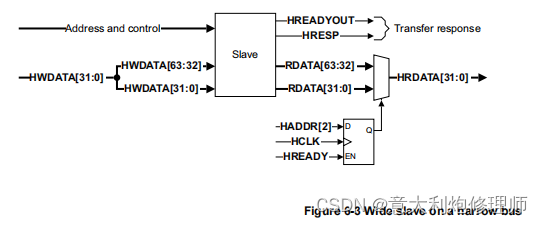
1.Motivation
本文希望比较online RL、offline RL、序列决策和BC等方法的泛化能力(对于不同的初始状态、transition functions、reward functions,现阶段offline RL训练的方式都是在同一个环境下的数据集进行训练)。实验发现offline的算法相较于online算法对新环境的适应能力更弱,同时增加offline dataset的多样性(不是数据量)将带来offline RL性能的提升
本文在两个场景中进行测试:① Procgen中未知的level;② WebShop中未见过的指令;本文发现所有的测试offline方法BCQ CQL IQL BCT DT的泛化性能均无法超过BC,因此对于offlineRL的泛化能力急需提升(但是此处没有对比过model-based offline RL算法的泛化能力)
(图1)展示了procgen和webshop的情况,前者具有相同的reward func但dynamic和初始状态不同;后者具有相同的dynamic,但reward和初始状态不同
图1:( a )四个Procgen游戏的训练和测试环境的样本截图。( b )来自webshop的人类演示的训练集和测试集的样本说明(项目描述)。红色和蓝色分别突出所需物品的类型和属性。

现有的离线学习数据集主要集中在单一环境中,所有轨迹都来自同一个环境(如玩阿塔利游戏或做人形散步),从而限制了泛化性的评估。相比之下,有大量的工作集中在评估和提高在线强化学习( RL )方法的泛化性。
2.摘要
尽管最近在离线学习方面取得了进展,但这些方法仍然在相同的环境下进行训练和测试。
在本文中:
(1)比较了在线强化学习( RL )、离线RL、序列建模和行为克隆等广泛使用的在线和离线学习方法的泛化能力。实验表明,离线学习算法在新环境下的表现要差于在线学习算法。
(2)介绍了离线学习中评估泛化性的第一个基准,从Procgen ( 2D视频游戏)和Webshop(电子商务网站)收集了不同规模和技能水平的数据集。该数据集包含有限数量的游戏级别或自然语言指令的轨迹,并且在测试时,智能体必须泛化到新的级别或指令。实验表明,现有的离线学习算法很难在训练和测试环境中匹配在线RL的性能。行为克隆是一个强大的基线,当在多个环境的数据上训练并在新的环境上测试时,性能优于最先进的离线RL和序列建模方法。
(3)作者们发现对于所有离线学习算法,增加数据的多样性,而不是增加数据的大小,可以提高在新环境下的性能。研究表明了当前离线学习算法的有限泛化性,强调了在该领域进行更多研究的必要性。
3.引言
Procgen基准测试程序由16个程序化生成的2D视频游戏组成,它们在视觉外观、布局、动态和奖励功能上各不相同。由于层次是程序性生成的,因此可以在该基准中评估泛化到新层次的情况。我们创建了许多Procgen数据集,旨在测试智能体解决新水平的能力,即具有相同的奖励函数,但不同的初始状态和动态。
Webshop是一个模拟的电子商务网站环境,拥有超过100万种现实世界的产品。给定描述所需产品的文本指令,代理需要导航多种类型的网页,并发出不同的动作来查找、定制和购买物品。我们通过使用提供的人类演示和生成次优轨迹创建了一些网上商店数据集,旨在测试智能体跟随新指令的能力,即具有相同的动态但不同的初始状态和奖励函数。图1显示了来自Procgen的一些样本观测和来自网上商店的轨迹。
4.实验设置
本文收集了以下数据集:
procgen expert dataset 1M;
procgen expert-suboptimal 1M;
procgen expert 10M;
procgen suboptimal 25M;
webshop human 452 trajectories;
webshop suboptimal 100 trajectories;
webshop suboptimal 1K trajectories;
webshop suboptimal 1.5K trajectories;
webshop suboptimal 5K trajectories;
webshop suboptimal 10K trajectories
在Procgen数据集上,评估了几种在其他离线学习基准上具有竞争力的方法:
( 1 )行为克隆( BC ),( 2 )批约束Q学习( BCQ ),( 3 )保守Q学习( CQL ) ,( 4 )内隐Q学习( IQL ),( 5 )行为克隆转换( BCT ) ,( 6 )决策转换( DT ) 。
对于WebShop数据集,评估了BC,CQL和BCQ。我们无法评估现有的基于变压器的方法,如DT或BCT,因为它们的潜在因果变压器的上下文长度有限。许多WebShop状态有512个令牌,因此我们通常无法拟合变压器上下文中的多个(状态,动作)对。类似地,对于IQL,实现损失函数并不简单,因为在WebShop中,每个状态的动作空间是不同的,因此动作空间的大小不是固定的。由于这些算法无法应用于WebShop而不发生显著变化,因此不在本文的研究范围之内。
5.实验结果
5.1利用专家数据对新环境进行泛化
图2展示了在Procgen16个任务下使用expert dataset训练的平均性能。在这种情况下,BC超出了所有的offline RL算法和序列决策算法。DT、BCT这种序列决策模型在原始任务上虽然比offline RL算法高,然而泛化性能却更低(且对比BC而言,训练集下的性能gap很小,但是在泛化时的gap却大幅度提升),这说明了transformer-based算法的泛化问题较严重。
图2:在Procgen 1M专家数据集上的表现。当在专家论证会上进行训练时,训练和测试所有16个Procgen游戏的一种小型地震检波器归一化返回结果。每种方法在从测试集中均匀采样的100个阶段中进行在线评估。IQM综合度量是在5个模型种子上计算的,误差条代表上( 75th )和下( 25th )区间估计。BC在训练和测试环境下都优于所有离线的RL和序列建模方法。所有离线学习方法在训练和测试上都落后于在线RL。
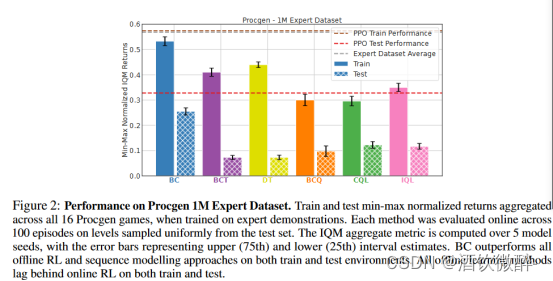
泛化到新环境(专家数据集)
现有的离线学习方法很难推广到新的环境中,即使在专家论证(由经过充分训练的在线RL代理生成)上进行训练,在测试时间上也不如在线RL。行为克隆是一种有竞争力的方法,在训练和测试环境中都优于最先进的离线RL和序列建模方法。

5.2使用混合专家-次优数据对新环境的泛化
在5.1中,我们观察到离线RL方法在expert demonstrations上训练时很难推广到新的环境中。
在单一环境(在相同的环境下对agent进行训练和测试)上的先前工作表明,当在次优演示上训练时,最先进的离线RL方法通常优于BC。
在5.2中,研究了当agent在不同的环境中进行训练和测试时,这一发现是否成立。为此,我们通过均匀混合来自专家PPO检查点和另一个检查点的数据创建一个混合的、专家次优的数据集,该检查点的性能是专家的50 %。因此,这些数据集的平均情景收益约为专家数据集的3 / 4。
如图3所示,与之前的结果相反,仍然是BC超过了其它SOTA offline RL算法的性能(即使使用次优数据,BC在测试水平上也优于其他离线学习基线)。不过,所有的方法都有类似的generalization gap即二者的差值,证明了它们的泛化能力是类似的,同时也说明了BC在多样的数据集下训练能够获得非常好的性能,即使这些demonstration是suboptimal的。在Procgen和其他CMDPs中,训练性能较好的方法通常也具有较好的测试性能,因为学习解决所有的训练任务都是非平凡的,并且现有的算法通常是欠拟合而不是过拟合。在这种情况下,现有的算法在优化和泛化问题上都面临挑战。
IQL原本能够在单一环境上获得SOTA性能,却在混合数据训练情况下性能很低,且难以泛化到test环境。因此,看起来是使用较多样性的数据来训练且要求在不同的环境上进行泛化会使得offline RL和序列决策模型面临新的挑战,即使它们能够在同质化的数据集下(同一个环境)实现较好的测试性能。
图3:在Procgen 1M混合专家-次优数据集上的性能。当在混合专家-次优演示上训练时,在所有16个Procgen游戏中训练和测试一种小型地震检波器归一化回报。每种方法在从测试集中均匀采样的100个阶段中进行在线评估。在3个模型种子上计算IQM聚合度量,误差条代表上( 75th )和下( 25th )区间估计。与图2类似,BC在训练和测试环境下都优于所有离线RL和序列建模方法。所有离线学习方法在训练和测试上都落后于在线RL。
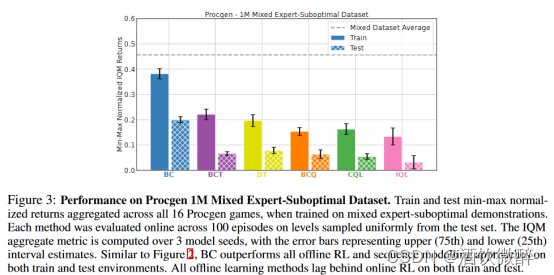
泛化到新环境(混合专家-次优数据集)
行为克隆在从多个环境的次优数据中学习时,在训练和测试环境中也优于最先进的离线RL和序列建模方法。

5.3单一环境下的训练与测试
根据前一部分的工作,SOTA offline RL算法能够在suboptimal数据集上超过BC;且BC能够在expert数据集上超过offline RL算法【相同环境】。(1)离线RL方法通常在单一环境的次优数据上训练并在相同的上测试时优于BC。同时,(2)BC已被证明在单个环境的专家数据上训练时优于离线RL。在这里,我们的目的是验证这两个观测(1)(2)在Procgen中是否成立,以确认我们实现的正确性。
在这一部分中,展示了当从单一层面对专家和次优数据进行训练和测试时的结果。在两个具有专家或次优演示的不同数据集,两个具有40和1种子的不同游戏水平,以及所有16个Procgen游戏中进行了实验。通过滚动最后的PPO检查点收集了这两个级别中的100,000条专家轨迹,并通过均匀抽样从两个检查点(最后一个检查点和另一个检查点)的转换中收集了这两个级别中的100,000条次优轨迹,其性能是最终检查点的50 %,类似于我们在前一部分中所做的工作。
如图4所示,确实大致能够符合前人工作。除了在mixed数据集上的chaser环境,这是因为该环境具有非常高的随机度,使得action难以被预测。之前的工作也表明,offlineRL算法和序列决策问题难以在随机环境中学到一个robust的策略。
图4(top)显示了在专家数据集上训练时的结果,在大多数游戏中,离线学习方法的表现与PPO相当,其中许多算法达到了可能的最大得分(如图10)。图4 (bottom)显示了在次优数据集上训练时的结果,其中离线RL方法要么与BC相当,要么优于BC,这与之前的工作一致。
特例是Chaser,当从专家和次优演示中学习时,大多数离线学习方法很难匹配平均数据集的性能。这并不奇怪,因为Chaser是一个高度随机的环境,包含多个移动实体,它们的行为无法预测。在这种情况下,通常需要更多的数据来学习好的离线(为了覆盖更多的可能被访问的状态)策略。同样适用于在相同环境下训练和测试时,离线学习的表现落后于在线学习方法的其他游戏。先前的工作还表明,离线RL和序列建模方法很难在随机环境中学习稳健的策略。
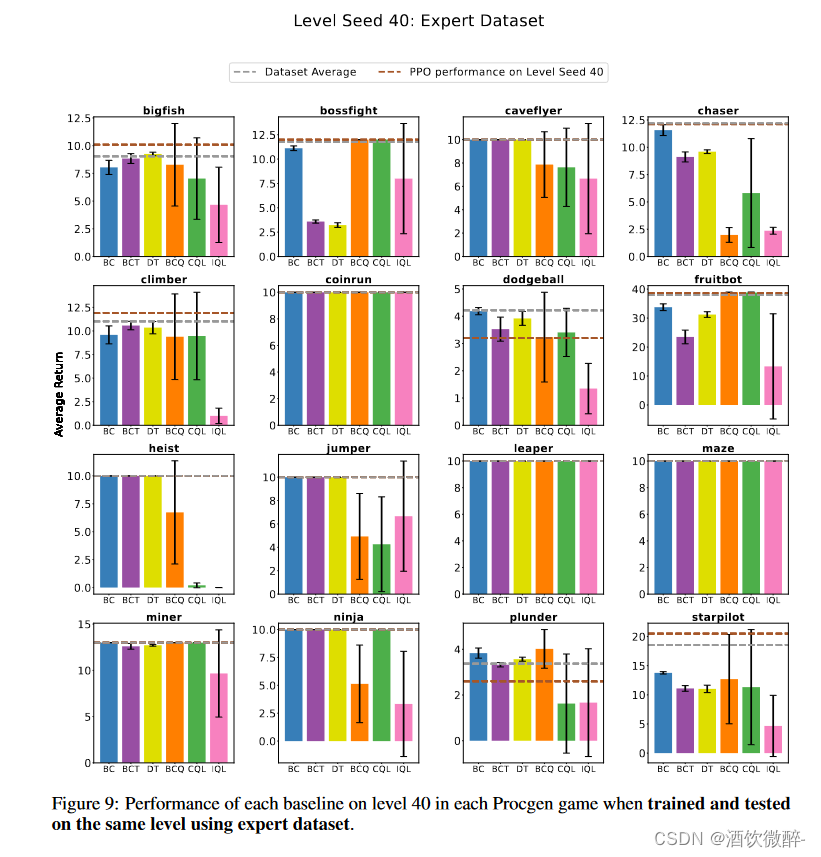
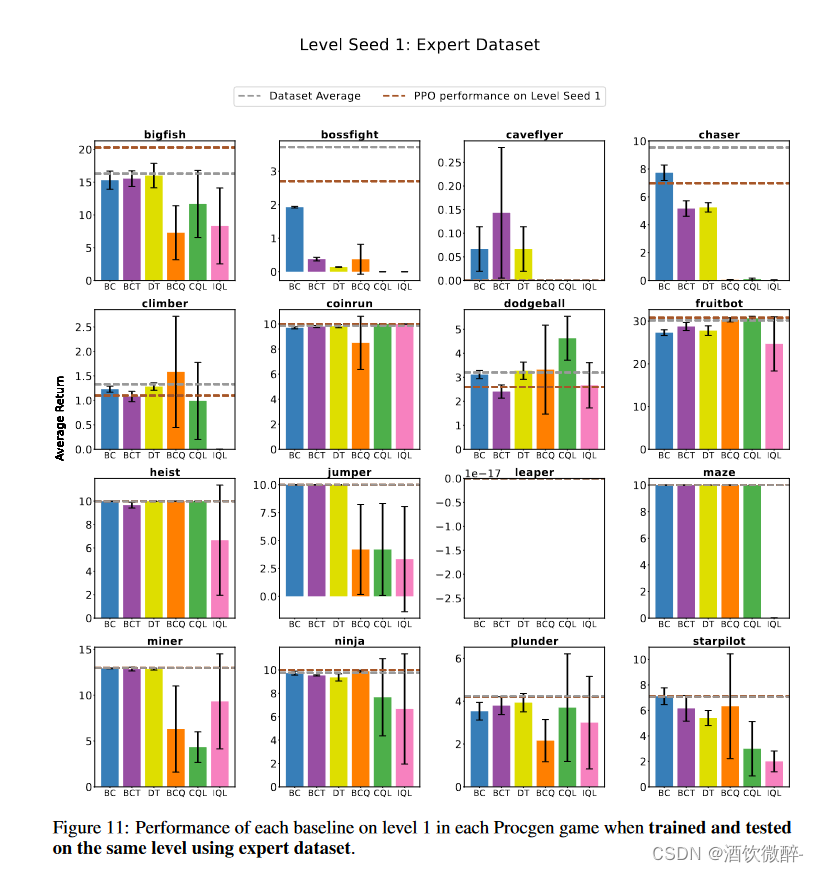
图4:当使用专家和次优数据集在同一水平上进行训练和测试时,每个基线在选定的Procgen游戏中的性能。在这里,我们报告了所选级别的性能:Chaser,Coinrun,Jumper和Leaper。对于所有游戏,参见附录一中的图9和图10。

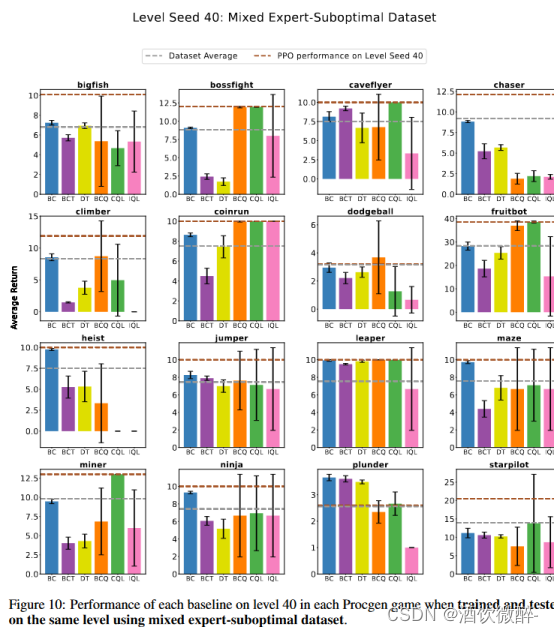
在相同环境下训练和测试次优演示时,离线RL的性能与BC相当,或在某些情况下优于BC。然而,正如前面章节所示,当这些算法在多个不同的环境中进行训练和测试时,这一发现并不成立。在这种情况下,BC往往优于其他离线学习方法,如图9所示。
单一环境下的训练和测试
所有离线学习算法在同一环境下训练和测试时表现良好,但在多个环境下训练和在新环境下测试时难以学习和推广。当使用专家数据在相同环境下进行训练和测试时,行为克隆表现最好,正如预期的那样。当在专家-次优混合数据上训练时,离线RL在大多数游戏上的表现与行为克隆相当或更好,这与之前的工作一致。

5.4数据多样性对泛化能力的影响
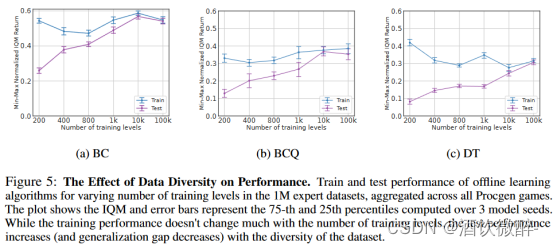
为了进一步研究数据的多样性对offline算法泛化能力的影响,本文保持数据集的规模1M不变,调节training levels(数据的多样性)(200,400,800,1k,10k和100k个),所有的offline算法在每个training level上使用相同的超参数。如图5所示,虽然训练性能变化不大,但是泛化性能能够得到显著提升。
对于each game,在相应的水平数上训练25M步的PPO策略。然后使用最终的PPO检查点(经过25M的训练步骤)收集总共1M个变迁(从相应的层次),并在这些数据集(对所有数据集使用相同的超参数)上训练每个离线学习算法。为了评估这些政策,我们遵循H.2 . 1节所述的程序。更具体地说,对于每个数据集,我们分别从[ n ,∞) ,其中n∈[ 250 , 450 , 850 , 1050 , 10050 , 100050]中随机抽取100个测试级别,并通过与这些级别的在线交互来评估模型。在每种情况下,[ n-51 , n - 1]中的级别用于评估,[ 0 , n-51 ]中的其余级别用于训练。由于我们对所有数据集都使用固定数量的迁移,因此层次的数量是数据集多样性的代理。由图5可知:
(数据多样性对泛化的影响
增加数据集的多样性,例如,在保持数据集大小不变的情况下,增加训练环境的数量,这将导致所有离线学习算法在新环境下的性能显著提高。)
图5:数据多样性对性能的影响。在1M专家数据集中训练和测试离线学习算法在不同数量的训练水平下的性能,在所有的Procgen游戏中聚合。图显示IQM和误差条代表在3个模型种子上计算的第75和25百分位数。虽然训练性能随训练层数变化不大,但测试性能随数据集的多样性增加(和泛化差距减小)。

5.5数据规模对泛化能力的影响
在机器学习的其他领域,众所周知,数据集的大小在模型性能和泛化能力中起着至关重要的作用。
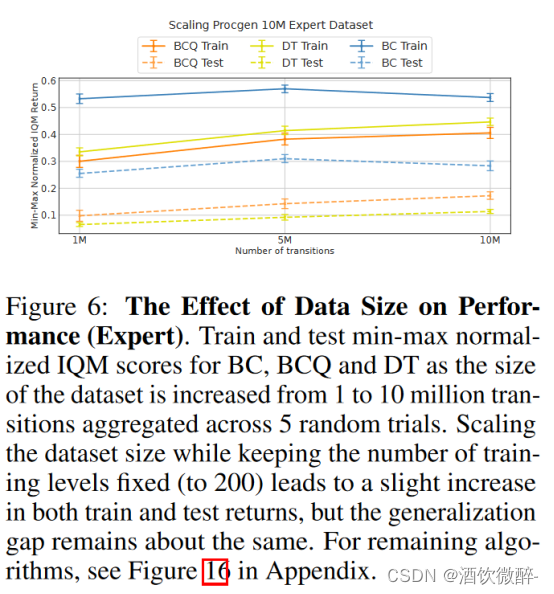
在这一部分中,研究了当数据集的多样性和质量固定时,泛化性与数据集大小之间的关系。为此,在Procgen中对训练数据集(专家和次优的(附录J) )进行了扩展,将数据集的规模从100万逐步增加到500万,然后再增加到1000万。在整个缩放过程中,保持其他所有超参数相同,并且训练层数恒定为200。从图6可以看出,在4种离线学习算法中,由于数据集规模的增加,训练和测试性能都只有小幅度的提高。然而,注意到generalization gap几乎保持不变。这表明增加数据集(在保持总规模不变的情况下)的多样性比增加数据集(在保持其多样性的同时)和(见图5)的大小能带来更大的泛化性提升。
保持模型的参数和training level不变,缩放数据集的大小从1M到5M再到10M。根据图6所示,提升数据量只有一点性能提升且generalization gap基本保持不变,这表明提升数据集的多样性能够更充分的带来泛化性能的提升。
图6:数据规模对绩效的影响(专家)。训练和测试一种小型地震检波器标准化的BC、BCQ和DT的IQM得分,随着数据集的大小从100万增加到1,000万,跨越5个随机试验。在保持训练水平数量不变(至200 )的情况下,扩大数据集规模会导致训练和测试收益的小幅增加,但泛化差距保持不变。对于其余算法,见附录中的图16。
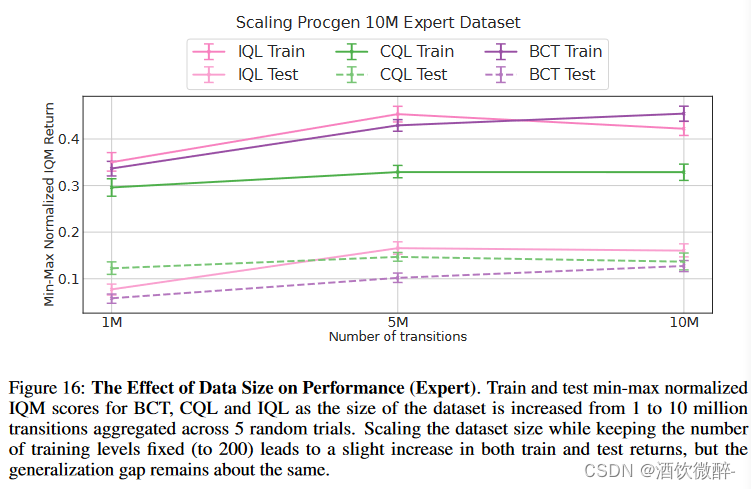
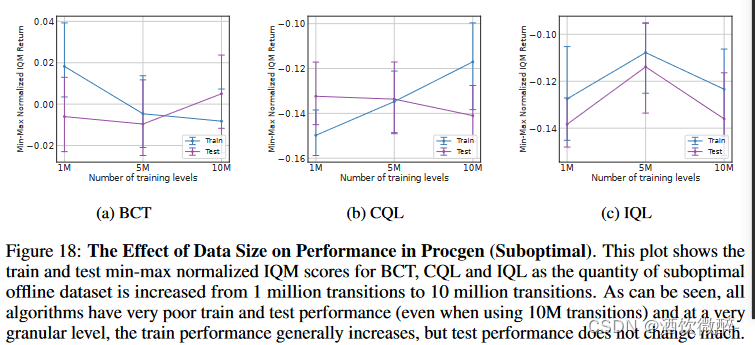 从图16可以看出,随着数据规模的增大,3种方法的泛化能力差距几乎保持不变。在次优数据集上(图18 ),所有方法的训练和测试性能都很差,与先前的工作相反,在我们的设置中,当我们从行为策略的训练日志中的子集上采样并训练离线学习算法时,得到的离线学习策略根本没有泛化能力,甚至在200个训练水平上也没有表现出良好的性能。
从图16可以看出,随着数据规模的增大,3种方法的泛化能力差距几乎保持不变。在次优数据集上(图18 ),所有方法的训练和测试性能都很差,与先前的工作相反,在我们的设置中,当我们从行为策略的训练日志中的子集上采样并训练离线学习算法时,得到的离线学习策略根本没有泛化能力,甚至在200个训练水平上也没有表现出良好的性能。
数据规模对泛化性的影响
单独增加数据集规模而不增加其多样性,例如增加迁移次数而不同时增加训练环境的数量,对于任何离线学习算法来说,在新环境下都不会带来显著的性能提升。

5 .6利用人工演示对新指令进行泛化
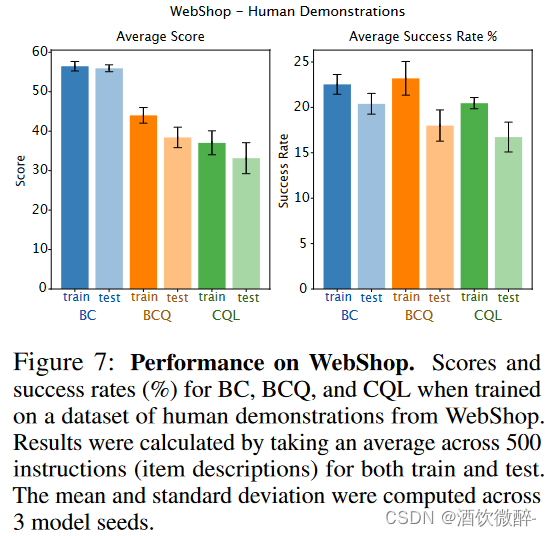
本节想验证一种新的generalization方式,即未见过的初始状态和reward functions(旨在评估一种不同类型的泛化,即对未知初始状态和奖励函数的泛化);同时希望验证上述结论是否在更加真实的场景中成立(human demonstrations)。如图7所示,BC在train和test上获得的性能分数最高,且generalization gap最低,虽然训练集上的成功率不是最高的,但是泛化的成功率达到了最高,表明了BC的优势。同时本文还发现,如果训练时间更久,这些方法都会陷入过拟合导致test上性能降低。
在人类演示数据集上,无论是在人类数据集的训练指令还是测试指令上,BC都取得了比CQL和BCQ更高的分数。值得注意的是,BC中的训练成绩和测试成绩之间的差异并不是很大。然而,如果训练时间更长,所有这些方法都获得了更好的训练性能,但它们的测试性能开始下降,这表明它们容易产生过拟合。在训练过程中,BCQ的成功率略高于BC和CQL。然而,在测试时间内,BC达到了最高的成功率,从而使BC成为该领域中性能更好的基线。报告了附录L.1中关于次优证明的结果(在这里,我们在使用预训练的行为克隆策略(见附录F.2)收集的数据集上训练BC,CQL和BCQ,以测试缩放情节数量(因此,目标指令的多样性)对这些基线性能的影响。图19显示,在所有三个基线中,当数据集至少有500个情节时,训练和测试性能显著提高。在此之后,虽然训练水平和测试水平的得分上升幅度不大,但BCQ和CQL的成功率有小幅上升的趋势。总体而言,与Procgen相似,BC在所有数据集上都优于BCQ和CQL,因此强调了在该领域进行更多研究的必要性)。
图7:在Webshop上的表现。在来自Webshop的人体示范数据集上训练时,BC,BCQ和CQL的分数和成功率( % )。结果通过对500份培训和测试的说明书(项目描述)取平均值来计算。计算了3个模型种子的平均值和标准差。
(见附录F.2):
Environment:Webshop是一个基于文本的网络导航环境,用于评估基于语言的智能体的自然语言指令跟踪和顺序决策能力。在这种环境下,有两类任务:搜索和选择。
(1)对于搜索任务,智能体必须学习根据对所需产品的描述生成相关的关键字,以增加在搜索结果中获得良好产品匹配的可能性。
(2)对于选择任务,代理需要通过搜索页面和每个项目的单独页面来选择、定制和购买与指令中提到的所有属性相匹配的项目。
由于我们的研究范围是评估线下代理人的序贯决策能力,因此我们的研究仅限于选择任务。对于搜索任务,我们使用中使用的预训练BART模型,在测试时刻生成搜索查询,然后继续推出我们的预训练策略。
Offline Data Collection:对于Webshop,收集了两类离线学习数据集:( i )作者提供的人类演示数据集,该数据集允许创建一个固定大小的高质量(因为人类的示威活动可以被认为是金标准)数据集;( ii )基于这些人类演示预训练的模仿学习( IL )策略,该策略允许创建多个不同大小的数据集,以研究性能如何随数据集大小和多样性而变化。
作者还通过Webshop的源代码*中提供的健身房环境模拟轨迹,收集了1571个人类演示中的452个环境奖励。该环境的初始状态由随机选取的10个英文字母决定。因此作者反复调用重置函数,直到环境生成数据集中的一条指令。然后执行数据集中情节的动作,验证环境每一步返回的状态与数据集(除了最后一个状态,由于数据集没有存储确认状态,一旦一个情节完成)中的状态相同。奖励是在飞行中收集的,作者将它们与"状态"、"行动"等一起存储在"奖励"的键下。通过这种方式,作者能够从Webshop环境中收集到452条轨迹及其对应的每步奖励(在人类数据集的1571个数据中)。
在原文的基础上,作者仅使用文本模态来表示观察。在人类数据集中,我们有452个片段,其中训练片段有398个片段,3.7 k个转换,平均奖励为7.54,评估片段有54个片段,406个转换,平均奖励为8。作者还使用f WebShop的作者提供的最终IL检查点来收集不同大小的数据集,即∈100,1000,1500,5000,10000集,其中所有这些数据集的平均奖励为5.8 - 5.9。在这种情况下,更大的数据集也具有不同自然语言指令(或条目描述)指定的环境实例的更大多样性。
6.结论
在本文中,比较了在线和离线学习方法的泛化能力。本文的实验表明,现有的离线学习算法(包括SOTA离线RL、行为克隆和序列建模方法)在新环境下的表现明显差于在线RL方法(如PPO )。
论文首先介绍了一个用于评估离线学习算法泛化性的基准。这种基准的缺失在历史上限制了作者对这些算法在真实世界中适用性的理解,因此作者的工作致力于弥合这一鸿沟。为了实现这一点,作者从Procgen和WebShop中发布了一组包含轨迹的离线学习数据集。
本文的结果表明,现有的不考虑泛化性的离线学习算法不足以应对这些挑战,这对于使它们能够用于实际应用是至关重要的。作者观察到,即使不增加数据集的大小,增加数据集的多样性也可以导致泛化能力的显著提高。与先前在单一环境下离线RL的工作相反,作者发现它们的泛化性并没有随着数据集的大小而显著提高,同时也没有增强其多样性。因此,走着认为需要更多的工作来开发能够在测试时在新场景中表现良好的离线学习算法。