一、model.train(),model.eval()作用?
model.train() 和 model.eval() 是 PyTorch 中的两个方法,用于设置模型的训练模式和评估模式。
model.train() 方法将模型设置为训练模式。在训练模式下,模型会启用 dropout 和 batch normalization 等正则化方法,并且可以计算梯度以进行参数更新,同时还可以追踪梯度计算的图。训练时,均值、方差分别是该批次内数据相应维度的均值与方差。
model.eval() 方法将模型设置为评估模式。在评估模式下,模型会禁用 dropout 和 batch normalization 等正则化方法,这样可以保证每次评估的结果是确定的。评估模式下的模型通常用于模型的测试、验证或推理阶段。推理时,均值、方差是基于所有批次的期望计算所得。
区分训练模式和评估模式的目的在于保证模型在不同阶段的行为一致性。例如,在训练模式下,模型需要计算并追踪梯度以进行反向传播和参数更新;而在评估模式下,模型不需要计算梯度,只需要给出确定的预测结果。
二、model.train(),model.eval()对dropout产生的影响
使用model.train():有神经元被置零,且比例符合nn.Dropout(0.5)中的0.5设定
import torch
import torch.nn as nn
model = nn.Dropout(0.5)
model.train()
input = torch.rand([3, 4])
print("before dropout:",input)
output = model(input)
print("after dropout in train mode:",output)

使用model.eval():没有神经元置零,nn.Dropout(0.5)被关闭
import torch
import torch.nn as nn
model = nn.Dropout(0.5)
#model.train()
model.eval()
input = torch.rand([3, 4])
print("before dropout:",input)
output = model(input)
print("after dropout in train mode:",output)

不使用model.train()和model.eval():有神经元被置零,但是比例非常随机,不符合nn.Dropout(0.5)中的0.5设定
import torch
import torch.nn as nn
model = nn.Dropout(0.5)
#model.train()
#model.eval()
input = torch.rand([3, 4])
print("before dropout:",input)
output = model(input)
print("after dropout in train mode:",output)



三、model.train(),model.eval()对batch normalization产生的影响
使用model.eval():bn中的均值,方差,不发生改变
# 1.导入所需的库:
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# 2.定义数据集的转换方法。MNIST数据集是由28x28像素的手写数字组成的图像,将其转换为torch张量并进行标准化处理:
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# 3.下载MNIST数据集并进行转换:
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
# 4.创建数据加载器:
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=0)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,
shuffle=False, num_workers=0)
# 5.现在你可以使用trainloader和testloader来获取训练集和测试集的批次数据了。例如,可以使用迭代器遍历数据集中的批次:
#dataiter = iter(trainloader)
#images, labels = dataiter.next()
# 上述代码将返回一个批次的图像和对应的标签。可以使用images和labels来进行模型的训练和评估。
# 这就是使用torch库自带的MNIST数据集的基本流程。根据需要,你还可以添加其他的数据处理和增强步骤。
# 定义模型
class Model(nn.Module):
def __init__(self, hidden_num=32, out_num=10):
super().__init__()
self.fc1 = nn.Linear(28*28, hidden_num)
self.bn = nn.BatchNorm1d(hidden_num)
self.fc2 = nn.Linear(hidden_num, out_num)
self.softmax = nn.Softmax()
def forward(self, inputs, **kwargs):
x = inputs.flatten(1)
x = self.fc1(x)
print("========= bn之前存的数据: =========")
print(self.bn.running_mean, self.bn.running_var)
print()
print("========= 当前 Batch 的数据: =========")
x_mean = torch.mean(x,0)
x_variance = torch.mean((x - x_mean)*(x - x_mean),0)
print(x_mean, x_variance)
print()
print("========= torch官方计算之后的bn新数据: =========")
x = self.bn(x)
print(self.bn.running_mean, self.bn.running_var)
print()
# x = self.dropout(x)
x = self.fc2(x)
x = self.softmax(x)
return x
torch.manual_seed(1)
model = Model()
#model.train()
model.eval()
for img, label in trainloader:
label = nn.functional.one_hot(label.flatten(), 10)
out = model(img)
break

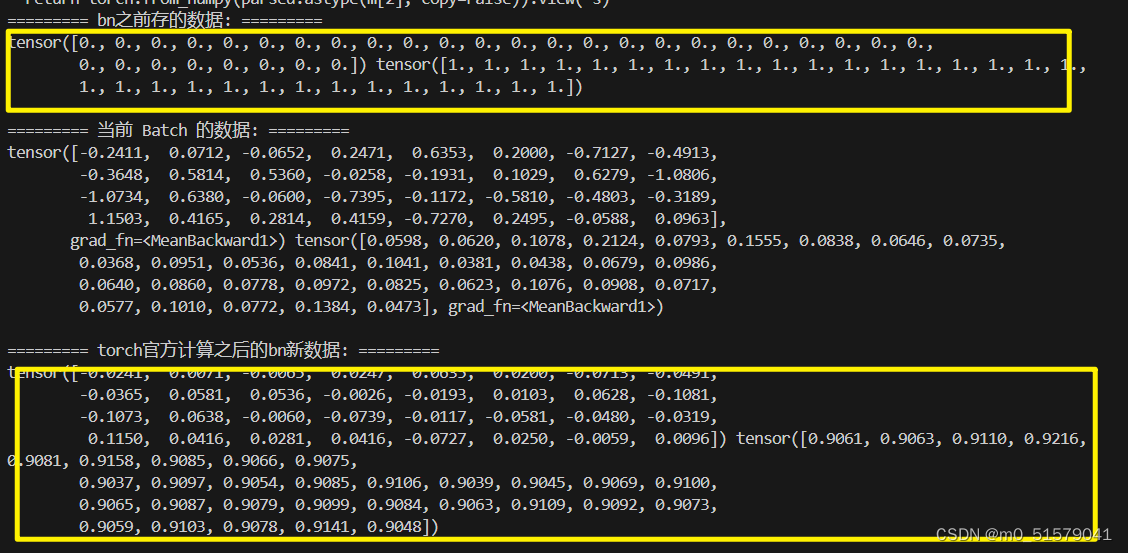
使用model.train():bn中的均值,方差,通过滑动平均地方式发生改变,
torch.manual_seed(1)
model = Model()
model.train()
#model.eval()
for img, label in trainloader:
label = nn.functional.one_hot(label.flatten(), 10)
out = model(img)
break
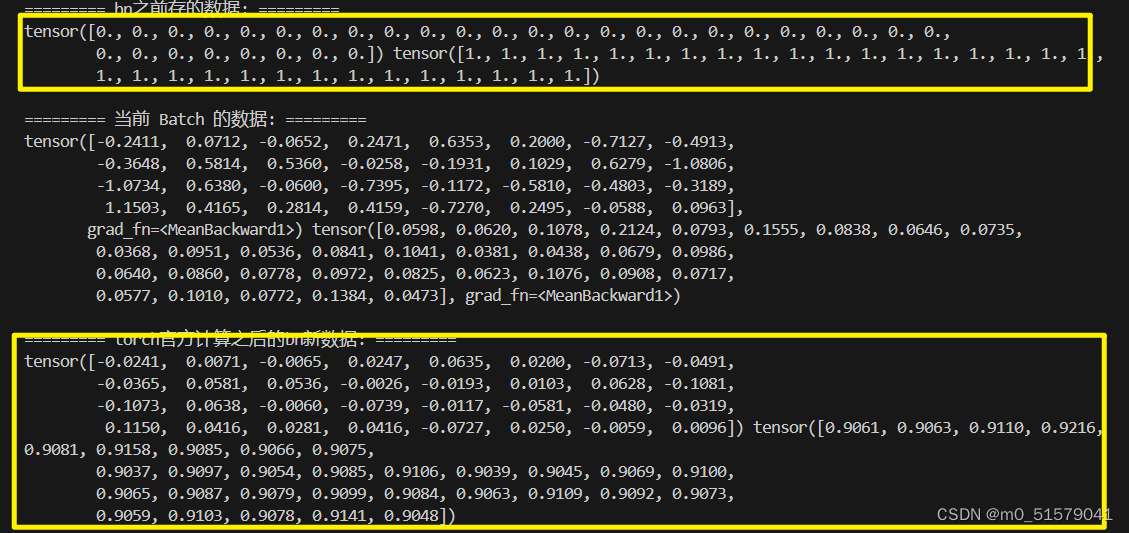
不使用model.train()和model.eval():默认bn中的均值,方差,通过滑动平均地方式发生改变,