进行解析,获取我们想要的数据。
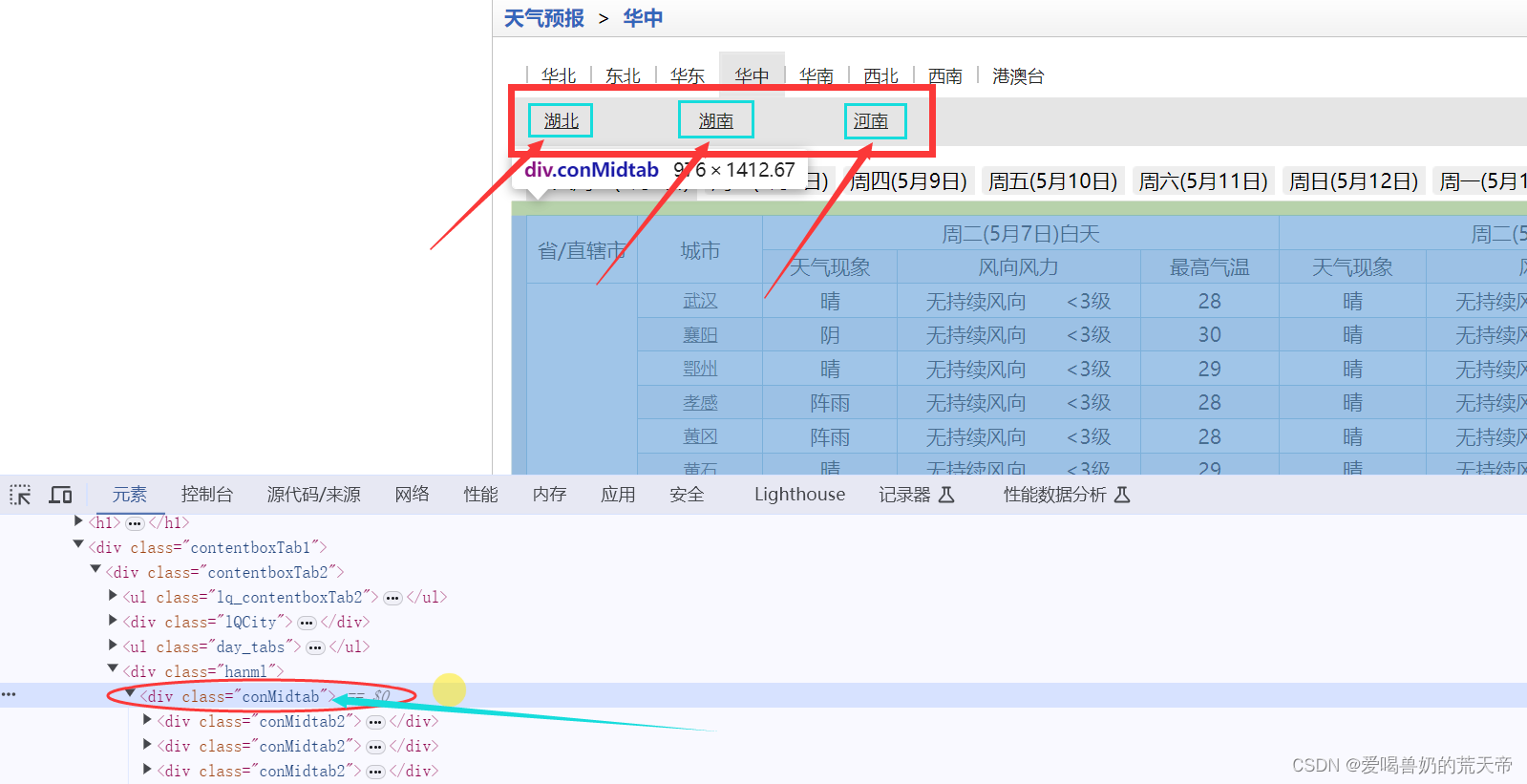
通过观察元素,每一个class="conMidtab2"的div标签就代表一个省份,那么他的父级元素class="conMidtab"的div标签就包含三个省份的天气信息,了解了这些,剩下的我们只需要根据元素之间的关系,一步步提取我们想要的数据即可。
# 解析数据
def parse_html(html):
# 创建对象
soup = BeautifulSoup(html, 'lxml')
conMidtab = soup.find('div', class_="conMidtab")
tables = conMidtab.find_all('table')
# print(tables)
for table in tables:
trs = table.find_all('tr')[2:]
# print(trs)
for index, tr in enumerate(trs):
tds = tr.find_all('td')
# print(tds)
city = list(tds[1].stripped_strings)[0] # 城市
temp = tds[-2].string # 最低气温
print(city, temp)
break
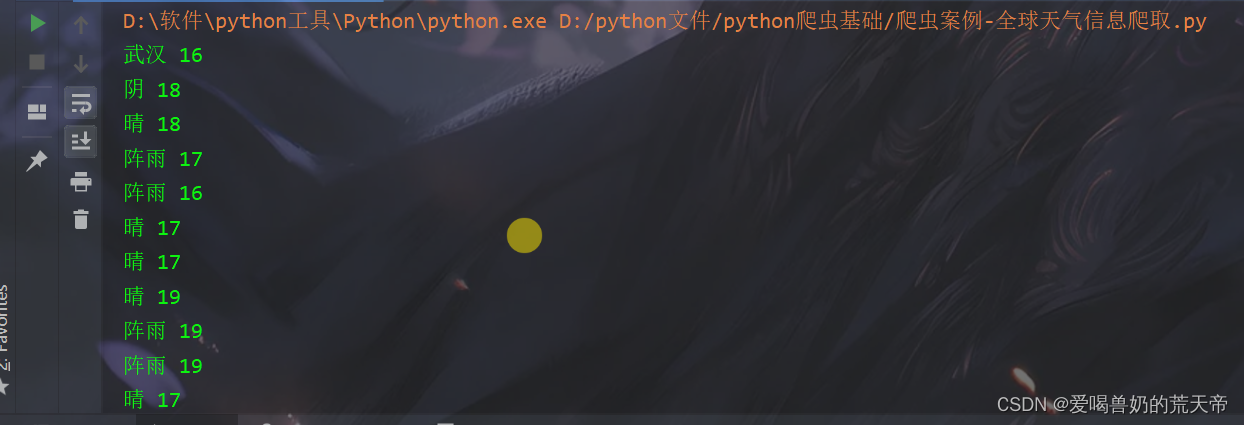
但是,这里出现了一个问题,那就是我们要打印城市信息的时候,只能打印出第一个城市,后面的城市无法打印出来,通过查看元素后我们会发现,除了第一个城市是在第二个td标签里面,其余城市都在第一个td标签里面,所以在这里我们要将循环改一下,同时还要加一个判断,只要是第一个城市就去第二个td标签,其余的取第一个td标签
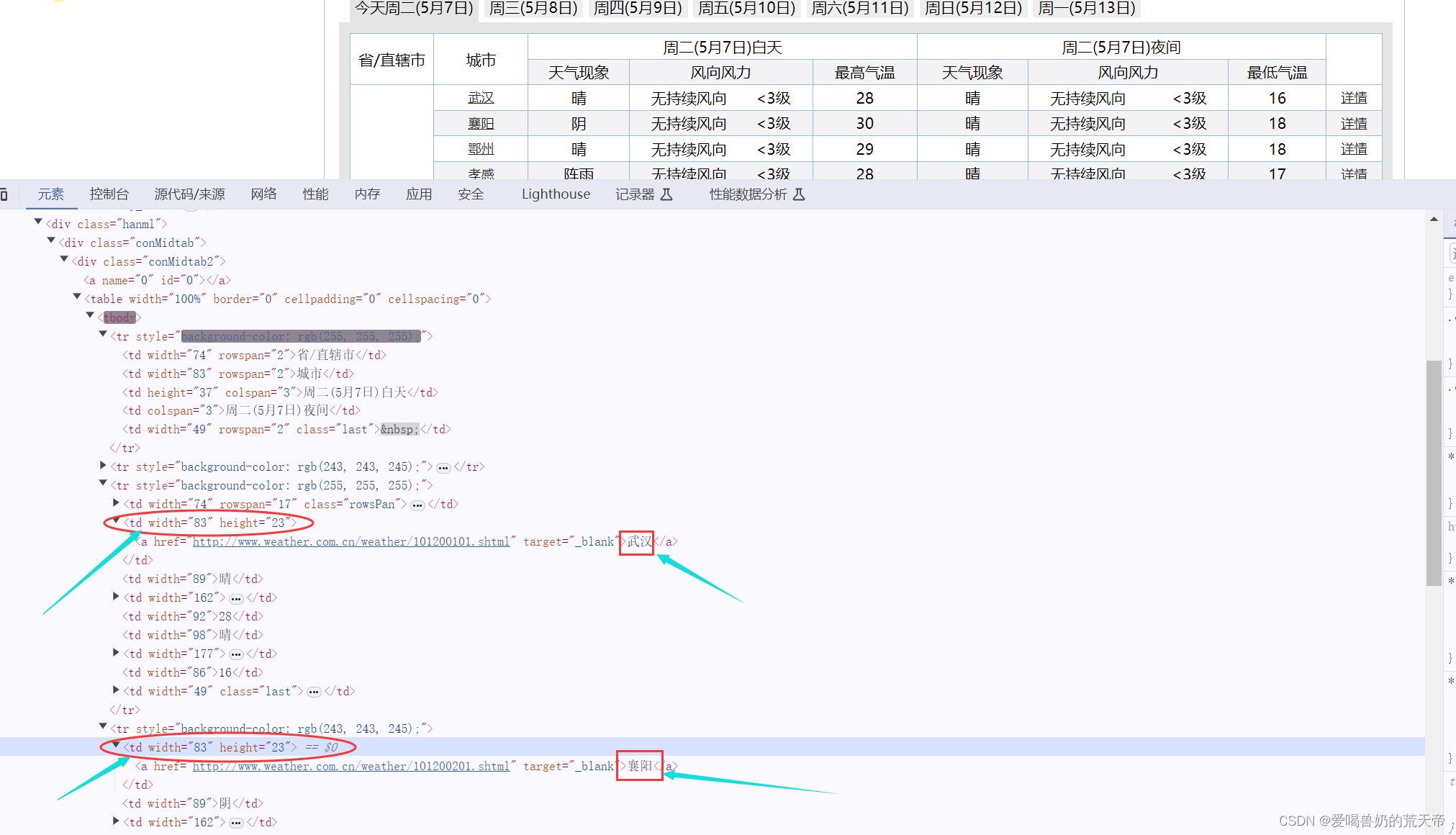
想要实现这种效果,我们就要用到一个函数enumerate,这个函数可以将下标和下标对应的值给显示出来。
# 解析数据
def parse_html(html):
# 创建对象
soup = BeautifulSoup(html, 'lxml')
conMidtab = soup.find('div', class_="conMidtab")
tables = conMidtab.find_all('table')
# print(tables)
for table in tables:
trs = table.find_all('tr')[2:]
# print(trs)
for index, tr in enumerate(trs):
tds = tr.find_all('td')
# print(tds)
if index == 0: # 第一个城市取第二个td标签
city = list(tds[1].stripped_strings)[0] # 城市
else: # 其余的取第一个td标签
city = list(tds[0].stripped_strings)[0] # 城市
temp = tds[-2].string # 最低气温
print(city, temp)

更换url查看数据信息
在主函数里面去更换url,然后查看打印的数据信息是否正确。运行后发现前面的都是正确的,直到更换到港澳台1地区时就出现了问题。
# 主函数
def main():
# url = 'http://www.weather.com.cn/textFC/hz.shtml' # 华中地区
# url = 'http://www.weather.com.cn/textFC/hb.shtml' # 华北地区
url = 'http://www.weather.com.cn/textFC/gat.shtml' # 港澳台地区
html = get_html(url)
parse_html(html)
main()
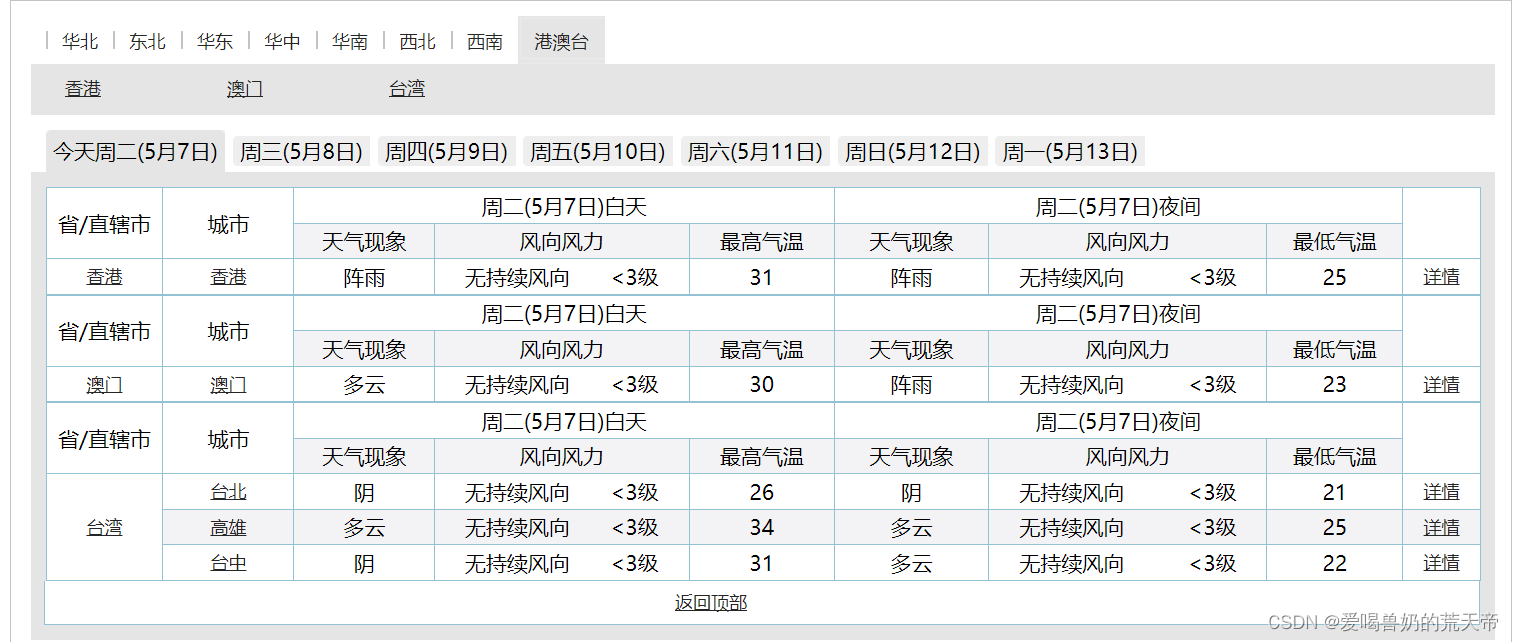
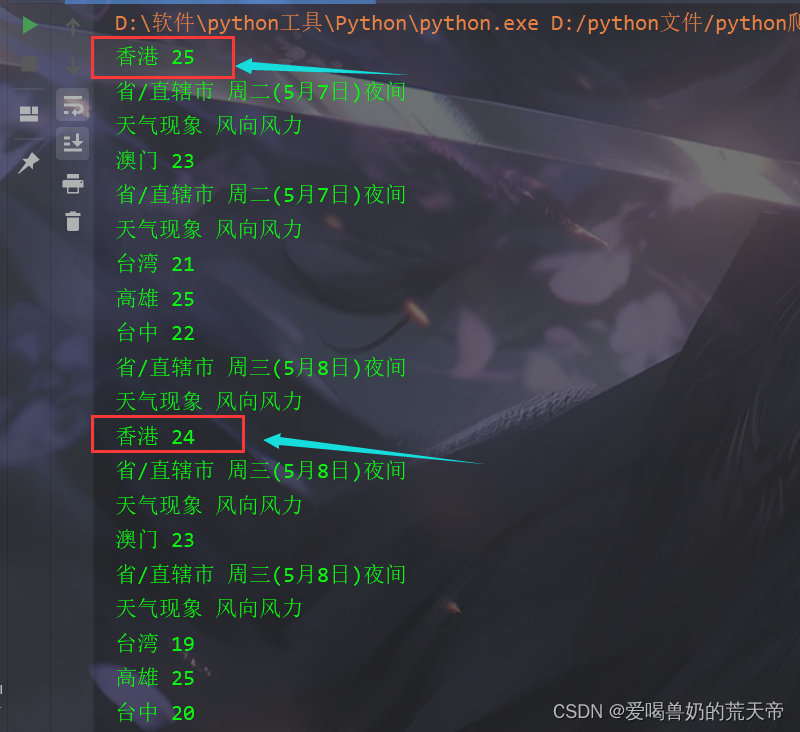
我们发现,我们无法在元素中发现问题,那么我们现在就应该查看一下网页源代码。
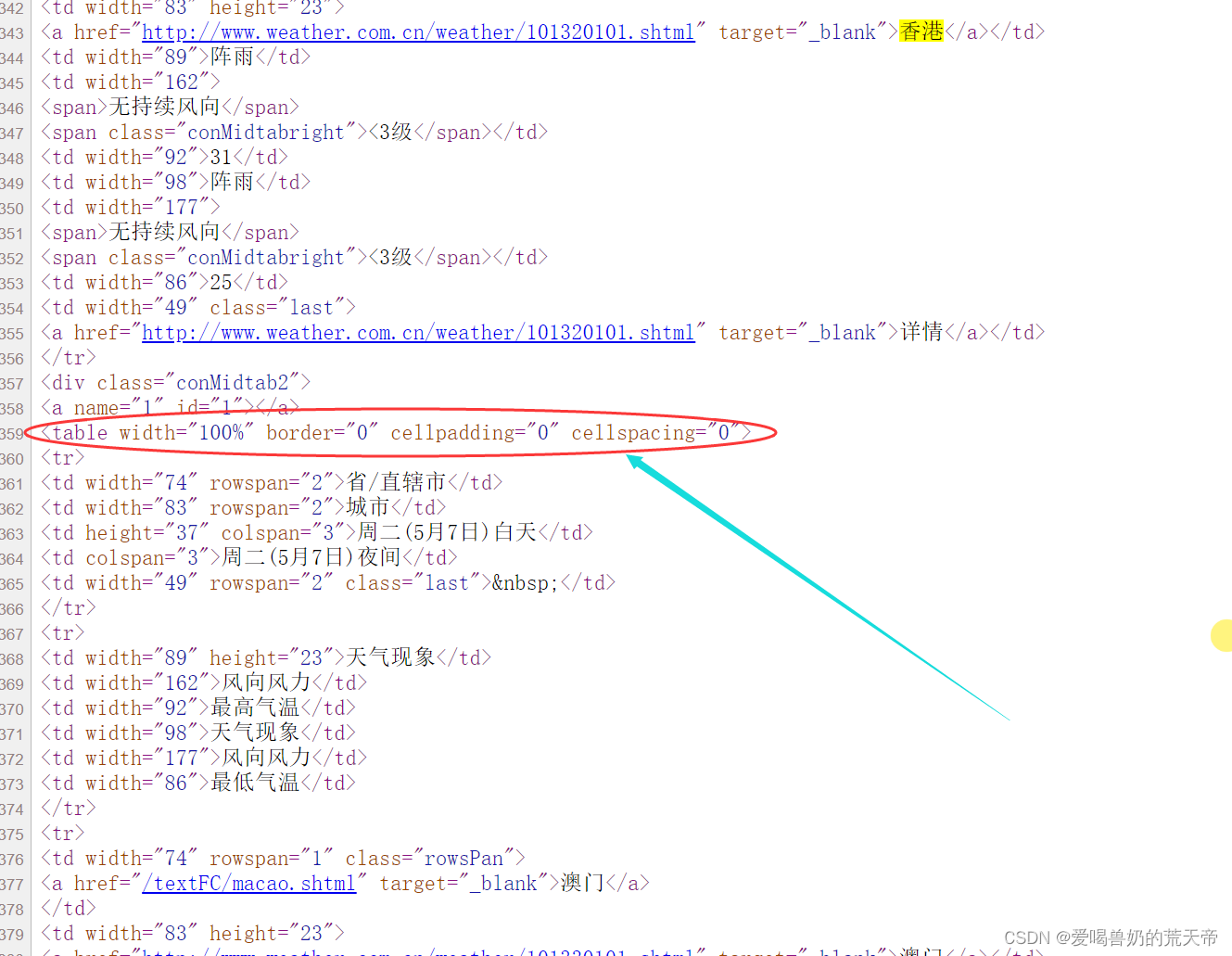
查看网页源代码之后可以发现,他所在的table标签是没有结束标签的,后面的城市的table标签也没有结束标签,这也就导致了数据混乱。
想要解决这个问题,就需要更换一下解析器。上面在提到BeautifulSoup4时的解析器,我们发现html5lib这个解析器拥有最好的容错性。

下载:pip install html5lib
# 解析数据
def parse_html(html):
# 创建对象
soup = BeautifulSoup(html, 'html5lib') # 将lxml换成html5lib
conMidtab = soup.find('div', class_="conMidtab")
tables = conMidtab.find_all('table')
# print(tables)
for table in tables:
trs = table.find_all('tr')[2:]
# print(trs)
for index, tr in enumerate(trs):
tds = tr.find_all('td')
# print(tds)
if index == 0: # 第一个城市取第二个td标签
city = list(tds[1].stripped_strings)[0] # 城市
else: # 其余的取第一个td标签
city = list(tds[0].stripped_strings)[0] # 城市
temp = tds[-2].string # 最低气温
print(city, temp)
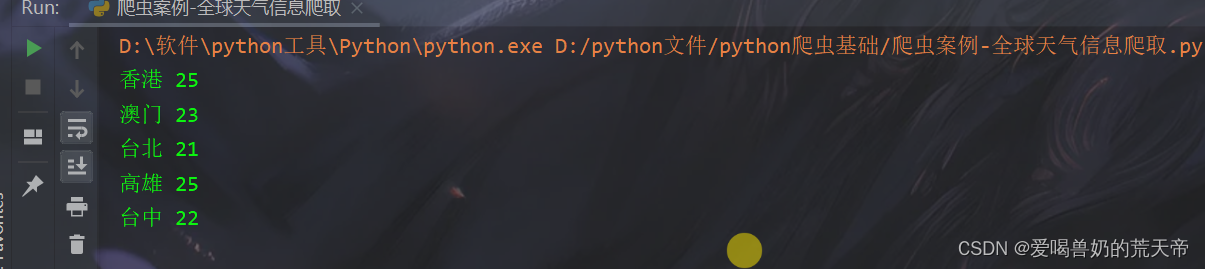
页面切换
要实现页面切换首先我们要观察一下不同页面的url
华北:http://www.weather.com.cn/textFC/hb.shtml
东北:http://www.weather.com.cn/textFC/db.shtml
华南:http://www.weather.com.cn/textFC/hn.shtml
华中:http://www.weather.com.cn/textFC/hz.shtml
港澳台:http://www.weather.com.cn/textFC/gat.shtml
我们发现,这些url的不同之处就在于后面的字母的不同,而这些字母又恰好是地区的首字母,那么我们只需要将这些地区的首字母存入到一个列表当中,循环之后就可以实现页面的切换。
# 主函数
def main():
district = ['hb', 'db', 'hd', 'hz', 'hn', 'xb', 'xn', 'gat']
# url = 'http://www.weather.com.cn/textFC/hz.shtml'
# url = 'http://www.weather.com.cn/textFC/hb.shtml'
for dist in district:
url = f'http://www.weather.com.cn/textFC/{dist}.shtml'
html = get_html(url)
parse_html(html)
main()
数据保存
定义一个全局变量的列表list_data,在解析数据的第二层循环中定义一个字典,将城市和最低气温添加到字典中去,最后将字典添加到list_data列表中。
# 保存数据
def save_data():
with open('全国天气.csv', 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.DictWriter(f, fieldnames=('城市', '最低气温'))
writer.writeheader()
writer.writerows(list_data)
四、完整代码
import requests
from bs4 import BeautifulSoup
import csv
list_data = []
# 获取网页源码
def get_html(url):
html = requests.get(url)
html.encoding = 'utf-8'
# print(html.text)
return html.text
# 解析数据
def parse_html(html):
# 创建对象
soup = BeautifulSoup(html, 'html5lib') # 将lxml换成html5lib
conMidtab = soup.find('div', class_="conMidtab")
tables = conMidtab.find_all('table')
# print(tables)
for table in tables:
trs = table.find_all('tr')[2:]
# print(trs)
for index, tr in enumerate(trs):
dic = {}
tds = tr.find_all('td')
# print(tds)
if index == 0: # 第一个城市取第二个td标签
city = list(tds[1].stripped_strings)[0] # 城市
else: # 其余的取第一个td标签
city = list(tds[0].stripped_strings)[0] # 城市
dic['城市'] = city
temp = tds[-2].string # 最低气温
dic['最低气温'] = temp
list_data.append(dic)
# 保存数据
def save_data():
with open('全国天气.csv', 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.DictWriter(f, fieldnames=('城市', '最低气温'))
writer.writeheader()
writer.writerows(list_data)
# 主函数
def main():
district = ['hb', 'db', 'hd', 'hz', 'hn', 'xb', 'xn', 'gat']
# url = 'http://www.weather.com.cn/textFC/hz.shtml'
# url = 'http://www.weather.com.cn/textFC/hb.shtml'
for dist in district:
url = f'http://www.weather.com.cn/textFC/{dist}.shtml'
html = get_html(url)
parse_html(html)
save_data() # 数据保存
main()