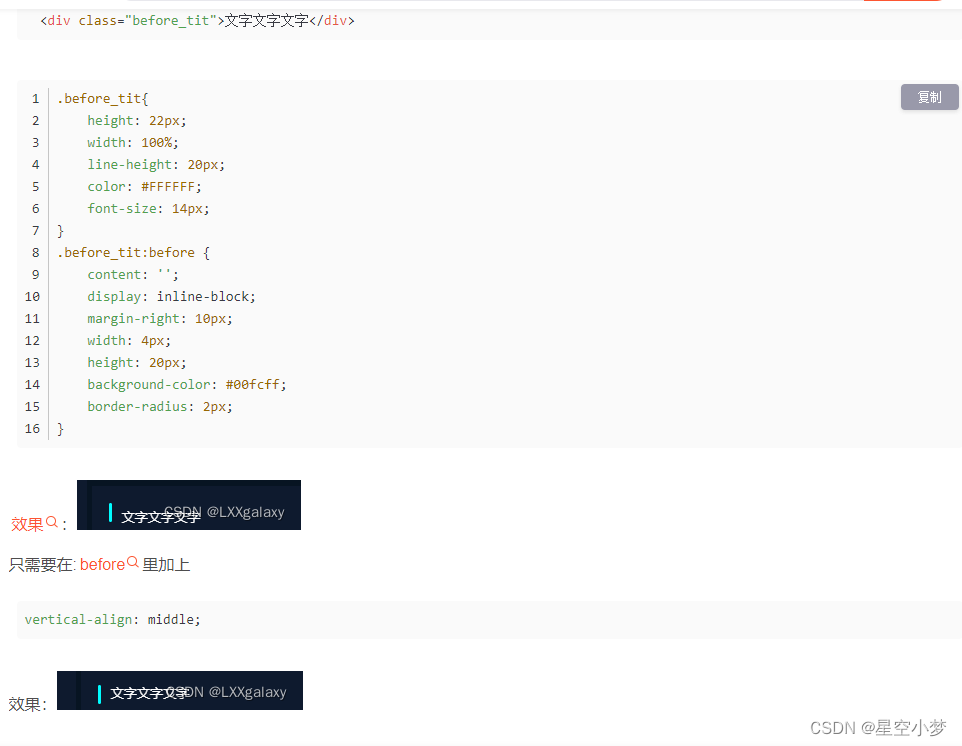
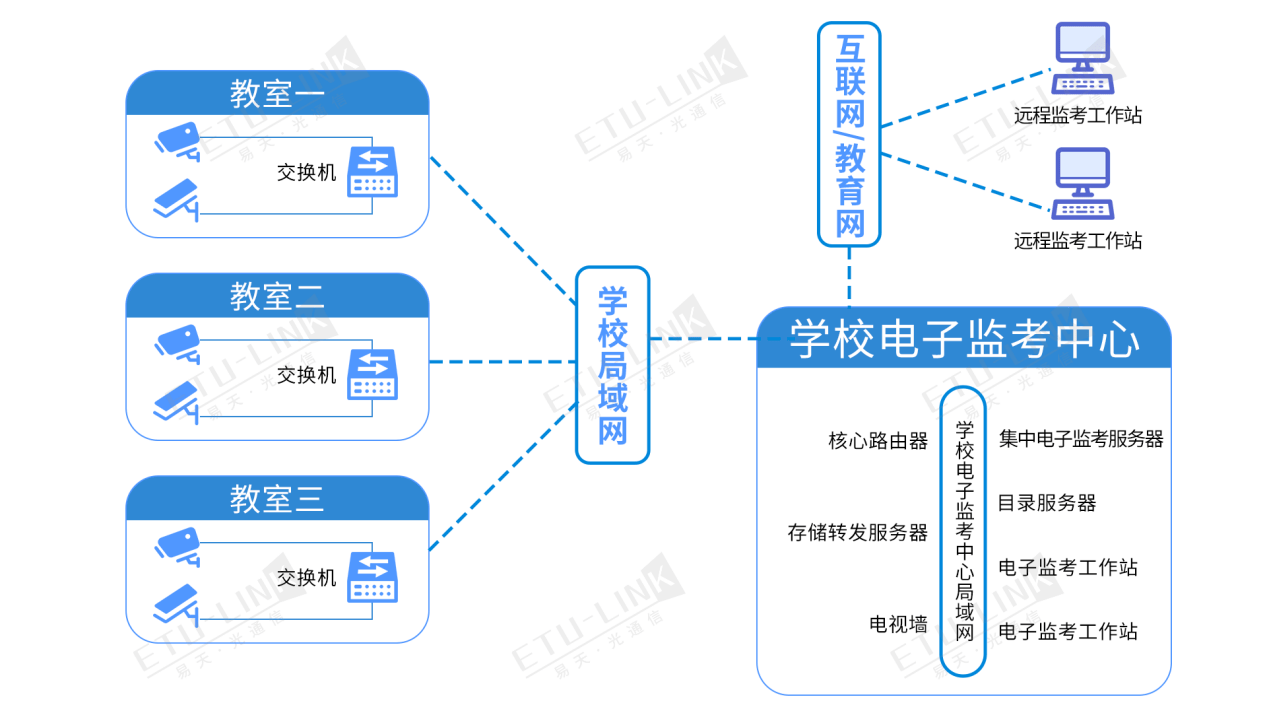
一、简介
-
目标是在不改变的Dataframe语义的情况下支持可扩展的dataframe操作。
-
什么是机会主义评价?Opportunistic Evaluation?
-
Exploratory data analysis(EDA):总结、理解并从数据集中获取价值的过程。
-
MPI:MPI是高性能计算常用的实现方式,它的全名叫做Message Passing Interface。顾名思义,它是一个实现了消息传递接口的库。并行计算之MPI篇 · XTAO Achelous
-
OpenMP:OpenMP(Open Multi-Processing)是一套支持跨平台共享内存方式的多线程并发的编程API,使用C,C++和Fortran语言,可以在大多数的处理器体系和操作系统中运行,包括Solaris, AIX, HP-UX, GNU/Linux, Mac OS X, 和Microsoft Windows。包括一套编译器指令、库和一些能够影响运行行为的环境变量。https://zh.m.wikipedia.org/zh-hans/OpenMP
-
lazy执行和eager执行的区别:lazy执行可以根据完整的数据流图进行优化,但eager执行对于数据科学家交互式执行的体验更好。lazy执行的框架Spark、Dask,eager执行的框架pandas等,但这样的框架通常无法做分布式计算(Modin就是为了解决这个问题)。
-
dataframe用户和可扩展数据工具例如mysql用户的行为差距,会影响到数据框架系统的性能。dataframe用户通常会用一种增量、迭代和交互式的方式构建查询。这本身就带来了关系型数据库所不具备的多种挑战,特别是围绕查询规划和查询优化。
-
Modin架构

-
Modin提出了一个机会主义评估Opportunistic evaluation的概念,利用用户的思考时间在dataframe语句上去的进展。机会主义评估利用用户的思考时间,去保证CPU在努力实现结果,以节省数据科学家的时间。这样的执行方式比lazy执行快8倍。这里的结果表明,传统的计算范式在交互式环境中并不是最优的,而机会主义评估是实现高效交互式数据科学的一个良好开端。
二、Dataframe系统的需求
-
在交互式工作流中,dataframe用户经常花费大量时间来检查结果,并思考接下来应该做什么。
-
在检查结果时,通常会检查前缀(前k行)和后缀(最后k行),以确保一系列的操作符按照预期执行。我们在第2.5节中探讨数据框架前缀和后缀计算的独特挑战。
-
可组合性是数据框架最重要的特征之一,因为它允许用户逐步测试并分块建立更大的工作流程。
-
data science lifecycle:

-
dataframe的以下特点使之成为数据探索的一个有吸引力的选择:
-
一个直观的数据模型,包含了对列和行的隐性排序,并对称地处理它们。
-
一种查询语言,连接各种数据分析模式,包括关系型(如过滤、连接)、线性代数(如转置)和电子表格型(如透视)运算符。
-
一个递增的可组合的查询语法,鼓励简单表达式的简单和快速验证,以及它们的迭代细化和组合成复杂的查询;
-
以及在主机语言(如Python)中的本地嵌入,具有熟悉的命令式语义。
-
-
通过数据科学家的操作习惯我们可以了解到,dataframe的常见使用情况具有以下这些特点:
-
大多数操作后会立刻进行视觉检查(可视化)
-
每个操作都是在之前的结果基础上递增的
-
通过用户定义的函数进行点和批量更新
-
具有用于处理、准备和分析数据的各种操作
-
-
和SQL的all-or-nothing提交方式不一样,dataframe用户会以一种增量的、迭代和交互的方式构建查询。
-
不同的执行模式对比:
-
eager模式:每个statement一经发出就会被计算,在语句被完全计算前,程序控制权不会返回给用户。但用户不需要中间结果的情况下,还是会被迫等待。
-
lazy模式:控制权会马上返回给用户,只有当用户想要查询结果时系统才会触发计算。lazy模式会有更多的优化机会,但是只有在查询时才会触发计算会给用户带来负担,特别是调试时,直到最后的计算被触发时才能发现错误。
-
opportunistic query evaluation paradigm模式(新提出的机会主义评估模式):上面的两种模式都没有利用用户在步骤之间的思考时间。在机会主义评估中,系统会适时地开始执行,同时将控制权传回用户,并提供一个指向最终计算完成的dataframe的指针(一个future)。机会主义评估会导致许多在查询片段中进行共享和复用的新挑战,这些查询片段的计算已经再后台安排好了。
-
-
dataframe提供的最常见的反馈形式是表格视图,表格视图允许用户检查单个数据值,而且还传达了dataframe相关的结构信息,特别是排序有关的信息。为了让让用户更快地收到反馈,可以采用前缀计算/后缀计算/近似计算,系统在后台再采用机会主义评估进行整体计算。
-
增量查询为查询优化带来了更大的挑战。在增量计算中,优化可以从以下2个点出发考虑:
-
联合优化:用户的语句通常是建立在其他语句基础之上
-
物化:用户经常返回旧的语句来尝试新的探索路径
-
-
Multi-query Optimization(MQO):不管在什么模式(eager、lazy、opportunistic),统一时间都可能会有许多语句被调度执行。因此可以考虑使用MQO来进行优化,同时需要考虑到用户触发的前缀/后缀计算需要以更高优先级查询。具体的优化策略有以下:
-
共享输入,以共享scan结果。
-
物化中间结果,但物化中间结果可能造成整体计划不是最优选择。通过观察用户在多个会话过程中检查中间结果的可能性,可以对所有的查询子表达式进行加权联合优化。可以预测哪些中间结果可能会被频繁使用,预测算法应该考虑到几个因素:用户意图、过滤的工作流、操作路线。
-
智能物化,计算耗时且经常重复使用的中间dataframe应优先于计算快速的大型中间dataframe。
-
需要关注预测算法,预测算法通常要考虑用户意图、历史工作流和算子血缘。
-
由于dataframe可以和非dataframe算子交互,算法需要对此进行特别考虑。
-
图分析技术
-
-
三、Dataframe的理论基础
-
dataframe中的一个关键点是:它的列的domain可以从数据中事后诱导出来,而不是像关系模型一样需要预先声明。我们可以定义一个schema诱导函数 S : (Σ∗)m → Dom,来讲一个具有m个字符串的数组分配给Dom中的一个domain。
-
dataframe的定义:dataframe是一个元组(Amn, Rm, Cn, Dn),其中Amn是来自域 Σ∗的一个数组条目,Rm是来自Σ∗的行标签向量,Cn是来自Σ∗的列标签向量,Dn是来自Dom的n个域的向量,每列一个,每个域也可以不被指定。我们称Dn为dataframe的schema。如果Dn中的任何一个条目没有被指定,那么该域可以通过将S(·)应用于Amn的相应列以获得其domain域i,然后通过p(·)获得其值来推导。
-
在dataframe中,行和列在很多方面是对称的。它们都可以被明确地引用,使用数字索引或是名称索引。列有schema,而行没有。
-
当schema Dn对于所有的n个列都有相同的domain时,我们称之为同质dataframe(homogeneous dataframe)。作为一个特例,如果同质dataframe具有一个类似flot或是int的domain和类似+ x等满足field代数定义的操作符,我们称之为矩阵dataframe(matrix dataframe)。因为它具有矩阵所需的代数特性,并且可以通过解析值和忽略lable来参与线性代数操作。矩阵dataframe在机器学习pipeline中常用。
-
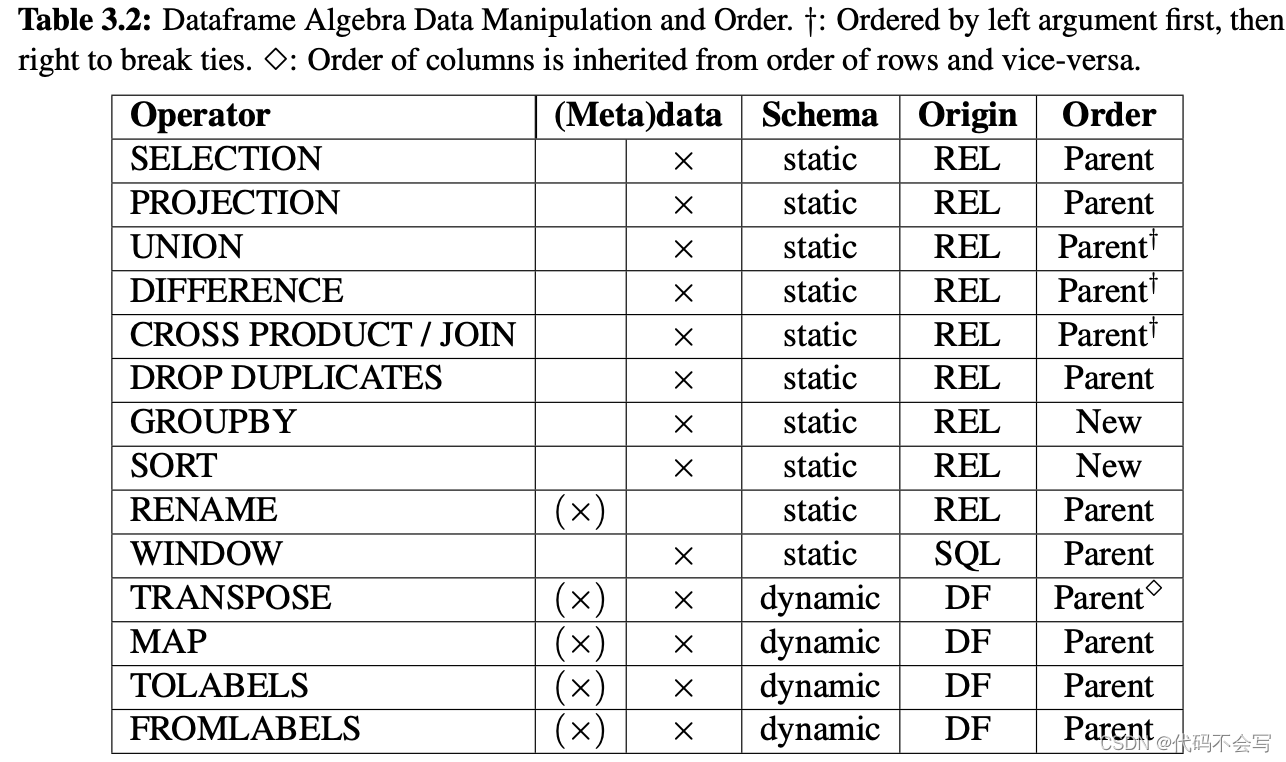
dataframe代数中包括了
-
扩展关系代数运算符的有序模拟,从Selection到Rename
-
一个不属于扩展关系代数,但是在许多数据库系统中能找到的运算符:Window
-
Window函数在RDBMS中很常用。关键区别在于,在SQL中,许多窗口函数例如LAG、LEAD需要一个额外的ORDER BY来定义。而在dataframe代数中,dataframe的固有有序性可以使得order by是可选的。
-
-
一个在数据库系统中不允许独立使用的运算符:Groupby
-
四个新的运算符:Transpose(转置)、Map、ToLabels、FromLabels
-
Transpose转置:不同的语言在转制后推断schema的方式是不一样的。例如R,转置后都为string,因此无法连续转置还原,而Python转制后转为Object,类型信息运行时内置,因此可以2次转置后推导还原schema。转置算子对于同质dataframe的矩阵操作、数据清理和演示都很有用。Modin通过Transpose,可以实现跨列计算,再次transpose回来后恢复原始的dataframe。
-
Map:接收一些函数f,并将它独立应用到每一行数据中,返回一个固定的单行输出。map对于数据清理和特征工程都很有用。
-
ToLabels:将数据转换为元数据。
-
FromLabels:创建一个新的dataframe,是ToLables的对立操作符。
-
-
-
pandas中的组合函数特例:
-
agg['f1', 'f2', ...]函数:为每一列单独计算聚合函数f1, f2, ...。得到的结果dataframe对于每个聚合函数具有一行结果,即第一行对应f1聚合函数,第二行对于f2聚合函数,以此类推。这个函数可以用每一个聚合函数一个Groupby操作符来重写,以产生对应于聚合的单独行,再加一个UNION函数。另一种重写方法是Transpose + 每列一个map函数去计算所有的聚合 + Transpose。
-
target.reindex_like(reference):支持改变一个给定的dataframe,通过对它的行列重排序来匹配另外一个dataframe(reference),即对齐。另外一种实现方法是首先对两个dataframe执行FromLabels,允许lable成为数据的一部分,然后使用Inner Join做行label的join,再使用一个map来将dataframe的属性投影出来,最后,tolabels将标签从数据中移出来。
-
pivot:将一列数据提升到列labels中,并使用这些新的labels创建一个新的dataframe。另一组组合的实现方法是 groupby + map + tolabels + transpose
-
-
支持dataframe数据模型和代数带来了一系列新的挑战:
-
灵活的schema和动态的类型:dataframe需要schema来解释数据。当某些列没有指定类型的情况下,我们需要对类型进行推导和解析,这个代价是很昂贵的。注意,我们在解析一列中的任何单元格值之前,必须先知道该列的类型。同时以数据库视角来看,dataframe比起table更像view,编程语言不存储数据而是从外部存储中读取文件,但外部存储通常都是无类型的。
-
减轻灵活shcema和动态类型的成本对dataframe来说是一个巨大的挑战。
-
dataframe需要从外部存储加载文件/数据,但外部存储通常都是无类型的。
-
schema的可变性也带来了动态性的困扰,类似加列删列的DDL操作使用是非常频繁的。
-
-
排序和等价:当前dataframe系统,例如pandas,是直接按照用户定义的顺序对数据进行存储,没有实现独立的物理数据架构,物理独立性可能会带来新的优化机会。只要最终展示结果保留了用户所需的顺序语义,就无须让中间的产品或是组件遵循顺序的约定。(即以元数据保存有序信息,而不是物理组织)。为了进一步扩展物理数据的独立性,我们可以采用数据库业界的其他代表技术,对dataframe进行优化,包括行列混合存储,以及其他来自于科学计算、数组数据库、或是电子表格等等其他优化技术。dataframe经常使用有序的访问,针对这个场景近期支持了位置索引,允许在O(log n)内支持有序访问。
-
-
我们从3个角度来考虑高效schema推导的挑战:rewriting, materialization, and query processing. (重写、物化和查询处理)
-
Schema Induction的重写规则:由于灵活的schema,dataframe支持添加和删除列作为第一类操作,在任何时候可能都会有几个未知类型的列。但我们对于dataframe的操作需要知道类型信息:例如,避免在类型不匹配的列上join,或是在字符串列上使用数字谓词。schema推导函数S,可以用来进行推导必要的类型信息,但是它代价昂贵,在为查询进行建模时必须要考虑到成本。
-
具体来说,如果不对某些列进行操作,那么通过S来推断类型可以推迟到第一次操作它们的时候,如果这些列在访问前就被丢弃,那么则可以完全省略了。
-
在一些只涉及到数据移动的操作,例如shuffle操作中,schema推导可以完全省略。
-
虽然省略或是推迟schema推导是可行的,但是元数据也是数据的一部分,用户在运行时也可能会进行类型检查,需要考虑到这一点。
-
-
复用类型信息(物化):在一个程序中的多个语句之间复用dataframe是非常常见的。在dataframe缺少显式类型的情况下,将schema induction和解析的结果进行物化--在程序调用中(内部状态),以及在存储的多个调用中,都会非常有帮助。但物化灵活类型schema又带来了一系列的新挑战。即物化的选择:
-
缓存schema induction函数S的结果(针对一列或是多列)
-
缓存解析函数的结果(原则上来说,粒度可以小到单元格级别)
-
对于复杂的多步骤dataframe表达式,我们也可以选择在引入了动态类型列的pipeline中的多个opeartor中执行这些决策。
-
综上,优化的搜索空间是非常巨大的。此外,查询负载也和传统的物化视图不一致,Python语言比SQL更难静态分析。
-
-
查询计划中的pipeline schema induction:对列执行schema induction和解析函数是不可避免的,我们也许可以通过尝试将其与其他无关的轻量化操作(如数据移动或是序列化/反序列化)融合来以最小开销低消成本,这个研究方向是可行的。例如,在应用于字符串的map函数中执行schema induction,而不是先S再map。
-
-
Modin将数据框架数据模型和代数视为一等公民,而不是实现分布式处理的手段,解决了pandas和R等系统中dataframe处理的挑战,同时也没有牺牲使dataframe如此流行的便利功能。
四、一个通用的Dataframe架构和设计
略,枚举了Dataframe的数据模型、代数层设计(API)、元数据管理等细节。
五、Modin: Dataframe实现参考
-
Modin,一个并行的数据框架系统,可作为pandas的替代品。
-
为了构建Modin,我们必须解决双重问题,即在确保在宽容数据模型上保证dataframe算子丰富度的可扩展性的同时,向用户提供清晰、一致和正确的语义。
-
Modin实现的两个关键方面:
-
基于规则的分解:和关系操作不一样,dataframe操作可以在行、列甚至单元格的粒度上进行。为了沿着行、列或是单元格并行地执行dataframe操作,我们必须开发一套分解规则,使我们能够灵活地将原始dataframe的操作重写为dataframe上的垂直、水平或是基于block的分区的类似计算。和关系操作符的交换律不一样,这些分解必须保留并维持顺序。我们必须了解到,列的类型可能以不可预测的方式在分解的dataframe中发生变化,这就需要分解过程中的协调,代价昂贵。此外,灵活的数据模型模糊了数据和元数据的边界,并支持在同一时间查询并操作数据和元数据。最后,我们需要为一组核心的dataframe代数算子提炼出这些分解规则,所有的操作符都可以使用这一组核心算子重写。无论如何,将pandas这样的系统中的600多个函数提炼成一个小的核心运算集仍然是一个巨大的工程挑战。
-
元数据独立:Modin努力追求元数据的独立,即在逻辑层面捕获元数据,而元数据的物理表示和逻辑是解耦的。pandas在每次操作结束后都会急切确定每一列的类型,这是一个耗时的阻塞步骤,会严重降低大dataframe的操作速度。此外,pandas经常在用户无意向的情况下强制转换类型,比如,在混合了整数和浮点数的列中将整数转换为浮点数。相反地,Modin的目标是为dataframe系统开一个独立的类型系统,支持列中的混合类型和未指定类型,基于此我们可以将类型推断延迟到需要的时候。另外一个重要的设计是以行和列的逻辑顺序来物理存储数据,我们需要支持顺序独立性,物理顺序可以根据需求和逻辑顺序匹配,但只在必要的时候。否则我们需要在每次操作后协调存储的顺序,使之匹配。总的来说,为海量dataframe算子保证正确的类型和有序性语义是一个很大的挑战。
-
-
Modin core operator:我们的核心操作符包括适应数据框架上下文的关系操作符(例如,有序版本的select、project和join),用于查询和操作元数据的操作符(例如,将数据转换为标签),以及能够应用系统或用户定义函数的低级操作符(例如,map和reduce)。为了让这些算子能够大规模并行执行,Modin定义了灵活的等价规则,将dataframe上的每个算子表达为分解或是分割的算子,如果需要的话,还可以使用合适的有序连接算子来重新组装整个dataframe。
-
Modin内部使用这些分解规则来重写计算,在必要时沿行、列、单元或单元块采用灵活的分区方案。我们确定了两类优化机会,通过智能地应用分解规则来显著提高系统性能。
-
我们还提出了一个在莫丁中实现的数据框架类型系统,并描述了类型化是如何在核心操作者之间继承的,并开发了支持基于label和order的访问的技术,而不要求物理顺序与逻辑顺序相匹配。总的来说,相对于pandas和Koalas,Modin在一系列的工作负载上提供了高达100倍的速度,包括连接、类型推理和面向行的UDFs。
-
Modin可插拔交互模式
-
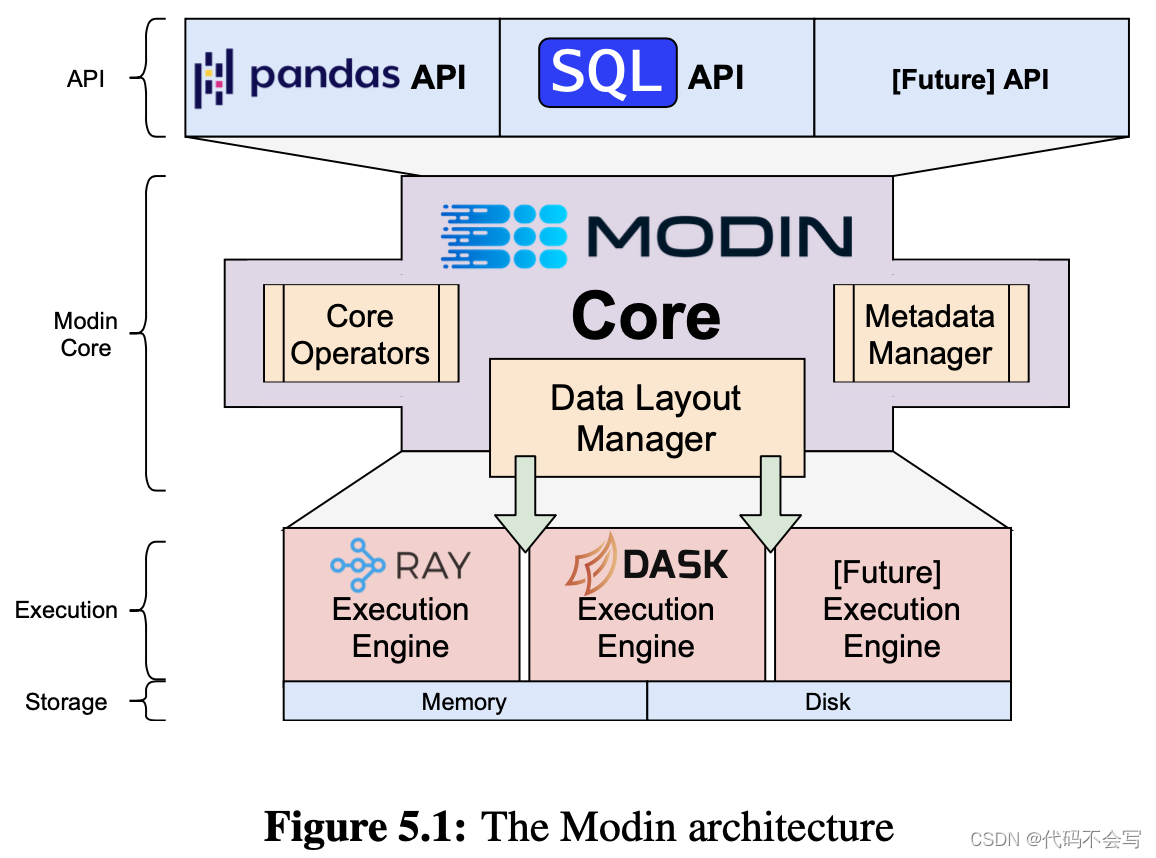
架构
-
Modin API:模块化,支持多种交互方式例如pandas、SQL、Spark Dataframe API,以支持数据科学家的使用习惯。
-
Modin Core:架构中的核心部分,包含一组core operator,决定最佳的数据布局或分区来并行化core oeprator和高效地管理元数据。
-
Core operators and data layout manager
-
Metadata manager
-
data types
-
column and row labels
-
logical order
-
-
-
Modin Operators and Optimization:core operator的设计要点
-
opeartor抽象需要功能强大且具有扩展性:从关系算子、元数据算子、low-level算子三个层次去抽象
-
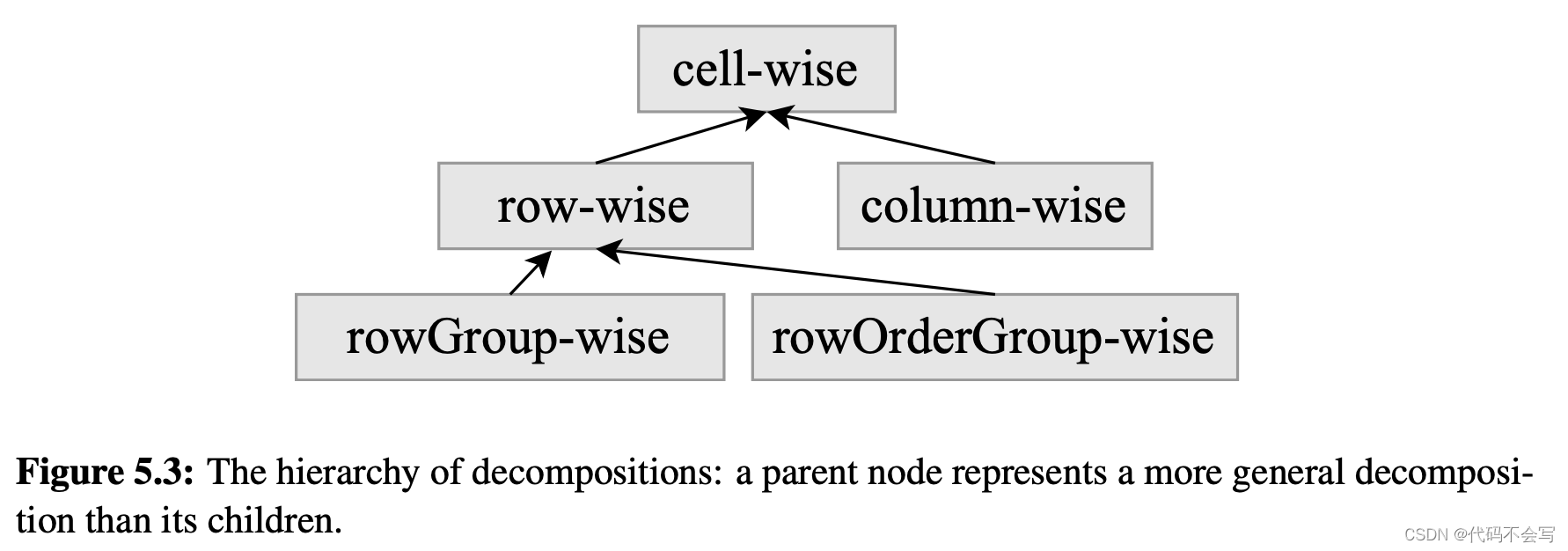
分解dataframe的语义:operator需要分解规则以并行化计算(5种):cell-wise, row-wise, column-wise,rowGroup-wise(按照自然序分组), rowOrderGroup-wise(按照groupby key对分组排序,用于sort算子)
-
operator的分解规则:这里只讨论最细粒度的分解规则,因为只要parent rule符合要求,child rule也是可以符合要求的
-
low-level operator:包括map,explode,groupby,reduce
-
map:cell-wise
-
explode:row-wise或是column-wise,取决于函数性质
-
groupby:rowGroup-wise
-
reduce:column-wise
-
-
metadata operator:infer_types,filter_by_types,to_labels,from_labels,transpose
-
infer_types、filter_by_types:column-wise
-
to_labels、from_labels:row-wise
-
transpose:cell-wise
-
-
relational operator:mask、filter、window、sort、join、rename、concat
-
mask、filter:对应关系算子中的project和select,区别在于mask和filter可以同时支持row、column轴的计算。即支持row-wise/ column-wise
-
window:row-wise/ column-wise
-
sort:rowOrderGroup-wise
-
join:rowGroup-wise
-
rename:没有分解rule
-
concat:row-wise
-
-
两个潜在的优化机会,通过智能地选择分解规则来实现:
-
eager data pipelining:使用分解规则来允许更多的数据pipeline。多个算子使用相同的拆解规则可以pipeline执行,因此对于有多种拆解规则的算子,可以动态的根据前后算子的规则进行选择,让pipeline计算最大化。
-
selective data exchange:我们也可以使用分解规则来在不同的算子之间将data exchange交换为pipeline。
-
-
-
-
meta管理:modin管理了多种类型的dataframe元数据:data type,row/ column labels,行列有序性的逻辑-物理映射。
-
data type:和关系型数据不一样,dataframe中的一列可能包含混合类型。Dataframe必须对一个包含多种类型数据的列提供准确和高效的类型推断。
-
类型延迟推断:为了效率。
-
层级类型系统:父节点是子节点的通用类型,服务于类型延迟推断会造成成的混合类型场景。
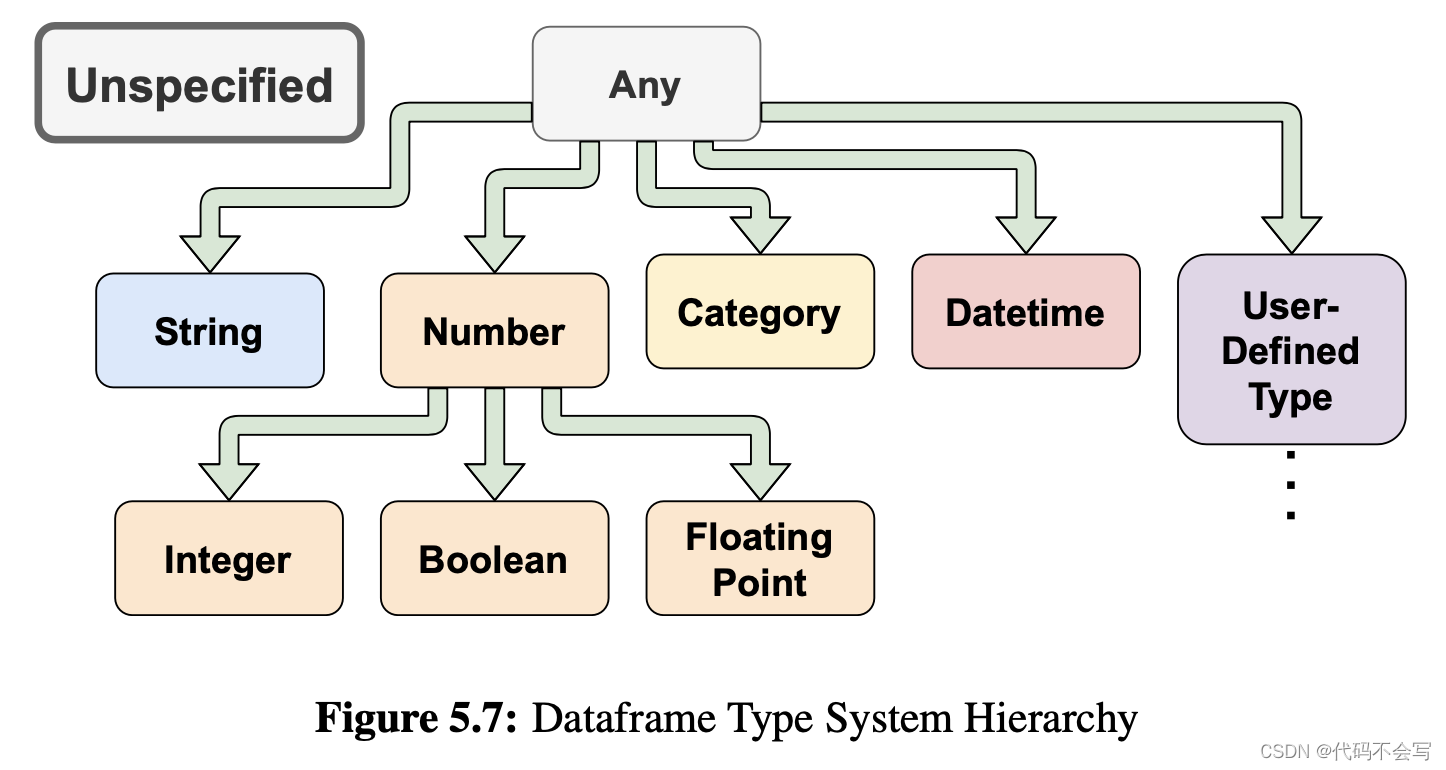
-
-
dataframe label和order管理
-
-
分区层
-
block分区:为了解决dataframe中行列交换的特性,Modin使用了一种block分区的模式,可以沿着columns和rows进行分区。
-
虚拟分区:block分区将行/列分开了,但是Modin中的许多算子需要访问整行/整列,因此Modin实现了虚拟分区。虚拟分区的实现动机是为了能更快地开发和实现新的算法,并降低实现新算法的门槛。开发人员无需理解分区机制和底层细节。
-
分区放置和shuffle:分区会优先被放在具有相同列分区的统一节点中,分区策略是可编程的。
-
-
执行和调度:执行层负责在一个或多个输入dataframe分区上序列化和执行代码。
-
在Ray上执行:
-
在Dask上执行:
-
-
六、评估
略
七、架构case study:机会主义评估
-
出发点:数据科学家的数据处理步骤是高度探索性和迭代式的。
-
机会主义评估保留了eager执行(关键部分被优先考虑场景),和lazy执行(非关键部分推迟计算)的好处。
-
我们从用户交互需求角度出发,将类似head、describe等算子归类为交互算子。
-
机会主义评估的激励场景和优化实例:为了更好地说明机会主义评估的优化潜力,我们提出了两个典型的数据分析场景,这些场景可以从思考时间内异步执行查询中受益,以最大限度地减少交互式延迟。虽然用户的程序保持不变,但我们说明了对执行计划的修改,以突出所做的转变。
-
基于交互的重排序:读取2个文件,并describe其中一个。我们可以对执行语句重排序,先加载需要交互的文件,把不需要交互的文件读取推迟到交互之后。
-
对部分结果进行优先排序:为了减少交互延迟,我们可以优先计算dataframe检查的那部分。这种方法本质是谓词下推的应用。
-
-
机会主义评估通过一个自定义的Jupyter Kernel来实现,它会检查拦截dataframe查询,以便透明地推迟、调度和优化它们。
-
Kernel接收到代码后,会解析代码的抽象语法树,构建一个自定义的中间表达,即operator DAG。operator DAG会传递给query optimizer来创建一个物理执行计划,这个物理执行计划会交给Python交互式shell进行执行。shell的返回值会被自定义的kernel检查,使用运行时的统计数据和部分结果来作为operator DAG的参数,供未来的查询使用,查询结果最终会返回给notebook server。
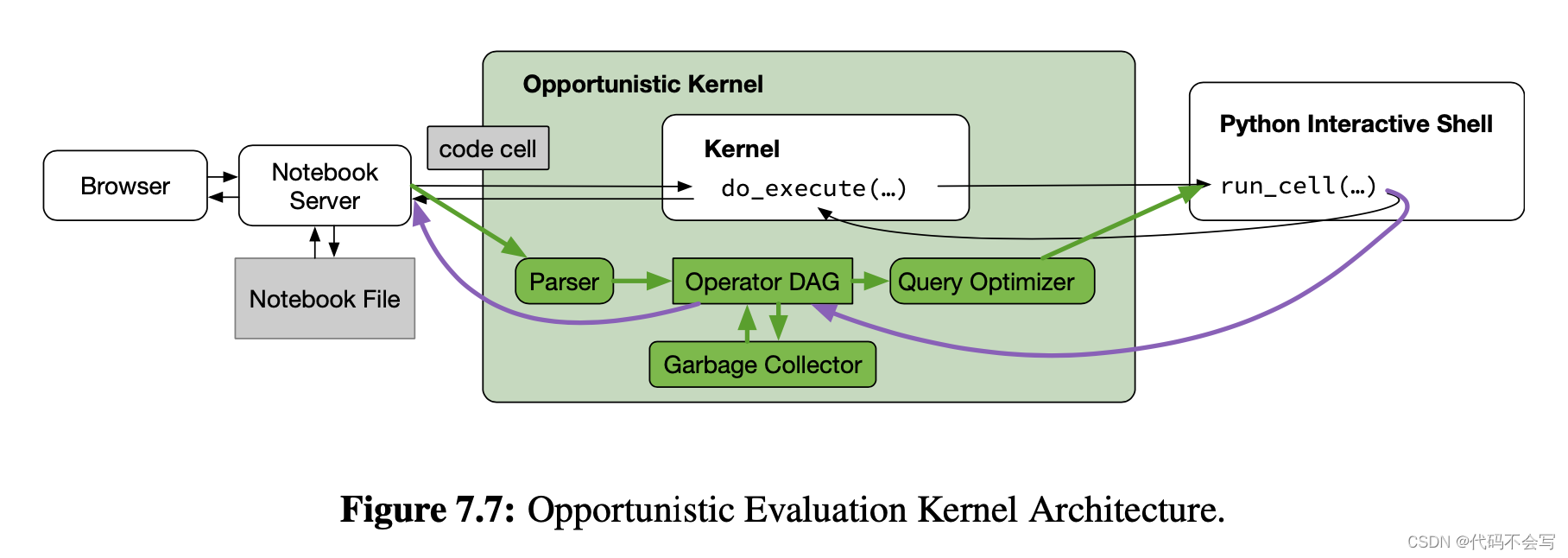
-
机会主义评估在query optimizer时对operator DAG进行优化的两个关键点:
-
关键路径识别:回溯DAG,识别依赖关系
-
识别重复计算
-
-
-
优化框架
-
优化当前交互:给定一个交互关键路径,我们可以对单个查询应用标准的数据库优化来优化交互延迟。例如head算子,可以用谓词下推优化。在机会主义评估中,优化交互式延迟的主要挑战是有效地抢占非关键操作者的执行能力。这种抢占确保我们避免因不相关的计算而增加交互式延迟。目前在pandas和其他数据框架库中的各种运算符的实现往往涉及到调用低级别的库,这些库在执行过程中不能被打断。在这种情况下,抢占非关键运算符的唯一方法是完全中止其执行,可能会浪费大量的进度。我们建议通过对dataframe进行分区来克服这一挑战,以便在最坏的情况下,抢占只导致当前分区的进度损失。
-
优化将来的交互平均思考时间
-
非关键算子调度:计算算子的交付成本,并影响调度策略,选择最高的调度,因为它会影响最多的下游调度。
-
缓存重用:缓存淘汰策略需要定制,根据重用概率、计算开销、内存使用量决定。
-
推测物化:需要识别用户行为,如果用户很有可能切换filter执行其他策略,那么我们可以直接缓存全量的基础结果集,避免下一次更换filter条件时需要重新计算。
-
-
用户行为预测:对用户行为的准确预测可以极大地提高机会主义评估的效果。具体来说,我们需要预测两种类型的用户行为:思考时间和未来互动。
-